PyTorch в действии: реализация распознавания рукописных цифр MNIST
Предисловие
Можно сказать, что PyTorch является наиболее подходящим для обучения среди трех основных платформ. По сравнению с другими основными платформами, простота и удобство использования PyTorch делают его лучшим выбором для новичков. Я хочу подчеркнуть, что фреймворк можно сравнить с языком программирования, который является для нас лишь инструментом для достижения проектных эффектов, то есть с колесами, которые мы используем для создания автомобилей. На чем нам нужно сосредоточиться, так это на понимании. как использовать Torch для реализации функций, не слишком заботясь об этом. Как сделать колеса, отнимет у нас слишком много времени на обучение. В будущем выйдет серия статей, подробно объясняющих структуру глубокого обучения, но только позже мы лучше познакомимся с теоретическими знаниями и практическими операциями глубокого обучения, прежде чем сможем начать изучать то, что нам больше всего нужно. На данном этапе необходимо научиться пользоваться этими инструментами.
Содержание глубокого обучения не так-то просто освоить. Оно содержит много математических теоретических знаний и множество принципов расчетных формул, которые требуют рассуждений. А без фактической эксплуатации трудно понять, какую роль в конечном итоге играет код, который мы пишем, в структуре вычислений на основе нейронных сетей. Тем не менее, я сделаю все возможное, чтобы упростить знания и преобразовать их в контент, с которым мы более знакомы. Я сделаю все возможное, чтобы каждый мог понять и ознакомиться с структурой нейронной сети, чтобы обеспечить плавное понимание и плавный вывод, а также старайтесь не использовать слишком много математических формул и профессиональных теоретических знаний. Быстро разберитесь и реализуйте алгоритм в одной статье и овладейте этими знаниями наиболее эффективным способом.
1. Загрузка набора данных
MNIST (Модифицированный национальный институт стандартов и технологий) — это набор рукописных цифр, обычно используемый для обучения различных систем обработки изображений.
Он содержит большое количество изображений рукописных цифр, эти цифры варьируются от 0 до 9. Каждое изображение представляет собой изображение в оттенках серого размером 28x28 пикселей, представляющее рукописную цифру.

Набор данных MNIST разделен на две части: обучающий набор и тестовый набор. Обучающий набор обычно содержит 60 000 изображений и используется для обучения модели. Тестовый набор содержит 10 000 изображений и используется для оценки производительности модели.
Набор данных MNIST — это очень популярный набор данных, который используется для тестирования и проверки различных моделей машинного и глубокого обучения, особенно в задачах распознавания изображений. Вы можете напрямую посетить официальный сайт, чтобы загрузить, или использовать torchvision в программе для загрузки набора данных.
Всего существует 4 файла: обучающий набор, метки обучающего набора, тестовый набор и метки тестового набора:
Имя файла | размер | содержание |
|---|---|---|
train-labels-idx1-ubyte.gz | 9,681 kb | 55 000 обучающих наборов и 5 000 проверочных наборов |
train-labels-idx1-ubyte.gz | 29 kb | Метки, соответствующие изображениям обучающего набора |
t10k-images-idx3-ubyte.gz | 1,611 kb | 10 000 наборов тестов |
t10k-labels-idx1-ubyte.gz | 5 kb | Метки, соответствующие изображениям тестового набора |
Программа загружает набор данных MNIST:
from torch.utils.data import DataLoader
import torchvision.datasets as dsets
transform = transforms.Compose([
transforms.Grayscale(num_output_channels=1), # Преобразовать изображение в оттенки серого
transforms.ToTensor(), # Преобразовать изображение в тензор
transforms.Normalize((0.1307,), (0.3081,))
])
#MNIST dataset
train_dataset = dsets.MNIST(root = '/ml/pymnist', #Выбираем корневой каталог данных
train = True, #Выбрать тренировочный набор
transform = transform, #Не рассматривайте возможность использования какой-либо предварительной обработки данных
download = True #Скачать картинки из Интернета
)
test_dataset = dsets.MNIST(root = '/ml/pymnist',#Выбираем корневой каталог данных
train = False,#Выбрать набор тестов
transform = transform, #Не рассматривайте возможность использования какой-либо предварительной обработки данных
download = True #Скачать картинки из Интернета
)
#Загрузить данные
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size = batch_size,
shuffle = True #Дезорганизуйте данные
)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size = batch_size,
shuffle = True
)Дисплей изображения:
import matplotlib.pyplot as plt
digit = train_dataset.train_data[0]
plt.imshow(digit,cmap=plt.cm.binary,interpolation='none')
plt.title("Labels: {}".format(train_dataset.train_labels[0]))
plt.show()
После этого вам нужно разделить набор данных на обучающий и тестовый набор. Набор данных MNIST уже готов и может быть использован напрямую:
print("train_data:",train_dataset.train_data.size())
print("train_labels:",train_dataset.train_labels.size())
print("test_data:",test_dataset.test_data.size())
print("test_labels:",test_dataset.test_labels.size())выход
train_data: torch.Size([60000, 28, 28])
train_labels: torch.Size([60000])
test_data: torch.Size([10000, 28, 28])
test_labels: torch.Size([10000])Также необходимо определиться с размером партии.,В обучении нейронных сетей,batch_size Это относится к количеству выборок, обрабатываемых моделью одновременно во время каждой итерации обучения.
в общем,Выбирайте правильный разумноbatch_sizeМожет сделать тренировочный процесс более эффективным、Стабилизировать,И это может улучшить способность модели к обобщению. Однако,Слишком большойbatch_sizeМожет вызвать переполнение памяти или замедление обучения.,слишком маленькийbatch_sizeМожет вызвать трудности со сходимостью моделей.。поэтому,Выберите правильныйbatch_sizeТребуется отладка и оптимизация на практике。
print("Трансформация:",train_loader.batch_size)
print("load_train_data:",train_loader.dataset.train_data.shape)
print("load_train_labels:",train_loader.dataset.train_labels.shape)выход:
Размер лота: 100
load_train_data: torch.Size([60000, 28, 28])
load_train_labels: torch.Size([60000])Из результатов выходных,Вы можете видеть, что общее количество строк в исходном наборе данных и наборе данных, прочитанном в пакетном режиме, одинаково.,В реальной работе train_loader и test_loader будут использоваться в качестве источника входных данных нейронной сети.
2. Определить нейронную сеть
В предыдущей статье я несколько раз предлагал вам построить нейронную сеть.,Обратите внимание на инициализацию сети и соответствующего входного слоя.,Скрытый слой и выходной слой.
import torch.nn as nn
import torch
input_size = 784 Пиксели #mnist имеют размер 28*28.
hidden_size = 500
num_classes = 10#выход — 10 категорий, соответствующих 0~9.
#Создаем модель нейронной сети
class Neural_net(nn.Module):
#Функция инициализации принимает размерность пользовательских входных объектов, размерность объекта скрытого слоя и размерность объекта выходного слоя.
def __init__(self,input_num,hidden_size,out_put):
super(Neural_net,self).__init__()
self.layer1 = nn.Linear(input_num,hidden_size) #Линейная обработка от ввода до скрытого слоя
self.layer2 = nn.Linear(hidden_size,out_put) #Линейная обработка от скрытого слоя к выходному слою
def forward(self,x):
x = self.layer1(x) #Линейный расчет от входного слоя к скрытому слою
x = torch.relu(x) #Активация скрытого слоя
x = self.layer2(x) #выходной слой, обратите внимание, что выходной слой напрямую связан с потерями
return x
net = Neural_net(input_size,hidden_size,num_classes)
print(net)выход:
Neural_net( (layer1): Linear(in_features=784, out_features=500, bias=True) (layer2): Linear(in_features=500, out_features=10, bias=True) )super(Neural_net, self).init() да Python Способ вызова методов или свойств родительского класса. Вот, Neural_net да Имя класса определенной вами модели нейронной сети, которое наследует nn.Module класс, пока nn.Module да PyTorch Базовый класс для построения моделей нейронных сетей. Другими словами, ваша модель нейронной сети унаследует nn.Module все свойства и методы, чтобы вы могли Neural_net используется в классе nn.Module Определены различные функции, такие как добавление слоев нейронной сети, указание функций потерь и т. д.
3. Модель обучения
Просто обратите внимание на Variable, о которой говорилось в предыдущей статье.
Переменная — абстракция для построения вычислительных графов в более ранних версиях PyTorch (до версии 0.4).,Он содержит такие атрибуты, как data, grad и grad_fn.,Может использоваться для построения вычислительных графиков.,И автоматически вычислять градиенты во время обратного распространения ошибки. Но из PyTorch Начиная с версии 0.4 от Variable официально отказались, а Tensor напрямую поддерживает функцию автоматического вывода, и нет необходимости явно создавать Variable.
поэтому,AutogradдаPyTorch реализует основной механизм автоматического вывода,Переменная — это абстракция, использовавшаяся в ранних версиях для построения вычислительных графов.,Сейчас былоTensorзаменен на。 Autograd автоматически отслеживает операции в Tensor и при необходимости рассчитывает градиенты, обеспечивая обратное распространение ошибки.
#optimization
import numpy as np
from torchvision import transforms
learning_rate = 1e-3 #скорость обучения
num_epoches = 5
criterion =nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(),lr = learning_rate) #стохастический градиентный спуск
for epoch in range(num_epoches):
print('current epoch = %d' % epoch)
for i ,(images,labels) in enumerate(train_loader,0):
images=images.view(-1,28*28)
outputs = net(images) #Переносим набор данных в сеть для прямого расчета
labels = torch.tensor(labels, dtype=torch.long)
loss = criterion(outputs, labels) #Рассчитать потерю
optimizer.zero_grad() #Перед обратным распространением сначала проверьте состояние сети
loss.backward() #LossBackpropagation
optimizer.step() #Обновить параметры
if i % 100 == 0:
print('current loss = %.5f' % loss.item())
print('finished training')4. Проверка точности
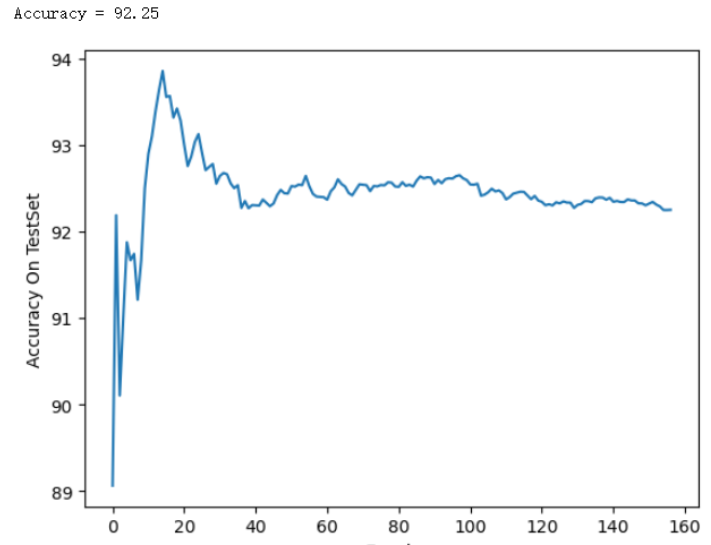
После того, как веса каждого слоя обновляются с помощью Loss с помощью метода стохастического градиентного спуска, точность цифровой классификации для тестового набора:
#prediction
total = 0
correct =0
acc_list_test = []
for images,labels in test_loader:
images=images.view(-1,28*28)
outputs = net(images) #Переносим набор данных в сеть для прямого расчета
_,predicts = torch.max(outputs.data,1)
total += labels.size(0)
correct += (predicts == labels).sum()
acc_list_test.append(100 * correct / total)
print('Accuracy = %.2f'%(100 * correct / total))
plt.plot(acc_list_test)
plt.xlabel('Epoch')
plt.ylabel('Accuracy On TestSet')
plt.show()
Вот и вседа Все в этом выпускесодержание。ядаfanstuck , если у вас есть вопросы, оставьте сообщение для обсуждения. , увидимся в следующий раз.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
