[python] Используйте docxtpl и Jinja2 для создания документов Word на основе шаблонов.
введение
Вы когда-нибудь сталкивались со сценарием, когда вам нужно создать индивидуальный документ Word на основе определенного шаблона? Что касается создания и настройки документов, нам часто нужен гибкий и эффективный метод создания документов Word на основе шаблонов. Эта статья принимает json Информация о конфигурации отображается в виде таблицы вWordслучай,Расскажите, как использоватьdocxtpl、python-docx и Jinja2ЭтиPythonбиблиотека для реализации существующихWordшаблонгенерировать Персонализированные документы。
принцип
При использовании Microsoft Word для редактирования шаблона документа вручную вы можете напрямую вставить теги Jinja2 в документ и сохранить документ как файл .docx (формат XML). Затем используйте docxtpl, чтобы загрузить этот шаблон .docx, и передайте связанные переменные контекста в соответствии с синтаксисом Jinja2, чтобы создать нужный документ Word.
docxtpl Это библиотека, разработанная на основе python-docxиjinja2. документация Основная причина, по которой автор разработал его, заключается в том, что python-docx хорош для создания текстовых документов, но не хорош для их изменения.
docxtpl В основном зависит от двух пакетов:python-docx для чтения и письмаwordдокумент;jinja2 Используется для управления тегами, вставленными в шаблоны.
Установить:
pip install docxtplСинтаксис, подобный Jinja2
Часть содержания здесь взята из:https://blog.51cto.com/u_11866025/5659528
4 важных эксклюзивных лейбла
Обычный синтаксис Jinja2 содержит только обычные теги %, тогда как синтаксис класса docxtpl включает %p, %tr, %tc и %r:
{%p jinja2_tag %} for paragraphs Абзац, соответствующий объекту docx.text.paragraph.Paragraph.
{%tr jinja2_tag %} for table rows Строка в таблице, соответствующая объекту docx.table._Row.
{%tc jinja2_tag %} for table columns Столбец в таблице, соответствующий объекту docx.table._Column.
{%r jinja2_tag %} for runs фрагмент в абзаце,переписыватьсяdocx.text.run.RunобъектИспользуя эти теги, python-docx-template помещает настоящие теги Jinja2 в правильное место в исходном коде XML документа.
PS: Для этих четырех типов тегов начальные теги не могут находиться в одной строке, а должны находиться в разных строках, иначе они не смогут корректно отображаться.
Например:
{%p if display_paragraph %}Here is my paragraph {%p endif %}Нужно переписать так:
{%p if display_paragraph %}
Here is my paragraph
{%p endif %}Обработка таблиц и объединение ячеек
- Объединить ячейки по горизонтали
Добавьте следующее перед содержимым ячейки, которое нужно объединить в цикле for:
{% hm %}- Объединить ячейки по вертикали
Добавьте следующее перед содержимым ячейки, которое нужно объединить в цикле for:
{% vm %}Подготовьте данные
прежде чем прочитать документ,Нам необходимо подготовить данные для вставки в документ. Эти данные могут поступать из различных источников,Например, база данных, API или локальные файлы. В соответствии с реальной ситуацией,Мы можем получить и Подготовьте данные, используя соответствующие методы.,и сохраните его в подходящей структуре данных,Например, словари, списки и т. д.
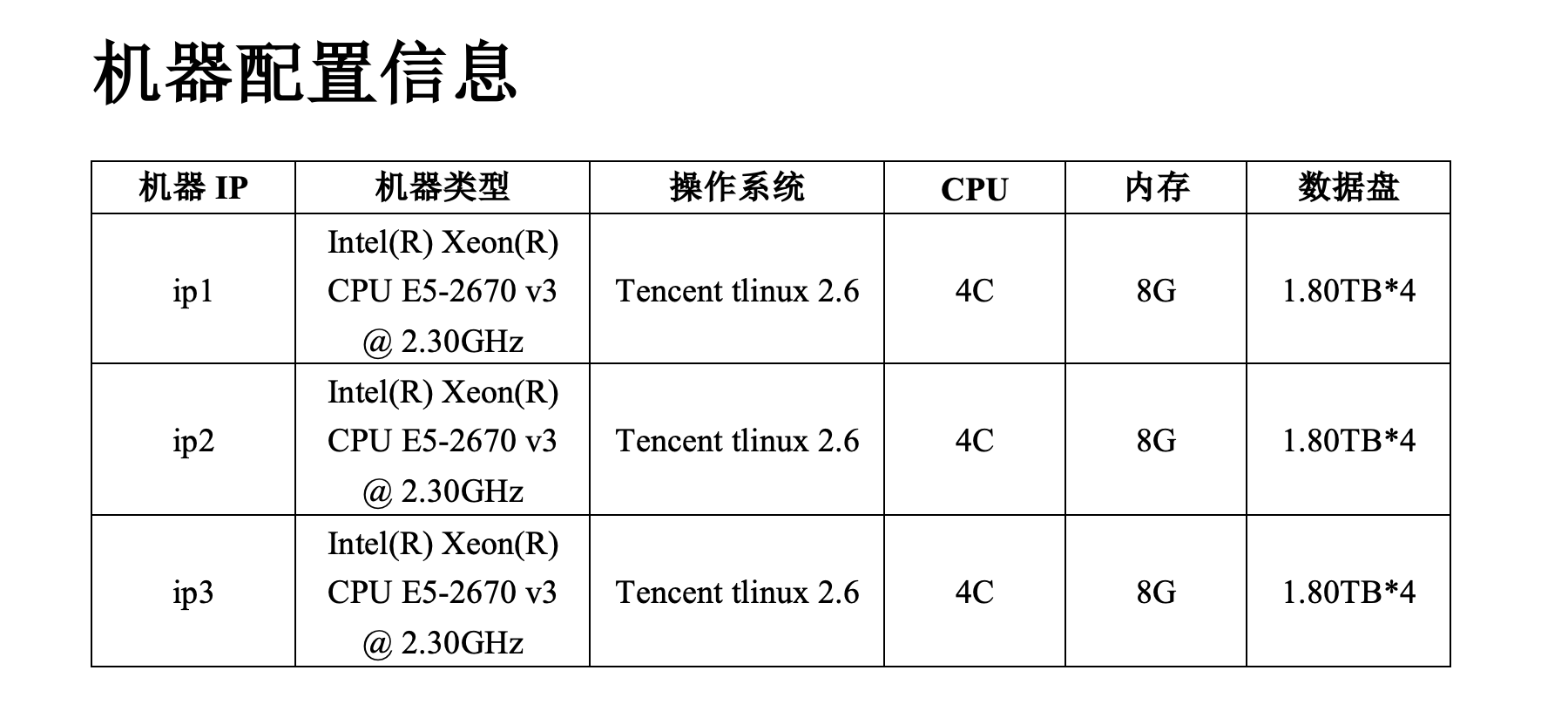
В этом случае данные, которые необходимо вставить в Word, представляют собой информацию о конфигурации ключевых параметров нескольких компьютеров с Linux. Конкретные примеры данных приведены ниже:
{
"node_config": {
"ip1": {
"check_hostnamectl": {
"hostname": "node01",
"operating_system": "Tencent tlinux 2.6",
"kernel": "Linux 5.4.119-1-tlinux4-0010",
"architecture": "x86-64"
},
"check_cpu_metrics": {
"cpu_num": "4C",
"model_name": "Intel(R) Xeon(R) CPU E5-2670 v3 @ 2.30GHz"
},
"check_physical_cpu": {
"physical_cpu": "4C"
},
"check_physical_mem": {
"physical_mem": "8G"
},
"check_nvme": {
"nvme_size": "1.80TB*4"
}
},
"ip2": {
"check_hostnamectl": {
"hostname": "node02",
"operating_system": "Tencent tlinux 2.6",
"kernel": "Linux 5.4.119-1-tlinux4-0010",
"architecture": "x86-64"
},
"check_cpu_metrics": {
"cpu_num": "4C",
"model_name": "Intel(R) Xeon(R) CPU E5-2670 v3 @ 2.30GHz"
},
"check_physical_cpu": {
"physical_cpu": "4C"
},
"check_physical_mem": {
"physical_mem": "8G"
},
"check_nvme": {
"nvme_size": "1.80TB*4"
}
},
"ip3": {
"check_hostnamectl": {
"hostname": "node03",
"operating_system": "Tencent tlinux 2.6",
"kernel": "Linux 5.4.119-1-tlinux4-0010",
"architecture": "x86-64"
},
"check_cpu_metrics": {
"cpu_num": "4C",
"model_name": "Intel(R) Xeon(R) CPU E5-2670 v3 @ 2.30GHz"
},
"check_physical_cpu": {
"physical_cpu": "4C"
},
"check_physical_mem": {
"physical_mem": "8G"
},
"check_nvme": {
"nvme_size": "1.80TB*4"
}
}
}
}Создать шаблон документа Word
Далее нам нужно создать шаблон документа Word, содержащий заполнители. Эти заполнители будут заменены фактическим содержимым во время последующего создания документа. использовать Jinja2 В грамматике шаблона мы можем определить заполнители и заменяемый контент. Например, вы можете использовать {{ todo }}Представляет заполнитель。
На основе приведенного выше json пример выходного шаблона таблицы Word выглядит следующим образом:
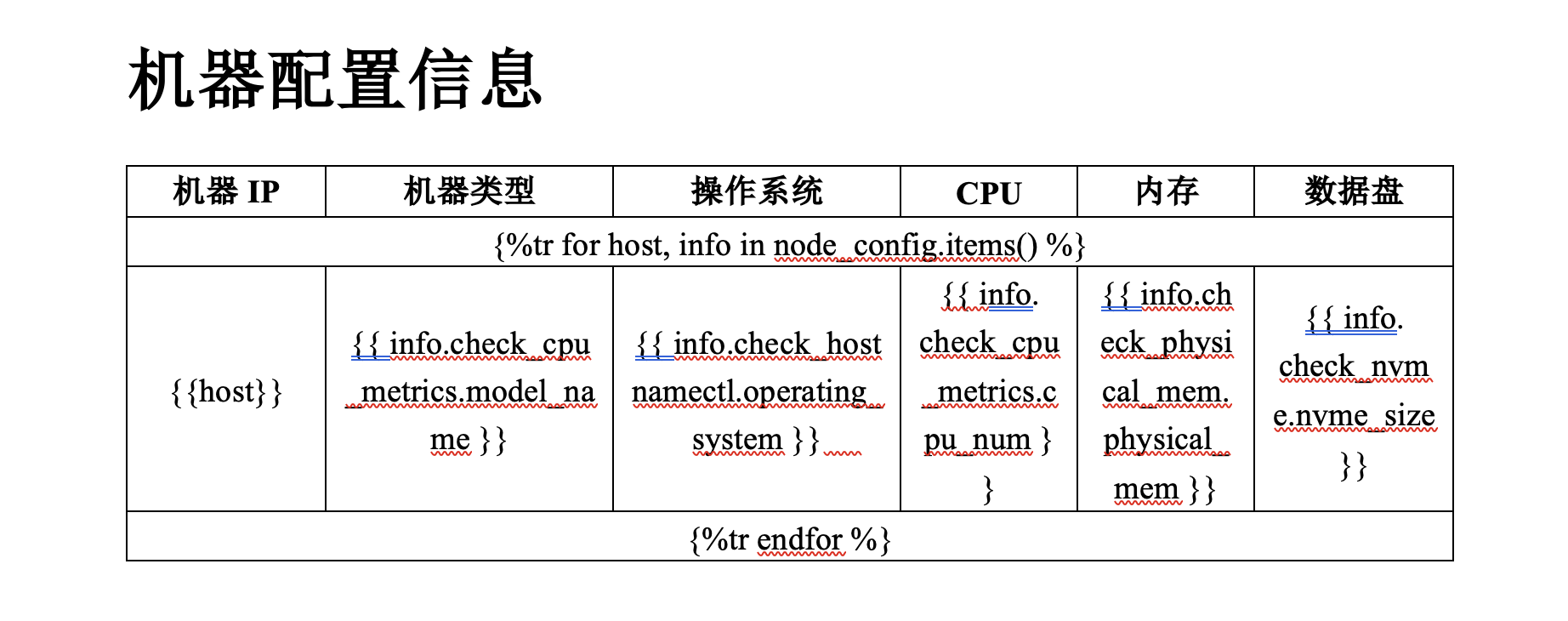
Рендеринг и создание документов
Теперь мы можем использовать docxtpl и Jinja2 заполнить данные в шаблон документа и сгенерировать окончательный документ.
первый,нам нужно загрузитьшаблонфайл и создайтеDocxTemplateобъект。Затем,Мы передаем данные вшаблонобъект,использоватьrenderметод Рендеринг документа。наконец,Вы можете сохранить документ в локальном файле или загрузить его напрямую.
import json
from docxtpl import DocxTemplate
def generate_word(input_path, out_path):
# путь к шаблону
template_path = "/path/to/template.docx"
# Чтобы загрузить файл шаблона, используйте DocxTemplate добрый Конвертировать файлы шаблонов в docx объект документа
docx = DocxTemplate(template_path)
# Получите данные для вставки в документ
with open(input_path, "r") as f:
input_data = json.load(f)
# Рендеринг документа
docx.render(input_data)
# Сохранить документ для рассмотрения
docx.save(out_path)
if __name__ == "__main__":
input_path = "/path/to/config.json"
out_path = "/path/to/config.docx"
try:
generate_word(input_path, out_path)
print("генерировать word Файл успешен")
except Exception as e:
print("генерировать word Файл не выполнен: {}".format(e))Сгенерированный эффект Word выглядит следующим образом:
Если окончательно сгенерированный Word состоит из нескольких шаблонов .docx, вы можете использовать следующий код:
import json
import os
from docxtpl import DocxTemplate
from docx import Document
from docxcompose.composer import Composer
def generate_word(input_path, output_path):
# Определить список путей к файлам шаблонов
path_lst = ["/path/to/template-1.docx",
"/path/to/template-2.docx",
"/path/to/template-3.docx"]
# Загрузите список путей к файлам шаблонов как DocxTemplate список объектов
doc_lst = [DocxTemplate(i) for i in path_lst]
# Определите список для хранения временных путей к файлам
rm_lst = []
# Чтение файла входных данных
with open(input_path, "r") as f:
input_data = json.load(f)
# Определить объект объединителя документов
composer = None
# траверсшаблонсписок объектов
for index, docx in enumerate(doc_lst):
# Укажите временный путь к документу
docx_path = "{}-test.docx".format(index)
# Добавить временный путь к документу для удаления списка
rm_lst.append(docx_path)
# Документ шаблона рендеринга
docx.render(input_data)
# Сохраните визуализированный документ
docx.save(docx_path)
# Загрузите временный документ как Document объект
docx_context = Document(docx_path)
# Определите, является ли это первым документом. Если да, назначьте его непосредственно комбинатору. В противном случае добавьте его в комбинатор.
if index == 0:
composer = Composer(docx_context)
else:
composer.append(docx_context)
# Сохраните объединенный документ
composer.save(output_path)
# Удалить временные файлы
for path in rm_lst:
os.remove(path)
if __name__ == "__main__":
input_path = "/path/to/config.json"
out_path = "/path/to/config.docx"
try:
generate_word(input_path, out_path)
print("генерировать Word Файл успешен")
except Exception as e:
print("генерировать Word Файл не выполнен: {}".format(e))Подвести итог
использоватьdocxtplиJinja2может легкогенерироватьна основешаблоннастройкиWordдокумент。Этот видметодупрощенныйдокументгенерироватьпроцесс,Повышенная эффективность. Мы можем создавать шаблоны на основе конкретных потребностей.,И использовать соответствующие данные для Рендеринга и создания документов. По индивидуальному стилю и формату,Мы можем удовлетворить различные потребности в документации.
ссылка



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
