Распознавание текста Python
Сначала установите необходимые библиотеки
pip install opencv-python
pip3 install --user numpy scipy matplotlib
pip3 install torch torchvision torchaudio
pip install matplotlib
pip install torchvisionОбучение модели распознавания цифр
"""
****************** Обучение модели распознавания цифр *******************
"""
# -*- coding: utf-8 -*-
import cv2
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
# По умолчанию отображается 512 изображений.
BATCH_SIZE = 512
# Пакет обучения по умолчанию составляет 20 раз.
EPOCHS = 20
# Использовать ускорение процессора по умолчанию
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Создать список преобразования данных
tsfrm = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1037,), (0.3081,))
])
# Поскольку официальный набор данных реализован, используйте DataLoader напрямую для получения данных.
# Набор данных MNIST содержит 60 000 обучающих выборок размером 28x28 и 10 000 тестовых выборок.
# Скачать обучающий набор
train_loader = torch.utils.data.DataLoader(
datasets.MNIST(root = 'data', train = True, download = True,
transform = tsfrm),
batch_size = BATCH_SIZE, shuffle = True)
# Скачать набор тестов
test_loader = torch.utils.data.DataLoader(
datasets.MNIST(root = 'data', train = False, download = True,
transform = tsfrm),
batch_size = BATCH_SIZE, shuffle = True)
# Отображение примеров обучающих изображений
# Используйте метод класса make_grid в torchvision.utils для создания пакета изображений в виде сетки.
def imshow(images):
img = torchvision.utils.make_grid(images)
npimg = img.numpy()
plt.imshow(np.transpose(npimg,(1,2,0)))
plt.show()
# Возьмите пакет изображений из обучающего набора.
# Используйте функции iter и next для получения пакета данных изображений и соответствующих им тегов изображений.
images,labels = next(iter(train_loader))
imshow(images)
print(labels)
# Определите сеть LeNet-5, включая два сверточных слоя conv1 и conv2, два линейных слоя в качестве выходных данных и, наконец, выведите 10 измерений.
# Эти 10 измерений служат идентификаторами от 0 до 9, чтобы определить, какое число распознается.
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
# 1*1*28*28
# 1 входной канал изображения, 10 выходных каналов, ядро свертки 5x5
self.conv1 = nn.Conv2d(1, 10, 5)
self.conv2 = nn.Conv2d(10, 20, 3)
# Полностью связный слой, выходной слой softmax, 10 измерений
self.fc1 = nn.Linear(20 * 10 * 10, 500)
self.fc2 = nn.Linear(500, 10)
# прямое распространение
def forward(self, x):
in_size = x.size(0)
out = self.conv1(x) # 1* 10 * 24 *24
out = F.relu(out)
out = F.max_pool2d(out, 2, 2) # 1* 10 * 12 * 12
out = self.conv2(out) # 1* 20 * 10 * 10
out = F.relu(out)
out = out.view(in_size, -1) # 1 * 2000
out = self.fc1(out) # 1 * 500
out = F.relu(out)
out = self.fc2(out) # 1 * 10
out = F.log_softmax(out, dim=1)
return out
# генерировать Модель
model = ConvNet().to(DEVICE)
print(model)
# Создает оптимизатор оптимизации, содержащий список всех параметров, которые можно перебирать.
# model.parameters() представляет параметры оптимизации, а lr представляет скорость обучения.
optimizer = optim.Adam(model.parameters(),lr=0.0001)
# Определить функцию обучения
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
# Введите образцы и этикетки
data, target = data.to(device), target.to(device)
# Очистка градиента для каждой тренировки
optimizer.zero_grad()
# прямое распространение、Процесс обратного распространения ошибки и оптимизации
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
# Распечатать статус обучения
if (batch_idx + 1) % 30 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# Определить функцию проверки
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
# Введите образцы и этикетки
data, target = data.to(device), target.to(device)
output = model(data)
# Сложите потери партии
test_loss += F.nll_loss(output, target, reduction='sum')
# Найдите индекс с наибольшей вероятностью
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
# Распечатать статус проверки
print("\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%) \n".format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)
))
# Начать обучение Модель
for epoch in range(1, EPOCHS + 1):
train(model, DEVICE, train_loader, optimizer, epoch)
test(model, DEVICE,test_loader)
# держать Модель
torch.save(model.state_dict(), "./MNISTModel.pkl")
Близкое начало обучения
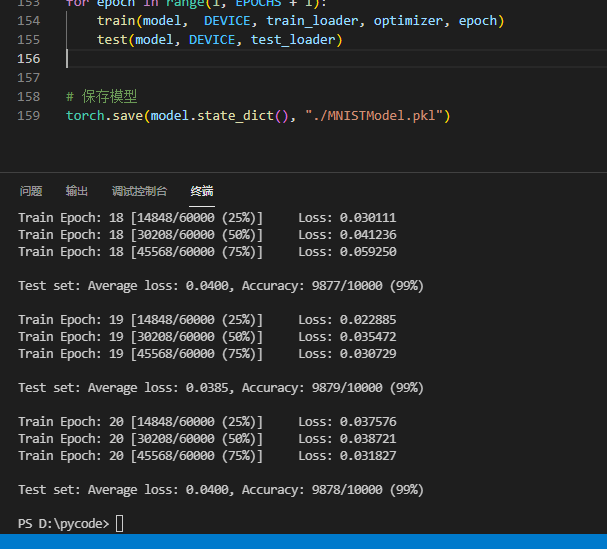
Пройдено 20 тренировок, модель сохранена.
Внедрить распознавание рукописных цифр MNIST
"""
****************** Внедрить распознавание рукописных цифр MNIST ************************
****************************************************************
"""
# -*- coding: utf-8 -*-
import cv2
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
# По умолчанию прогнозируются четыре изображения, содержащие числа.
BATCH_SIZE = 4
# Использовать ускорение процессора по умолчанию
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Создать список преобразования данных
tsfrm = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1037,), (0.3081,))
])
# тестовый набор
test_loader = torch.utils.data.DataLoader(
datasets.MNIST(root = 'data', train = False, download = True,
transform = tsfrm),
batch_size = BATCH_SIZE, shuffle = True)
# Определить функцию визуализации изображения
def imshow(images):
img = torchvision.utils.make_grid(images)
img = img.numpy().transpose(1, 2, 0)
std = [0.5, 0.5, 0.5]
mean = [0.5, 0.5, 0.5]
img = img * std + mean
# Назначьте высоту и ширину изображения x1 и y1 соответственно.
x1, y1 = img.shape[0:2]
# Изображение увеличивается в 5 раз по сравнению с исходным размером, а выходной формат размера (ширина, высота)
enlarge_img = cv2.resize(img, (int(y1*5), int(x1*5)))
cv2.imshow('image', enlarge_img)
cv2.waitKey(0)
# Определите сеть LeNet-5, включая два сверточных слоя conv1 и conv2, два линейных слоя в качестве выходных данных и, наконец, выведите 10 измерений.
# Эти 10 измерений служат идентификаторами от 0 до 9, чтобы определить, какое число распознается.
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
# 1*1*28*28
# 1 входной канал изображения, 10 выходных каналов, ядро свертки 5x5
self.conv1 = nn.Conv2d(1, 10, 5)
self.conv2 = nn.Conv2d(10, 20, 3)
# Полностью связный слой, выходной слой softmax, 10 измерений
self.fc1 = nn.Linear(20 * 10 * 10, 500)
self.fc2 = nn.Linear(500, 10)
# прямое распространение
def forward(self, x):
in_size = x.size(0)
out = self.conv1(x) # 1* 10 * 24 *24
out = F.relu(out)
out = F.max_pool2d(out, 2, 2) # 1* 10 * 12 * 12
out = self.conv2(out) # 1* 20 * 10 * 10
out = F.relu(out)
out = out.view(in_size, -1) # 1 * 2000
out = self.fc1(out) # 1 * 500
out = F.relu(out)
out = self.fc2(out) # 1 * 10
out = F.log_softmax(out, dim=1)
return out
# Основная запись программы
if __name__ == "__main__":
model_eval = ConvNet()
# Тренировочная нагрузка Модель
model_eval.load_state_dict(torch.load('./MNISTModel.pkl', map_location=DEVICE))
model_eval.eval()
# оттестовый набор Выложите несколько фотографий внутри
images,labels = next(iter(test_loader))
# Показать картинку
imshow(images)
# входить
inputs = images.to(DEVICE)
# выход
outputs = model_eval(inputs)
# Найдите индекс с наибольшей вероятностью
_, preds = torch.max(outputs, 1)
# Распечатать результаты прогноза
numlist = []
for i in range(len(preds)):
label = preds.numpy()[i]
numlist.append(label)
List = ' '.join(repr(s) for s in numlist)
print('Текущее предсказанное число: ',List)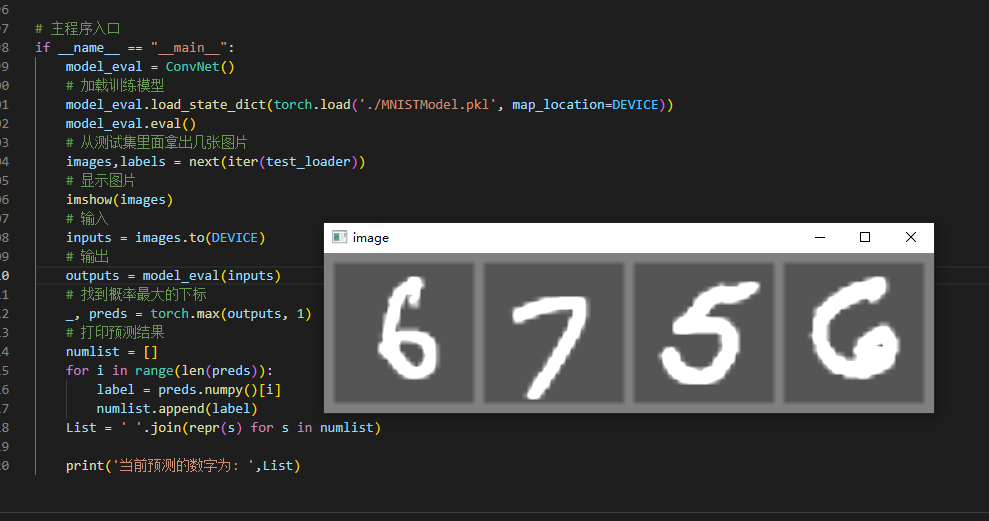
Закрыть Вывод прогнозируемых чисел




Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
