Python устарел, а Hadoop устарел? Практическая интерпретация классики с нуля.

👉Введение
Если рабочий хочет хорошо выполнять свою работу, он должен сначала заточить свои инструменты. Будучи кроссплатформенным языком программирования, Python обладает характеристиками интерпретируемости, вариативности, интерактивности и объектно-ориентированности и может применяться для независимой разработки проектов. Сегодня мы специально пригласили автора публичного аккаунта «Технология Бинхэ» и преподавателя Бинхэ из Tencent Cloud TVP. Он даст нам пошаговое обучение тому, как реализовать подсчет слов на основе Python+Hadoop.
👉Содержание
1 Принцип и механизм работы Hadoop
2. Создайте автономную среду Hadoop
3. Установите рабочую среду Python3.
4 Подсчет количества слов на основе Python+Hadoop
5 Резюме
За последние десять лет Python и Hadoop были золотой комбинацией для обработки больших данных. В последние годы популярность приобрел Mojo, претендующий на замену Python, и продолжалась риторика оскорбления Hadoop. С появлением крупных модельных технологий, представленных ChatGPT и Tencent Hunyuan, эта область открыла новые проблемы и возможности. Python+Hadoop, стоит ли изучать эту золотую пару сегодня, в 2023 году? Сегодня мы объясним техническое очарование классики на пошаговом примере практического проекта.
В сегодняшней среде больших данных данные генерируются постоянно, и объем данных, обрабатываемых каждый день, намного превышает объем данных, которые может хранить и вычислять один компьютер. Как хранить и обрабатывать эти данные, стало двумя основными проблемами в области больших данных, и появление Hadoop эффективно решило эту проблему. Две основные технологии, которые он предоставляет: распределенная файловая система HDFS и параллельные вычисления MapReduce, успешно обеспечивают надежную гарантию. для хранения и расчета больших данных.
В этой статье кратко представлены базовые знания, принципы и механизм работы Hadoop, создается локальный режим Hadoop с нуля и реализована функция подсчета слов на основе Python+Hadoop.
01.Принцип и механизм работы Hadoop
Как мы все знаем, Hadoop, как базовая платформа распределенной системы с открытым исходным кодом, в основном включает в себя два основных компонента: распределенную файловую систему HDFS и структуру распределенных параллельных вычислений MapReduce. Кроме того, эти два основных компонента являются основой и краеугольным камнем обработки больших данных Hadoop. В число важных компонентов Hadoop также входят: Hadoop Common и платформа YARN. В настоящее время Hadoop в основном разрабатывается и поддерживается Apache Software Foundation.
Фактически, когда мы используем Hadoop, нам не нужно понимать основные детали распределенной системы. При разработке распределенных программ Hadoop нам нужно просто написать функции map() и функцию уменьшения(), чтобы завершить разработку. Hadoop и может в полной мере использовать крупномасштабные хранилища и высокопараллельные вычисления кластеров Hadoop для выполнения сложных услуг по обработке больших данных.
В то же время такие преимущества распределенной файловой системы Hadoop, как высокая отказоустойчивость и высокая масштабируемость, позволяют развертывать Hadoop на дешевых серверных кластерах, что может значительно сэкономить затраты на хранение больших объемов данных. Высокая степень отказоустойчивости MapReduce эффективно обеспечивает точность результатов расчетов системы и в целом решает проблему надежного хранения и обработки больших данных.
Фактически, основные (или важные) компоненты Hadoop в основном включают в себя: Hadoop Common, распределенную файловую систему HDFS, структуру распределенных вычислений MapReduce и структуру планирования ресурсов YARN. Далее давайте кратко разберемся с работающими процессами HDFS, MapReduce и YARN.
1.1 Распределенная файловая система HDFS
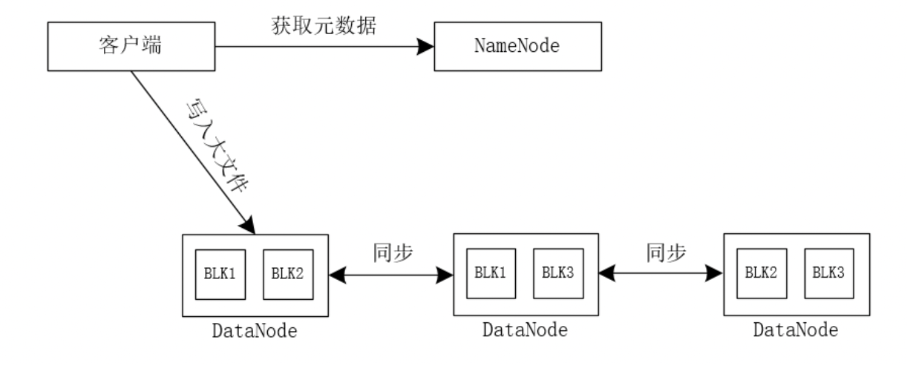
Во-первых, Hadoop разделит большой файл на N небольших блоков данных и сохранит их в разных узлах данных соответственно, как показано на рисунке 1.
(рис. 1)
Когда мы записываем большой файл в Hadoop, клиент сначала получает информацию метаданных с сервера NameNode. После получения информации метаданных он записывает файл в соответствующий узел данных. Платформа Hadoop сравнивает размер файла с размером файла. блок данных. Если размер файла меньше размера блока данных, файл не будет разделен и будет сохранен непосредственно в соответствующем блоке данных, если размер файла больше размера; блок данных, Hadoop Платформа разделит исходный большой файл на несколько файлов блоков данных и сохранит эти файлы блоков данных в соответствующих блоках данных. При этом по умолчанию каждый блок данных сохраняет 3 копии и сохраняет их в разных узлах данных.
Поскольку узел NameNode в Hadoop хранит метаданные всего кластера данных и отвечает за управление данными всего кластера, он немного отличается от других традиционных распределенных файловых систем при чтении/записи данных.
Простой процесс чтения данных в Hadoop показан на рисунке ниже.

(рис. 2)
- Клиент выдает запрос на чтение данных, запрашивая NameNode узелиз Юаньданные。
- Узел NameNode возвращает клиенту информацию о метаданных.
- Клиент на основе NameNode Узел возвращает информацию о данных элемента, прибытие соответствует из DataNode Чтение данных блока на узле. Если прочитанный файл относительно большой, он будет. Hadoop Разрезайте данные на несколько частей, сохраняйте возможность приезжать в разные места. DataNode начальство.
- После прочтения 3 изданных блоков,Если данные не закончили чтение,Затем прочитайте данные.
- После прочтения 4 изданных блоков,Если данные не закончили чтение,Затем прочитайте данные.
- Уведомление после прочтения всех изданных NameNode Закройте поток данных.
Простой процесс записи данных в Hadoop показан на рисунке ниже.

(рис. 3)
- клиент для NameNode Узел инициирует метазапрос и указывает путь загрузки файла. В это время NameNode. Внутри узла будет выполняться ряд операций из, таких как: проверка легальности пути, указанного клиентом, наличия у клиента возможности записи Разрешения и т. д. После прохождения проверки NameNode Узел выделяет информацию о блочном хранилище для файла.
- Клиент узла NameNode К возвращает информацию метаданных и возвращает выходной поток клиенту.
- После того, как клиент получает выходной поток данных приезжающего элемента, он начинает записывать блоки данных в узел Кпервый DataNode.
- первый DataNode Узел отправляет блок данных второму DataNode узел, второй DataNode Узел отправляет блок данных третьему DataNode узел,и так далее,Завершите все изданные блоки.
- Каждый Узел DataNode будет двигаться вверх по течению. Узел DataNode отправляет сообщение с подтверждением результата, чтобы гарантировать целостность записи данных.
- Клиент узла DataNode K отправляет информацию о подтверждении результата, чтобы гарантировать успешную запись данных.
- Когда все изданные блоки записаны,И после того, как клиент получит сообщение об успехе прибытия, напишет сообщение с подтверждением.,клиент будет К NameNode Узел отправляет запрос на закрытие потока данных NameNode. Узел закроет ранее созданный выходной поток.
1.2 Платформа распределенных вычислений MapReduce
Стоит отметить, что среда распределенных вычислений Hadoop MapReduce разбивает большую сложную вычислительную задачу на небольшие простые вычислительные задачи. Эти декомпозированные вычислительные задачи будут выполняться параллельно в среде MapReduce, а затем промежуточные результаты вычислений сортируются. агрегированные и другие операции на основе ключа, и, наконец, выводится окончательный результат расчета.
Мы можем разделить весь этот процесс MapReduce на: этап ввода данных, этап отображения, этап обработки промежуточного результата (включая этап объединителя и этап перемешивания), этап сокращения и этап вывода данных.
Этап ввода данных: ввод данных для обработки в систему MapReduce.
Этап карты: параметры в функцию map() вводятся в виде пар ключ-значение. После серии параллельных обработок функцией map() промежуточные результаты выводятся на локальный диск.
Этап обработки промежуточного результата: этот этап также включает в себя этап сумматора и этап перемешивания. Промежуточные результаты, выводимые функцией map(), сортируются и агрегируются по ключу, и выполняется серия операций с данными с одним и тем же ключом. ввод в ту же функцию сокращения() Обработка (пользователи сами также могут указать правила распределения данных в соответствии с реальными условиями).
Этап сокращения: входные параметры функции сокращения вводятся в виде набора ключей и соответствующих значений. После обработки функцией сокращения генерируется ряд окончательных результирующих данных в виде пар ключ-значение, которые выводятся в файл. распределенная файловая система HDFS.
Этап вывода данных: данные выводятся из системы MapReduce в распределенную файловую систему HDFS.
Вышеупомянутый краткий процесс выполнения показан на рисунке 4.

(рис. 4)
Исходные данные вводятся на этап карты в виде «(k, данные строки исходных данных)». После серии параллельных обработок функцией map() этапа карты данные промежуточного результата обрабатываются в виде из «{(k1, v1), (k1, v2)}» выводится на локальный компьютер, а затем обрабатывается этапом обработки промежуточного результата платформы MapReduce. Этот этап обработки промежуточного результата сортирует и агрегирует данные в соответствии с ключом. и отправляет данные с тем же ключом в ту же функцию сокращения.
Затем мы переходим на этап сокращения. Все данные, полученные на этапе сокращения, имеют форму «{k1,[v1, v2]...}». После обработки этих данных на этапе сокращения мы наконец получаем «{ ( k1,v3)}" и выведите окончательные данные результата в распределенную файловую систему HDFS.
1.3 Система планирования ресурсов YARN
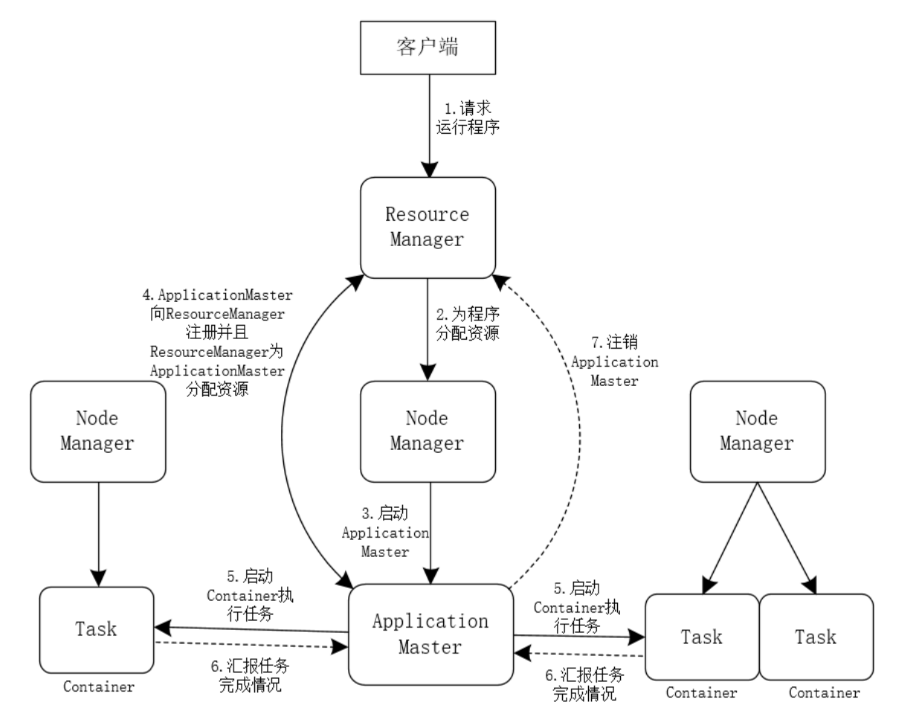
Платформа YARN в основном отвечает за распределение ресурсов и планирование Hadoop, и ее рабочий процесс можно упростить, как показано на рисунке 5.
(рис. 5)
- клиент для ResourceManager проблемабегатьприложениепрограммаизпросить。
- После получения запроса клиента на посещение приложения ResourceManager выделяет ресурсы прикладной программе.
- ResourceManager для запуска ApplicationMaster в NodeManager.
- ApplicationMaster регистрируется в ResourceManager, чтобы ResourceManager мог постоянно получать информацию о состоянии процесса выполняемых задач; в то же время ResourceManager выделяет ресурсы для ApplicationMaster и отправляет информацию о выделении ресурсов в ApplicationMaster.
- После того как ApplicationMaster получает информацию о выделенных ресурсах, он запускает Контейнер на соответствующем узле и выполняет определенные задачи Task.
- Контейнер постоянно взаимодействует с ApplicationMaster и сообщает ApplicationMaster о состоянии выполнения задачи.
- Когда все задачи выполнены, ApplicationMaster отправляет ResourceManager запрос на выход из системы.
02. Создайте автономную среду Hadoop
Для простой демонстрации здесь мы создаем автономную среду Hadoop. По умолчанию все установили операционную систему CentOS7 и настроили среду JDK. Информация о конкретной среде следующая.
- Операционная система: CentOS7
- Имя хоста: binghe102
- IP-адрес: 192.168.184.102
- Версия JDK: 1.8
- Версия Hadoop: Apache Hadoop 3.2.0.
Примечание. Эта часть операции выполняется путем входа на сервер CentOS7 в качестве пользователя Hadoop.
2.1 Настройка базовой среды операционной системы
В основном мы являемся пользователями Hadoop для установки и запуска Hadoop, поэтому сначала нам необходимо добавить пользователей Hadoop на сервер.
(1) Добавьте группу пользователей Hadoop и пользователя.
Сначала нам нужно войти в учетную запись root и выполнить следующую команду, чтобы добавить группу пользователей и пользователя Hadoop.
groupadd hadoop
useradd -r -g hadoop hadoop(2) Предоставьте права доступа к каталогу пользователю Hadoop.
Чтобы облегчить установку среды Hadoop, нам необходимо предоставить пользователю Hadoop разрешения на доступ к каталогу /usr/local сервера. Конкретные команды следующие.
mkdir -p /home/hadoop
chown -R hadoop.hadoop /usr/local/
chown -R hadoop.hadoop /tmp/
chown -R hadoop.hadoop /home/(3) Предоставьте разрешения sudo пользователю Hadoop.
Здесь мы в основном редактируем файл /etc/sudoers через редактор vim, чтобы предоставить права sudo пользователю Hadoop. Конкретные операции заключаются в следующем:
vim /etc/sudoersЗатем найдите следующий код.
root ALL=(ALL) ALLЗатем добавьте следующий код после этой строки кода.
hadoop ALL=(ALL) ALLПримечание. Поскольку файл «/etc/sudoers» доступен только для чтения, сохраните файл «/etc/sudoers» и закройте его с помощью команды «wq!».
(4) Укажите пароль пользователя Hadoop.
Мы используем следующий метод для назначения паролей пользователям Hadoop.
[root@binghe102 ~]# clear
[root@binghe102 ~]# passwd hadoop
Changing password for user hadoop.
New password: Введите пароль
BAD PASSWORD: The password is shorter than 8 characters
Retype new password: снова Введите пароль
passwd: all authentication tokens updated successfully.(5) Отключите брандмауэр
И введите следующую команду в командной строке, чтобы отключить брандмауэр CentOS7.
systemctl stop firewalld
systemctl disable firewalld(6) Настройте вход пользователя Hadoop без пароля.
Наконец, войдите на сервер как пользователь Hadoop и введите следующие команды, чтобы настроить вход без пароля для пользователя Hadoop.
ssh-keygen -t rsa
cat /home/hadoop/.ssh/id_rsa.pub >> /home/hadoop/.ssh/authorized_keys
chmod 700 /home/hadoop/
chmod 700 /home/hadoop/.ssh
chmod 644 /home/hadoop/.ssh/authorized_keys
chmod 600 /home/hadoop/.ssh/id_rsa
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub Имя хоста (IP-адрес)2.2. Настройка локального режима Hadoop
Фактически, режим локальной установки Hadoop является самым простым из трех режимов установки. Нам нужно только настроить JAVA_HOME в файле Hadoop-env.sh Hadoop.
(1) Загрузите установочный пакет Hadoop.
Сначала нам нужно ввести следующую команду в командной строке CentOS7, чтобы загрузить установочный пакет Hadoop.
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz(2) Разархивируйте установочный пакет Hadoop.
Затем введите следующую команду в командной строке CentOS7, чтобы распаковать установочный пакет Hadoop.
tar -zxvf hadoop-3.2.0.tar.gz (3) Настройте переменные среды Hadoop.
Затем добавьте следующее содержимое в файл /etc/profile.
HADOOP_HOME=/usr/local/hadoop-3.2.0
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH HADOOP_HOMEЗатем введите следующую команду, чтобы переменные среды вступили в силу.
source /etc/profile(4) Проверьте статус установки Hadoop.
Введите команду Hadoop version в командной строке CentOS7, чтобы проверить, успешно ли настроена среда Hadoop, как показано ниже.
-bash-4.2$ hadoop version
Hadoop 3.2.0
Source code repository https://github.com/apache/hadoop.git -r e97acb3bd8f3befd27418996fa5d4b50bf2e17bf
Compiled by sunilg on 2019-01-08T06:08Z
Compiled with protoc 2.5.0
From source with checksum d3f0795ed0d9dc378e2c785d3668f39
This command was run using /usr/local/hadoop-3.2.0/share/hadoop/common/hadoop-common-3.2.0.jarКак видите, мы выводим номер версии Hadoop, указывающий на то, что среда Hadoop была успешно построена.
(5) Размещение Hadoop
Здесь мы в основном настраиваем файл Hadoop-env.sh в каталоге /etc/hadoop в каталоге установки Hadoop. Например, мы установили Hadoop в каталог /usr/local/hadoop-3.2.0, поэтому Hadoop-env. Файл .sh находится в каталоге /usr/local/hadoop-3.2.0/etc/hadoop.
Сначала откройте файл Hadoop-env.sh с помощью редактора Vim, как показано ниже.
vim /usr/local/hadoop-3.2.0/etc/hadoop/hadoop-env.shЗатем найдите следующий код.
# export JAVA_HOME=Затем откройте комментарий и укажите каталог установки JDK после знака равенства.
export JAVA_HOME=/usr/local/jdk1.8.0_321На этом этапе создание среды Hadoop завершено.
03. Установите рабочую среду Python3.
Версия Python по умолчанию, установленная в операционной системе CentOS7, — 2.7.5. Здесь мы обновляем версию Python до 3.7.4.
Примечание. Эта часть операции выполняется путем входа на сервер CentOS7 в качестве пользователя root.
3.1 Просмотр исходной версии Python
Мы можем просмотреть текущую версию Python, введя Python непосредственно в командной строке, как показано ниже.
[root@binghe102 ~]# python
Python 2.7.5 (default, Oct 14 2020, 14:45:30)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux2
Type "help", "copyright", "credits" or "license" for more information.Как видите, установленная по умолчанию версия Python CentOS7 — 2.7.5. Далее мы обновим версию Python до 3.7.4.
3.2 Установите среду Python3
(1) Установите базовую среду компиляции.
Во-первых, нам нужно ввести следующую команду в командной строке сервера, чтобы установить базовую среду компиляции.
yum install -y zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel zlib* libffi-devel readline-devel tk-devel(2) Загрузите установочный пакет Python.
Затем мы вводим следующую команду в командной строке сервера, чтобы загрузить установочный пакет Python.
wget https://www.python.org/ftp/python/3.7.4/Python-3.7.4.tgz(3) Разархивируйте установочный пакет Python.
Затем введите следующую команду, чтобы распаковать установочный пакет Python.
tar -zxvf Python-3.7.4.tgz(4) Установите среду Python
Затем войдите в каталог распаковки Python, как показано ниже.
cd Python-3.7.4Затем мы вводим следующие команды, чтобы установить среду Python.
./configure
make && make install(5) Проверьте результаты установки.
Наконец, мы вводим команду Python3 в командной строке, чтобы проверить результаты установки, как показано ниже.
[root@binghe102 ~]# python3
Python 3.7.4 (default, Nov 26 2023, 15:04:38)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.Мы видим, что после входа в Python3 версия Python успешно выводится как 3.7.4, что указывает на то, что наша среда Python3 успешно установлена.
04. Подсчитайте количество слов на основе Python+Hadoop.
В процессе подсчета количества слов мы можем реализовать программу Hadoop Mapper и программу Редуктор на основе Python.
Примечание. Операции в этой части выполняются путем входа на сервер CentOS7 в качестве пользователя Hadoop.
4.1 Реализация программы Mapper
Сначала мы создаем файл mapper.py в каталоге /home/hadoop/python сервера. Конкретный код выглядит следующим образом.
import sys
#Читать в стандартном вводе серединаизданные
for line in sys.stdin:
#Удалить начальные и конечные пробелы
line = line.strip()
#Разделить каждую строку пробелами
words = line.split()
#Проходим по списку слов и выводим результаты между серединами, разделенными \t
for word in words:
print('%s\t%s' % (word, 1))Как мы видим из вышеизложенного, код в Mapper.py в основном считывает данные из стандартного ввода, удаляет начальные и конечные пробелы считанных данных, а затем разбивает их в соответствии с пробелами, затем обходит разделенный массив, а затем массив может быть Каждый элемент выводится на стандартный вывод.
4.2 Реализация программы Редуктор
Мы создаем файл редуктора.py в каталоге /home/hadoop/python сервера. Конкретный код выглядит следующим образом.
import sys
#Текущая обработка слова
handler_word = None
#Обработанное на данный момент количество
handler_count = 0
#Текущие результаты середина серединаиз слова
word = None
#Читаем данные со стандартного ввода
for line in sys.stdin:
#Удалить начальные и конечные пробелы
line = line.strip()
#Разделить результат между картизсередина с помощью \tданные
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
if handler_word == word:
handler_count += count
else:
if handler_word:
#Текущая обработка статистических результатов прибывает в стандартный вывод
print('%s\t%s' % (handler_word, handler_count))
handler_word = word
handler_count = count
#Вывод статистической информации о последнем обработанном слове
if handler_word == word:
print('%s\t%s' % (handler_word, handler_count))Как видите, функция редуктора.py заключается в чтении данных результата, выводимых Mapper.py, подсчете количества каждого слова, а затем выводе окончательных данных результата.
4.3 Создание входных данных
Мы создаем новый файл data.input в каталоге /home/hadoop/input сервера. Содержимое файла следующее.
hadoop mapreduce hive flume
hbase spark storm flume
sqoop hadoop hive kafka
spark hadoop stormКак видите, мы добавили некоторые словесные данные в качестве файла тестовых данных в файл data.input.
4.4 Запуск программ Python на основе Hadoop
Чтобы запустить программу Python на основе Hadoop, мы вводим в командной строке следующее:
hadoop jar /usr/local/hadoop-3.2.0/share/hadoop/tools/lib/hadoop-streaming-3.2.0.jar -file /home/hadoop/python/mapper.py -mapper "python3 mapper.py" -file /home/hadoop/python/reducer.py -reducer "python3 reducer.py" -input /home/hadoop/input/data.input -output /home/hadoop/outputСреди них значение параметров приведенной выше команды следующее.
- hadoop банка: использовать Hadoop бегатьпрограмма。
- /usr/local/hadoop-3.2.0/share/hadoop/tools/lib/hadoop-streaming-3.2.0.jar: пакет Jar, в котором находится API потоковой передачи Hadoop, который в основном предоставляет интерфейсы программирования на других языках.
- -file /home/hadoop/python/mapper.py: укажите расположение каталога программирования Python на этапе карты.
- -mapper "python3 mapper.py": спецификация Команда выполнения программы Python фазы отображения.
- -file /home/hadoop/python/reducer.py: укажите Reduce этап Python программаизрасположение каталога。
- -reducer "python3 редуктор.py": спецификация Reduce этап Python программаизвыполнить команду。
- -input /home/hadoop/input/data.input: укажите каталог тестового файла.
- -output /home/hadoop/output: укажите каталог для вывода результатов.
В журнале вывода имеется следующая информация, указывающая на то, что мы успешно запустили программу MapReduce, написанную на Python на основе Hadoop.
INFO mapreduce.Job: map 100% reduce 100%
INFO mapreduce.Job: Job job_local307776602_0001 completed successfullЗатем мы просматриваем содержимое вывода в каталоге /home/hadoop/output, как показано ниже.
-bash-4.2$ ll /home/hadoop/output
total 4
-rw-r--r--. 1 hadoop hadoop 76 Nov 26 15:32 part-00000
-rw-r--r--. 1 hadoop hadoop 0 Nov 26 15:32 _SUCCESSЗатем просмотрите содержимое файла part-00000, как показано ниже.
-bash-4.2$ cat /home/hadoop/output/part-00000
flume 2
hadoop 3
hbase 1
hive 2
kafka 1
mapreduce 1
spark 2
sqoop 1
storm 2Мы видим, что каждое слово и соответствующее статистическое число выводятся в файле part-00000.
05. Резюме
В последнее время большие модели, представленные ChatGPT, стали очень популярны, но эти большие модели требуют огромных объемов данных в качестве основы для обучения и анализа искусственного интеллекта. Что касается модели параметров, то это также модель параметров с сотнями миллиардов или триллионов параметров, которая также требует огромных данных в качестве основы для анализа. Хотя сегодняшняя технология онлайн-анализа в реальном времени очень развита, технология автономной пакетной обработки в качестве резервной меры и механизма проверки данных для анализа данных по-прежнему является незаменимым и важным техническим компонентом в современную эпоху больших данных и искусственного интеллекта.
Hadoop не только поддерживает технологию автономной пакетной обработки с MapReduce в качестве ядра, но и предоставляемая им распределенная файловая система HDFS обеспечивает надежное хранение больших объемов данных. Кроме того, хотя основные функции Hadoop написаны на Java, Hadoop поддерживает несколько языков программирования для реализации технологии автономной пакетной обработки больших данных. Учитывая преимущества Python в анализе данных и статистике, Hadoop, естественно, также поддерживает реализацию на основе Python. . Технология пакетной обработки больших объемов данных в автономном режиме. Таким образом, Python+Hadoop по-прежнему является важной комбинированной технологией для реализации анализа пакетной обработки в автономном режиме и статистики больших данных в эпоху ChatGPT.
Часть этой статьи взята из книги «Практическая борьба с массовой обработкой данных и технологиями больших данных». В ней в основном представлены базовые знания Hadoop, а также принципы и механизмы работы Hadoop с трех точек зрения: HDFS, MapReduce и YARN, а также принципы и механизмы работы Hadoop. создает Hadoop с практической точки зрения, устанавливает рабочую среду Python3 и, наконец, реализует кейс-программу для подсчета количества слов на основе Python+Hadoop.
Я надеюсь, что вы сможете что-то почерпнуть из этой статьи. Чтобы узнать больше, прочтите книгу «Массовая обработка данных и технологии больших данных на практике».
-End-
Автор оригинала|Бинхэ



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
