Раскрыта структура данных Redis и лежащая в ее основе реализация
При разработке систем с высоким уровнем параллелизма механизмы кэширования и эффективного хранения данных имеют решающее значение для повышения производительности приложений. Redis, как один из лучших, завоевал расположение разработчиков отличной производительностью и богатыми структурами данных. В этой статье мы углубимся в структуру данных и базовую реализацию Redis, знакомя читателей с закулисным миром этой высокопроизводительной базы данных.
1. Обзор структуры данных Redis
Redis поддерживает пять основных структур данных: строки, списки, хеши, наборы и отсортированные наборы. Эти структуры данных предоставляют разработчикам гибкие методы работы с данными для удовлетворения потребностей в хранении данных в различных сценариях.
- Строки: самый простой тип данных, который может содержать любые данные, такие как числа, строки, двоичные данные и т. д. В Redis строки безопасны на двоичном уровне, что означает, что они могут иметь любую длину и не будут усекаться, если содержат нулевые символы.
- Списки: простые списки строк, отсортированные в порядке вставки. Вы можете добавить элемент в голову (слева) или хвост (справа).
- Хэш-таблица(Hashes):это ключценить Дасобирать,имеет строковый тип Полеиценитьтаблица сопоставления。Подходит для хранения предметов.。
- сбор (наборы): представляет собой неупорядоченную сборку строкового типа. Это реализуется через хеш-таблицу,Можно добавить、удалить、Временная сложность поиска равна O(1).
- упорядоченныйсобирать(Sorted Наборы): аналогично наборам, но каждый строковый элемент связан с долей типа с плавающей запятой. Оценка элемента используется для ранжирования, и если два элемента имеют одинаковую оценку, их рейтинг рассчитывается лексикографически.
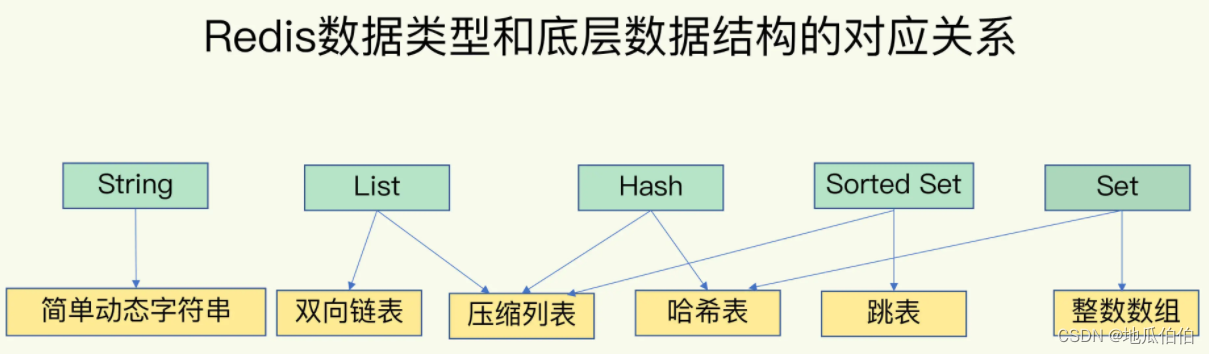
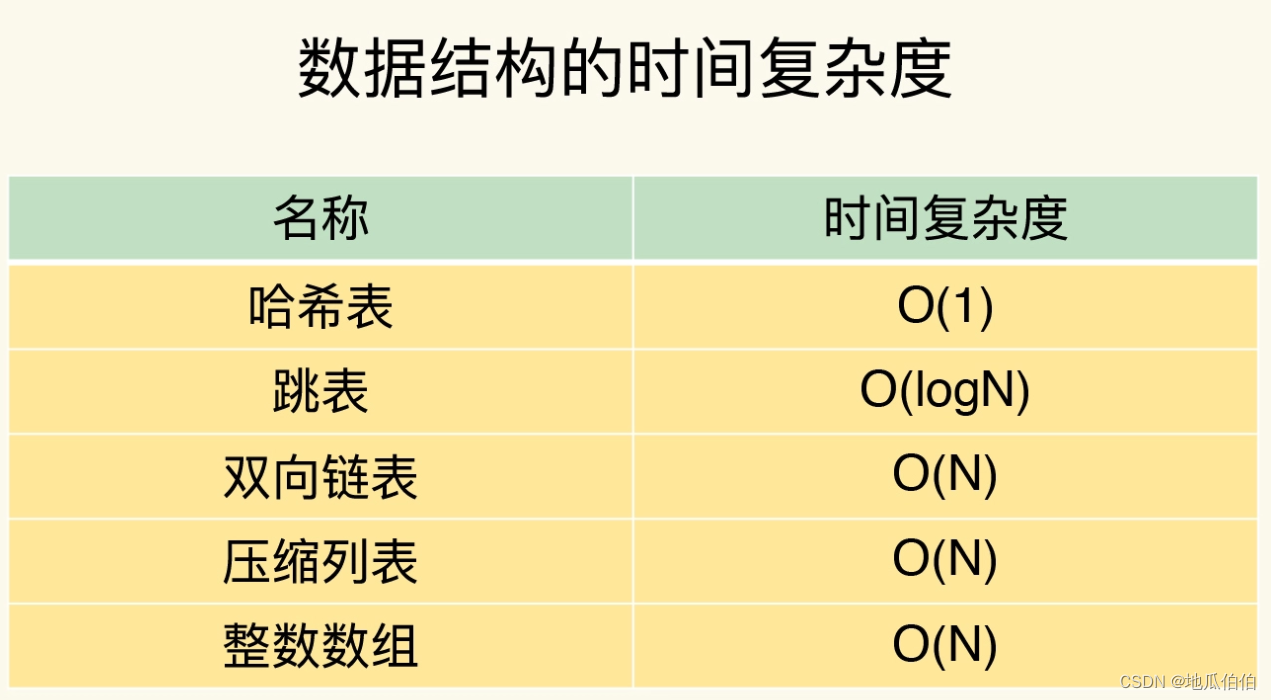
2. Раскрытие базовой реализации Redis
Преимущество Redis в производительности во многом обусловлено его изысканной базовой структурой данных и кодированием. Redis не использует напрямую упомянутые выше расширенные структуры данных для хранения, а выбирает наиболее подходящий метод внутреннего кодирования, исходя из характеристик и размера данных.
1. Базовая реализация строк: простые динамические строки (SDS).
Строковый тип Redis не использует для хранения напрямую собственную строку языка C (массив символов, заканчивающийся нулевым символом\0), а использует данные, называемые структурой Simple Dynamic String (SDS). Такой выбор дизайна дает Redis множество преимуществ, особенно с точки зрения производительности и гибкости.
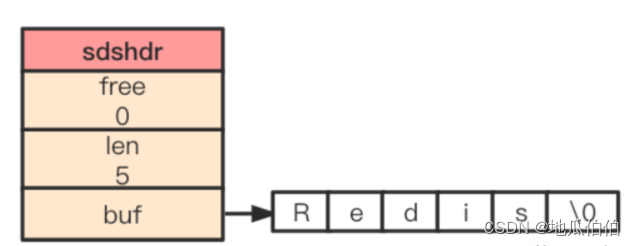
Структура паспорта безопасности
Определение структуры данных SDS примерно следующее (может различаться в зависимости от версии Redis):
struct sdshdr {
int len; // Запишите количество используемых байтов в массиве buf, равное длине строки, хранящейся в SDS.
int free; // Запишите количество неиспользуемых байтов в массиве buf.
char buf[]; // Массив байтов, используемый для хранения строк. Обратите внимание, что длина массива здесь не указана. Это гибкий массив. array member)
};
Анализ преимуществ
- Предварительное выделение: SDS выделит дополнительное неиспользуемое пространство для buf (записанное через свободное поле). Это означает, что при добавлении содержимого в строку SDS Redis не нужно перераспределять память, если неиспользуемого пространства достаточно. Это уменьшает количество выделений памяти, тем самым повышая производительность.
- Постоянная сложность получения длины строки: из-за структуры паспорта Внутренняя безопасность поддерживает lenPole для записи текущей длины строки.,Операцию получения длины строки можно выполнить за постоянное время сложности O(1),Нет необходимости проходить всю строку, как собственную строку в языке C.
- Двоичная безопасность: SDS может хранить произвольные двоичные данные, включая нулевой символ \0. Собственные строки в языке C завершаются нулевым символом, что не позволяет им содержать нулевые символы. SDS использует поле len для определения длины строки, поэтому на него не распространяется это ограничение.
- Совместимость со строковыми функциями языка C: хотя SDS предоставляет собственный набор API для строковых операций.,но этоbufПоле На самом деле это просто обычныйCнить(к\0окончание),Это означает, что при необходимости,Можетк Используйте стандарт напрямуюCязыкнитьфункция обработчика для работыbufПоле(Хотя обычно это не рекомендуется,Поскольку целостность структуры паспорта безопасности может быть нарушена).
Оптимизация работы
SDS предоставляет набор API для создания, изменения и объединения строк. Эти API обрабатывают такие детали, как распределение памяти и обновление длины, внутри, поэтому пользователям не нужно заботиться о базовой реализации при их использовании.
Например, когда вы используете функцию sdscat для добавления содержимого в строку SDS, функция сначала проверяет, достаточно ли неиспользуемого пространства. Если нет, она перераспределяет больший объем памяти и затем копирует исходные данные в новое место. добавить новый контент. Все эти операции прозрачны для пользователя.
Используя SDS в качестве базовой реализации строк, Redis достигает высокой эффективности и гибкости в операциях со строками, предоставляет богатые интерфейсы операций с данными для верхнего уровня и обеспечивает согласованность и стабильность внутренних данных. Такая конструкция позволяет Redis поддерживать отличную производительность при обработке больших объемов строковых данных.
2. Базовая реализация списков: двусвязные списки и сжатые списки.
Тип данных Redis Lists — это очень важная структура данных, которая позволяет пользователям перемещать или извлекать элементы на обоих концах списка. Для достижения этой эффективной операции список Redis использует две структуры данных внизу: двусвязный список и сжатый список. Какая структура будет выбрана, зависит от размера списка и характеристик элементов.
- двусвязный список
Когда количество элементов в списке велико или сами элементы большие, Redis выберет использование двусвязного списка в качестве базовой реализации. Каждый узел двусвязного списка хранит указатель на предыдущий узел и следующий узел, что позволяет относительно легко вставлять или удалять элементы в любом месте списка.
Структура двусвязного списка примерно следующая:
typedef struct listNode {
struct listNode *prev; // указатель на предыдущий узел
struct listNode *next; // Указатель на следующий узел
void *value; // Данные, сохраненные узлом
} listNode;
typedef struct list {
listNode *head; // Указатель на начало связанного списка
listNode *tail; // Указатель на конец связанного списка
unsigned long len; // длина связанного списка
// ... Могут быть и другие поля, например функции копировать, функции сравнения и т. д.
} list;Преимущества использования двусвязного списка:
Вставка и удаление элементов в начале или конце списка может быть выполнена за время O(1).
Когда вам нужно пройти по списку, вы можете начать с головы или хвоста и последовательно обращаться к узлам вдоль указателя.
- Сжатый список
Когда количество элементов в списке невелико и сами элементы малы, Redis будет использовать сжатый список (ziplist) в качестве базовой реализации для экономии памяти. Упакованный список — это компактный непрерывный блок памяти, в котором элементы списка хранятся по порядку.
Структура сжатого списка примерно следующая:
+--------+--------+--------+------+
| ZLBYTE | LEN | 'one' | 'two'| ...
+--------+--------+--------+------+- ZLBYTE: Сжатый Заголовок списка содержит специальную кодировку и Сжатый. Информация о длине списка.
- LEN: поле длины перед каждым элементом, используемое для записи длины элемента или смещения от предыдущего элемента до текущего элемента.
- ‘one’, ‘two’: Фактические элементы списка, они хранятся в Сжатом подряд. списоксередина。
Преимущества использования сжатых списков:
Высокое использование памяти, поскольку элементы хранятся последовательно без дополнительных затрат на указатели.
Для небольших списков операции могут быть быстрыми, поскольку все данные находятся в непрерывном блоке памяти.
Оптимизация работы
Реализация списков Redis предоставляет набор API для создания, изменения, перемещения и других операций со списками. Эти API внутренне выбирают подходящую базовую структуру данных на основе размера списка и характеристик элементов и при необходимости преобразуют между структурами данных.
Например, при добавлении нового элемента в список, реализованный с помощью сжатого списка, если добавленный список по-прежнему соответствует условиям использования сжатого списка (то есть количество и размер элементов не превышают заданный порог), то Redis будет напрямую Добавляет новые элементы в конец сжатого списка. В противном случае Redis преобразует сжатый список в двусвязный список и добавит новые элементы в хвост связанного списка.
Используя двусвязные списки и сжатые списки в качестве базовой реализации, тип данных списка Redis может обеспечить эффективную работу в различных сценариях использования. Эта гибкая конструкция позволяет Redis обрабатывать данные списков различного размера и сложности, сохраняя при этом низкое потребление памяти и высокую скорость работы.
3. Базовая реализация хеширования: словарь и сжатый список в Redis
Тип Redis Hashes позволяет пользователям хранить несколько полей и соответствующие значения в одном ключе. Чтобы эффективно поддерживать эту структуру данных, Redis использует две основные структуры данных для реализации хеширования: словари (также называемые хеш-таблицами) и сжатые списки.
- словарь (хеш-таблица)
Когда в хэше много или больших полей и значений, Redis выберет использование словаря в качестве базовой реализации. Словарь — это структура данных, которая напрямую обращается к значениям через ключи (поля в хешировании Redis). Он может обеспечить в среднем операции поиска, вставки и удаления со сложностью O(1).
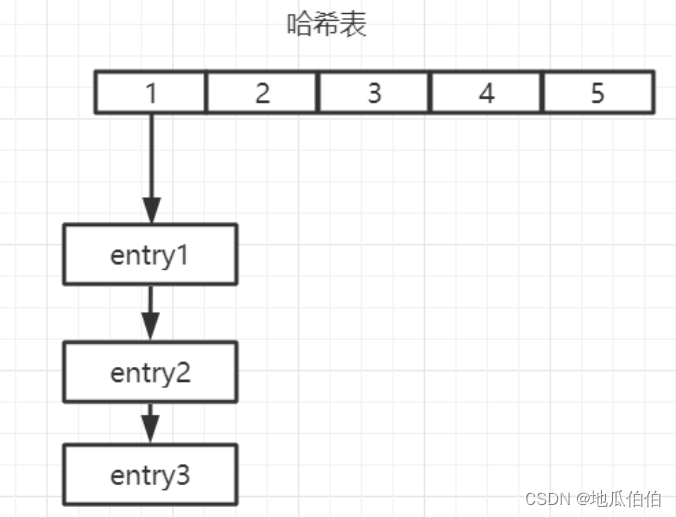
Реализация словаря Redis обычно содержит две хеш-таблицы, которые используются для управления миграцией данных при расширении хеш-таблицы. Каждый узел хеш-таблицы сохраняет хеш-значение поля, само поле и соответствующее значение. Структура примерно следующая:
typedef struct dictEntry {
void *key; // Поле
union {
void *val;
uint64_t u64;
int64_t s64;
// ... Другие возможные типы значений
} v; // ценить
struct dictEntry *next; // Указатель на следующий узел, используемый для разрешения коллизий хэшей.
} dictEntry;
typedef struct dict {
dictEntry **table; // Массив хеш-таблицы
unsigned long size; // Размер хеш-таблицы
unsigned long sizemask; // Маска, используемая для расчета индекса
unsigned long used; // Количество используемых узлов
// ... Могут быть и другие поляки,Такие как хэш-функция, функция копирования и т. д.
} Дикт;Преимущества использования словаря:
Обеспечивает быстрый поиск полей, операции вставки и удаления.
Механизм расширения хеш-таблицы может поддерживать низкую частоту хэш-конфликтов, тем самым обеспечивая эффективность операции.
- Сжатый список
Redis использует сжатые списки в качестве базовой реализации для экономии памяти, когда полей и значений в хеше мало и они малы. Сжатый список — это компактный непрерывный блок памяти, в котором пары полей и значений хранятся в хеше по порядку.
Структура сжатого списка примерно следующая:
+--------+--------+--------+--------+
| ZLBYTE | LEN1 | FIELD1 | LEN2 | VALUE2 | ...
+--------+--------+--------+--------+
ZLBYTE:Сжатый Информация в шапке списка.
LEN1、FIELD1:первый Поледлинаи Полесам。
LEN2、VALUE2:первый Поле Соответствующийценитьдлинаиценитьсам。По аналогии, последующие пары полей и значений также сохраняются в этом формате.
Преимущества использования сжатых списков:
- Высокое использование памяти, поскольку поля и значения хранятся последовательно без дополнительных затрат на указатели и метаданные.
- Для небольших хэшей операции могут быть быстрыми, поскольку все данные находятся в одном непрерывном блоке памяти.
Оптимизация работы
Реализация хеша Redis предоставляет набор API для создания, изменения, поиска и других операций хеша. Эти API внутренне выбирают подходящую базовую структуру данных на основе размера хеша и характеристик поля и при необходимости преобразуют между структурами данных.
Например, при добавлении нового поля и значения в хэш, реализованный с помощью сжатого списка, если добавленный хеш по-прежнему соответствует условиям использования сжатого списка (то есть количество и размер полей и значений не превышают заданный порог), то Redis добавит новые поля и значения прямо в конец списка сжатия. В противном случае Redis преобразует сжатый список в словарь и вставляет в словарь новые поля и значения.
Используя словари и сжатые списки в качестве базовой реализации, тип хеш-данных Redis может обеспечить эффективную производительность операций в различных сценариях использования. Эта гибкая конструкция позволяет Redis обрабатывать хеш-данные различного размера и сложности, сохраняя при этом низкое потребление памяти и высокую скорость работы.
4. Базовая реализация множеств: целочисленные множества и словари.
Набор Redis (Наборы) — это неупорядоченный набор с неповторяющимися элементами. Чтобы эффективно поддерживать эту структуру данных и ее операции, Redis использует две основные структуры данных внизу: набор целых чисел (intset) и словарь (хеш-таблица).
набор int
Если все элементы коллекции являются целыми числами и количество элементов невелико, Redis выберет использование целочисленной коллекции в качестве базовой реализации. Целочисленный набор — это компактный массив, в котором каждый элемент является целым числом в наборе.
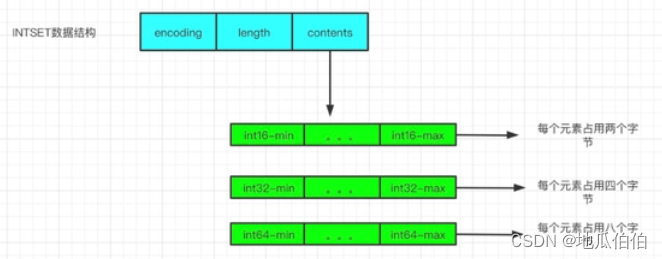
Преимущества целочисленных коллекций:
- Высокое использование памяти: сбор целых чисел сохраняет целое число близко к непрерывному блоку памяти.,Никаких дополнительных указателей или метаданных не требуется.
- Быстрая работа: сбор элементов в целых числах,Доступ к Redis можно получить напрямую через индекс массива.,Это позволяет очень быстро находить, добавлять и удалять целые числа. Однако,Целые числа также имеют свои ограничения. Поскольку требуется, чтобы элементы в сборе были целыми числами.,И количество элементов небольшое,Поэтому при работе с нецелочисленными элементами или большим количеством элементов,Целочисленная сборка может быть не оптимальным выбором.
Словарь (хеш-таблица)
Если элементы в коллекции не соответствуют условиям целочисленной коллекции (то есть элементы не являются целыми числами или количество элементов велико), Redis будет использовать словарь в качестве базовой реализации. Словарь — это хэш-таблица, которая сопоставляет хеш-значения элементов с соответствующими сегментами с помощью хэш-функции для поддержки операций быстрого поиска, вставки и удаления.
Преимущества словарей:
- Высокая гибкость: словари могут хранить элементы любого типа, а не только целые числа.
- Высокая эксплуатационная эффективность: благодаря хеш-функции словарь может выполнять в среднем операции поиска, вставки и удаления с временной сложностью O(1).
Однако словари также имеют некоторые накладные расходы. Каждому элементу словаря требуется дополнительное пространство для хранения метаданных, таких как хэши, указатели и т. д. Кроме того, когда в хеш-таблице возникает конфликт хэшей, может потребоваться разрешить конфликт с помощью связанного списка или других методов, что может снизить эффективность операции.
Оптимизация работыи Конвертировать
Реализация коллекций Redis предоставляет набор API-интерфейсов для создания, изменения, поиска и других операций с коллекциями. Эти API внутренне выбирают подходящую базовую структуру данных на основе размера коллекции и характеристик элементов и при необходимости преобразуют между собой структуры данных.
Например, при добавлении нового целочисленного элемента в коллекцию, реализованную с использованием целочисленной коллекции, если добавленная коллекция по-прежнему соответствует условиям использования целочисленной коллекции (то есть количество элементов не превышает заданный порог), то Redis будет непосредственно добавить целочисленный элемент в коллекцию. Добавляет новые элементы в конец коллекции. В противном случае Redis преобразует коллекцию целых чисел в словарь и вставит в словарь новые элементы.
Коллекции Redis реализованы с использованием двух структур данных: целочисленных коллекций и словарей на нижнем уровне. Наборы целых чисел подходят для сценариев, в которых мало элементов и все они являются целыми числами, а словари подходят для сценариев, в которых количество элементов велико или типы элементов не ограничены. Благодаря такой гибкой конструкции Redis может обеспечить эффективную работу в различных сценариях использования, сохраняя при этом низкое потребление памяти и высокую скорость работы.
5. Базовая реализация упорядоченных коллекций: структура данных в Redis
Сортированные наборы Redis — это упорядоченный набор с неповторяющимися элементами, в котором каждому элементу присвоена оценка. Чтобы добиться эффективности этой структуры данных и связанных с ней операций, Redis в основном использует две структуры данных внизу: список сжатия (ziplist) и список пропуска (skiplist).
Пропустить
Когда количество элементов в упорядоченной коллекции велико или размер элементов велик, Redis будет использовать список переходов в качестве базовой реализации. Список пропуска — это многоуровневый упорядоченный связанный список, который ускоряет операции поиска, вставки и удаления за счет поддержки нескольких уровней указателей.
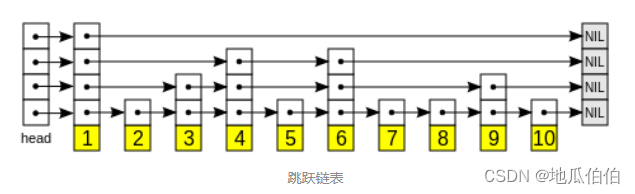
Преимущества пропуска таблиц:
- Высокая эффективность поиска: поддерживая несколько уровней указателей, таблица пропуска может обеспечить операцию поиска со средней временной сложностью O (log N), где N — количество элементов.
- Операции вставки и удаления выполняются быстро: операции вставки и удаления таблиц переходов требуют только локальной настройки указателей без перемещения большого объема данных.
- Поддержка запроса диапазона: таблица переходов может легко поддерживать операцию запроса элементов в соответствии с диапазоном оценок.
Однако пропуск таблиц также имеет некоторые накладные расходы. Каждый элемент имеет несколько указателей на предшественников и преемников в списке переходов, и эти указатели будут занимать дополнительное пространство памяти.
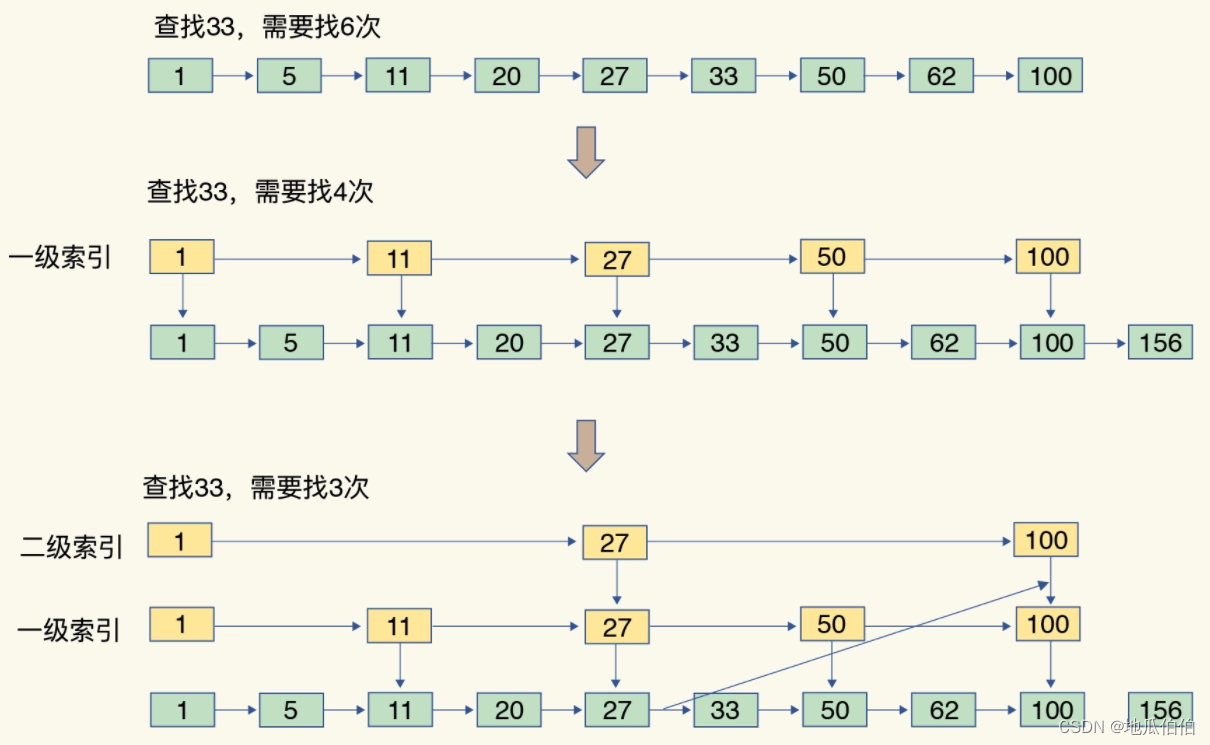
Оптимизация работыи Конвертировать
Реализация упорядоченной коллекции Redis предоставляет набор API для создания, изменения и поиска коллекций. Эти API внутренне выбирают подходящую базовую структуру данных на основе размера коллекции и характеристик элементов и при необходимости преобразуют между собой структуры данных.
Например, при добавлении нового элемента в упорядоченный набор, реализованный с помощью сжатого списка, если добавленный набор по-прежнему соответствует условиям использования сжатого списка (то есть количество элементов не превышает заданный порог), то Redis будет напрямую Добавляет новые элементы в конец сжатого списка. В противном случае Redis преобразует сжатый список в список пропуска и вставит в него новые элементы.
Упорядоченная коллекция Redis реализована с использованием двух структур данных: сжатого списка и таблицы пропуска. Сжатые списки подходят для сценариев с меньшим количеством элементов и меньшими размерами, а списки пропуска подходят для сценариев с большим количеством элементов или большими размерами элементов. Благодаря такой гибкой конструкции Redis может обеспечить эффективную работу в различных сценариях использования, сохраняя при этом низкое потребление памяти и высокую скорость работы. Реализация упорядоченных наборов позволяет Redis поддерживать сложные операции, такие как сортировка по баллам и запросам диапазона, удовлетворяя разнообразные потребности бизнеса.
3. Резюме
Redis обеспечивает высокопроизводительное хранение и операции с данными благодаря изысканным структурам данных и методам кодирования. Его базовая реализация не только учитывает эффективность использования памяти, но также полностью учитывает производительность операций с данными. Это позволяет Redis поддерживать отличную производительность при обработке больших объемов данных и одновременных запросов. Разработчикам понимание структуры данных и базовой реализации Redis поможет лучше использовать и оптимизировать Redis, тем самым улучшая общую производительность приложения.
Навыки обновляются благодаря обмену ими, и каждый раз, когда я получаю новые знания, мое сердце переполняется радостью. Искренне приглашаем вас подписаться на публичный аккаунт 『
код тридцать пять』 , для получения дополнительной технической информации.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
