РАГ или доводка? Microsoft выпустила руководство по процессу построения больших моделей приложений в конкретных областях
Отчет о сердце машины
Редактор: Рим
Генерация с расширенным поиском (RAG) и точная настройка — два распространенных метода повышения производительности больших языковых моделей. Какой же метод лучше? Что более эффективно при создании приложений в конкретной области? Этот документ от Microsoft предназначен для справки при выборе.
Обычно существует два распространенных подхода к включению собственных и специфичных для предметной области данных при создании приложений с большими языковыми моделями: генерация расширений поиска и точная настройка. Расширение поиска генерирует подсказки, дополненные внешними данными, а точная настройка интегрирует дополнительные знания в саму модель. Однако преимущества и недостатки этих двух методов до конца не изучены.
В этой статье исследователи из Microsoft представляют новый фокус: создание помощников ИИ для отрасли (сельского хозяйства), которая требует особого контекста и адаптивных ответов. В этой статье представлен комплексный конвейер больших языковых моделей для создания высококачественных отраслевых вопросов и ответов. Этот подход предполагает систематический процесс выявления и сбора соответствующих документов, охватывающих широкий спектр сельскохозяйственных тем. Затем эти документы очищаются и структурируются для создания осмысленных пар вопрос-ответ с использованием базовой модели GPT. Сгенерированные пары вопрос-ответ затем оцениваются и фильтруются по их качеству.
Целью этой статьи является создание ценного ресурса знаний для конкретной отрасли на примере сельского хозяйства с конечной целью внести вклад в развитие LLM в сельскохозяйственной области.

- Адрес статьи: https://arxiv.org/pdf/2401.08406.pdf.
- Название статьи: RAG против тонкой настройки: трубопроводы, компромиссы и практический пример сельского хозяйства
Процесс, предложенный в этой статье, направлен на создание вопросов и ответов, специфичных для предметной области, которые отвечают потребностям профессионалов и заинтересованных сторон в отрасли, где ответы, ожидаемые от помощника по искусственному интеллекту, должны основываться на соответствующих отраслевых факторах.
В этой статье речь идет о сельскохозяйственных исследованиях.,Цель состоит в том, чтобы получить ответы для этой конкретной области. Итак, отправной точкой исследования является сельское хозяйство. Набор данных,это введеноприезжатьтрииндивидуальныйв основных компонентах:Генерация вопросов и ответов, генерация расширений поиска итонкая настройка процесса。Вопросы и ответы, созданные на основе сельского хозяйства Набор Информация в данных используется для создания вопросов и ответов, а функция улучшения поиска использует ее в качестве источника знаний. Полученные данные уточняются и используются для тонких настройкамногоиндивидуальный Модель,Его качество оценивается набором предложенных метрик. Благодаря этому комплексному методу,Использование возможностей модели большого языка,Приносит пользу сельскохозяйственной отрасли и другим заинтересованным сторонам.
Эта статья внесла особый вклад в понимание больших языковых моделей в области сельского хозяйства. Этот вклад можно резюмировать следующим образом:
1、Комплексная оценка LLM:Эта статья о Большая языковая модель была тщательно оценена, в том числе LlaMa2-13B、GPT-4 и Викунья, чтобы ответить на вопросы, связанные с сельским хозяйством. Для оценки использовался базовый набор данных из основных стран-производителей сельскохозяйственной продукции. В анализе этой статьи GPT-4 Всегда поверхность лучше, чем у других моделей, но нужно учитывать и ее тонкую поверхность. настройкаи Затраты, связанные с рассуждениями.
2、Технология поиска итонкая настройкавернопроизводительностьвлияние:В этой статье изучается Технология поиска итонкая настройкаверно LLMs Влияние производительности. Исследования показывают, что улучшение поиска приводит к итонкой настройка – это улучшение LLMs Эффективная технология для производительности.
3、Влияние потенциального применения LLM в различных отрасляхкольцо:верно Вхочу построить RAG итонкая Технология настройки в LLMs Что касается процесса, используемого в,Эта статья представляет собой революционный шаг,И способствует инновациям и сотрудничеству между многими компаниями.
метод
Статья № 1 2 Часть подробного введения использует теорию методов, включая процесс получения данных, процесс извлечения информации, генерацию вопросов и ответов, а также тонкую модель Модели. настройка. Тезис о методе вращается вокруг индивидуального подхода, предназначенного для создания и оценки процесса вопросов и ответов для создания помощников, ориентированных на конкретную предметную область, как показано ниже. 1 показано.
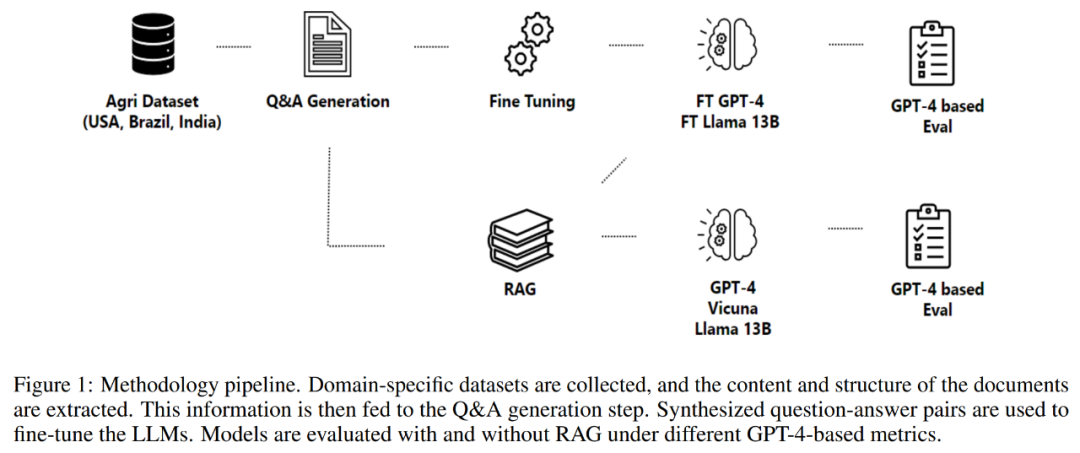
Процесс начинается со сбора данных, который включает получение данных из различных высококачественных хранилищ, таких как государственные учреждения, базы научных знаний, а также использование собственных данных, когда это необходимо.
После завершения сбора данных процесс продолжает извлекать информацию из собранных документов. Этот шаг имеет решающее значение, поскольку он включает в себя анализ сложных и неструктурированных данных. PDF файл для восстановления его содержимого и структуры. Изображение ниже 2 Показывает набор данных PDF Пример файла.

Следующим компонентом процесса является генерация вопросов и ответов. Целью здесь является создание качественных вопросов с учетом контекста.,Точно отразить содержание извлеченного текста. В этом методе статьи используется индивидуальная структура для управления структурным составом ввода и вывода.,Тем самым усиливая общий эффект языка, генерирующего ответы Модели.
впоследствии,Процессы генерируют ответы на сформулированные вопросы. Используемый здесь метод использует преимущества генерации расширений поиска.,Сочетает в себе возможности механизмов поиска и генерации.,создавать качественные ответы.
Наконец, процесс проходит Q&A вернотонкая настройка Модель。В процессе оптимизации используется корректировка низкого ранга.(LoRA)ждатьметод,Обеспечить всестороннее понимание содержания и контекста научной литературы.,Что делает его ценным ресурсом для различных областей или областей.
Набор данных
В исследовании оценивалось влияние тонкая настройки получения расширенной сгенерированной языковой модели с использованием контекстно-зависимых вопросов и ответов. данных,Этот Набор данных взят из трех основных стран-производителей сельскохозяйственных культур: США, Бразилии и Индии. В случае с этой статьей,Сельское хозяйство как основа промышленности. Доступные данные сильно различаются по формату и содержанию.,Охватывает нормативные документы、научный отчет、База данных сельскохозяйственных экспертиз и знаний и другие типы.
Эта статья опубликована Министерством сельского хозяйства США.、Общедоступные онлайн-документы государственных органов сельского хозяйства и бытового обслуживания и т. д.、Информация собрана в руководстве и отчете.
Доступные документы включают федеральные постановления и политическую информацию по управлению растениеводством и животноводством, болезням и передовому опыту.,Гарантия качества и правила экспорта,Подробности программы помощи,и страхованиеи Руководство по ценообразованию。собранныйданные Общая сумма превышает 23,000 индивидуальный PDF файлы,содержащие более 5000 Десять тысячиндивидуальный токены, охватывающие Соединенные Штаты 44 индивидуальный Чжоу. Исследователи загрузили и предварительно обработали эти файлы, чтобы извлечь текстовую информацию, которую можно было бы использовать в качестве входных данных для процесса генерации вопросов и ответов.
Для точного бенчмаркинга и оценки модели, этой статье используются Документы, относящиеся к штату Вашингтон, в том числе 573 индивидуальныйфайлы,содержащие более 200 Десять тысячиндивидуальный жетоны. Следующий список 5 Показаны примеры содержимого этих файлов.

метрики
Основная цель этого раздела — создать полный набор показателей.,Целью является руководство оценкой качества процесса генерации вопросов и ответов.,Особенно вертонкая Настройка поиска улучшает оценку сгенерированного метода.
При разработке метрик,Есть несколько ключевых факторов, которые необходимо учитывать. первый,Субъективность, присущая качеству вопросов, представляет собой серьезную проблему.
Во-вторых, метрики должны учитывать актуальность, практичность, верную контекстную зависимость проблемы перемещения.
третий,Необходимо оценить новизну возникшей проблемы. Мощная система генерации вопросов должна быть способна генерировать широкий спектр вопросов, охватывающих все аспекты данного контента. Однако,верно Разнообразиеи Количественная оценка новизны может быть сложной задачей,Потому что это касается уникальности оценочных вопросов приезжать и их схожести по содержанию с другими вопросами генерации.
Наконец, на хорошие вопросы должна быть возможность ответить на основе предоставленного содержания. Оценка того, можно ли точно ответить на вопрос, используя доступную информацию, требует глубокого понимания содержания и способности идентифицировать соответствующую информацию для ответа на вопрос.
Эти метрики играют важную роль в обеспечении того, чтобы ответы, предоставленные Моделью, отвечали на ваши вопросы точно, актуально и эффективно. Однако существует существенная нехватка показателей, специально предназначенных для оценки качества вопросов.
Отсутствие сознания приезжать,В данной статье основное внимание уделяется разработке метрик, предназначенных для оценки качества вопросов. Учитывайте решающую роль вопросов о прибытии в формирование осмысленных верных высказываний, которые генерируют полезные ответы.,Обеспечение качества ваших вопросов так же важно, как и обеспечение качества ваших ответов.
метрики, разработанные в этой статье, призваны заполнить пробелы в предыдущих исследованиях в этой области.,Предоставляет средства всесторонней оценки качества вопросов.,Это окажет существенное влияние на ход процесса генерации вопросов и ответов.
оценка проблемы
Метрики, разработанные в этой статье для задачи оценки, следующие:
- Актуальность
- общая ситуация Актуальность
- Покрытие
- Перекрывать
- Разнообразие
- Уровень детализации
- беглость
Оценка ответа
Поскольку большие языковые модели имеют тенденцию генерировать длинные, подробные и информативные разговорные ответы, оценить ответы, которые они генерируют, сложно.
В этой статье используются модели оценки AzureML. Для сравнения сгенерированного ответа с реальной ситуацией используйте следующие метрики:
- Согласованность: сравнивает согласованность между фактическими условиями и прогнозами с учетом контекста.
- Актуальность: измеряет, насколько эффективно ответ отвечает на основные аспекты вопроса в контексте.
- Подлинность: определяет, соответствует ли ответ логически информации, содержащейся в контексте.,И укажите индивидуальную целую дробь, чтобы определить достоверность ответа.
Оценка модели
Оценивать разные тонкие настройка Модель,В этой статье используется GPT-4 в качестве оценщика. использовать GPT-4 Создано на основе сельскохозяйственной документации ок. 270 индивидуальные вопросы и ответы правда, как в реальной ситуации Набор данных。верно Ю каждыйиндивидуальныйтонкая настройка Модели, улучшение поиска генерирует Модели, генерирует ответы на эти вопросы.
Эта статья о LLM провела несколько оценок различных показателей:
- Оценка с помощью руководящих принципов:верно Ю каждыйиндивидуальный Вопросы и ответы по реальной ситуацииверно,Советы из этой статьи GPT-4 Создайте руководство по оцениванию, в котором будет указано, что должен содержать правильный ответ. Тогда ГПТ-4 Вам будет предложено оценить каждый индивидуальный ответ на основе критериев, указанных в Руководстве по оцениванию, с баллами в диапазоне от 0 приезжать 1. Вот пример:
- Простота:Создал краткое описаниеи Длинные ответы могут содержать оценки контента.поверхность。Судя по этому рейтингуповерхность、Ответ на реальную ситуацию и LLM Ответить на советы GPT-4 и требует 1 приезжать 5 Баллы выставлены.
- правильность:Эта статья создалаиндивидуальный Полное описание、Частично правильные или неправильные ответы должны содержать оценку поверхности контента. На основе этого рейтинга、Ответ на реальную ситуацию и LLM Ответить на советы GPT-4 и требует оценки правильного, неправильного или частично правильного.
эксперимент
Эксперимент в этой статье разделен на несколько независимых экспериментов, каждый из которых ориентирован на генерацию и оценку вопросов и ответов, улучшение поиска и генерацию итонкой. Особенности настройки.
Эти эксперименты исследуют следующие области:
- Качество вопросов и ответов
- контекстное исследование
- Модель для расчета метрики
- Сравнение комбинированной генерации и раздельной генерации
- Поиск исследований по абляции
- тонкая настройка
Качество вопросов и ответов
Эксперимент оценивает три индивидуальных больших языка Модель,Это GPT-3, GPT-3.5 и GPT-4.,Качество вопросов и ответов, создаваемых в различных контекстных условиях. Оценка качества на основе множества индивидуальных показателей,включать Актуальность、Покрытие、Перекрыватьи Разнообразие。
контекстное исследование
Эксперимент изучает влияние различных настроек контекста на генерацию вопросов и ответов. Он оценивает сгенерированные вопросы и ответы в трех контекстных настройках: без контекста, контекст и внешний контекст. Пример индивидуального варианта приведен на поверхности 12.

В контекстно-свободной среде GPT-4 имеет самый высокий охват среди трех насадок по размеру.,поверхность показывает, что она может покрывать больше частей текста,Но возникающие в результате вопросы более длинные. Однако,трииндивидуальный Модельсуществовать Разнообразие、Перекрывать、Числовые значения Актуальности ибеглости аналогичны.
Когда контекст включен, с GPT-3 По сравнению с GPT-3,5 охват несколько увеличился, в то время как GPT-4 Поддержал самый высокий охват. для Size Prompt,GPT-4 имеет наибольшее числовое значение,поверхность демонстрирует свою способность генерировать более длинные вопросы и ответы.
существовать Разнообразиеи Перекрыватьаспект,трииндивидуальный Модельповерхность Похожий。верно ВАктуальностьибеглость,По сравнению с другой моделью,GPT-4 немного увеличился.
В настройках внешнего контекста аналогичная ситуация.
также,Наблюдайте каждый раз,Кажется, нет настроек контекстасуществоватьсредний охват、Разнообразие、Перекрывать、Актуальностьибеглостьаспектдля GPT-4 Обеспечивает наилучший баланс, но дает более короткие вопросы и ответы. Настройка контекста привела к небольшому уменьшению других показателей для более длинных вопросов и ответов, за исключением размера. Настройка внешнего контекста вызвала самые длинные вопросы и ответы, но сохранила средний охват и была в среднем Актуальностьибеглостнемного. увеличился.
В целом, для GPT-4, бесконтекстная настройка, кажется, обеспечивает лучший баланс с точки зрения среднего охвата, Разнообразия, Перекрытия, Актуальности ибеглости, но генерирует более короткие ответы. Настройки контекста привели к увеличению длины подсказок и небольшому снижению других показателей. Настройка внешнего контекста генерировала самые длинные подсказки, но сохраняла средний охват и была в среднем Актуальностьибеглостнемного. увеличился.
поэтому,Выбор между этими тремя будет зависеть от конкретных требований задачи. Если длина приглашения не учитывается,то из-за более высокого показателя Актуальностиибеглости,Внешний контекст, вероятно, лучший выбор.
Модель для расчета метрики
В ходе эксперимента метрики сравнивались с производительностью GPT-3.5 и GPT-4 в расчетах, используемых для оценки качества ответов на вопросы.
В целом, однако GPT-4 Сгенерированные вопросы и ответы обычно оцениваются как более беглые и контекстуальные, но не такие последовательные, как GPT-3.5 По сравнению с рейтингами Их Разнообразиеи Актуальность ниже. Эти точки зрения имеют решающее значение для понимания того, как разные авторы воспринимают и оценивают качество создаваемого контента.
Сравнение комбинированной генерации и раздельной генерации
В этом эксперименте исследуются плюсы и минусы создания вопросов и ответов по отдельности, а не их комбинирования, с акцентом на токен «Сравнение по эффективности использования».
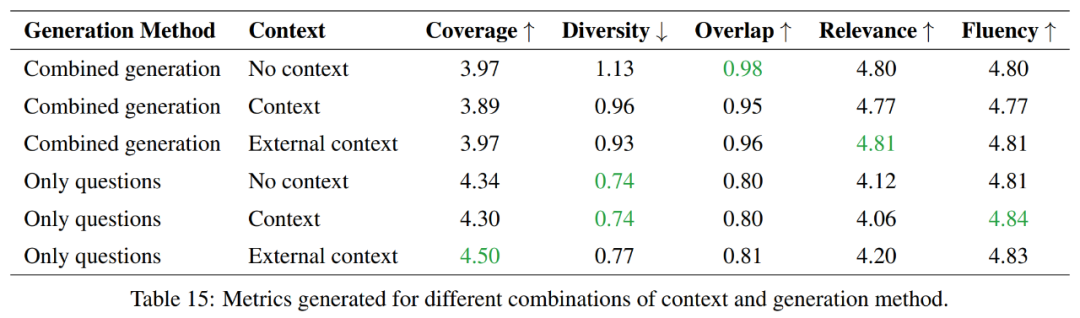
в общем,Только тот метод, который генерирует вопрос, обеспечивает лучшее раскрытие, меньшее разнообразие.,А метод комбинированной генерации имеет более высокие оценки в Перекрытии Актуальность. С точки зрения беглости,Два видаметодповерхность Похожий。поэтомусуществоватьэтот Два видаметодмеждуиз Выбор будет зависеть от ВЗадачаиз Особые требования。
Если цель состоит в том, чтобы охватить больше информации и сохранить больше разнообразия,Тогда популярнее будет метод, который только порождает вопросы. Однако,Если вы хотите поддерживать высокий уровень перекрытия с исходным материалом,Тогда комбинированное поколение метода будет лучшим выбором.
Поиск исследований по абляции
Этот индивидуальный эксперимент оценивает поисковые возможности генерации улучшений поиска - метода, который расширяет присущие LLM знания, предоставляя дополнительный контекст во время ответов на вопросы.
В этой статье изучается влияние количества извлеченных фрагментов (т. е. top-k) на результаты и представлены результаты в Таблице 16. Рассматривая больше фрагментов, генерация с расширенными возможностями поиска позволяет более последовательно восстанавливать исходные фрагменты.
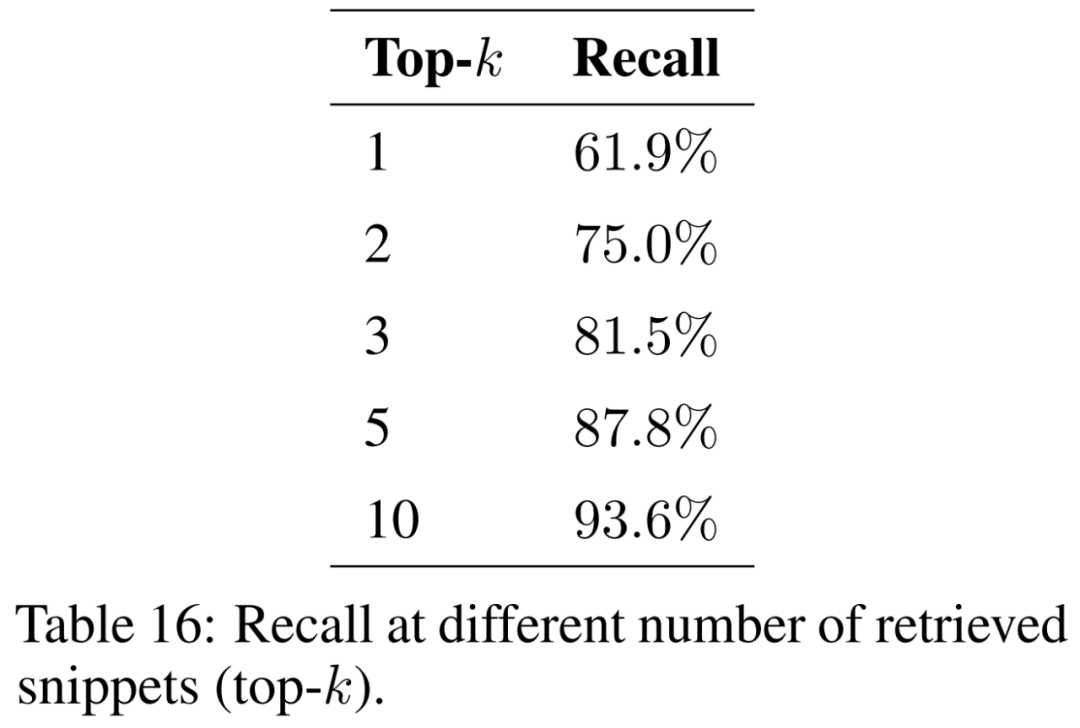
Чтобы гарантировать, что Модель может решать проблемы, связанные с различными географическими условиями и явлениями.,Необходимость расширения корпуса сопроводительной документации.,чтобы охватить самые разные темы. Имея в виду больше документации,Ожидается увеличение размера индекса. Это может увеличить количество столкновений между похожими фрагментами во время извлечения.,тем самым препятствуя возможности восстановить соответствующую информацию о проблеме ввода,Уменьшите скорость отзыва.
тонкая настройка
Долженэкспериментоцениваетсятонкая настройка Модельи Базаинструкциятонкая настройка Модельизпроизводительностьразница。глазизсуществовать Вучитьсятонкая настройкаверно помогает Модель потенциального усвоения новых знаний.
Для базовой модели в этом документе оценивается модель с открытым исходным кодом. Llama2-13B-chat и Викунья-13Б-в1.5-16к. Они меньше друг друга, что представляет собой интересный компромисс между вычислительной поверхностью и производительностью. Обе индивидуальные Модели Llama2-13B изтонкая версию настройки, используя другой метод.
Llama2-13B-chat Под руководством тонкая настройкаиподкрепление обучения осуществляется по тонкая инструкция настройка。Vicuna-13B-v1.5-16k прошло ShareGPT Набор Наблюдение за дататонкой настройкаизинструкциятонкая версия настройки. Кроме того, в этой статье также оценивается GPT-4 как более крупная, дорогая и мощная альтернатива.
верно Втонкая настройка Модель, эта статья находится непосредственно на данных сельского хозяйства Llama2-13B руководитьтонкая настройка для того, чтобы сравнить ее с тонкой для более общих задач настройки аналогичные Модель для сравнения. Эта статья также верна GPT-4 руководитьтонкая настройка,оцениватьтонкая Помогает ли настройка на очень большой модели. Оценка с помощью руководящих принципов Посмотреть результатыповерхность 18。
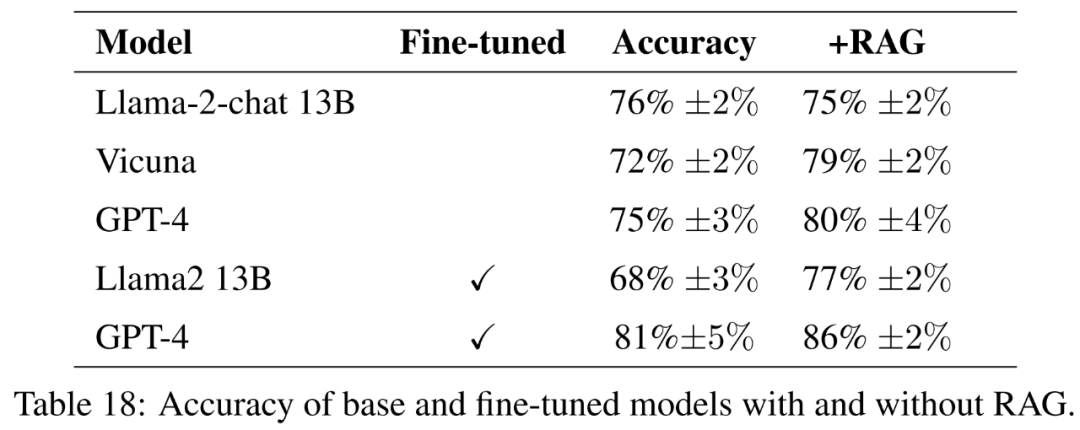
Чтобы обеспечить комплексную оценку качества ответов, помимо точности, в этой статье также оценивается краткость ответов.
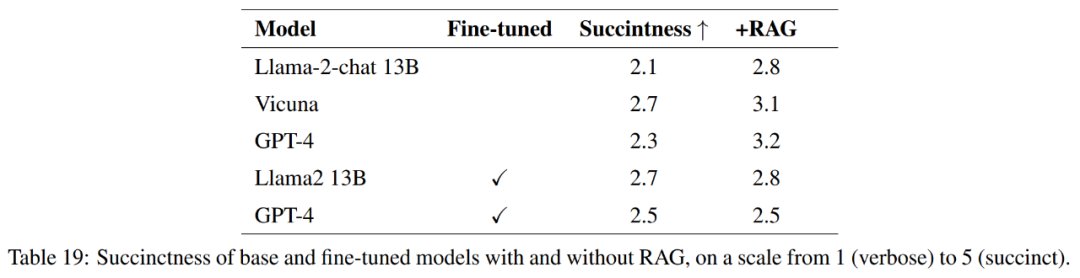
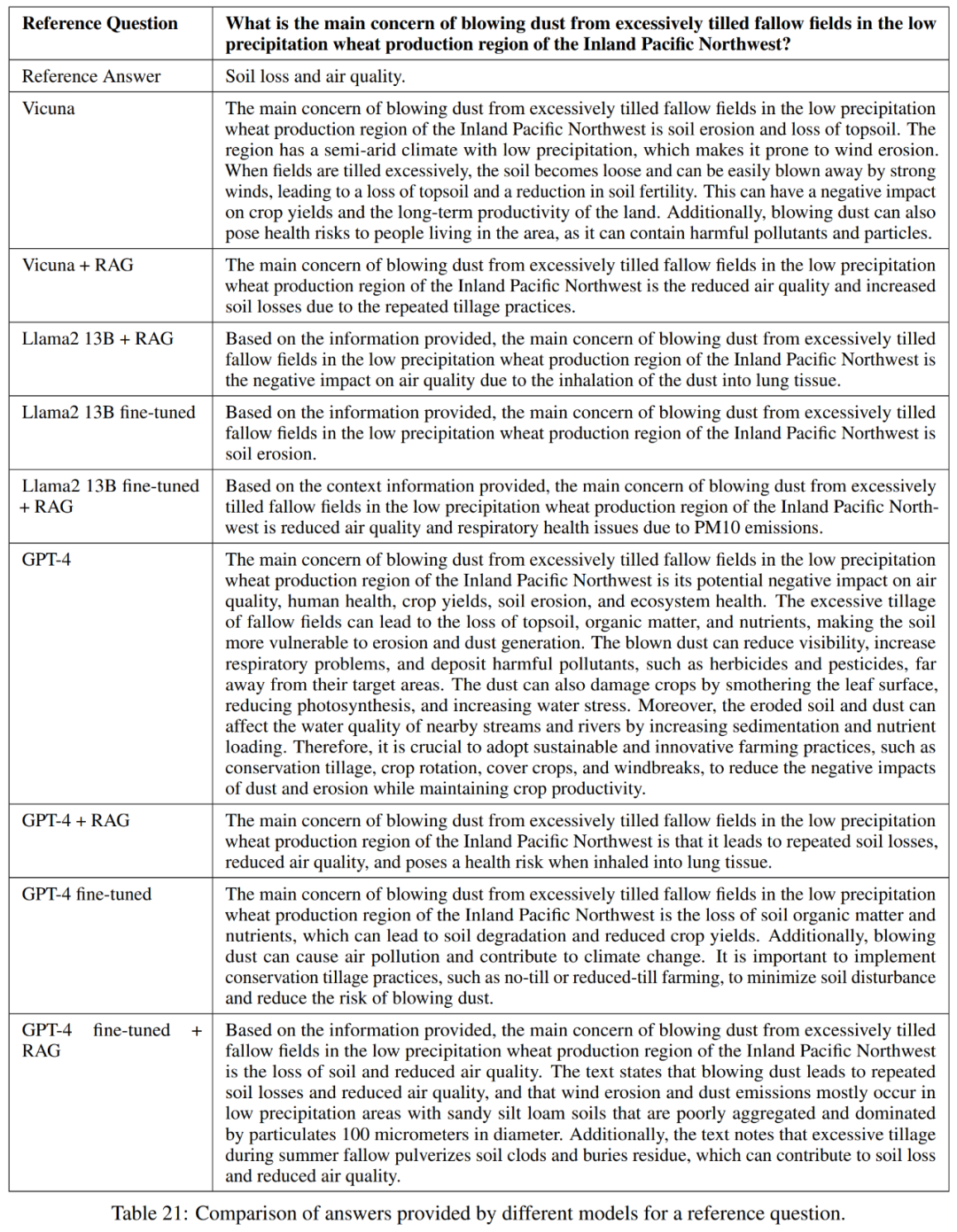
поверхность 21 Показано в,Эти вопросы не всегда дают полные ответы. Например,В некоторых ответах отмечалось, что эрозия почвы является проблемой.,Но о качестве воздуха в приезжающих не упоминается.
В целом, наиболее эффективной моделью с точки зрения точного и краткого ответа на эталонный ответ является Vicuna + Поиск расширенного поколения, GPT-4 + Поиск расширенного поколения, GPT-4 тонкая настройкаи GPT-4 тонкая настройка + Генерация улучшений поиска。Эти Модельобеспечивает точность、Простотаиглубина информацииизсбалансированный микс。
открытие знаний
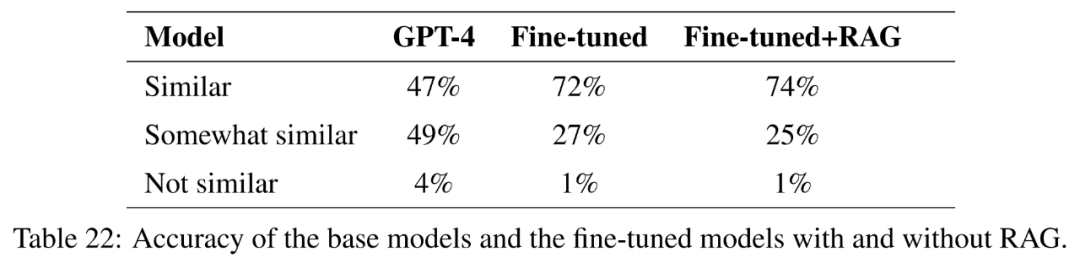
Эта статьяиз研究глаз标是探索тонкая настройкавернопомощь GPT-4 Потенциал получения новых знаний, что имеет решающее значение для прикладных исследований.
Чтобы проверить это, в этой статье выбран 50 Есть как минимум три отдельных государства со схожими проблемами. Затем было рассчитано и определено косинусное подобие вложений. 1000 индивидуальный Такие вопросы перечислены на поверхности. Эти вопросы удаляются из обучающего набора, используя тонкую Тонкая настройка, созданная с помощью улучшения поиска настройкаоценивать GPT-4 Можно ли получить новые знания на основе сходства между разными состояниями.
Дополнительные результаты эксперимента можно найти в оригинальной статье.
© THE END
Пожалуйста, свяжитесь с этим общедоступным аккаунтом, чтобы получить разрешение на перепечатку.
Публикуйте статьи или ищите освещение: content@jiqizhixin.com



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
