Расшифровка подсказки Серия 19. LLM Применение Агента в области анализа данных: Data-Copilot & InsightPilot
в предыдущем LLM Agent+DB из главы I уже говорилось о том, как использовать большие модели для доступа к базе данных и получения данных.,этотодна глава яих Поговорим о крупных модельных агентах в области анализа данных.изприложение。Анализ данных в основном относится к после получения данных.изОчистка данных,Обработка данных,Моделирование данных,Анализ данныхивизуализация данныхизшаг。может быть частои Работа с данными,Тем не менее, это не слишком сложно слишком Способность анализа данных и студенты обеспечивают ежедневную работу и поддержку,видел много BI Платформы пробуют аналогичные решения. Здесь мы говорим о двух статьях: Data-Copilot и InsightPilot, В основном относятся к некоторым интересным идеям ~
Анализ данных: Data-Copilot
paper: Data-Copilot: Bridging Billions of Data and Humans with Autonomous Workflow github: https://github.com/zwq2018/Data-Copilot
Во-первых, давайте представим расширенную структуру анализа данных, предложенную Чжэцзянским университетом.,поддерживатьРазличные типы финансовых данных: запрос, Обработка данных,Простое моделирование,ивизуализация данных。Data-copilot Если взять в качестве примера анализ данных в финансовой сфере, он предоставляет структуру анализа данных, которую можно легко расширить и создать на основе существующих данных.
Вся конструкция разделена на две части,На основе большой модели APIиНа основе ограниченного API для планирования и выполнения задач llm.。На самом деле, это совсем не сложно.,Несколько основных элементов задач анализа данных:
- Что анализировать: Вопрос из сущности,запас? Связь? Управляющий фондом?
- Какой период анализировать: данные охвата, первый квартал? В этом году?
- Какой индикатор использовать: доходность акций? Процентные ставки по облигациям? Чистая стоимость фонда?
- Как анализировать: сравнение доходов? Цены растут или падают? Рейтинг?
- Как вывести: сюжет? лист? текст?
Генерация API
В части проектирования фактически используются большие модели для построения более контекстной семантики. API заявление о вызове и API извходитьвыход。этот Некоторые коды не имеют открытого исходного кода......так что яих Только на основе бумагии Краткое введение в добавку для мозга。В основном разделены на следующие четырешаг
1. Генерируйте больше запросов пользователей
API Генерировать необходимо на основе того, какие вопросы будет задавать пользователь. Вопросы пользователя основаны на том, какие данные у вас есть. Таким образом, здесь используется описание данных, написание вручную и начальные вопросы, как указано выше, так что LLM Еще больше вопросов пользователей.
2. Создание операторов вызова API
Спросите всех пользователей, которые указали выше,Ввод моделей по одной,Используйте следующую подсказку Руководство по эксплуатации llm, чтобы выполнить задачу анализа данных.,Требуется несколько шагов,и каждыйшагпереписыватьсяизAPI Описание и Псевдокод "Interface1={Интерфейс Name: %s, Function description:%s, Input and Output:%s}"
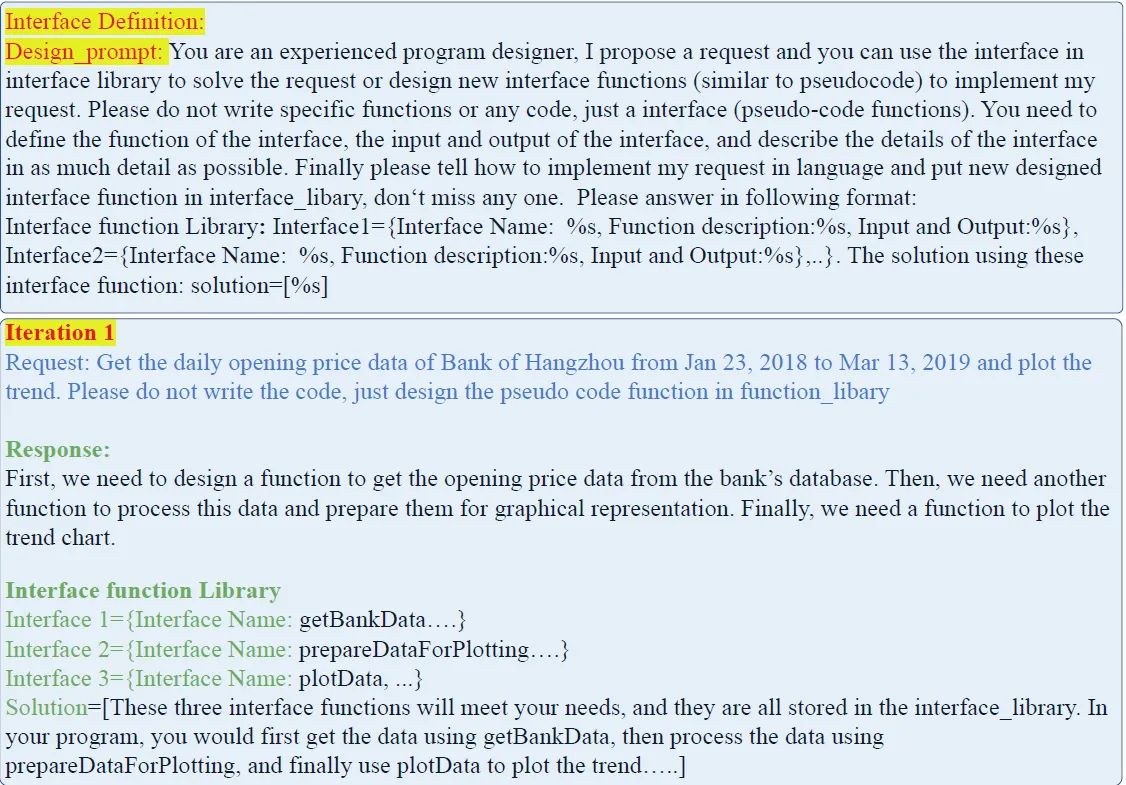
3. Объедините похожие вызовы API
Каждый раз, когда вы получаете новый из API function,городiужесоздано API function После сопряжения войдите в модель и используйте следующую команду, чтобы позволить большой модели оценить двух function Можно ли объединить аналогичные функции в новую API. Например, запрос GDP из API iQuery CPI из API объединить в запрос GDP_CPI из API. Но мое личное ощущение таково, что планирование занимает много времени. token Стоимость довольно высокая, поэтому может быть более подходящим online API из Создавайте онлайн, при сборке офлайн сначала на основе API из описания кластеризуется, а затем каждый cluster Может быть, выгоднее объединиться?

4. Сгенерируйте соответствующий код для каждого API.
Наконец, после слияния, API,генерация кода с использованием больших моделей. используется здесь pandas DataFrame как Обработка данные, рисование данных из формата взаимодействия данных. В этой статье вызов инструмента разделен на 5 Категория: сбор данных, Обработка данных,Объединить фрагменты,Моделирование и визуализация.

Прочитав весь процесс создания API, описанный выше, нетрудно обнаружить, что использование llm для автоматического создания API имеет следующие преимущества (хотя предполагается, что полная автоматизация будет затруднена...)
- Экономьте рабочую силу
- и APE Идея аналогична, команда «большая модель «уменьшение»» больше соответствует модели «уменьшение предпочтения», API Та же причина
- В настоящее время пакет находится в автономном режиме, если его можно оптимизировать как online из API generirovathiзgenererowathiз, может сделать API С динамической масштабируемостью
вызов API
API API изExecution для ответа на вопросы пользователя/выполнения задач пользователя. Поток задач в этом разделе также разделен на несколько этапов:
Распознавание намерений
Первый шаг – Распознание намерений, это вообще-то интегрировано в поиск query Несколько функций предварительной обработки:
- Распознавание намерений используется для сужения круга проблемы и улучшения следующих API точность вызова
- Модуль своевременности основан на сегодняшней дате и вопросах пользователей, а вопросы соответствуют конкретным временным диапазонам (включая стандартизацию временных диапазонов).
- Модуль сущностей используется для обнаружения проблем и основных сущностей.
- Выходная форма оценивается как рисунок.、Табличный или текстовый вывод
В статье перечисленные выше модули объединены в один, основанный на few-shot Задача перезаписи большой модели перепишет вопрос пользователя в новый с четким интервалом времени, а тип задачи будет более понятным из текста, а не столько Распознавание намерения, вообще-то больше похоже query переписать. следующее
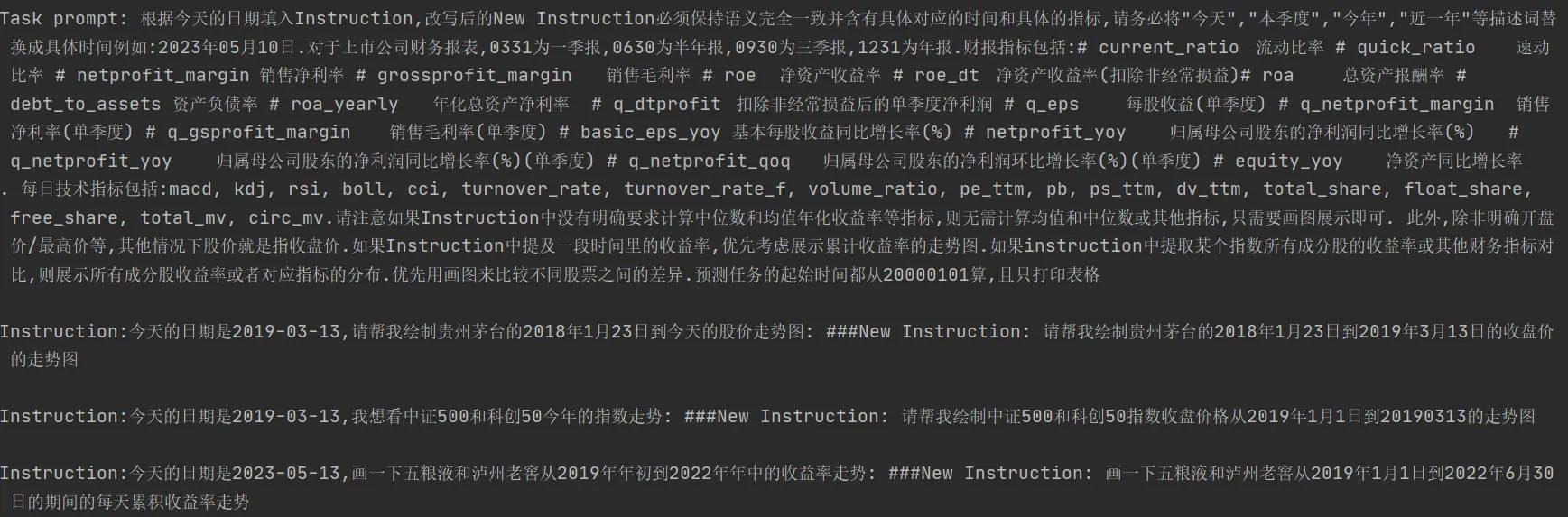
Лично я считаю, что это намерение вообще не обязательно должно основываться на большой модели, или большая модель может быть использована для создания выборки, а затем преобразована в маленькую модель. и все Распознание Модуль намерений можно разделить на несколько независимых и более детальных модулей. В финансовой сфере его можно, по крайней мере, разделить на большие категории объектов активов, извлечение и согласование, выявление различных проблемных намерений для разных типов активов и независимую своевременность. Модуль дискриминации. Модуль намерений напрямую влияет на следующее ипланирование Таким образом, точность и успешность выполнения должны быть достаточно высокими.
планирование поведения
планирование Модуль поведения состоит из двух шагов. Первый шаг — дизассемблирование задачи. query Он будет использоваться в качестве входных данных для модуля дизассемблирования задачи. Также на основе few-shot из Командная задача большой модели,Разделите задачу на несколько этапов выполнения.,Каждый шаг включает тип задачи.
Здесь автор определяет stock_task、fund_task、economic_task, visualization_task、financial_task этот 5 вид задач, демонтаж задач аналогичен COT Разделите задачу на несколько этапов выполнения, но, по сути, для уменьшения APIизвызовобъем。Инструкции следующие:

На основе вышеуказанного модуля выбора задач каждый шаг по типу задачи,Например, stock_task, будут различия few-shot prompt Чтобы использовать модель для этого типа задач, API вызов, включая каждый шаг вызова API, ввод, вывод и возвращаемое значение. планирование Некоторые общие инструкции по поведению заключаются в следующем:
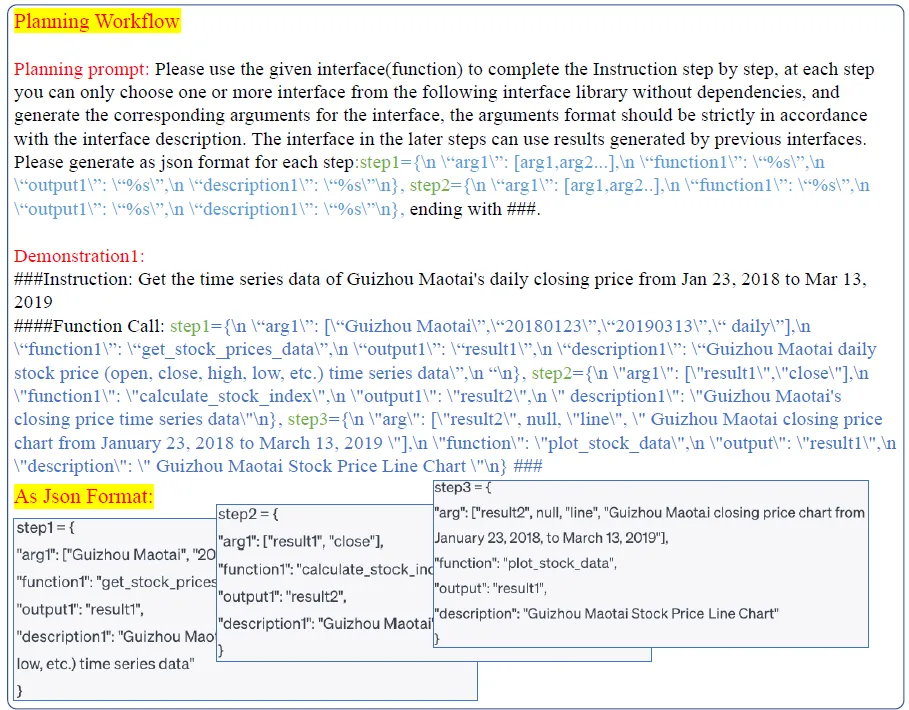
планирование Интересным моментом в поведении является то, что API, встроенный в статью, содержит три различных метода выполнения: последовательную операцию с одним входом и одним выходом, параллельную операцию для получения нескольких индикаторных данных для ценной бумаги и циклическую операцию, аналогичную map к несколькимвходитьвыполнить то же самоеиздействовать。Ниже приводитсяData-CopilotизDemo
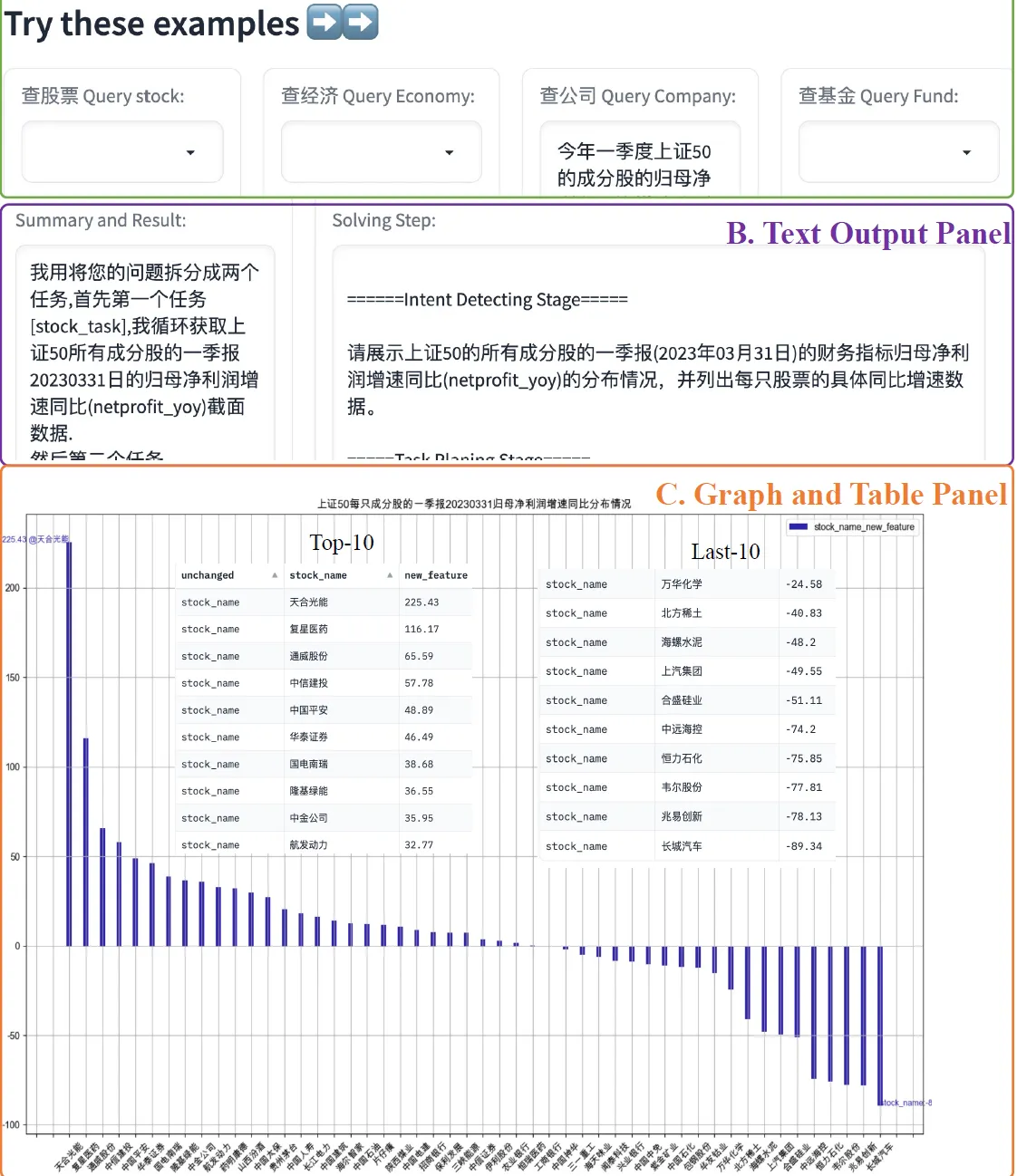
Анализ данных: InsightPilot
paper:Demonstration of InsightPilot: An LLM-Empowered Automated Data Exploration System Связанный paper:QuickInsights: Quick and Automatic Discovery of Insights from Multi-Dimensional Data Связанный paper:MetaInsight: Automatic Discovery of Structured Knowledge for Exploratory Data Analysis Связанный paper:XInsight: eXplainable Data Analysis Through The Lens of Causality https://www.msra.cn/zh-cn/news/features/exploratory-data-analysis
InsightPilot — это не столько статья бумага, больше похожая на Microsoft BI из Информационный документ о продукте. Основной продукт EDA Анализ данных,ивышеиз Data-copilot В совокупности его можно рассматривать как охватывающее самую базовую работу по анализу данных. Дайте мне пример данныеиз каштана, первый в UG Когда работает отдел роста пользователей, каждый раз APP Количество активных пользователей сократилось. Команда анализа данных получила задание проанализировать данные активных пользователей, чтобы выяснить, почему пользователи были потеряны, потому что их отобрали конкурирующие продукты. Это из-за каких-то новых функций, которые пользователи не использовали? не так, как недавно? Или это было предыдущее? Качество привлеченных по активности пользователей невысокое, а удержание низкое, что обусловлено отсутствием пользовательского опыта. данных,Лучше сформулировать следующий шаг, чтобы удержать пользователей потокового вещания.,Конкретные планы по активации тихих пользователей.
Так как же найти выбросы в данных? Основная операция — разделить и сравнить данные в разных измерениях. Например, разделите активных пользователей на мужчин и женщин.,старый и молодой,разные города,Различные модели,Источник канала,Различные предпочтения чтения и другие аспекты,Понаблюдайте, не снизилась ли активность пользователей в разных подгруппах.,Коэффициенты снижения одинаковы?,Есть ли определенный аспект, в котором потеря групп пользователей является наиболее значительной? Это разделение измерений может быть параллельным измерениям.,Это также может быть детализированное измерение.,Метод сравнения может представлять собой сравнение тенденций изменений первого порядка.,Это также может быть второй порядок, такой как волатильность.тенденцияиз Сравнить и т. д.
Решение Microsoft по реализации фактически заключается в использовании LLM Microsoft разработала ранее и применялась к BI из Три модели Анализ Инструменты обработки данных объединены последовательно, это три типа анализа. Инструменты обработки данных QuickInsight,Мета Инсайт и XInsight. Позвольте мне сначала кратко представить три инструмента,Давайте посмотрим, как большие модели объединяют и связывают инструменты анализа данных.
Информация
QuickInsight
QuickInisght Это самый ранний и базовый инструмент анализа данных. Он позволяет быстро обнаружить различия в многомерных данных. pattern。этоиз Блок данных Insights состоит из трех элементов.subject ≔ {𝑠𝑢𝑏𝑠𝑝𝑎𝑐𝑒(𝑠) пространство данных, 𝑏𝑟𝑒𝑎𝑘𝑑𝑜𝑤𝑛 разделение размеров, 𝑚𝑒𝑎𝑠𝑢𝑟𝑒(𝑠)индикатор наблюдения}, Ниже приводится {Los Анхелес, Месяц, Продажи} производит из Анализ данных
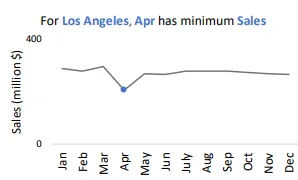
QuickInsight сначала рассчитает разные показатели в соответствии с разными измерениями, чтобы получить несколько наборов данных. Аналитическая часть запланирована 12 вид разницыиз Методы анализа данных,Например, выбросы,точка мутации,тенденция,Сезонный,Связанный секс и многое другое. Каждый тип понимания будет оцениваться комплексно на основе значимости и вклада.,На вершине рейтинга должны находиться одномерные данные с наиболее значительными изменениями.,И это оказывает большее влияние на общую ситуацию.
MetaInsight
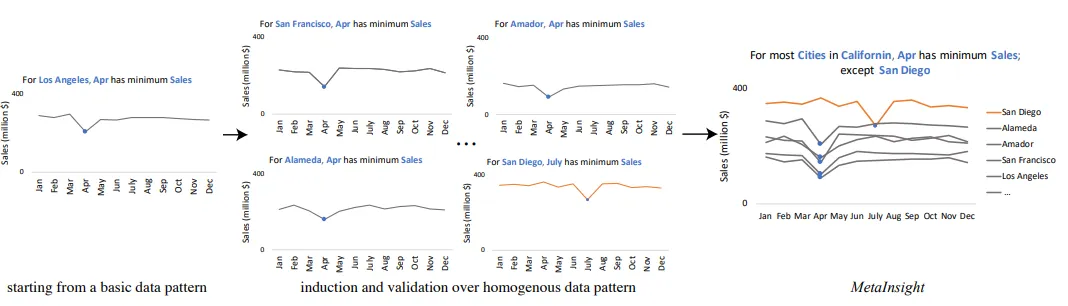
Аналитика QuickInsight в основном основана на одном блоке данных аналитики.,MetaInsight может агрегировать и коррелировать несколько единиц аналитических данных.,Вывод более сложный,передовойиз Анализ данные. Проще говоря, в приведенном выше тройке Анализ Основываясь на данных, найдите разные изподъязы и измерьте, найдите похожий Анализ. данныхизтриплет,и выполнить комбинированный анализ. Продолжаем приведенные выше данные о продажах в Лос-Анджелесе от Insights.,Когда я расширю подпространство на другие города из данных о продажах,MetaInsight выполнит следующий корреляционный анализ.
XInsight
Вышеупомянутые QuickInsight и MetaInsight все еще относятся к сфере анализа сексуальных данных.,XInsight фокусируется на причинно-следственном анализе,Его также можно рассматривать как очень популярное направление причинно-следственного вывода за последние два года. То есть я не только хочу знать, что на моем телефоне одновременно есть пользователи приложений Kuaishou и Douyin.,Используйте Douyin в течение более короткого времени,Я все еще хочу знать, не отнимает ли у пользователей время приложение Kuaishou.,Или это Некоторые группы пользователей сами принадлежат к группе, которая смотрит по сторонам и не имеет фиксированных предпочтений. Но в реальном мире сложно найти причинно-следственные выводы, полностью соответствующие гипотезе.,Потому что хаха параллельного мира не существует,Поэтому можно использовать только некоторые управляющие переменные.,иматематическое моделированиеизсхема для аппроксимации причинно-следственных сценариев。заинтересованныйиз Студенты могут просмотретьПричинно-следственный вывод из весны
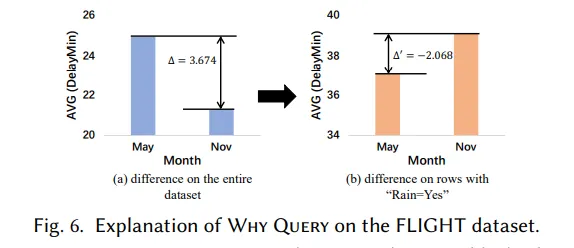
В следующих случаях,Также разбито по месяцам.,Время задержки рейса как индикатор. При анализе всех данных обнаруживается, что время задержки в мае намного больше, чем в ноябре.,Но когда контрольной переменной является, будет ли в этот день дождь,Вы обнаружите, что в дождливые дни задержки рейсов в мае меньше, чем в ноябре.,Таким образом, более высокие уровни осадков в мае могут объяснить более высокие задержки рейсов в мае.
LLM Pipeline
InsightPilot основан на трех вышеупомянутых механизмах анализа данных.,Использование больших моделей для конкатенации,Для удовлетворения потребностей пользователей из Анализ данных. Все еще та же точка зрения,Комбинация LLM+Агент,Что действительно важно, так это агент,LLM отвечает только за выбор наиболее подходящего агента на основе контекстной семантики.,И решите следующий шаг на основе содержимого, возвращенного агентом.,Грубо говоря, это просто тусовка.,Конечно, в конечном итоге LLM также необходим для предоставления отчетов по анализу данных.
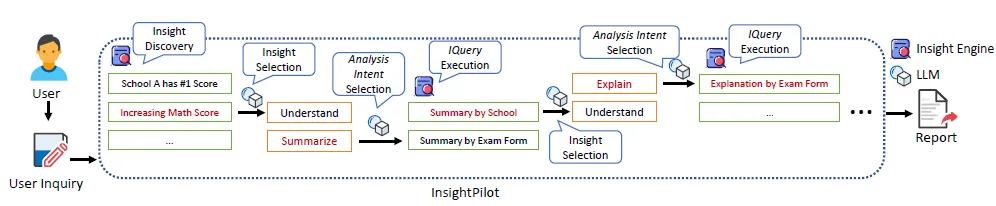
этот Ли Да Модель в основном отвечает за:инициализация->Понимание выбора->выбор намерения->Понимание выбора->выбор намерения....->Отчетгенерировать
- Задача инициализации: сначала вызов QuickInsightгенерировать набор данных изBasic Insights.,Затем используйте подсказку,Пусть LLM возвращает несколько элементов в зависимости от агента данные, пользовательский запрос и набор данных из описания (аналогично БД Схема), чтобы выбрать результат анализа для дальнейшего анализа.
- Задача выбора намерения: как проанализировать приведенные выше выводы,В этом есть три намерения,Соответствует вышеуказанным 3 агентам соответственно,Понять-QuickInsight, Суммировать-MetaInsight, Объяснить-XInsight. Большие модели будут основаны на запросах пользователей.,Вышеуказанный контент из Insight,Давайте выберем Агента для продолжения анализа.
- Выбор Insight: новое поколение нескольких документов на основе агента данных,Если LLM определит, что не может ответить на вопрос пользователя,затем будет выбрана инсайт для продолжения анализа.
- Отчет думать: Последний на основе TopK Анализ генерировать отчеты для ответов на вопросы пользователей
Оставьте раздел Top-K Insights из раздела в итоговом фильтре.,В документе также добавлена ссылка на рейтинг.,Говорят, что он отсортирован, но это зависит от реализации.,Это больше похоже на дедупликацию + фильтрацию по сходству + рассеяние.
- Прежде всего, разберитесь в отношениях между ними.,Если инсайт A содержит контент инсайта B,Удалить статистику Б
- Далее следует фильтрация сходства,Будет фильтровать и вопросы пользователей, имеющие отношение к более низкой информации. Но на самом деле есть некоторые сомнения в этом,Поскольку информация существует, детализация по измерениям и многомерное сравнение,Похоже, сходство не подходит в качестве критерия фильтрации.
- Наконец, стратегия расставания,Это делается для того, чтобы уменьшить сходство между идеями.,Улучшите богатство конечного контента. В этой стратегии используется следующая приблизительная оценка второго порядка:,где |I| — показатель полезности каждого понимания,Оценка пересечения представляет собой минимальное значение полезности двух идей * перекрытия идей.,Общая стратегия заключается в улучшении общего объема информации, содержащейся в аналитике TopK.
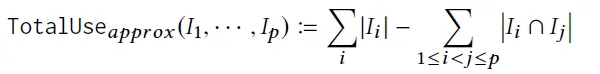
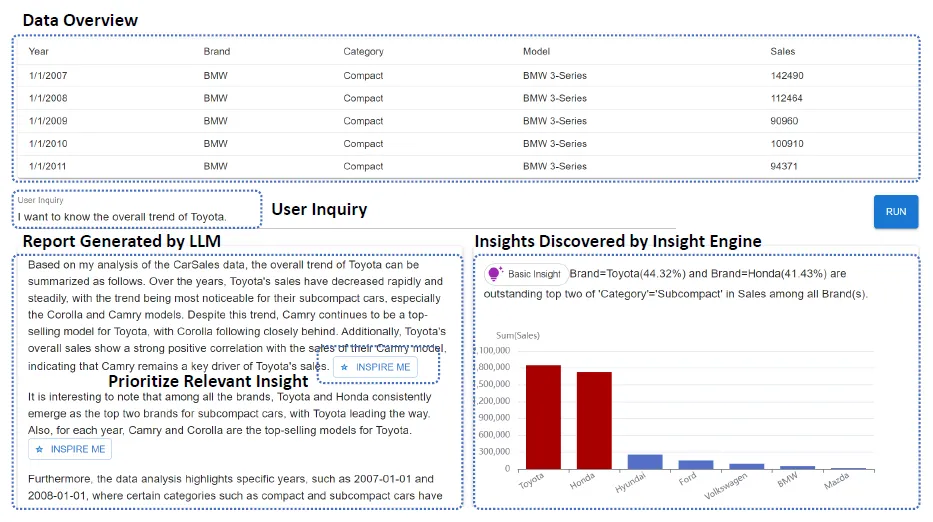
Наконец, InsightPilot сообщает об эффекте снижения,И помогайте пользователям анализировать каждый абзац содержания отчета.,Выполнить проверку данных,Когда вы нажмете на первый абзац Inspire Me, появится диаграмма данных соответствующего абзаца «Связанныйиз» (рисунок справа). Честно говоря, я смотрел только эту демку,Эффект несколько потрясающий,Но что действительно мощно, так это три механизма понимания, описанные выше.,LLM – это просто портье и копирайтер.
Если вы хотите увидеть более полный обзор большой модели, данные и структуру для точной настройки и предварительного обучения, а также приложение AIGC, перейдите на Github. >> DecryPrompt
Я участвую в третьем этапе специального тренировочного лагеря Tencent Technology Creation 2023 с эссе, получившими приз, и сформирую команду, которая разделит приз!



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
