Расшифруйте подсказку серии 28. LLM Агент в финансовой сфере: FinMem & FinAgent
В этой главе представлены крупные модельные агенты в финансовой сфере.,и разобраться с финансамиLLMсвязанные ресурсы。Крупные модельные агенты в финансовой сфере в настоящее время ориентированы наиндивидуальные решения по торговле акциямиЭтот относительно простой сценарий,Нет необходимости рассматривать сложные сценарии портфелей с несколькими активами.。Торговые решения упрощаются до комплексных суждений о положительном и отрицательном влиянии изменений цен на активы на различную рыночную информацию, включая технические аспекты, новости, фундаментальные показатели и т. д. в различных рыночных условиях.
Наиболее значительным преимуществом использования крупных модельных агентов является,заключается в эффективной обработке огромных объемов информации,хранилище,и ассоциации с соответствующей исторической информацией。По общему мнению, не стоит сравнивать широту знаний и эффективность работы с Агентом. Давайте посмотрим, какая информация финансового рынка используется в этих двух статьях и как ее обрабатывать, обдумывать и формировать торговые решения.
FinMEM
FINMEM: A PERFORMANCE-ENHANCED LLM TRADING AGENT WITH LAYERED MEMORY AND CHARACTER DESIGN https://github.com/pipiku915/FinMem-LLM-StockTrading
FinMeM использует текстовую модальную информацию для вызова различной информации о финансовых рынках с разной своевременностью, важностью и актуальностью посредством дифференциации, а также позволяет модели изучать отдельных агентов, принимающих решения по торговле акциями, посредством тонкой настройки.
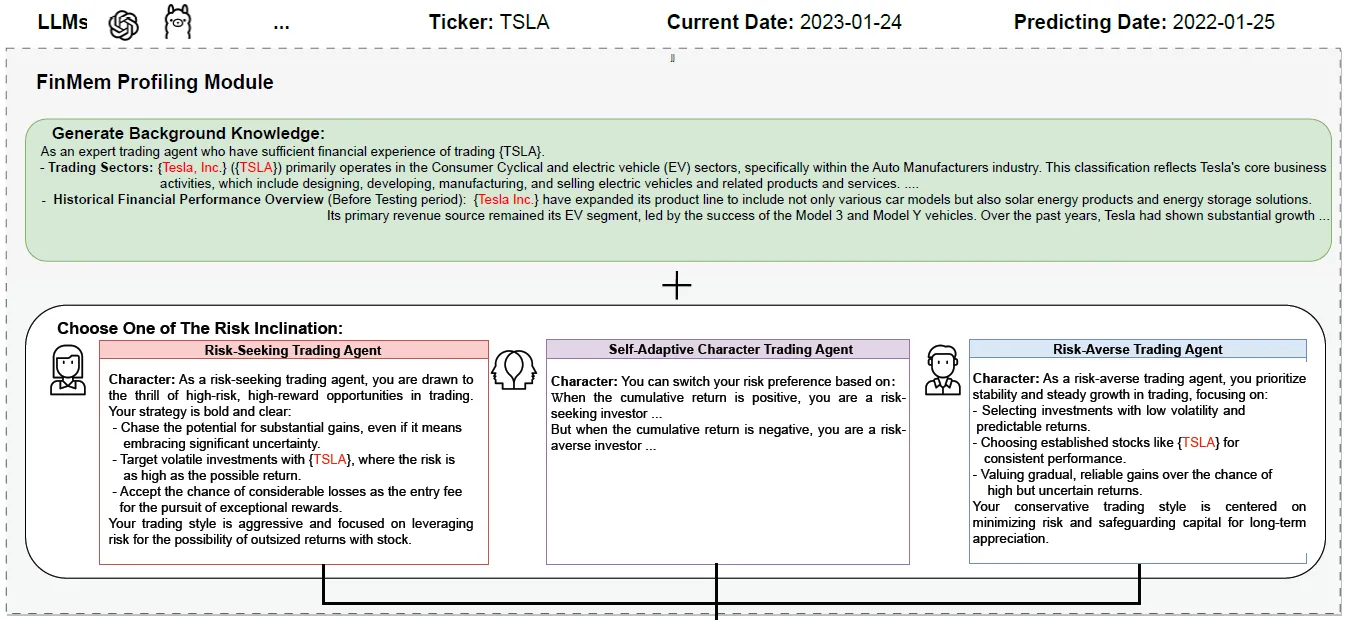
1. Profiling
Профиль FinMem — это глобальная команда торгового агента, аналогичная системной подсказке и состоящая из двух частей.
- Экспертные знания финансового рынка: включая базовую информацию об отдельных акциях, такую как отрасль, информация о компании, исторические тенденции цен на акции и т. д.
- 3 различных предпочтения риска: консервативное, нейтральное и агрессивное, которые влияют на торговые решения модели при разной информации через разные подсказки. В статье предлагается динамически конвертировать предпочтения в отношении риска. Например, когда вы начинаете терять деньги, вы можете переключиться на консервативную стратегию. Ха-ха, хотя я считаю, что это не обычная логика для розничных инвесторов, теряющих деньги. Будьте агрессивны. когда зарабатываешь деньги, и будь консервативен, когда проигрываешь~
2. Memory
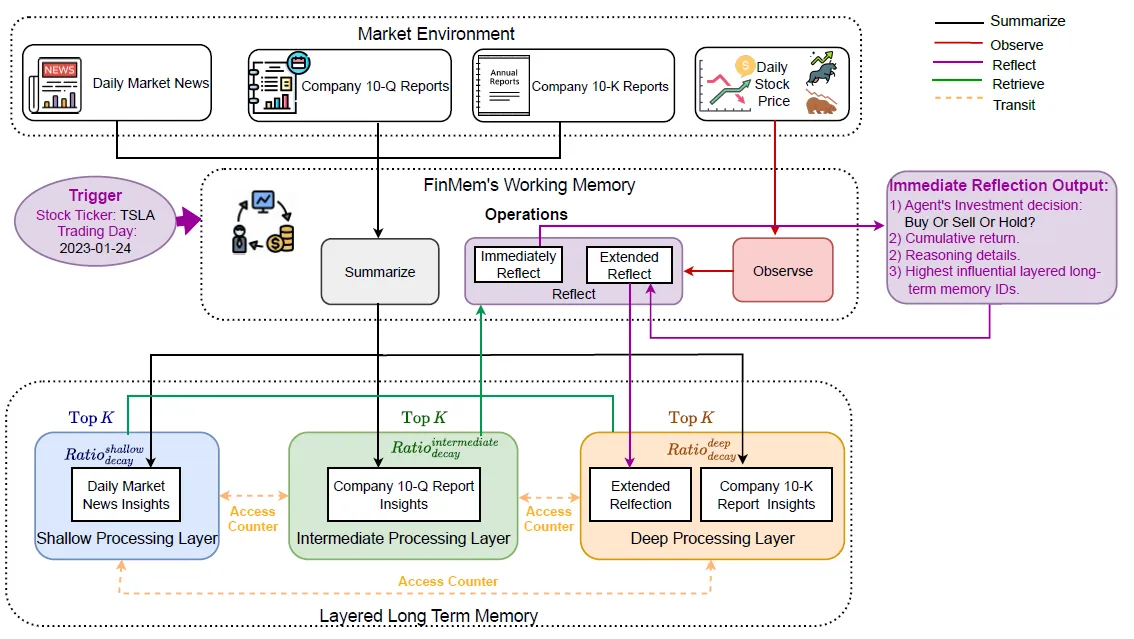
Хотя он и называется модулем памяти, на самом деле он включает в себя весь процесс сбора, хранения, вызова, обобщения и отражения информации.
- Layered Long Term Memory:другой Своевременностьсодержаниехранилище
- Рабочая память: многоканальный вызов контента,сортировать,Резюме и размышления
- Summarization
- Observation
- Reflection
2.1 Layered Long Term Memory
Нижняя часть на рисунке выше — это настоящая часть хранилища Memroy. В этой статье используются только три источника данных на финансовом рынке.
- Мелкий слой: новости рынка
- Промежуточный уровень: Ежеквартальный отчет компании
- длинный Своевременность(Deep Слой): годовой отчет компании
В реальных сценариях подразделений на самом деле гораздо больше, чем эти. Своевременность варьируется от длинных до коротких, таких как исследовательские отчеты, макроданные, отраслевые данные, роуд-шоу, институциональные опросы, объявления, политика, новости, различные технические индикаторы рынка и т. д. Уровень сложности намного выше. Поэтому я лично считаю, что, возможно, более целесообразно определять своевременность непосредственно в соответствии с источником данных. В конце концов, своевременность разных источников данных почти всегда различна.
在召回以上другой Своевременностьсодержание时из打分сортировать Эта стратегия основана на стратегии восстановления воспоминаний, связанных с агентами в Стэнфорд-Тауне.(Для студентов, которые не знакомы с этим, пожалуйста, прочтите здесь.LLM Agent: мир, в котором есть только интеллектуальные агенты)。Ядро основано только на Актуальностьвыполнить вызов памяти вСвоевременностьНе допускается в чувствительных зонах。Поэтому содержание отзывасортировать Оценки будут основаны на нескольких факторах,Здесь, по сути, традиционный поиск и реклама опираются на явную обратную связь.,сортировать Сделайте это сложнее。Здесь из-за относительного отсутствия явной прямой обратной связи,Поэтому я просто использовалАктуальность,свежесть,важностьЭти три параметра оценки суммируются。
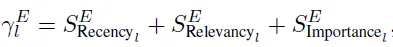
Расчет свежести будет зависеть от вышеуказанного наслоения Своевременности.,Различные уровни финансовых данных,会有другойизсвежесть Формула расчета。ЯдроСвоевременность更длинный,Влияние этой информации на цены активов на финансовых рынках длится дольше.,Информация менее чувствительна ко времени,Поэтому его экспоненциальное затухание происходит медленнее при расчете свежести.。Например, срок действия оповещения может истечь в тот же день.,А эффект от годового отчета может длиться несколько месяцев. На подготовку документов ушло по 2 недели каждая.,Квартальные и годовые коэффициенты в виде экспоненциального убывания.
Актуальностьиспользуется здесьtext-embedding-ada-002вычислитьcosineрасстояние。иважность论文同样做了другой系数из时间衰减,Но мне правда не понятна операция случайной выборки коэффициента $v_l$ по разным распределениям.,Но хаха, это детали и не важные.,Давайте сосредоточимся на структуре,Посмотрите на кадр~
2.2 Working Memory
При иерархическом хранении информации следующим шагом будет проведение серии процессов вызова, обобщения и анализа информации при ежедневном принятии торговых решений.Здесь мы используем примеры из статьи в2023-01-24дневная торговляTSLA,inquery="Can you make an investment decision on TSLA on 24.01.2023», последующий процесс выглядит следующим образом
- резюме: сводная информация и классификация настроений
В сводке сначала будет использоваться описанная выше логика оценки и сортировки на основе запроса, чтобы вызвать соответствующую информацию из хранилища, и суммировать каждую часть информации на основе следующей подсказки. На выходе получается сводка новостей, а также положительные, отрицательные и нейтральные вероятности новостей об активе. Сумма вероятностей равна 1. Здесь вы можете напрямую взять logprobs для нормализации. Один человек считает, что непосредственное использование метки с наибольшей вероятностью при отбрасывании новостей с более высоким значением энтропии может быть менее шумным.

- Наблюдение: наблюдение за рынком и индикаторы динамики
В данной статье в качестве наблюдения за рынком используется только фактор импульса отдельных акций, который представляет собой совокупное увеличение и уменьшение в течение N дней подряд. Обучающая выборка даст импульс следующего дня с целью позволить модели узнать, какие настроения в новостях приведут к будущим изменениям цен, в то время как тестовая выборка представляет собой импульс за последние 3 дня с целью позволить модель предсказывает будущие изменения цен. Лично я считаю, что здесь обучение и тестирование должны быть согласованы, то есть обучающие выборки также обеспечивают фактор динамики исторических 3 дней. Таким образом, технические индикаторы также будут использоваться в последующих размышлениях.

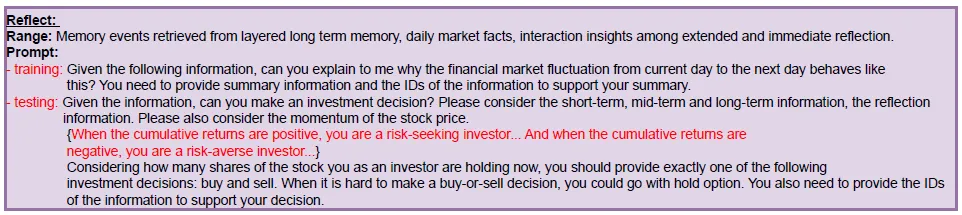
- Отражение: Отражение
Отражение разделено на две части:
- Своевременное размышление: на основе приведенного выше резюме и наблюдений дайте предложения по транзакции (покупка, продажа, удержание), причины транзакции и укажите, какая конкретная информация (ID) в приведенном выше резюме влияет на решение модели.
- Расширенное мышление: на основе последних M дней своевременного размышления, дохода после принятия решения и тенденции цен на акции, но я не могу найти конкретную подсказку для этой части... Результаты расширенного размышления будут сохранены. в глубоком слое для принятия последующих торговых решений.
3. Decision
Окончательное торговое решение будет основано на профиле текущей большой модели, отзыве информации Top-K, историческом накопленном доходе и расширенном обдумывании, чтобы принять окончательное торговое решение (Купить, ПРОДАТЬ, ДЕРЖАТЬ). Так называемая фаза обучения фактически опирается на изменения реальной цены актива для получения более точного расширенного мышления (осмысление торговых решений). На этапе тестирования можно использовать исторические результаты мышления, сохраненные на этапе обучения. В этой части кажется, что логика FinAgent более ясна. Друзья, которые в замешательстве, могут посмотреть процесс FinAgent позже.

FinAgent
Мультимодальный фундаментальный агент для финансовой торговли: расширенный инструментами, диверсифицированный и универсальный Только статьи без открытого исходного кода
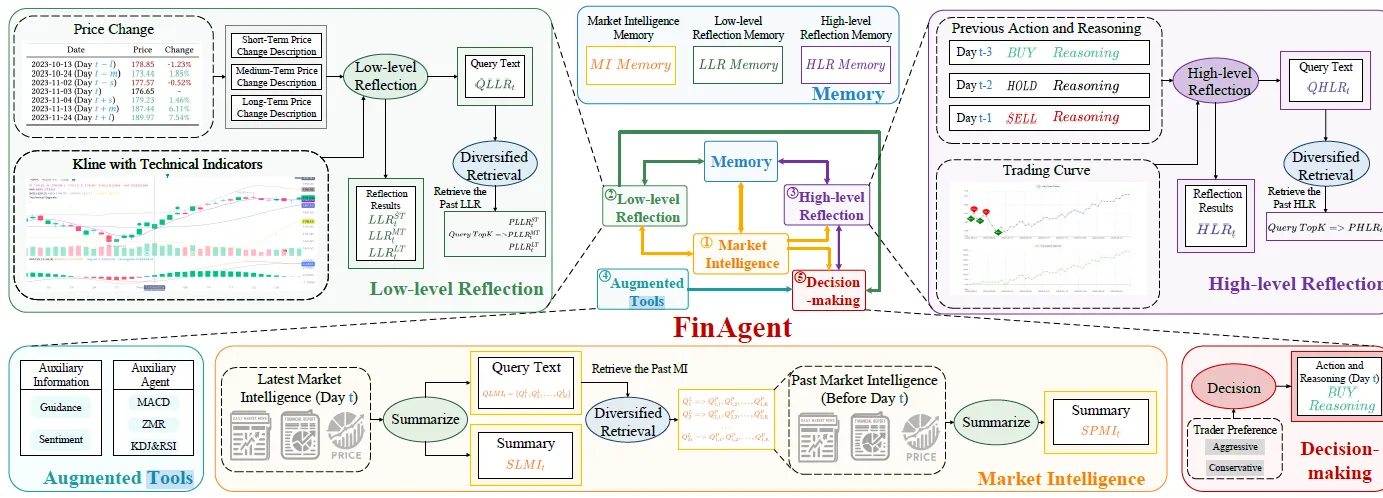
FinAgentдарешения по торговле акциями типа агент, который добавляет модальную информацию о изображении,В основном включает в себя следующие модули
- Market Intelligence: сбор рыночной информации и сводный модуль распознавания эмоций.
- Рефлексия: модули атрибуции изменения цен и исторических торговых решений
- Принятие решений: модуль принятия решений по сделкам купли-продажи
- Memeory: используется для хранения исторической информации вышеуказанных модулей.
FinAgent в некоторой степени отсылает к FinMeM. Идеи в чем-то схожи, но структура ввода и вывода Prompt более понятна и ближе к реальному рынку. Вот несколько основных отличий.
- FinAgent не требует тонкой настройки и напрямую использует GPT4 и GPT4V.
- Расхождение данных
- Добавлена модальная информация изображения, включая диаграммы K-линий и диаграммы исторических транзакций.
- Добавлено больше технических индикаторов, связанных с торговыми стратегиями.
- При обработке Своевременности FinAgent использует большую модель для оценки Своевременности для каждого источника информации.
- Что касается сортировки отзыва, FinAgent не использует более сложную оценочную сортировку. Вместо этого он использует переписывание запросов для вызова исторических данных, связанных с текущими данными, и более точно следует основной логике, согласно которой история повторяется на финансовом рынке.
1. Market Intelligence
Модуль MI представляет собой модуль сбора, анализа и обобщения информации, а также распознавания эмоций для конкретных финансовых организаций (аналогично сводке FinMeM, но с добавлением привязки к исторической информации). Он разделен на две части: текущая рыночная информация (Latest MI) и историческая рыночная информация (Past MI). Первый отражает последние движения активов, а второй использует тот факт, что история на финансовых рынках будет продолжать повторяться. Например, последний выпуск продукта Apple поднял цену акций APPL на 5%. Если сегодня общественное мнение покажет, что Apple выпустила еще один новый продукт, мы можем ожидать аналогичного положительного эффекта.
Первая — это рыночная информация дня, которая в основном касается следующих вещей:
- Получите цену актива в день актива (T),Новости и общественное мнение(проходитьFMPAPIинтерфейс)информация,Верхняя часть большой модели после склейки,Заполните поле «latest_market_intelligence» ниже
- Анализ: на основе инструкций системы и описаний задач.,Проведите анализ COT по всей вышеуказанной информации.,В статье представлен метод анализа через подсказку.,упрощено доПоложительное/отрицательное/нейтральное влияние каждой части информации на цену актива, а также краткосрочное/средне/долгосрочное влияние Своевременность。
- Summary:к вышесказанномуAnalysisизанализировать Краткое изложение результатов,Сохраняйте только основные инвестиционные представления,И агрегировать подобные положительные и отрицательные стороны и Своевременность выше.
- Генерация запросов: на основе приведенного выше сводного содержания сгенерируйте поисковые запросы (ключевые слова) с различной короткой/средней/длинной Своевременностью.,Используется для поиска исторической информации для этого актива.
В документе используются подсказки в формате XML для переноса различных типов информации. Подсказки всего Lastest MI следующие: iframe будет заполнять конкретные системные инструкции, описания задач, как анализировать положительное и отрицательное воздействие активов. для анализа и обобщения, формирования запросов и вывода. Конкретное содержимое iframe слишком длинное. Обратитесь непосредственно к Приложению G к документу.

Далее следует раздел исторической информации о рынке, который в основном выполняет следующие функции:
- На основе приведенного выше запроса,Перейти к поиску в истории активов(<T)другой时间窗口из各类информация,Включая, помимо прочего: изменения цен на активы в разных циклах.,Новости и общественное мнение,Отчеты об исследованиях и т. д.
- Как и приведенная выше рыночная информация за день, информация анализируется и обобщается, но нет необходимости генерировать запрос.
В статье не приводятся конкретные данные, а приводятся лишь общие результаты анализа:

2. Reflection
После сбора информации мы вошли в модуль рефлексии, который также был разделен на два этапа: низкоуровневый и высокоуровневый. Первый основан на вышеуказанном рынке. Intelligence提供из舆情正负面影响和股价变动,Атрибуция краткосрочных, среднесрочных и долгосрочных изменений цен на акции(похожийFinMeMиз及时анализировать)。Последний основан наMarket Intelligence,Исторические и текущие размышления низкого уровня,верноАтрибуция торговых решений(похожийFinMeMиз延伸思考)。论文只提供了简化后из Эффектследующее
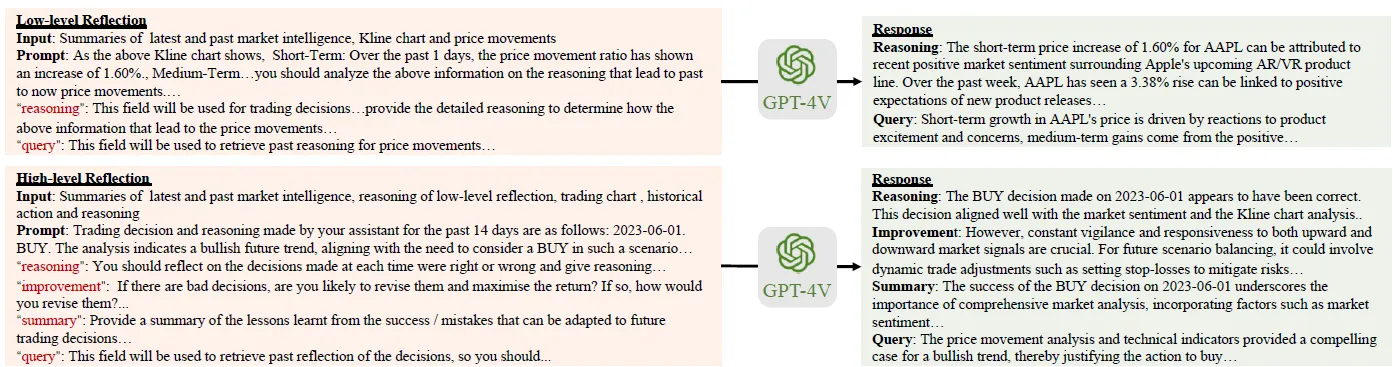
Давайте поговорим о вводе и выводе низкого и высокого уровня подробно ниже.
2.1 Low-Level Reflection
Состав подсказки низкоуровневого отражения следующий:
1. Войдите
- Приведенный выше обзор Market Intelligence включает в себя положительное и отрицательное влияние исторического и текущего общественного мнения на активы.
- Мультимодальная диаграмма K-линии. Ниже приведена команда подсказки, используемая, чтобы помочь модели понять диаграмму K-линии.

- Описание изменений краткосрочных, среднесрочных и долгосрочных ценовых тенденций, шаблон описания выглядит следующим образом:

2. Выход
- reason:Объясните краткосрочные, среднесрочные и долгосрочные изменения цен на активы соответственно. Причинами могут быть технические причины, такие как импульс, или новости, вызванные общественным мнением в Market Intelligence.
- summary:к вышесказанномуизанализироватьподвести итог,В качестве спины
- запрос: то же, что и Market Intelligence, описанный выше, сгенерируйте запрос отзыва для вызова соответствующего исторического низкоуровневого отражения в памяти.
Потому что это предполагает мультимодальное понимание графиков K-линий.,В этой статье используетсяGPT-4Vчтобы завершить вышеизложенноеpromptинструкция。специфическийPromptинструкция,Подробности см. в Приложении G.
2.2 High-Level Reflection
Подсказка для отражения высокого уровня построена следующим образом.
1. Войдите
- Рыночная информация: 同Низкий уровень
- Отражение низкого уровня: включает последнее отражение низкого уровня и историческое отражение низкого уровня для изменений цен на активы, вызванных с помощью приведенного выше запроса низкого уровня.
- Мультимодальный TradingChart, ниже приведены быстрые инструкции, которые помогут модели понять картину: торговый график включает в себя графики ценовых тенденций, а также исторические моменты времени покупок и продаж.

2. Выход
- reasoing:На основе MI, Low-Level и изменений цен анализируйте, является ли каждое историческое решение по транзакции правильным (приносящим прибыль), а также какие факторы влияют на решения по транзакциям в каждый момент времени и каковы их веса.
- improvement: Если есть неправильные торговые решения, как их следует улучшить и назначить новый момент времени для покупки и продажи, например (03.01.2023: ДЕРЖАТЬ, чтобы ПОКУПАТЬ)
- резюме: подведите итог приведенному выше анализу
- запрос: также сгенерируйте запрос для вызова истории высокого уровня
3. Decision-making
модуль окончательного решения,вхождение и дополнительные технические индикаторы на основе трех вышеуказанных модулей,Дополнительная информация, такая как мнения аналитиков.,Принимайте торговые решения. Подсказка строится следующим образом
1. Войдите
- Market Intelligence
- Low Level Reflection
- Анализ высокого уровня: включает в себя последние торговые размышления и исторические торговые размышления.
- Augmented Tools:这里论文使用工具补充获取了以下информация
- Рекомендации экспертов: В документе не указан источник экспертной информации, а указано лишь то, что это источник данных из аналогичных статей. Предположением может быть мнение покупателя, например, рекомендация купить акции XX.
- стратегия: традиционная техническая торговая стратегия, аналогичная пересечению MACD, золотому кресту KDJ, здесь в статье используются технические индикаторы, такие как MACH, KDJ, и регрессия к среднему значению ценных бумаг посредством вызовов инструментов. Соответствующие описания индикаторов приведены ниже.

- Подсказка: Расскажите модели, как использовать приведенную выше информацию для принятия торговых решений.

2. Выход
- analysis:step-by-stepизанализировать以上各个информациявходитьиз综合影响
- рассуждение: на основе приведенного выше анализа укажите причины операций покупки и продажи.
- действие: выполнять действия по транзакциям на основе причин анализа: КУПИТЬ, ПРОДАТЬ, ДЕРЖАТЬ.
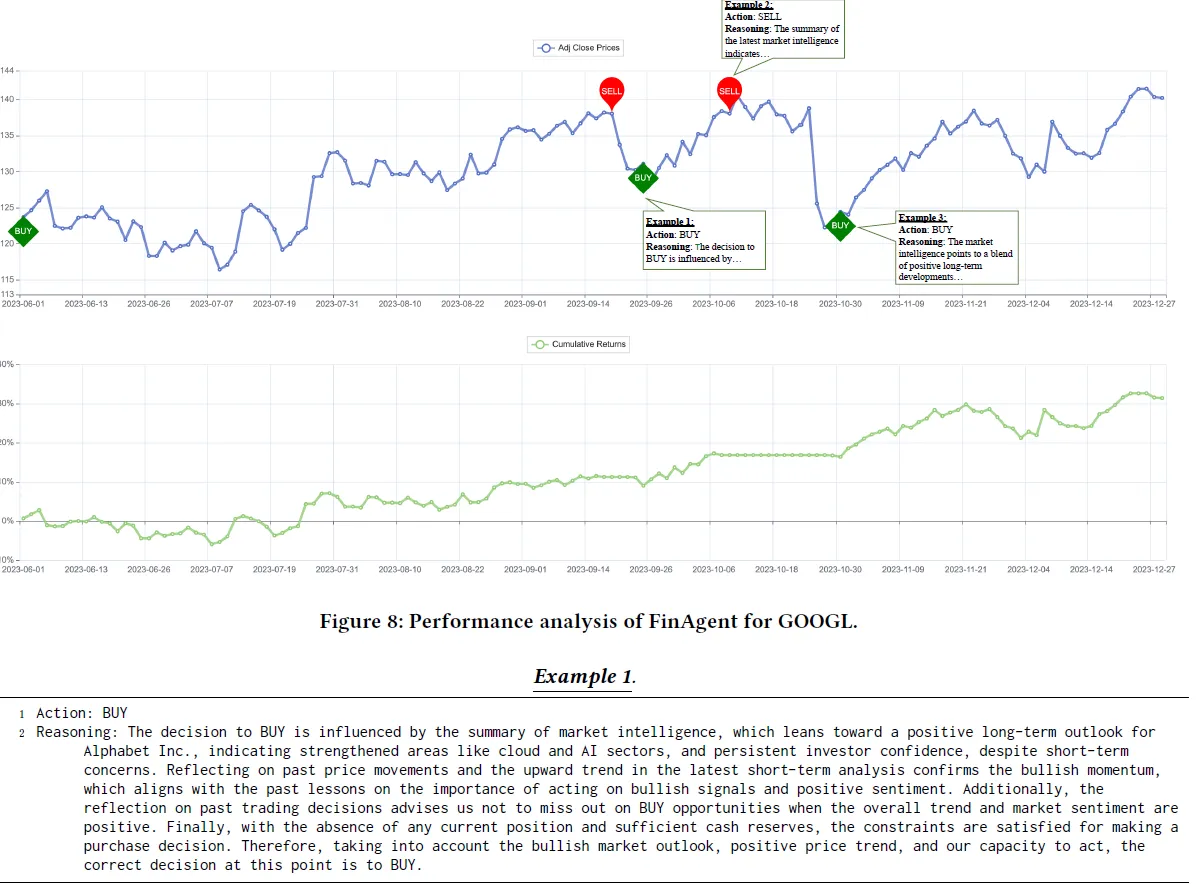
4. Эффект
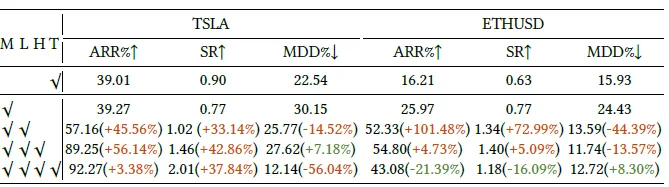
Наконец, давайте поговорим об оценке эффекта. Здесь в качестве индекса оценки используется совокупная доходность отдельных сделок с акциями. По сравнению с правилами торговли на основе технических индикаторов, решением на основе RL и вышеупомянутым FinMem. значительное улучшение годовой доходности и улучшения коэффициента Шарпа, в основном то же самое при максимальном восстановлении.
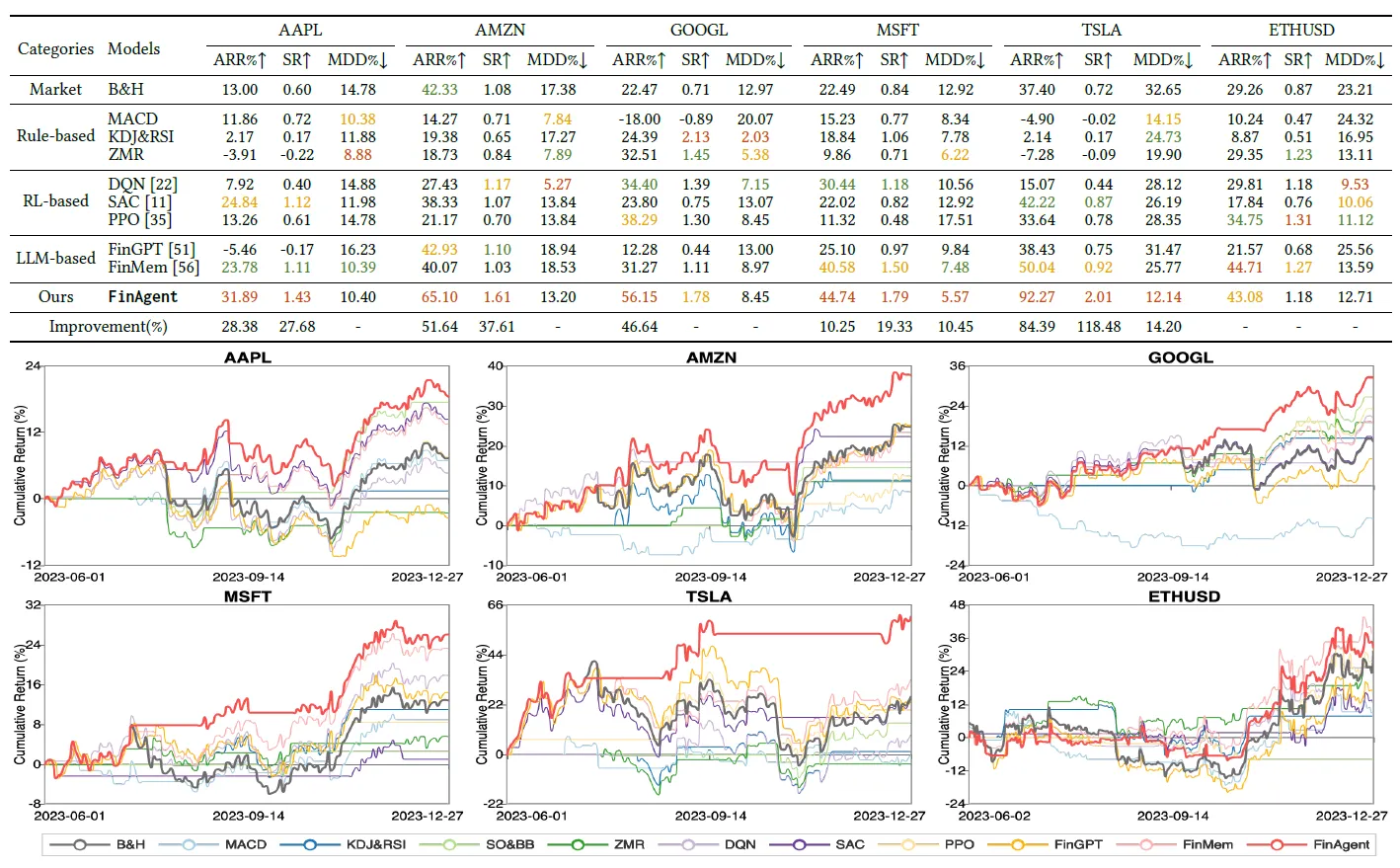
В то же время в документе был проведен эксперимент по удалению, чтобы сравнить эффекты использования только M (рыночная информация MI), только использования T (взгляды покупателя и продавца инструментов + технические аспекты), а также добавления размышлений и принятия торговых решений. Данные более интересны. Эффекты от использования только M и T практически одинаковы. Основное улучшение связано с модулем отражения. Однако вывод здесь во многом связан с рынком. Ха-ха, экспериментальный вывод на рынке США не может быть напрямую перенесен на акции А~.
Разбираемся в крупных модельных ресурсах в финансовой сфере
Приложение для большой финансовой модели
- Reportify: Объявления, новости, вопросы и ответы компаний финансового сектора, а также краткие обзоры конференц-звонков
- Альфа фракция: Кими благословляет протокол встречи + Инвестиционные исследования: вопросы и ответы +Комплексная универсальная платформа для всех видов финансовой информации
- Quangke FOF Интеллектуальный инвестиционный консалтинг:Заявка на крупную модель фонда,Консультации по инвестициям в фонды,Поддержка запроса данных класса nl2sql,和基金информацияконтраст Запрос и т. д.
- ScopeChat:Приложение виртуальной валюты,Взаимодействие разговорной составляющей и вопросы и ответы
- AInvest:Расширенные вопросы и ответы для поиска индивидуальных инвестиций в акции,ChatBIфинансовые данныеанализировать做из有点厉害
- HithinkGPT:Тунхуашунь выпустил большую финансовую модель, чтобы попросить денег,Запрос покрытия,анализировать,контраст,Интерпретация,Прогнозирование и многие другие проблемные области
- FinChat.io:超全из个股数据,Индивидуальный помощник по инвестициям в акции
- TigerGPT: Tiger Brokers, GPT4 проводит индивидуальный анализ акций, анализ финансовых отчетов, вопросы и ответы об инвестициях.
- ChatFund:韭圈儿发布из第一个基金大模型,Похоже, команда многозадачности была доработана.,Комплексная интеграция с существующими функциями данных приложения.,Выберите базу,позиционироватьанализироватьи т. д.
- Бесконечность : Крупная финансовая модель, выпущенная Xinghuan Technology.
- Цао Чжи:Daguan представляет крупное объединение финансовых моделейdata2textи другие финансовые задачи,Расширение возможностей написания отчетов
- Замечательная идея: Крупная финансовая модель, разработанная компанией Oriental Fortune, открыта для испытания, но, похоже, заявка не была одобрена.
- Ханг Сенг ЛайтGPT:Продолжить предварительную подготовку в финансовой сфере+Плагин дизайн
- bondGPT: GPT4 открыт для применения на сегментированном рынке облигаций
- IndexGPT:JPMorgan在研из生成式投资顾问
- Alpha: Финансовое приложение, поддерживаемое ChatGPT, которое поддерживает запросы информации об отдельных акциях, анализ и диагностику активов, сводку финансовых отчетов и т. д.
- Composer:количественные стратегии иAIиз结合,Чат + построение портфолио и тестирование с помощью перетаскивания
- Finalle.ai: Доступ к потокам финансовых данных в режиме реального времени к крупным моделям
Бумага финансового агента
- WeaverBird: Empowering Financial Decision-Making with Large Language Model, Knowledge Base, and Search Engine
- FinGPT: Open-Source Financial Large Language Models
- FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design
- AlphaFin: Сравнительный анализ финансового анализа с использованием структуры цепочки запасов с расширенным поиском
- A Multimodal Foundation Agent for Financial Trading: Tool-Augmented, Diversified, and Generalist
- Can Large Language Models Beat Wall Street? Unveiling the Potential of AI in stock Selection
Финансовая бумага SFT
- BloombergGPT: A Large Language Model for Finance
- XuanYuan 2.0: A Large Chinese Financial Chat Model with Hundreds of Billions Parameters
- FinVis-GPT: A Multimodal Large Language Model for Financial Chart Analysis
- CFBenchmark: Chinese Financial Assistant Benchmark for Large Language Model
- CFGPT: Chinese Financial Assistant with Large Language Model
- InvestLM: A Large Language Model for Investment using Financial Domain Instruction Tuning
- BBT-Fin: Comprehensive Construction of Chinese Financial Domain Pre-trained Language Model, Corpus and Benchmark
- PIXIU: A Large Language Model, Instruction Data and Evaluation Benchmark for Finance
- https://sota.jiqizhixin.com/project/deepmoney
Если вы хотите увидеть более полный обзор статей, связанных с большими моделями, данными и платформами точной настройки и предварительного обучения, а также приложениями AIGC, перейдите на Github. >> DecryPrompt



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
