Python автоматически читает PDF-файлы, поэтому рекомендуется использовать библиотеку pdfplumber!
Привет, я Го Чжэнь
pdfplumber это Python библиотека, предназначенная для рабов PDF 文件中Извлечение текста и табличных данныхИ дизайн。
Сравнение других библиотек обработки PDF,pdfplumber Больше внимания уделяется сохранению визуального расположения текста на странице, что делает его полезным при работе со страницами, содержащими сложные макеты или несколько столбцов текста. PDF работать лучше с файлами。pdfplumber зависит от PDFMiner анализировать PDF файл, но обеспечивает более удобный и интуитивно понятный API。
Основные особенности
- извлечение текста:
pdfplumberМожет точно извлечь текст на странице,Сохраняя информацию о макете текста,Это полезно для анализа структуры документа. - Извлечение таблицы:Он может обнаруживать и извлекать PDF листовые, что особенно ценно для проектов анализа данных, требующих извлечения данных из отчетов или исследовательских документов.
- Визуальная отладка:
pdfplumberПредоставляет способ визуализации страницы, позволяя пользователям понять, как текст и другие элементы организованы на странице. - гибкость:Это позволяет пользователям настраивать в соответствии со своими потребностями.извлечение текстовые стратегии, такие как извлечение определенной части текста или данных путем определения интересующей области страницы.
Установить
pdfplumber может пройти pip легкий Установить:
pip install pdfplumber
Пример использования
Ниже приведен базовый пример использования, показывает, как открыть PDF файл и извлеките его текстовое содержимое:
import pdfplumber
with pdfplumber.open("тест искусственного интеллекта.pdf") as pdf:
first_page = pdf.pages[0] # Получить первую страницу
text = first_page.extract_text() # Извлечь текст
print(text)

Это первая страница PDF-файла. Извлеченное текстовое содержимое печатается следующим образом:

Уровень точности по-прежнему относительно высок, но не на 100 %, а также извлекается содержимое таблицы.
Для добычи листовых,pdfplumber Также предусмотрен простой и прямой метод:
with pdfplumber.open("тест искусственного интеллекта.pdf") as pdf:
page = pdf.pages[0]
table = page.extract_table() # экстракт листовые
for row in table:
print(row)
Результаты извлечения содержимого таблицы следующие, и они полностью верны:
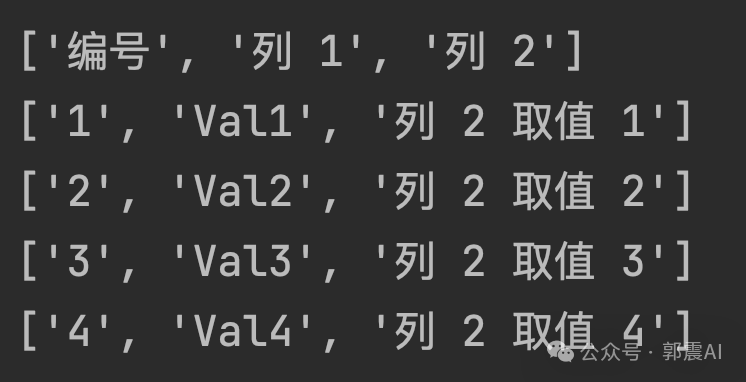
pdfplumber Благодаря своим простым, но мощным функциям он становится средством обработки PDF Мощный инструмент для задач извлечения текста и данных из файлов.,Особенно подходит для анализа данных и автоматического создания отчетов.и т. д.。



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
