QQ 9 «Глупый, глупый, быстрый»? ! Позвольте мне показать вам технические секреты, стоящие за этим.
С момента запуска недавно выпущенного QQ 9 он получил похвалы от многих пользователей за плавность работы. Многие пользователи в шутку называли QQ 9 «глупым быстрым», настолько быстрым, что «это немного непривычно».
В каких аспектах QQ 9 было оптимизировано для крупномасштабного приложения, чтобы пользователи могли четко ощутить улучшение беглости речи? В этой статье будет подробно представлена техническая реализация обеспечения плавности QQ 9, а также исследование оптимизации производительности, проведенное в течение всего процесса, и предоставлен многоразовый опыт для повышения плавности работы приложений.
01. 500 миллионов человек все еще настаивают на использовании QQ
В этом году исполняется 30 лет с тех пор, как в Китае началась эра Интернета, 25-й год QQ как «интернет-продукта первого поколения» и 14-й год мобильного QQ.
#Есть еще 500 миллионов человек, которые настаивают на использовании QQ #. Именно настойчивость этой группы пользователей побуждает техническую команду QQ постоянно внедрять инновации и повышать производительность, чтобы предоставить пользователям лучший опыт.
Рекламное изображение QQ 9
Начиная с QQ 9, мы реконструировали и оптимизировали базовую архитектуру снизу вверх, решив ряд проблем, таких как медленный запуск мобильного клиента, легкие задержки, длительное время ожидания последовательной передачи и скачки пользовательского интерфейса. После запуска он получил множество положительных отзывов от пользователей. Одно из часто встречающихся ключевых слов — «шелковистый». За шелковистой гладкостью он на самом деле отшлифован техническими специалистами.
В этой статье будут раскрыты технические разработки, лежащие в основе QQ 9, и представлены методы жесткой оптимизации, разработанные мастерами QQ.
02. Привередливая полировка
2.1 Чрезвычайно быстрая оптимизация скорости запуска
Работа QQ начинается с «оптимизации запуска». На примере iOS процесс запуска в основном разделен на три этапа:
- T0: щелкните значок, чтобы запустить основную функцию;
- T1: Начиная с основной функции и заканчивая DidFinishLaunchingWithOptions;
- T2: DidFinishLaunchingWithOptions завершается до завершения рендеринга первого кадра.
Обычно процесс запуска делится на два этапа выполнения: предосновной (Т0) и пост-основной (Т1+Т2):
- pre-main этап:система dyld нагрузка App Поведение зеркалирования и инициализации имеет большую связь со структурой и масштабом программы.
- Пост-основной этап: поведение бизнес-инициализации, выполняемое приложением перед рендерингом на экране, тесно связано с конкретной бизнес-логикой.
Направления общей инженерной оптимизации:
- этап pre-main сокращает затраты времени на нагрузку по ссылке: например, динамическую ссылку на статическую ссылку,Код разбит на динамические библиотеки и реализуется лениво.
- post-main этап Уменьшить общий объем кода, выполняемого основным: если код удален,Время выполнения кода задерживается или асинхронно вычитается.,оптимизация эффективности выполнения логики кода и т.д.
Ниже мы представим основные моменты работы QQ в этих двух направлениях.
2.1.1 предосновной этап — загрузка кода по требованию
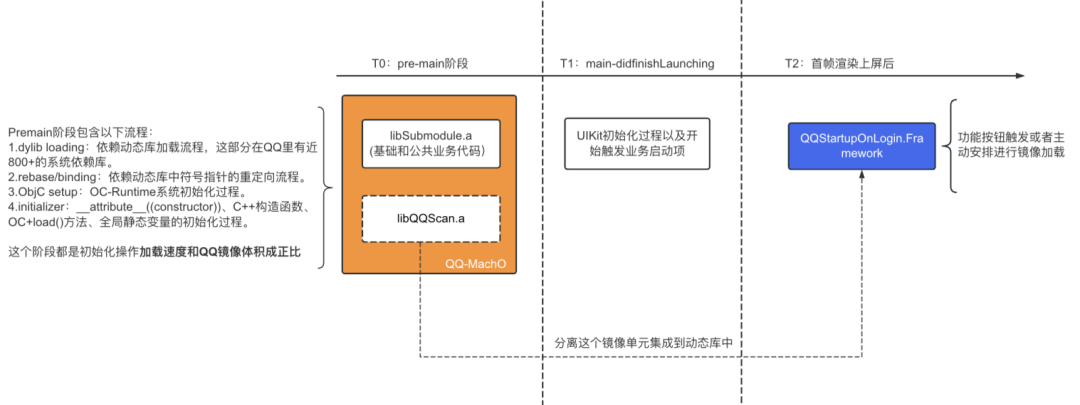
Принципиальная схема решения отложенной загрузки динамической библиотеки
Разделение кода на динамические библиотеки и ленивая загрузка этой технологии в основном используется в крупномасштабных приложениях в отрасли (Douyin, Facebook, Kuaishou). Однако сложность бизнеса QQ довольно высока, и прямое использование отраслевых решений не может удовлетворить наши потребности. После некоторых исследований мы обнаружили несколько инновационных технических моментов:
- Используйте __attribute__((objc_runtime_visible)) для недорогого динамического преобразования кода.
- Используйте objc_setHook_getClass для достижения динамической сходимости ввода кода и обеспечения стабильности решения.
Наконец, крупномасштабное приложение в QQ 9 реализовало оптимизацию времени запуска предварительной основной стадии (это техническое решение обеспечило около 33% общего дохода от данных по оптимизации времени запуска):
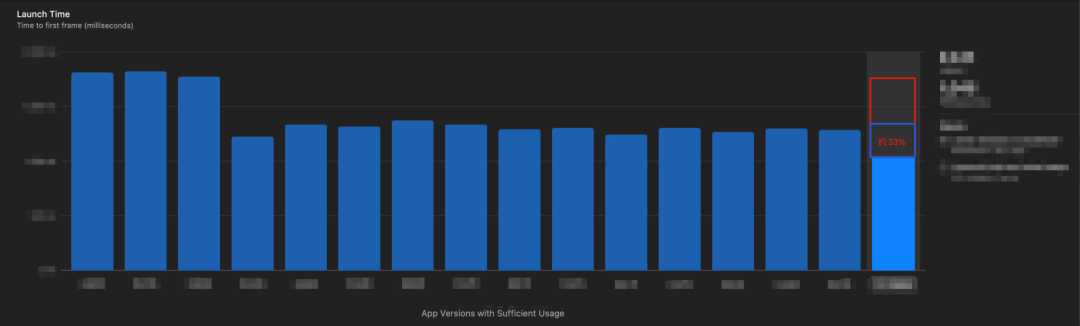
График данных запуска Xcode Organizer
2.1.2 пост-основной этап — управление потоками
Наша система предотвращения деградации отслеживает, что проблема вытеснения основного потока становится все более серьезной. С помощью инструментов мы обнаружили, что в некоторых серьезных случаях 14% интервала времени основного потока в процессе теплого запуска вытесняется. другие темы.
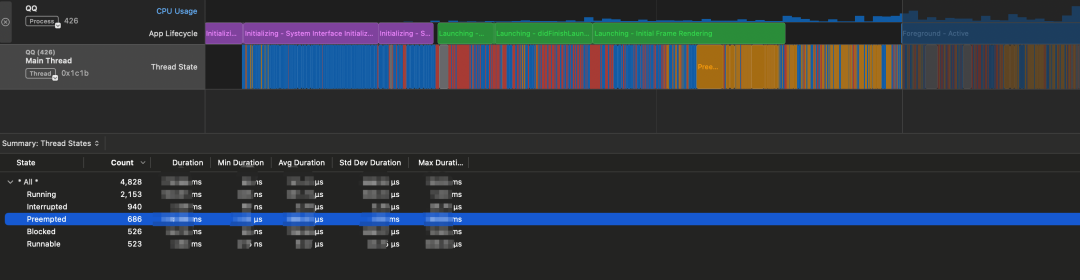
Анализ инструментов QQ, трудоемкий график запуска
В чем заключается проблема вытеснения основного потока (Preempted)? Проще говоря, часть времени ЦП основного потока вытесняется другими потоками, в результате чего основной поток не получает ресурсы ЦП. Поскольку проблема вытеснения становится все более серьезной, она также приводит к некоторым сопутствующим проблемам, таким как общее время запуска также ухудшается, задержки после запуска, время запуска сильно колеблется, и вероятность ошибочной оценки в отчете о производительности по борьбе с деградацией увеличивается. , и т. д.
Почему основной поток вытесняется? Проще говоря, причин несколько:
- системалиния отправкидля、системасортнить(например PageIn нить)захватывать。
- APP Если вы часто открываете подпрогоны, не обращая внимания на управление количеством подпрогонов, может произойти «взрыв прогона», и подпрогоны могут быть установлены неправильно. QoS легко приведет к вытеснению хоста.
- Основная задача слишком тяжела,Временной интервал слишком длинный,Будет наказан и понижен в должности,Потом его вытеснило другое суб-зинить.
Поняв причины, мы будем управлять ими по следующим трем аспектам:
Уменьшите количество дочерних потоков
GCD широко используется в большинстве компаний, занимающихся мобильным QQ. После поиска информации и исследований мы обнаружили, что частое использование глобальной очереди GCD может привести к взрыву потока. Причина в том, что когда дочерний поток находится в состоянии сна/ожидания/блокировки. он будет считаться неактивным по состоянию GCD, новый поток может быть создан при поступлении новой задачи.

Комментарии инженера Apple и бывшего инженера-разработчика GCD
Apple официально рекомендует не создавать большое количество очередей. Используйте target_queue для установки иерархической структуры очереди. Несколько подсистем образуют древовидную структуру очереди. Наконец, нижний уровень очереди использует последовательную очередь как target_queue. Подробности см. в разделе «Модернизация использования Grand Central Dispatch — WWDC17».
Уменьшите качество обслуживания дочернего потока
Если для качества обслуживания глобальной очереди установлено значение DISPATCH_QUEUE_PRIORITY_DEFAULT, качество обслуживания задачи унаследует качество обслуживания исходной очереди (если исходная очередь является основной очередью, оно будет уменьшено с QOS_CLASS_USER_INTERACTIVE до QOS_CLASS_USER_INITIATED). Разработчики часто отправляют задачи в глобальную очередь в основном потоке и указывают QoS как DISPATCH_QUEUE_PRIORITY_DEFAULT, что приводит к появлению большого количества подпотоков с QoS как QOS_CLASS_USER_INITIATED. Ниже приведены приоритеты QoS:
__QOS_ENUM(qos_class, unsigned int,
QOS_CLASS_USER_INTERACTIVE = 0x21, // 33
QOS_CLASS_USER_INITIATED = 0x19, // 25
QOS_CLASS_DEFAULT = 0x15, // 21
QOS_CLASS_UTILITY = 0x11, // 17
QOS_CLASS_BACKGROUND = 0x09, // 9
QOS_CLASS_UNSPECIFIED = 0x00, // 0
);В реальной разработке многие сетевые запросы и операции ввода-вывода на диск используют это качество обслуживания. Фактически, приоритет дочернего потока можно снизить, уменьшив качество обслуживания.
Увеличить приоритет основного потока
QoS не полностью эквивалентен конечному приоритету потока. Диапазон приоритетов основного потока составляет 29–47. Почему приоритет основного потока меняется во время работы? Глава «Почему изменился приоритет моего потока?» в официальном документе «Планирование Маха и интерфейсы потоков» объясняет эту причину: если поток работает дольше, чем выделенное ему время, но не блокируется, он будет наказан или даже уменьшен. Целью этого является предотвращение постоянного захвата системных ресурсов потоками с высоким приоритетом, в результате чего потоки с низким приоритетом остаются голодными.
Как избежать того, чтобы основной поток работал сверх времени, выделенного ЦП, без штрафа за ухудшение? Нагрузку можно снизить с уровня RunLoop.
Первый RunLoop, который запускается во время процесса запуска приложения, будет выполняться до тех пор, пока не завершится рендеринг первого экрана. Задачи на первом экране, как правило, очень тяжелые, из-за чего RunLoop занимает много времени и легко ухудшается системой.

Трудоемкая диаграмма первого цикла выполнения при запуске QQ
Решение состоит в том, чтобы разделить задачи в первом RunLoop. Наш подход заключается в том, чтобы сохранить необходимую глобальную логику инициализации в первом цикле выполнения и отложить создание основного пользовательского интерфейса до следующего цикла выполнения. Это не только эффективно решает проблему вытеснения основного потока во время запуска, но также ускоряет запуск и позволяет быстрее увидеть главную страницу.
На самом деле, здесь еще есть место для оптимизации. Мы перенесли все задачи первого RunLoop во второй RunLoop, что приведет к тому, что второй RunLoop будет занимать больше времени. Мы можем продолжить оптимизацию в соответствии с этой идеей.
2.2 «Всем» нравится шелковистая плавность — улучшенная производительность и плавность хода
2.2.1 Как определить беглость?
Плавные (мягкие) соматосенсорные характеристики заключаются в том, что содержимое экрана мгновенно меняется вслед за действиями пальцев, и каждое действие мгновенно возвращается на экран. Как показано на рисунке, если высокая частота обновления кадров не включена, пользовательские операции должны обновляться на экране в течение 16,67 мс.
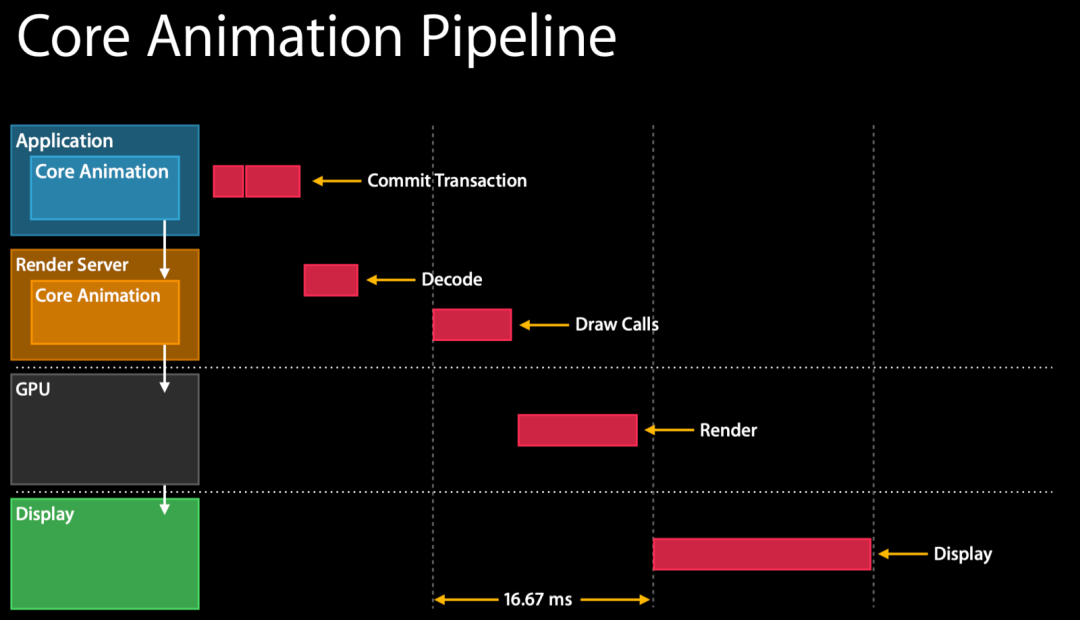
Каждая операция пользователя должна пройти через 4 шага, показанных на рисунке. Если какой-либо шаг занимает слишком много времени, экран не будет обновляться вовремя, что приведет к задержкам. Источник: «Продвинутая производительность графики и анимации».
Сложно ли сделать так, чтобы приложение обновляло действия пользователя каждые 16,67 миллисекунды? Трудно, сложно. CPU и GPU должны выполнить множество задач за такой короткий период времени.
- Содержимое, отображаемое на экране, можно обновлять только на главном экране (только одноядерные, многоядерные использовать нельзя) CPU)。
- Существует множество трудоемких факторов, влияющих на работу графического процессора. Чем сложнее отображаемый интерфейс, тем больше времени он занимает.
16,67 миллисекунды для основного потока — время, необходимое системе = время, доступное разработчику. Как показано на рисунке ниже, синяя область — это время, занятое разработчиками. Если разработчики используют ее слишком долго, это приводит к зависанию, то есть задержке.
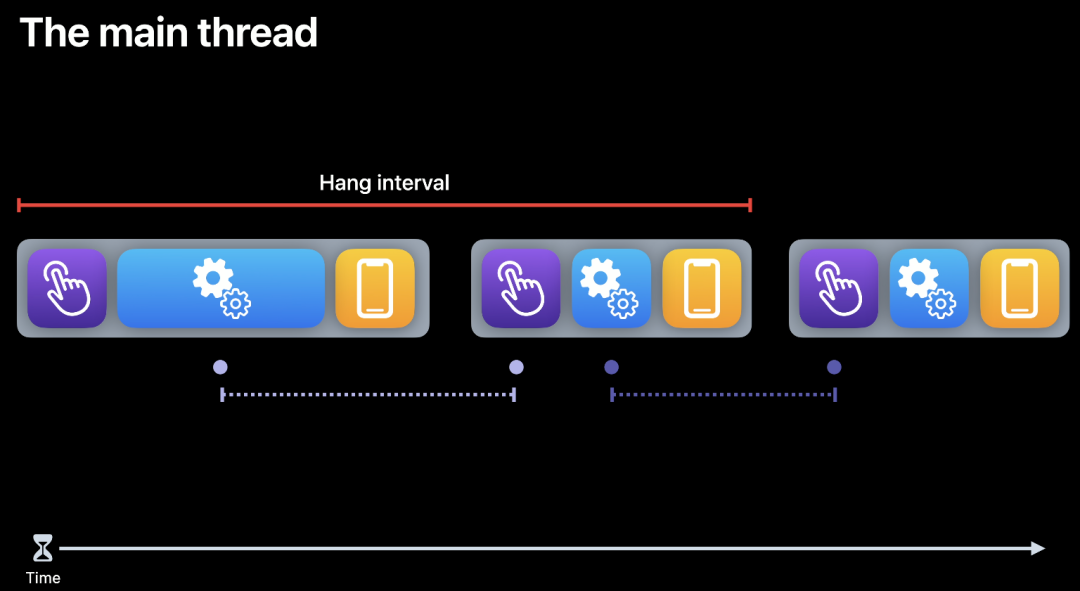
Фиолетовая область: время, необходимое системе для принятия и обработки жестов пользователя.
Синяя область: сколько времени требуется разработчикам, чтобы преобразовать действия пользователя в экранный контент?
Желтая область: время, необходимое для отображения контента на экране.
источник:《Изучите особенности анимации пользовательского интерфейса и цикл рендеринга》
Таким образом, если вы хотите, чтобы ваша кожа была гладкой и шелковистой, вам необходимо сделать следующие две вещи:
- Используйте мультипрограммирование и делайте как можно меньше обновлений на главном сервере. UI другие вещи.
- Пусть графический процессор рисует как можно больше простых интерфейсов, чтобы сократить потребление времени графическим процессором.
2.2.2. Эффективно используйте многопоточное программирование и делайте как можно меньше в основном потоке, кроме обновления пользовательского интерфейса.
Архитектура ядра NT закладывает прочную основу
Ядро NT (NT: Новая технология, здесь дань уважения ядру Windows NT), используемое в QQ 9, было создано на основе концепции максимизации энергоэффективности многоядерных процессоров. Как показано на рисунке ниже, бизнес-обработка. Логика в наибольшей степени отделена от пользователя, ответственного за отображение пользовательского интерфейса. Она отделена от основного потока и использует асинхронные вызовы вместо блокировок потоков, чтобы повысить эффективность и уменьшить вероятность взаимоблокировки.
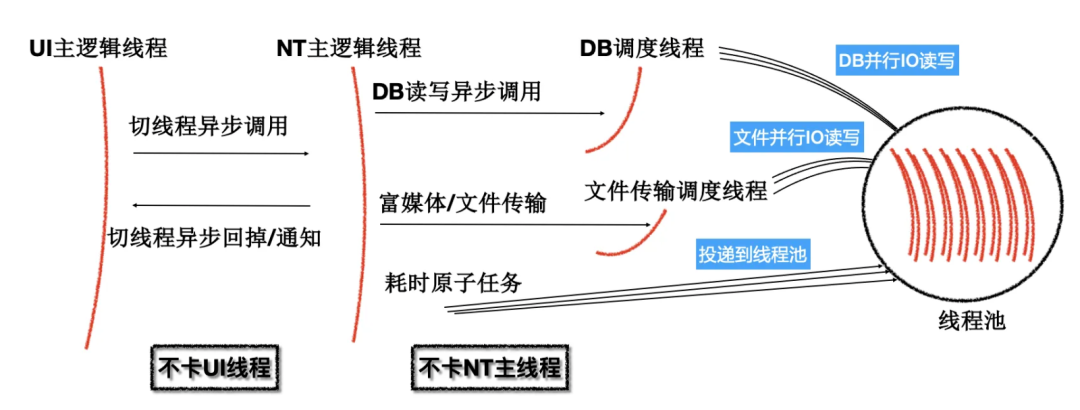
Многопоточная модель ядра NT
Кроме того, NT Kernel использует C++ для реализации основных базовых возможностей программного обеспечения IM, что позволяет использовать его на разных платформах для обеспечения единообразной производительности на каждой платформе. Интерфейс взаимодействия с пользователем реализован на родном языке каждой платформы. Это позволяет пользователям ощущать высокую производительность, обеспечивая при этом уникальные возможности каждой платформы.

NT Kernel поддерживает диаграмму многоплатформенной архитектуры.
Полное обновление изменено на добавочное обновление
Благодаря поддержке нового ядра NT трудоемкая бизнес-логика была перенесена в подпотоки, а в основном потоке выполняется только работа, связанная с обновлением пользовательского интерфейса. Так есть ли возможность дальнейшей оптимизации при обновлении пользовательского интерфейса? Ответ — да. Когда 14-летний мобильный телефон QQ обновляет новое сообщение на экране, он обновляет все отображаемые в данный момент сообщения, что представляет собой механизм «полного обновления». Неприятные ощущения, такие как невозможность обновления сообщений и скачки ресурсов во время прокрутки, вызваны этим механизмом.
Почему сообщение не обновляется при прокрутке? Дело не в том, что его нельзя обновить, а в том, что его нельзя обновить. Избыточные операции обновления могут легко помешать завершению обновления пользовательского интерфейса в течение 16,67 мс, что приведет к задержкам.
Почему происходит скачок ресурсов? Полное обновление вызовет переработку и повторное использование всех узлов на экране, и это повторное использование по-прежнему не работает. Как показано на рисунке ниже, положение узла будет меняться случайным образом после полного обновления. Например, узел с хвостовым номером 1b400 (второй на рисунке слева) используется для отображения 2 перед обновлением, а после обновления он отображается. отображается цифра 7 (седьмая на правом рисунке).
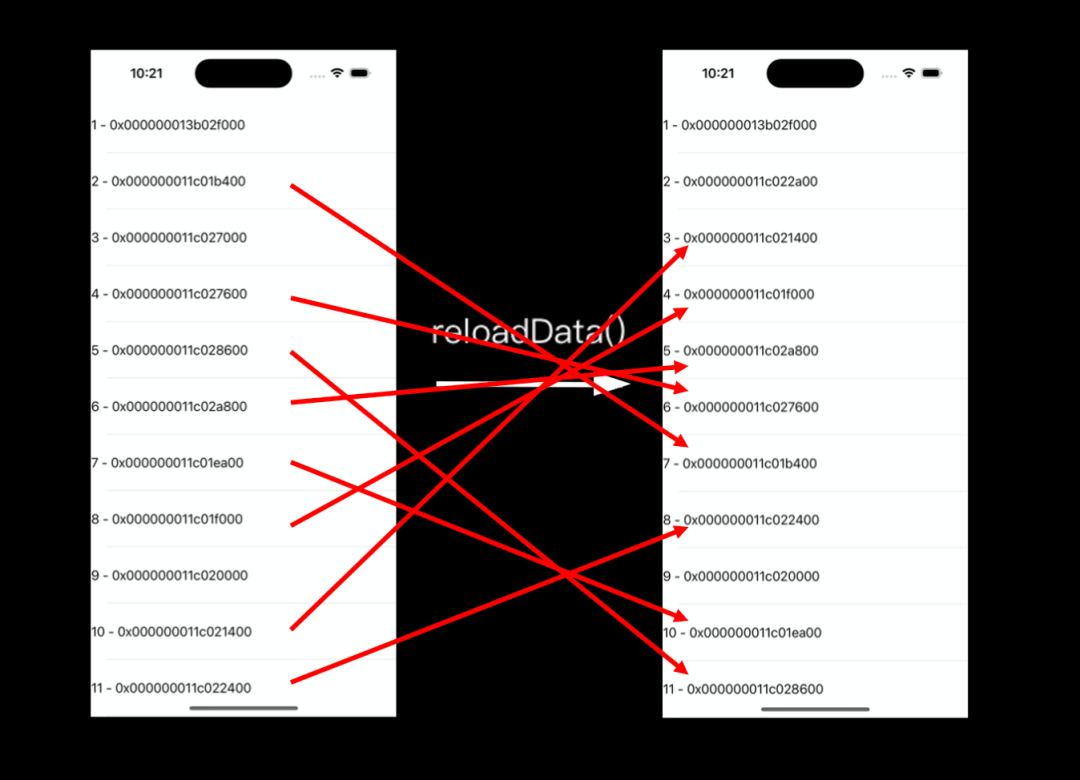
Сравнивая адреса памяти узлов двух изображений слева и справа, мы видим, что после полного обновления будут случайные изменения и закономерности нет.
Независимо от того, является ли это статическим или динамическим изображением, существуют трудоемкие операции, такие как дисковый ввод-вывод и декодирование. Обычно асинхронная загрузка используется, чтобы избежать зависания основного потока. В сочетании с этой функцией случайного повторного использования это приводит к явлению «скачка ресурсов».
В зависимости от различных ситуаций повторного использования будут следующие три проявления:
- Это может быть тот узел, который использовался в прошлый раз, или контент точно такой же: назначен тот же контент, без каких-либо изменений.
- Нет соответствующих движущихся/неподвижных изображений: контент создается с нуля и соответствует ожиданиям.
- Есть связанные движущиеся/неподвижные изображения, но они не соответствуют содержимому текущей Модели: возникает мерцание. Как показано на рисунке ниже.
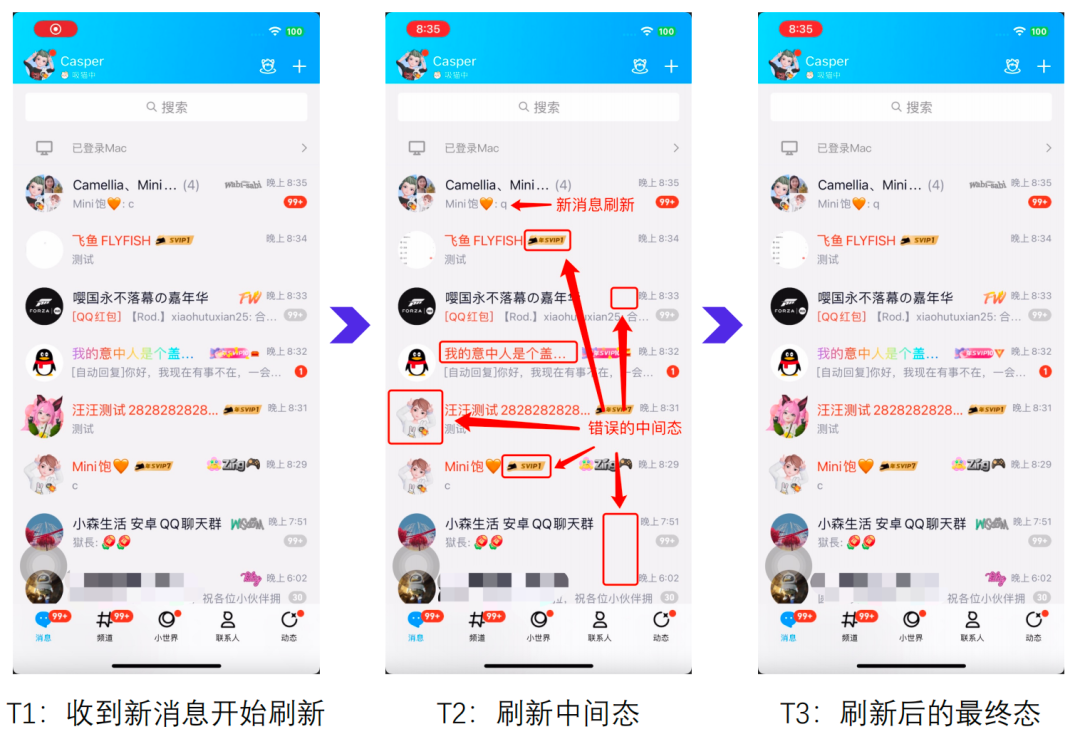
Все данные и элементы асинхронной нагрузки полностью обновляются.,Другие узлы и старая информация будут отображаться до его завершения, даже сброс представления во время обновления не может решить проблему;,только что изA->A->BИзменить наA->нулевой->B,Есть еще явный скачок.
«Пошаговое обновление», принятое в QQ 9, вполне может решить две вышеупомянутые проблемы с опытом. Кроме того, есть скрытое преимущество, которого невозможно достичь при полном обновлении: анимация узлов, как показано на видео ниже.
Для реализации инкрементного обновления требуется надежный алгоритм Diff, который сообщает системе, какие операции обновления, вставки, удаления и перемещения необходимо выполнить на измененном узле. Если будет предоставлена неверная информация, это напрямую приведет к сбою приложения. Процесс доработки алгоритма также был полон неожиданных поворотов.
Прежде всего, прочитав исходный код, я обнаружил, что встроенные инструменты Diff в системах Android и iOS реализованы с использованием алгоритма Майерса.
Майерс: Результаты вычислений сохраняются в массиве изменений, которых всего два типа: вставка и удаление. (Источник: Swift Diffing)
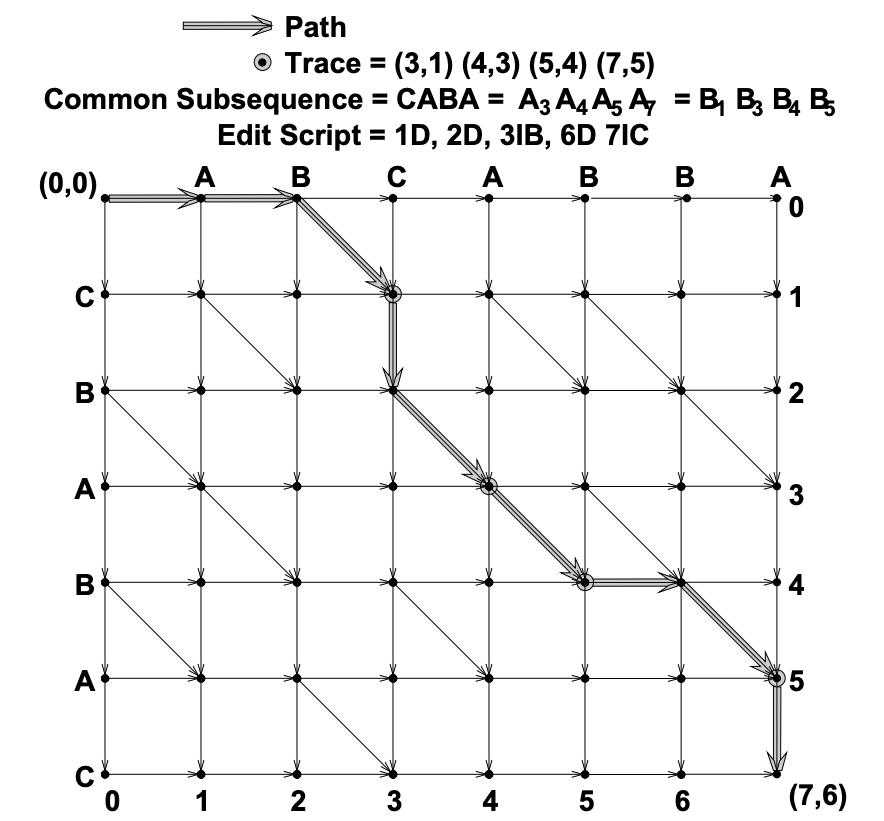
Процесс решения алгоритма Майерса находит кратчайшее расстояние редактирования от источника до места назначения посредством вставки и удаления. Источник: Разностный алгоритм AnO(ND) и его варианты.
У этого алгоритма есть «недостатки» при расчете перемещения. Он предполагает перемещение посредством поведения вставки + удаления. В определенных сценариях операция перемещения будет понижена до уровня вставки + удаления. Например, сначала удаление, а затем перемещение будет преобразовано в удаление+вставка и наоборот: перемещение+удаление:
- удалить + сдвиг → удалить + увеличивать: Набор данных A:[1, 2, 3, 4, 5]->Набор данныхB:[2, 3, 5, 4]. Удалим деление 1 и 4, а затем вставим 4.
- сдвиг + удалить → сдвиг + удалить: Набор данных A:[1, 2, 3, 4, 5]->Набор данныхB:[1, 2, 4, 3]. 3 и 4 поменяются местами, а затем удаление будет разделено на 5.
После анализа идеальный алгоритм Diff должен иметь следующие две характеристики:
- Возможность записи динамических связей между узлами,Это не выводится из вставки, удаление за исключением соединения.
- Он имеет меньшую временную и пространственную сложность.
После сравнения отраслевых решений был выбран алгоритм Heckel Diff, описанный в статье «Методика изоляции различий между файлами». Оптимальная, средняя и наихудшая комплексная временная/пространственная сложность этого алгоритма равна O(m+n), что лучше, чем O((m+n)*d) алгоритма Майерса. Реализация его таблицы символов гарантирует, что все операции перемещения будут записаны, и в Майерсе больше не будет потерянных операций перемещения, как показано на рисунке ниже.
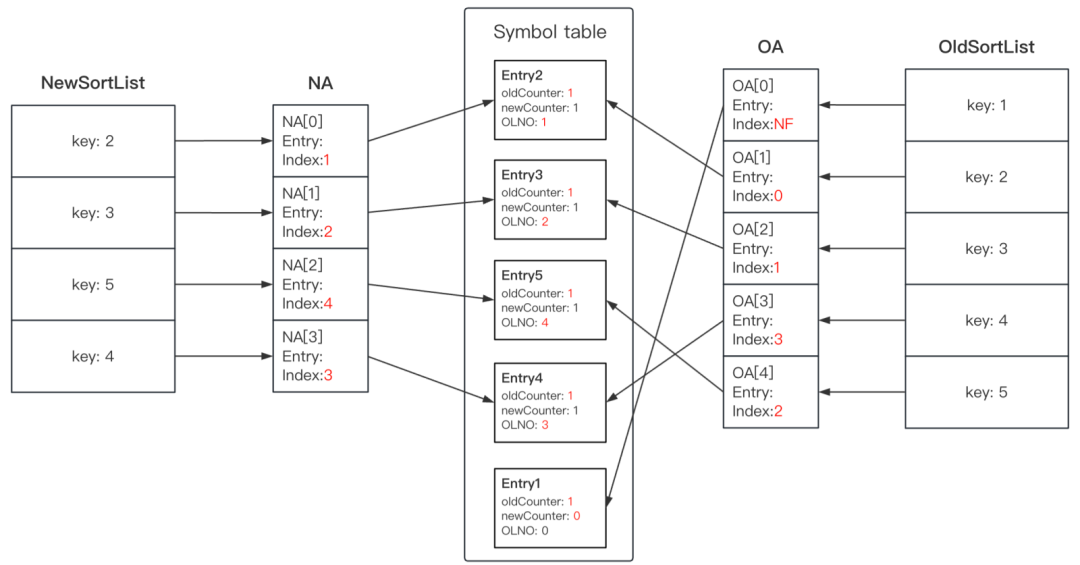
Алгоритм Хекеля использует таблицу символов для генерации информации о различиях между старыми и новыми данными за 6 шагов.
- PASS1 Установите связь между новым массивом индексов (NA), необходимым для новых данных, и таблицей символов.
- PASS2 Установите связь между старым массивом индексов (OA) и таблицей символов, необходимой для старых данных.
- PASS3. Найдите узлы, позиции которых не изменились, и обновите информацию индекса в старом и новом массивах индексов (NA, OA).
- PASS4 – PASS5: подходит для случаев сравнения двух статей (значения ключей одинаковы). В сценариях приложений QQ одинаковые значения ключей не допускаются и могут быть пропущены. Заинтересованные студенты могут проверить статью напрямую.
- PASS6 Рассчитайте разницу на основе существующих результатов, как показано на рисунке ниже:
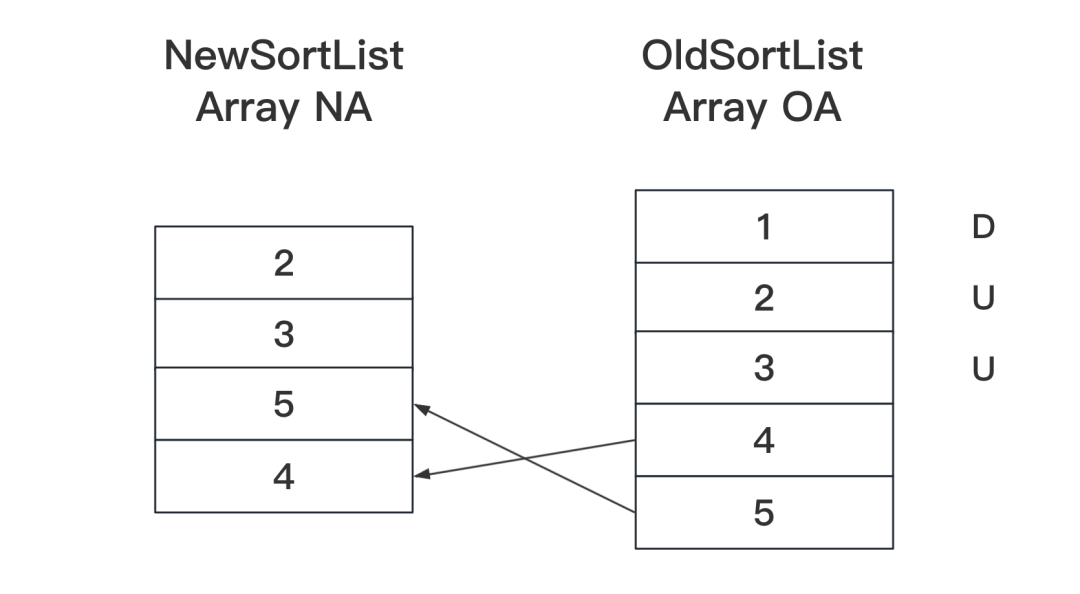
D означает удаление, U означает отсутствие изменений, и между 4 и 5 существует движущаяся связь.
Итак, идеален ли алгоритм Хеккеля? В противном случае он не учитывает избыточную информацию о движении, а избыточные операции перемещения приведут к проблеме нарушения анимации, как показано на рисунке ниже.
Мы улучшили и оптимизировали алгоритм Хеккеля, отслеживали и записывали операции движения, различали прямые движения и косвенные движения, фильтровали и удаляли косвенные движения и, наконец, получили алгоритм Diff, который соответствует различным требованиям индикаторов QQ 9. Как показано в примере ниже, ID5 перемещается непосредственно в первую строку, а ID1-4 перемещаются косвенно вниз.
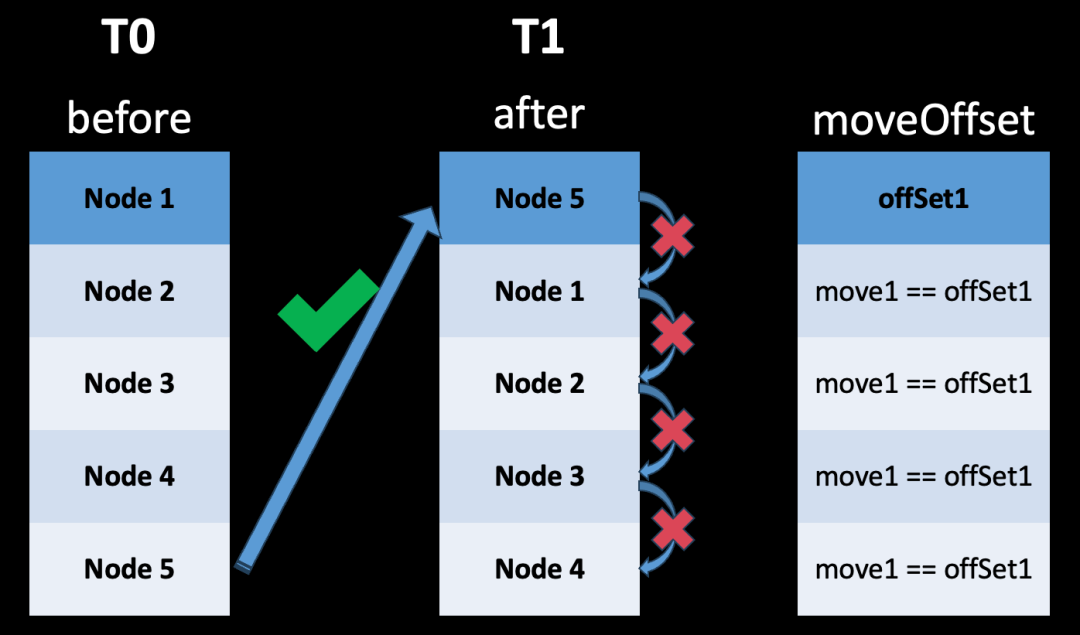
Запишите смещение прямого движения (необходимо записать смещение перемещения = вставка X + удаление Y), исправьте результат непрямого/пассивного перемещения (перемещение ID 1–4)
Параллельная предварительная компоновка
Согласно передовому опыту в отрасли, асинхронная компоновка не может отсутствовать в QQ 9. Мы также попытались распараллелить асинхронную компоновку и углубиться в ограничения производительности.
Сначала попробовал N сообщения N Решение темы: используйте GCD распространять N параллельные задачи, а затем использовать DispatchGroup Дождитесь завершения этих задач. От Параллельная предварительная компоновка, которая изначально требовала десятков миллисекунд предварительного макета для того, чтобы индивидуальнонить одну дюжину миллисекунд. Этот индивидуальный план был позже обнаружен 2 Вопросы:
- Параллельный макет N Суммарная трудоемкость сообщений все же гораздо больше, чем у серийных макетов-сообщений, ограниченных CPU Количество ядер, блокировка или другие конфликты за ресурсы в коде вызывают N сообщенияиз Подготовка параметров. Расчеты имакетов не удалось полностью распараллелить.
- Это Нсообщенияизмакет задач соответственно и N индивидуальный GCD Задачи привязаны один к одному, НОД Запланируйте это N Любое медленное планирование задачи удлинит всю задачу.
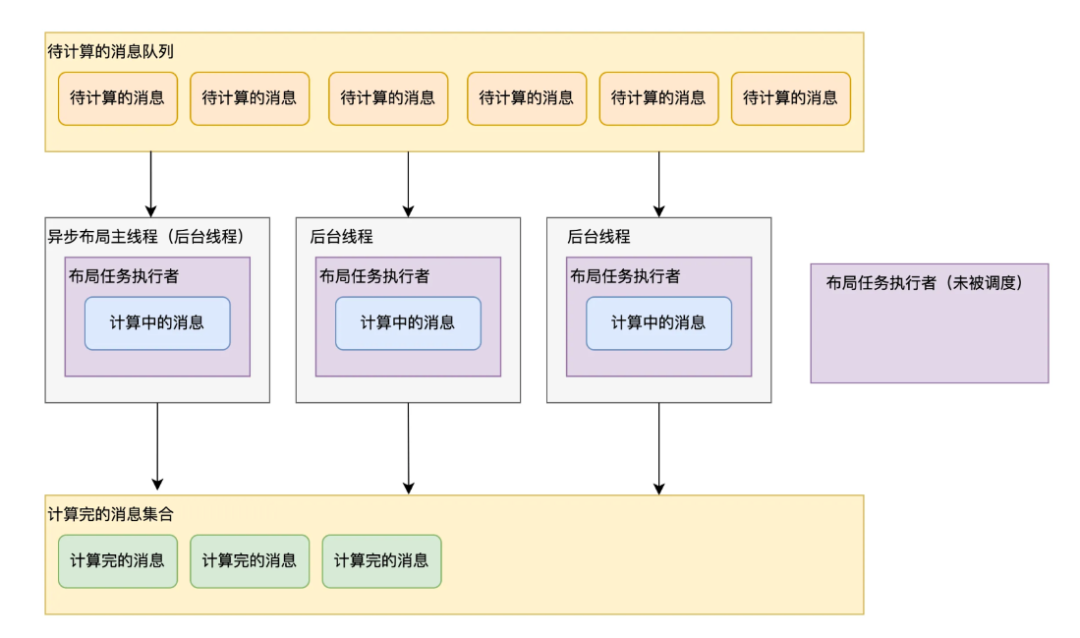
В полной мере используйте вычислительную мощность многоядерных процессоров с помощью параллельных вычислений, общие трудоемкие расчеты компоновки сокращаются примерно на 76%.
Скорректированное решение показано на рисунке выше с использованием M индивидуальныйисполнитель для выполненияNсообщенияизмакет Задача(N>=M>0)。текущийнить(асинхронныймакетхозяиннить)выполнить 1 исполнитель, а затем GCD Дополнительные (M-1) потоки запланированы для выполнения (M-1) исполнителей. Сначала индивидуальное сообщение, подлежащее вычислению, помещается в индивидуальную очередь. Каждый отдельный исполнитель будет зацикливать сообщение из очереди сообщений для расчета и выполнять макетный расчет до тех пор, пока очередь сообщений для расчета не станет пустой. Поскольку задача для сообщения измакет не привязана к какому-либо исполнителю, даже если исполнитель не запланирован в течение длительного времени, это не приведет к задержке расчета макета. В большинстве случаев это приведет к задержке. M Исполнитель будет M Потоки выполняются параллельно.
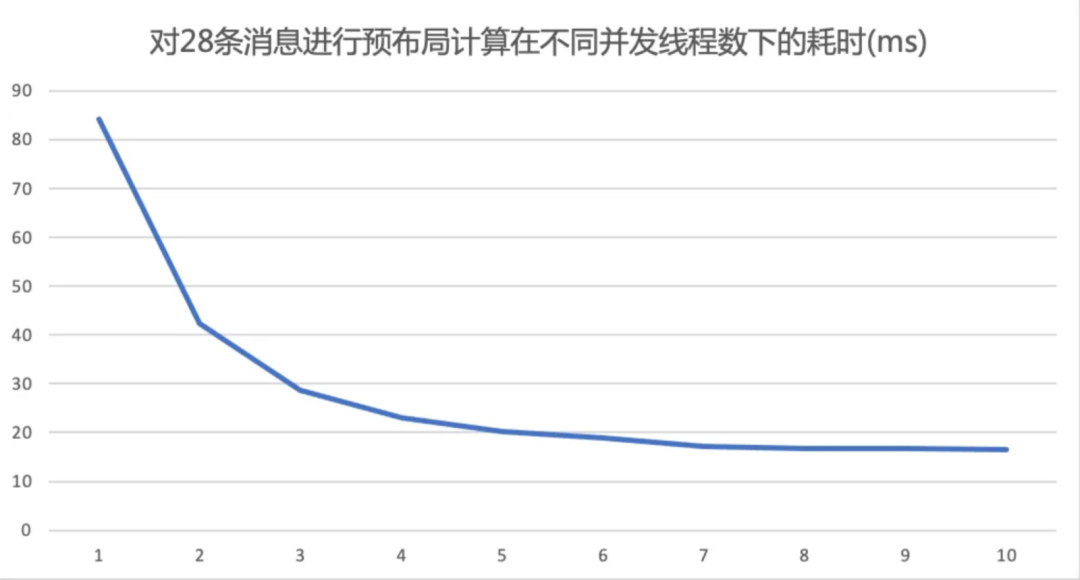
Общие затраты времени при параллельной компоновке будут уменьшаться по мере увеличения количества одновременных потоков. При увеличении их до 5 затраты времени сильно не уменьшатся.
Кажется, что текущая работа по расчету макета была перенесена из основного потока. Реальность такова, что во многих случаях рассчитанные координаты и размеры не соответствуют размеру пикселей экрана. В это время система выполняет «выравнивание пикселей». снова в основной теме. Эту деталь нельзя игнорировать при «асинхронной компоновке», чтобы действительно снизить нагрузку на основной поток, как показано на рисунке ниже.

OLEDЭкраниз1индивидуальный ПиксельR:G:BПропорциядля1:2:1,При отображении DDIC (Дисплей Driver IC, чип драйвера дисплея) будет выполнять субпиксельный рендеринг и заимствовать элементы из других пикселей, чтобы сделать дисплей более полным. Однако код не может напрямую контролировать такое поведение. Система должна гарантировать, что отправляемый контент полностью совмещен с пикселями экрана, то есть не может быть такой ситуации, как использование 0,5 пикселя.
Желтая область указывает на то, что результаты координат и размеров не совпадают с пикселями экрана.
Другие оптимизации включают в себя: интеллектуальную предварительную загрузку, переработку сообщений, асинхронное декодирование ресурсов изображения и т. д. Как показано на рисунке ниже, отображение кэша первого уровня и предварительная загрузка кэша второго уровня получаются в соответствии с соотношением экрана. Лишняя часть перерабатывается и освобождается.
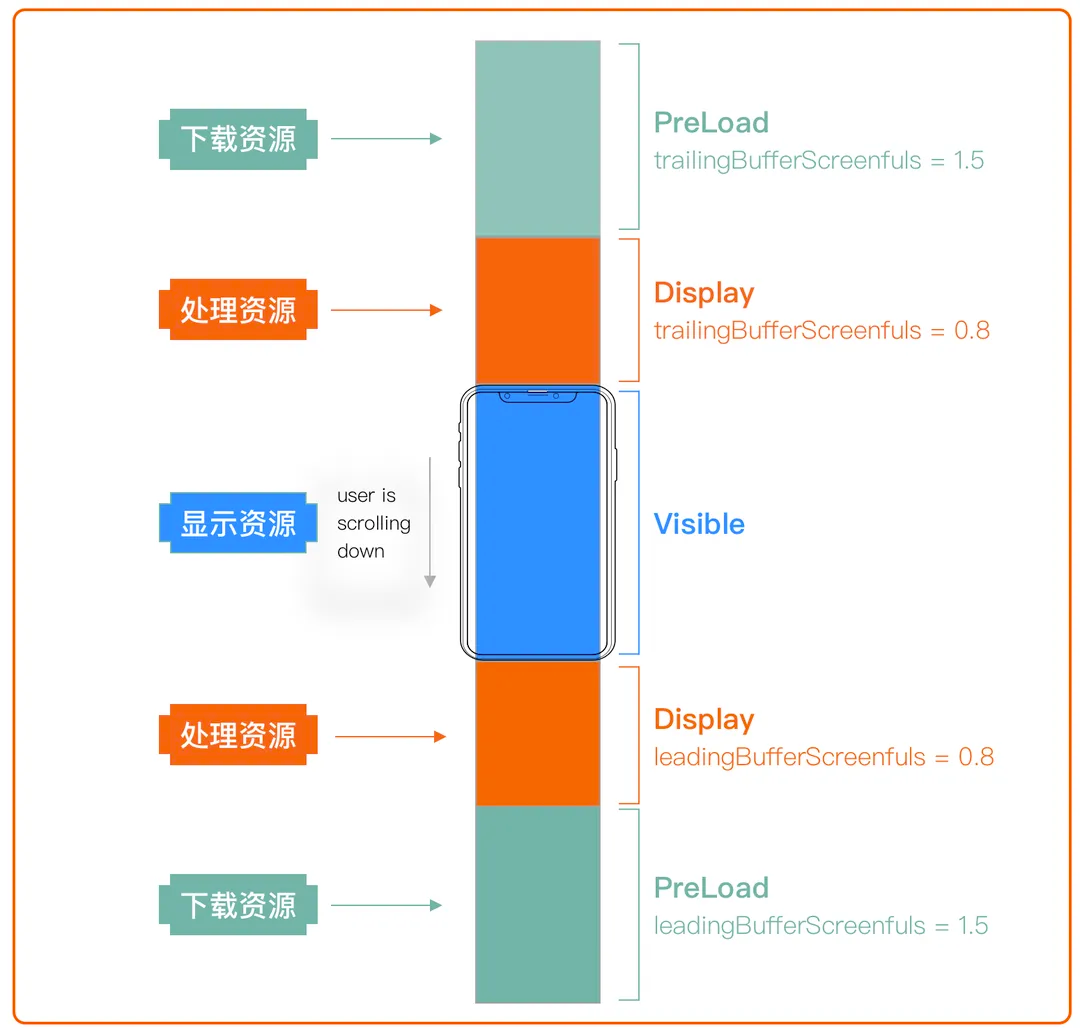
Диаграмма стратегии предварительной загрузки ресурсов
2.2.3 Пусть графический процессор рисует максимально простой интерфейс, чтобы сократить потребление времени графическим процессором.
В дополнение к макетам, которые могут рассчитываться асинхронно, сложные изображения также могут использовать «асинхронный рендеринг» для сокращения затрат времени графического процессора, особенно при работе с графикой, которую необходимо накладывать и обрезать, задачи рисования графического процессора не могут быть выполнены в течение одного кадра и более; требуется обработка. Открытие кадрового буфера для рисования и объединение содержимого двух буферов после завершения называется «внеэкранным рендерингом». Внеэкранный рендеринг оказывает огромное влияние на производительность, главным образом потому, что переключение контекста графического процессора требует больших накладных расходов, а текущий конвейер и ограждения необходимо очищать. Оригинальные слова здесь: Взгляд на дизайн iOS, ориентированный на производительность | В этом случае инженеры Apple предлагают использовать отрисовку процессора, чтобы разделить часть работы с графическим процессором. Как показано ниже:
Область, отмеченная желтым цветом, представляет собой внеэкранный рендеринг с помощью графического процессора. Нельзя отрицать, что внеэкранный рендеринг с помощью графического процессора намного дороже, чем внеэкранный рендеринг с процессором; в сценариях, где маски невозможно избежать, производительность асинхронного рендеринга лучше при использовании многоядерных процессоров.
Мы используем многоядерные процессоры для асинхронного рендеринга при рендеринге сообщений, чтобы сократить затраты времени на часть графического процессора. Сложность здесь в том, что проблема «белого мигания» возникает при использовании в сценариях списков, которые можно быстро обновлять путем скольжения. Например, известный сторонний фреймворк с открытым исходным кодом YYKit также имеет такие проблемы. Наш метод LRU-кэш + инкрементальный. обновление очень хорошо решило эту проблему.
2.2.4 Шелковистый опыт с полным буфером
На основе вышеупомянутых оптимизаций в размерах CPU и GPU мы реализовали возможность получения сообщений в режиме реального времени во время прокрутки на вкладке «Сообщения», чего на данный момент нет в аналогичных ведущих отечественных приложениях, кроме того, мы не отстаем; также расширили старую версию. Ограничение в 150 сеансов соответствует интерфейсу чата. Все узлы сеансов пользователя загружаются в форме пейджинга, как показано ниже:
Получайте сообщения во время прокрутки без задержек
Скорость входа в интерфейс группового чата и чата с друзьями также была качественно улучшена. Несмотря на ускорение анимации входа, по-прежнему гарантированно можно сразу увидеть самый последний контент чата. Как показано на рисунке ниже — одна и та же учетная запись заходит на одну и ту же страницу чата. Левая часть — эффект до оптимизации. Страница чата отображается почти полностью, а контент все еще загружается. Правая часть — эффект после оптимизации. Страница чата отображается лишь немного, аватар отправителя и содержимое сообщения могут отображаться. уже видно.
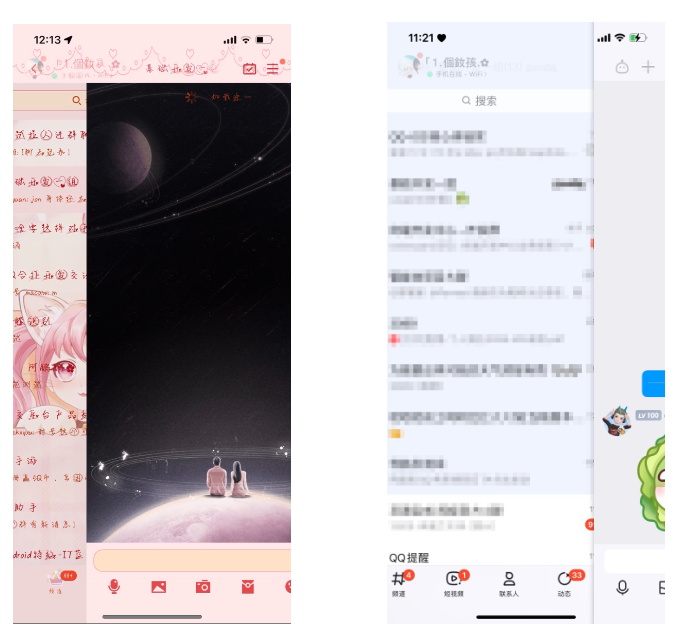
Введите сравнительную диаграмму скорости загрузки страницы чата (слева — до оптимизации, справа — после оптимизации)
Помимо улучшения скорости входа, скорость перелистывания страниц контента чата также достигла высшего уровня в отрасли: она превзошла лучшие отечественные аналогичные приложения и сравнилась с Telegram. Независимо от того, сколько сообщений у пользователя, их все можно увидеть, постоянно подтягивая вверх, и пользователь не может воспринимать состояние загрузки.
Сравнение страницы чата до и после оптимизации (сверху — до оптимизации, снизу — после оптимизации)
2.3 Молодость всегда рядом – система борьбы с деградацией
Завоевать страну легко, но защитить ее трудно. Борьба с деградацией — это головная боль для всех технических команд, достигших определенного масштаба. Столкнувшись со сложной деловой и технической задолженностью, команда Hand Q вложила 3 года в итеративную оптимизацию. Теперь система борьбы с деградацией Hand Q достигла передового уровня в отрасли. уровень. Как хранитель качества руки Q, мы назвали его Ходор (Держи дверь).
Цель борьбы с ухудшением: заранее обнаружить некоторые основные проблемы пути и предотвратить снижение производительности с помощью контроля доступа.
- Контроль доступа к слиянию главных магистралей: для более стабильных показателей,Автоматическая проверка перед слиянием.
- Ежедневный автоматический коносамент: для случайных проблем разработан этап для их предварительного обнаружения.
- Панель данных о производительности: нормализованная панель с подробными данными, производительность с точки зрения Бога.
- Робот-сигнализатор: настройка правил сигнализации для каждого измерения,Вопросы обратной связи как можно скорее.
Общее решение основано на Instruments Коллекция технологий динамического отслеживания diagnostic Диагностические данные; Автоматический анализ trace Точная атрибуция файлов и стеков перевода выполняется для каждой представленной сборки для точного обнаружения проблем, а также имеется панель визуализации данных; + Автоматический коносамент распространять,Переместите массу влевосдвигразвиватьэтап。финальныйвыполнить Понятнопроизводительность Отчет、данныеанализировать、Интеллектуальное планирование、Оповещение о коносаменте、Управление устройствами、Управление вариантами использования и ряд возможностей. Одна картинка, чтобы подвести итог:
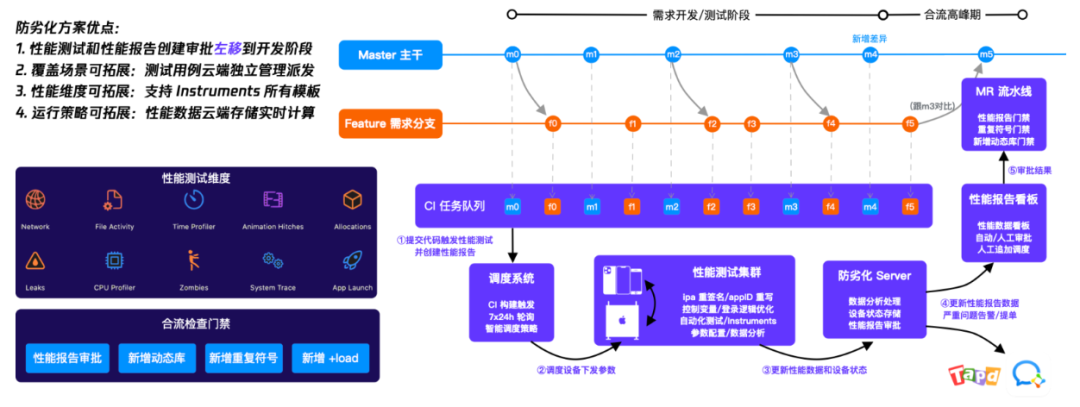
Введение в системные решения по предотвращению износа
Xcode 12 начал предоставлять xctrace, и многие проблемы, решенные в его примечаниях к выпуску, также были основаны на выводах и отзывах команды Mobile Q в процессе разработки, направленной на предотвращение деградации. Что касается оптимизации производительности, QQ тесно сотрудничает с командой производительности Apple, и каждый будет работать сверхурочно, чтобы преодолеть разницу во времени между Китаем и США.
С момента запуска всей системы предотвращения деградации мобильной Q она эффективно обеспечивала стабильность базовой сети разработки, обнаруживала большое количество проблем с производительностью и сбоями, а также предотвращала многие проблемы с производительностью, вызванные новыми требованиями.
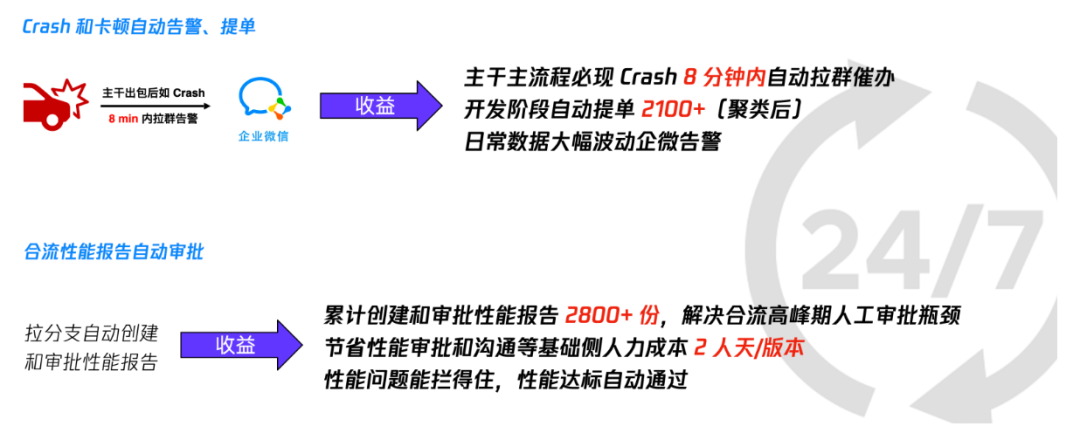
Таблица результатов борьбы с ухудшением качества
На данный момент Ходор рассмотрел десятки сценариев и работает на пяти платформах: iOS/Android/Windows/macOS/Linux.
03. Легкий и освежающий QQ 9
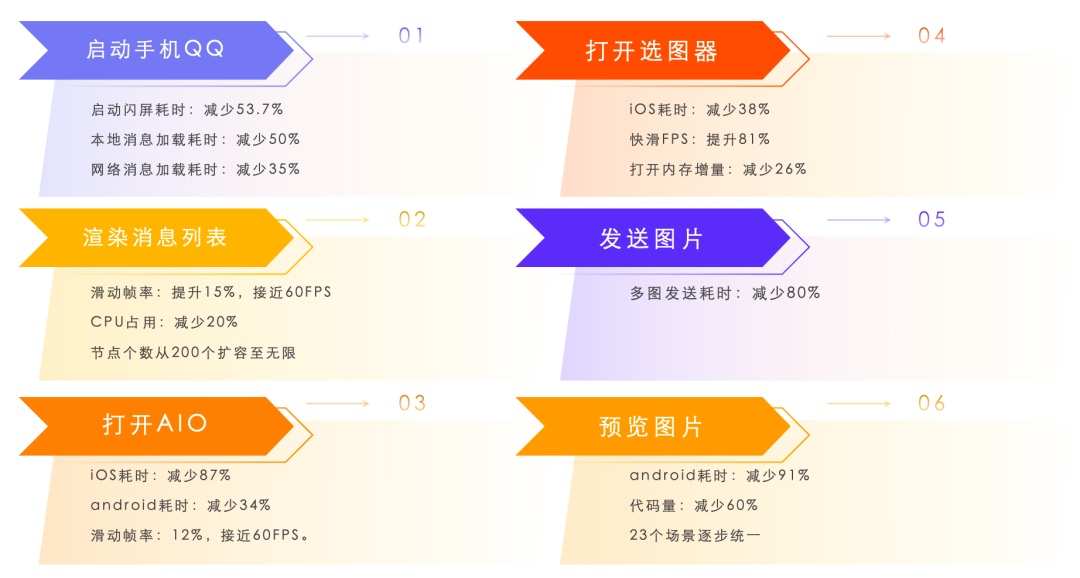
После вышеупомянутой всесторонней оптимизации производительность QQ 9 в различных сценариях значительно улучшилась по сравнению с исторической версией, как показано на следующем рисунке:
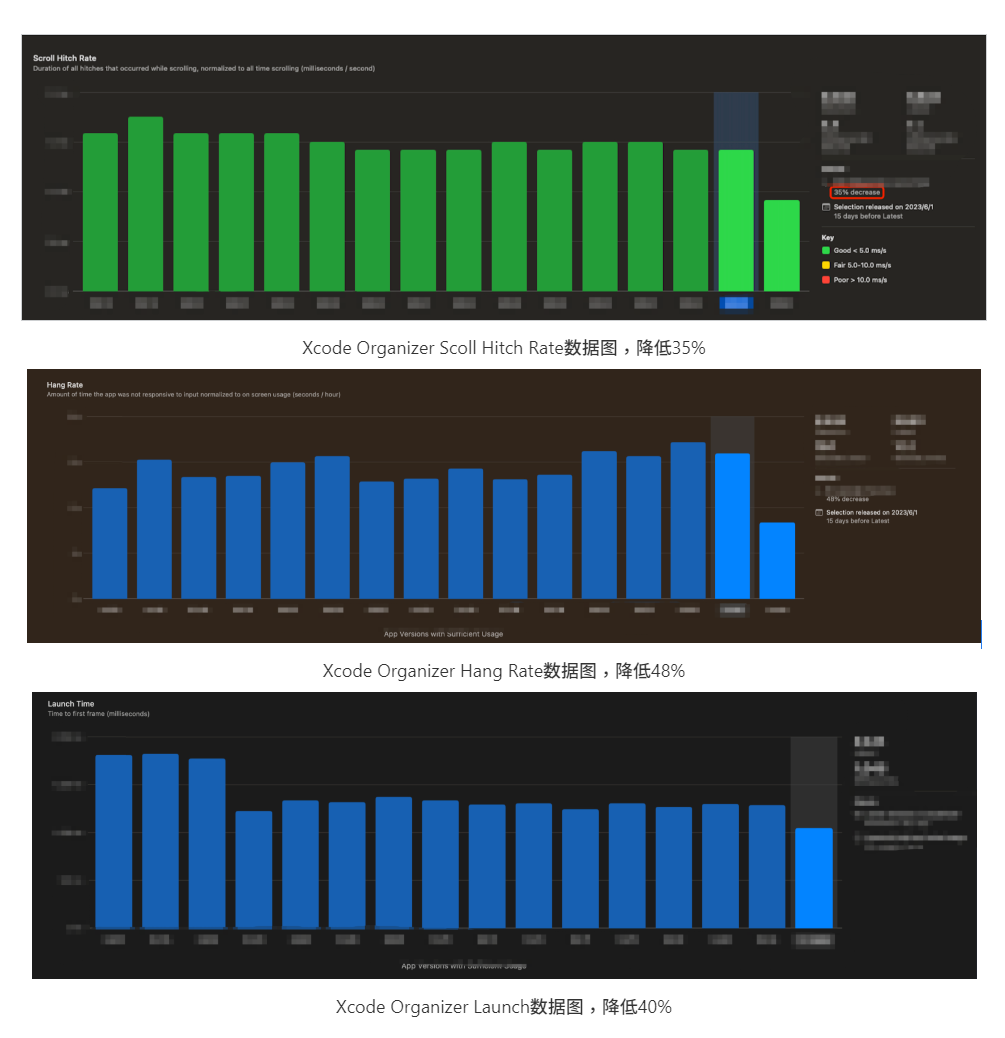
Используя официальный инструмент Apple: Xcode Organizer, вы можете увидеть, что беглость QQ 9 на 35% выше, чем 50-й процентиль предыдущей версии, скорость задержки снижена на 48%, а время запуска уменьшено на 40%. Как показано ниже.
04. Резюме и перспективы
В этой статье мы представляем техническую реализацию QQ 9 Silky, представляем полную оптимизацию процессов, которую мы сделали с точки зрения производительности с точки зрения таких аспектов, как скорость запуска, обновление страниц, алгоритм различия, предварительная загрузка и перезагрузка, асинхронная компоновка и рендеринг, а также представляем несколько аспектов производительности сценариев для улучшения пользовательского опыта.
На самом деле, техническая область глубока и сложна, и каждый пункт оптимизации можно рассмотреть и объяснить отдельно. Из-за нехватки места в будущем мы сможем делиться этим с вами лишь постепенно.
Я надеюсь, что улучшения, внесенные технической командой QQ, смогут существенно улучшить пользовательский опыт. Я также надеюсь, что QQ будет становиться все лучше и лучше, потому что каждый из нас — один из 500 миллионов, кто настаивает на использовании QQ;
-End-
Автор оригинала: Чжан Чжао, Би Лэй
Соавторы: Ян Сяоюй, Яо Вэйбинь, Дай Лимин, Мэй Юншэн, Линь Сяорун, Ван Чжэ
Техническое руководство: Чжун Юй, Тан Кун
Все еще хотите знать истории QQ 9? Добро пожаловать, чтобы оставлять комментарии и сообщения.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
