Раш~! Быстро разверните ChatGLM3-6B в Linux, и фактические результаты тестирования будут хорошими! Поделитесь подробными инструкциями~~
введение
В минувшие выходные компания Zhipu AI представила на Китайской компьютерной конференции (CNCC) 2023 года полностью самостоятельно разработанную базовую модель ChatGLM3 третьего поколения, которая значительно улучшилась по сравнению с ChatGLM2 в различных задачах. Сегодня я наконец загрузил тест развертывания модели, и фактический эффект действительно лучше, чем у ChatGLM2.
Основываясь на реальном процессе работы, я составил документ о развертывании ChatGLM3, которым хочу поделиться с вами. Эта статья в основном состоит из шести частей: установка драйвера видеокарты, виртуальная среда Python, установка зависимостей ChatGLM3, подготовка файла модели, демонстрационный тест загрузки модели, адаптация интерфейса OpenAI и т. д. Если драйвер видеокарты и среда Python готовы, вы можете сразу перейти к следующему шагу. назад.
кроме того,Автор разобрался со всеми моделями и зависимостями установки.,Если вам нужен прямой ответ:chatglm3-6b
Сказал это впереди
Основная среда установки в этой статье: видеокарта Centos7 (8C24G), T4 (16G). Поскольку компьютер в лаборатории не может быть подключен к Интернету, эта статья в основном представляет собой автономную установку. Таким образом, весь установочный пакет разделен на три части: файлы зависимостей ChatGLM3, файлы модели ChatGLM3, ChatGLM3. WebПоказать файлы、Другие зависимые пакеты,Как показано ниже。«Примечание. Независимо от того, выполняете ли вы установку в автономном режиме или онлайн, просто скопируйте следующие файлы в соответствующий каталог и запустите демонстрационный тест непосредственно для запуска программы».,Так что начните прямо сейчас! ! !
1. Установка драйвера видеокарты.
[Вы можете пропустить его, если вы уже установили драйвер] Драйвер видеокарты необходим для запуска модели. Основное содержание этой части включает в себя: выравнивание модели драйвера видеокарты, установку зависимостей драйвера и установку видеокарты. Если вы уже установили драйвер видеокарты, вы можете пропустить этот шаг.
"Примечание":переписыватьсяLinuxВ плане машин,Для установки видеокарты требуется пользователь root,Пользователи приложения не могут быть использованы. Если вы установите и протестируете его самостоятельно,Нет проблем, если вы настроите его напрямую как пользователь root.,Если речь идет о приложениях корпоративного уровняили У пользователя есть ограничения на права доступа к машине,Вам необходимо обратиться к системному администратору, чтобы запросить права root.
1. Проверьте модель сервера:
cat /etc/redhat-release
2. Проверьте модель видеокарты сервера:
sudo lshw -numeric -C display или lspci | grep -i vga
3. Загрузите драйвер видеокарты.
Посетите официальный сайт Nvidia: https://www.nvidia.cn/Download/index.aspx?lang=cn, выберите версию, соответствующую модели вашей видеокарты, и загрузите ее. Как показано ниже:
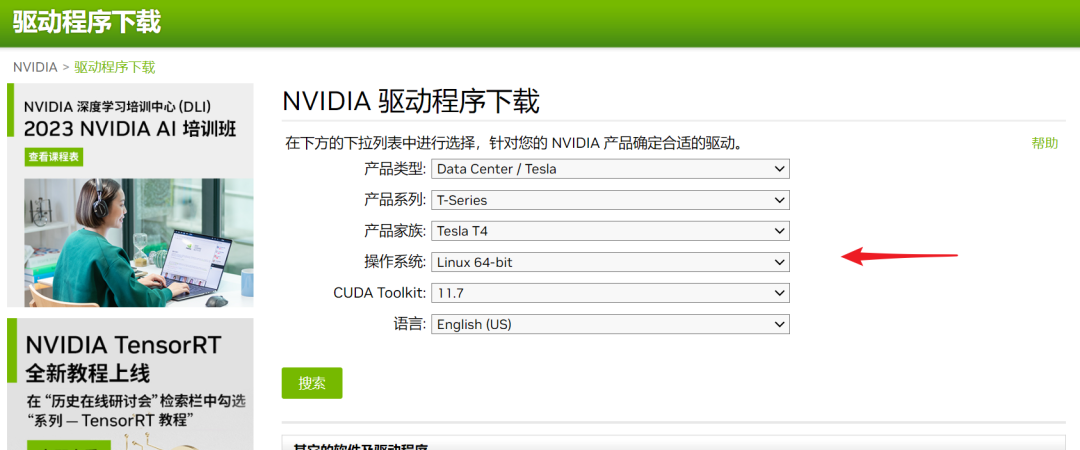
Я использую видеокарту T4 и операционную систему Centos7.9, поэтому я выбрал эту версию. Здесь следует также отметить, что версия CUDA Toolkit должна соответствовать версии Pytorch, Tensorflow и других используемых фреймворков. В настоящее время я вижу, что Pytorch может поддерживать CUDA до версии 11.8. Если драйвер вашей видеокарты такой же, как у меня, вы можете получить его непосредственно из моего пакета ресурсов, а именно: ./packages/NVIDIA-Linux-x86_64-515.105.01.run
4. Установите GCC, компоненты ядра, dkms и другие связанные зависимости.
yum install gcc
yum install gcc-c++
yum -y install kernel-devel
yum -y install kernel-headers
yum -y install epel-release
yum -y install dkms
5. Закрытый модерн.
Среди них Nouveau — это 3D-драйвер с открытым исходным кодом, разработанный третьей стороной для видеокарт NVIDIA, который не распознается и не поддерживается NVIDIA. Хотя Nouveau Gallium3D далеко не сравним с официальным частным драйвером NVIDIA с точки зрения скорости игры, он облегчает Linux работу с различными сложными средами видеокарт NVIDIA, позволяя пользователям войти на рабочий стол после установки системы и получить хорошие эффекты отображения. Поэтому многие дистрибутивы Linux по умолчанию интегрируют драйвер Nouveau и устанавливают его по умолчанию при работе с видеокартами NVIDIA. Это особенно актуально для корпоративной версии Linux. Почти все корпоративные дистрибутивы Linux, поддерживающие графические интерфейсы, включают Nouveau.
Для отдельных пользователей настольных компьютеров Nouveau на этапе роста не идеален. В отличие от корпоративной версии, отдельным пользователям часто требуются некоторые 3D-специальные эффекты в дополнение к обычному отображению графического интерфейса, и пользователи в большинстве случаев не могут этого сделать. При установке официального частного драйвера NVIDIA Nouveau снова становится препятствием. Если Nouveau не отключен, во время установки всегда появляется сообщение об ошибке: ОШИБКА: В настоящее время вашей системой используется драйвер ядра Nouveau. несовместим с драйвером NVIDIA…
- 1) Проверьте, работает ли Nouveau:
lsmod | grep nouveau
- 2) Измените файл конфигурации черного списка системы.,Перейдите в папку /etc/modprobe.d.,Найдите файл со словами blacklist.conf. Измените файл конфигурации через vim,Добавьте в файл следующее содержимое,наконец сохранено с помощью !wq.
blacklist nouveau
blacklist lbm-nouveau
options nouveau modeset=0
alias nouveau off
alias lbm-nouveau off
- 3) Обновить параметры сервера ядра.(Если первая команда не работает,Можешь попробовать второй)
update-initramfs -u или ВОЗ dracut --force
- 4) Перезагрузите сервер
reboot
- 5) Еще раз проверьте, работает ли nouveau. Если нет, значит, nouveau полностью закрыт.
lsmod | grep nouveau
5. Установите драйвер видеокарты.
Скопируйте драйвер на сервер и выполните следующую команду (при возникновении ошибки установки см. пункт 6 ниже):
chmod +x NVIDIA-Linux-x86_64-515.105.01.run
sh NVIDIA-Linux-x86_64-515.105.01.run
6. Устранение ошибок установки видеокарты.
В процессе установки основная ошибка, с которой я столкнулся, была: ОШИБКА: Невозможно найти дерево исходного кода для текущего ядра...
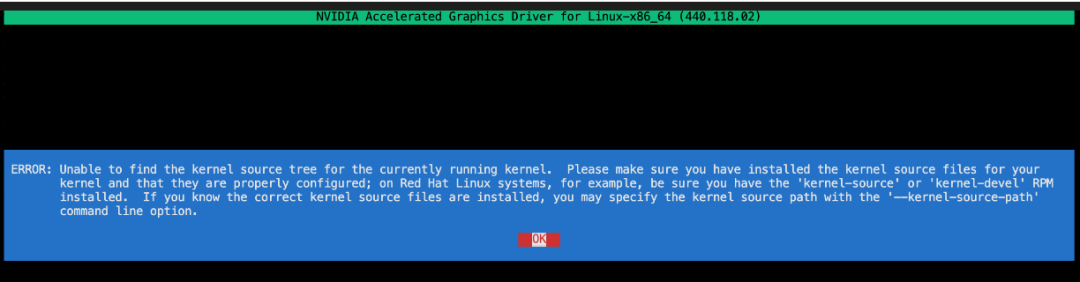
Когда я столкнулся с этой проблемой, я прочитал много примеров в Интернете и суммирую их здесь. Эта ошибка означает, что версия ядра, работающая в операционной системе, несовместима с kernel-devel. Просто совместите две версии здесь. Конкретные операции заключаются в следующем:
- 1) Проверьте номер Ядро работающей версии системы.
cat /proc/version
- 2) Перечислите все ресурсы, связанные с Ядро, в текущей системе.
rpm -qa | grep kernel
- Или напрямую перечислите установленные версии kernel-devel и kernel-headers.
yum info kernel-devel、kernel-headers
Как показано ниже:
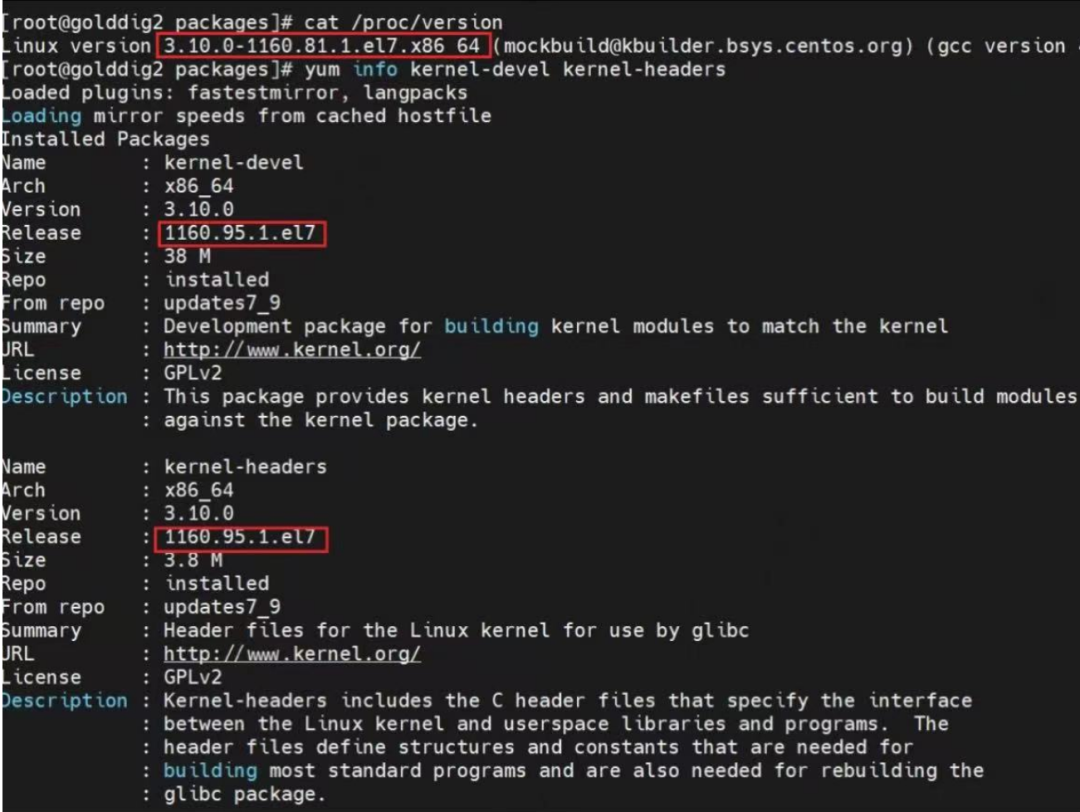
Можно обнаружить, что номер ядра, работающего на сервере, отличается от номеров версий kernel-devel и заголовков ядра. В настоящее время существует два метода: один — совместить номер версии ядра сервера с номерами версий ядра-devel и заголовков ядра. Другой — совместить номера версий ядра-devel и заголовков ядра с номером ядра. Серверная система работает.
- 1) Системный номер Ядро совпадает с номером kernel-devel и другими номерами.
# Установите соответствующую систему Ядро в соответствии с номером ядра-разработки.
yum install kernel-3.10.0-1160.95.1.el7.x86_64
# Настройте систему на запуск версии Ядро по умолчанию.
grub2-set-default kernel-3.10.0-1160.95.1.el7.x86_64
# перезапустить сервер
reboot
# Снова войдите в сервер и проверьте рабочий номер системы.
cat /proc/version
- 2) Совместить kernel-devel и другие цифры с системным номером Ядро (здесь, если системный номер Ядро: kernel-3.10.0-1160.95.1.el7.x86_64)
# Установите соответствующие ядра-devel и заголовки ядра в соответствии с системным номером Ядро.
yum install kernel-headers-3.10.0-1160.95.1.el7.x86_64
yum install kernel-devel-3.10.0-1160.95.1.el7.x86_64
Независимо от описанного выше метода, результат будет таким, как показано на рисунке ниже. На этом этапе выполните команду из шага 5 выше, чтобы установить драйвер видеокарты.
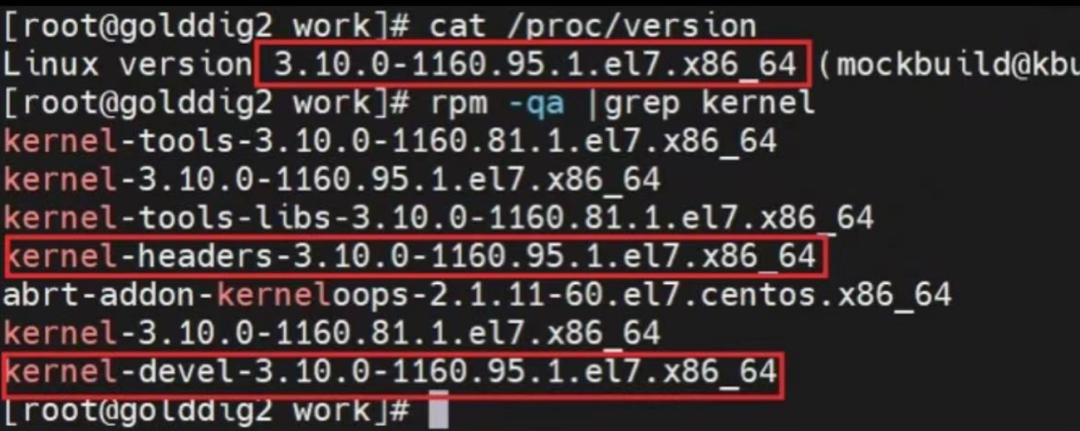
Кроме того, если есть другие сервисы, требующие предыдущее ядро, то нужно переключить ядро для сервера. Конкретные операции заключаются в следующем:
# войти в/boot/grub2или ВОЗ/etcНиже каталога,Среди них: файл /etc/grub2.cfg — это ссылка на файл.,Фактическая ссылка на /boot/grub2/grub.cfg
#Проверьте, есть ли: grub.cfg, если нет, то нужно его создать.
grub2-mkconfig -o /boot/grub2/grub.cfg
#Просмотреть текущий Ядро
grub2-editenv list
#Просмотреть установленное Ядро
awk -F' '$1=="menuentry " {print i++ " : " $2}' /boot/grub2/grub.cfg
# Установить версию запуска по умолчанию
grub2-set-default xx #xx — это номер Ядро, который вы видите.
# Пересобрать файл конфигурации Ядро
grub2-mkconfig -o /boot/grub2/grub.cfg
# Перезапуск вступает в силу
reboot
После решения проблемы с ошибкой в соответствии с вышеуказанным методом выполните следующие действия. 5) шаг Выполните команду установки видеокарты,наконец проверьте, прошла ли установка видеокарты успешно через nvidia-smi. Конкретные команды следующие:
# Выполните команду установки видеокарты
chmod +x NVIDIA-Linux-x86_64-515.105.01.run
sh NVIDIA-Linux-x86_64-515.105.01.run
# Следуйте приведенной выше команде, чтобы завершить установку, и выполните следующую команду, чтобы проверить, прошла ли установка успешно.
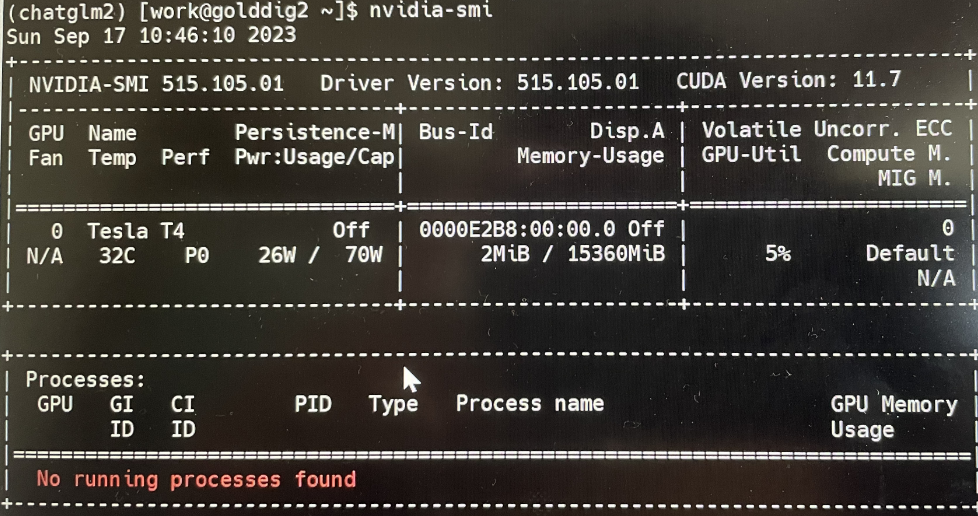
nvidia-smi
Скриншот наконец показан ниже:
2. Создание виртуальной среды Python
1. Зачем устанавливать среду виртуальной машины Python?
Ответ: На сервере вам может потребоваться запустить несколько моделей. Каждая модель зависит от другой версии Python или зависимой версии пакета. Например: модель A зависит от версии Python2.7, Transformers == 4.30.2, а модель B зависит. Версия Python3.8, Transformers==4.26.1 требует изоляции среды виртуальной машины Python; Если ваш сервер в будущем будет запускать только эту модель, вы можете проигнорировать этот шаг, и проблем не возникнет.
2. Способ создания виртуальной среды Python
Вероятно, существует два основных метода создания среды виртуальной машины Python: один — установить библиотеку virtualenv для реализации управления средой виртуальной машины Python, другой — использовать conda; Поскольку я использовал conda с самого начала, я не очень знаком с virtualenv, поэтому здесь я в основном рассказываю, как создать виртуальную среду Python с помощью conda. Если кто-то интересуется virtualenv, на Baidu должно быть много руководств.
3. Знакомство с Миникондой
Лично я предпочитаю Miniconda, я могу скачать и установить любые библиотеки, которые мне нужны. Ниже приведено сравнение Миниконды и Анаконды. Это два очень популярных дистрибутива Python. Miniconda содержит только самые основные инструменты и библиотеки и требует ручной установки других инструментов. Anaconda — это полный дистрибутив, содержащий множество важных инструментов и библиотек. По сравнению с Anaconda, Miniconda более легкая и гибкая, подходит для тех, кому необходимо переключаться в разных средах.
4. Установка Миниконды
- 1) Получите установочный пакет Miniconda: Поскольку в Chatglm3 используется фреймворк pytorch, согласно рекомендациям официального сайта, здесь выбрана версия python3.8.
«Метод 1» Перейдите прямо к статье наконец,Получите метод наконец,в другом пакете.
«Метод 2» Поскольку Miniconda поставляется с Python, вам необходимо загрузить версию Miniconda с Python версии 3.8 с официального сайта. Адрес загрузки: https://docs.conda.io/en/latest/miniconda.html#linux-installers. Ниже приведены конкретные снимки экрана.
- 2) Установите Миниконду
Поместите пакет загрузки и установки Miniconda в каталог, в который вы хотите его поместить. Я разместил его здесь: /home/work/miniconda. , а затем выполните sh Miniconda3-latest-Linux-x86_64.sh Как показано ниже:

После выполнения просто следуйте подсказкам и нажмите Enter.,Примечание: наконец Выберите «да»,Таким образом, каждый раз, когда вы начинаете,Он автоматически переключит вас в базовую среду Conda.
- 3) Создайте среду виртуальной машины.
miniconda поддерживает создание нескольких виртуальных сред для поддержки различных версий (python) кода. Здесь создается отдельная среда виртуальной машины Python с именем: Chatglm3-, которая будет установлена и запущена в этой среде позже. зависимости модели 6б. Ниже приведены команды и скриншоты:
conda create -n chatglm3 # Если вы можете подключиться к Интернету, вы можете напрямую выполнить эту команду. Если вы не можете ее установить, выполните следующую команду с помощью «клонирования».
илиconda create -n chatglm3 --clone base # Примечание. Поскольку это автономная установка, выберите метод клонирования для ее создания. Если вы создаете ее напрямую, будет сообщено об ошибке, поскольку это автономная установка.
conda env list # Получить список среды
conda activate chatglm3 # Переключить среду Chatglm3
- 4) Настройки среды виртуальной машины Python по умолчанию
Если вам нужно использовать среду Chatglm3 по умолчанию каждый раз, когда вы входите в машину, вы можете настроить ее следующим образом. (Этот шаг не обязателен!)
vi ~/.bashrc
# Место происхождения: Конда activate chatglm3
# Просто выполните следующую команду
source ~/.bashrc
3. Установка зависимостей Chatglm3
1. Скопируйте пакет зависимостей Chatglm3: Chatglm3-Dependence в: /home/work/chatglm3/. (Здесь работой может быть ваше собственное имя пользователя) Как показано ниже:

2. Устанавливаем через pip, команда такая:
pip install --no-index --find-links=/home/work/chatglm3/chatglm3-dependence -r requirements.txt
3. Научите его ловить рыбу (не обязательно) Все зависимости в чатглм3-зависимости в основном загружаются через требования.txt по адресу https://github.com/THUDM/ChatGLM3/tree/main. Команда загрузки для связанных пакетов зависимостей:
pip download -d ./chatglm3-dependence -r requirements.txt
4. Подготовка файла модели.
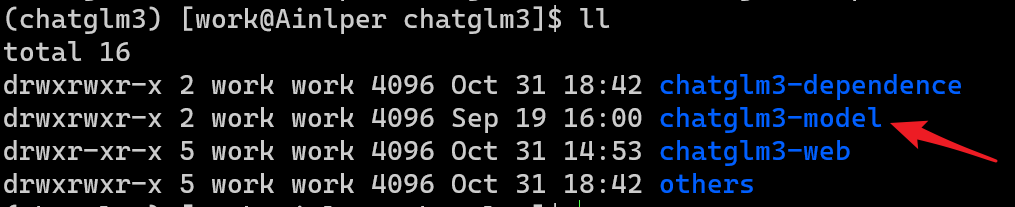
1. Скопируйте файл моделиchatglm3:chatglm3-model в: /home/work/chatglm3/. Как показано ниже
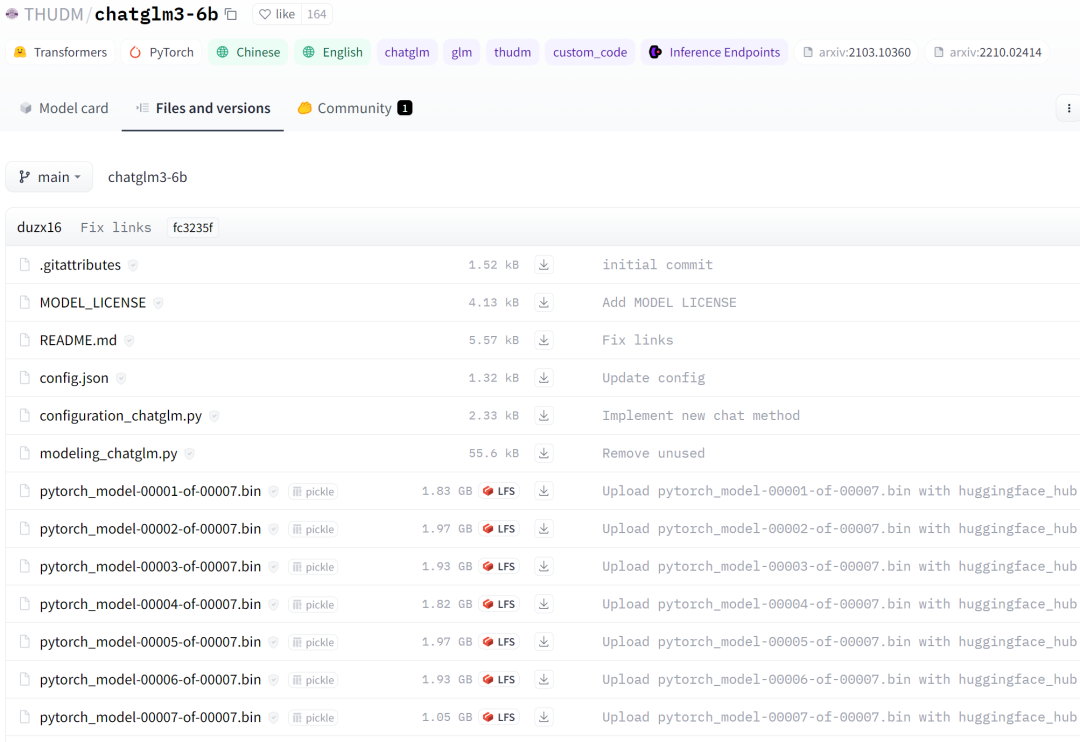
2. Научите его ловить рыбу (необязательно). Файл модели можно скачать по адресу https://huggingface.co/THUDM/chatglm3-6b. Конкретные скриншоты приведены ниже:
5. Демо-тест загрузки модели
Что касается отображения демонстрации загрузки модели, официальный сайт в настоящее время предоставляет три метода: командная строка, веб-версия на основе Gradio и веб-версия на основе Streamlit. Вот как это сделать.
1. Сначала скопируйте Chatglm-web в: /home/work/chatglm3/. Как показано ниже

2. Способ 1: Демо-тест модели из командной строки: перейдите в папку Chatglm-web и измените адрес пути к модели в файле cli_demo.py, как показано на рисунке ниже.
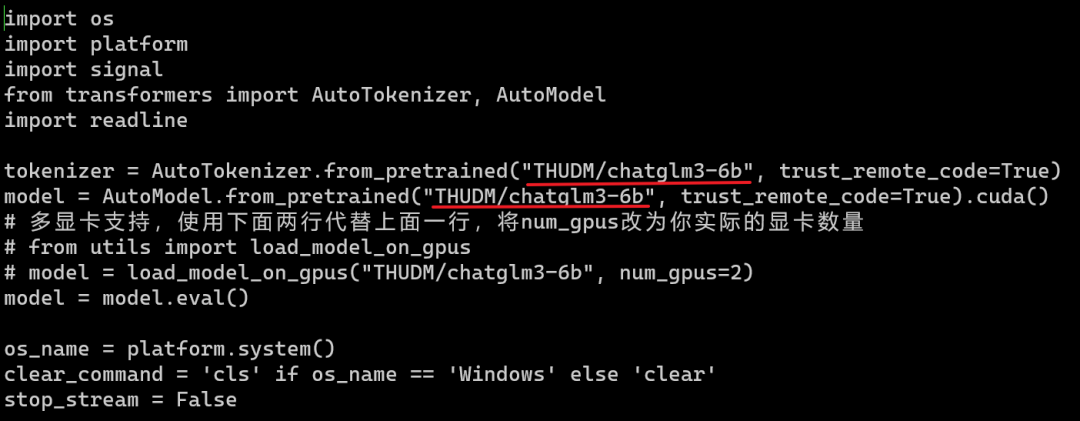
В частности, измените приведенный выше путь «THUDM/chatglm3-6b» на свой собственный путь к файлу модели: /home/work/chatglm3/chatglm3-model. Результат после изменения будет следующим:
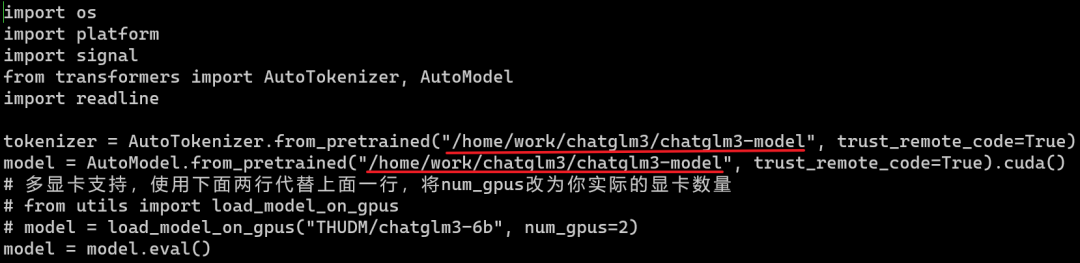
наконец,вк! Сохраните измененную информацию. Здесь следует отметить одну вещь: используйте как можно больше абсолютных путей.,Я видел, как кто-то использовал относительный путь при развертывании.,Невозможно найти при загрузке Модель. После изменения файла конфигурации,Выполните следующую команду,Вы можете запустить скрипт напрямую.
python cli_demo.py
Скриншот запуска выглядит следующим образом:

3. Способ 2: запустить демо-тест загрузки модели через веб-версию на базе Gradio.
Подобно методу 1, здесь вы в основном изменяете файл конфигурации web_demo.py и меняете «THUDM/chatglm3-6b» на свой собственный путь к файлу модели. Затем выполните следующую команду, чтобы запустить скрипт напрямую.
python web_demo.py
Кроме того, если вы хотите указать IP-адрес и порт, на котором работает служба, вы можете изменить его следующим образом.

4. Способ 3, запустить демо-тест загрузки модели через веб-версию на базе Streamlit.
Подобно методу 1, здесь вы в основном изменяете файл конфигурации web_demo2.py и меняете «THUDM/chatglm3-6b» на свой собственный путь к файлу модели. Затем выполните следующую команду, чтобы запустить скрипт напрямую. Кроме того, этот метод позволяет напрямую указывать порт и IP-адрес службы с помощью команд.
streamlit run web_demo2.py --server.address='0.0.0.0' --server.port=8099
6. Адаптация интерфейса OpenAI
Реализовано развертывание потокового API в формате OpenAI. То есть, если вы ранее вызывали интерфейс ChatGPT, вы можете плавно переключиться на Chatglm3-6b. Конкретный метод реализации заключается в следующем:
1. Перейдите в /home/work/chatglm3/chatglm3-web, измените файл openai_api.py и измените путь к файлу модели. Если вы хотите изменить порт службы, вы можете изменить параметр порта ниже, здесь он изменен. на порт 8099.
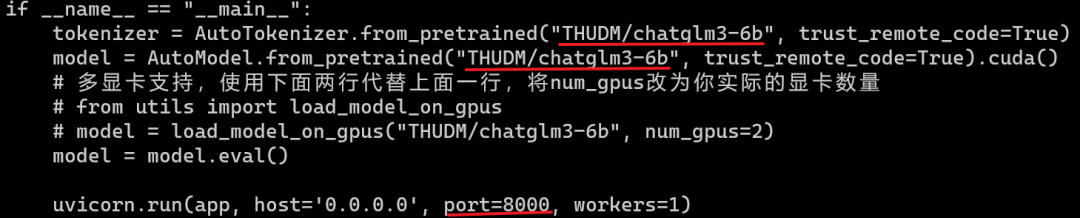
2. Затем запустите службу
python openai_api.py
3. Проверьте доступность службы. Пример кода для вызова API:
import openai
if __name__ == "__main__":
openai.api_base = "http://xxx.xxx.xxx.xxx:8099/v1"
openai.api_key = "none"
for chunk in openai.ChatCompletion.create(
model="chatglm3-6b",
messages=[
{"role": "user", "content": "Привет"}
],
stream=True
):
if hasattr(chunk.choices[0].delta, "content"):
print(chunk.choices[0].delta.content, end="", flush=True)
наконец
Выше приведен весь процесс развертывания автора,Фактически, Университет Цинхуа также подготовилКомплексная демонстрация, объединяющая следующие три функции:он содержит режим разговора、режим инструмента、шаблон кода,Сегодня из-за нехватки времени еще не пришел развертывать,Мне понадобится время, чтобы наверстать упущенное на этой неделе.,благодарныйсосредоточиться на



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
