Расшифровка подсказки Серия 14. LLM Дизайн приложения для поиска агентов: WebGPT & WebGLM & WebCPM
В первых двух главах мы представили решения для вызова инструментов, основанные на точной настройке и подсказках соответственно. Суть заключается в том, как взаимодействовать между большими моделями и инструментами, включая создание операторов вызова инструментов и обработку запросов на вызов инструментов. Однако в практических приложениях, если вы хотите разработать агента LLM, который можно реализовать, требуется более комплексный и общий проект системы. В этой главе мы возьмем инструмент поиска в качестве примера, чтобы познакомить агента LLM с тем, как лучше взаимодействовать с поисковой системой.
План поискового агента
Зачем нужен общий подход?,Непосредственно вызовите интерфейс поиска, чтобы получитьTop1Ты не можешь вернуться??Если это правдаSimple&Naive,New BingРазве не было бы легко воспроизвести?->.->
Давайте сначала рассмотрим пример,Технология создания сверхпроводников при комнатной температуре, недавно ставшая популярной в Интернете,Если вы хотите ответитьКакие отрасли вырастут в LK99?,Вы получите следующие ответы на поискслучай
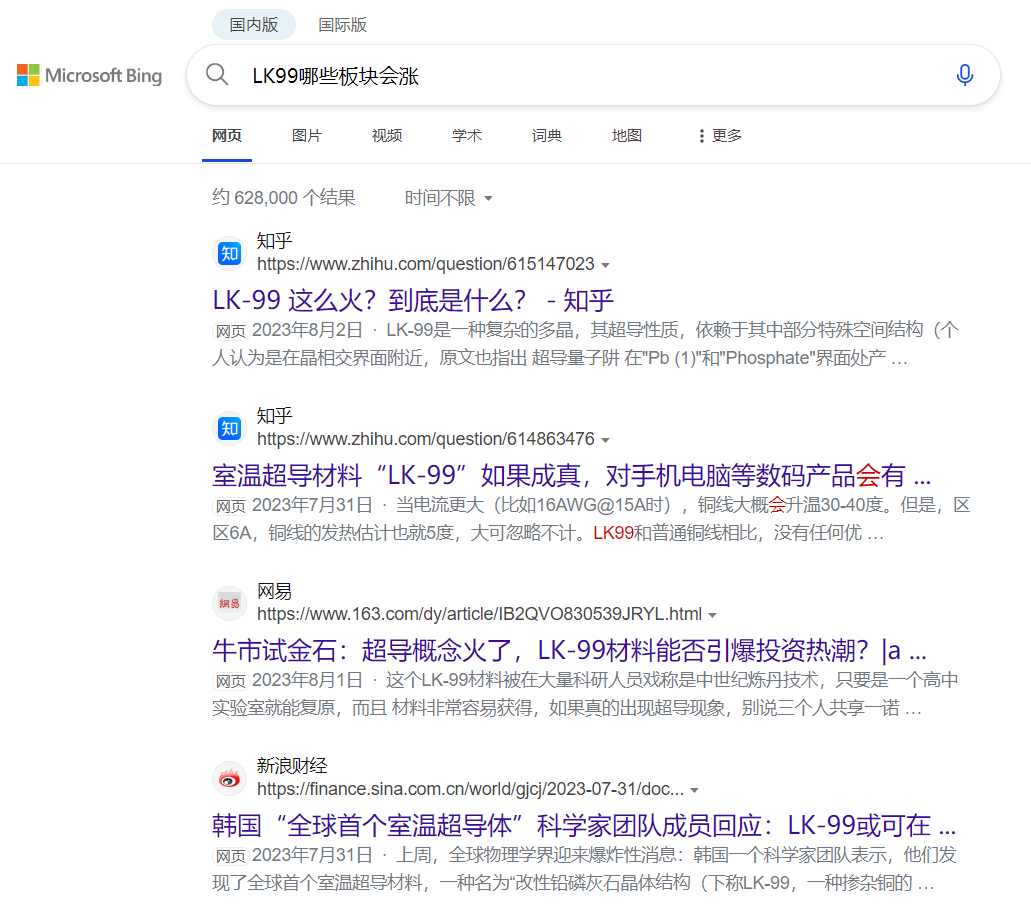
Из приведенных выше результатов поиска нетрудно обнаружить, что ответ Top1 не отвечает на вопрос. Несколько возможных вопросов при взаимодействии с поисковой системой:
- Запрос: запрос пользователя не подходит для поисковой системы, в результате чего не выполняется поиск действительного контента, или проблему необходимо решить путем нескольких раундов поиска с использованием цепочки размышлений, аналогичной самозадаче;
- Рейтинг: присмотритесь к поисковой оболочке langchain.,Вы обнаружите, что по умолчанию для возврата используется только первая часть поиска.,Но помимо традиционных энциклопедических вопросов,Этот тип проблемы связан с оптимизацией,Top1 часто является лучшим ответом. Но другие сцены,Например, текущая проблема,Третий контент явно более подходит. Современные традиционные поисковые системы не предназначены для использования в крупных моделях.,Поэтому необходимо использовать некоторые модули оптимизации сортировки.,Например, бумага REPLUG.
- Фрагмент: заголовок веб-страницы Bing по умолчанию отображает текстовую сводку длиной около 150 слов на основе позиционирования запроса, что также является результатом веб-страницы, используемым такими платформами, как langchain. Однако нетрудно обнаружить, что если фрагмент слишком короткий или неточное позиционирование, в нем не будет эффективной информации.
Чтобы решить три основные проблемы, упомянутые выше, на основе трех статей: WebGPT, WebGLM и WebCPM, мы подробно опишем, как более эффективно взаимодействовать с поисковыми системами, чтобы решить длинный текстовый открытый вопрос и ответить на проблему LFQA. Взаимодействие с поисковыми системами в основном разделено на следующие четыре модуля:
- Поиск. Создайте запрос поискового запроса или перепишите запрос на основе результатов, чтобы запросить API поиска. Аналогично «Мысли в самозадаче», за исключением того, что в самозадаче особое внимание уделяется устранению проблем, а поиск здесь также имеет переписывание запроса, отслеживание и другие функции.
- Извлечение: из большого фрагмента контента, полученного в результате поиска, найдите подтверждающие факты, которые могут ответить на запрос, и выполните извлекающее и генеративное обобщение. Подобно поведению LookUp в React, но более сложному, чем простое позиционирование текста.
- Синтез: собрать несколько материалов, ввести модель для вывода и получить ответ.
- Действие: Для сценариев, требующих нескольких раундов взаимодействия с поисковой системой, необходимо спрогнозировать следующее поведение: продолжать ли поиск, извлекать сводки, останавливать поиск, собирать контент для рассуждения и т. д., что соответствует модулю планирования в LLM. Агент. Фактически, он обогащает действия в React/SelfAsk и добавляет больше вариантов поведения для взаимодействия с поисковыми системами, таких как продолжение просмотра, перелистывание страниц и т. д.
Хотя порядок публикации статейwebcpm>webglm>webgpt,Но учтите, что webcpm имеет в открытом доступе очень полные китайские данные, ха-ха.,Как вручную! Я представлю это подробно, используя webcpm в качестве эталона.,Затем мы представим сходства и различия между webglm и webgpt соответственно.
webcpm
paper:WEBCPM: Interactive Web Search for Chinese Long-form Question Answering github:https://github.com/thunlp/WebCPM
WebCPM на самом деле является последней из этих трех статей, поэтому она объединяет некоторые решения webgpt и webglm. Был составлен общий план для завершения длинных текстовых открытых вопросов и ответов (LFQA) посредством нескольких раундов взаимодействия с поисковыми системами. API поиска, который он использует, — Bing. 23 аннотатора провели несколько раундов поиска, чтобы получить подтверждающие факты, необходимые для ответа на вопросы.
Проблема с webCPM связана с английским QA на Reddit, преобразованным в китайский. Baidu знает, что причина, по которой Reddit используется вместо Zhihu, заключается в том, что ответы последних двух часто хорошо обрабатываются, а хорошие ответы можно получить, выполняя поиск непосредственно в одном раунде, что снижает сложность взаимодействия в нескольких раундах поиска. Модель 10B CPM была доработана с использованием аннотированных вручную поисковых данных и дала хорошие результаты в задаче LFQA.
Общая структура WebCPM — это четыре упомянутых выше модуля. Давайте представим их отдельно ниже. Настоятельно рекомендуется читать его вместе с исходным кодом. Сама статья немного проста, ха-ха, и оставляет читателю много места для воображения.
Действие: планирование поведения
Первый — это планирование поведения, которое позволяет модели изучать связи поведения, возникающие в результате взаимодействия между людьми и поисковыми системами. Для проблем интерактивного поиска webcpm определяет следующие 10 вариантов поведения, включая поиск, загрузку страницы, ее скольжение и т. д. Тем не менее, я лично считаю, что если мы сосредоточимся только на решении длинных текстовых вопросов и ответов, прокрутка, загрузка страницы и другие операции в следующем поведении могут быть оптимизированы, поскольку перемещение контента можно фильтровать, введя модуль сортировки и вышеописанное. сводный модуль для фильтрации релевантных и нерелевантных материалов. Содержимое не обязательно должно быть реализовано посредством действия. Это может еще больше упростить пространство действий и улучшить эффект.
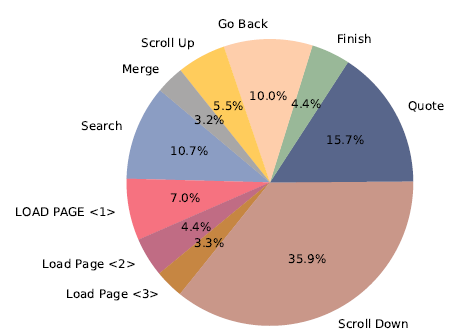
Моделирование последовательностей поведения абстрагируется как задача классификации текста. Преобразуйте текущий статус в текстовое представление и спрогнозируйте, какой из вышеперечисленных 10 категорий будет следующее действие. Описание текущего статуса включает в себя следующее
- Оригинальный вопрос: вопрос
- Текущий поисковый запрос: заголовок
- Сращивание исторической последовательности действий: last_few_actions, эксперимент по удалению доказал, что историческая последовательность действий является наиболее важной, ха-ха, так что, может быть, ее можно упростить до HMM?
- Объединение всего исторического сводного контента: цитаты
- Интерфейс поиска предыдущего шага: Past_view, текст заголовка и аннотация всего контента, отображаемого на предыдущей странице.
- Текущий интерфейс поиска: текст, текст, который отображает заголовки и аннотации всего контента на текущей странице.
- Оставшиеся шаги действия: action_left.
Ниже приведен код конструкции примера инструкции, который предназначен для объединения вышеуказанных состояний в качестве входных данных и использования следующего действия в качестве выходных данных.
def make_input(self, info_dict, type="action"):
context_ids = ""
def convert_nothing(info):
return "никто" if len(info) == 0 else info
context_ids += "Вопрос:\n" + info_dict["question"] + "\n"
context_ids += "Сводка:\n" + convert_nothing(info_dict["quotes"]) + "\n"
last_few_actions = ""
for past_action in info_dict["past_actions"]:
if past_action != []:
last_few_actions += past_action
context_ids += "Текущий поиск:\n" + convert_nothing(info_dict["title"]) + "\n"
context_ids += "Предыдущий интерфейс:\n" + convert_nothing(info_dict["past_view"]) + "\n"
context_ids += "Текущий интерфейс:\n" + convert_nothing(info_dict["text"]) + "\n"
context_ids += «Количество оставшихся шагов:» + str(info_dict["actions_left"]) + "\n"
if type == "action":
context_ids += «Необязательные действия:»
for idx, k in enumerate(self.action2idx):
context_ids += self.action2idx[k]
if idx != len(self.action2idx) - 1:
context_ids += ";"
context_ids += "\n"
context_ids += «Исторические операции:» + convert_nothing(last_few_actions) + "\n"
if type == "action":
context_ids += «Следующий шаг:»
elif type == "query":
context_ids += «Пожалуйста, создайте новый соответствующий запрос:»
elif type == "abstract":
context_ids += «Пожалуйста, извлеките содержимое, связанное с проблемой, из текущего содержимого интерфейса:»
next_action = info_dict["next_action"]
return context_ids, next_actionО тонкой настройке конкретной модели классификации сказать особо нечего. Однако здесь следует отметить, что исходный код фактически предоставляет два решения для реализации webcpm. Оба решения имеют открытый исходный код данных.
- Интерактивное решение:Модель, соответствующая текущему поведению,Какое поведение будет выполняться на каждом этапе, будет прогнозироваться моделью действий.,В то же время переписывается следующий запрос,Реферат и другие модули,Вы также получите приведенный выше результат всех предыдущих шагов выполнения.,Выполнение задач по созданию условного текста
- трубопроводное решение:Общая ссылка на поведение фиксируется по порядку:,перезапись запроса -> Все переписанные поисковые запросы будут получать контент Top-K. -> Извлечение аннотаций для каждой страницы -> Соберите все вместе, чтобы ответить на вопрос. поэтомуPipelineнаправлениеслучайне нуженActionМодель,При этом следующие абстрактные переписывания и других модулей,Он также будет упрощен до задач генерации текста, которые не зависят от вышеизложенного.
Это немного абстрактно. Давайте воспользуемся Query, чтобы переписать его, чтобы увидеть разницу между двумя вышеупомянутыми решениями. Предположим, пользователь спрашивает: Какой тип макета веб-страницы существует? Какая планировка обычно используется?
- Интерактивный: первый запрос переписывает запрос = тип макета веб-страницы, а затем выполняет поиск + сводку, чтобы получить сводный обзор макета веб-страницы. Второй запрос переписывает запрос = лучшие практики макета веб-страницы на основе существующего сводного содержимого, так что оба запроса переписываются. объединены. Содержание запроса может ответить на вышеуказанные вопросы.
- Конвейер: вначале вызывается модель перезаписи запросов для создания набора переписанных запросов, таких как типы макета веб-страницы, методы макета веб-страницы, режимы макета веб-страницы и преимущества макета веб-страницы. Затем вызываются все поисковые системы и все возвращаемые результаты интегрируются.
Хотя кажется, что Interactive может найти лучшее решение.,Но на самом деле выигрыш для очевидно последовательных поисковых задач лишь незначителен.,Полное отсутствие конвейерного режима выглядит более лаконично и элегантно. Из-за безусловной генерации моделей конвейеров,Чтобы каждый шаг мог обрабатываться одновременно,Легче приземлиться. И каждый модуль можно оптимизировать независимо,Можно отделить друг от друга。Поэтому мы представим следующие три модуля с трубопроводным решение представить
Поиск:запрос переписан
Модель перезаписи запроса — это модель генерации текста seq2seq. Фактически, по своей природе он похож на «Само-вопрос», который использует самоанализ для устранения проблем. Переписывание ядра должно решить две проблемы
- Decompose:Задача пользователя состоит из множества параллельных、Комбинация составного контента,Поэтому необходимо демонтировать проблему,Получите подзапрос. Например, пример в главе «Самостоятельный вопрос».,Пользователи спрашивали, каков объем торгов сектора с наибольшим ростом? Его нужно разбить на сектор с наибольшим ростом + объем торгов ХХ сектора.
- Rephrase:Сам вопрос пользователя не подходит для поисковых систем,Нужно переписать, чтобы было более кратко,Ключевые слова Больше поисковых запросов. Например, «Новый Bing от Microsoft онлайн, какие у вас впечатления?» можно переписать как «новое» взаимодействие пользователя с Bing.
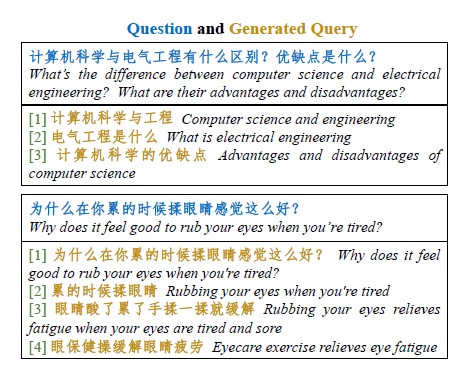
Ниже приведен эффект модели генерации запросов, полученной в результате тонкой настройки webcpm.,webcpm предоставляет эту часть тренироваться данных,Включает один запрос и несколько переписанных запросов.
Ретривер: извлечение сводки
Retriever отвечает за извлечение содержимого, связанного с запросом, из текста веб-страницы, что представляет собой проблему понимания прочитанного/извлечения сводки. Таким образом, вам не нужно полагаться на сводку фрагмента, предоставленную непосредственно API поиска. Вы можете определить длину извлечения в соответствии со своим сценарием и выбрать, следует ли извлекать весь абзац или комбинацию нескольких абзацев.
Чтобы уменьшить задержку вывода, webcpm реализует решение, аналогичное извлечению интервала через декодер. Декодер декодирует только первое и последнее слова абзаца, которые необходимо извлечь. Например
Запрос = Что такое круги на полях?
Content= Круг на полях относится к геометрическому узору, полученному в результате сглаживания посевов на пшеничных или других полях под действием какой-то неизвестной силы (большая часть кругов создана людьми). Это загадочное явление иногда называют «Формирование урожая». Появление кругов на полях породило множество мнений среди сторонников теории инопланетного существования.
Предположим, что первое предложение в абзаце должно быть извлечено
Fact=пшеницаПолевой круг(Crop Circle),Относится к полям пшеницы или другим полям.,через какую-то неведомую силу(Самые странные круги вызваны людьми)Геометрическая фигура, созданная путем сплющивания сельскохозяйственных культур.случай
则Модель的解码器输出的结果даНачальный персонаж: пшеница - Конечный персонаж: случай,Если первый и последние два символа могут соответствовать многотерминальному тексту,Затем возьмите самый длинный соответствующий абзац текста. Самолет,Было обнаружено, что пайплайн и интерактив имеют разные методы построения выборки в сводном разделе.,Только в следующем интерактивном примере построения используется указанный выше метод извлечения интервала.
abstract = "Начальный персонаж:" + self.tokenizer.decode(decoded_abstract[: num_start_end_tokens]) + "-Конечный символ:" + self.tokenizer.decode(decoded_abstract[-num_start_end_tokens: ])Синтез: агрегирование информации
Синтез отвечает за интеграцию множества фактов, полученных с помощью вышеуказанного поиска + Retriever, и их объединение, как указано выше. Благодаря аннотированным вручную ответам модель учится генерировать последовательные, плавные и длинные ответы на основе приведенного выше контента на основе нескольких частей. факты.
Чтобы решить проблему, заключающуюся в том, что сама модель будет собирать нерелевантную информацию во время процесса автоматического поиска, как указано в пункте 1, нерелевантные выше входные данные будут влиять на результаты вывода. Когда Webcpm создает набор инструкций по обеспечению качества вопросов и ответов на основе нескольких абзацев контекста, на основе нескольких сводных фактов, соответствующих каждому запросу, собранных вручную, он будет случайным образом выбирать несвязанные контексты одинаковой величины и исходные факты из других выборок. , сращивание используется в качестве входных данных для выполнения запроса+контента. -> Точная настройка модели ответа. Пусть модель научится отличать релевантные факты от нерелевантных и не обращать внимания на нерелевантную информацию при рассуждениях.
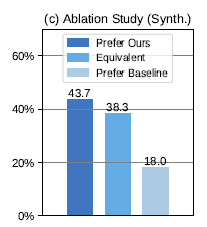
В то же время в статье сравнивается добавление несущественных фактов,Разница между эффектом модели и эффектом модели после точной настройки только с использованием соответствующих фактов,следующее. Уровень предпочтения базовой модели, использующей только релевантный контент, составляет 18%, что значительно ниже, чем,43,7% после добавления случайного нерелевантного контента и тонкой настройки. Поэтому присоединяйтесь к неактуальному тексту, тренироваться,Это действительно может улучшить способность модели различать шум.
WebGPT
paper: WebGPT:Browser-assisted question-answering with human feedback Demo: https://openaipublic.blob.core.windows.net/webgpt-answer-viewer/index.html
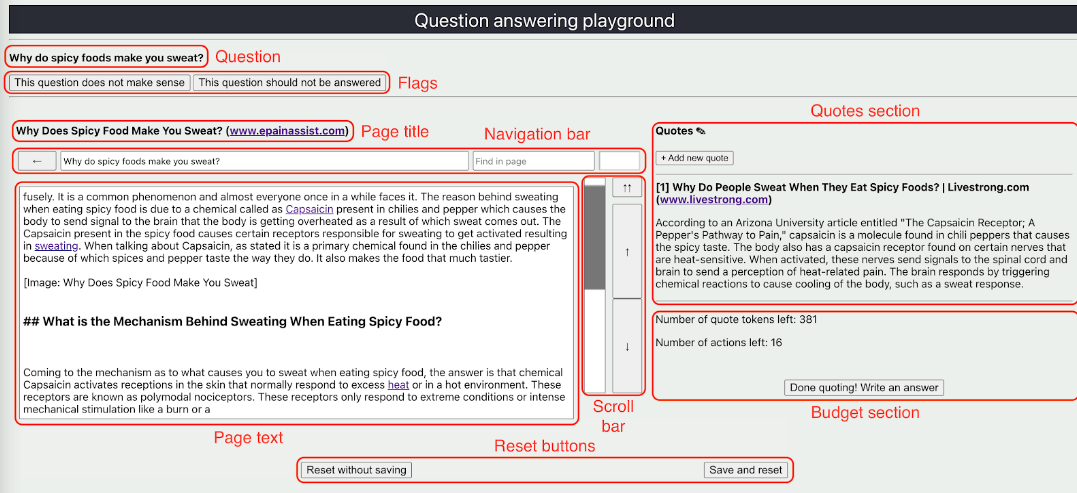
Статья webgpt была опубликована раньше всех, но сама статья довольно «высотная». Возможно, ее будет легче понять, прочитав сначала webcpm, а затем webgpt. Если вы просто посмотрите на интерфейс, используемый для сбора данных интерактивного поиска, вы поймете. найти, что эти два очень разные.
Вопросы webgpt в основном ELI5, смешанные с небольшим количеством TriviaQA, AI2, вопросы по почерку и другие вопросы. Поисковые системы также используют Bing API. Как и webcpm, чтобы избежать прямого поиска ответов и упростить процесс поиска, webgpt фильтрует информацию с таких сайтов, как Reddit и Quora, чтобы повысить сложность задачи.
Большинство деталей схожи с webcpm. Самое большое отличие состоит в том, что помимо использования точной настройки инструкций, webgpt также добавляет схему оценки предпочтений выборки с подкреплением/отклонением.
сбор данных
Сбор данных webgpt разделен на две части:
- Демонстрации: Аналогично всему процессу поиска данных в WebCPM: от ввода запроса, поиска, сводки до ответов на вопросы, собираются данные о взаимодействии людей, которые здесь не будут подробно описываться.
- Comparison: Данные о предпочтениях двух ответов, сгенерированных одной и той же моделью запроса, используются в модели предпочтений тренироваться. webgpt открыл исходный код этой части данных
Ниже мы подробно объясняем построение набора данных сравнения. Чтобы уменьшить шум аннотации предпочтений и влияние субъективных предпочтений человека, webgpt использует только справочные источники для оценки качества ответов модели. Конкретные шаги аннотации следующие.
- Флаги: Устраните необоснованные и спорные вопросы.
- Надежность. Сначала обозначьте источники данных, на которые ссылается модель: они разделены на три уровня: заслуживающие доверия, нейтральные и подозрительные, чтобы различать авторитетность и подлинность различных веб-страниц.
- Аннотации: выберите каждый пункт (выделенный), на который отвечает модель, и всесторонне оцените каждый пункт на основе того, подтверждается ли этот пункт цитатами и к какой категории относятся цитаты, подтверждающие этот пункт, в приведенной выше авторитетной классификации. Он также разделен на три уровня: сильная поддержка, слабая поддержка и отсутствие поддержки. При этом необходимо отметить важность каждого пункта в ответе на финальный вопрос. Существует три уровня: основной, побочный и нерелевантный.
- Рейтинги: после выполнения трех вышеуказанных шагов отметьте два ответа AB, полученные в результате выборки модели, соответственно.,Пришло время сравнить и подвести итоги. webgpt дает очень подробное описание того, как синтезировать важность каждого пункта и имеет ли он поддержку.,Оценить случай ответа AB,Затем сравните две оценки, чтобы получить относительную оценку.,Здесь бесчисленное множество разумных искусственных интеллектов... Подробности можно найти по ссылке на аннотационный документ в статье~
тренироваться
Соответствует вышеуказанной сборке данных, процесс тренирования webgpt по сути такой же, как и InstructGPT. Сначала используйте демонстрационные данные для точной настройки инструкций, которые в статье называются «Поведение». Cloning,Как следует из названия, он имитирует процесс поиска человека (БК). Тогда на основе модели BC,Сравните данные с помощью модели предпочтений сравнения тренироваться (RM). Наконец, алгоритм PPO используется для точной настройки модели BC на основе модели предпочтений для получения улучшенной модели точной настройки (RL). Подробности тренироваться можно напрямую передать в InstructGPT.
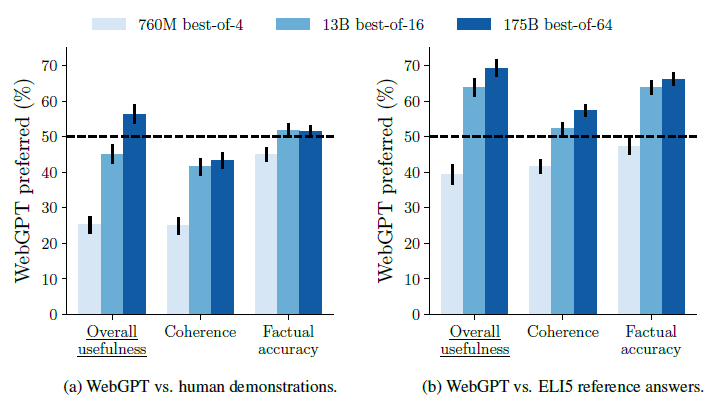
существоватьРасшифруйте подсказку7. Согласование предпочтений RLHF-OpenAI·DeepMind·Антропный сравнительный анализ.Мы обсуждали, что одной из сути обучения с подкреплением на самом деле является выборка отклонений.,В статье также сравнивается использование модели BC/RL в качестве базовой.,Добавить выборку отклонения,Случайная выборка ответов модели от 16 апреля 1964 г.,从中选取偏好Модель打分最高的回答作为结果的направлениеслучай。论文中效果最好的направлениеслучайдаBC+Best of 64 отбраковка выборки。RLМодель相比BCнемного улучшено,Однако улучшение не такое высокое, как при отклонении выборки.
Что касается плана оценки, в документе сравниваются результаты, полученные с помощью webgpt, с исходными результатами набора данных Eli5 (высоко оцененные ответы на Reddit) и помеченными вручную ответами в демонстрации, что позволяет помеченным учащимся выбрать более предпочтительный ответ. Фактически, точно настроенная модель 175B может значительно превзойти человеческие ответы, выбирая ответ с самым высоким показателем RM среди 64 ответов.
WebGLM
paper: WebGLM: Towards An Efficient Web-Enhanced Question Answering System with Human Preferences github: https://github.com/THUDM/WebGLM
Webglm находится между ними. Это проект, созданный с использованием API поиска Google и данных на английском языке. Весь процесс создания набора данных проекта более автоматизирован, меньше требует ручного аннотирования и более экономичен. Здесь мы в основном представляем некоторые различия в построении набора данных. Архитектура аналогична двум предыдущим.
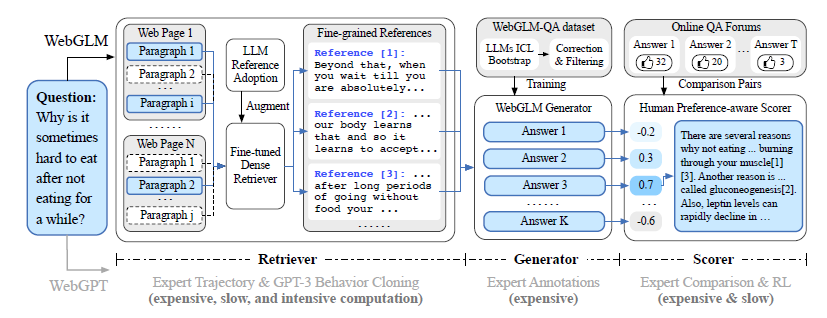
Retriever
Он отличается от метода извлечения, используемого webcpm для поиска частей, связанных с запросом, в веб-контенте.,webglm впервые сегментировал веб-страницу,Затем вычислите сходство между каждым абзацем и запросом.,Метод фильтрации связанного контента на основе сходства. Автор выбрал модель претренирования Contriever, основанную на контрастном обучении.,Однако точность оценки составляет менее 70%.
Таким образом, способность понимания прочитанного большой модели используется в качестве дополнения к паре «запрос*справочный образец». В статье используется одноразовый GPT-3. То есть для соответствующего абзаца извлекается случай, а большая модель используется для фильтрации тех, которые связаны с запросом из многих абзацев. А фильтрация корреляции запроса и ссылки набора выборок, построенного моделью, низкая, и существует высокая вероятность того, что это выборка низкого качества для выполнения модели.
Затем на основе выборок, созданных на основе большой модели, внутренний продукт внедрения запроса и ссылки используется в качестве оценки сходства, а цель тонкой настройки состоит в том, чтобы соответствовать потере MSE оценки сходства.
synthesis
Синтез, который является частью QA и Q&A на основе больших моделей на основе справочного контента, использует davinci-003 для создания образцов. Он в основном включает четыре этапа.
- Инструкция по созданию большой модели: Здесь автор использует метод APE случай,Для студентов, которые не знакомы с этим, пожалуйста, прочтите здесь.APE+SELF=Реализация кода автоматического построения набора команд。输入даQuestion+Refernce,Результатом является ответ, задающий вопрос большой модели.,Какие инструкции могут лучше описать такого родаLFQAЗадача。大Модель给出的指令да:Read the Refernces Provided and answer the corresponding question
- Пример построения из нескольких кадров: на основе сгенерированной инструкции вручную напишите несколько образцов из нескольких кадров, чтобы дать большой модели больше запросов + ссылок, и позвольте davinci-003 построить образцы вывода.
- Калибровка цитирования: в документе обнаружено, что результаты создания модели имеют правильное содержание цитирования, но неправильные серийные номера цитирования. Здесь автор использует Rouge-1 для оценки сходства и калибровки цитируемой ссылки.
- Фильтрация сэмплов: какой бы мощной ни была большая модель, она все равно остается моделью. Качество сэмплов, созданных davinci-003, неравномерно, и некоторые модели будут работать самостоятельно. Поэтому был добавлен модуль качественной фильтрации, который в основном отфильтровывает ссылки с низкой долей, слишком малым количеством ссылок и с высокой частотой ошибок.
Посредством вышеуказанной генерации + фильтрации 45 тысяч выборок LFQA более высокого качества были окончательно отфильтрованы из 83 тысяч выборок, сгенерированных моделью, для точной настройки модели в части вывода.
модель РМ
Webglm не использует ручную аннотацию для сравнения данных о предпочтениях, например webgpt. Вместо этого он использует аналогичные данные с онлайн-форумов по контролю качества в качестве данных о предпочтениях. Те, у кого много лайков, являются положительными образцами. А отфильтровывая вопросы с меньшим количеством ответов, усекая длинные тексты и используя ответы с большой разницей в количестве лайков для построения пар сравнительных выборок и другой логики предварительной обработки данных, мы можем получить относительно высокое качество, большие различия в предпочтениях и относительно длинные длины. Непредвзятые выборки предпочтений. Общий объем составляет 93 тыс. вопросов и 249 тыс. пар выборок.
На самом деле часто существует два решения для построения выборки больших моделей: одно — это небольшие выборки высокого качества, а другое — большие выборки среднего или низкого качества. Первое напрямую сообщает модели, как это сделать, а второе — это делать. постоянно искать точки соприкосновения, сохраняя при этом различия между образцами разного качества. Позвольте модели выявить общие черты. webglm — последний, а webgpt — первый.
Во-вторых, первоначальная модель RL сравнивается с моделью BC webgpt, описанной выше. Как мы упоминали в предыдущем блоге RL, первоначальная модель должна быть согласованной моделью, способной генерировать ответы, предпочитаемые человеком. Здесь webglm напрямую использует сводные данные Reddit, полученные путем тонкой настройки инструкций, а не данные ручных аннотаций, учитывая, что сводная задача также является подзадачой понимания прочитанного.
Разработка крупного модельного приложения на основе инструментов поиска,Это все, что мы можем сказать в этой главе. Переписано для запроса,Некоторые попытки оптимизации с помощью ретривера также упоминаются в статьях Reference3 и 4. Хочу увидеть обзор статьи,кликните сюдаНесколько слов о бумаге
Если вы хотите увидеть более полный обзор крупных статей, связанных с моделями, тонкой настройкой и предварительной тренировкой данных и структуры, приложения AIGC, перейдите на Github. >> DecryPrompt
Reference
1 Large Language Models Can Be Easily Distracted by Irrelevant Context
3 Query Rewriting for Retrieval-Augmented Large Language Models
4 REPLUG: Retrieval-Augmented Black-Box Language Models



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
