Расшифровка подсказок. Серия 4. Настройка инструкций обновления: Flan/T0/InstructGPT/TKInstruct.
В этой главе мы говорим о тонкой настройке команд. Какова связь между тонкой настройкой команд и приглашением, представленным в первых трех главах? Ха-ха, если вы присмотритесь повнимательнее, вы обнаружите некоторые различия в определениях подсказки и инструкции. Некоторые люди думают, что инструкция — это разновидность подсказки, а некоторые думают, что инструкция — это подсказка типа предложения. .
По сравнению с основной парадигмой подсказок, представленной в первых трех главах, точная настройка команд имеет следующие характеристики:
- Для больших моделей:Суть задачи точной настройки инструкций заключается ввыпускатьМодель уже существует Понимание возможность использования инструкций (впервые предложено в GPT3),Поэтому инструкция по тонкой настройке рассчитана на большие модели.,потому чтоПонимание инструкцийбольшой Модельизпоявлятьсяспособность№1。иpromptНекоторые ориентированы на обычные модели, например.BERT
- Предварительная подготовка: не так много инструкций tunning,больше похоже наinstruction pretraining,Он предназначен для включения различных тонких настроек инструкций НЛП на этапе предварительной подготовки.,вместо тонкой настройки конкретных последующих задач,Предыдущие подсказки в основном были сосредоточены на тонкой настройке и сценах с нулевым кадром.
- Многозадачность: следующие модели разработаны с использованием различных наборов данных для точной настройки инструкций.,Но суть в Разнообразии,Дифференциация,Охватывает более широкий спектр задач НЛП.,Большинство предыдущих моделей подсказок имеют конкретную ориентацию на задачи.
- Обобщение. Инструкции по точной настройке больших моделей имеют хорошее обобщение, а также будут улучшены инструкции, выходящие за пределы выборки.
- Применимые модели: Учитывая, что все инструкции имеют форму предложений, они применимы только к моделям классов En-Dn и Decoder only. Предыдущая часть приглашения представляла собой закрытие для Encoder.
Ниже мы представляем несколько моделей, связанных с точной настройкой инструкций. Все модели представляют собой знакомые модели. Основное различие заключается в разных наборах данных инструкций для точной настройки и различных фокусах оценки. Мы фокусируемся только на различиях для каждой модели. В хронологическом порядке это Flan, T0, InstructGPT, TK-Instruct.
Google: Flan
paper: 2021.9 Finetuned Langauge Models are zero-shot learners github:https://github.com/google-research/FLAN Модель: 137Б LaMDA-PT В двух словах: воспользуйтесь этой возможностью: Google первым предлагает точную настройку инструкций, чтобы разблокировать возможности понимания инструкций для больших моделей.
Флан из Google был первым, кто предложил парадигму точной настройки инструкций. Цель та же, что и в названии. В ней используется точная настройка инструкций для улучшения возможности модели с нулевым результатом. В документе используется 137B LAMDA-PT, односторонняя языковая модель, предварительно обученная в Интернете, коде, диалоге и вики.
набор команд
Google более традиционен в построении наборов данных. Непосредственное преобразование 12 основных категорий набора данных Tensorflow, в общей сложности 62 набора данных задач НЛП, в набор данных инструкций с помощью шаблонов.
Чтобы увеличить разнообразие набора данных инструкций, для каждой задачи будет разработано 10 шаблонов, всего будет 620 инструкций, а шаблонов преобразования задач будет до 3. Так называемое преобразование задачи заключается в преобразовании задачи классификации эмоций, такой как обзор фильма, в задачу создания обзора фильма, в полной мере используя существующие аннотированные данные для создания более богатого набора данных инструкций. Ха-ха, такое ощущение, будто это место наполнено искусственной силой.
Чтобы обеспечить разнообразие и сбалансированность набора данных, обучающие выборки каждого набора данных ограничены 30 000, а учитывая, что скорость адаптации модели к задаче зависит от размера набора данных задачи, она пропорциональна к размеру выборки используемого набора данных. Выборочное гибридное обучение.
Эффект
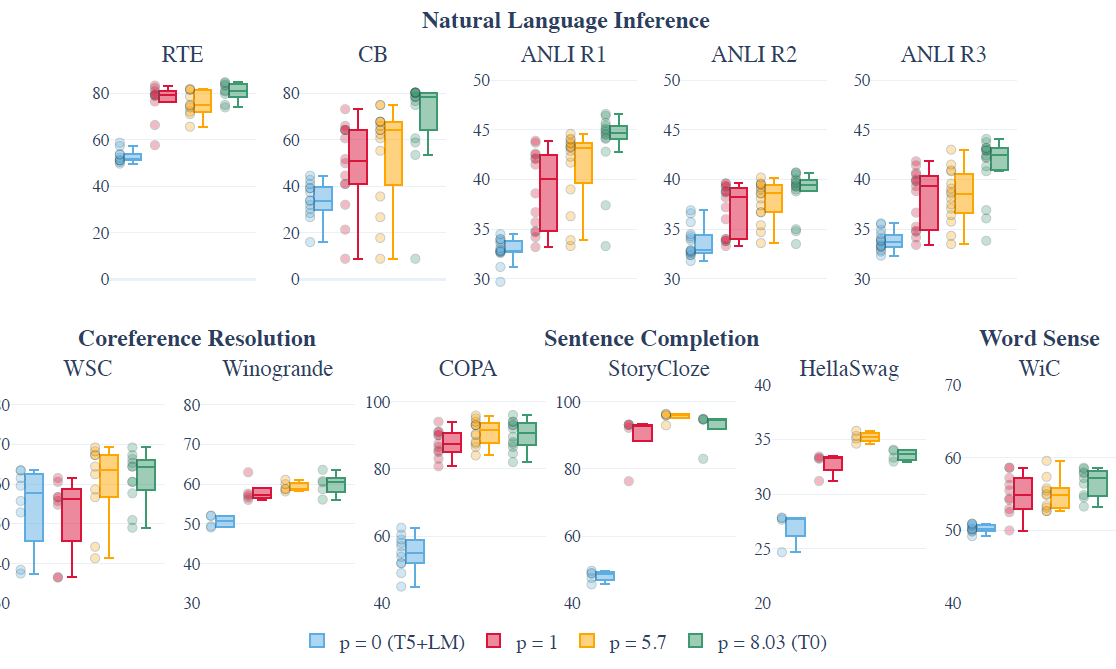
Модель точной настройки инструкций 137B в Эффекте значительно превосходит GPT3 с несколькими кадрами, особенно в задачах NLI, учитывая, что NLI обычно не будет естественным образом появляться в виде последовательных предложений в тексте перед обучением. Создание более естественного шаблона для тонкой настройки инструкций привело к значительному улучшению производительности.
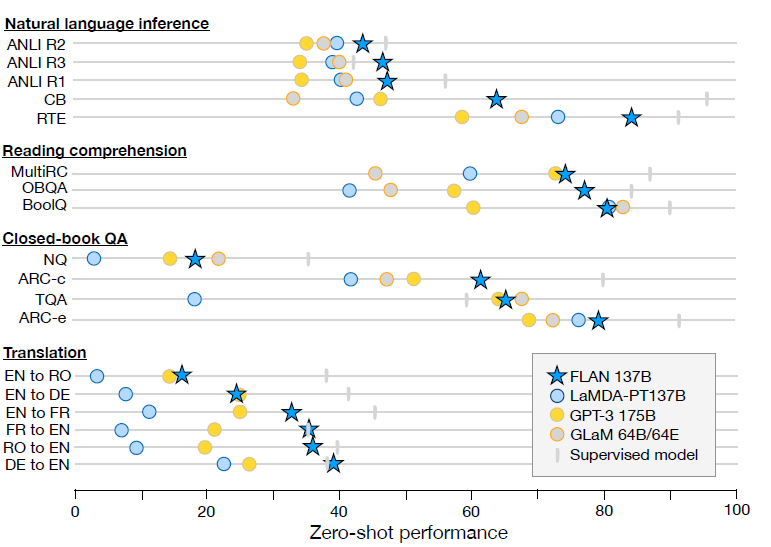
В дополнение к вышеперечисленным задачам, имеющим очевидные улучшения Эффекта,В некоторых задачах, где сами задания аналогичны инструкциям.,Например, рассуждения на основе здравого смысла и задачи по устранению ссылочной неоднозначности.,Доработка директив не приносит существенных улучшений.
Автор провел дополнительные эксперименты по абляции, чтобы проверить следующие переменные при точной настройке инструкций.
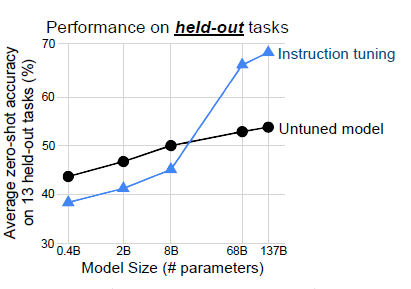
- Размер модели: Далее автор демонстрируетУлучшение «Эффекта», вызванное тонкой настройкой команды, имеет очевидный эффект большой модели.,Только когда масштаб модели составляет около 10 миллиардов,Только тонкая настройка инструкций приведет к улучшению выполнения задач, выходящих за рамки выборки. Авторы подозревают, что когда размер модели меньше,Точная настройка большего количества задач может занять ограниченное пространство параметров модели.,Вызывает забывание общих знаний во время предварительной тренировки.,Снижен эффект от новых задач.
- Влияние многозадачности: Учитывая, что точная настройка инструкций выполняется для нескольких задач, автор надеется устранить влияние многозадачной тонкой настройки на тонкую настройку инструкций. Поэтому мы попытались выполнить точную настройку многозадачности без инструкций (с использованием имен наборов данных вместо инструкций). Точная настройка инструкций в «Эффекте» оказалась значительно лучше, что указывает на то, что дизайн шаблона инструкций действительно улучшает модель. инструкциймощный Эффект。
- малозарядный: Помимо нулевого выстрела, Флан также проверил эффект нескольких выстрелов. В целом, эффект от нескольких выстрелов лучше, чем от нулевого. Это показывает, что точная настройка инструкций также улучшает несколько кадров.
- В сочетании с оперативной настройкой Поскольку точная настройка инструкций улучшает способность модели понимать инструкции, автор считает, что дальнейшее использование программных подсказок также должно быть улучшено. Поэтому быстрая настройка в дальнейшем использовалась для точной настройки последующих задач. Неудивительно, что Flan имеет значительное улучшение по сравнению с предварительно обученным LaMDA Effect.
BigScience: T0
paper: 2021.10 Multitask prompted training enables zero-shot task generation T0: https://github.com/bigscience-workshop/t-zero Model: 11B T5-LM В двух словах: Флан, я подумал о том же, что и ты! Но мой набор командных данных богаче и разнообразнее
T0 — документ, выпущенный сразу после Flan. По сравнению с Flan он имеет следующие основные отличия:
- Различия в моделях предварительного обучения: Flan предназначен только для декодера, T0 — это T5 кодера-декодера, и, учитывая, что предварительное обучение T5 не имеет цели LM, T5-LM, который продолжает предварительное обучение с задачей LM в используется быстрая настройка
- Разнообразие инструкций: T0 использует набор данных PromptSource, а инструкции богаче, чем у Flan.
- Масштаб модели: Флан обнаружил в эксперименте по абляции, что инструкции по точной настройке ниже 8B не подходят.,T0 3B также был улучшен за счет тонкой настройки команд. Возможное влияние – это разница в целевых показателях En-Dn перед тренировкой.,И набор Т0 команда Более разнообразная и креативная
- Задача обобщения вне выборки: чтобы проверить обобщение тонкой настройки инструкций, Флан резервирует один тип задач за раз для обучения оставшимся задачам и обучает несколько моделей. Т0 исправляет 4 типа задач и дорабатывает остальные задачи.
Далее мы подробно объясним данные команды и эксперименты по абляции T0.
набор команд
T0 создал набор данных Prompt с открытым исходным кодом P3 (Public Pool of Prompts),включать173 набора данных и 2073 подсказки。По сравнению с богатствомFlanУлучшено на целый порядок,Но содержит только текст на английском языке,Более подробную информацию о построении набора данных можно найти в документе PromptSource.
Автор в наборе командизРазнообразиеСделал это2эксперименты по абляции
- набор Количество наборов данных, включенных в команду: в Т0 оригинальный набор командизпо сути,Авторы отдельно добавили в проверочный комплект ГПТ-3,и Супер КЛЕЙ,Были обучены модели T0+ и T0++. На 5 отложенных задачах,Увеличение количества наборов данных не обязательно приведет к улучшению Эффекта.,И в некоторых логических задачах,Увеличение количества наборов данных также приведет к увеличению разброса (снижается стабильность работы модели на разных шаблонах подсказок)
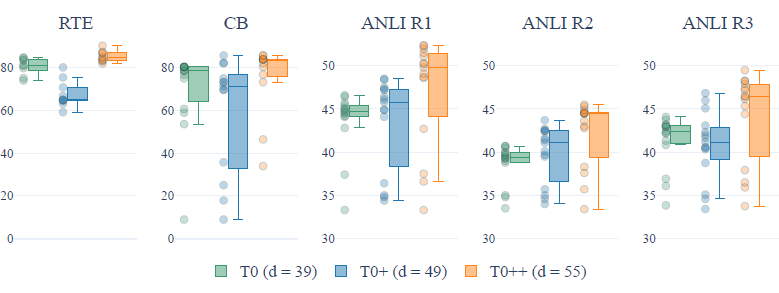
- Количество подсказок для каждого набора данных (p). Отбирая различное количество подсказок из каждого набора данных для обучения, автор обнаружил, что по мере увеличения количества подсказок медианная производительность модели значительно увеличится, а разброс уменьшится. в разной степени, но, по-видимому, наблюдается уменьшающийся предельный эффект.
OpenAI: InstructGPT
документ: 2022.3 Языковая модель обучения для следования инструкциям с обратной связью от человека Модель: (1.3B, 6B, 175B) GPT3 В двух словах: Вы все еще играете в Бенчамрк? Мы изменили геймплей! Улучшение искусственного интеллекта — наша цель
Здесь InstructGPT разделен на две части. В этой главе рассказывается только о части тонкой настройки инструкций, которая является первым шагом в трилогии обучения. В статье она называется SFT (контролируемая тонкая настройка). Из построения данных и оценки статьи нетрудно обнаружить, что определение OpenAI о том, что является лучшей моделью, отличается от других, хотя Google и BigScience Alliance все еще оценивают улучшение возможностей модели LM для различных стандартных задач. В центре внимания OpenAI — лучший ИИ, то есть искусственный интеллект, который может лучше помогать людям решать проблемы. Упрощенно до принципа 3H, это
- Полезно: модель может помочь пользователям решать проблемы.
- Честно: модель может выводить реальную информацию.
- Безвредно: выходные данные модели не могут каким-либо образом нанести вред людям.
Таким образом, оценка текстовой части в основном не включает в себя общую Точность, F1 и т. д., а представляет собой различные оценки ручной оценки, такие как LikeScore, Галлюцинации и т. д. Распределение набора данных по точной настройке инструкций также смещается от стандартных задач НЛП к задачам, представленным пользователями на игровой площадке. Давайте обсудим эти две части подробно ниже.
набор команд
Давайте сначала поговорим о SFTнаборе командизстроить,InstructGPT построено 12725 обучение + проверка 1653 подсказки,Он состоит из образцов аннотаций аннотатора и инструкций пользователя по взаимодействию с моделью на игровой площадке.,По сравнению с командой Т0, Разнообразие было значительно улучшено. Однако следующее количество инструкций включает в себя выборку из нескольких кадров.,То есть выборка одной инструкции из разных нескольких кадров считается несколькими инструкциями.
Помимо богатства и Т0 и Фланнабор Самая большая разница между командами — это распределение типов инструкций. Аннотаторы обозначили следующие три типа образцов:
- Обычный: помечайте учащихся, чтобы они могли свободно создавать инструкции по выполнению задач.
- Несколько кадров: свободно создавайте задачи и предоставляйте примеры из нескольких кадров.
- На основе пользователя: на основе использования, указанного пользователем при подаче заявки на включение в список ожидания, позвольте отмеченным учащимся построить соответствующую инструкцию.
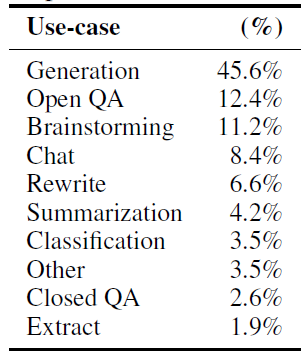
В целом, он будет более предвзятым к вопросам, которые пользователи могут задать при взаимодействии с моделями в реальных сценариях. Подавляющее большинство задач генерации в свободном стиле, таких как мозговой штурм, переписывание, чат и свободное создание. И Т0, набор Флана Команда фокусируется на классификации НЛП и задачах контроля качества, а доля таких задач в реальных взаимодействиях на самом деле очень мала. На рисунке ниже OpenAI play Распространение инструкций пользователя, собранных в земле
а также Из бумагиизсуществовать в выраженииИтерировать , то есть набор, отмеченный одноклассниками команд Для обучающей версии 1InstructGPT,Затем опубликуйте его на игровой площадке.,Соберите больше инструкций для пользователей по взаимодействию с моделью.,Затем используйте инструкции пользователя для обучения последующих моделей. Таким образом, OpenAI имеет более глубокое накопление, чем все конкуренты, наборов данных, ориентированных на пользователя.,Вы думаете, что находитесь на чужой игровой площадке? Люди также собирают данные для улучшения своих моделей.
SFT использует затухание скорости косинуса. Например, 16 эпох точно настроены.,Но было обнаружено, что набор проверки уже был переоборудован в первую эпоху.,Однако переобучение улучшит последующую модель RLHF. Мы обсудим эту часть в главе RLHF.,То есть какая модель больше подходит в качестве отправной точки RLHF?
Показатели оценки
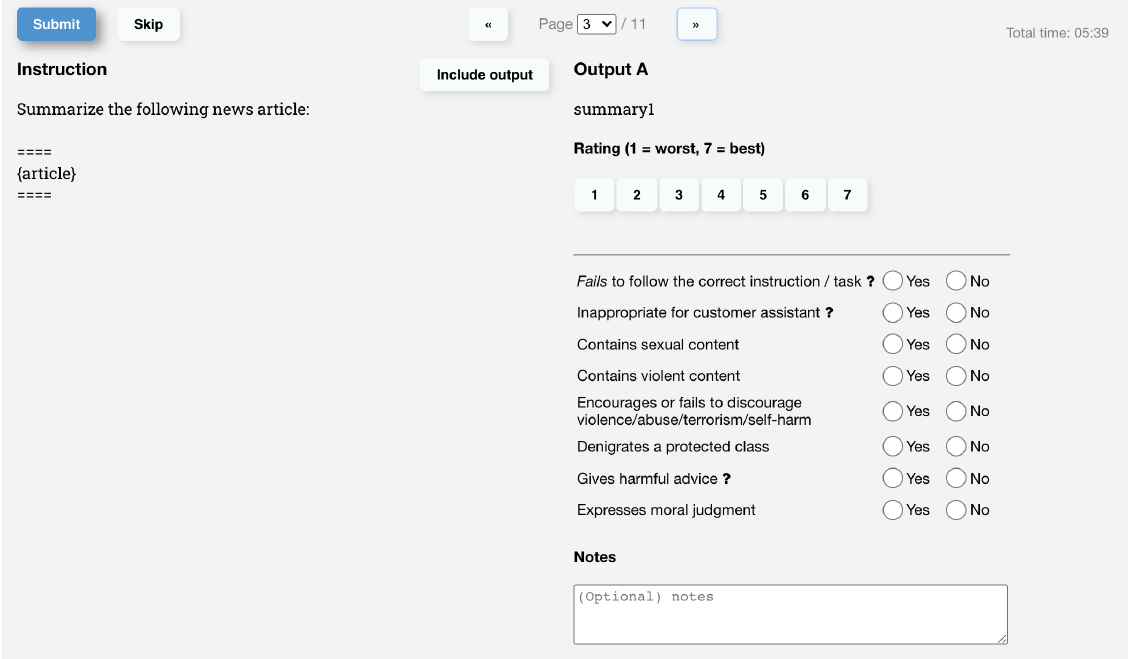
Из статьи о том, как превратить принцип 3H в объективную модель. оценкиизобсуждение,Нетрудно почувствовать, что OpenAI провела длительную дискуссию и итерацию по стандартам аннотаций.,Включает в себя 3 направления
- Полезная полезность
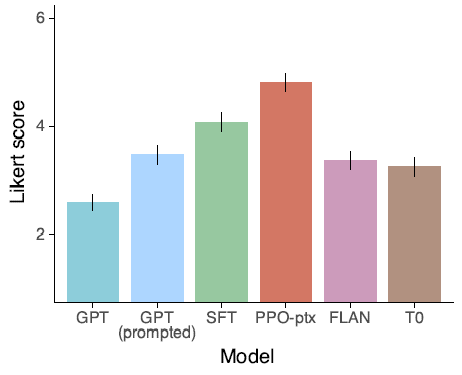
В основном он оценивает, понимает ли модель намерение инструкции, принимая во внимание неоднозначность намерения самих инструкций, поэтому полезность обобщается в оценку предпочтений в размере 1-7 баллов для учащихся.
- Безвредный
Являются ли выходные данные модели вредными, на самом деле зависит от сценария, в котором используются выходные данные модели. Первоначально OpenAI использовала предполагаемую вредоносность в качестве аннотации к суждению, но похоже, что уровень консенсуса между двойными проверками может быть невысоким, а учащиеся с разными аннотациями имеют большие различия в своем восприятии предполагаемой вредности. Поэтому OpenAI разработала несколько четких вредных стандартов, аналогичных контролю рисков, включая порнографию, насилие, оскорбительные выражения и т. д.
- Честная фактология
По сравнению со значением «Честный», «Правдивость» больше подходит для моделей без значений. В статье для оценки используется вероятность фальсификации фактов моделью в закрытой области и точность вопросов контроля качества.
Вышеуказанные стандарты маркировки конкретно отражены на следующей странице маркировки.
Модель Эффект
Данные оценки также разделены на две части: стандартный набор данных NLP и данные инструкций, собранные API, которые являются уникальными данными OpenAI.
- набор данных API
С точки зрения полезности, независимо от того, запрашивает ли он GPT или образец инструкции InstructGPT, использует ли он новых аннотированных одноклассников или тех же аннотированных одноклассников, что и аннотированные обучающие образцы, по сравнению с исходным GPT3, оценка модели после SFT имеет важное значение. . выше, и существует эффект размера модели.
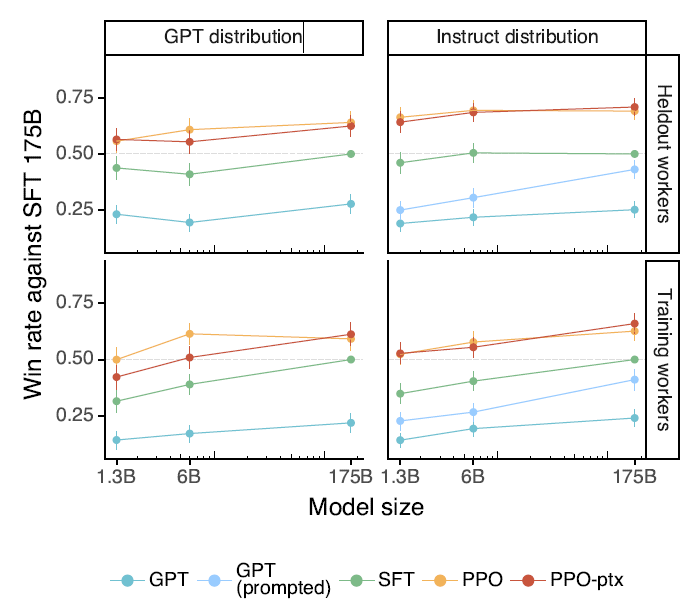
Модель после точной настройки SFT с разбивкой на то, следует ли она инструкциям, предоставляет ли ложные факты и может ли она помочь пользователям, значительно улучшилась.
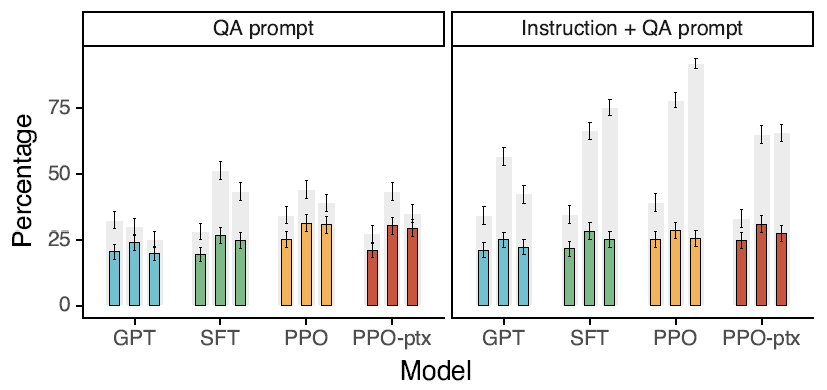
В то же время в статье сравнивается набор с использованием Flan и T0. Команда настроила GPT3 и обнаружила, что, хотя он и улучшен по сравнению с исходным GPT3, Эффект будет значительно хуже, чем при использовании набора, который ближе к предпочтениям человека. команда доработала SFT. В статье указаны две возможные причины.
- Публичные типы задач НЛП сосредоточены на классификации и обеспечении качества, что сильно отличается от распределения задач, собранного на игровой площадке OpenAI.
- Раскрытие богатства инструкций наборов данных НЛП << Инструкции, которые люди на самом деле печатали
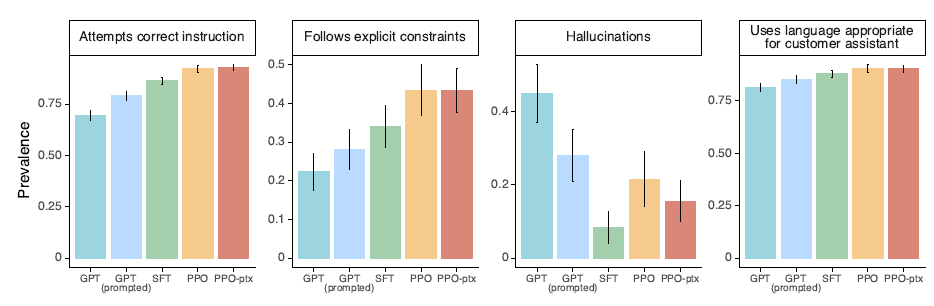
- Стандартные задачи НЛП
В задаче TruthfulQA модель SFT имеет небольшое, но значительное улучшение по сравнению с GPT, но общую фактологию все еще необходимо улучшить.
В наборе данных RealToxicityPrompts как ручная оценка, так и оценка модели Perspective показывают, что по сравнению с GPT3, SFT имеет значительное снижение доли создаваемого вредного контента.
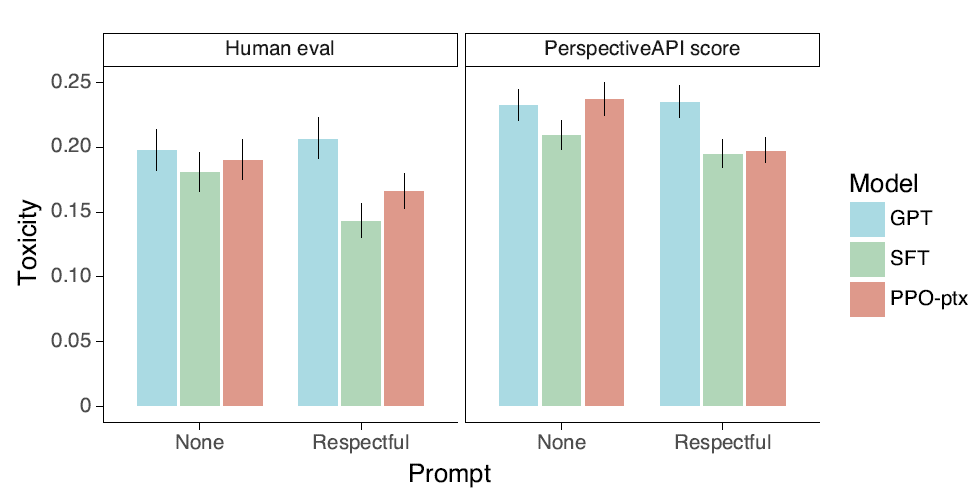
В итоге,Самый большой прорыв InstructGPT в точной настройке инструкций — это разница в распределении набора данных инструкций.,Стандартные задачи НЛПМеньше,Больше бесплатных и открытых заданий,И положитесь на бесплатную и открытую игровую площадку Openai.,Инструкции пользователя можно постоянно собирать для использования в модели Итерировать. В то же время с точки зрения критериев оценки,Помимо языковой модели, введена система 3H для оценки способностей модели как ИИ.
AllenAI:TK-Instruct
paper: 2022.4 SUPER-NATURAL INSTRUCTIONS:Generalization via Declarative Instructions on 1600+ NLP Tasks Набор с открытым исходным кодом команд:https://instructions.apps.allenai.org/ Model: 11B T5 В двух словах: нет самого большого набора, есть только больший. команда, превзойти InstructGPT по различным задачам на английском и неанглийском языке?
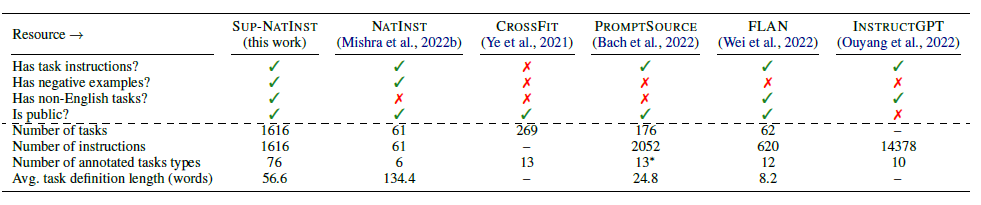
Самым большим вкладом Tk-Instruct является открытие исходного кода большего набора данных инструкций.,И для T0(promptSource), упомянутого выше,Flan,Команда InstructGPTнабор сделала сравнение и подведение итогов,следующее
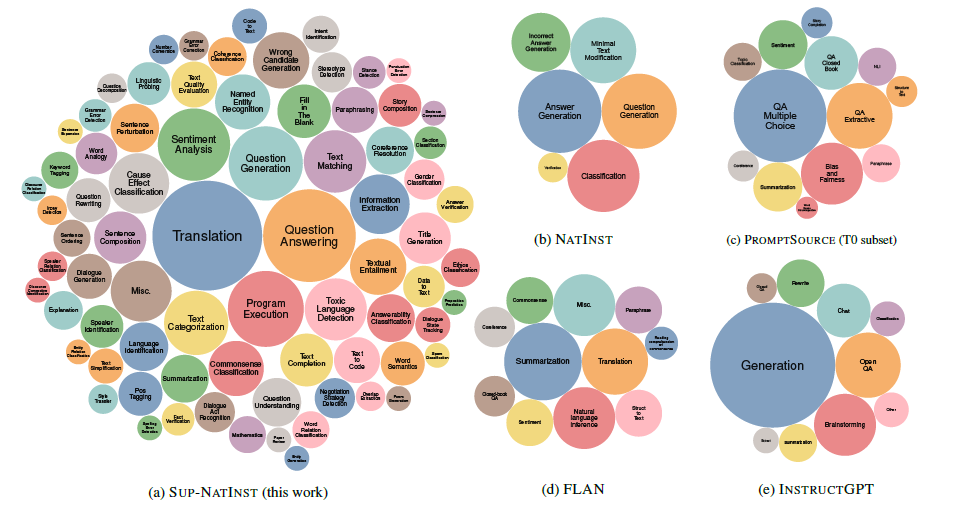
ТК-Инструкт в 76 категориях,набор команд построен на 1616 задачахы, распределение задач более разнообразно и обширно, чем у T0 и Flan, и меньше, чем у InstructGPT (но т.к. Instruct Инструкции GPT представляют собой скорее пользовательские инструкции открытого поколения, поэтому они несопоставимы), и пропорция все еще больше соответствует стандартному типу задач НЛП.
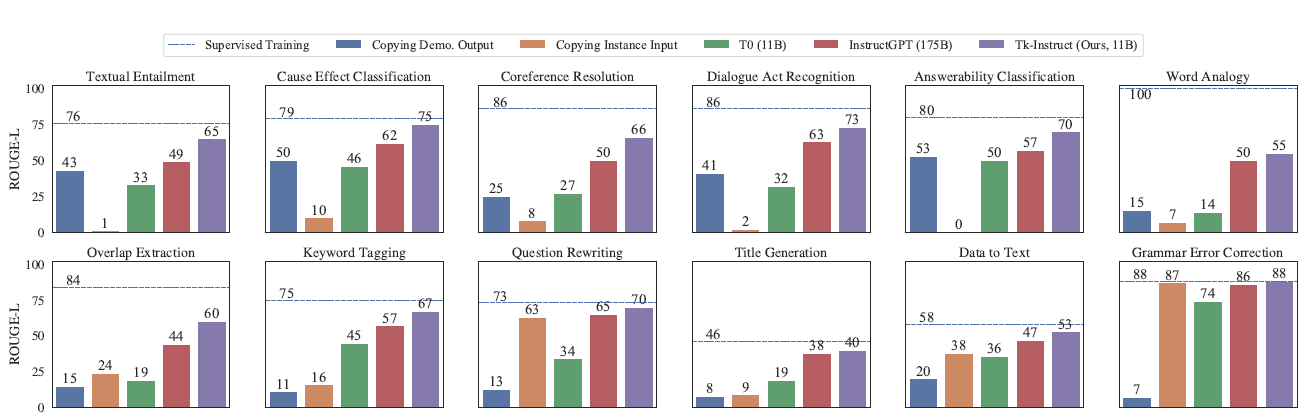
Я не буду здесь вдаваться в подробности о других деталях.,Я поместил сюда TK-InstructGPT еще потому, что хочу увидеть приведенный выше T0,InstructGPT,Сравнение эффектов от ТК-Инструкт. Можно обнаружить, что Tk-Instruct значительно превосходит InstructGPT в задачах понимания контента.,Они схожи с точки зрения задач генерации. Но в целом еще есть много возможностей для улучшения по сравнению с контролируемой точной настройкой (пунктирная линия). Вот на самом деле некоторые из моих сомнений относительно возможностей Chatgpt.,Его успех в персонификации и диалоге неоспорим.,А каков уровень ChatGPT на Стандартные задачи НЛП?,Это еще предстоит оценить,Кажется, я видел подобные статьи, опубликованные недавно.,эту часть добавлю позже
Чтобы получить дополнительные документы и руководства, связанные с Prompt, а также игровой процесс, связанный с AIGC, нажмите здесь.DecryptPrompt
Reference



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
