Путь к исследованию и разработке агентов искусственного интеллекта. Инженерная часть, часть 4. Развертывание Xinference в один клик, платформы службы вывода больших моделей
1. Введение
Предыдущая статьяСреда службы вывода большой языковой модели — ОлламапредставилOllama,Оллама завершает рассуждения одной строчкой превосходного дизайна: развернуть рамку.,Одна строка команд для выполнения задачи,Загрузка Модели не зависит от лестниц.,очень быстро,Значительно повысить эффективность Моделиразвертывания.,в то же время,При наличии нескольких карт графического процессора,Оллама может автоматически сегментировать модель для каждого графического процессора.,Блогер использует видеокарту V100 (одна карта видеопамяти 32Гб) развернутьllama3 70B (ожидается, что потребуется 40 ГБ видеопамяти), и выделение видеопамяти будет завершено автоматически.
Сегодня давайте представим Xinference,Сравните с Олламой,Xinference поставляется с Webui, чтобы сделать взаимодействие с пользователем более дружелюбным.,Просто нажмите на нужную Модель,автозаполнениеразвертывать,в то же время,Xinference может указать загрузку модели сообществом Modelscope при запуске.,Для тех, кто не может войтиОбнять лицопартнер,Это может значительно повысить эффективность загрузки модели.
Я все же хочу сказать здесь несколько слов. В области крупных моделей США на данный момент действительно лидируют. Все, что мы можем сделать, это попытаться догнать их. Однако в процессе догонения мы обнаружили, что многие из них. отличные проекты с открытым исходным кодом в области больших моделей имеют конфигурации по умолчанию, с одной стороны время загрузки модели даже превышает время знакомства с самим проектом, с другой стороны, ее вообще невозможно подключить, в результате чего. в проекте невозможно запустить, что приводит к акклиматизации этой земли. Конечно, для компаний и инженеров, которые выживают в этой жаркой стране, повышение порога обучения также может быть полезным, ха-ха.
2. Завершите локальное развертывание Xinference с помощью одной строки кода.
docker run -it --name xinference -d -p 9997:9997 -e XINFERENCE_MODEL_SRC=modelscope -e XINFERENCE_HOME=/workspace -v /yourworkspace/Xinference:/workspace --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0- docker run -it: запустить контейнер докеров и взаимодействовать с терминалом внутри.
- --name xinference: укажите имя Docker-контейнера как xinference. Если оно не установлено, оно будет сгенерировано случайным образом.
- -d: работает в фоновом режиме. Если не установлено, он войдет в контейнер докера.
- -p: 9997:9997, порт хоста: порт контейнера докера
- -e XINFERENCE_MODEL_SRC=modelscope: укажите источник модели как modelscope, значение по умолчанию — hf.
- -e XINFERENCE_HOME=/workspace: указывает корневой каталог xinference внутри контейнера докеров.
- -v /yourworkspace/Xinference:/workspace: укажите локальный каталог, который будет сопоставлен с корневым каталогом xinference в контейнере Docker.
- --gpus all: открыть все графические процессоры хоста в контейнере.
- xprobe/xinference:latest: извлеките последнюю версию проекта xinference издателя xprobe в dockerhub.
- xinference-local -H 0.0.0.0: выполнить эту команду после завершения развертывания контейнера.
3. Две строки кода завершают распределенное развертывание Xinference.
основное развертывание:
docker run -it --name xinference-master -d -p 9997:9997 -e XINFERENCE_MODEL_SRC=modelscope -e XINFERENCE_HOME=/workspace -v /yourworkspace/Xinference:/workspace --gpus all xprobe/xinference:latest xinference-supervisor -H "${master_host}"развертывание работы:
docker run -it --name xinference-worker -d -p 16500:16500 -e XINFERENCE_MODEL_SRC=modelscope -e XINFERENCE_HOME=/workspace -v /yourworkspace/Xinference:/workspace -e "http://${supervisor_host}:9997" -H "${worker_host}"4. Используйте webui «из коробки»
Браузер открывается:http://123.123.123.123:9997/ui/#/launch_model/llm
1.Launch Model
Начальные модели, включая языковые модели, модели изображений, речевые модели и пользовательские модели. Предоставляется окно поиска модели, а также включены базовые основные модели.
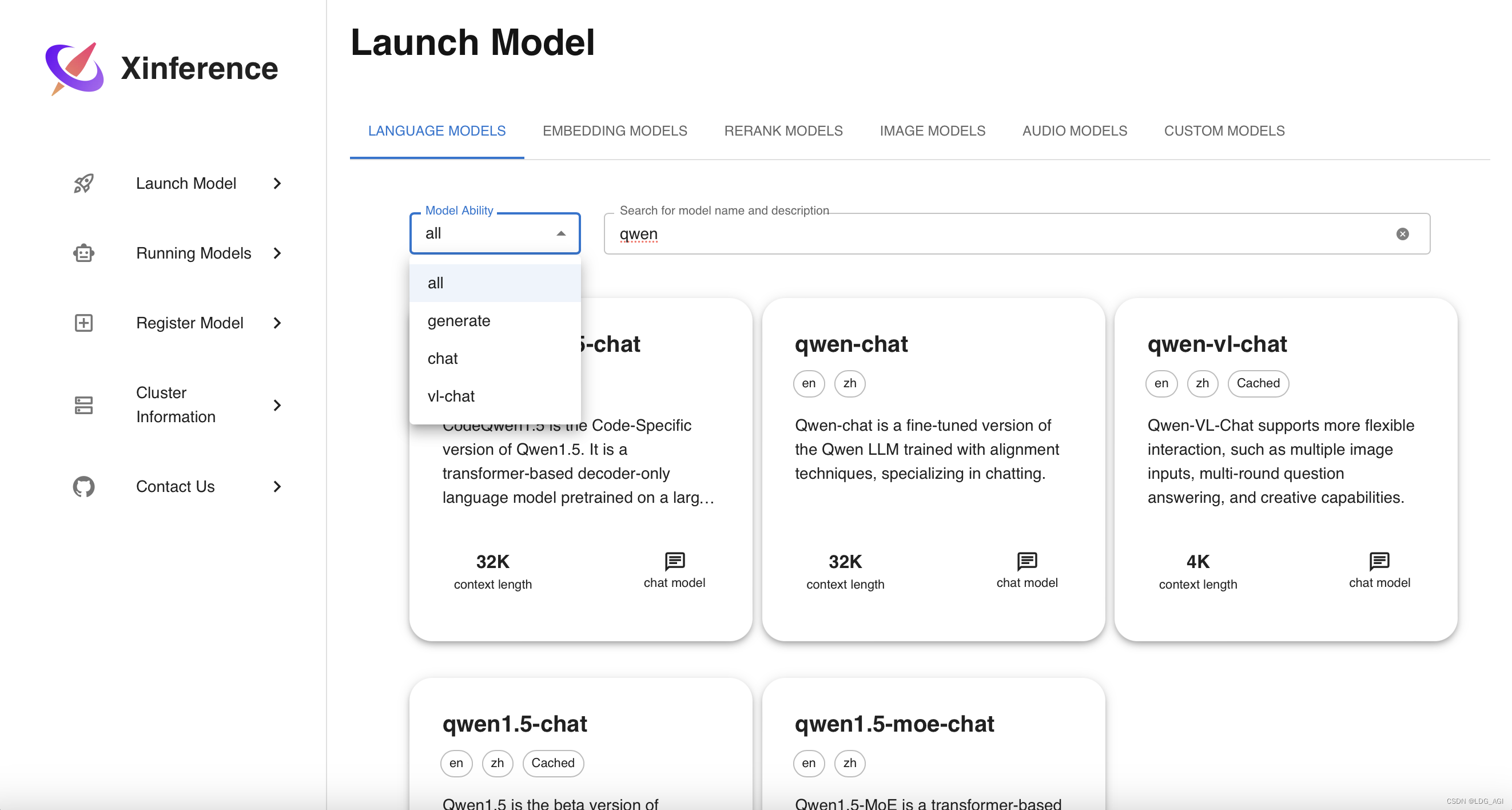
Взяв в качестве примера qwen1.5, найдите qwen1.5 и выберите версию чата:
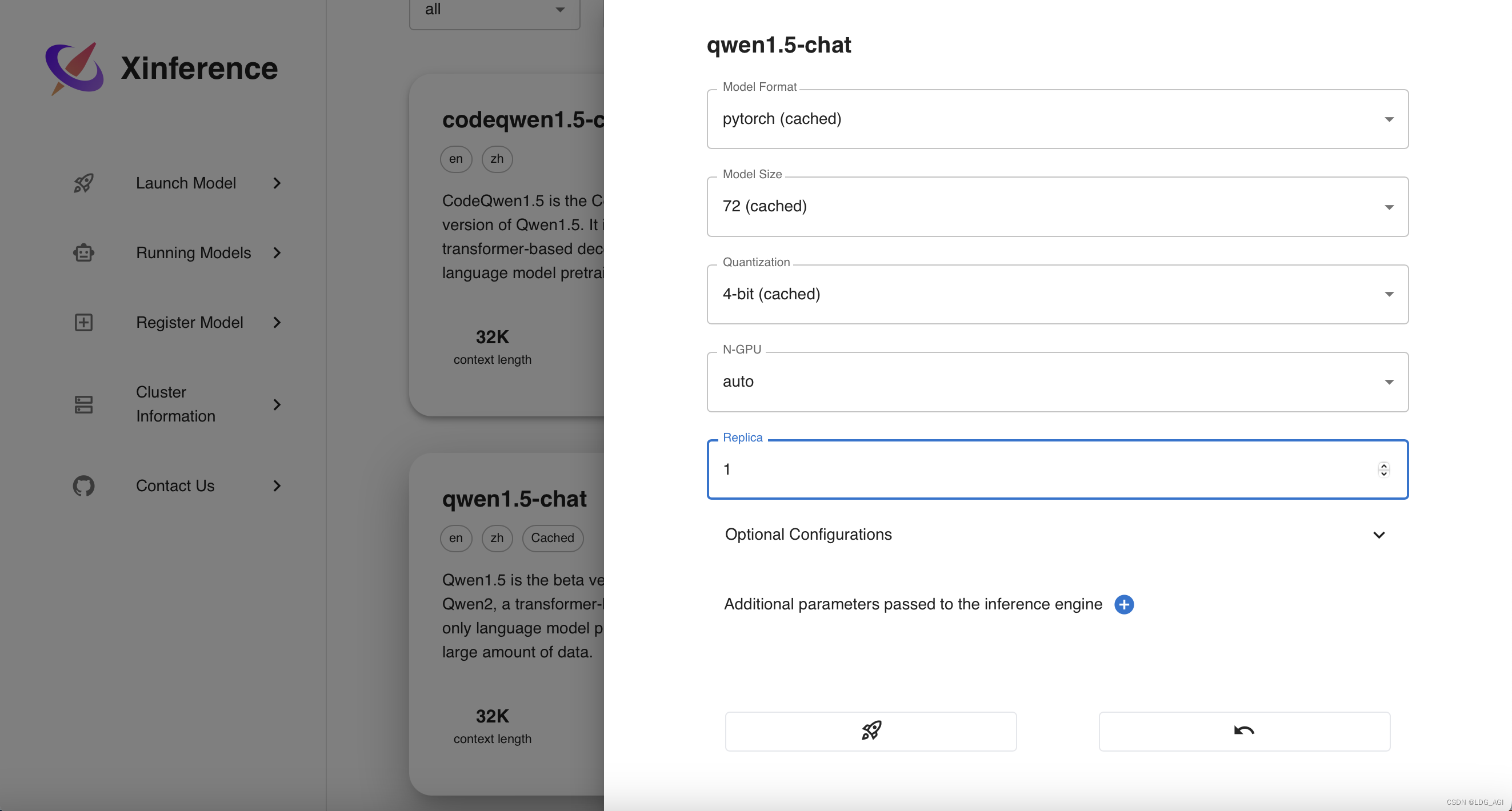
- Формат модели (формат модели): содержит pytorch.、gptq、awq、ggufv2 и т. д.
- Размер модели (Размер модели): включая полноразмерную модель 0,5B ~ 110B,
- Квантование (Модель квантования): содержит 4 бита.、8 бит、Не количественно и т.д.
- N-GPU (количество используемых графических процессоров): количество используемых графических процессоров можно выбрать автоматически или вручную.
- Реплика (количество копий): Количество предоставленных копий Служить.
Нажмите на маленькую ракету ниже, чтобы запустить (запустить) модель. Модель будет автоматически загружена и запущена в modelscope.
2.Running Models
После начала загрузки модели ее можно просмотреть в разделе «Запуск моделей». Вы можете щелкнуть окно в разделе «Действия», чтобы открыть тестовый пользовательский интерфейс.
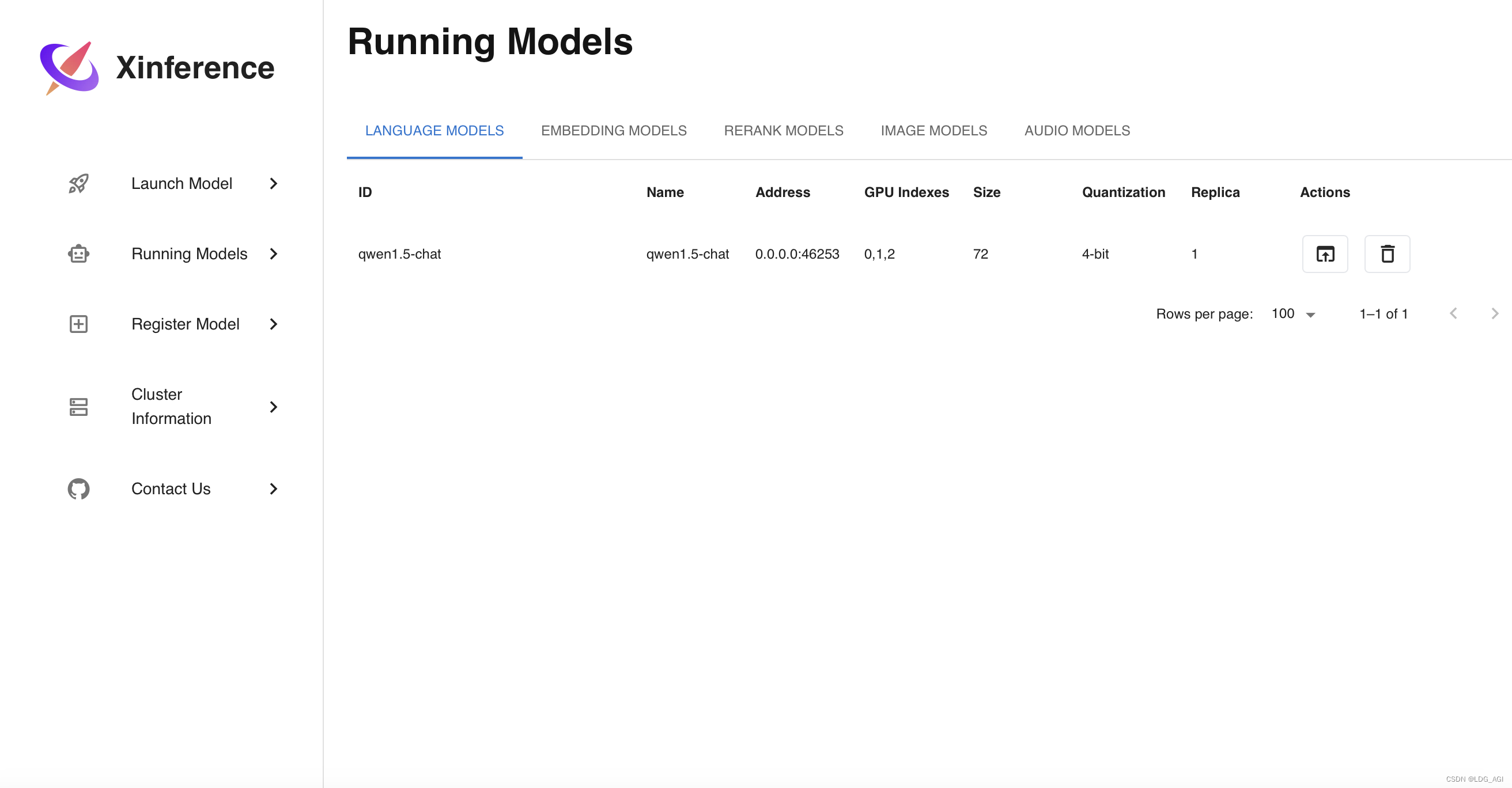
- ID: Modelid, который будет использоваться в дальнейшем при звонке
- Имя: Имя модели, которое будет использоваться позже при вызове.
- Address:Модельразвертыватьизcontainerпорт,Позже будут использоваться только адрес и порт хоста.,Позже в состоянии контейнера он не понадобится.
- Индексы графического процессора: индекс графического процессора, Xinferenceрамка автоматически разделит Модельразвертывания на несколько карт в зависимости от ресурсов графического процессора.
- Size,Квантование: размер модели и биты квантования.
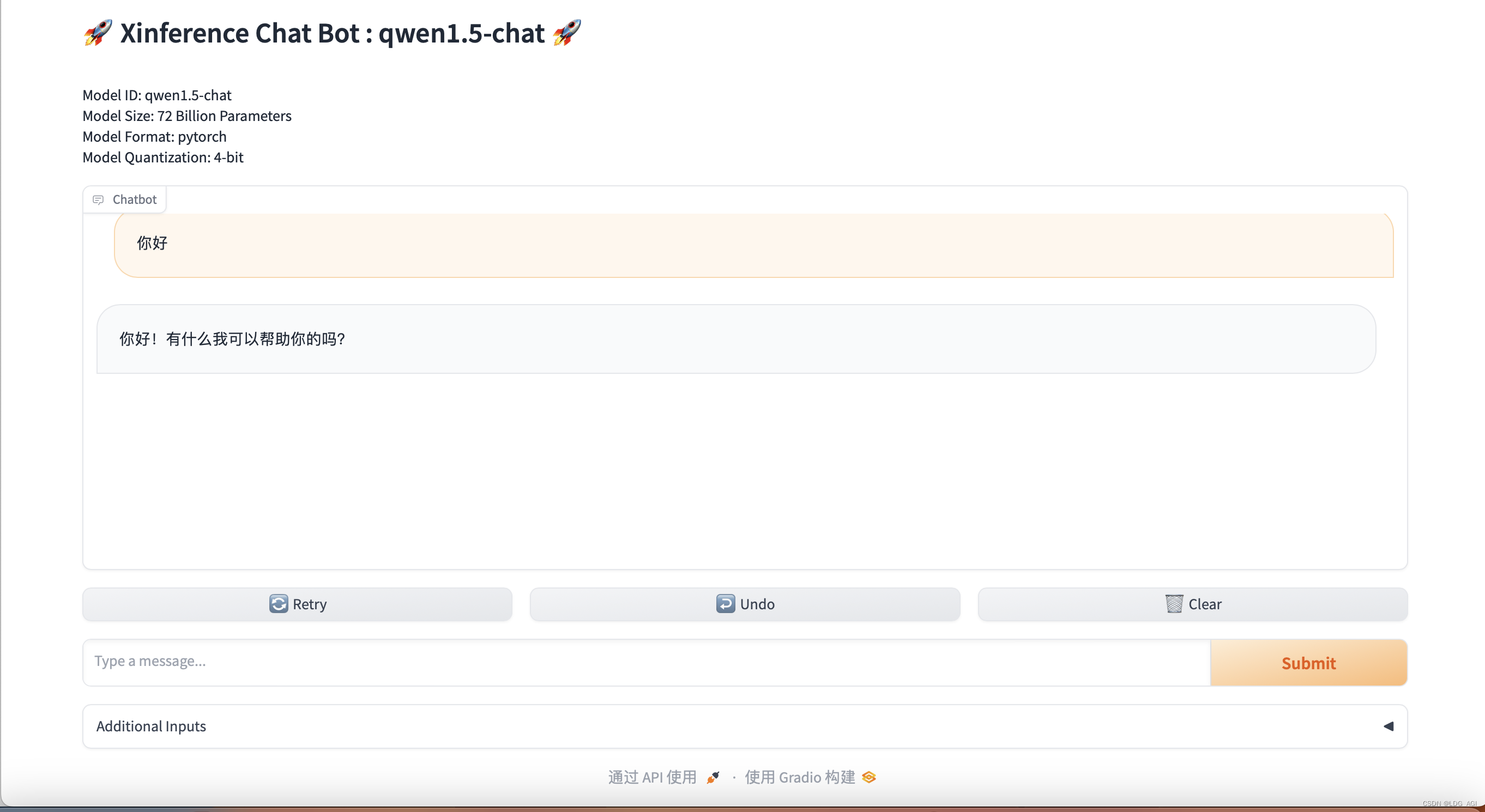
2.1 Тест qwen1.5-чата
2.2 Путь хранения модели
При запуске Docker-контейнера укажите корневой каталог контейнера и укажите путь, связанный с хостом:
- -e XINFERENCE_HOME=/workspace
- -v /yourworkspace/Xinference:/workspace
Таким образом, вы можете просмотреть загруженную модель локально на хост-компьютере без входа в контейнер.
3.Register Model
Вы также можете зарегистрировать свои собственные загруженные или доработанные модели:
Вам нужно только настроить имя модели, формат модели, длину контекста, размер модели, путь к модели и т. д.
После завершения регистрации запустите ее в Launch Model — Custom Models.
4.Cluster Information
Здесь будет отображаться количество узлов-супервизоров кластера и рабочих узлов, а также конкретное использование ЦП и графического процессора для облегчения управления.
5. Использование модели
Ссылаясь на предыдущую статью Оллама, мы можем использовать Curl или платформу погружения для вызова службы вывода, развернутой Xinference.
DIFY: вам нужно настроить только имя модели, URL-адрес сервера и UID модели. Имя модели и UID модели можно найти в списке «Работающие модели». URL-адрес сервера — http://хост:порт. Не забудьте указать http://, иначе будет сообщено об ошибке.
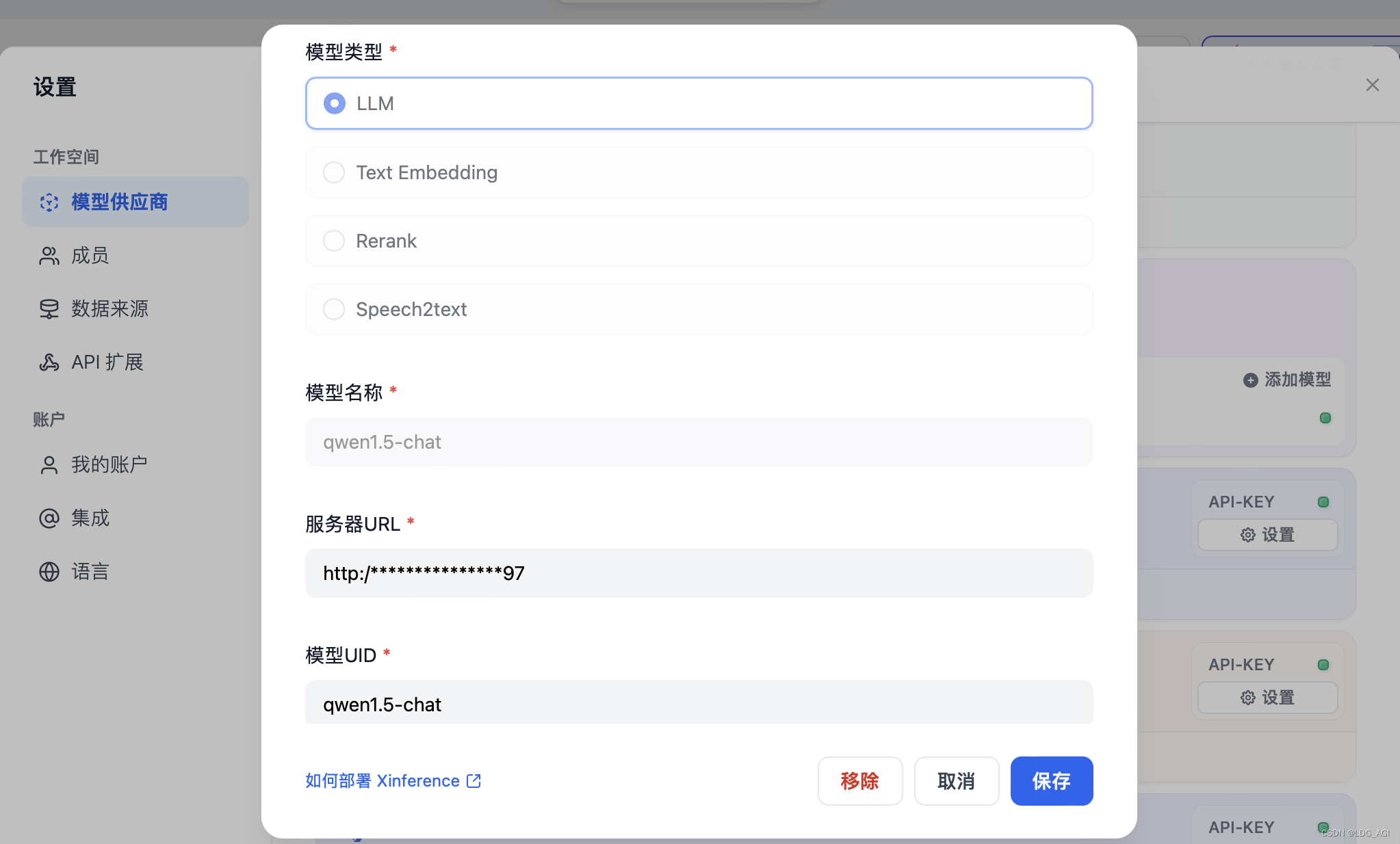
CURL:
Тот же почтовый запрос, что и у OpenAI:
curl -X 'POST' \
'http://123.123.123.123:9997/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen1.5-chat",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What is the largest animal?"
}
]
}'возвращаться:
{"id":"chatd9e11eea-0c57-11ef-b2c7-0242ac110003","object":"chat.completion","created":1715075692,"model":"qwen1.5-chat","choices":[{"index":0,"message":{"role":"assistant","content":"The largest animal on Earth is the blue whale (Balaenoptera musculus). Adult blue whales can grow up to lengths of around 98 feet (30 meters) and can weigh as much as 200 tons (180 metric tonnes). They are marine mammals found in all major oceans, primarily in the Antarctic and Sub-Antarctic waters. Their size is a result of their filter-feeding lifestyle; they feed on large quantities of small shrimp-like creatures called krill, rather than needing to hunt larger prey."},"finish_reason":"stop"}],"usage":{"prompt_tokens":25,"completion_tokens":111,"total_tokens":136}}Совместимый с OpenAI API:
Xinference предоставляет API, совместимый с OpenAI, поэтому модель, запускаемая Xinference, может напрямую заменить модель OpenAI.
from openai import OpenAI
client = OpenAI(base_url="http://123.123.123.123:9997/v1", api_key="not used actually")
response = client.chat.completions.create(
model="qwen1.5-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the largest animal?"}
]
)
print(response)6. Резюме
В этой статье кратко описывается одна строка кода для завершения локального развертывания Xinference и две строки кода для завершения распределенного развертывания Xinference, а также вызовы веб-интерфейса и интерфейса. Среди них есть много преимуществ, таких как быстрое развертывание и чрезвычайно удобный веб-интерфейс. , настраиваемая модель и API, совместимый с OpenAI. Это действительно хорошая идея.
Я искренне надеюсь поделиться со всеми крупными проектами с открытым исходным кодом Model, в которых я принимал участие, посредством ведения блога.,Из-за ограниченного личного опыта,Нет никакой гарантии, что каждая статья будет особенно подробной.,Но постарайтесь убедиться, что контент действительно использовался вами.,Чтобы не дать всем снова попасть в ловушку. Если вы хотите узнать больше о большой модели Xinference, рамка для рассуждений,Пожалуйста, обратитесь к официальной документации:Официальная документация Xinference 。



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
