Расшифруйте серию подсказок 35. Выполняется стандартизированная подсказка! Бумажный коллаж DSPy и примеры кода
Перенесемся в 24 года, и половина из них прошла. Давайте по-новому взглянем на самое хрупкое звено в приложениях с большими моделями: Подскажите. Какие новые решения есть у Engineering? В этой главе мы сначала рассмотрим популярную структуру DSPy. Сначала мы разберем несколько основных документов, связанных с DSPy, чтобы понять идеи и принципы проектирования, лежащие в основе этой структуры. Затем мы будем использовать вопросы FinEval с одним выбором в качестве задач. от простых инструкций, инструкций COT до инструкций по выборке нескольких кадров и оптимизации, приведите пример код и оценка эффекта.
Эссе на вертеле
DEMONSTRATE–SEARCH–PREDICT:Composing retrieval and language models for knowledge-intensive NLP DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines In-Context Learning for Extreme Multi-Label Classification Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs DSPy Assertions: Computational Constraints for Self-Refining Language Model Pipelines
Платформа подсказок DSPY уже некоторое время пользуется большой популярностью, и в рамках проекта также опубликовано множество статей, указанных выше. Каждая статья соответствует одному или нескольким модулям проекта. Давайте рассмотрим основные идеи приведенной выше статьи.
DEMONSTRATE–SEARCH–PREDICTдаDSPyПервая статья,Основная идея очень похожа на нынешнее программное обеспечение для управления процессами, такое как coze (ха-ха, в области больших моделей сейчас необычно много существительных),Этот рабочий процесс на самом деле связан с агентом,chain,pipeline,Значение бота тоже очень похоже). Суть заключается в фиксированном процессе,Модульный процесс рассуждения и процесс генерации инструкций (несколько шагов).
Несмотря на то, что для задачи RAG предложена структура DSP, мы оставляем в стороне процессы поиска и прогнозирования RAG. Суть статьи состоит в том, чтобы разделить задачу на несколько атомарных узлов. Каждый атомарный узел представляет собой неделимую функцию. соединены последовательно через общий поток управления. В то же время эта оптимизированная структура позволяет каждому узлу генерировать демонстрацию на основе обучающих данных и может использовать различную логику отзыва для динамического выбора нескольких кадров во время вывода для оптимизации эффекта каждого узла.
Ниже приведен пример рабочего процесса для задачи OpenQA. Весь процесс состоит из трех частей: создание демонстрации и выполнение поиска и рассуждения на основе примеров.

При создании примеров будут использоваться данные обучения для одного и того же процесса, а в качестве примеров будут использоваться результаты каждого шага текущего процесса. Здесь выбран пример из трех шагов с k = 3.

На основе вышеуказанного DSP,DSPy: Compiling Declarative Language Model Calls into Self-Improving PipelinesДальнейшая абстракция и реконструкция процесса,Структура быстрого создания и оптимизации на основе трех основных модулей.
- Signature: Наследует BaseModel pydantic и определяет парадигму задачи, например контекст, вопрос. -> Answer
- Module:похожийpytorchопределено для моделиcallable Функция определяет рабочий процесс задачи, например процесс RAG «получить-затем прочитать», описанный выше.
- Teleprompter: Компилятор, который оптимизирует процесс на основе индикаторов задач. Оптимизация здесь фокусируется на выборке нескольких шагов и динамическом выборе процесса. Выбор процесса здесь в основном является ансамблевым, а не прямым изменением рабочего процесса. В документе говорится, что он также предоставляет возможности тонкой настройки. Фактически, он также настраивается на основе демонстрации, созданной процессом в качестве образца.
Среди них Telepropmter предоставляет BootstrapFewShot, BootstrapFewShotWithRandomSearch,Ensembleждатьpromptоптимизатор。Основное внимание в этой статье уделяется выбору нескольких шагов и оптимизации в оперативном режиме.
Взяв в качестве примера BootstrapFewShotWithRandomSearch, Teleprompter сначала сгенерирует пакет демонстраций на основе обучающего набора, а затем на основе метрики указанной задачи выберет несколько снимков с лучшей производительностью в проверочном наборе для построения окончательного приглашения.
In-Context Learning for Extreme Multi-Label Classification其实да利用了DSPyрамка,Новый рабочий процесс был построен на задаче классификации с очень большими метками (≥10 000).,Это называется Infer-Retreve-Rank. То есть вы хотите, чтобы модель угадала N возможных меток классификации.,Эти метки затем вызываются.
Optimizing Instructions and Demonstrations for Multi-Stage Language Model ProgramsСосредоточьтесь на комплексных задачахpromptПровести общую оптимизацию,Кроме малозарядных,Также включает в себяОптимизация инструкций и условий миссии。Здесь есть две технические трудности.,Во-первых, диапазон поиска в пространстве подсказок чрезвычайно велик.,Другой вопрос – это вопрос присвоения показателей при общей оптимизации.
Для решения проблемы пространства быстрого поиска в статье используется APE, который представляет собой идею большой модели, анализирующей суть задачи и генерирующей инструкции задачи на основе выборок ввода-вывода. А при описании задачи, помимо необходимых обучающих образцов, также предоставляется множественная дополнительная информация о задаче, в том числе
- Следует ли использовать описание задачи из 2–3 предложений, созданное большой моделью.
- Использовать ли код процесса задачи
- Использовать ли команды, опробованные в истории
- Следует ли использовать разные стили команд (советы), например более креативные и лаконичные.
Код инструкции генерации модели следующий:
TIPS = {
"none": "",
"creative": "Don't be afraid to be creative when creating the new instruction!",
"simple": "Keep the instruction clear and concise.",
"description": "Make sure your instruction is very informative and descriptive.",
"high_stakes": "The instruction should include a high stakes scenario in which the LM must solve the task!",
"persona": 'Include a persona that is relevant to the task in the instruction (ie. "You are a ...")',
}
class GenerateSingleModuleInstruction(dspy.Signature):
(
"""Use the information below to learn about a task that we are trying to solve using calls to an LM, then generate a new instruction that will be used to prompt a Language Model to better solve the task."""
)
if use_dataset_summary:
dataset_description = dspy.InputField(
desc="A description of the dataset that we are using.",
prefix="DATASET SUMMARY:",
)
if program_aware:
program_code = dspy.InputField(
format=str,
desc="Language model program designed to solve a particular task.",
prefix="PROGRAM CODE:",
)
program_description = dspy.InputField(
desc="Summary of the task the program is designed to solve, and how it goes about solving it.",
prefix="PROGRAM DESCRIPTION:",
)
module = dspy.InputField(
desc="The module to create an instruction for.", prefix="MODULE:",
)
task_demos = dspy.InputField(
format=str,
desc="Example inputs/outputs of our module.",
prefix="TASK DEMO(S):",
)
if use_instruct_history:
previous_instructions = dspy.InputField(
format=str,
desc="Previous instructions we've attempted, along with their associated scores.",
prefix="PREVIOUS INSTRUCTIONS:",
)
basic_instruction = dspy.InputField(
format=str, desc="Basic instruction.", prefix="BASIC INSTRUCTION:",
)
if use_tip:
tip = dspy.InputField(
format=str,
desc="A suggestion for how to go about generating the new instruction.",
prefix="TIP:",
)
proposed_instruction = dspy.OutputField(
desc="Propose an instruction that will be used to prompt a Language Model to perform this task.",
prefix="PROPOSED INSTRUCTION:",
)На основе кандидатов инструкций, сгенерированных приведенной выше большой моделью, и множества примеров, сгенерированных BootstrapFewShot, следующим шагом будет выбор оптимальной инструкции на основе обучающего набора. В данном документе создаются несколько оптимизаторов, включая случайный поиск. Основная рекомендация в документе — MIPRO (оптимизатор предложений с несколькими подсказками), который использует общий алгоритм оптимизации гиперпараметров TPE, чтобы соответствовать положительному эффекту нескольких гиперпараметров в приведенных выше инструкциях в последнем подсказке. Влияние отрицательное: оптимальная инструкция в конечном итоге выбирается на основе показателей оценки на обучающем наборе. Следовательно, это выбор гиперпараметров для генерации инструкций (в том числе инструкций, генерируемых методом выборки), а не непосредственное итеративное обновление самих инструкций.
Фактически, здесь также можно использовать различные интерпретируемые модели алгоритмы. Основная трудность заключается в том, что во всей задаче имеется несколько узлов, и каждое приглашение узла имеет несколько гиперпараметров, которые влияют друг на друга и в конечном итоге влияют на завершение задачи. Однако мы можем получить только метку окончательного завершения задачи. не может получить выходную обратную связь промежуточных узлов. Сложность аналогична алгоритмам атрибуции, таким как деревья решений.
DSPy: Compiling Declarative Language Model Calls into Self-Improving PipelinesдаDSPyНовая подфункция-Условное суждение。Рассмотрим общиеpromptПо сути, он состоит из трех частей,Описание задачи,пример с несколькими выстрелами,Также есть требования к деталям выполнения задачи.,В двух предыдущих статьях дана оптимизация генерации соответственно. задача и схема выборочного скрининга с несколькими выстрелами,Тогда Assert — это решение по оптимизации требований.
В реальных задачах требования часто являются самой тривиальной частью. Например, в задаче переписывания запроса нам может потребоваться потребовать, чтобы сходство между переписанным запросом и исходным запросом не было слишком высоким, но основной предмет не может быть таким. быть потеряны, а сущность времени не может быть потеряна или переписана. Запрос не может быть слишком похожим. Он не может включать в себя ненужные детали и т. д.
В документе представлены два метода: жесткие требования (Утверждение) и мягкие предложения (Предложение), которые добавляются непосредственно в модуль задачи, написанный ранее. Таким образом, процесс обоснования задачи будет напрямую генерировать предложения на основе Утверждения и Предложения, и есть такие методы. два способа их использования. Первый заключается в том, что после того, как модель нажимает «утверждение» и «предложение» во время вывода, соответствующие предложения будут непосредственно добавлены в приглашение для самоуточнения модели. Другой заключается в том, что утверждение может напрямую прервать приведение модели и повторить попытку.
Это все, что касается статьи. Давайте возьмем финансовую задачу с множественным выбором в качестве примера, чтобы попытаться оптимизировать подсказку.
пример кода
https://github.com/stanfordnlp/dspy https://dspy-docs.vercel.app/
Затем мы используем вопрос FinEval с одним выбором в качестве задачи и пытаемся использовать DSPy для генерации подсказок, оптимизации подсказок и оценки эффекта. Учитывая стоимость, здесь использовано всего 100 образцов.
Основная подсказка
Сначала определите модель LLM, здесь я использую Azure GPT4.
import dspy
model = dspy.AzureOpenAI(**kwargs)
dspy.settings.configure(lm=model)Использование DSPy для определения приглашения означает определение модели Pydantic, включая описание задачи, описание ввода и описание вывода, называемую сигнатурой, следующим образом.
class SingleChoiceQA(dspy.Signature):
"""Вопрос с одним выбором, учитывая вопрос и четыре варианта ABCD, выведите правильный вариант"""
question = dspy.InputField(desc='Вопросы и параметры')
answer = dspy.OutputField(desc="Правильный вариант для одного из [ABCD]")Затем мы импортируем и конвертируем данные в образец формата, указанный DSPy. Аналогично, пока указаны входные данные, example будет автоматически обрабатывать оставшиеся поля как выходные данные.
def format_example(line):
input = line['question']
for choice in ['A', 'B', 'C', 'D']:
input += f'\n{choice}. {line[f"{choice}"]}'
output = line["answer"]
example = dspy.Example(question=input, answer=output).with_inputs('question')
return example
Следующим шагом является определение задачи. DSPy называет ее «Модуль», что означает определение потока задач. Например, RAG — это получение-чтение, многошаговый контроль качества — это несколько раундов контроля качества, и, поскольку это простой вопрос с одним выбором, Определение модуля очень простое.
class SQA(dspy.Module):
def __init__(self):
self.generate_answer = dspy.Predict(SingleChoiceQA)
def forward(self, question):
return self.generate_answer(question=question)
singlechoice_qa = SQA()
pred = singlechoice_qa(question=examples[0]['question'])
print('Ниже приведено приглашение, сгенерированное DSPy')
print(model.inspect_history(n=1))В то же время мы можем использовать Inspect_history, чтобы легко просмотреть конкретное приглашение, сгенерированное DSPy, и эффект вывода соответствующей модели, как показано ниже.

Оптимизация и оценка COT
Основываясь на приведенном выше базовом определении задачи, следующий шаг — посмотреть, сможем ли мы оптимизировать эффект задачи, просто используя COT. В определение COT добавлены следующие модули: DSPy предоставляет подсказки для общего мышления, такие как ReACT и POT.
class SQACOT(dspy.Module):
def __init__(self):
self.generate_answer = dspy.ChainOfThought(SingleChoiceQA)
def forward(self, question):
return self.generate_answer(question=question)
singlechoice_qa_cot = SQACOT()Эффекты подсказки и обоснования после добавления COT следующие:
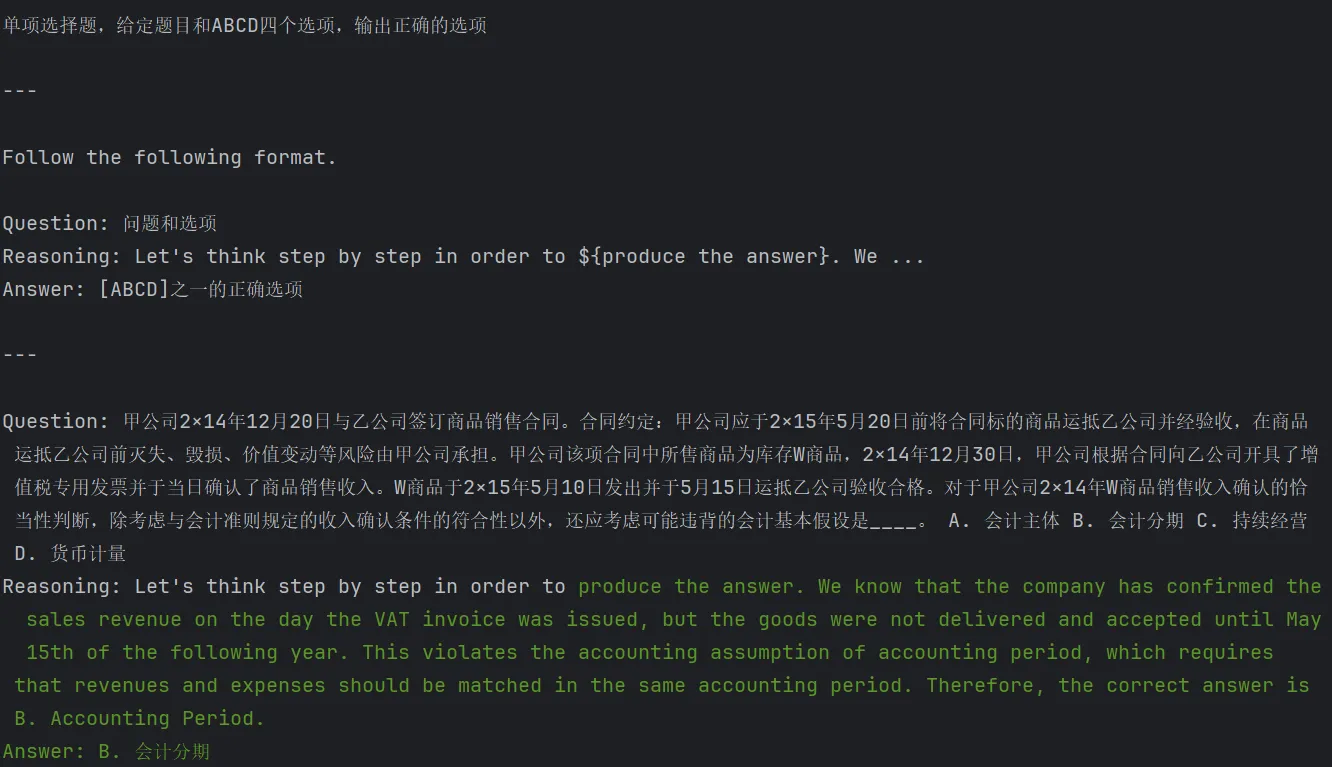
Далее мы определяем показатели оценки задачи, а затем используем Основную подсказку и COT Эффект от Prompt разный для пакетной оценки.
DSPy предоставляет некоторые индикаторы, такие как точное совпадение и совпадение проходов, но на самом деле удобнее всего определить свои собственные индикаторы. Просто совместите его с входными и выходными данными DSPy Metric. Здесь мы просто извлекаем ABCD и стандартные ответы в ответе, чтобы рассчитать точность. Код оценки выглядит следующим образом: DSPy поддерживает возврат конкретных результатов каждого прогноза при возврате оценки.
from dspy.evaluate.evaluate import Evaluate
def choice_match(example, pred, trace=None):
def extract_choice(gen_ans):
m = re.findall(r'[ABCD]', gen_ans, re.M)
if len(m) >= 1:
answer = m[0]
return answer
return random.choice('ABCD')
return extract_choice(pred.answer) == example.answer
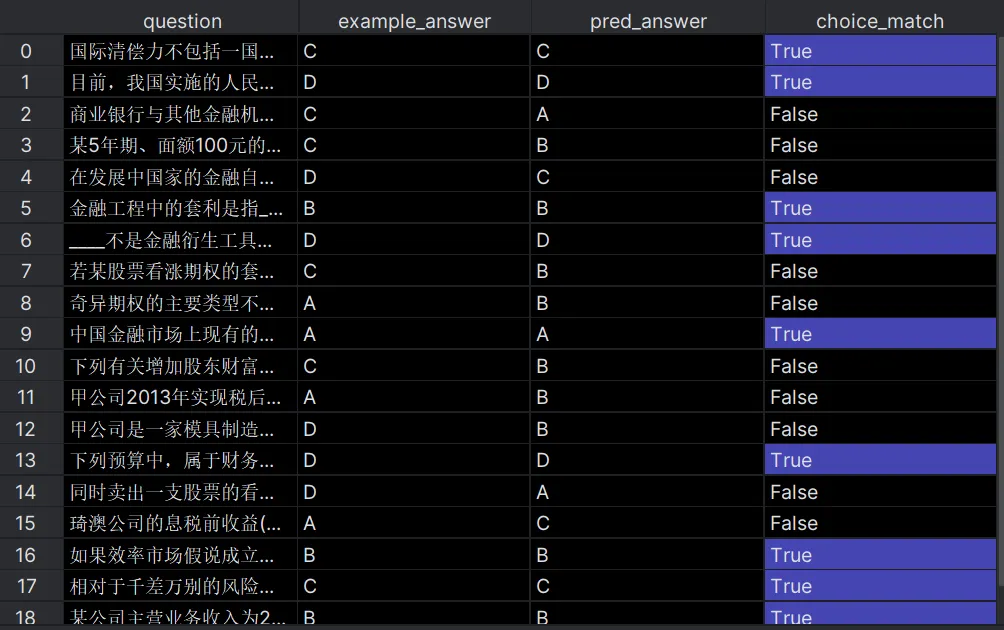
evaluate_on_qa = Evaluate(devset=test, num_threads=1,
display_progress=True, display_table=True)
output1 = evaluate_on_qa(singlechoice_qa, metric=choice_match,return_outputs=True,return_all_scores=True)
output2 = evaluate_on_qa(singlechoice_qa_cot, metric=choice_match,return_outputs=True,return_all_scores=True)Приведенная выше оценка, Точность подсказки 50%, при этом COT Точность подсказки 60%.
Оптимизация FewShot
Давайте сделаем шаг дальше и воспользуемся оптимизацией выборки FewShot, на которой фокусируется DSPy, чтобы посмотреть, можно ли еще улучшить эффект. Здесь DSPy предоставляет множество оптимизаторов для адаптации к различным размерам выборки. Учитывая стоимость, мы используем базовый BootstrapFewShot. Для получения дополнительных образцов вы можете попробовать BootstrapFewShotWithRandomSearch или BootstrapFewShotWithOptuna.
BootstrapFewShot может указать, что несколько снимков содержат несколько выборок, предсказанных моделью (max_bootstrapped_demos), и несколько реальных обучающих выборок (max_labeld_demos).
teleprompter = BootstrapFewShot(metric=choice_match,
max_bootstrapped_demos=4,
max_labeled_demos=16)
compiled_qa = teleprompter.compile(singlechoice_qa_cot, trainset=train)
score3, results3, output3, df3 = evaluate_on_qa(compiled_qa, metric=choice_match,
return_outputs=True,
return_all_scores=True)После добавления выборки Few-Shot точность вывода увеличилась до 75%. , используя 2 демонстрации вывода и 4 демонстрации реальных меток, подсказка модели выглядит следующим образом:
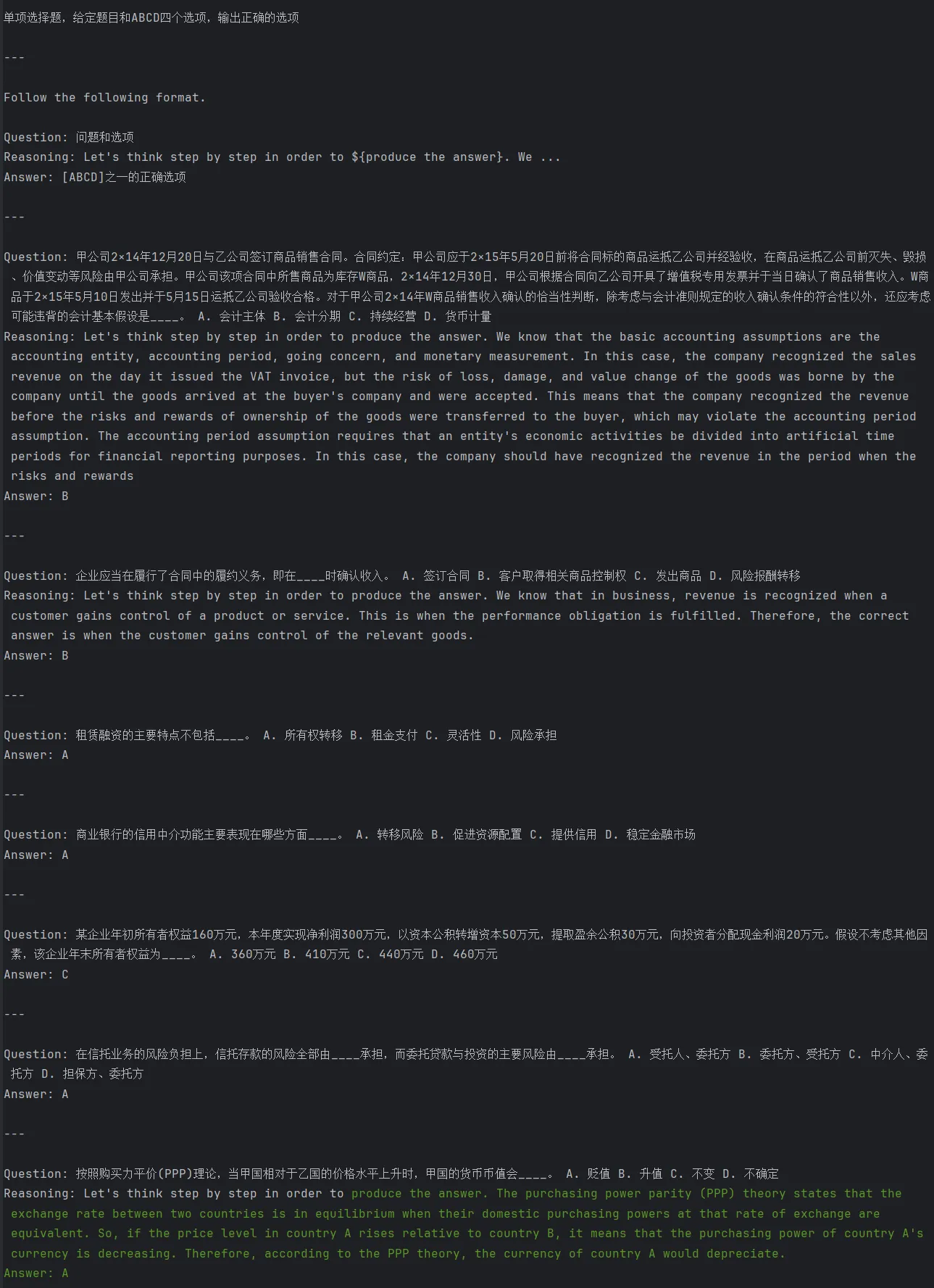
Оптимизация инструкций
Взгляните еще раз на Оптимизацию инструкций,Здесь используется оптимизатор COPRO.,То есть использование подсказок позволяет оптимизировать большие модели и создавать новые подсказки на основе исходных подсказок.,Инструкции по оптимизации и приглашение, генерируемые первым раундом оптимизации, следующие:
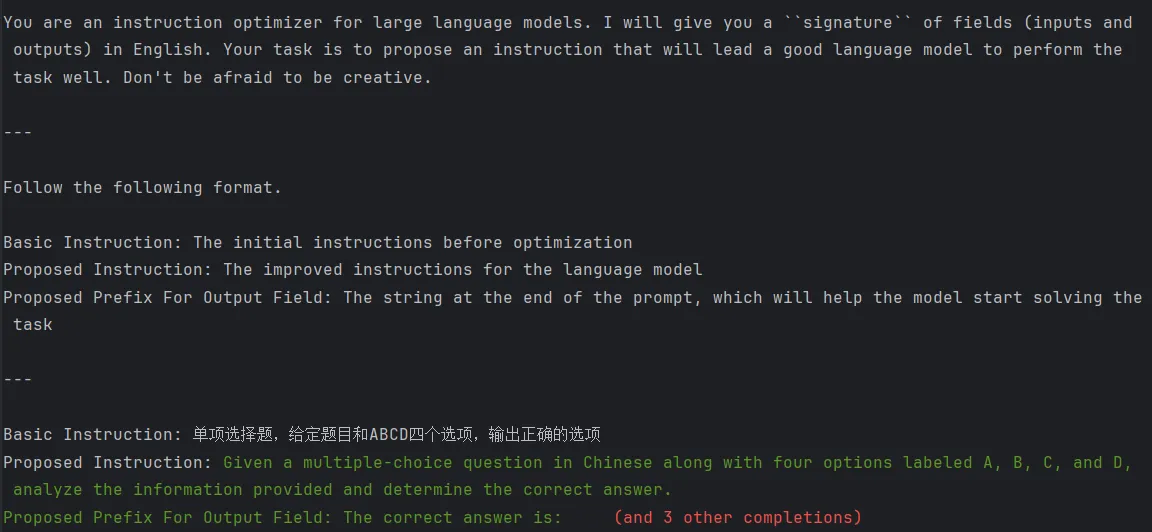
После второго тура Оптимизация инструкции дадут все команды, опробованные ранее,и оценка каждой инструкции в проверочном наборе,и позволить модели выполнить целевую оптимизацию,Назовите это GenerateInstructionGivenAttempts.,Инструкции следующие:
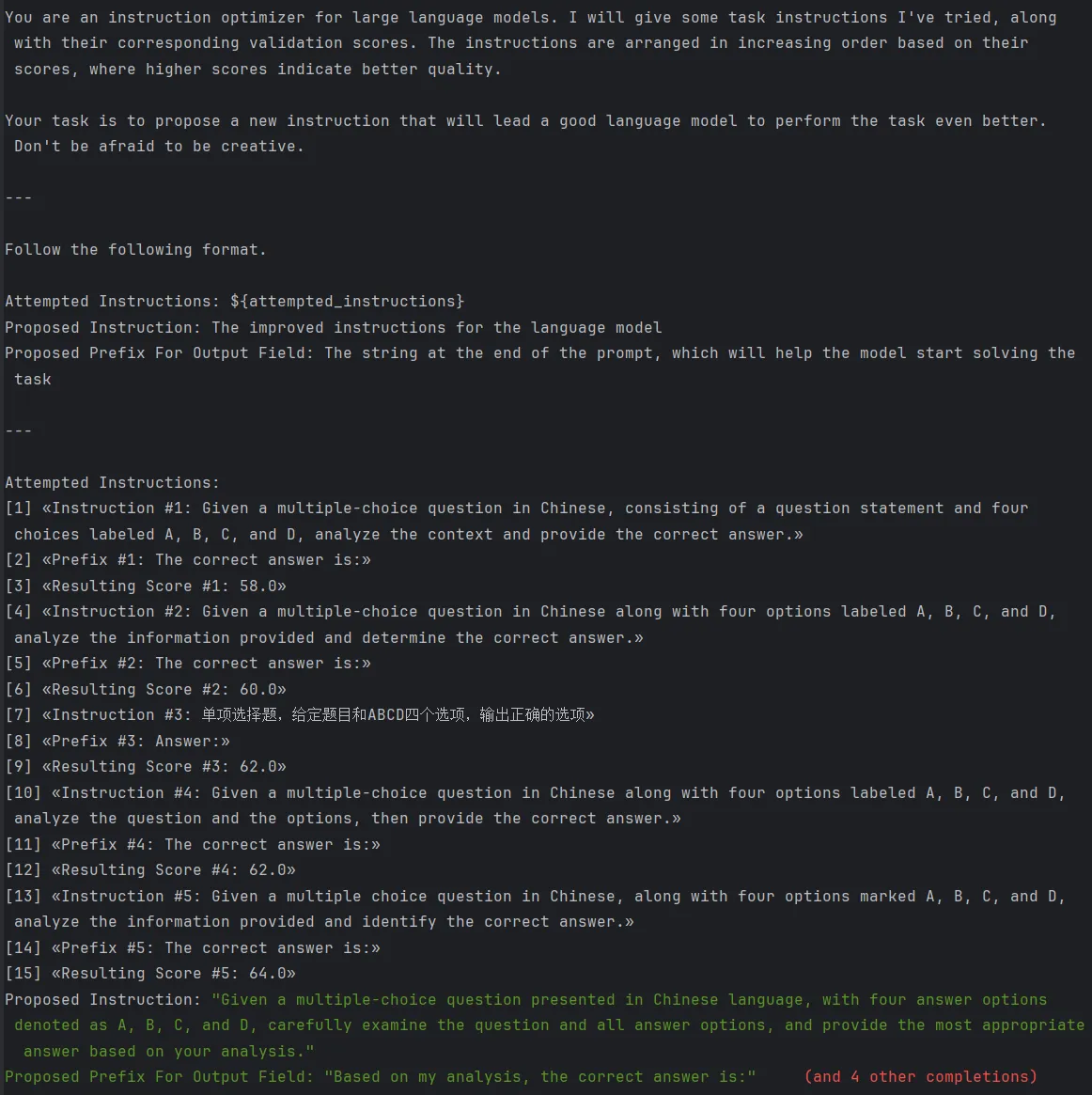
При температуре 0,7 каждый раунд модели будет генерировать новые подсказки шириной = 5 на основе оптимального подсказки предыдущего раунда и повторять описанный выше процесс для глубины = 3 раундов и, наконец, выбирать подсказку с наилучшим эффектом для набор для проверки.
COPRO_teleprompter = COPRO(prompt_model=model ,
metric=choice_match,
breadth=5,
depth=3,
init_temperature=0.7,
track_stats=True)
kwargs = dict(num_threads=1, display_progress=True, display_table=5)
COPRO_compiled_qa = COPRO_teleprompter.compile(singlechoice_qa_cot,
trainset=train,
eval_kwargs=kwargs)
print(model.inspect_history(n=1))Оптимальная инструкция после окончательной оптимизации выглядит следующим образом:

Но в итоге точность на тестовом наборе не улучшилась, которая все еще составляла 60%.,其中一个主要原因也да单选QAСама задача относительно простая,В инструкциях не так много возможностей для оптимизации.,Инструкции по оптимизации более сложны.,Эффект на нерутинных задачах будет более существенным.
В целом DSPy обеспечивает модульность.,Стандартизированное проектное решение,但да在Описание Решения по оптимизации этой задачи в настоящее время относительно ограничены.,Хотя GenerateInstructionGivenAttempts выше предоставляет исторически проверенные инструкции и оценки набора проверок.,Но модели не хватает шага, чтобы суммировать проблемы с текущими инструкциями модели из ответов на исторические подсказки.,Позже вы можете рассмотреть другие решения по оптимизации, связанные с отражением, такие как TextGrad.,Я подведу итоги после того, как поиграю~
Если вы хотите увидеть более полный обзор статей, связанных с большими моделями, данными и платформами точной настройки и предварительного обучения, а также приложениями AIGC, перейдите на Github. >> DecryPrompt



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
