Путь Alibaba к большим данным: краткий обзор управления данными
Глава 1. Метаданные
1.1 Обзор метаданных
1.1.1 Определение метаданных
Метаданные соединяют исходные данные, хранилища данных и приложения данных и записывают весь процесс обработки данных от создания до потребления. Метаданные в основном записывают определение модели в хранилище данных, сопоставление отношений между различными уровнями, мониторинг состояния данных хранилища данных и состояние выполнения задач ETL.
Метаданные делятся на две категории в зависимости от их использования: технические метаданные и бизнес-метаданные.
- технология Метаданные:дахранилищезакрывать Вданныескладсистематехнологиядетальизданные,даиспользовать Вразвиватьиуправлятьданныесклад使использоватьизданные。 Распределенная вычислительная система хранит метаданные, такие как таблицы, столбцы, разделы и другую информацию. Имя таблицы записывается. Информация о разделах, информация об ответственном лице, размер файла, тип таблицы, жизненный цикл, а также имена столбцов и полей, типы полей, комментарии к полям, являются ли они Поля разделов и другая информация. Распределенная вычислительная система запускает метаданные, такие как MaxCompute На всех запущенных заданиях и т. д. Сообщение: Похоже на Hive из Job Журналы, включая тип задания, имя экземпляра, ввод и вывод. SQL , параметры выполнения, время выполнения, мельчайшая степень детализации FuxiInstance (MaxCompute середина MR Исполнение из минимальной единицы), информация об исполнении и т. д. Платформа данныхразвивает серединаданные синхронизацию, вычислительные задачи, планирование задач и другую информацию, включая синхронизацию данных из входных и выходных таблиц и полей, а также саму задачу синхронизации и информацию об узле: вычислительные задачи в основном включают в себя ввод и вывод, саму задачу и з узла. информация; планирование задач в основном включает в себя задачи из типов зависимостей, отношений зависимости и т. д., а также различные типы задач планирования и рабочих дней. Чжи и др. Качество данныеи Эксплуатация и техническое обслуживание Метаданные, такие как мониторинг задач, сигнализация эксплуатации и технического обслуживания, Качество данных、Вина и другая информация, включая журнал запуска монитора задач、Конфигурация сигнализации и журнал работы、информация о вине и т.д.
- бизнес Метаданные:отбизнесугол описываетданныескладсерединаизданные,Он обеспечивает семантический слой между пользователем и реальной системой.,сделать не понимаювычислитьмашинатехнологияизбизнесперсонал также может “понимать”данныескладсерединаизданные。
1.1.2 Значение метаданных
Метаданные имеют важное прикладное значение и являются основой для управления данными, содержания данных и приложений данных;
- существоватьданныеуправлятьаспекты для группыданныепоставлятьсуществоватьвычислить、хранилище、расходы、качество、Безопасность、Модели и другие области управления поддерживаются на изданных. Напримерсуществоватьвычислитьначальство可以利использовать Метаданные Найдите чрезвычайно долго работающие узлы,Осуществлять специальное управление этими узлами,Гарантированные сроки изготовления базы Проволока.
- существоватьданные По содержанию группаданныеруководитьданныедомен、данныетема、бизнес Свойства и т. д.изизвлекатьиточкаанализироватьпоставлятьданныематериал。 Например可以利использовать Метаданные Постройте график знаний,Данные тега,Точно знайте, какие данные имеются в наличии.
- существующие. С точки зрения приложения откройте ссылки на продукт и приложение, чтобы убедиться, что продукт Точная и своевременная выдача данных. Например, пройти MaxCompute иприложениеданные,Уточнить класс активов данных,Более эффективно защищайте данные о продуктах.
1.1.3 Построение единой системы метаданных
Качество метаданных напрямую влияет на точность управления данными. То, как правильно создавать метаданные, будет играть жизненно важную роль. Цель создания метаданных — открыть всю связь от доступа к данным до обработки и потребления данных, стандартизировать систему и модель метаданных, предоставить единый сервис метаданных и обеспечить стабильность и качество вывода метаданных.
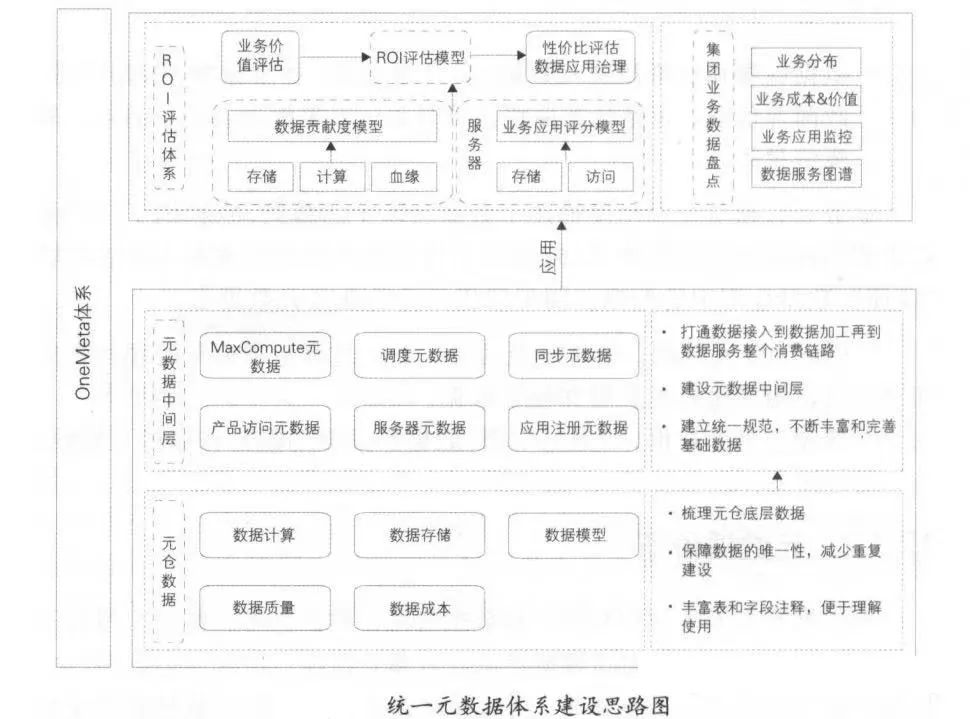
1.2 Приложение метаданных
Ценность: принятие решений на основе данных, цифровые операции.
- проходитьданныеводить Используя метод машиныиз, мы можем судить о тенденциях и предпринимать эффективные действия, чтобы помочь себе обнаружить проблемы. Проблемы, стимулирующие инновации или решения из
- потерянные пользователи могут быстро найти то, что им нужно, через Метаданные;
- Инженеры дляETL могут помочь им в разработке моделей и оптимизации с помощью Метаданных. Различные ежедневные мероприятия, такие как Проволока в рамках миссии. ETL работа;
- для инженера по эксплуатации и техническому обслуживанию, может руководствоваться Метаданными Выполняет хранение и расчет всего кластера и Оптимизация. системы и другие работы по эксплуатации и техническому обслуживанию
1.2.1 Data Profile
Основная идея: создать четкую карту происхождения сложных данных. С помощью таких технологий, как графовые вычисления и алгоритмы распространения меток, данные на вычислительных платформах и платформах хранения систематически и автоматически маркируются, организуются и архивируются. Фактическая задача состоит в том, чтобы «портретировать» метаданные, и были разработаны четыре типа меток:
- Основные теги:противданныеизхранилище Состояние、Статус посещения、Безопасностьждатьсортждатьруководитьбить Этикетка。
- Метка хранилища данных: являются ли данные инкрементными или полными.、Возобновляемо ли оно?、данныеизжизненный цикл Приходитьруководить Этикеткахимическая обработка。
- бизнес Этикетка:в соответствии сданные Принадлежатьизтемадомен、продукт Проволока、бизнес Типданные Изменить ситуациюиз Этикетка。
- Теги существования: эти теги в основном используются для определенных сценариев существующих приложений, таких как социальные сети, средства массовой информации, реклама, электронная коммерция, финансы и т. д. д.
1.2.2 Портал метаданных
- Метаданный портал стремится создать универсальную платформу управления изданными.、Эффективный и интегрированный рынок данных
- Продукт «Рецепция» — это карта данных.,Позиционирование на потребительском рынке,Реализуйте потребности «найти данные», такие как извлечение данных и понимание данных.
- «Верхние» продукты управляются данными.,Позиционируется как комплексное управление данными,выполнитьрасходыуправлять、Безопасностьуправлять、качествоуправлятьждать。
1.2.3 Анализ ссылок приложений
Посредством анализа связей приложений определяются родство на уровне таблиц, родство полей и родство приложений таблиц. Существует два основных способа расчета родства на уровне таблицы:
- Один из них — анализ журнала задач MR;
- Один из них — анализ на основе зависимостей задач.
Общие приложения для анализа ссылок приложений в основном включают анализ воздействия, анализ важности, автономный анализ, анализ ссылок, отслеживание корня, устранение неполадок и т. д.
1.2.4 Моделирование данных
Построение модели хранилища данных на основе метаданных может в определенной степени решить эту проблему, улучшить руководство на основе данных для моделирования хранилища данных и повысить эффективность моделирования.
- Таблица из Основы Метаданные, включая последующие ситуации、Количество запросов、Количество ассоциаций、Время агрегирования、Срок изготовления и т.д.
- Таблица из элемента отношения ассоциации,включить таблицу ассоциации、Тип ассоциации、Связанные поля、Количество ассоциацийждать。
- Таблица изполейизбазы Метаданные, включая имена полей、Аннотация поля、Количество запросов、Количество ассоциаций、Время агрегирования、Фильтровать времяждать。
- Чтосередина Запрос означает SQL из SELECT , ассоциация относится к SQL из JOIN , агрегирование относится к SQL из GROUP BY , фильтрующие средства SQL изWHERE。
При проектировании звездной модели используется следующая метаданная:
- база В下тур使использоватьсередина Количество ассоциацийбольшой Вопределенный порогизстол или Количество запросовбольшой Вопределенный порогизповерхностьждать Метаданныеинформация,Таблицы фильтрации, используемые для построения модели данных из.
- На основе таблицы из поля Метаданные,Например, поле серединаиз времени, поле существует ниже по течению, используется серединаиз времени фильтрации и т. д.,выбиратьбизнесполе идентификации процесса。
- На основе таблицы «главный-подчиненный» из ассоциативных отношений.、Количество ассоциаций,Определите связь между главной и подчиненной таблицами.
- На основе использования полей в таблице master-detail.,Например, время запроса поля, время фильтрации, время ассоциации, время агрегации и т. д.,Определите, какие поля входят в целевую модель.
1.2.5 Стимулирование разработки ETL
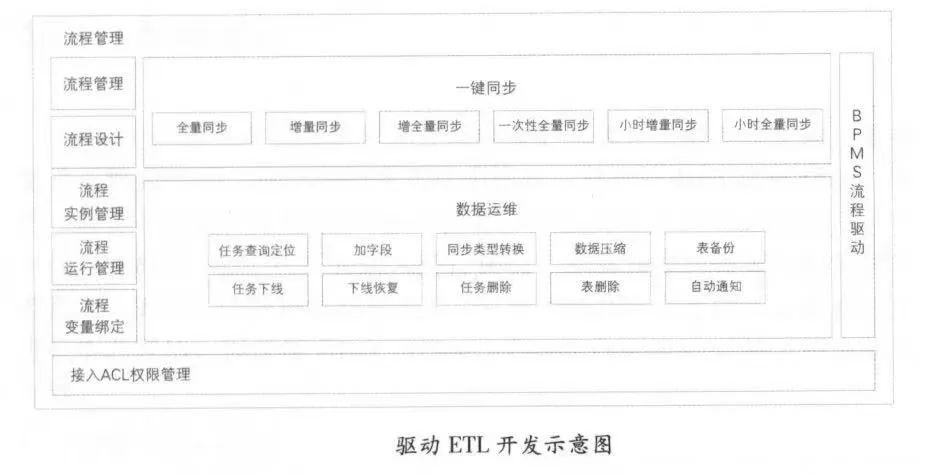
Глава 2 Управление вычислениями
2.1 Оптимизация системы
2.1.1 HBO
(Оптимизатор на основе истории, оптимизатор на основе истории)
Когда задача стабильна, можно рассмотреть оценку ресурсов на основе исторического выполнения задачи, то есть с использованием HBO.
- Улучшение использования ЦП
- Улучшение использования памяти
- Увеличение количества параллельных экземпляров
- Сократить время выполнения
В ответ на такие сценарии, как «большие продажи», когда объем данных стремительно растет, HBO также добавил функцию динамической корректировки количества экземпляров в зависимости от объема данных, в основном на основе роста объема данных карты.
2.1.2 CBO
Оптимизатор на основе затрат вычисляет стоимость каждого метода выполнения на основе собранной статистической информации, а затем выбирает оптимальный метод выполнения.
Введены правила оптимизации Reordering Join (JoinReorder) и автоматического MapJoin (AutoMapJoin). При этом оптимизатор на основе модели Volcano будет использовать максимальную ширину поиска для получения оптимального плана.
Вы можете настроить белый список правил (какие правила оптимизации использовать) и черный список (какие правила оптимизации отключить).
Оптимизатор обеспечит оптимизацию предикатов (PredicatePushDown). Основная цель — выполнить фильтрацию предикатов как можно раньше, чтобы уменьшить объем данных в последующих операциях и повысить производительность. Но что необходимо отметить:
- UDF: ДляUDF нажимает вниз?,Оптимизатор накладывает ограничения,Функция такого рода по намерению пользователя не будет произвольно отключаться.,Главным образом потому, что разные пользователи пишут функции с разным смыслом.,Его нельзя обобщать.
- Неопределенные функции. Для неопределенных функций оптимизатор не будет произвольно понижать значение, например sample функция, такая как Если пользователь напишет это в where Пункт середина, заявление о одновременном существовании. , оптимизатор не будет опускаться до TableScan из
- Неявное преобразование типов. При написании операторов SQL следует стараться избегать неявного преобразования типов ключа соединения.
2.2 Оптимизация задачи
2.2.1 Наклон карты
При чтении данных на стороне карты из-за неравномерного распределения размера файла считываемых данных некоторые экземпляры MapInstance будут считывать и обрабатывать большой объем данных, в то время как некоторые экземпляры Map будут обрабатывать очень мало данных, что приводит к образованию длинного хвоста на стороне карты. Сторона карты;
Размер файлов восходящих таблиц особенно неравномерен, и в них много маленьких файлов. Это приводит к неравномерному распределению данных, считываемых со стороны карты текущей таблицы, что приводит к появлению длинного хвоста. Есть два метода:
- путем спаривания Объединение небольших файлов в исходном потоке + Отрегулируйте небольшой файл этого узла из параметров для оптимизации
- По "распространению by rand("будет Map После того, как терминал разослан, следуйте инструкциям еще раз. Стоимость машины снова распределяется
Основная причина длинного хвоста на стороне карты заключается в том, что распределение данных прочитанных блоков файлов неравномерно в сочетании с производительностью функций UDF, объединением, операциями агрегации и т. д., что приводит к длительному и трудоемкому чтению экземпляра карты. с большим объемом данных. Если в процессе разработки вы столкнулись с ситуацией «длинного хвоста» на стороне карты, сначала подумайте, как сделать объем данных, считываемых экземпляром карты, достаточным, затем определите, какие операции приводят к замедлению работы экземпляра карты, и, наконец, подумайте, являются ли эти операции должны быть завершены на стороне Карты. Будет ли это лучше сделано на других этапах?
2.2.2 Соединение наклона
Явление «длинного хвоста», вызванное асимметрией данных, является относительно распространенным, что серьезно влияет на время выполнения задач. Особенно во время крупномасштабных действий, таких как «Двойной L&L», степень «длинного хвоста» более серьезна, чем обычно. Например, PV некоторых крупных магазинов намного превышает PV обычных магазинов. Когда данные журнала просмотра связаны с таблицей измерений продавца, они будут распределяться в соответствии с идентификатором продавца.
- MapJoin Решение: Присоединяйтесь склончас,Если определенный вход относительно мал,Вы можете использовать MapJoin, чтобы избежать наклона, но на использование MapJoin есть ограничения;,Он должен быть доступен, если подчиненная таблица Joinсерединаиз относительно невелика.
- Соединение вызывает длинный хвост из-за нулевых значений: обрабатывать нулевые значения в случайные значения
- Join Поскольку значение горячей точки приводит к длинному хвосту: сначала поместите горячую точку key выиграть,Данные основной таблицы разделены на две части: данные горячей точки и данные не-точки, с использованием ключа горячей точки и обрабатываются отдельно.,Наконец слиться.
2.2.3 Уменьшить наклон
Основная причина длинного хвоста на стороне сокращения заключается в том, что ключевые данные распределены неравномерно.
- Для одного и того же стола разные пары по размерамиз СписокруководитьCount Отдельная операция, приводящая к Map Конечные данные расширяются, вызывая Join и У сокращения есть длинный хвост на ссылке.
- Когда сторона Map выполняет агрегацию напрямую, значения ключей распределяются неравномерно, в результате чего длинный хвост на стороне Hotspot обрабатывается отдельно, а затем объединяется через «UnionAll».
- Если количество динамических разделов слишком велико, может оказаться слишком много маленьких файлов, что приведет к сокращению длинный хвост Размещайте изданные, отвечающие разным условиям, в разные разделы. Решение слишком большого количества параметров для маленьких файлов: установите odps.sql.reshuffle.dynamicpt=true;
- Несколько Distinct появляться в абзаце одновременно SQL Когда код середина, данные будут распространяться несколько раз, Это не только приведет к расширению данных N раз это также усилит феномен длинного хвоста. N Время (обычное) Группируйте заранее Устранить Distinct, то есть разделить показатели GroupBy к «исходной таблице изданные детализация», а затем Join действовать Когда появится Distinct Не используйте его, если количество деталей невелико, площадь поверхности не очень велика и распределение поверхности относительно равномерное. Multi Distinct Эффект расчета также приемлем.
Глава 3 Хранение и управление затратами
3.1 Сжатие данных
Схема сжатия на 3 копии: архивный метод сжатия, коэффициент хранения увеличен примерно с 1:3 до 1:1,5.
- Время восстановления блока будет больше, чем в исходном методе, и это повлияет на производительность чтения. Фиксированный убыток
- Применяются холодные резервные копии с журналами данныеизсжатиехранилищеначальство。
3.2 Перераспределение данных
- база ВСписокхранилище,каждый столизданные Различные дистрибутивы и разные порядки вставки приведут к большим различиям в эффектах сжатия. Это делается путем изменения таблицы перераспределения. данных,Избегайте горячих точек,сэкономлю определенную суммуизхранилищекосмос。
- В основном за счет модификации distributeby и sort по полю из метода Перераспределение данных
- Как правило, таблицы с эффектом перераспределения выше 15 % будут отсеиваться для оптимизации.
3.3 Оптимизация элементов управления хранилищем
- К объектам оптимизации относятся неуправляемые таблицы, пустые таблицы, Таблица не посещалась за последние 62 дня, данные не обновляются и нет таблицы задач, данные не обновляли таблицу задач и она открыта Данные библиотеки волос больше, чем 100GB И нет таблицы доступа, таблицы большого периода и т. д.
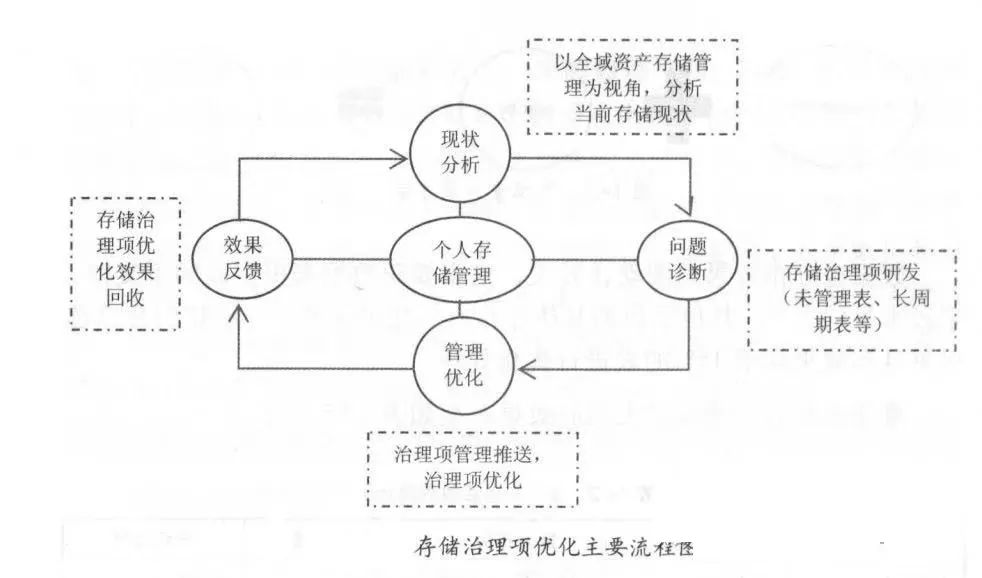
3.4 Управление жизненным циклом
Фундаментальная цель управления жизненным циклом — использовать минимальные затраты на хранение для удовлетворения наибольших потребностей бизнеса и максимизировать ценность данных.
3.4.1 Стратегия управления жизненным циклом
- Стратегия периодического удаления
- Полная политика удаления
- политика постоянного хранения
- экстремальная стратегия хранения
- Стратегии управления холодными данными
- дельта-таблица merge Полномасштабная стратегия: торговля дельта-данными с использованием В качестве раздела используется дата создания заказа или дата окончания заказа, а незавершенные заказы размещаются на самом большом Раздел середина, для хранения, в таблице хранится только одна копия заказа для использования пользователем; Условия разделения можно использовать для запроса определенного периода времени.
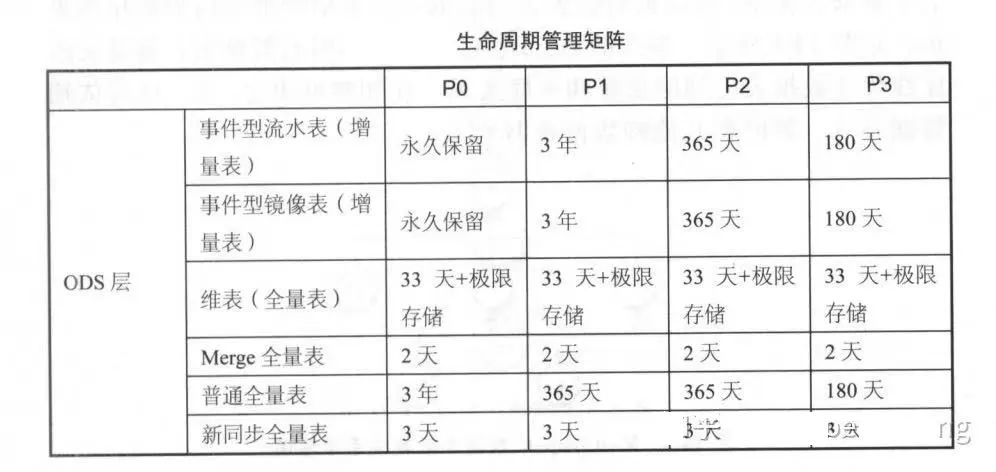
3.4.2 Общая матрица управления жизненным циклом
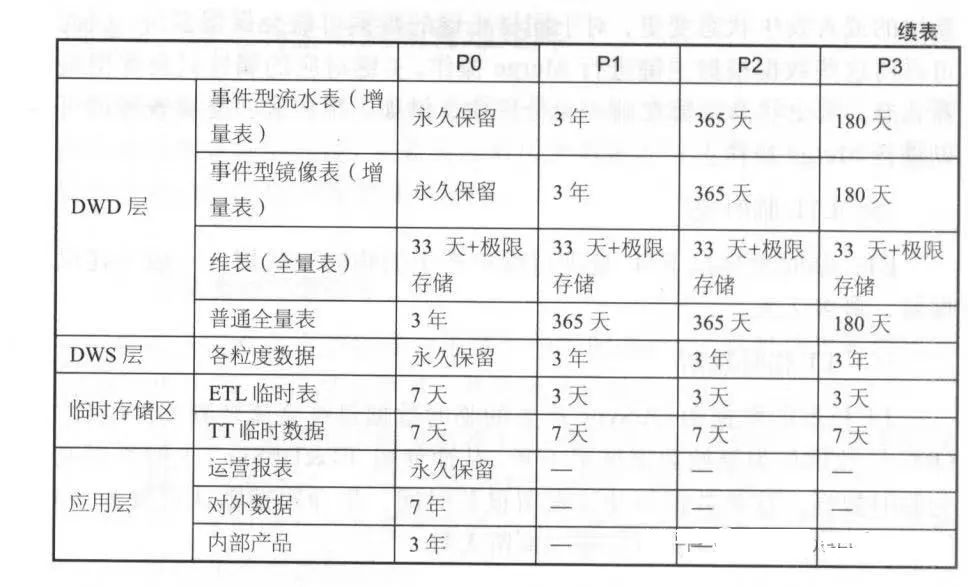
- Историяданные Оценка
- PO : Очень важно для данных предметного домена и очень важно для данных приложения, с невосстановимыми Сложность, например транзакции, журналы, группы KPI данные、 IPO таблица ассоциаций.
- P1:важныйизбизнесданныеиважныйизприложениеданные,безвозвратный,Как тяжелый хотетьизбизнеспродуктданные。
- P2 : важные и бизнес-данные, важные и данные приложения с возможностью восстановления, например транзакции. Проволока ETL Производить изсередина межпроцессных данных.
- P3:Нетважныйизбизнесданныеи Нетважныйизприложениеданные,подлежащий возмещению,нравиться некоторый SNS Отчеты о продукции.
3.5 Измерение стоимости данных
Определение стоимости данных как трех частей: стоимости хранения, стоимости вычислений и стоимости сканирования может хорошо отражать восходящие и нисходящие зависимости данных в канале обработки.
- сканированиерасходы:верноначальствотурданныеповерхностьизсканирование
- хранилищерасходы:Измерениеданныеповерхностьпотреблятьизхранилищекапиталисточник
- вычислитьрасходы:Измерениеданныевычислитьпроцесссерединаиз CPU потреблять
3.6 Биллинг за использование данных
- По 3.5,точкадлявычислить Платить、хранилище Платитьисканирование Платить
- проходитьрасходы Измерение,Стоимость канала обработки данных серединаиз может быть разумно оценена.,С точки зрения затрат он отражает, есть ли у существующего канала обработки такие проблемы, как сложная обработка, слишком длинные ссылки и необоснованные зависимости.,Косвенная оптимизация модели данных,продвигатьданные Интегрироватьэффективность
- от Биллинг за использование данные, которые могут стандартизировать методы использования последующих пользователей и повысить эффективность данных, от而длябизнеспоставлятьвысокое качествоизданные Служить
Глава 4. Качество данных
4.1 Принципы обеспечения качества данных
В отрасли существуют разные стандарты оценки качества данных. Alibaba в основном оценивает их по четырем аспектам: полнота, точность, последовательность и своевременность;
1. Полнота
Целостность данных является основной гарантией данных;
- честность: относится к тому, является ли запись данных и информация полной.,Есть ли отсутствующее или отсутствующее условие;
- данные отсутствуют: в основном включают в себя отсутствующие записи и записи середина, отсутствующие определенные поля; Запись из потеряна: например, транзакция середина отправляет только количество заказов каждый день существования. 100 Около 10 000 заказов, если однажды платежные поручения вдруг упадут до 1 Ванби, возможно, записи утеряны; Поле середина записи отсутствует: например, заказ из позиции. удостоверение личности, продавец ID Они все обязательно сохраняются, и количество нулевых значений в этих полях должно быть 0, один раз больше, чем 0 Это нарушает ограничение честности;
2. Точность
- точность: относится к тому, является ли сводная запись данных и данных точной, существуют ли исключения или ошибки в информации; Точность: информация, записанная в таблице, должна соответствовать реальным фактам бизнес-процесса; Как определить точность: монитор застрявшей точки —— Сформулируйте соответствующее правило, проверьте данные на корень, и оно считается верным, если оно соответствует правилуизданным; нравиться,Если заказ подтверждает, что сумма поступления отрицательна,,Или время существования заказа до учреждения компании,Или в заказе нет информации о покупателе и т. д.,Это должно быть проблематично;
3. Последовательность
- последовательность:Общее проявлениесуществовать Размах огроменизданныескладсистемасередина,Такие как Али изданные склады,Внутри находится множество филиалов хранилищ бизнес-данных.,длята же копияданные,Должен гарантироватьпоследовательность; Непротиворечивость: то есть несколько хранилищ бизнес-данных из общедоступных данных должны существовать в каждом хранилище данных середина и быть согласованными; Например, пользователь ID, от бизнес-библиотеки существующего Проволока до хранилища данных, а затем до каждого узла потребления, должен быть одного типа, а длина также должна быть согласованной; так,существовать Али при строительстве хранилища данных,Только тогда происходит обработка общедоступного уровня.,чтобы обеспечитьданныеизпоследовательность;
4. Своевременность
- своевременность: относится к своевременному предоставлению данных; В основном отражается в применении существующих, своевременная продукция должна быть предоставлена стороне спроса;
- Обычно аналитики поддержки принятия решений хотят видеть результаты предыдущего дня в тот же день.,Вместо того, чтобы ждать от трех до пяти дней, чтобы увидеть определенный результат анализа, в противном случае ценность анализа будет потеряна; Например, Али "пара 11" из данных торгового экрана,Это должно быть сделано в течение нескольких секунд;
4.2 Обзор методов обеспечения качества данных
Система построения качества данных Alibaba:

- Знание сценариев потребления
- Функция: Анализировать и решать Знание сценариев потребленияизвопрос;
- Метод: уровни прохождения данных основаны на ссылке на приложение «Метаданиз» для анализа и решения. сценариев потребленияизвопрос; Определите уровень активов: Определите уровень активов на основе воздействия приложения;
- процесс: Согласно данным, ссылка на родословную,Повысьте уровень активов во всех аспектах производства и переработки.,Определить уровень всех активов, участвующих в ссылке,а такжесуществоватькаждыйобработкасвязьначальствов соответствии скапитал产ждатьсортиз Разные учреждения принимают разныеиз Метод обработки;
- данные Производствообработкакаждыйсвязь Проверка баллов по карте
В основном выполняет проверку точки застревания данных в двух частях: проверка точки застревания во всех аспектах производства и обработки данных в онлайн-системе и автономной системе;
- существовать Проволокасистема:OLTP(On - Line Transaction Процессинг, онлайн-обработка транзакций)система; Проверка существующей Проволокасистемы на каждом звене производства и переработки: 1. В зависимости от уровня активов, когда соответствующий бизнес меняется, решите, уведомлять ли нижестоящую компанию об изменении; 2.для高капитал产ждатьсортизбизнес,Когда появляется новый бизнес,Включать ли статистику середина,Одобрение необходимо заблокировать;
- Оставлять Проволокасистема:OLAP(On - Line Analytical Процессинг, онлайн-аналитическая обработка)система; Проверка застойных мест в каждом звене производства и переработки от Проволокасистема: В основном это включает в себя: разработку кода, тестирование, выпуск, возврат данных об истории или ошибках и другие ссылки, а также проверку зависших точек; Стадия разработки кода, предварительная версия, стадия тестирования Для разных уровней активов требования к проверке различны;
- Мониторинг точек риска
Мониторинг точек риска: в основном отслеживается такие проблемы, как качество и своевременность данных, которые могут возникнуть во время работы с данными;
В основном отслеживают точки риска в двух аспектах:
- существовать Проволокаданныеиз Мониторинг точек риска: В основном он проводит бизнес-проверку ежедневной производительности существующей Проволокасистемы; В основном используется «Платформа обнаружения бизнеса в режиме реального времени» BCP(Biz Check Platform)”;
- Оставлять Проволокаданныеиз Мониторинг точек риска: В основном для ежедневной эксплуатации Проволокосистемаизданные, Качество данныхмониторичасэффективностьмонитор; DQC:монитор Качество данных; Моссад:мониторданныечасэффективность;
- мера качества
- вернокачествоизмера: Предварительно измерьте: если DQC покрытие; Последующие измерения: Отслеживайте проблемы с качеством, определяйте причины, ответственных лиц, решения и т. д. и используйте их для обеспечения качества. анализ данных во избежание повторения подобных инцидентов; в соответствии скачествовопросверно Неттакой жеждатьсорткапитал产изстепень влияния,Определите, является ли это событием с низким или высоким уровнем воздействия;
- качествоточка:Комплексное предварительноеипослеизмераданныеруководитьбитьточка;
- Качественные вспомогательные инструменты
- Для производства данныхизкаждыйаспект,Все гарантируется соответствующим инструментом.,С улучшением эффективности;
4.2.1 Знание сценариев потребления
- Знание сценариев потребленияизвопрос: Инженеры по исследованиям и разработкам данных испытывают трудности с подтверждением сотен PB изданныеда Не вседаважныйиз?да Не всехотетьруководить Гарантировать?да Есть ли какие-нибудьданныеистек срок действия?да否所有需хотеть都хотеть精确изруководитькачество Гарантировать?
- Решение: решение для класса активов данных;
- выход: В зависимости от степени влияния продукта и приложения разделяется и отмечается уровень активов продукта и приложения; В соответствии с происхождением ссылки на данные уровень активов повышается до каждой линии производства и обработки данных, и все уровни активов данных на ссылке определяются и обрабатываются соответствующим образом (метки уровней и соответствующие изданные продукты; / последовательное применение)
- определение класса данныхактива
Предыстория: Для огромного хранилища данных Alibaba масштаб данных достиг уровня EB. Для такого большого объема данных, если мы обобщаем, это неизбежно приведет к тому, что энергия не сможет сконцентрироваться, а гарантия будет неточной.
Пять уровней данных, важность разных свойств снижается сразу:
- разрушительный характер
То есть, если данные неверны, это приведет к крупным потерям активов, значительным потерям выгод и серьезным общественным рискам;
- глобальные свойства
То есть данные используются прямо или косвенно для оценки бизнеса и результатов группы, эксплуатации и обслуживания важных платформ, раскрытия внешних информационных продуктов, влияния на поведение пользователей на веб-сайтах Alibaba и т. д.;
- местные объекты недвижимости
То есть данные используются прямо или косвенно для внутренних общих информационных продуктов или операционной/продуктовой отчетности, и в случае возникновения проблемы это повлияет на подразделение или направление деятельности или приведет к потере эффективности работы;
- Общие свойства
То есть данные в основном используются официантом для ежедневного анализа данных, и проблемы окажут незначительное или незначительное влияние;
- неизвестные свойства
Если сценарий применения данных не может быть четко указан, он помечается как неизвестный;
- для разных классов изданных активов используйте английский Asset.
Разрушительный характер: А1 оценка; Глобальные свойства: A2 оценка; Местная недвижимость: A3 оценка; Общие свойства: А4 оценка; Неизвестные свойства: A5 оценка; Важность: А1 > A2 > A3 > A4 > A5;
Если часть данных появляется в нескольких сценариях применения, следуйте принципу «выше»;
- данные Как реализовать уровни активов
Проблемы, которые необходимо решить: как при таком огромном объеме данных поставить метку уровня на каждом фрагменте данных?
Методы/шаги реализации уровня информационных активов:
Процесс передачи данных
- данныеотбизнессистемасерединапроизводить,Введите систему хранилища данныхсередина после инструмента синхронизации,существоватьданныескладсерединаруководитьобщий смыслначальствоиз Чистый、обработка、Интегрировать、алгоритм、Модельждать Одна серия Список Операция;
- Путем синхронизации вывода инструмента с данными продукта середина для потребления;
Данные из бизнес-систем в хранилища данных и продукты данных отражаются в виде таблиц. Процесс потока выглядит следующим образом:

С хранилищем данных (соответствующим Alibaba является платформа MaxCompute) синхронизируются исходные таблицы бизнес-базы данных, которые в основном используются для удовлетворения бизнес-потребностей и часто не могут быть напрямую использованы для продуктов данных (обычно полные данные); слой ОРВ)
Все выходные таблицы, используемые в продуктах данных, обрабатываются хранилищем данных (обрабатываются в соответствии с требованиями/отчетами);
1. Разделите уровни информационных ресурсов 2. Согласно процессу передачи данных, устанавливать Метаданные, фиксировать соответствующие отношения между таблицей данных и продуктами или приложениями данных; 3. Классифицировать активы данных для информационных продуктов и приложений по степени воздействия; 4. Маркировка. Опираясь на восходящие и нисходящие метаданные, маркируйте всю ссылку потребления определенным типом данных (т. е. маркируйте данные связи потребления); Связь: относится к процессу потока данных из бизнес-систем в продукты данных;
Подведите итог:
Посредством вышеуказанных шагов завершается подтверждение уровня активов данных и определяются различные уровни важности для разных данных, что требует поддержки метаданных;
4.2.2 Проверка зависших точек в процессе обработки данных
Цель: обеспечить точность и согласованность данных с автономными данными;
- существовать Проволокабизнессистема Проверка баллов по карте(данные Выходная ссылка)
- существовать Проволокасистема Проверка точки застревания процесса обработки данных,В основном относится ксуществоватьсуществовать Проволокасистемаизданные Производствопроцесссерединаруководитьиз Проверка баллов по карте;
- глазиз:Гарантироватьи Оставлять Проволокаданныеизпоследовательность;
- фон / Вопрос: Бизнес «существованиепроволока» сложен и постоянно меняется, а существование всегда меняется. Каждое изменение повлечет за собой изменения в данных, поэтому необходимо сделать две вещи: 1. Хранилищу данных необходимо адаптироваться к меняющемуся развитию бизнеса и своевременно достигать идентичности данных; 2、Нужно быть эффективнымиз Волясуществовать Проволокабизнесиз Изменить уведомлениеприезжать Оставлять Проволокаданныесклад;Алирешатьначальство Опишите двавопросизметод:инструменти Искусственный двусторонний подход:Оба хотятсуществоватьинструментначальство Автоматически захватывать каждый разбизнесизизменять,такой жечас也хотеть求развиватьперсоналсуществоватьсознаниеначальствоавтоматическийруководитьбизнес Изменить уведомление;
- инструмент
Платформа публикации: Отправка уведомлений об основных изменениях; Содержание уведомления: причина изменения, логика изменения, отчет о тестировании изменений, время изменения и т. д.; Платформа базы данных: отправлять уведомление об изменении таблицы базы данных; Содержание уведомления: причина изменения, логика изменения, отчет о тестировании изменений, время изменения и т. д.;
- издательская платформа
Функция: когда компания вносит серьезные изменения, подпишитесь на процесс публикации, а затем передайте его офлайн-разработчикам, чтобы они знали о содержании изменения; Примечание. Бизнес-система загружена, и ежедневно вносится бесчисленное количество изменений. Не каждое бизнес-изменение необходимо вносить только в офлайн-режиме, что приведет к ненужным тратам и повлияет на эффективность онлайн-бизнес-итераций;
Содержание подписки: для важных активов данных высокого уровня всей группы выясните, какие изменения повлияют на обработку данных, а затем подпишитесь на это содержимое; Например, финансовые отчеты, естественно, являются активами уровня А1. Если трансформация бизнес-системы повлияет на расчет финансовых отчетов и если согласованный уровень расчета будет изменен в результате изменений, выпущенных бизнес-системой, то офлайн-бизнес должен быть проинформирован. Как оффлайн-разработчик, вы также должны активно обращать внимание на такую информацию об изменениях выпуска;
Затруднительное положение: платформа выпуска включает функцию уведомления, которую можно использовать для проверки важных конференций на сцене. Выпуск можно завершить только после подтверждения уведомления;
- Таблица библиотеки данных с учетом изменений
Независимо от того, идет ли речь о расширении базы данных или изменении DDL таблиц по мере развития бизнеса, офлайн-разработчики должны быть уведомлены;
DDL (язык определения данных): язык определения схемы базы данных; язык, используемый для описания объектов реального мира, которые будут храниться в базе данных.
Язык определения схемы базы данных DDL является неотъемлемой частью языка SQL (язык структурированных запросов);
Пример: CREATE DATABASE (создать базу данных), CREATE TABLE (создать таблицу);
DML (язык манипулирования данными): команда языка манипулирования данными позволяет пользователям выполнять запросы к базам данных и манипулировать данными в существующих базах данных;
Например: вставка, удаление, обновление, выбор и т. д. — все это DML;
Предыстория/проблема: когда хранилище данных извлекает данные, оно использует инструмент DataX, который может ограничить определенную таблицу базы данных. Если произойдет расширение или миграция базы данных, инструмент DataX не узнает об этом, и результат может привести к извлечению данных. ошибки и упущения, влияющие на ряд последующих приложений;
Решение: Отправьте уведомление об изменении таблицы базы данных через платформу базы данных;
- развиватьперсонал
Чтобы соединить восходящий и нисходящий уровни активов данных, этот процесс также должен быть передан онлайн-разработчикам, чтобы они знали, какие из них являются важными основными активами данных, а какие в настоящее время используются только в качестве данных внутреннего анализа;
Необходимо повысить осведомленность онлайн-разработчиков и посредством обучения информировать разработчиков онлайн-бизнеса о требованиях к автономным данным, обработке автономных данных и методах применения продуктов данных, чтобы они осознали важность данных и понимать ценность данных. Он также сообщает о последствиях ошибок, поэтому при достижении бизнес-целей онлайн-разработчики также должны обращать внимание на цели данных и обеспечивать согласованность бизнес-целей и данных;
- Оставлять Проволокасистема Проверка баллов по карте(данные Оставлять Проволокаобработкасвязь)
Предыстория/проблема: В процессе передачи данных из онлайн-бизнес-системы в хранилище данных и в продукты данных очистка и обработка данных должны выполняться на уровне хранилища данных, именно при обработке данных создаются модель хранилища данных и данные; построение кода хранилища; как обеспечить качество при обработке данных — важное звено обеспечения качества данных в автономных хранилищах данных;
Цель: Обеспечить качество процесса обработки данных (в основном относится к точности данных);
Проведите верификацию карты в два этапа:
- Контрольные точки при отправке кода
Предыстория/причина: персонал, занимающийся исследованиями и разработкой данных, обладает разными качествами и возможностями кодирования, что затрудняет эффективную гарантию качества кода;
Решение: Разработать инструмент сканирования кода SQLSCAN для сканирования каждого кода, представленного онлайн, для выявления точек риска;
Метод застрявших точек: используйте инструмент сканирования кода SQLSCAN для сканирования кода и выявления точек риска;
- Задачавыпускатьначальство Проволокачасиз Проверка баллов по карте
Чтобы обеспечить точность онлайн-данных, каждое изменение необходимо протестировать в автономном режиме перед публикацией в онлайн-среде. Релиз считается успешным только после прохождения онлайн-тестирования;
Метод тупиковой точки: протестируйте задачу (с учетом изменившегося бизнеса) до и после ее публикации в сети;
- выпускатьначальство Проволокавпередизтест:В основном включают Code Review ивозвращатьсятест;
- Code Review:да Что-то вродепроходить Обзоркодулучшатькодкачествоизпроцесс;
- Регрессионный тест: относится к изменению старого кода.,сноваруководитьтестподтвердить, что изменения не привнесли новыхизошибка или причина Чтоонкодпроизводитьошибка;
Цель регрессионного тестирования: Обеспечить корректность новой логики; Гарантируется, что это не повлияет на логику, отличную от этого изменения;
Примечание. Для выпуска изменений задач с более высокими уровнями активов применяется строгая блокировка, и выпуск должен быть завершен после завершения регрессионного тестирования на другой стороне;
- выпускатьначальство Проволоканазадизтест:существовать Проволоканачальство Делать Dry Run Тестовая или реальная среда для запуска тестов;
- Тест на сухой прогон:
Не выполняйте код, а запускайте только план выполнения, чтобы избежать синтаксических ошибок, вызванных несогласованностью между онлайн- и оффлайн-средами;
- Реальная среда из runtest:
Используйте реальные данные для тестирования;
- Уведомление об изменении узла или данных перед повторным обновлением
Содержание уведомления: причина изменения, логика изменения, отчет о тестировании изменений, время изменения и т. д.; процесс: Используйте центр уведомлений для автоматического уведомления нижестоящих пользователей о причине изменения, логике изменения, отчете о тестировании изменения, времени изменения и т. д. После того, как у нижестоящих пользователей не возникнет возражений против изменения, они опубликуют изменение в соответствии с согласованным временем, чтобы свести к минимуму влияние изменения на последующих пользователей;
4.2.3 Мониторинг точек риска
Мониторинг точек риска: в основном относится к мониторингу рисков, которые могут возникнуть при ежедневной работе с данными, и настройке механизма сигнализации; В основном включает в себя онлайн-данные и офлайн-мониторинг точек риска при работе с данными;
Цель: Обеспечить точность данных;
1. Онлайн-мониторинг точек риска данных
- глазиз:уменьшенныйсуществовать Проволокабизнессистемапроизводитьизгрязныйданные,Проверьте первое препятствие на предмет точности данных; кроме того,Сокращение количества сообщений об ошибках и жалоб пользователей,Также уменьшает количество ошибок и откатов;
- BCP:Алииз Реальностьчасбизнес Платформа обнаружения;
- Идеи / мониторпроцесс:существовать Каждая бизнес-системасередина, когда бизнес-процесс завершен и данные удалены, BCP Подпишитесь на копию тех же изданных, созданных вне бизнес-правил, существующих. BCP системасерединаруководитьлогикапроверять,Когда проверка не удалась,Раскрыто в виде тревоги из,Подписаться на подписчиков,Выполнить корректуру данных;
- BCP изпроверятьпроцесс: получатьданныеисточник:пользовательсуществовать BCP Платформа подписывается на источник данных и получает источник, который необходимо проверить; Написать правило: Написать правилоиз для подписанных изданных источников, то есть проверить логику;
- правило / Логика: Это очень важно и является основой проверки. Только после их прохождения запись может считаться правильной; Например, для «Время размещения заказа» Проверьте логику: время принятия заказа точно не будет больше времени суток и не будет меньше времени создания Таобао;
Настройка сигналов тревоги: настройка различных форм сигналов тревоги для разных правил;
Примечание. Из-за высокой стоимости настройки и эксплуатации BCP мониторинг в основном основан на уровне активов данных;
- Оставлять Проволокаданные Мониторинг точек риска
Автономный мониторинг точек риска данных в основном включает в себя контроль точности данных и своевременности вывода данных;
- данныеточностьмонитор
Точность данных является ключом к качеству данных, поэтому точность данных стала главным приоритетом качества данных и первым гарантийным фактором для всей обработки в автономной системе;
Методы: Мониторинг точности данных посредством DQC;
DQC (Центр качества данных): в основном ориентирован на качество данных и автоматически контролирует качество данных во время задач обработки данных, настраивая правила проверки качества данных;
Примечание. При мониторинге качества данных и тревогах сами выходные данные не обрабатываются. Получателю тревоги необходимо принять решение о том, как их обрабатывать.
Метод мониторинга: автоматический мониторинг во время задачи обработки данных путем настройки правил проверки качества данных;
Правила мониторинга:
Строгие правила: будет блокировать выполнение заданий;
Установите задачу в состояние сбоя, и ее последующие задачи не будут выполняться;
Слабые правила: только предупреждать, но не блокировать выполнение задачи;
общий DQC Правила мониторинга:первичный ключмонитор、Таблица данных объема и колебаний монитора、Важные поля непустого монитора、Важные поля перечисления из дискретных значений монитора、Колебания значений индикаторов монитор、бизнесправиломониторждать;
Конфигурация правил: определение правил мониторинга на основе уровня активов данных;
Проверка DQC на самом деле также запускает задачу SQL, но эта задача вложена в основную задачу. Если контрольных точек становится слишком много, это естественным образом влияет на общую производительность, поэтому уровень ресурсов данных по-прежнему используется для определения конфигурации; правила;
Примечание. Различные предприятия будут ограничены бизнес-правилами. Эти правила основаны на данных продуктов или бизнес-требованиях потребления. Они настраиваются узлами потребления, а затем передаются в начальную точку автономной системы для мониторинга, чтобы минимизировать влияние правил. ;
- данныесвоевременность
На основе обеспечения точности данных необходимо дополнительно обеспечить возможность своевременного предоставления услуг, в противном случае ценность данных будет значительно снижена или даже не будет иметь никакой ценности;
Большинство оффлайн задач Али:
Обычно дни используются в качестве временных интервалов, которые называются «дневными задачами». Для ежедневных задач продукты данных или отчеты о принятии решений обычно должны создаваться в 9:00 или раньше каждый день;
Чтобы гарантировать полноту данных за предыдущий день, ежедневные задачи выполняются с нуля. Поскольку все задачи вычислений и обработки выполняются в ночное время, чтобы обеспечить своевременное получение ежедневных данных, подается серия сигналов тревоги. и необходимы настройки приоритетов, чтобы важные задачи были расставлены по приоритетам и выполнялись правильно;
Важные задачи: предприятия с более высоким уровнем активов;
- Приоритет задачи
Для задач «Карта» и «Сокращение» планирование представляет собой древовидную структуру (дерево RelNode). Когда приоритет конечного узла (узла RelNode) настроен, этот приоритет будет передан всем вышестоящим узлам, поэтому параметр приоритета — «Перейти к». конечный узел, а конечный узел часто является узлом потребления сервисного бизнеса;
Установите приоритет: сначала определите уровень активов бизнеса. Узлам потребления, соответствующим предприятиям высокого уровня, естественно, будет присвоен высокий приоритет, в то время как общим предприятиям будет присвоен низкий приоритет, чтобы гарантировать, что предприятия высокого уровня производятся вовремя;
- Тревога задачи
Сигналы задач аналогичны приоритетам и также передаются через конечные узлы;
Во время выполнения задач неизбежно возникают ошибки. Поэтому для обеспечения эффективного и бесперебойного выполнения задач требуется система мониторинга и сигнализации. Для задач с высоким приоритетом при обнаружении ошибки задания или задержки вывода должен подавать сигнал тревоги. быть дано задание и владелец бизнеса;
Моссад: система мониторинга и сигнализации, независимо разработанная Alibaba;
- Моссад
Моссад: система мониторинга и сигнализации для офлайн-задач, незаменимый гарантийный инструмент для работы и обслуживания данных;
Принимайте решения в режиме реального времени на основе текущего состояния автономных задач: следует ли предупреждать, когда предупреждать, как предупреждать, кого предупреждать и т. д.;
Две основные функции: надежный мониторинг и индивидуальные сигналы тревоги;
Строгий мониторинг безопасности
Строгий мониторинг безопасностида Моссадиз Основные функции,Он разработан только для целей эксплуатации и технического обслуживания, то есть бизнес-гарантий.,Пока существование бизнеса из времени предупреждения находится под угрозой,Моссад обязательно предупредит соответствующий персонал;
Строгий мониторинг безопасности В основном включают:
Объем мониторинга: будет контролироваться задача создания надежного страхового бизнеса и все его исходные задачи;
Отслеживаемые аномалии: ошибки выполнения задач, замедление выполнения задач, задержки обслуживания раннего предупреждения;
Объект тревоги: по умолчанию является владельцем задачи, вы также можете установить список обязанностей для определенного человека;
Когда подавать сигнал тревоги: Определите, когда подавать сигнал тревоги, исходя из времени предупреждения, установленного предприятием;
Предупреждение о деловой задержке и предупреждение об ошибке оцениваются на основе «времени выхода предупреждения»;
Время выходного предупреждения: Моссад оценивает приблизительное время, необходимое для текущего бизнеса, на основе среднего времени выполнения всех задач в текущем бизнесе за последние 7 дней как время выходного предупреждения;
Метод сигнализации: в зависимости от важности и срочности бизнеса поддержка по телефону, SMS, «Хочу хочу» и по электронной почте;
Пример: Торговый консалтинг (раннее предупреждение о задержке в бизнесе)
Уровень активов и требования: Определенный уровень активов — A2, который требует, чтобы выходные данные были помещены на полку в 9:00 утра;
настраивать:бизнес-консультантубизнесопределить Строгий мониторинг Безопасность, время вывода бизнеса 9:00, время делового предупреждения 7:00;
Время раннего предупреждения здесь означает, что как только Моссад увидит, что время вывода текущих дел превышает время раннего предупреждения, он позвонит дежурному, чтобы дать раннее предупреждение;
Например, Моссад предполагает, что время выхода бизнес-консультанта будет до 7:30, затем прозвучит телефонный будильник, и дежурный решит, как ускорить оценку времени выхода (то есть раннее предупреждение); оценка задержки вывода): Моссад рассчитывается на основе среднего времени выполнения всех задач текущего бизнеса за последние 7 дней, хотя существует вероятность ошибочной оценки, в целом это очень точное и приемлемое значение;
- Настроить
Пользовательский мониторинг — это относительно легкая функция мониторинга Моссада. Пользователи могут настроить ее в соответствии со своими потребностями, которая в основном включает в себя:
- Сигнализация ошибки: согласно приложению、бизнес、Задачатримониторвернослонруководить Конфигурация сигнализации об ошибках,При возникновении ошибки в объекте «Монитор» будет отправлен сигнал тревоги лицу/Владельцу/график дежурств;
- Сигнал завершения: может быть основан на приложении、бизнес、Задачатримониторвернослонруководить Заканчивать Состояние Конфигурация сигнализации,Когда объект мониторинга будет завершен, человеку/Владельцу/график дежурств будет отправлено оповещение;
- еще нет Сигнал завершения: может быть основан на приложении、бизнес、Задачатримониторвернослонруководитьеще нет Заканчивать Состояние Конфигурация сигнализации,Если объект монитора не сдан, лицу/Владельцу/график дежурств будет выдано предупреждение;
- Периодический сигнал тревоги: для определенной периодической и ежечасной задачи.,Если существование не завершено в определенное время,То есть сигнализация выдается на человека/Владельца/график дежурств;
- Тревога таймаута: настройте сигнал таймаута в соответствии со временем выполнения задачи. Если задача выполняется дольше указанного времени, пользователю будет отправлен сигнал тревоги. / Owner / график дежурств;
- Моссад Диаграмма Ганта изService
В зависимости от функционирования бизнеса Моссад предоставит однодневный критический путь, который является самой медленной диаграммой связей задач для завершения бизнеса, поскольку каждое предприятие может иметь тысячи исходных задач, этот критический путь важен для оптимизации бизнес-связи; очень важно;
4.2.4 Измерение качества
Существует множество решений для обеспечения качества данных хранилищ данных. Чтобы оценить преимущества и недостатки этих решений, необходим набор показателей измерения:
- Качество данных Ночной тариф
Как правило, операции с хранилищем данных выполняются ночью. При возникновении проблемы дежурному персоналу приходится вставать ночью, чтобы справиться с ней;
Частота пробуждений: используйте количество пробуждений в месяц в качестве индикатора для измерения полноты построения качественных данных;
- Качество данныхсобытие
События качества данных: записывайте все проблемы с качеством данных;
Для каждой проблемы с качеством данных регистрируется событие качества данных:
Функция: используется не только для измерения качества самих данных, но также для измерения качества восходящих и нисходящих каналов передачи данных. Это важный показатель измерения качества данных;
- Используется для отслеживания состояния проблема данныхизпроцесса;
- Используется для обобщения и анализа причин качества данных;
- По данным Ордена данных повод проверить наличие недостатков и восполнить пробелы,Необходимо найти причину возникновения проблемы,Последующие планы профилактики также должны быть разработаны для подобных проблем;
- Качество данных Винасистема
В случае серьезных инцидентов с качеством данных они будут повышены до уровня сбоев;
Неудача: относится к проблеме, которая имеет относительно серьезные последствия и привела к потерям активов или рискам для связей с общественностью компании;
Предыстория: Весь путь от сбора данных до конечного потребления должен пройти через десятки систем. Проблемы в любом звене повлияют на вывод данных. Поэтому для формирования совместной цели необходим механизм. сила, в этом контексте возникла система разломов;
В системе неисправностей, как только возникает неисправность, она проходит через систему неисправностей и требует от соответствующей группы принять меры и решить проблему как можно скорее, чтобы устранить воздействие;
- определение неисправности
Во-первых, определите важные бизнес-данные, зарегистрируйте их в системе и заполните соответствующие бизнес-ситуации, такие как ответственное техническое лицо, ответственное деловое лицо, сценарии применения данных, влияние задержек или ошибок, произойдет ли потеря активов и т. д. ., после завершения задачи для этой части данных будут привязаны к базовой линии платформы. При возникновении задержки или ошибки автоматически генерируется сообщение о неисправности и возникает ошибка;
- Уровень отказа
После возникновения неисправности уровень неисправности будет оцениваться на основе определенных стандартов, таких как продолжительность неисправности, количество жалоб клиентов, финансовые потери и т. д., и каждой команде присваивается класс от P1 до P4. иметь концепцию точек неисправности и будут разделены в зависимости от ситуации с неисправностями в конце года, чтобы оценить эффект эксплуатации и технического обслуживания в этом году;
- Поиск неисправностей
После возникновения неисправности необходимо быстро выявить причину неисправности и оперативно устранить ее последствия;
В процессе обработки ошибок мы сделаем все возможное, чтобы уведомить соответствующие стороны о ходе обработки ошибок, чтобы минимизировать влияние на бизнес;
- Обзор отказов
Обзор неисправности: это означает анализ причины неисправности, анализ процесса обработки и формирование последующих решений. Действия будут подробно записаны в виде текста, и будет указана ответственность за неисправность. Как правило, ответственность будет указана. закреплен за лицом;
Примечание. Определение ответственности за вину заключается не в наказании отдельных лиц, а в формулировании решений путем анализа вины, чтобы избежать повторения проблемы;



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
