Раскрыта основная технология интеллектуальной обработки документов в эпоху больших моделей
С развитием технологий искусственного интеллекта интеллектуальная обработка изображений стала популярной технологией, популярной во всем мире. Интеллектуальная обработка изображений может помочь нам извлечь наиболее ценную информацию из больших объемов данных изображений, внеся значительный вклад в медицину, военную сферу, безопасность и другие области. Однако возникают и трудности обработки изображений. Кратко представим трудности обработки изображений и сравним решения.
Прежде всего, сложность обработки изображений заключается в том, как получить ценную информацию из большого количества данных изображения. Данные изображения обычно содержат большое количество избыточной информации. Выбор значимых данных для обработки является одной из трудностей обработки изображений. Во-вторых, при обработке изображений также необходимо решить проблему удаления шума и искажений. Это связано с тем, что в процессе передачи и обработки изображения часто вводятся некоторый шум и искажения, что приводит к снижению качества изображения. Наконец, обработка изображений также должна решить проблему обработки крупномасштабных данных изображений, поскольку объем данных изображений становится все больше и больше, а традиционные методы обработки изображений больше не могут удовлетворить спрос.
Для решения этих трудностей в настоящее время широко применяются некоторые решения.
Прежде всего, в области обработки изображений широко используются технологии глубокого обучения, и ценные данные можно отбирать для обработки путем обучения моделей.
Во-вторых, технологии обработки изображений также постоянно развиваются, например, передовые технологии шумоподавления и устранения искажений, которые могут эффективно обрабатывать данные изображения.
Наконец, в области обработки изображений также широко используются технологии распределенных вычислений, которые могут обрабатывать крупномасштабные данные изображений и повышать эффективность обработки.
Короче говоря, интеллектуальная обработка изображений — это сложная технология, которая должна решать трудности извлечения ценной информации из больших объемов данных изображений, удаления шума и искажений, а также обработки крупномасштабных данных изображений. Однако с помощью современных технических средств, таких как глубокое обучение, технологии снижения шума и устранения искажений, распределенные вычисления и т. д., эти проблемы постепенно преодолеваются, а технология интеллектуальной обработки изображений получила широкое распространение и развитие.
Обзор одной картинки
Доктор Дин Кай из Hehe Information упомянул на форуме, что сценарии интеллектуальной обработки документов разнообразны и сопряжены с множеством проблем. Давайте воспользуемся изображением, чтобы дать общее представление.
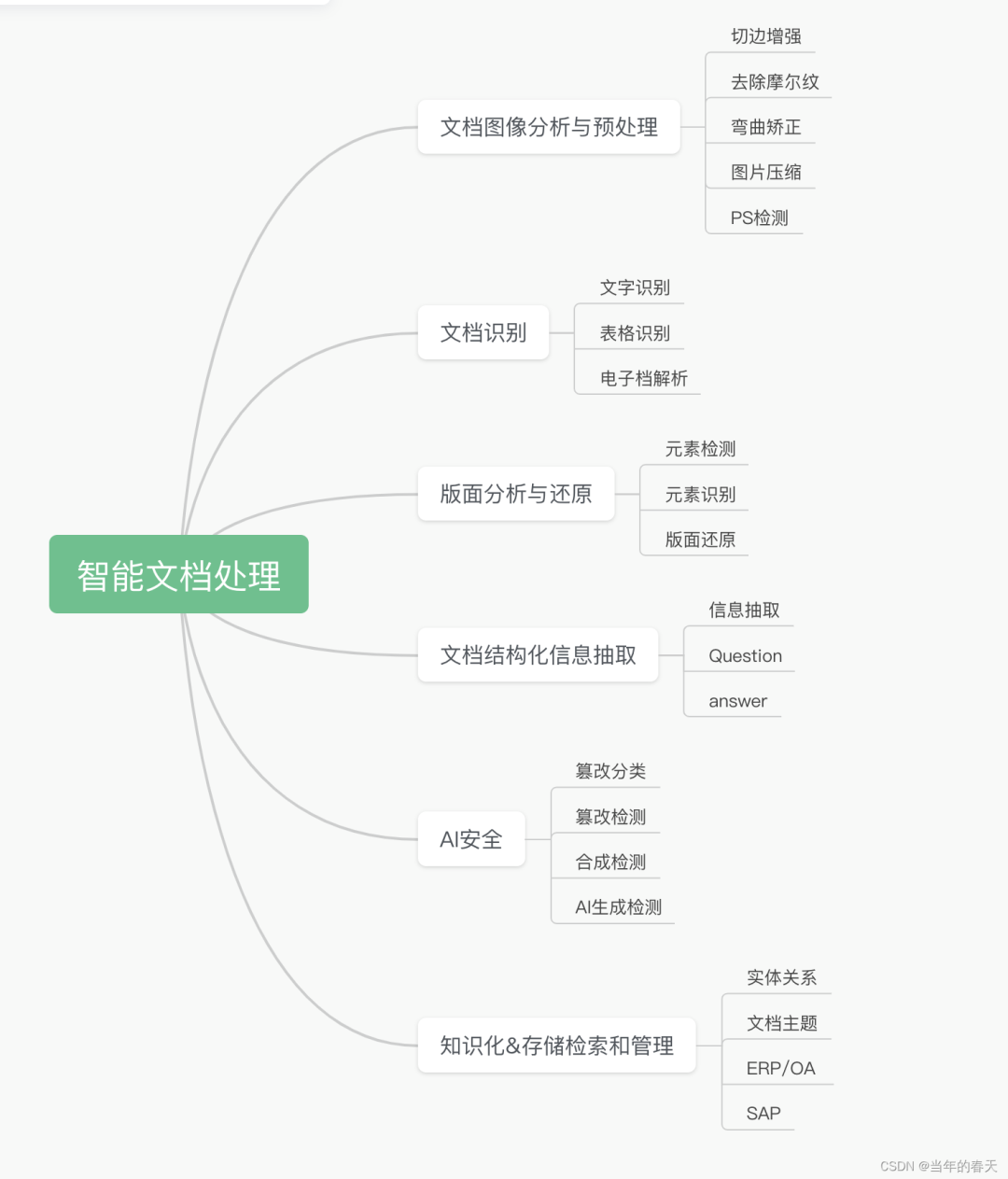
Анализ и предварительная обработка изображений документов
Общая архитектура предварительной обработки изображений
Документ с изогнутым изображением необходимо преобразовать в изображение, которое будет выглядеть плоским и четким.,Может обрабатываться как:Ввод изображения–>Извлечение документа–>удаление пальца–>Коррекция деформации–>улучшение изображения,общая архитектура Как показано на картинке:
Давайте посмотрим на отображение эффекта после описанных выше шагов. Мы видим, что изображение становится четким и плоским:

Основные технические моменты
Улучшение обрезки краев. Улучшение обрезки краев означает использование ряда алгоритмов и методов для четкости краев изображений документов для лучшего распознавания текста и изображений. Общие методы включают алгоритмы, основанные на обнаружении краев, алгоритмы, основанные на сверточных нейронных сетях и т. д.
Удаление муара. Муар — это интерференционная текстура, которая может появляться на цифровых изображениях. Эта интерференционная текстура влияет на распознавание текста и изображений во время обработки изображений. Методы удаления муара включают алгоритмы шумоподавления на основе фильтров, алгоритмы на основе вейвлет-преобразования и т. д.
Коррекция изгиба. Коррекция изгиба — это исправление изгибов и искажений, появляющихся на изображениях отсканированных документов, для лучшего распознавания текста и изображений. К распространенным методам относятся алгоритмы, основанные на технологии обработки изображений, такие как поворот изображения, аффинное преобразование и т. д.
Сжатие изображений. Сжатие изображений означает сжатие изображений высокой четкости большого размера в изображения низкого разрешения небольшого размера для экономии места и времени при хранении и передаче. Общие методы включают алгоритмы, основанные на сжатии с потерями, такие как JPEG, PNG и т. д.
Обнаружение PS: Обнаружение PS относится к использованию ряда алгоритмов и технологий для определения наличия в изображении документа следов обработки с помощью программного обеспечения для редактирования изображений, такого как Photoshop. Общие методы включают алгоритмы, основанные на технологии обработки изображений, такие как анализ изображений, извлечение признаков и т. д.
Сценарии применения
Теперь, когда мы разобрались с основными техническими моментами, давайте рассмотрим сценарии использования. Проблемы, которые мы видим в следующих графических документах: изгиб, тени, муар и т. д. После обработки повышения качества изображения документа мы можем получить совершенно новое изображение. графический документ с функциями. Все еще довольно мощный. Только представьте, если у нас есть несколько старых и изношенных книг, как было бы замечательно получить документы с четкими изображениями посредством обработки изображений, чтобы их можно было передать по наследству.

Анализ и восстановление макета
общая архитектура
При обработке сложного изображения с макетом задействуется ряд моделей глубокого обучения, таких как обнаружение и распознавание текста, обнаружение и распознавание элементов макета, разделение слоев, верстка и макет. После идентификации каждого модуля каждый модуль необходимо объединить и сопоставить с ним. рендеринг документа. Наконец, можно создать редактируемый пользователем текст Word или Excel. Общий процесс выглядит следующим образом:
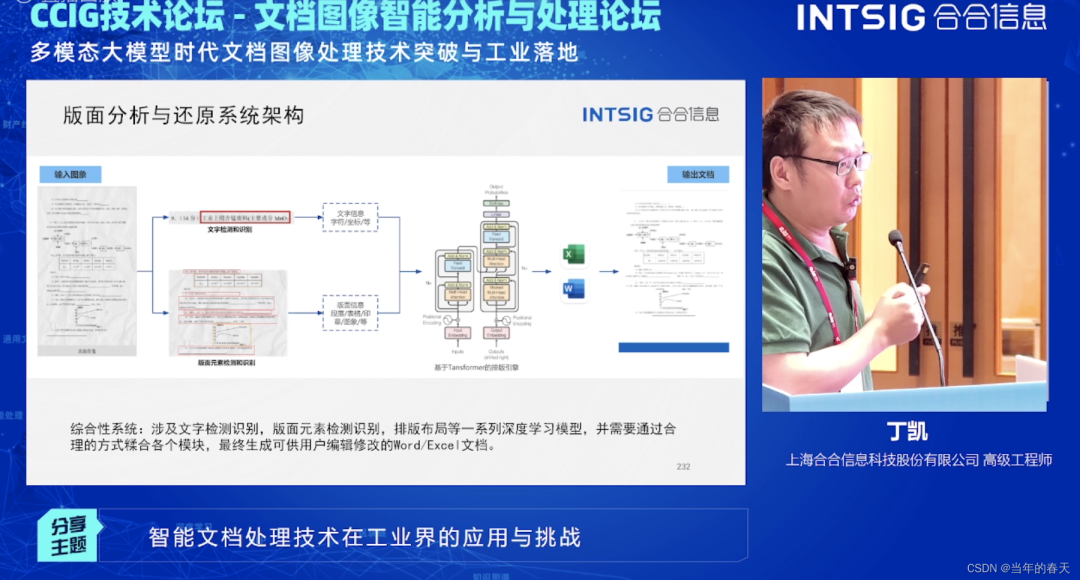
Основные технические моменты
Анализ и восстановление макета:Анализ и восстановление Макет подразумевает анализ изображения документа, идентификацию элементов макета (таких как верхние и нижние колонтитулы, номера страниц, заголовки и т. д.) и восстановление исходной структуры макета. Эта технология может улучшить качество чтения документов и эффективность поиска. Общие методы включают в себя обработку изображенийизалгоритм,Такие как обнаружение краев, Морфологические операции、Сегментация и т. д.
Обнаружение элементов. Обнаружение элементов — это обнаружение элементов в изображениях документов с помощью ряда алгоритмов и технологий, включая текст, таблицы, изображения, графику и т. д. К распространенным методам относятся алгоритмы, основанные на глубоком обучении, такие как сверточные нейронные сети (CNN), рекуррентные нейронные сети (RNN) и т. д.
Распознавание элементов. Под распознаванием элементов понимается распознавание элементов, обнаруженных в изображениях документов, например, распознавание текста OCR, структурированное распознавание таблиц и т. д. Общие методы включают алгоритмы на основе машинного обучения, такие как SVM, Наивный Байес и т. д., и алгоритмы на основе глубокого обучения, такие как распознавание символов на основе CNN, распознавание последовательностей на основе RNN и т. д.
Восстановление макета. Под восстановлением макета понимается восстановление исходной структуры макета изображения документа, обработанного путем обнаружения элементов, распознавания элементов и т. д. К распространенным методам относятся алгоритмы, основанные на анализе макета, такие как восстановление макета на основе структуры документа, восстановление макета на основе сегментации и т. д. В то же время восстановление макета также можно сочетать с некоторыми правилами и требованиями верстки документа для выполнения автоматизированной верстки для улучшения общей красоты и читабельности документа.
Сценарии применения
Сложный макет содержит множество сложных элементов, среди которых: текст, печати, заголовки, таблицы, печати швов, QR-коды, штрих-коды и т. д. Например, при идентификации информации в счете-фактуре помимо простого определения текста нам также необходимо идентифицировать печати и другую информацию. После идентификации каждого элемента в документе документ печатается и размечается. Путем установления набора связей между визуальной информацией и структурой потока наконец получается макет абзаца, соответствующий входной информации.

Безопасность ИИ
Безопасность ИИ означает учет вопросов безопасности при применении технологии искусственного интеллекта для предотвращения таких рисков, как злонамеренные атаки и утечки данных. В интеллектуальной обработке документов Безопасность ИИ в основном включает в себя технологии защиты конфиденциальности данных, классификации и обнаружения несанкционированного доступа.
Классификация несанкционированного доступа: Классификация несанкционированного доступа относится к классификации действий по фальсификации документов, при этом фальсификация делится на две категории: вредное вмешательство и безвредное вмешательство. Вредное вмешательство относится к злонамеренному вмешательству, например, изменению текстового содержимого, вставке вредоносного кода и т. д., тогда как безвредное вмешательство относится к непреднамеренному вмешательству, например исправлению опечатки, корректировке набора текста и т. д. Общие методы включают алгоритмы на основе машинного обучения, такие как деревья решений, наивный Байес и т. д.
Обнаружение несанкционированного доступа. Обнаружение несанкционированного доступа относится к обнаружению документов с целью определить, были ли они подделаны. Общие методы включают алгоритмы на основе признаков изображения, такие как SIFT, SURF и т. д., и алгоритмы на основе машинного обучения, такие как машина опорных векторов (SVM), случайный лес и т. д.
Синтетическое обнаружение. Синтетическое обнаружение относится к обнаружению документов с целью определить, есть ли в документе синтетические изображения. Общие методы включают алгоритмы, основанные на особенностях изображения, такие как метод центра тяжести, градиентный метод и т. д., и алгоритмы, основанные на глубоком обучении, такие как обнаружение синтетических изображений на основе сверточных нейронных сетей (CNN).
Обнаружение, созданное искусственным интеллектом. Обнаружение, созданное искусственным интеллектом, относится к обнаружению изображений в документах, чтобы определить, были ли изображения созданы искусственным интеллектом. Общие методы включают методы обнаружения, основанные на состязательных генеративных сетях (AGN), такие как методы обнаружения, основанные на состязательных выборках, методы обнаружения, основанные на состязательных потерях и т. д. Кроме того, о подлинности изображения можно судить и путем анализа текстуры, структуры и других характеристик созданного изображения.
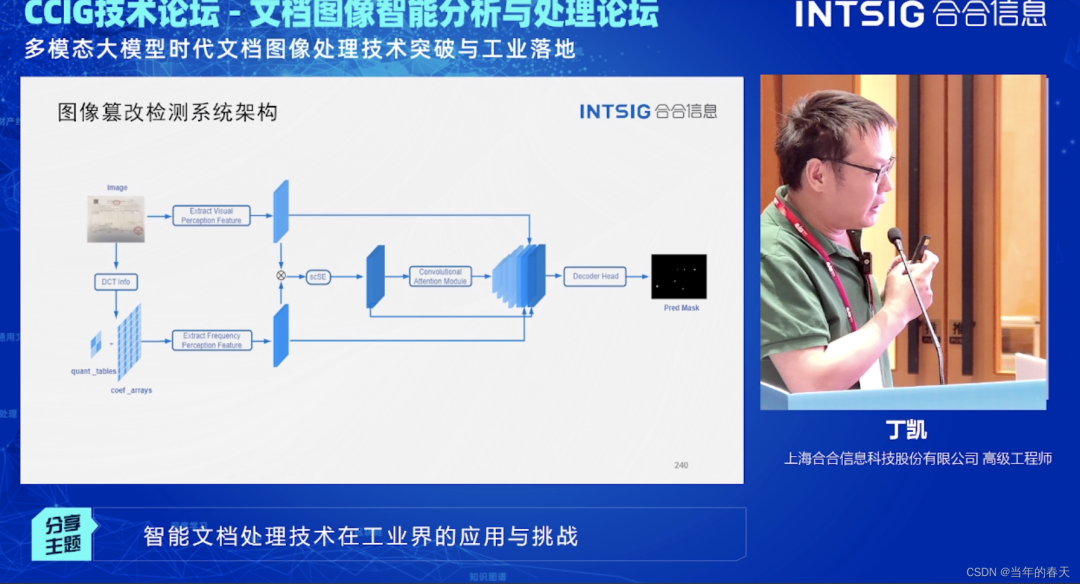
Обнаружение подделки изображения документа
С популяризацией электронного оборудования и программного обеспечения для обработки изображений порог и стоимость модификации изображений становятся все ниже и ниже. Сообщается, что подделка изображения делится на «глобальную подделку» и «локальную подделку», включая изменение насыщенности и контрастности изображения, а также улучшение цвета; локальная подделка включает копирование и вставку, сращивание и комбинирование, а также стирание. например, подделка карт и банкнот. Как правило, это частичное подделка, затрагивающая некоторые поля изображения, образцы печатей и т. д.

Безопасность содержания изображения – это Безопасность ИИизобласти внимания,Если следы подделки текста можно точно обнаружить,Будет обеспечена безопасность содержания изображений. Существует также полная системная архитектура для этого подделанного содержимого:
Мышление в эпоху больших моделей
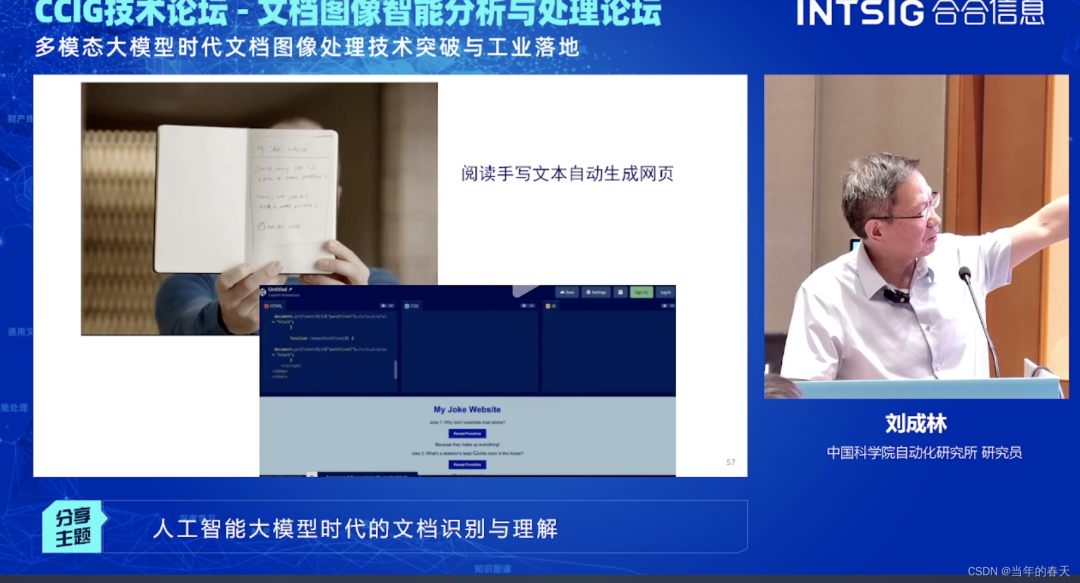
С появлением чата Gpt и Gpt4 в нашу жизнь незаметно вошла эра больших моделей. Друзья, посмотревшие конференцию GPT4, были шокированы сценой. Ведущий просто нарисовал в своем блокноте свои потребности для сайта, GPT умеет читать рукописные тексты. текст и быстро создавать веб-страницы. Как разработчик программы, я был крайне шокирован, когда увидел этот сценарий использования. Я подумал: «Это так здорово». Веб-сайт был создан всего за несколько минут. Я снова посмотрел на написанный мной код и подумал: «Берегите его, вы можете». время писать код.
Помимо прочего, GPT4 может объяснять комиксы:

С этой точки зрения разработка моделей OCR при распознавании больших моделей по-прежнему очень важна, а также открывает некоторые возможности:
- Большая модель все еще имеет много недостатков
- Необходимо в полной мере использовать представление крупных функций модели и возможности языка для решения более интеллектуальных сценариев распознавания.
- Специализированная модель для различных задач и алгоритм обучения еще могут многое предложить.
Подвести итог
С быстрым развитием технологий искусственного интеллекта интеллектуальная обработка документов стала горячей темой. Интеллектуальная технология обработки документов может помочь пользователям более эффективно получать, управлять и использовать информацию в документах, повышая эффективность работы пользователей и ценность документов. В то же время интеллектуальная технология обработки документов также обеспечивает более интеллектуальные и эффективные решения для обработки документов для предприятий, правительств и других учреждений.
Возможность интеллектуальной обработки документов заключается в том, что с наступлением информационного века количество и сложность документов продолжают увеличиваться, и традиционные методы обработки документов больше не могут удовлетворить потребности пользователей. Развитие технологий искусственного интеллекта предоставило более эффективные и точные решения для обработки документов, позволяющие лучше адаптировать обработку документов к потребностям информационного века. Технология интеллектуальной обработки документов может выполнять автоматическую обработку, интеллектуальный анализ, приложения искусственного интеллекта и т. д. для документов, реализуя автоматическую обработку документов, тем самым повышая потребительскую ценность и эффективность документов.
Эра больших моделей больше не ограничивается распознаванием документов, но также может использоваться для интерпретации изображений. Анализ и распознавание документов быстро развиваются, но пространство для исследований все еще остается большим, и это дало нам некоторые новые направления, такие как: извлечение семантической информации, кросс-модальное слияние, прикладно-ориентированное рассуждение и принятие решений и т. д.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
