pyspark (1) — основные понятия и принципы работы.
существоватьПредыдущая статьяВ мы представилибольшие Основные понятия данных,иУстановка писпарка。
В этой статье мы в основном знакомим с основными концепциями и принципами pyspark. Когда будет время, мы продолжим знакомить с использованием pyspark.
Mapreduce и RDD
Давайте сначала рассмотрим различия между Mapreduce и RDD, представленные ранее.
Идея MapReduce — «разделяй и властвуй». Mapper отвечает за «разделение», то есть разложение сложных задач на несколько «простых задач» для обработки; Редюсер отвечает за обобщение результатов этапа карты. Но одним из недостатков Mapreduce является то, что каждое вычисление требует чтения и записи данных с жесткого диска.
Spark — это механизм обработки больших данных, созданный для решения проблемы медленной вычислительной среды MapReduce. Используемая им конструкция RDD максимально избегает чтения и записи на жесткий диск и вместо этого сначала сохраняет данные в памяти. Чтобы максимально оптимизировать процесс вычислений RDD в памяти, также введена функция отложенного выполнения.
RDD (Resilient Distributed Dataset), эластичный распределенный набор данных. Он предоставляет множество операторов операций, а не только операции сопоставления и сокращения; он поддерживает ленивые операции, создавая DAG между RDD, а также не требует выполнения промежуточных результатов. Он также поддерживает кэширование и может быстро выполнять вычисления в памяти.
РДД имеет следующие свойства:
(1) Раздел: базовая единица набора данных. Во время расчета данные каждого сегмента получаются с помощью функции вычисления. Каждый сегмент обрабатывается вычислительной задачей. Сегментация определяет степень детализации вычислительной задачи.
(2) Только для чтения: RDD доступен только для чтения. Если вы хотите изменить данные RDD, вы можете преобразовать их в новый RDD на основе существующего RDD с помощью операторов операций.
В RDD есть два типа операторов: преобразование и действие. Преобразование только устанавливает процесс логического преобразования, а Spark внутренне вызывает процесс вычисления RDD для построения ориентированного ациклического графа (DAG).
(3) Зависимости. Как упоминалось выше, СДР преобразуются посредством арифметических операций, поэтому между СДР существуют зависимости.
Узкая зависимость: между разделами дочернего и родительского RDD существует взаимно однозначное соответствие. Существует только одна зависимость, и нет необходимости ждать других разделов. Например: карта, фильтр, объединение и другие операции создают узкие зависимости.
Широкая зависимость: между разделами в дочернем RDD и родительском RDD существует связь «один ко многим». Определенный раздел в дочернем RDD должен ожидать разделов из других или родительских RDD. Например, группировка и сортировка создают широкие зависимости.
(4) Кэширование: если RDD используется несколько раз и нет необходимости каждый раз преобразовывать его, мы можем кэшировать RDD, так что нам нужно будет вычислить его только один раз при вычислении, а в следующий раз просто извлечь его из кеша. .
Кстати, позвольте мне рассказать о нескольких понятиях: работа, перемешивание, этап и задача.
Задание: действие запускает задание.
Перетасовка: если преобразование или действие приводит к тому, что RDD имеет широкие зависимости, то есть разделы не могут быть распараллелены, и все сегменты необходимо разбить и реорганизовать (например, операции группировки, объединения), это перемешивание.
Этап: Задача — это группа обеспечения доступности баз данных, состоящая из RDD. Если существует процесс перемешивания, то это перемешивание делит поток задач на различные этапы, то есть этап. Из-за операции перемешивания различные этапы не могут быть распараллелены, и последующие этапы должны ждать завершения предыдущего этапа, прежде чем они смогут начаться.
Задача: конкретная задача. Задание создает несколько задач для одновременного выполнения в зависимости от количества разделов в RDD. Логика каждой задачи абсолютно одинакова, но данные в сегментах разные.
Как правило, задачи делятся на несколько заданий на основе действий, одно задание делится на несколько этапов на основе широких зависимостей (перемешивание), а один этап делится на несколько задач на основе количества осколков.
хадуп и спарк
Hadoop — это система инфраструктуры больших данных, которая обновляет NSDF и MapReduce.
Наиболее важные модули в архитектуре Hadoop: HBase (распределенная база данных реального времени), MapReduce (инфраструктура распределенных вычислений), HDFS (распределенная файловая система).
Spark — это улучшение по сравнению с медленными вычислениями Hadoop. Наиболее важные модули архитектуры Spark: Spark SQL, Spark Streaming, GraphX и MLlib построены на RDD.
Отношения между Hadoop и Mapreduce аналогичны отношениям между Spark и rdd.
Принцип работы искры
Spark в основном разработан на языке Scala, частично разработан на языке Java и работает на JVM. В то же время он инкапсулирован во внешний слой для реализации интерфейсов разработки для Python, R и других языков.
Кластер Spark состоит из менеджера кластера, рабочего узла Worker, исполнителя Executor, драйвера, приложения-приложения и других частей. Конкретные отношения заключаются в следующем:
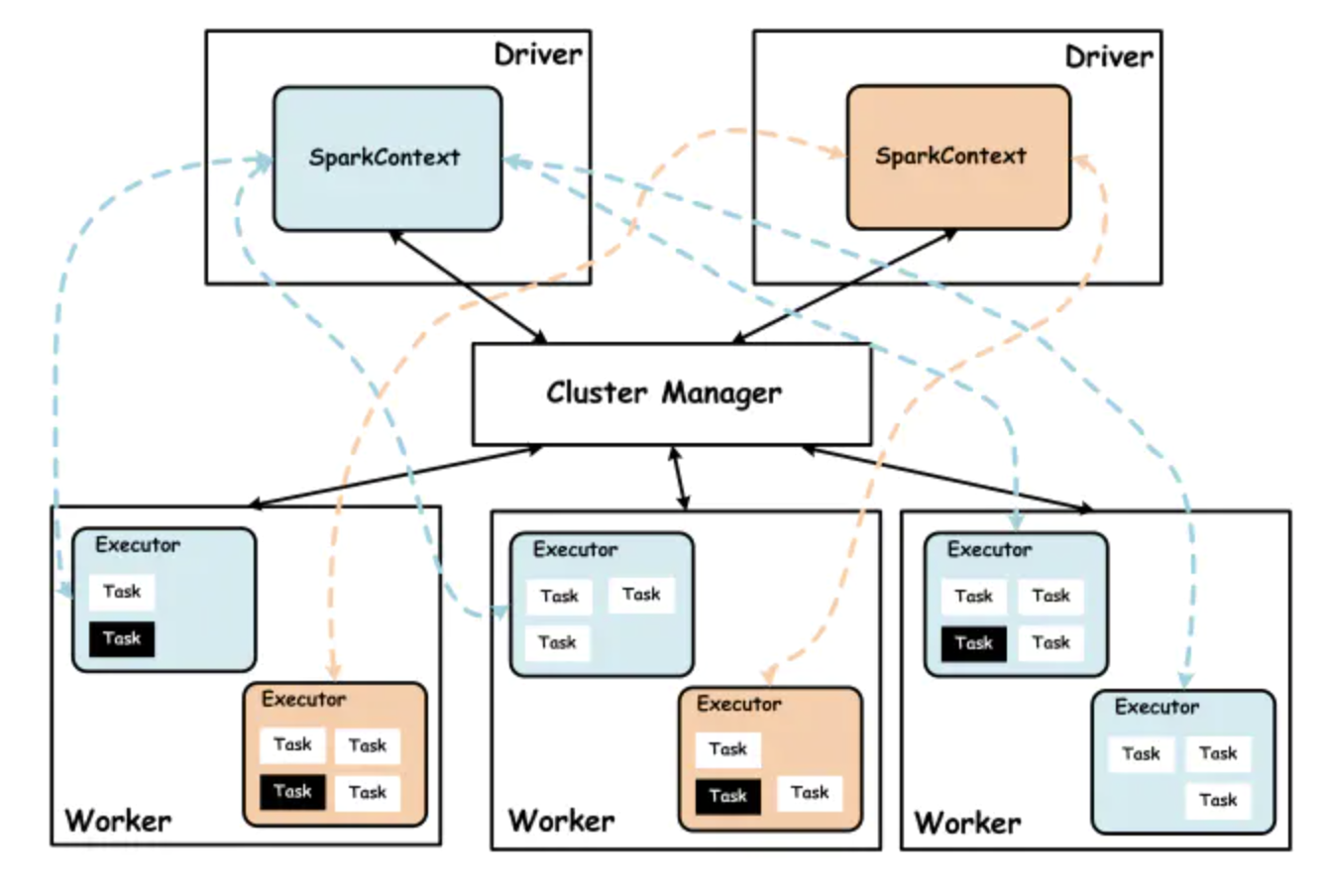
Cluter Manager
Менеджер кластера Spark в основном отвечает за распределение и управление всеми ресурсами кластера. По разным режимам развертывания они делятся на YARN, Mesos и Standalone. Spark развертывается на пряже в двух режимах работы: клиентском и кластерном. Разница заключается в том, работает ли драйвер на стороне клиента или на стороне ApplicationMaster.
Worker
Рабочий узел Spark, используемый для выполнения отправленных заданий. Работник в основном отвечает за отчетность перед менеджером по кластерам.
Сообщайте о собственных ресурсах ЦП и памяти, создавайте и назначайте ресурсы Исполнителю, а также синхронизируйте ресурсы и статус Исполнителя с Cluter Manager.
Executor
Приложение — это процесс, работающий на узле Worker, отвечающий за расчет задач и хранение данных в памяти или на диске.
Driver
Драйвер приложения, основная функция при запуске программы, создание SparkContext, разделение RDD и формирование DAG задач. Приложение взаимодействует с Cluter Manager и Executor через драйвер.
Application
Программы, реализуемые пользователями с использованием Spark, включают код драйвера и код исполнителя, распределенные в кластере и работающие на нескольких узлах.
Общий процесс примерно следующий: клиент запрашивает приложение из Yarn, Yarn запускает ApplicationMaster, когда видит достаточно ресурсов, а затем ApplicationMater запускает Driver, создает контекст, формирует поток задач, запускает и распределяет задачи по Executor и контролирует выполнение задач, а Executor запускает задачи. Выполняет конкретные задачи.
pyПринцип работы искры
Как упоминалось выше, Spark инкапсулирует интерфейс Python на внешнем уровне, в основном используя py4j для реализации взаимодействия между Python и Java. Таким образом, пользователям Python не нужно изучать другую Java, и они могут легко использовать Python для разработки больших данных.
py4j
py4j — это библиотека, реализованная на Python и Java. Через PY4J Python может динамически получать доступ к объектам Java на виртуальной машине Java, а программы Java также могут вызывать объекты Python.
Механизм реализации pyspark следующий:
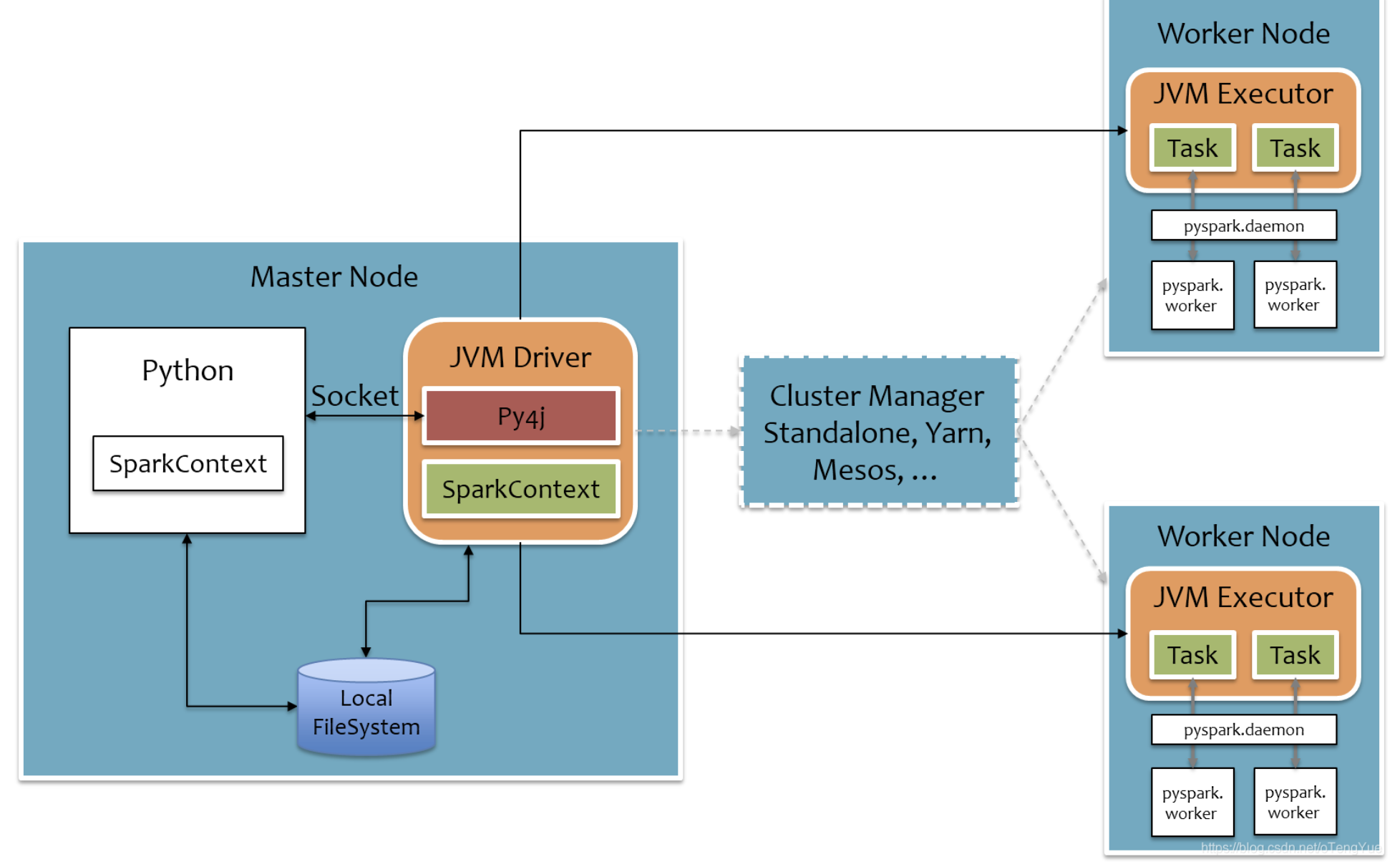

На стороне драйвера Spark выполняется в JVM, а Python вызывает методы Java через py4j. SparkContext использует Py4J для запуска JVM и создания JavaSparkContext для сопоставления программы pyspark с JVM;
На стороне Executor искра также выполняется в JVA. Задачи уже представляют собой упорядоченные байт-коды, поэтому нет необходимости использовать py4j. Однако, если он содержит некоторые функции библиотеки Python, JVM не может обрабатывать эти функции Python, поэтому потребуется каждая задача. Чтобы запустить процесс Python, выполнить функцию Python в процессе Python через соединение через сокет и вернуть результат.
Выше описано, как работает pyspark. Пользователям Python легче начать работу с Pyspark, но у него также есть фатальный недостаток: он медленный. В конце концов, у него есть слой упаковки. Вы можете выбрать pyspark для автономных задач, но для реальных задач лучше использовать Scala. -временные задачи.
ссылка:



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
