Рассматриваем дизайнерские идеи отличных подключаемых систем от VS Code

👉Введение
В популярных в настоящее время фреймворках обычно используются плагины для настройки и расширения возможностей системы. На самом деле, система плагинов имеет более профессиональный термин в архитектуре программного обеспечения: микроядерная архитектура. В этой статье будут подробно представлены принципы, преимущества и классификации микроядерной архитектуры, а также проанализированы отличные примеры программного обеспечения. Наконец, в сочетании со средним фронтенд-проектом, за который в настоящее время отвечает автор, поделитесь практикой. микроядерная архитектура в реальных проектах. Из этой статьи вы узнаете, что такое система плагинов, как спроектировать систему плагинов и как более элегантно реализовать систему плагинов. Добро пожаловать к чтению.
👉Содержание
1 Обзор микроядерной архитектуры
2 Зачем нужна микроядерная архитектура?
3 Как реализовать плагины
4 передовых метода разработки плагинов VS Code
5 Практика и усовершенствование системы плагинов H5 Forgame
6 Резюме
01
Обзор микроядерной архитектуры
Что такое микроядерная архитектура? Если вы измените название, возможно, оно всем будет знакомо, и это система плагинов. Большая часть крупномасштабного программного обеспечения, с которым мы сталкиваемся в нашей реальной работе и жизни, имеет подключаемые модули.
Например, инструмент разработки VS Code имеет мощную систему плагинов, которая может добавлять новую поддержку синтаксиса, новые темы и даже возможности, которые VS Code изначально не поддерживал. Благодаря более чем 20 000 плагинов, предоставленных сообществом VS Code. Способность становится непобедимой.
Для сравнения, такое программное обеспечение, как «Блокнот», без системы плагинов имеет единственную функцию и не имеет возможности расширения.
Другие мощные системы плагинов включают браузер Chrome и инструменты разработки внешнего интерфейса Webpack, Rollup и т. д. Почти все крупномасштабное программное обеспечение имеет систему плагинов.
В микроядерной архитектуре основную часть программного обеспечения часто называют микроядром или хост-программой. Микроядро предоставляет некоторые стандартные интерфейсы и точки расширения, которые позволяют плагинам взаимодействовать с ним определенными способами. Плагины — это независимые модули, которые можно разрабатывать независимо, загружать и выполнять в главном приложении.
Необходимо ли в реальном процессе разработки внедрять микроядерную архитектуру? Ответ: нет. Ее необходимо объединить с потребностями программной системы, чтобы увидеть, есть ли необходимость в ее настройке или расширении, и можно ли ее решить? проблемы, с которыми сталкивается существующая система программного обеспечения.
Далее мы расскажем, какие проблемы решаются и какие преимущества дает использование микроядерной архитектуры.
02
Зачем нам нужна микроядерная архитектура
Итак, какие проблемы программного обеспечения решает микроядерная архитектура?
В основном это отражается в двух аспектах: настройке существующих возможностей самого программного обеспечения и предоставлении новых возможностей программного обеспечения;
Преимущество этого подхода заключается в том, что он предоставляет набор открытых интерфейсов, которые позволяют третьим сторонам участвовать в настройке и расширении программного обеспечения, позволяя гибко расширять возможности большого программного обеспечения.
Фактически не существует единого стандарта реализации микроядерной архитектуры. Ее архитектура показана на рисунке ниже:
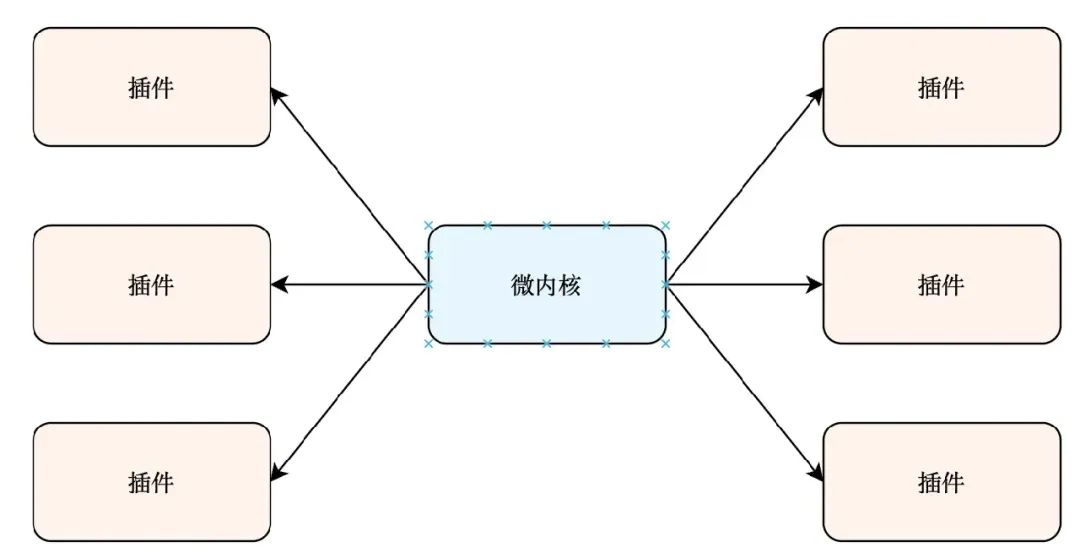
Основной код микроядерной архитектуры поддерживает единую логику и отвечает только за запуск и уничтожение программ, а также за загрузку, выполнение и выгрузку функциональных модулей. Наложение функций программного обеспечения реализуется с помощью различных плагинов, которые устанавливаются на ядро для реализации расширения функций.
Это позволяет динамически расширять и настраивать функциональные возможности программного обеспечения, улучшая существующие функциональные возможности программного обеспечения или добавляя новые без изменения основного программного кода.
Вы можете взглянуть на еще один архитектурный проект, полностью противоположный микроядру:
Объедините часть программного обеспечения и его различные функции и соедините основные функции с каждым функциональным модулем, как показано ниже:
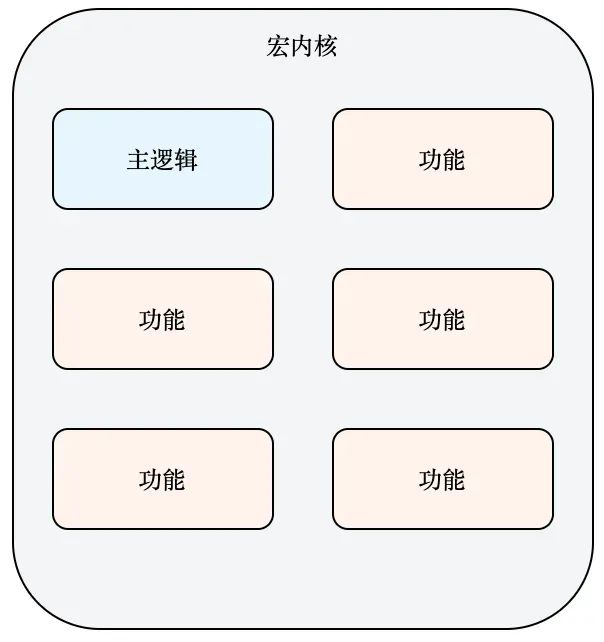
В этом сценарии, когда нам нужно настроить определенную функцию, нам необходимо напрямую изменить базовую логику программного обеспечения, что явно не соответствует принципу открытия и закрытия при разработке программного обеспечения. Это не только увеличивает сложность разработки программного обеспечения, но и увеличивает его. обслуживание, но также значительно увеличивает сложность расширения программного обеспечения, так что само программное обеспечение не обладает хорошей масштабируемостью.
Если вы измените архитектуру макроядра на архитектуру микроядра:
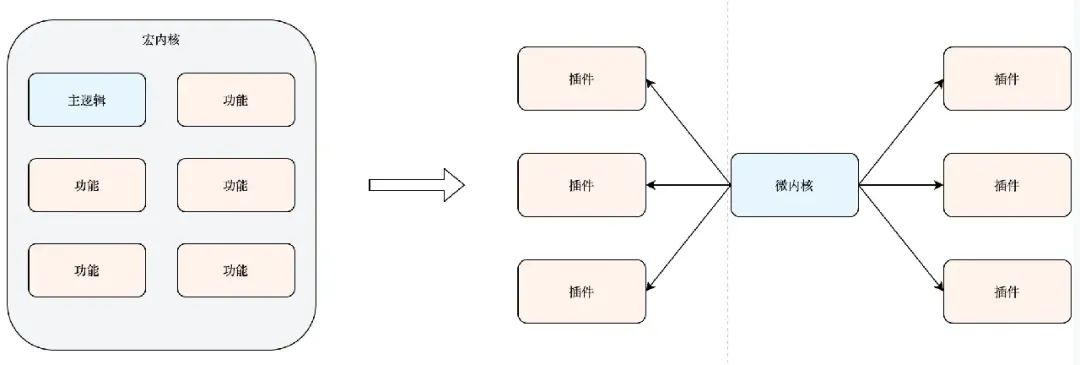
Каждая функция становится плагином, который поддерживается и разрабатывается независимо и не связан с ядром. Каждый плагин должен быть настроен и может быть изменен и выпущен независимо, не затрагивая другие плагины и ядро. Также можно добавлять новые плагины. По сравнению с макроядром сложность обслуживания программного обеспечения значительно снижается. В то же время, если следовать определению интерфейса плагина, для программного обеспечения можно разработать новые функции, что снижает сложность программного обеспечения. расширение и придает программному обеспечению хорошую гибкость и масштабируемость.
Подводя итог, микроядерная архитектура имеет следующие преимущества:
Гибкость и масштабируемость: система плагинов позволяет программному обеспечению загружать и выгружать плагины во время выполнения, обеспечивая гибкое расширение и настройку функций. С помощью плагинов можно добавлять, удалять или заменять определенные функции в соответствии с потребностями пользователя без изменения основного кода, что упрощает расширение и адаптацию программного обеспечения к меняющимся потребностям. Повторное использование кода и модульность. Плагины можно рассматривать как независимые модули, которые можно повторно использовать в разных приложениях. Такая модульная конструкция делает код более удобным в сопровождении, уменьшает избыточность кода и улучшает повторное использование кода. Участие сообщества и обмен информацией: система плагинов поощряет участие и вклад сообщества, а сторонние разработчики могут разрабатывать свои собственные плагины и интегрировать их с программным обеспечением. Таким образом, функции программного обеспечения значительно расширяются, и члены сообщества могут делиться своими собственными расширениями, способствуя развитию экосистемы программного обеспечения. Развязка и удобство обслуживания: система плагинов помогает разделить функции программного обеспечения на независимые части и уменьшает связь между модулями. Это упрощает обслуживание программного обеспечения. Когда какую-либо функцию необходимо изменить или обновить, вам нужно сосредоточиться только на соответствующем плагине, не затрагивая всю систему. Оптимизация производительности и ресурсов. Динамическая загрузка и выгрузка плагинов позволяет программному обеспечению выбирать загрузку определенных функций по мере необходимости, тем самым экономя память и вычислительные ресурсы и повышая производительность программного обеспечения. Настройка и персонализация: система плагинов позволяет пользователям настраивать функциональность и внешний вид программного обеспечения в соответствии со своими потребностями. Пользователи могут устанавливать и включать определенные плагины в соответствии с личными предпочтениями и рабочими процессами. |
|---|
Вообще говоря, архитектура микроядра обеспечивает гибкость, масштабируемость и возможности настройки программного обеспечения, делая программное обеспечение более мощным и адаптируемым. Это один из ключевых элементов для создания многофункционального, простого в обслуживании программного обеспечения с сильной экосистемой.
03
Как реализовать плагин
Ранее мы говорили о различных преимуществах микроядерной архитектуры. В этом разделе будут представлены конкретные реализации микроядерной архитектуры и анализ микроядерной архитектуры известного программного обеспечения. Благодаря этим случаям мы можем применить микроядерную архитектуру к нашим собственным проектам.
Хотя архитектура микроядра реализуется по-разному, обычно она включает в себя следующие этапы:
Определите интерфейс плагина: во-первых, вам необходимо определить интерфейс между плагином и основной программой, включая метод инициализации плагина, метод выполнения, мониторинг событий и т. д. Это гарантирует стандартизацию взаимодействия плагина и основной программы. Как загружать плагины: Определите форму загрузки плагинов, например, через пакеты npm, через файлы, через репозитории git и т. д. Хорошая организация плагинов делает всю систему достаточно гибкой. Разработка времени загрузки плагинов, например, отложенная загрузка, загрузка по зависимости и т. д., а также хороший контроль времени загрузки могут улучшить производительность больших систем. Регистрация и управление плагинами: основная программа должна обеспечивать функции регистрации и управления плагинами для управления загруженным списком плагинов. Когда плагин загружен, зарегистрируйте его в основной программе, чтобы основная программа могла вызывать возможности плагина. Механизм связи событий. Между основной программой и подключаемым модулем должен быть установлен механизм связи событий, чтобы обеспечить взаимодействие при необходимости. Вы можете использовать пользовательские события, режим публикации-подписки или режим наблюдателя для отслеживания и запуска событий. Конфигурация плагина: вы можете предоставить некоторые параметры конфигурации плагина, чтобы его поведение можно было настроить в соответствии с потребностями пользователя. Соображения безопасности. Системы подключаемых модулей предполагают динамическую загрузку кода, поэтому безопасность является важным фактором. Убедитесь, что загружены только доверенные плагины, и выполняются проверки безопасности кода плагина, чтобы предотвратить внедрение потенциально вредоносного кода. |
|---|
В отрасли существует множество видов моделей.,Но после индукции.,Мы считаем, что наиболее часто используемыйиз В основномк Следующие три типаплагинмодель:Тип трубы, тип лукаитип события,Наиболее широко используется тип событияплагин.,Далее мы также представим эти три режима плагина с точки зрения «функций» и «приложения».
3.1 Плагин конвейера
Плагин Pipeline — один из часто используемых шаблонов проектирования плагинов. Его основная цель — разбить поток обработки на ряд независимых шагов и позволить разработчикам расширять или изменять эти шаги с помощью подключаемых модулей, обеспечивая тем самым более гибкий и удобный в сопровождении код.
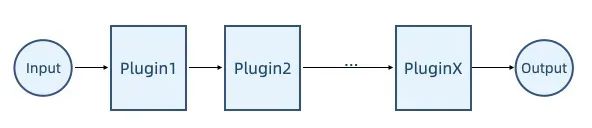
Как показано на рисунке выше, в плагине конвейера поток обработки представлен в виде конвейера. Данные вводятся с одного конца конвейера, обрабатываются посредством ряда шагов и, наконец, выводятся на другом конце конвейера. . Каждый этап обработки реализуется плагином, который отвечает за выполнение определенной задачи и передачу обработанных данных следующему плагину.
3.1.1 Характеристики плагинов трубопровода
Преимущества конвейерных плагинов включают в себя:
▶︎ Сильная развязка: каждое звено конвейера независимо друг от друга, решает только конкретные проблемы и может разрабатываться, тестироваться и обслуживаться независимо.
▶︎ Когда ввод и вывод стандартизированы, плагины можно гибко комбинировать для динамического изменения структуры конвейера в соответствии с потребностями для достижения настройки и масштабируемости процесса обработки данных.
Например: конвейеры Linux, мы можем комбинировать различные команды конвейера для гибкой обработки данных. Ниже приведена комбинация команды cat и других команд.
# Строки с символами «ключевого слова» в выходном текстовом файле .txt.
cat file.txt | grep "keyword"
# выход file.txt Количество строк, слов и символов в файле.
cat file.txt | wc
# выходfile.txt Первый столбец файла
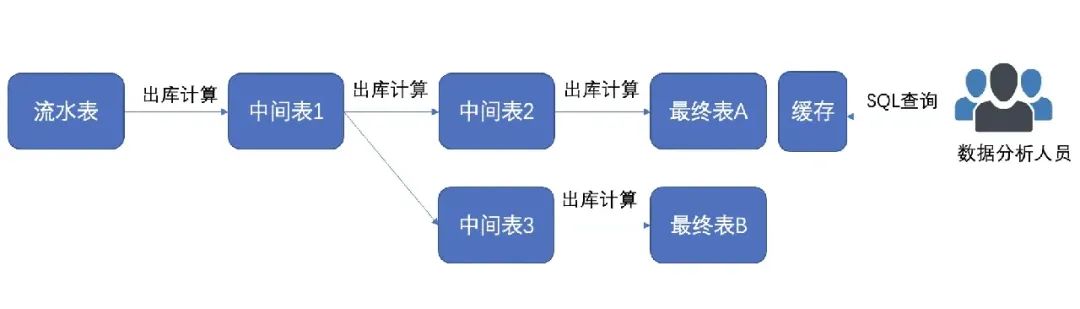
cat file.txt | awk '{print $1}'▶︎ Благодаря конвейерной архитектуре можно легко реализовать кэширование данных, асинхронную обработку, параллелизм и другие оптимизации для повышения эффективности обработки и производительности системы.
Например: Платформы анализа данных (такие как Lighthouse) используют конвейерную архитектуру для использования промежуточных таблиц и кэшей для повышения скорости запросов больших данных. В то же время из-за разборки каждой промежуточной таблицы сложность запросов SQL-операторов увеличивается. уменьшенный.
Ограничения конвейерных плагинов включают в себя:
При проектировании конвейера необходимо учитывать близость данных и порядок выполнения между плагинами, что может увеличить сложность разработки и проектирования. Если конвейерный процесс спроектирован неразумно, это может привести к неполноте и неточности данных, что повлияет на систему. |
|---|
- Конвейеры должны учитывать сходство данных и порядок выполнения между конвейерами.,Это может увеличить трудность и сложность разработки.
- нравиться фрукты неразумныйиздизайн трубопроводного процесса,Может привести к неполноте и неточности данных.,Влияние на систему.
Например: в вышеупомянутой платформе анализа данных, если задача исходящего вычисления промежуточной таблицы завершается сбоем, это может привести к сбою всех задач вычисления последующих промежуточных таблиц, что в конечном итоге сделает запрос данных недоступным.
3.1.2 Применение плагина конвейера
Плагины Pipeline находят применение во многих областях, таких как:
Конвейер обработки данных. При обработке данных подключаемые модули конвейера могут использоваться для выполнения таких задач, как преобразование, фильтрация и проверка данных, чтобы гарантировать, что данные обрабатываются должным образом на разных этапах. Автоматизированное выполнение задач: выполнение автоматической сборки, автоматического развертывания и других задач, таких как конвейер CI/CD и развертывание облачных сервисов. Инструменты внешней сборки. В инструментах внешней сборки, таких как Gulp, плагины конвейера широко используются для обработки и преобразования исходного кода, например компиляции, сжатия, объединения файлов и т. д. |
|---|
Если взять в качестве примера интерфейсный инструмент Gulp, то ниже представлена архитектурная диаграмма Gulp:
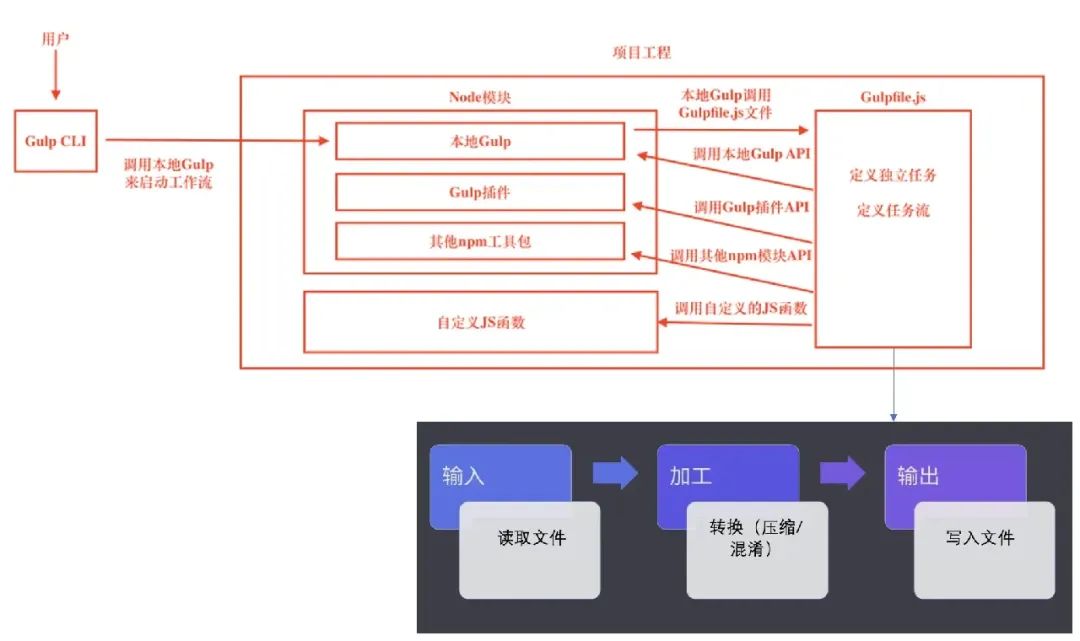
Источник изображения (Gulp для разработки интерфейса автоматизации — личный кабинет Хунчао — OSCHINA)
Пример конфигурации потока задач Gulp:
/*создавать Человек по имениcssиз Задача будетsrcв каталогеиз МестоиметьизlessПреобразование файлов стилей вcss,Затем сожмите и объедините его в файл с именем app.cssиз.,Добавьте подпись версии md5 в этот файл,
Сгенерируйте его по пути build/css, сгенерируйте файл сопоставления и поместите его в src/css*/.
gulp.task('css', ['cleanWatchBuild', 'txtCopy'], function() {
return gulp.src(['src/css/**/*.less'])
.pipe(less())
.pipe(minifyCss())
.pipe(concat('app.css'))
.pipe(rev())
.pipe(gulp.dest('build/css'))
.pipe(rev.manifest({
base: 'src/**',
merge: true
}))
.pipe(gulp.dest("src/css"));
});Подводя итог, можно сказать, что плагин конвейера — это мощный шаблон проектирования, который может сделать код более гибким, удобным в сопровождении и расширяемым, обеспечивая при этом модульный способ организации и решения сложных задач.
3.2 Луковый плагин
Плагин Onion Architecture также является широко используемым шаблоном проектирования плагинов, который произошел от Onion Architecture.
Луковая архитектура — это шаблон архитектуры программного обеспечения для создания удобных в обслуживании, гибких и тестируемых приложений. В луковой архитектуре основная логика приложения находится внутри, а внешние зависимости (такие как база данных, пользовательский интерфейс и т. д.) — снаружи. Луковая архитектура выражает различные проблемы, обертывая их слоями, подобно структуре луковицы, отсюда и название.
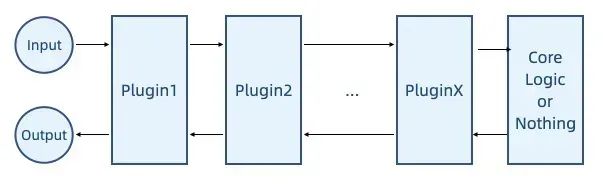
Плагины Onion сочетают в себе архитектуру луковицы с системой плагинов для создания подключаемых масштабируемых приложений. В этом режиме плагины можно загружать и выгружать динамически, не затрагивая основную логику приложения, что делает приложение более гибким и удобным в обслуживании.
3.2.1 Характеристики луковых плагинов
К основным преимуществам onion-плагинов относятся:
Луковая архитектура имеет четкую иерархию, а подключаемый модуль луковой архитектуры сохраняет внутреннее ядро и иерархию внешних зависимостей луковой архитектуры. Плагины часто считаются внешними зависимостями, в то время как основная логика хост-приложения находится внутри.
Он обладает хорошей возможностью повторного использования. Каждый уровень и компонент луковой архитектуры можно повторно использовать независимо и в разных проектах и сценариях, что повышает возможность повторного использования кода.
Например: например, многие промежуточные программы в Koa имеют хорошую возможность повторного использования (например, koa-session) и могут быть внедрены и использованы в нескольких проектах.
Плагины Onion позволяют запускать плагины один за другим во время обработки запроса. Плагины можно добавлять или удалять по мере необходимости, и каждый плагин может решать, продолжать выполнение или прекращать выполнение по мере необходимости. -ины очень подходят для выполнения роли сервисных перехватчиков.
По сравнению с конвейерными плагинами, луковые плагины обладают более полными возможностями по вмешательству в данные. Они могут не только вмешиваться и обрабатывать собственные каналы ввода данных, но также вмешиваться и обрабатывать вывод других плагинов в канале вывода данных.
Ограничения луковых плагинов включают в себя:
По сравнению с плагинами конвейера, которые являются более сложными, режим лукового плагина требует совместной работы и передачи данных между плагинами, то есть обработки входных потоков и обработки выходных потоков. При обработке сложной логики код может усложниться и стать более сложным. трудно понять.
Иерархическая вложенность в луковой архитектуре может увеличить количество и уровень вызовов функций, тем самым вызывая определенные потери производительности.
3.2.2 Применение луковых плагинов
Шаблон подключаемого модуля «луковица» широко используется в промежуточном программном обеспечении служб:
Плагин в стиле «луковицы» обладает гибкими возможностями обработки потоков данных с высоким уровнем полномочий (он может решать, прерывать или продолжать выполнение как во входных, так и в выходных каналах), что очень соответствует сценарию использования сервисного промежуточного программного обеспечения.
В области внешнего интерфейса, помимо Koa и Express, использующих режим лукового плагина, некоторые известные платформы Nodejs также используют режим лукового плагина, например Midway и Uni-request.
Если взять в качестве примера Koa, фаза работы плагина Onion пройдет три этапа:

- Регистрация задач
Koa использует метод use для регистрации задач.
- Оркестровка задач
Оркестровка задачразделен наПредварительная обработка, основная логика и постпроцессор.
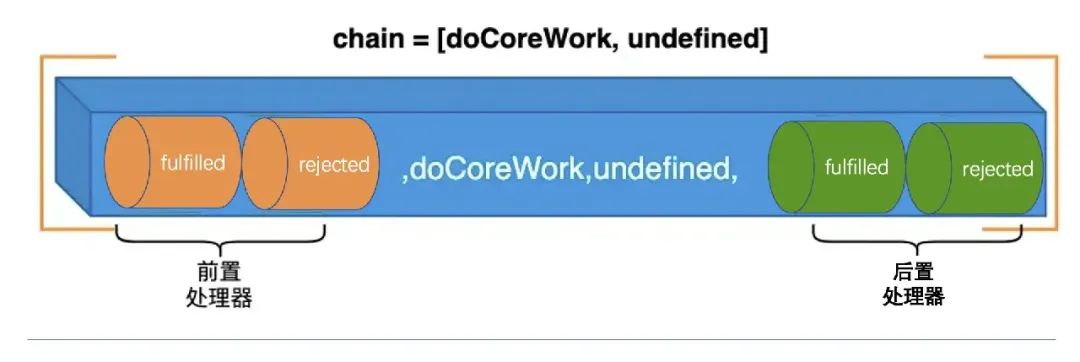
Изображение взято из статьи «Как лучше понять промежуточное программное обеспечение и луковые модели».
- Планирование задач
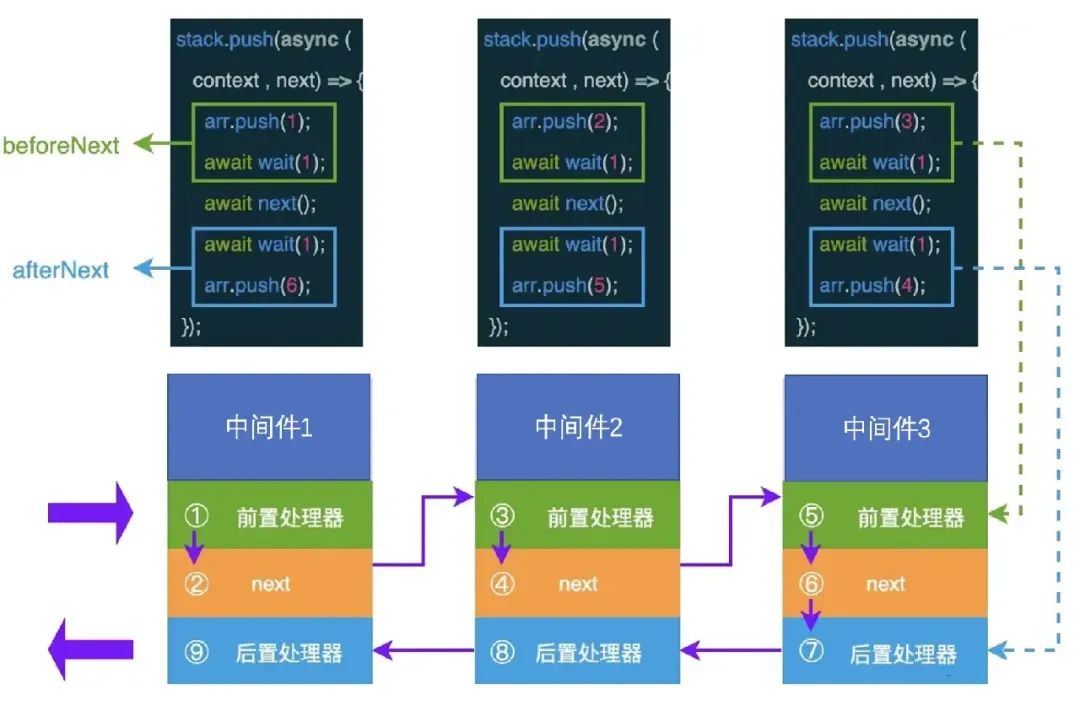
Планированием задач в Koa занимается Koa-compose.
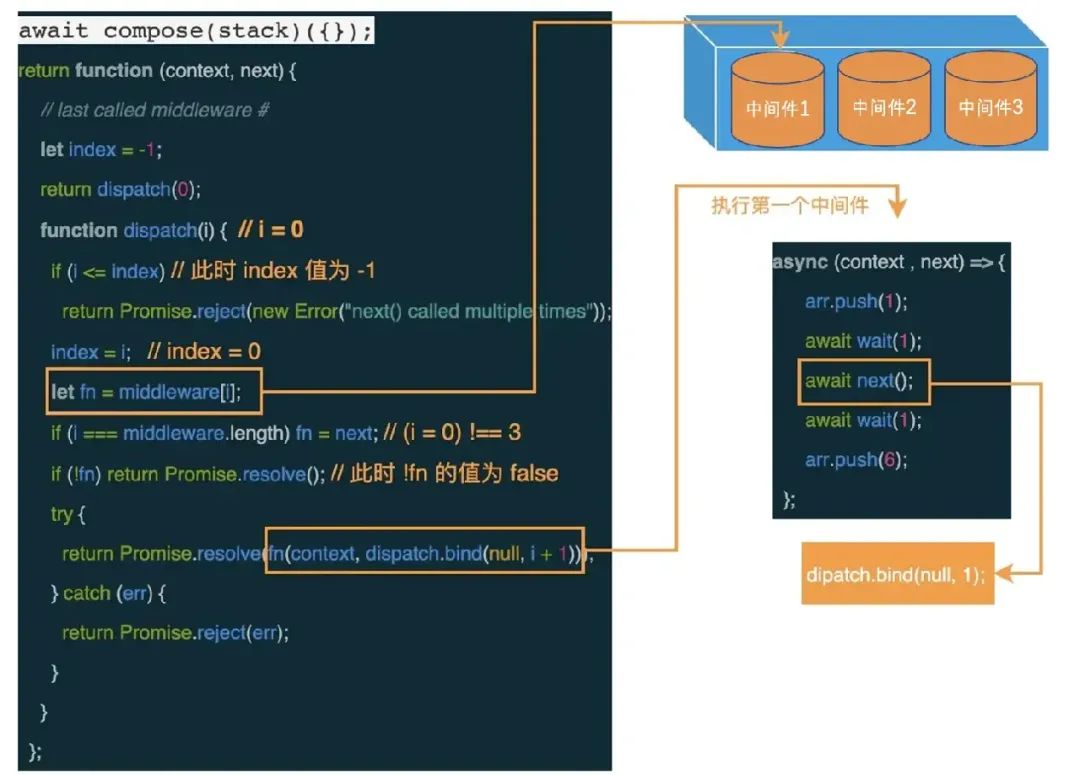
Изображение взято из статьи «Как лучше понять промежуточное программное обеспечение и луковые модели».
Вышеупомянутое предназначено для выполнения первого промежуточного программного обеспечения и запуска диспетчера (0). После того, как первое промежуточное программное обеспечение выполняет next(), оно запускает диспетчеризацию (1) и вводит второе промежуточное программное обеспечение и так далее.
3.3 Плагины на основе событий
Плагин на основе событий — это наиболее гибкий шаблон проектирования плагинов, основанный на программировании, управляемом событиями. В плагинах, основанных на событиях, основная программа (или главное приложение) уведомляет плагин о необходимости выполнения соответствующих операций, запуская события. Система плагинов позволяет плагинам регистрировать прослушиватели определенных событий и выполнять соответствующие функции при запуске соответствующих событий.
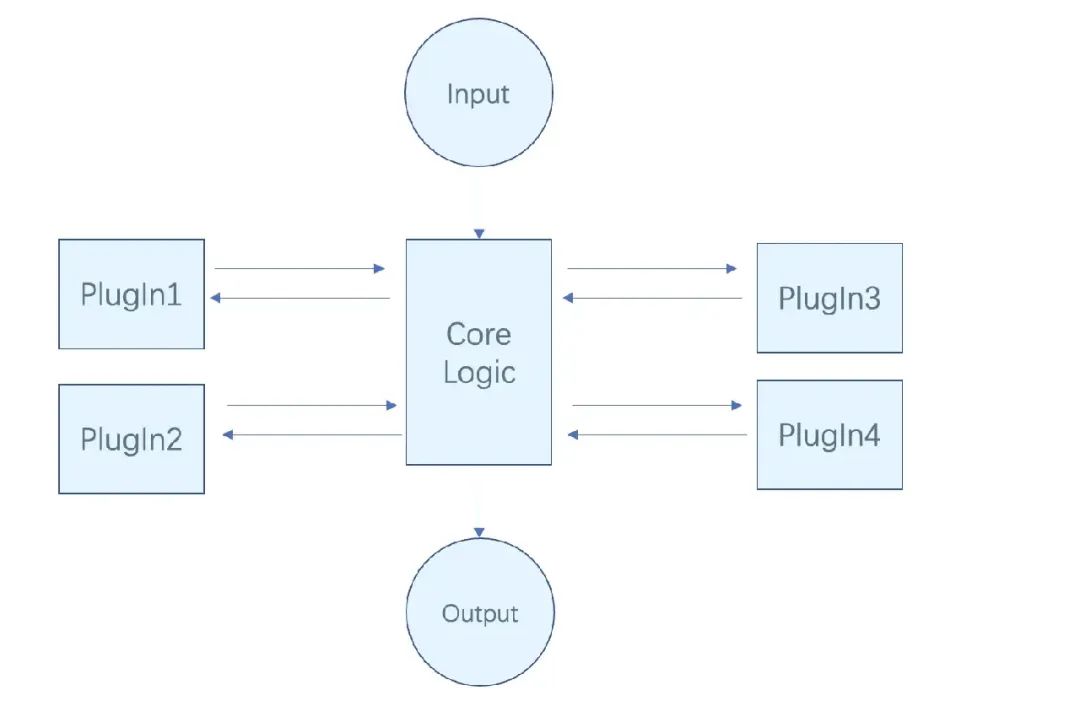
3.3.1 Характеристики плагинов, основанных на событиях
К основным преимуществам плагинов на основе событий относятся:
Высокая гибкость и широкие сценарии применения.
Он имеет различные режимы работы, множество типов событий, очень гибок и может быть адаптирован к различным сценариям.
Например, Webpack реализует механизм подключаемого модуля модели публикации-подписчика через Tapable, предоставляя синхронные/асинхронные перехватчики, последовательные/параллельные перехватчики, которые делятся на водопадные/страховые/циклические перехватчики в зависимости от типа выполнения и могут гибко комбинироваться для Meet Webpack компилирует и упаковывает все требования к функциональному расширению.
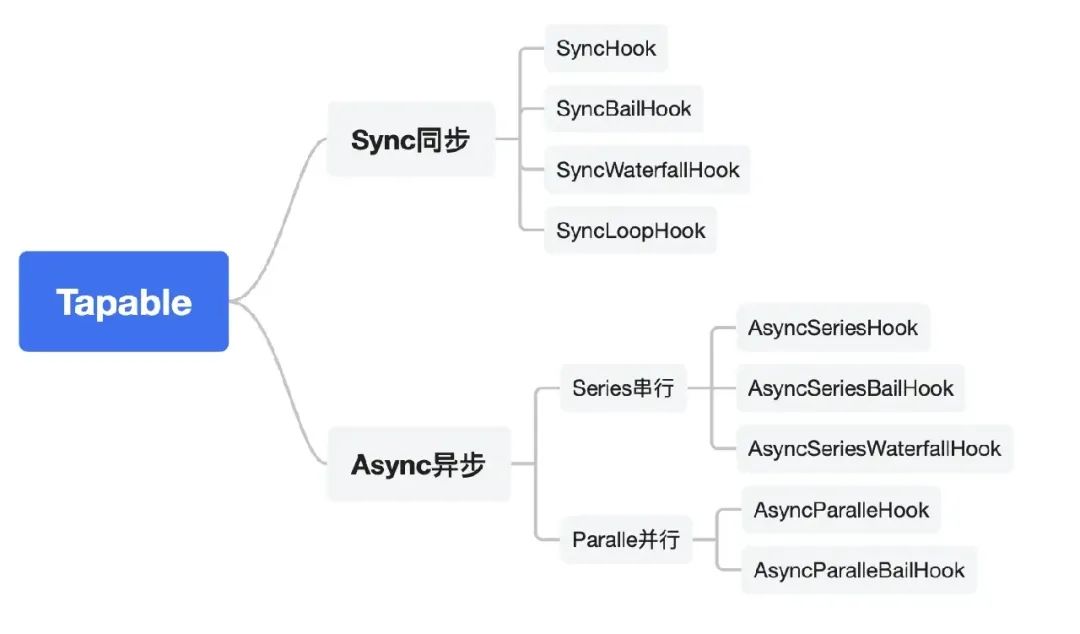
Картинка взята из «Tapable, просто прочитайте эту статью»
Время выполнения является асинхронным для повышения общей производительности.
Поскольку подключаемый модуль на основе событий реализован на основе публикации и подписки, время выполнения является асинхронным, а код выполняется неблокирующим образом, что полезно для повышения общей производительности.
В системе плагинов VS Code не будет иметь особых проблем с производительностью при работе с десятками приложений-плагинов не только потому, что плагины инициализируются после запуска событий, но и из-за преимуществ плагинов на основе событий. ins.
Подключаемый дизайн.
Еще одной важной особенностью плагинов, основанных на событиях, является подключаемая конструкция, поэтому добавление или удаление плагина не влияет на выполнение основного процесса.
Например, браузер Chrome поддерживает использование плагинов на основе событий для расширения своих функций, не влияя на выполнение исходных функций браузера.
Основные проблемы с плагинами на основе событий включают в себя:
Хотя плагины на основе событий обладают большой гибкостью в регистрации и исполнении плагинов, соответствующая архитектура будет более сложной, чем у конвейерных и луковых плагинов, что упрощает создание неизвестных проблем.
Система подключаемых модулей на основе событий может полностью охватывать функции системы подключаемых модулей конвейерного типа (с использованием режима последовательных событий для достижения эффекта конвейера), но если требования к типу конвейера ясны, рекомендуется используйте подключаемую систему конвейерного типа, потому что подключаемая система конвейерного типа больше подходит для простоты.
3.3.2 Применение плагинов на основе событий
Плагины, основанные на событиях, широко используются во фронтенд-сфере, такие как инструмент построения Webpack и известный редактор кода VS Code. Здесь мы используем VS Code в качестве примера для описания принципа работы основанного на событиях. плагины.
Здесь мы в основном изучаем процесс работы системы плагинов на стороне клиента, который аналогичен на веб-стороне.
Общий процесс работы выглядит следующим образом:
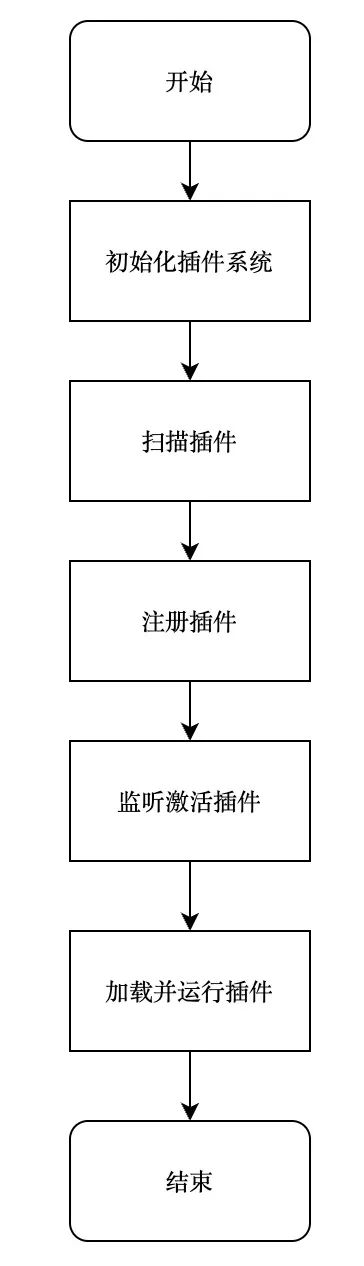
▶︎ Инициализировать систему плагинов
/**
vscode/src/vs/workbench/services/extensions/electron-sandbox/electronExtensionService.ts
*/
export abstract class ElectronExtensionService extends AbstractExtensionService implements IExtensionService {
(
@ILifecycleService lifecycleService: ILifecycleService,
) {
// Инициализировать систему плагинов Служить lifecycleService.when(LifecyclePhase.Ready).then(() => {
// reschedule to ensure this runs after restoring viewlets, panels, and editors
runWhenIdle(() => {
this._initialize();
}, 50 /*max delay*/);
});
}
}При инициализации службы клиентского плагина, после настройки всех служб, жизненный цикл перейдет на стадию Готово, после чего будет инициализирована служба.
▶︎ Плагин сканирования
При инициализации системы плагинов установленные плагины сканируются с помощью модуля CachedExtensionScanner, в основном для анализа следующей информации:
Имя плагина; версия плагина; файл записи; конфигурация, относящаяся к основному процессу плагина: «activationEvents», привязка событий активации, при срабатывании инструкции произойдет событие. активироваться; «команды», инструкция регистрации; «проводник/контекст», команда установки меню; «команда палитры», команда установки панели команд. |
|---|
- плагинизимя;
- плагиниз версии;
- входной файл;
- Конфигурация, связанная с основным процессом плагина:
- “activationEvents”,Событие активации привязки,когда команда срабатывает,событие будет активировано;
- «команды», инструкции по регистрации;
- «проводник/контекст», команда установки меню;
- «commandPalette», установите команду палитры команд.
{
"name": "ts2plantuml",
"version": "1.0.4",
"description": "",
"main": "./out/extension.js",
"activationEvents": [
"onCommand:ts2plantuml.explorer.preview"
],
"contributes": {
"commands": [
{
"command": "ts2plantuml.explorer.preview",
"title": "Preview Class Diagram",
"category": "TS2PLANTUML"
}
],
"menus": {
"explorer/context": [
{
"command": "ts2plantuml.explorer.preview",
"when": "resourceLangId == typescript"
}
],
"commandPalette": [
{
"command": "ts2plantuml.explorer.preview",
"when": "resourceLangId == typescript"
}
]
}
}▶︎ Зарегистрировать плагин
Согласно сканированной при обращении конфигурации, плагин регистрируется через модуль ExtensionDescriptionRegistry. Сначала происходит регистрация инструкций через поле команд, и объявляются события, активирующие плагин, а также инструкции, которые могут. запускаться каждым путем операции.
▶︎ Слушайте события активации
проходить Слушайте события активации,активировать плагин,нравитьсяобращатьсяиз Настройка,когда ts2plantuml.explorer.preview При срабатывании команды активируется соответствующий плагин.
// vscode/src/vs/workbench/api/common/extHostExtensionService.ts
export abstract class AbstractExtHostExtensionService extends Disposable implements ExtHostExtensionServiceShape {
private _startExtensionHost(): Promise<void> {
if (this._started) {
throw new Error(`Extension host is already started!`);
}
this._started = true;
return this._readyToStartExtensionHost.wait()
.then(() => this._readyToRunExtensions.open())
// Слушайте события активации
.then(() => this._handleEagerExtensions())
.then(() => {
// активацияплагин this._eagerExtensionsActivated.open();
this._logService.info(`Eager extensions activated`);
});
}
}проходитькурокизактивациясобытие,активацияплагин,При этом активация изсобытия будет сделана в кэше.,Предотвратить повторное выполнение,Вот Слушайте события активировать внутри из логики.
// vscode/src/vs/workbench/api/common/extHostExtensionActivator.ts
export class ExtensionsActivator implements IDisposable {
public async activateByEvent(activationEvent: string, startup: boolean): Promise<void> {
if (this._alreadyActivatedEvents[activationEvent]) {
return;
}
const activateExtensions = this._registry.getExtensionDescriptionsForActivationEvent(activationEvent);
await this._activateExtensions(activateExtensions.map(e => ({
id: e.identifier,
reason: { startup, extensionId: e.identifier, activationEvent }
})));
this._alreadyActivatedEvents[activationEvent] = true;
}
}▶︎ Загрузите плагин и выполните
Наконец, плагин загружается через модуль AbstractExtHostExtensionService. При загрузке плагина перехватывается запрос VS Code, чтобы обеспечить безопасную среду выполнения. Наконец, выполняется функция активации, предоставляемая входом плагина. активируйте плагин.
04
Отличные практики разработки плагинов VS Code
В предыдущей статье VS Code использовался в качестве примера для представления принципа работы плагинов, основанных на событиях. На самом деле, еще многое предстоит узнать о конструкции системы плагинов VS Code, например, соображениях безопасности. такие как развязка кода и соображения удобства сопровождения, например, соображения о том, как писать элегантный код и т. д.
Внедрить систему плагинов на основе событий не сложно. Но отличная реализация требует более тщательного проектирования во всех упомянутых выше аспектах, чем грубая реализация. Давайте далее изучим дизайн VS Code с двух сторон.
4.1 Изоляция с помощью песочницы
Плагины обычно разрабатываются сторонними разработчиками, и качество проектов варьируется. Есть плагины со стабильной производительностью, безопасностью и надежностью, а есть плагины, которые просто хорошо работают и скрывают множество ошибок.
После внедрения в основную программу плагина с угрозами безопасности, если он не защищен, он может выйти из строя вместе с основной программой.
Поскольку VS Code имеет более 30 000 плагинов, его архитектура определенно не позволяет реализовать описанную выше ситуацию, иначе репутация VS Code рухнет. Фактически, мы почти никогда не видим сбоя VS Code в нашей повседневной разработке.
Так как же VS Code обеспечивает изоляцию плагинов? Ответ: через изоляцию среды выполнения.
Первым шагом при запуске плагина в VS Code является создание нового Webworker для запуска логики плагина, чтобы логика плагина не могла напрямую влиять на логику основной программы. VS Code создает новый Webworker в качестве среды выполнения подключаемого модуля с помощью метода start в vs/workbench/services/extensions/browser/webWorkerExtensionHostStarter.ts.
const url = getWorkerBootstrapUrl(require.toUrl('../worker/extensionHostWorkerMain.js'), 'WorkerExtensionHost');
const worker = new Worker(url, { name: 'WorkerExtensionHost' });Тогда основная программа и плагин полностью изолированы, как они могут взаимодействовать друг с другом? Ответ: отправить сообщением.
После инициализации плагина он инициирует канал сообщений с основной программой, как показано в следующем коде:
start(){
.....
const protocol: IMessagePassingProtocol = {
onMessage: emitter.event,
send: vsbuf => {
const data = vsbuf.buffer.buffer.slice(vsbuf.buffer.byteOffset, vsbuf.buffer.byteOffset + vsbuf.buffer.byteLength);
worker.postMessage(data, [data]);
}
}
return protocol;
}VS Code определяет стандартную структуру протокола связи: IMessagePassingProtocol.
Поддерживайте канал сообщений через onMessage и postMessage Webworker для реализации
Интерфейс IMessagePassingProtocol определяет метод send и метод onMessage соответственно для отправки сообщений работникам и получения сообщений от работников. Как показано в следующем коде
export interface IMessagePassingProtocol {
send(buffer: VSBuffer): void;
onMessage: Event;
}IMessagePassingProtocol дополнительно инкапсулирует и создает канал RPCProtocol. Вызовы модулей могут осуществляться между основным процессом и рабочими процессами через RPCProtocol.
4.2 Связь через прокси
Теперь, когда проблема изоляции плагинов решена, позвольте мне рассмотреть механизм связи системы плагинов. Как общая система плагинов реализует связь между плагином и основной программой?
Обычно мы определяем это следующим образом на основе событий:
Получение ответных событий:
eventSystem.on('xxxсобытие', () => {
// логика обработки событий
})Отправить событие:
eventSystem.send('xxxсобытие', Параметр 1, Параметр 2 ...)Хотя это работает, на самом деле это очень неэлегантно и неинтуитивно. VS Code умело использует функцию прокси JS для этого сценария.
Например, когда основная программа хочет вызвать метод плагина, она делает следующее:
extensionProxy.$doSomeStuff(arg1, arg2);Очень просто, очень элегантно и интуитивно понятно. Межпроцессный вызов реализуется не иначе, чем локальный вызов, и вообще не выглядит отправкой события. Это все из-за RPCProtocol.
Принцип реализации RPCProtocol заключается в использовании Proxy для преобразования вызовов методов в удаленную отправку сообщений. Как показано в следующем коде:
export class RPCProtocol extends Disposable implements IRPCProtocol {
((protocol: IMessagePassingProtocol, ...){
super();
this._protocol = protocol;
}
....
//Создаем прокси для преобразования вызовов методов локального объекта в удаленный вызов
private _createProxy(rpcId: number): T {
let handler = {
get: (target: any, name: PropertyKey) => {
//нравиться Если имя метода начинается с к$, оно конвертируется в удаленный вызов
if (typeof name === 'string' && !target[name] && name.charCodeAt(0) === CharCode.DollarSign) {
target[name] = (...myArgs: any[]) => {
//Отправляем удаленное сообщение
return this._remoteCall(rpcId, name, myArgs);
};
}
return target[name];
}
};
return new Proxy(Object.create(null), handler);
}
//Собираем удаленные сообщения, выдаваемые протоколом IMessagePassingProtocol
private _remoteCall(rpcId: number, methodName: string, args: any[]): Promise {
const msg = MessageIO.serializeRequest(..., rpcId, methodName, ....);
this._protocol.send(msg);
}
}Далее автор расскажет о наших практиках применения в конкретных проектах на базе проекта облачных путешествий H5.
05
Практика и совершенствование системы плагинов для онлайн-игр H5
Что касается архитектурного проектирования, проект H5 Cloud Game не только использует DDD для проектирования многоуровневой и абстрактной архитектуры, но также активно использует идеи архитектуры микроядра в модуле-оболочке SDK.
Текущая микроядерная конструкция проекта «Запретный город» достигла определенного масштаба и имеет преимущества, которым стоит поучиться. В то же время есть и области, которые нуждаются в улучшении. Благодаря этому углубленному анализу теории микроядерной архитектуры и дизайнерских идей микроядерной архитектуры известных крупномасштабных проектов мы подумали о точках объединения, которые можно использовать для улучшения микроядерной архитектуры Forgame в будущем.
5.1 Текущая архитектура системы плагинов Forgame
Во-первых, давайте рассмотрим текущую микроядерную архитектуру Forgame. Архитектура микроядра Forgame в основном используется в системе-оболочке SDK. Основная функция оболочки SDK — инкапсулировать возможности Forgame SDK с использованием управляемой событиями двусторонней архитектуры микроядра подключаемого модуля. Есть два основных аспекта:
Упаковка:Воля Путешествие вокруг SDK Он инкапсулирует сложность вызова и обеспечивает простой и согласованный интерфейс с внешним миром, то есть микроядро.
Расширения:для Путешествие вокруг SDK Добавить возможности расширения, т. е. систему плагинов, поддержку на основе SDK Базовые возможности дополнительно расширены, например: SDK Управление статусом, адаптация к среде, отчетность, подсказки об ошибках, полноэкранный режим и т. д.
На данный момент система плагинов обертки SDK начала оформляться следующим образом:
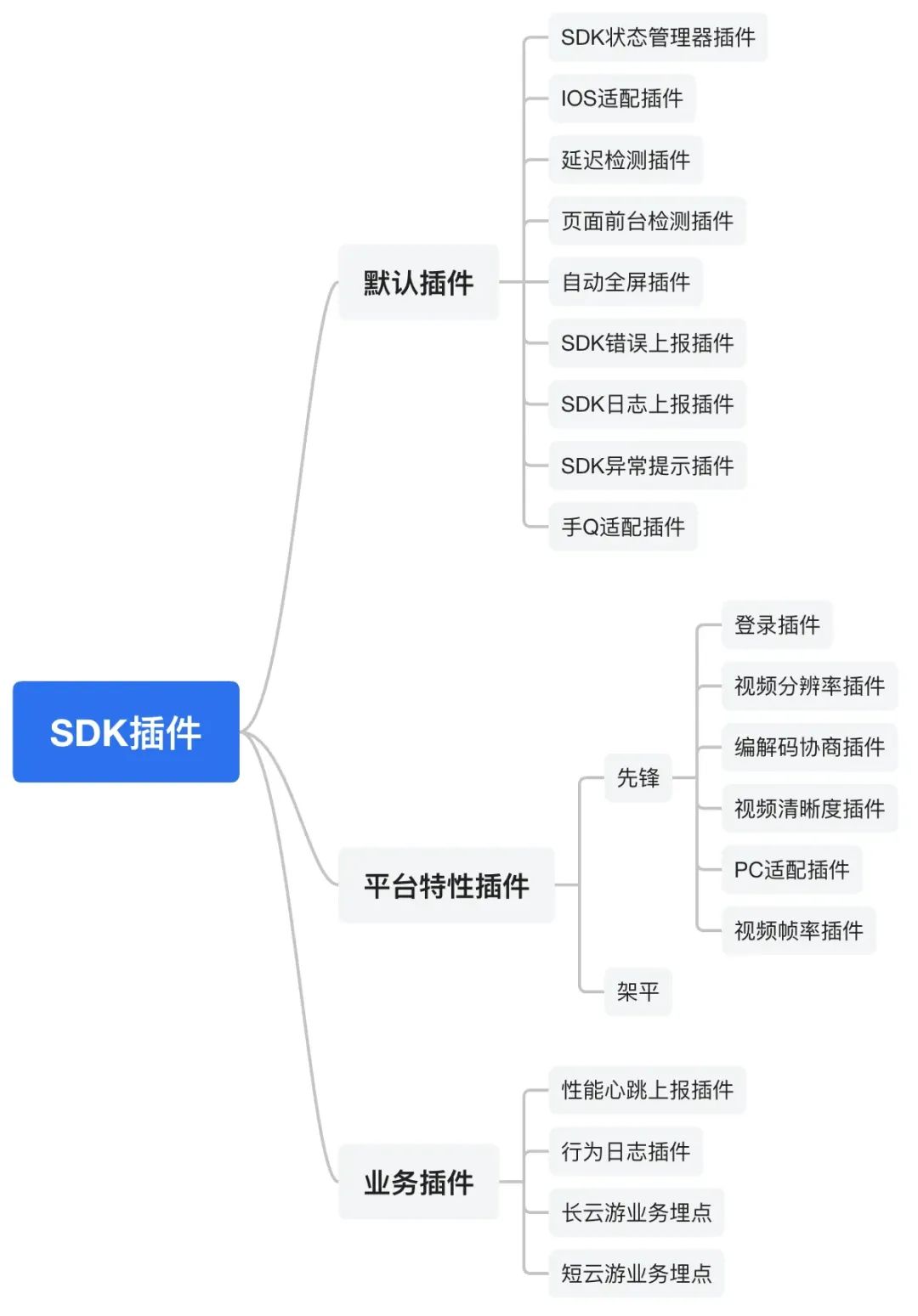
Схема архитектуры оболочки Forgame SDK: (Pioneer и Jiuping представляют две платформы реализации Forgame)
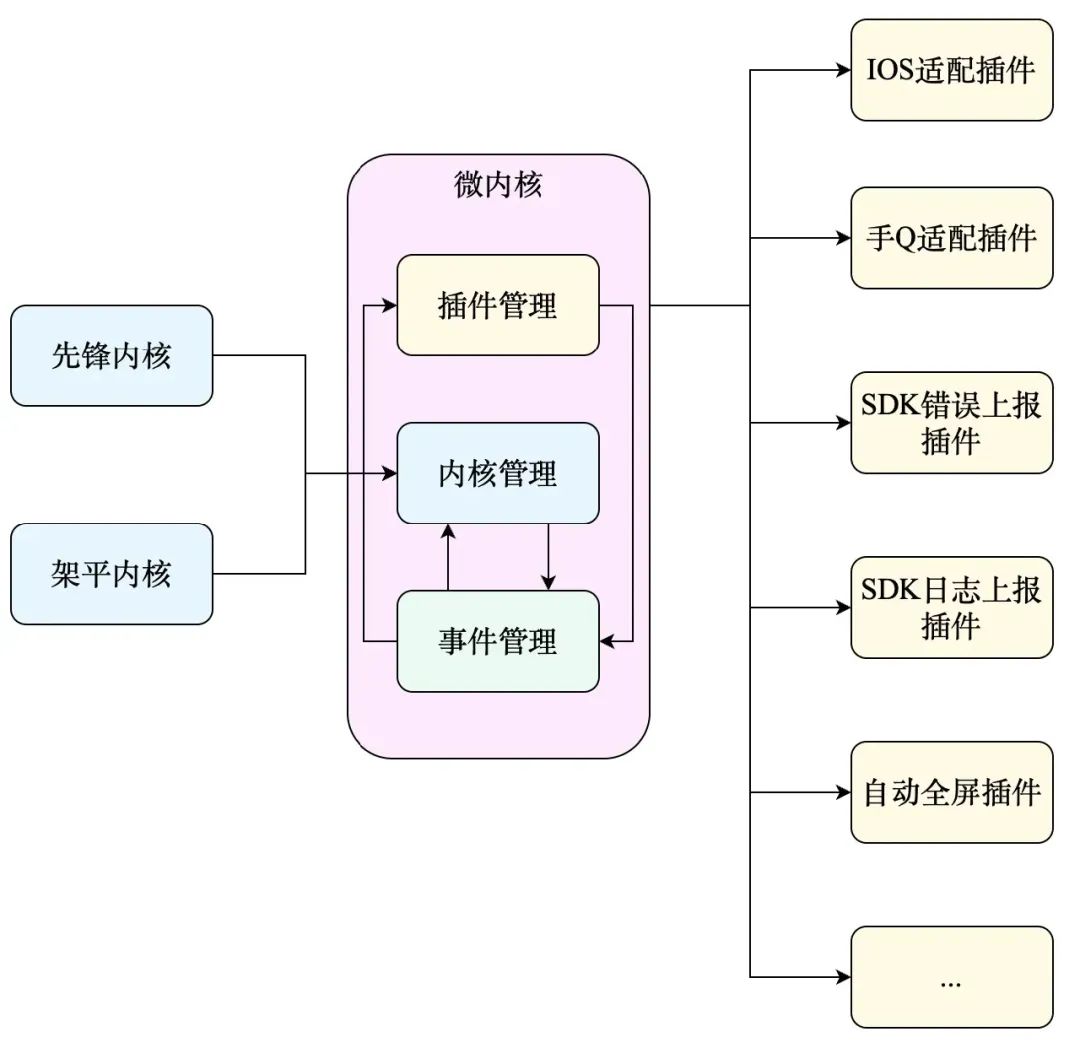
Микроядро разделено на три функциональных модуля:
5.1.1 Многоядерный модуль управления
Для поддержки нескольких SDK облачных игр оболочка SDK использует многоядерную архитектуру.
С помощью модуля управления ядром можно сгладить различия в вызовах внешнего интерфейса ядра и передаче событий.
Эта архитектура значительно упрощает сложность бизнес-проектирования верхнего уровня. Бизнес верхнего уровня работает на абстрактном ядре и не знает о фактической реализации базового ядра.
При этом такая архитектура не только увеличивает возможность последующего переключения на другие ядра, но и снижает стоимость переключения.
Следующий BaseSDKAdapter реализует уровень абстракции ядра. Новым ядрам необходимо только наследовать и выборочно реализовывать различные интерфейсы для доступа к проекту облачной игры, а степень связи с бизнесом верхнего уровня равна 0.
export class BaseSDKAdapter {
...
/** Получить статус SDK */
public getSDKState() {
return this.sdkState;
}
/** Предварительная загрузка SDK */
public async preload() {
// Реализация наследования подкласса
}
/** Инициализация конфигурации адаптера */
public async init(uiConfig: UIInitConfig, sdkConfig: InitConfig): Promise<void> {
}
...
/** Начать играть в Путешествие о потоковом видео */
public async play(): Promise<void> {
// Реализация наследования подкласса
}
/** пауза Путешествие о потоковом видео */
public pause(): void {
// Реализация наследования подкласса
}
/** Установить звуковые эффекты */
public setVolume(_volume: number) {
// Реализация наследования подкласса
}
/** Установить скорость передачи данных */
public setBitrate(_minBitrate: number, _maxBitrate: number) {
// Реализация наследования подкласса
}
...
}Следующий код взят из реализации адаптера ядра Pioneer SDK:
export class GameMatrixSDKAdapter extends BaseSDKAdapter {
private cloudGame: CloudGame | null = null;
/** предварительная загрузка */
public async preload() {
const ret = await sdkPreloaderEntity.preload();
this.afterPreload();
return ret;
}
...
/** возвращаться SDK сущность */
public getRaw(): any {
return this.cloudGame;
}
/** Получить текущее устройство id нужно быть внутри device ready можно получить позже */
public getDeviceId() {
return this.cloudGame?.getDeviceId();
}
/** Получать Путешествие вокругизvideoузел */
public getCloudGameVideo() {
return this.cloudGame?.videoManager.video;
}
...
}Многоядерная архитектура, по сути, представляет собой механизм подключаемого модуля. Путем определения абстрактного уровня интерфейса определяются спецификации подключаемого модуля. Благодаря реализации этой спецификации к текущему проекту можно подключить различные ядра. Создание экземпляра ядра здесь будет выполнено SDKManager для создания экземпляра указанного ядра на основе текущей конфигурации, выпущенной Forgame.
5.1.2 Управление событиями с поддержкой пересылки событий
Архитектура микроядра оболочки SDK реализует связь между ядром и плагинами посредством событий. Однако, поскольку источник событий ядра не единый, а между схожими событиями существуют различия, в архитектуре принят механизм пересылки событий для унификации протокола отправки событий.
В то же время, поскольку источники событий делятся на два типа: один — события SDK, а другой — события расширения, режим стратегии событий разработан в соответствии с разными источниками событий, чтобы скрыть различия в событиях.
Благодаря вышеуказанному решению плагин не знает различий и источников событий, что делает реализацию плагина более простой и удобной в обслуживании.
На рисунке ниже показана архитектура пересылки событий оболочки SDK. События ядра Pioneer, события ядра платформы и события расширения YYB SDK объединены в средстве пересылки событий для адаптации. Красная стрелка представляет событие отправки, а синяя стрелка представляет событие получения. .
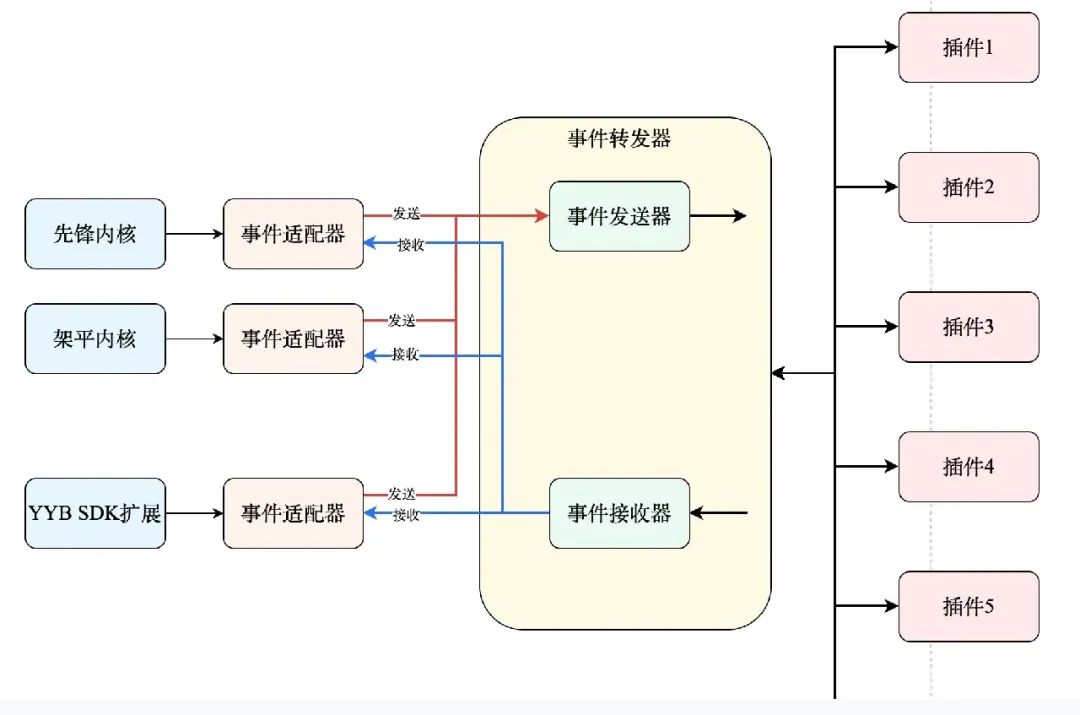
Ниже приводится сводка кода базового класса пересылки событий:
класс BaseEventTransformer {
/** событие: событие */
публичное событие (eventType: SDKWrapperEvent, callback: any) {
}
/** регистрация событий (только один раз) */
public eventOnce(eventType: SDKWrapperEvent,обратный вызов: любой) {
}
/** триггер события */
публичный выпуск (eventType: SDKWrapperEvent,data?: any) {
}
/** событие Удалять */
public removeEvent(eventType: SDKWrapperEvent, callback: EventCallback) {
}
}Вот краткое описание кода адаптера событий, который выравнивает ядро:
class JiapingEventAdapter extends BaseEventTransformer {
}Благодаря такой архитектуре при получении и отправке событий внутри плагина нет необходимости обращать внимание на источники и различия событий, а нужно иметь дело только с набором систем событий.
5.1.3 Поддержка мультипарадигмального управления плагинами (устарело)
Хотя эта способность устарела, о ней все же стоит упомянуть.
Наши парадигмы программирования включают функциональное программирование и объектно-ориентированное программирование. Каждое программирование имеет свои применимые сценарии. Чтобы упростить разработку простых плагинов вниз и поддержать разработку сложных плагинов вверх, оболочка Forgame SDK предлагает метод написания плагинов, который поддерживает несколько парадигм.
Простые плагины могут быть реализованы с помощью функционального программирования, а сложные плагины могут быть реализованы с помощью объектно-ориентированных методов.
Этот подход имеет преимущества и недостатки. Преимущество заключается в том, что плагины можно разрабатывать с использованием парадигм по требованию, что позволяет сократить количество ненужных избыточных реализаций. Простые плагины могут быть дополнены одной функцией, а сложные плагины могут быть реализованы с помощью объектно-ориентированного подхода. наследование.
Но плохо то, что способ написания плагина требует поддержки двух наборов механизмов, а стиль не унифицирован.
Основываясь на соображениях проектирования единой парадигмы и стиля разработки, это управление плагинами, поддерживающее несколько парадигм, было отменено в процессе реконструкции, а плагины были написаны в унифицированном объектно-ориентированном виде.
Давайте рассмотрим, как реализованы функциональные плагины и объектно-ориентированные плагины многопарадигмального управления плагинами и как они загружаются системой плагинов.
Функциональный плагин:
export function MySimplePlugin(config: PluginConfig) {
// Инициализировать плагин
// Зарегистрируйтесь, чтобы слушать событие
}Объектно-ориентированные плагины:
export function MyComplexPlugin extends BasePlugin {
public register(config: PluginConfig) {
}
private init() {
}
...
}Загрузка плагинов и как единообразно управлять плагинами разных парадигм:
class PluginManager {
...
loadPlugin(Plugin: FuntionalPlugin | typeof BasePlugin) {
let PluginClass: BasePlugin | null = null;
// суждение Plugin Унаследовано ли от BasePlugin
if (Plugin.prototype instanceof BasePlugin) {
PluginClass = Plugin;
} else {
// нравитьсяфрукты Plugin Это функциональный стиль, использующий анонимные классы для адаптации плагина функционального стиля к плагину объектного стиля.
PluginClass = class extends BasePlugin {
public register(config: PluginConfig) {
Plugin(config);
}
}
}
// Выполните регистрацию и инициализацию плагина.
}
...
}5.2 Идеи по улучшению системы плагинов Forgame
Благодаря обзору архитектурного проекта системы плагинов Forgame весь наш проект является относительно полным: от настройки плагина, управления жизненным циклом плагина, дизайна интерфейса плагина и механизма связи между плагинами и системой. ядро, все было разумно спроектировано.
Однако благодаря нашему углубленному изучению архитектуры микроядра и изучению существующих превосходных проектов архитектуры программного обеспечения мы все же обнаружили, что существует множество способов улучшить удобство сопровождения проекта и элегантность кода.
5.2.1 Управление категориями плагинов
В настоящее время в плагинах Forgame отсутствует управление категориями плагинов. Все плагины обрабатываются одинаково, им предоставляются одинаковые разрешения и одинаковый интерфейс. Очевидно, что такая конструкция отвечает текущим потребностям, но если рассматривать последующее расширение, то она недостаточно гибкая и разумная.
Это может быть немного абстрактно. Каковы категории плагинов?
Например, VS Code имеет более 30 000 плагинов. Эти плагины не могут выполнять одно и то же. Некоторые плагины используются для изменения темы VS Code, некоторые используются для взаимодействия с внешними инструментами, а некоторые используются для добавления поддержки нового языка.
Вы можете сказать: почему я не могу создать одну и ту же модель, способную выполнять все эти задачи? Ответ — да, но такая модель будет очень раздутой, очень избыточной и совершенно не соответствующей принципу открытия и закрытия. Например, плагину на основе темы не нужно обращать внимание на интерфейсы и события, связанные с поддержкой синтаксиса языка программирования. Плагин, взаимодействующий с внешними инструментами, вряд ли будет обращать внимание на стиль редактора.
Таким образом, различные варианты поведения и проблемы делят плагины на категории.
Различные категории плагинов имеют разные методы работы, разные разрешения и разные жизненные циклы.
Таким образом, Forgame может обратиться к классификации плагинов VS Code и дополнительно добавить классификации плагинов, чтобы уточнить механизм работы плагина и разрешения, улучшить удобство сопровождения кода и обеспечить большее соответствие принципу открытия и закрытия.
Вот идея по улучшению категории плагинов.
Во-первых, определение плагина должно включать информацию о типе. Например, три основные категории существующих плагинов в Forgame определяют соответственно три абстрактных базовых класса плагинов. один за другим:
SDKExtendPlugin: отвечает за настройку возможностей Forgame SDK самого низкого уровня. Он должен взаимодействовать с ядром SDK и знать детали реализации ядра. Поэтому ему предоставляются самые высокие права доступа и все разрешения на чтение и запись. внутренние события SDK. Подобные плагины могут быть плагинами, обеспечивающими адаптацию декодирования H265 для SDK и т. д. PlatformAdaptPlugin: этот тип плагина обычно должен обращать внимание только на базовые события, отправляемые SDK, такие как события связи WebRTC в реальном времени, поэтому его можно использовать для отображения состояния связи или выполнения анализа данных, составления отчетов и т. д. . Плагину этого типа требуются полные разрешения на получение событий SDK, но ему не разрешено изменять внутреннее состояние SDK, поэтому разрешения на отправку событий SDK отключены. К аналогичным плагинам относятся плагин статистики статуса WebRTC и т. д. BusinessPlugin: этот тип плагина в основном полагается на временные события SDK для завершения бизнес-логики. Он не обращает внимания на детали базовой логики SDK, поэтому имеет возможность подписаться только на некоторые расширенные функции. события SDK. Имеет самые низкие разрешения среди трех типов плагинов. Плагин с минимальной зависимостью от SDK. Подобные плагины включают плагин интерфейса загрузки Yungyou и т. д. |
|---|
// для продления SDK из Основные способности, обладать иметь SDK Внутренние события: разрешения на чтение и запись, поддержка вызова всех функций ядра.
export class SDKExtendPlugin extends BasePlugin {
}
// Плагин кроссплатформенной адаптации, вы можете подписаться SDK Так иметьсобытие, не может действовать SDK, поддерживает вызов некоторых интерфейсов ядра, связанных с операциями платформы.
export class PlatformAdaptPlugin extends BasePlugin {
}
// Плагин для бизнеса, можно только подписаться SDK из Передача статусасобытие, невозможно работать SDK, поддерживает только небольшое количество интерфейсов вызовов ядра.
export class BusinessPlugin extends BasePlugin {
}Загрузка и управление каждым типом плагинов разделены, жизненный цикл управляется отдельно, а на внедренные объекты ядра распространяются ограничения разрешений.
class PluginManager {
private sdkExtendPlugins: SDKExtendPlugin[] = [];
private platformAdaptPlugins: PlatformAdaptPlugin[] = [];
private businessPlugins: BusinessPlugin[] = [];
...
loadPlugin(Plugin: typeof BasePlugin) {
if (isExtendClass(Plugin, SDKExtendPlugin) {
// руководить sdk extend plugin из Регистрацияи Инициализация
}
if (isExtendClass(Plugin, PlatformAdaptPlugin) {
// руководить platform adapt plugin из Регистрацияи Инициализация
}
if (isExtendClass(Plugin, BusinessPlugin) {
// руководить business plugin из Регистрацияи Инициализация
}
}
...
}5.2.2 Принципы открытия и закрытия ядра и плагинов
Упомянутое выше управление категориями плагинов говорит об управлении разрешениями интерфейса ядра. Тогда в этом разделе будет описано, почему необходимо осуществлять управление разрешениями на интерфейсе ядра и как реализовать управление разрешениями.
Во-первых, зачем нам нужно управлять разрешениями в интерфейсе ядра? Давайте пока не будем спешить с ответом.
Давайте сначала посмотрим, как гипотетический плагин инициализирует и вызывает возможности ядра:
class Plugin {
// Ссылка на ядро
private core: Core;
/**
* @param core объект ядра
* @param config информация о конфигурации плагина
**/
init(core: Core, config: Config) {
// Сохранить ядро из ссылки
this.core = core
}
// определенный метод подключения
doSomething() {
// Как уничтожить ядро
core.destroy();
}
}В приведенном выше примере, если мы не ограничиваем ядро, мы можем напрямую уничтожить ядро плагина. Это определенно неразумная конструкция.
В частности, для такого программного обеспечения, как VS Code, все его плагины созданы сообществом. Если нет ограничений на разрешения интерфейса, репутация VS Code больше не должна существовать.
На самом деле, VS Code проделал большую работу для обеспечения стабильности плагина, например управление разрешениями, запуск песочницы и т. д.
Учитывая, что Forgame — веб-проект, и плагины поддерживаются внутри проекта. Нам пока не нужно использовать работающую песочницу, но управление разрешениями ядра по-прежнему необходимо.
Почему? Посредством управления разрешениями ядра мы можем предоставить интерфейсу ядра разные разрешения для каждого типа плагинов, гарантируя, что при разработке плагинов мы не напишем по ошибке код, превышающий обязанности плагина. Когда мы пишем и сталкиваемся с кодом, превышающим наши обязанности, мы думаем о том, разумно ли классифицированы наши плагины и являются ли их обязанности едиными, тем самым ограничивая нас в написании более удобного в сопровождении кода.
Итак, как улучшить приведенный выше пример, чтобы он поддерживал ограничения интерфейса ядра?
class Plugin {
// Ссылка на ядро
private core: Core;
/**
* @param core объект ядра
* @param config информация о конфигурации плагина
**/
init(core: Core, config: Config) {
// Сохранить ядро из ссылки
this.core = core
}
// определенный метод подключения
doSomething() {
// Как уничтожить ядро
core.destroy();
}
}Как ядро получает различные подмножества разрешений? Конечно, мы можем просто и грубо использовать методы для прозрачной инкапсуляции подмножества разрешений. Но что касается реализации VS Code, мы можем использовать прокси для ее реализации. Ниже приведен псевдокод.
export function getCore<PluginType>(): PluginType {
// создавать proxy
const coreProxy = new Proxy(Object.create(null), {
get(target, callee) {
// читать sdk extend из конфигурации Permission, нравиться прозрачная передача вызова, если вызов разрешен
if (isValidFor<PluginType>(callee) {
callee.apply(core, arguments);
} else {
throw new Ошибка («незаконный вызов»)
}
}
});
return coreProxy as PluginType
}06
Подвести итог
Благодаря углубленному изучению архитектуры микроядра в сочетании с анализом превосходных реализаций программного обеспечения мы получили общее представление о преимуществах высокой масштабируемости архитектуры микроядра и превосходных практиках использования различных микроядер. В то же время мы также черпали вдохновение из плана архитектурной оптимизации системы плагинов для облачных игр H5 и дополнительно улучшили текущую архитектуру системы плагинов. В будущем мы выделим систему плагинов проекта «Запретный город» в набор общих библиотек классов системы плагинов и применим ее к другим проектам.
Спасибо за прочтение статьи, написанной MoonWebTeam. Если эта статья вдохновила вас, поделитесь ею.
-End-
Автор оригинала|Лай Вэньхуэй

Что вы думаете о микроядерной архитектуре? Как начать работу с микроядерной архитектурой? Добро пожаловать, чтобы поделиться. Мы выберем наиболее содержательный комментарий и подарим держатель для мобильного телефона Tencent Cloud Developer (см. рисунок ниже). Розыгрыш лотереи состоится в 12:00 11 сентября.








Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
