Просветление! Для проектирования удаленной мультиактивной архитектуры достаточно прочитать эту статью.
Многофункциональность в удаленных местах — это вершина проектирования архитектуры распределенной системы. Когда бизнес-система достигает точки, когда необходимо учитывать многофункциональность в удаленных местах, ее размер и сложность достигают очень высокого уровня. Трехуровневая архитектура уровня доступа, логического уровня и уровня данных — это, по сути, форма инфраструктуры, которую будет иметь каждый бизнес. Ключ к трехуровневой архитектуре лежит в уровне данных. Эту статью мы начнем с уровня данных. влияние удаленной мультиактивности на проектирование инфраструктуры.
Следите за разработчиками Tencent Cloud и заранее получайте техническую информацию из первых рук👇
01. Об инфраструктуре
Развитие информационных технологий проникло во все стороны деятельности людей, а проблемы, с которыми они сталкиваются, разнообразны и сложны, порождая очень сложные программные системы для различных предприятий. Основная цель архитектуры — решить проблему сложности программной системы. Сложность крупных предприятий в распределенной системе Интернета особенно высока, главным образом, по следующим аспектам:
- Высокая доступность В распределенной системе много узлов, и сбои неизбежны. Ключом к проектированию высокой доступности является то, как уменьшить влияние сбоев и как можно быстрее восстановиться после сбоев.
- Высокая производительность и большие объемы запросов для крупных предприятий требуют программных систем, которые могут обрабатывать большой параллелизм, иметь высокую пропускную способность и иметь более короткие задержки ответа;
- Высокая масштабируемость, функциональная итерация, модель запросов и внешняя среда меняются, и система программного обеспечения должна быть хорошо спроектирована с учетом таких изменений, чтобы гибко реагировать;
- бюджетный,Программные системы часто являются бизнес-деятельностью.,Необходимо сосредоточиться на коммерческой ценности,Его конструкция должна измерять соотношение затрат и выпуска.,Минимизируйте затраты и максимизируйте ценность бизнеса;
- безопасность,Требования к безопасности программной системы,Необходимо предотвратить утечку данных, защитить конфиденциальность пользователей и предотвратить незаконный доступ и операции.,Обеспечить стабильность и надежность системы,Защищать права и интересы пользователей;
- Многофункциональный,Бизнес постоянно меняется,Архитектурный дизайн Форсайт в конечном итоге имеет ограничения.,Неизвестное чрезвычайно разрушительно для архитектуры.,Это корень сложности.
Архитектура — это огромная тема, в которой есть принципы проектирования, абстрактные методы, разделение бизнеса, модели предметной области, разделение модулей и т. д. Есть статьи по каждому аспекту. Однако, вообще говоря, независимо от того, насколько сложна программная система, ее можно абстрагировать до «серии комбинаций логики обработки, основанных на данных, позволяющих целевым пользователям получить доступ к системе и использовать ее». Доступ, логика и данные — это то, о чем говорится в этой статье. обсуждает инфраструктуру», как показано на рисунке ниже. Инфраструктура фокусируется на требованиях высокой доступности, высокой производительности и высокой масштабируемости. Эта статья начнется с общей точки зрения и рассмотрит влияние этих факторов на проектирование инфраструктуры.
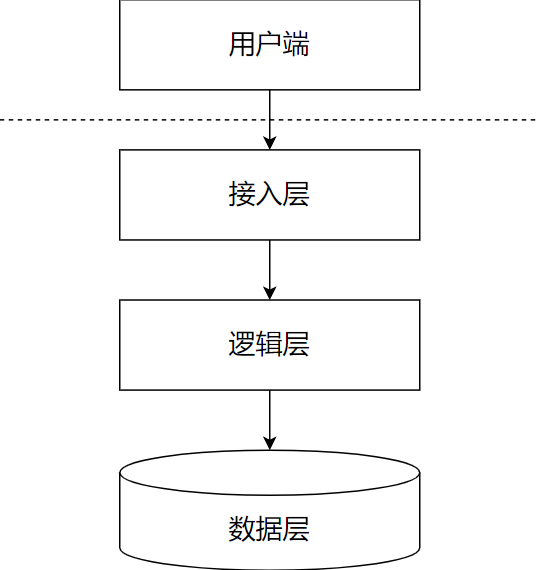
02. О том, как жить больше в разных местах
Необходимо учитывать предприятия, действующие в удаленных местах, и высокая доступность, скорее всего, будет рассматриваться как основная цель. Высокая доступность фокусируется на плане реагирования программной системы на случай сбоев. Ни один компонент распределенной Интернет-системы не является абсолютно надежным на 100%, и всегда существует вероятность сбоя. Для обеспечения доступности системы требуется разработка аварийного восстановления при сбоях. Суть аварийного восстановления заключается в обеспечении избыточности во избежание единых точек сбоя. При выходе из строя определенного компонента системы резервная часть может взять на себя обслуживание, так что вся служба не будет (или меньше) затронута.
На разных этапах развития бизнеса объем и масштаб бизнеса определяют его различную приемлемость к катастрофам, и типы одиночных сбоев, с которыми необходимо иметь дело при аварийном восстановлении, также различны:
- Одна машина,Стадия открытия бизнеса,Очень маленький размер,Развертывание на одной машине может поддерживать,В настоящее время сбои одного компьютера могут быть связаны с повреждением диска, сбоями в работе операционной системы, случайным удалением и т. д.,Чтобы справиться с этой неудачей,Избегайте потери данных,Нужно сделать резервную копию данных,Построить мастер-подчиненный;
- В одном компьютерном зале, поскольку масштабы бизнеса растут, а объемы относительно велики, требуется значительное количество машин. Во время развертывания машины будут развернуты в разных компьютерных залах. проблемы, вызванные выходом из строя одного компьютерного зала;
- В одном городе бизнес продолжает расти, и его объем очень велик. Несколько компьютерных залов в одном городе больше не могут удовлетворить потребности бизнеса в аварийном восстановлении, если происходит стихийное бедствие на уровне города, например, тайфуны, землетрясения. наводнений и других стихийных бедствий, город станет единой точкой обслуживания всего.
Решение единой точки отказа на уровне города — это «множественные действия в разных местах» в названии этой статьи. Существует огромная разница между проблемой одной точки в городе и проблемой одной точки в одной машине или в одном компьютерном зале. Города становятся едиными точками чрезвычайно серьезных стихийных бедствий, таких как тайфуны, землетрясения и наводнения. Эти бедствия часто затрагивают большие территории, и от них страдают одновременно несколько городов в этом районе. Поэтому, чтобы решить проблему единой точки в городе, необходимо переместить резерв в другой район, который находится далеко, например, Гуанчжоу и Шэньчжэнь, оба принадлежат к городскому округу дельты Жемчужной реки, Пекин и Тяньцзинь, оба принадлежат Такие города, как Шанхай и Ханчжоу, находящиеся в городском округе, часто имеют общую инфраструктуру. Такое расстояние не может удовлетворить потребности в восстановлении после стихийных бедствий. Чтобы достичь цели аварийного восстановления, обеспечивающей множественную деятельность в разных местах, в основном необходимо развернуть службы за тысячи миль, такие как распределение в Шэньчжэне и Шанхае, распределение в Пекине и Шанхае и т. д.
03. Задержка записи — ключевой момент
3.1 Ядро заключается в операции записи уровня данных.
В инфраструктуре, вообще говоря, логический уровень отвечает за вычисления и не имеет состояния, что обеспечивает плавное переключение и перехват управления. Основой служб логического уровня являются чтение, обработка и запись данных. Сбои на уровне данных включают синхронизацию, перемещение и восстановление данных. Их целостность и согласованность должны быть обеспечены, прежде чем их можно будет переключить и использовать. Инфраструктура Ключ к аварийному восстановлению лежит на уровне данных.
Операции уровня данных включают чтение и запись. Поскольку операция чтения не предполагает изменения состояния данных, ее можно легко расширить за счет копирования. Операция записи обеспечивает целостность и согласованность записанных данных среди нескольких избыточных копий. требуется репликация, поэтому ключ к уровню данных лежит в обработке запросов на запись.
3.2 Задержка письма качественно меняется при пересечении городов
Причина качественного изменения задержки записи между городами заключается в том, что при аварийном восстановлении до уровня между городами практически все предприятия могут принять задержку, а репликация данных может быть напрямую синхронизирована. При выполнении операций между городами вам необходимо тщательно подумать, может ли компания допустить более высокие задержки, и это также повлияет на конкретный план реагирования.
Большее расстояние означает большую задержку. С помощью инструмента ping измеренная задержка примерно следующая:
- Обратный путь внутри одного компьютерного зала занимает примерно менее 0,5 мс;
- Время прохождения туда и обратно в пределах одного города и между компьютерными залами составляет примерно 3 мс;
- Время в пути между Шэньчжэнем и Шанхаем, который находится за тысячи миль, составляет менее 30 мс. Время в Пекине, Шанхае, Шэньчжэне и Тяньцзине будет больше.

Когда задержка достигает уровня 30 мс, доступность бизнеса сталкивается с новым уровнем проверки. Может ли бизнес принять время записи данных между городами, это не просто проблема в 30 мс:
- Сценарии аварийного восстановления в пределах города,Включает запись данных и копирование реплик.,Запрос на запись вызовет задержку в две секунды.,Это 60 мс;
- Должен ли бизнес-запрос на запись инициировать n запросов на запись последовательно, то есть n раз по 60 мс;
- Необходимо разработать некоторый перспективный дизайн, но в настоящее время это приемлемо. 60ms из сейчас, продолжение из n Будет ли она расширяться, расширится ли до такой степени, что это неприемлемо, и сможет ли эта зависимость быть реализована в последующем проектировании, на всем этом необходимо сосредоточить внимание. на;
- Ситуация в городе,Условия сети могут быть хуже,Например, он склонен к дрожанию,Это не большая проблема,Вообще говоря, это компании, которые имеют возможность строить междугородные сети.,Он также имеет возможность обеспечить стабильность сети.,В ходе теста также выяснилось, что время, необходимое для пересечения городов, было вполне стабильным.,В тесте, продолжавшемся почти 4 с половиной часа,,Максимальный джиттер не превышает 8 миллисекунд.,А максимальное время затрат находится в пределах 30 миллисекунд.
Если компания сможет принять задержку записи между городами, то проблема сведется к аварийному восстановлению внутри города, и можно будет использовать напрямую синхронную репликацию между городами. Если вы не можете принять задержку записи, вы не можете использовать синхронную репликацию между городами на большие расстояния. Вам необходимо найти следующее лучшее решение. Давайте поговорим о двух направлениях.
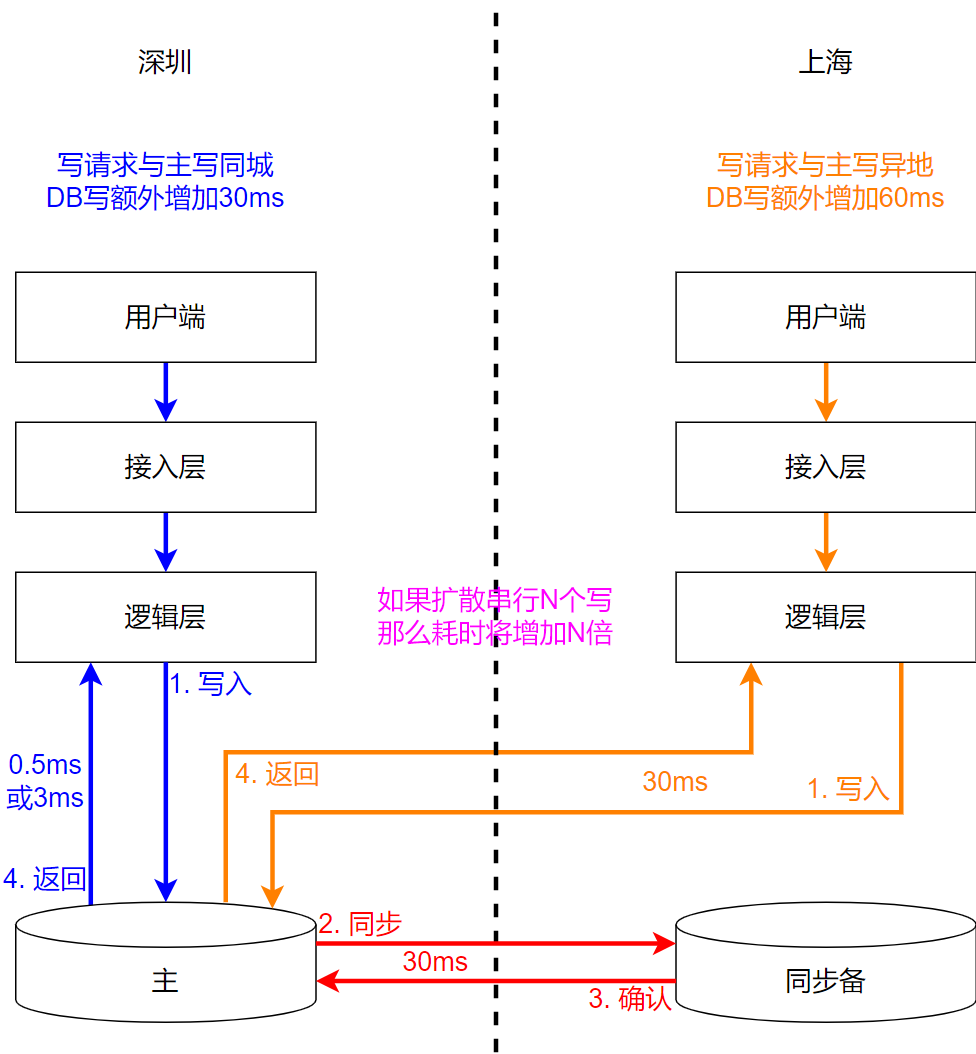
3.3 Синхронная репликация сокращает расстояние и уменьшает цель
Сократите расстояние. Вместо того, чтобы выполнять работу за тысячи миль, выберите маршрут по городу на более коротком расстоянии, например, Гуанчжоу-Шэньчжэнь, Шанхай-Ханчжоу, Пекин-Тяньцзинь. Расстояние составляет 100-200 километров и задержка. составляет 5-7 мс, так что синхронную репликацию все еще можно использовать, но, как упоминалось ранее, этот метод не может достичь реальной цели - нескольких жизней в городах и разных местах.
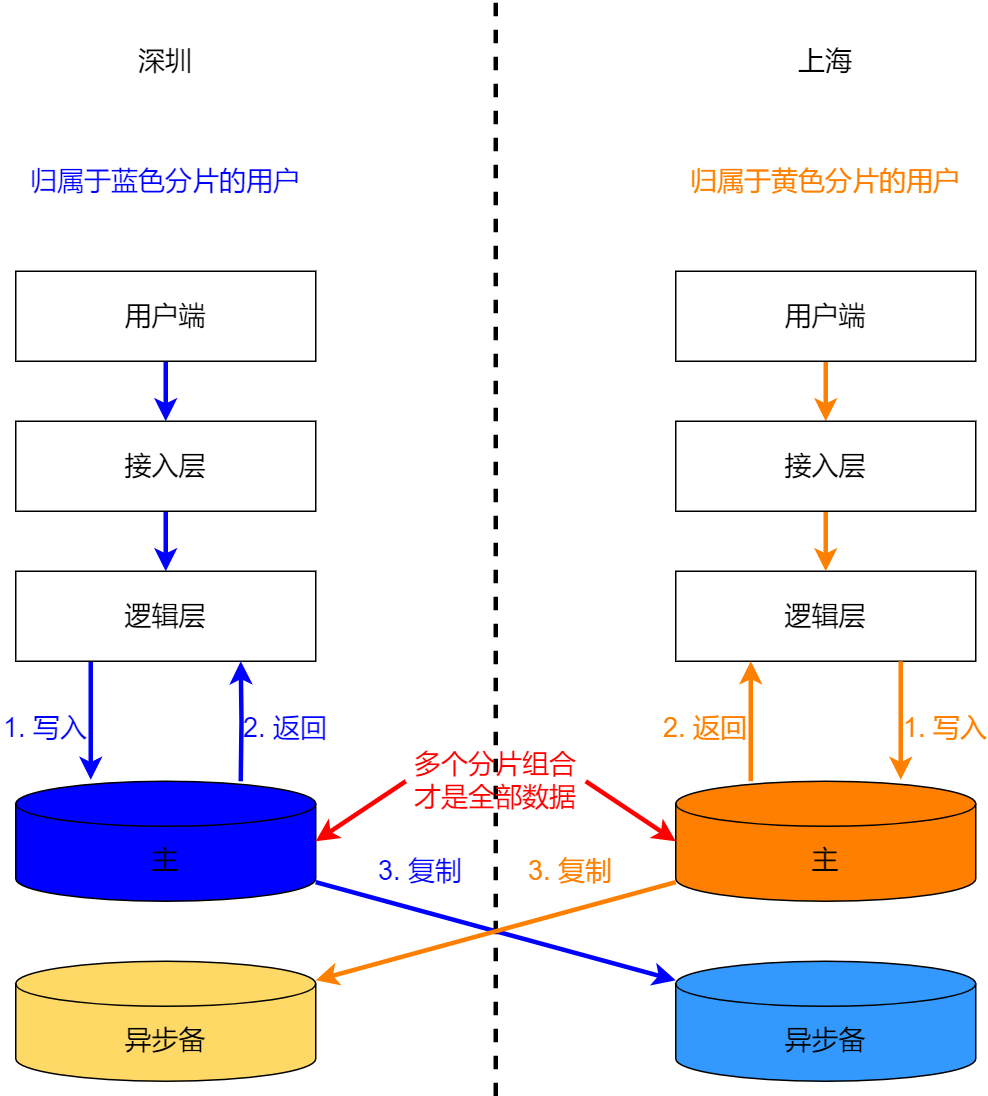
3.4 Асинхронная репликация соседних шардов выполняется с потерями
Без синхронной репликации первое, что нужно сделать, — это сегментировать данные в соответствии с географическим местоположением. Когда задержка недопустима из-за нескольких операций в разных местах, правила сегментирования разных предприятий могут быть разными, например, для определенного бизнеса. определенный восток и определенное сокровище. Правила шардинга для бизнеса электронной коммерции Hungry XX и бизнеса по доставке еды XX Group определенно различаются, но в основном они основаны на географическом местоположении пользователя: пусть данные пользователя будут ближайшими. в какой город поместить в соответствующий город как можно дальше. Как показано на рисунке ниже, после выполнения локального сегментирования для пользователей запись данных не требует межгородской синхронной репликации. После записи в основную точку записи успех напрямую возвращается во внешний мир, не дожидаясь синхронизации данных. другие места.
При использовании асинхронной репликации неизбежно возникнет ситуация, когда данные не будут скопированы в другое место вовремя при возникновении сбоя, как показано на следующем рисунке:
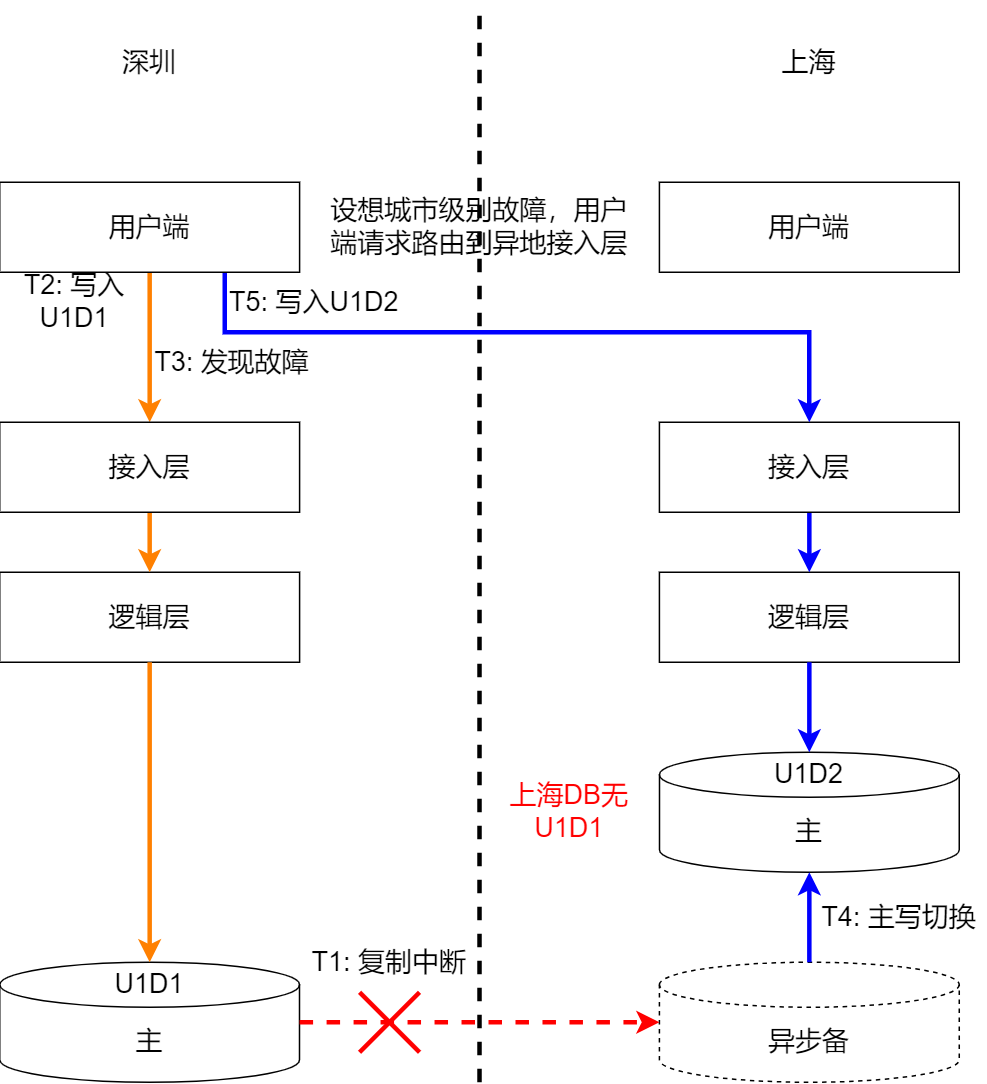
Для предприятий, которым не требуется высокая согласованность данных, таких как Weibo, видео и т. д., вы можете допускать дублирование данных и свободно переключаться. В сочетании с некоторой логикой дедупликации бизнес-уровня, например, в сочетании с аварийными ситуациями, дублирование данных во время стихийного бедствия может привести к дублированию. В принципе, достаточно сбросить вес.
Для предприятий с высокими требованиями к согласованности данных, таких как финансы, платежи и т. д., необходимо обеспечить, чтобы во время аварийного переключения, чтобы минимизировать затронутые данные, необходимо обводить данные, которые могут быть затронуты, в соответствии с характеристиками. бизнеса и нацелены на них. Соответствующие операции пользователя, которому принадлежат соответствующие данные, не обслуживаются. Это будет упомянуто в архитектуре репликации данных ниже.
04. Разделите произведение большим количеством текста
Объем запросов на запись велик, и емкость одной точки записи не может его выдержать. В этом случае все записи данных не могут быть обработаны одной и той же точкой записи. Для разделения полных данных на несколько частей требуется сегментирование. часть имеет свою независимую точку записи. Просто учитывая большой объем записи, нет необходимости выполнять соседнее сегментирование, но соседнее сегментирование все же может получить некоторые преимущества, например, сокращение затрат времени на 30 мс, поэтому соседнее сегментирование, как правило, все еще выполняется. Как показано на рисунке ниже, когда большой объем записи разбивается на сегменты, при записи данных запрос считается успешно обработанным и возвращается на верхний уровень после синхронного копирования данных в другое место.
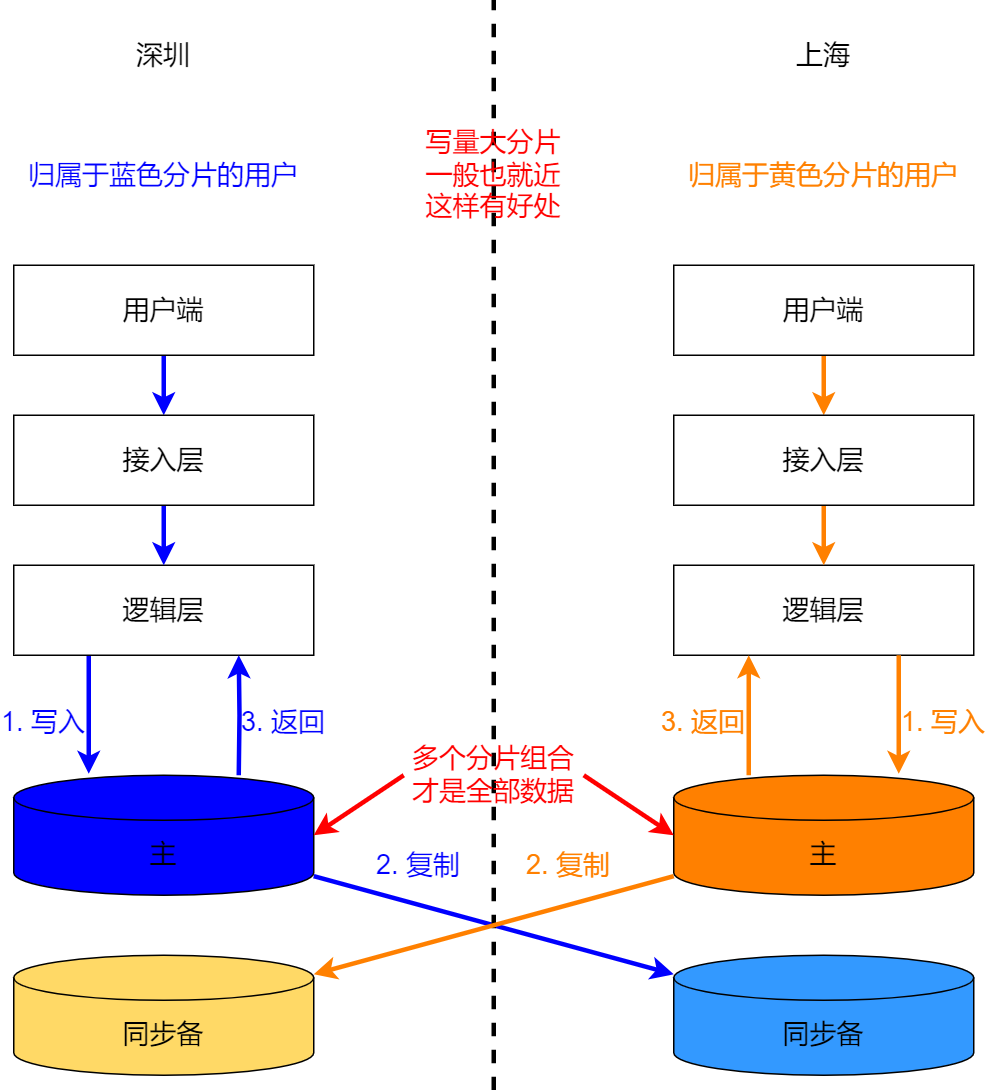
Кроме того, если данные, генерируемые бизнесом с большим объемом записи, раздуты (например, данные о заказах в сфере электронной коммерции), они будут накапливаться с течением времени, и объем данных будет продолжать увеличиваться. Этот тип данных часто имеет характеристики конвейера, и к ним невозможно получить доступ или обновить их снова после записи в течение определенного периода времени; для данных, частота доступа к которым очень низкая или даже равна нулю, они занимают место хранения онлайн-бизнес-библиотеки, в результате чего они занимают место в хранилище онлайн-бизнес-библиотеки; в большом количестве растрат аппаратных ресурсов, накоплении ИТ-расходов предприятий. В этом случае, в зависимости от ситуации с расширением, достаточно разделить базу данных на таблицы и заархивировать старые данные. Это не вызовет влияния фрагментации данных и необходимости изоляции экземпляра.
05. Делайте изолирующие разделения
Изоляция делается для уменьшения влияния сбоев/ненормальностей на всю бизнес-систему. Основная идея — «не кладите яйца в одну корзину». Это оказывает такое же влияние на уровень данных, как и упомянутое выше «разделение шардов с большим объемом записи», то есть все сегменты данных разбиваются на несколько частей, и если с каждой частью возникает проблема, другие данные не будут затронутый. На самом деле изоляция не имеет ничего общего с аварийным восстановлением в пределах города, которое требует больше работы в разных местах. Это также распространенный метод аварийного восстановления в одном и том же городе.
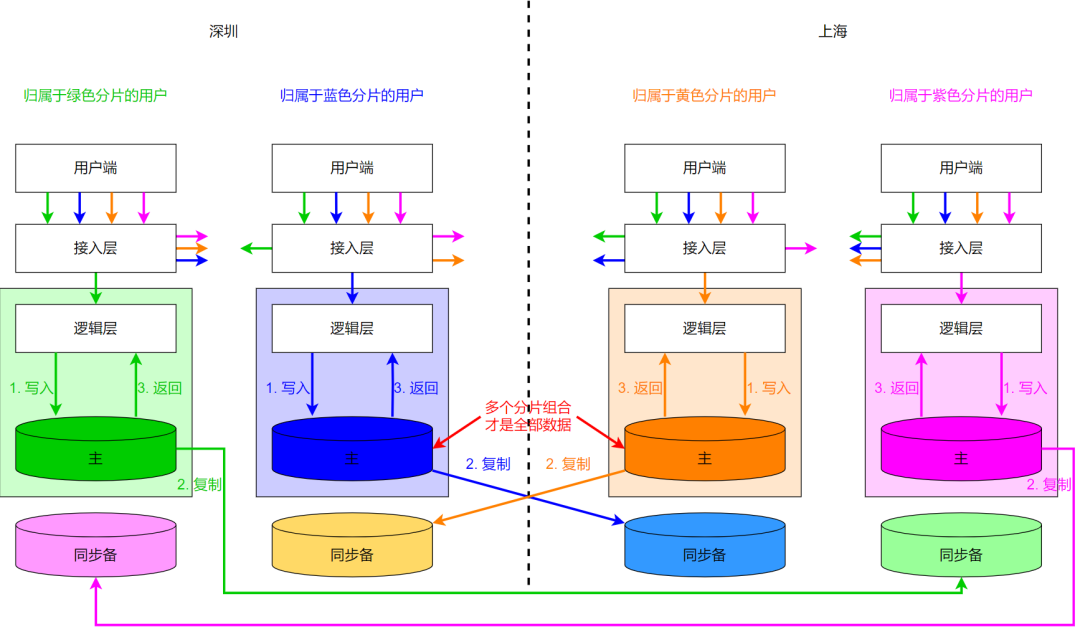
Помимо собственного уровня данных, бизнес-системы часто включают в себя и другие зависимости, такие как связанные базовые компоненты, сервисы более низкого уровня, операционные платформы и т. д. Поэтому при выполнении изоляции часто не ограничиваются изоляцией уровня данных, но в общее рассмотрение также включаются различные зависимости и даже верхний логический уровень. Этот вид схемы изоляции, которая последовательно соединяет верхние и нижние зависимости, имеет множество названий, таких как «объединение», «SET», «чередование» и т. д. На рисунке ниже представлена схематическая диаграмма:
- уровень доступа,Сделать выбор фрагментации объекта на основе соответствующей информации в запросе;
- Логический уровень обрабатывает только запросы, принадлежащие шардам этого блока;
- данныеслой,Просто с точки зрения изоляции,Может выполнять синхронное копирование данных между городами;
- Унифицированная изоляция не особенно тесно связана с обсуждением в этой статье мультиактивности в разных местах и аварийного восстановления между городами.,Но не расширяйте слишком сильно,Влияние маршрутизации будет упомянуто ниже.
06. Другие влияющие факторы
Обсуждая модели данных, мы часто говорим о «большем чтении и меньшем количестве записи», «частом чтении и записи», «разделении чтения и записи» и т. д. Видно, что чтение также является важным фактором при определении модели данных. . Однако в отличие от вышеупомянутых факторов, таких как задержка записи, объем записи, изоляция и т. д., которые могут привести к фрагментации данных, влияние операций чтения в основном проявляется на управлении копированием, механизме кэширования и управлении соединениями. Чтение является послевторичным соображением, то есть после первого определения того, следует ли выполнять сегментирование, затем оно рассматривается на основе сегментирования.
6.1 Задержка чтения может быть достигнута поблизости
Операции чтения можно разделить на две ситуации в зависимости от потребностей бизнес-сценария:
- Читать сразу после написания,эта ситуация,Требуется последнее значение после чтения и записи.,Это строгое требование последовательности,Ее необходимо решить, прочитав и написав пункт из,Фактически, это относится к категории операций записи;
- Откладывайте чтение правильно,эта ситуация,Допустимо читать старые исторические ценности,Просто соблюдайте требования к возможной согласованности,С этой проблемой можно справиться, прочитав и написав копию последующей копии.,Именно этот контент обсуждается в этом разделе.
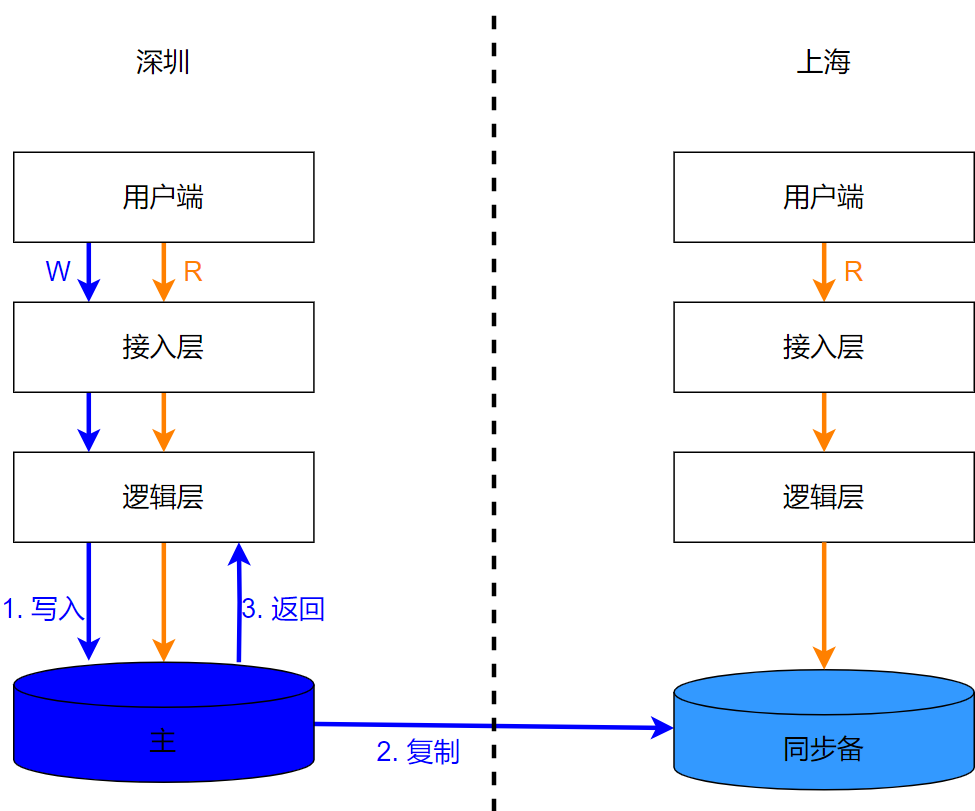
Вообще говоря, предприятия предъявляют более строгие требования к задержке для операций чтения, чем для операций записи. Например, при написании сообщения Weibo, публикации видео, заказе продукта или инициации передачи пользователи должны ждать соответствующим образом. Как и ожидалось, если. пользователи чувствуют себя застрявшими во время чтения Weibo, просмотра видео, просмотра продуктов, проверки баланса счетов и других операций, они по сути будут потеряны. В большинстве сценариев чтения допустима умеренная задержка, и последний контент невозможно увидеть. Пользователи могут его «обновить». После выяснения требований сценария решение проблемы задержки чтения становится очевидным: предоставить копию для чтения ближе к пользователю. Как показано на рисунке ниже, пользователи, посещающие Шанхай, могут получить доступ к резервной копии в Шанхае, и им не нужно ехать в Шэньчжэнь, чтобы прочитать данные.
6.2 Значительное расширение объема чтения
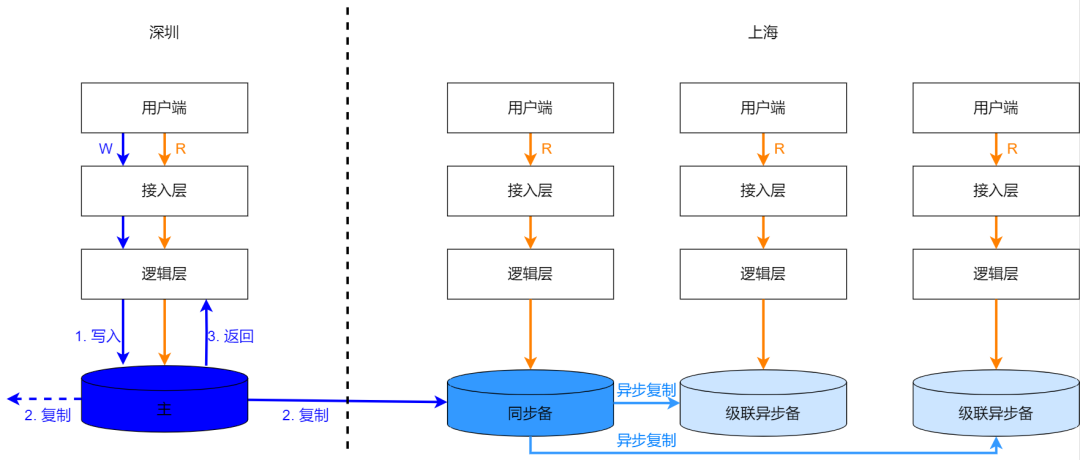
Подобно вышесказанному «задержка чтения может быть близкой», здесь все еще обсуждается сценарий, в котором может быть принято соответствующее отложенное чтение. Многие предприятия читают больше и пишут меньше, а большое количество запросов на чтение можно удовлетворить за счет расширения реплик. Однако следует отметить, что при расширении реплики до определенного масштаба нагрузка на точку записи возрастет из-за необходимости репликации данных реплики чтения, которую можно решить за счет каскадной синхронизации. Кроме того, пропускная способность запросов на чтение будет дополнительно улучшена за счет добавления кэша, который здесь расширяться не будет. Вообще говоря, объем чтения обычно не оказывает такого же влияния, как задержка записи и объем записи, которые вызывают фрагментацию данных и требуют изоляции экземпляра. На рисунке ниже представлена схема каскадной репликации.
6.3 Подключение к нескольким прокси
Уровень данных является основой бизнеса. Хотя количество запросов к БД сокращается до приемлемого уровня за счет таких операций, как сегментирование, копирование и кэширование, логический уровень, как вызывающий уровень данных, все равно неизбежно нуждается. для установления и данных. Если на логическом уровне слишком много вызывающих абонентов, потребуется установить больше соединений с БД. Увеличение количества подключений может повысить параллелизм БД, поддержать больше вызывающих абонентов и повысить пропускную способность. Однако производительность базы данных не может быть бесконечно увеличена. При достижении порогового значения вытеснение ресурсов и переключение контекста потока, вызванное высоким уровнем параллелизма, вместо этого приведут к снижению общей производительности базы данных. Более распространенный подход — добавить уровень прокси-сервера к базе данных уровня данных, чтобы предотвратить прямое подключение вызывающей стороны логического уровня к БД и позволить прокси-серверу закрыть соединение с БД.
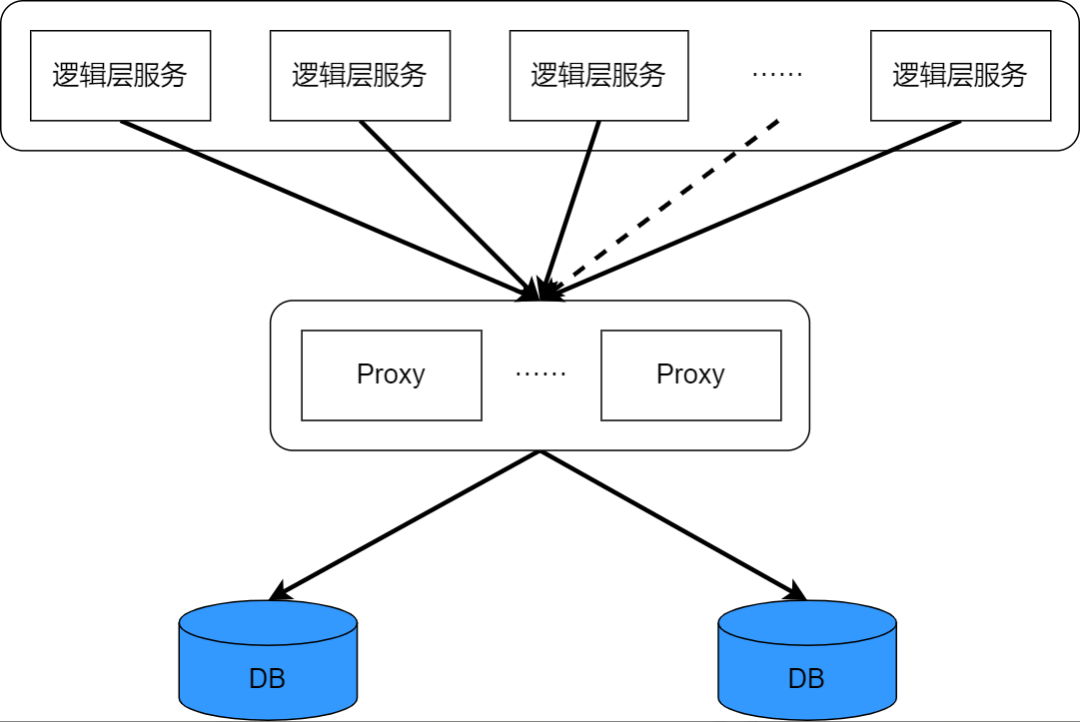
07. Архитектура репликации данных
В приведенном выше обсуждении для репликации данных использовалось упрощенное выражение: один главный и один резервный. Фактически, для аварийного восстановления недостаточно одного главного сервера и одного резервного сервера. Давайте рассмотрим несколько типичных архитектур репликации данных.
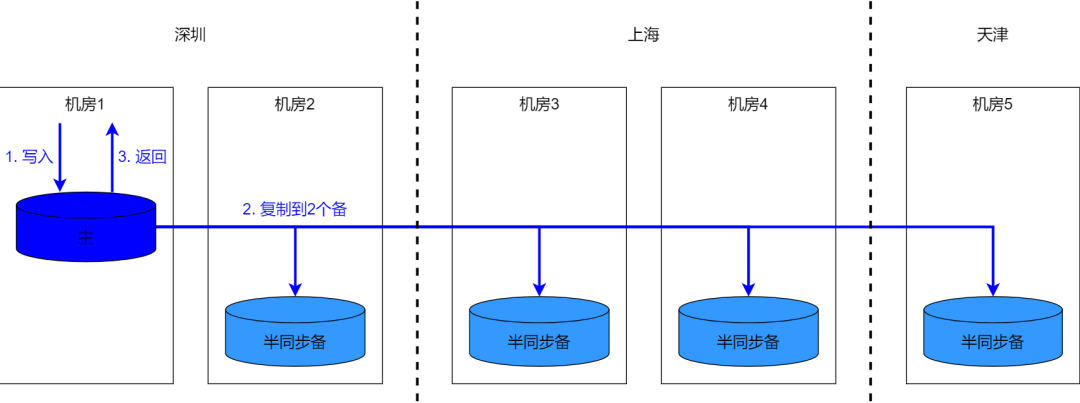
7.1 Три места и пять центров
Для обеспечения аварийного восстановления в принципе необходимо использовать соглашение большинства. Более классической моделью является архитектура с тремя точками и пятью центрами:
- Постройте 1 главного, 4 подчиненных и 5 инстансов, распределенных по 3 городам и 5 инстансам. IDC В компьютерном зале;
- Запрос на запись должен гарантировать, что соответствующие изданные записаны в 1 главный, 4 средних и 3 экземпляра.,То есть напишите основной пост,Синхронно с двумя другими,Достичь требований большинства;
- В случае аварии в городе,Независимо от того, в каком городе произошел сбой,за пределами города,Все они полностью изданы и отвечают требованиям аварийного восстановления.
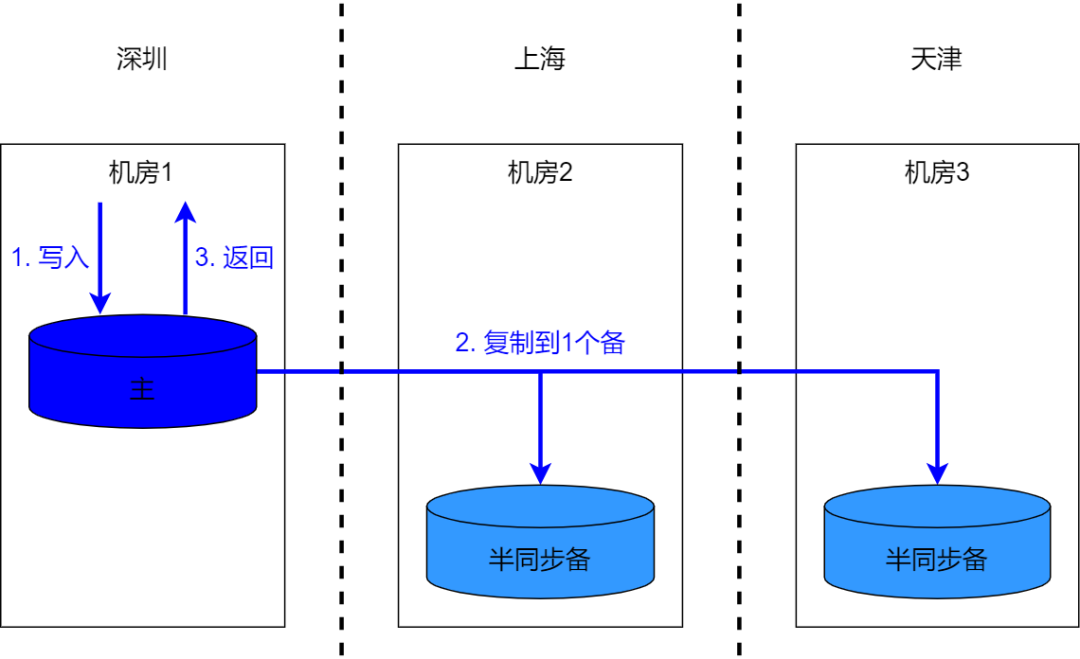
7.2 Три места и три центра
Три места и три центра могут составить наименьшее большинство и могут также удовлетворить потребности аварийного восстановления. Однако, учитывая следующие моменты, они обычно не принимаются:
- Вообще говоря, переключение между городами является более сложным и дорогостоящим;
- Вероятность отказа машин и компьютерного зала намного выше, чем вероятность отказа в городе;
- в определенном DB При сбое инстанса попробуйте переключить его в пределах одного города. места и три центра, переключение между городами будет происходить при возникновении неисправности;
- Три места и пять центров по отношению к Три места и три Будет растрата машинных ресурсов. В ситуациях, когда ресурсов недостаточно, можно использовать метод смешанного распределения для изоляции некоторых ресурсов (например, CGroup)механизм,Для улучшения использования ресурсов и в то же время,Это также позволяет избежать взаимного влияния между предприятиями, производящими смешанные ткани.
7.3 Три центра в одном городе
В сценариях, когда задержки между городами недопустимы, будет использоваться архитектура репликации с тремя центрами в одном городе.
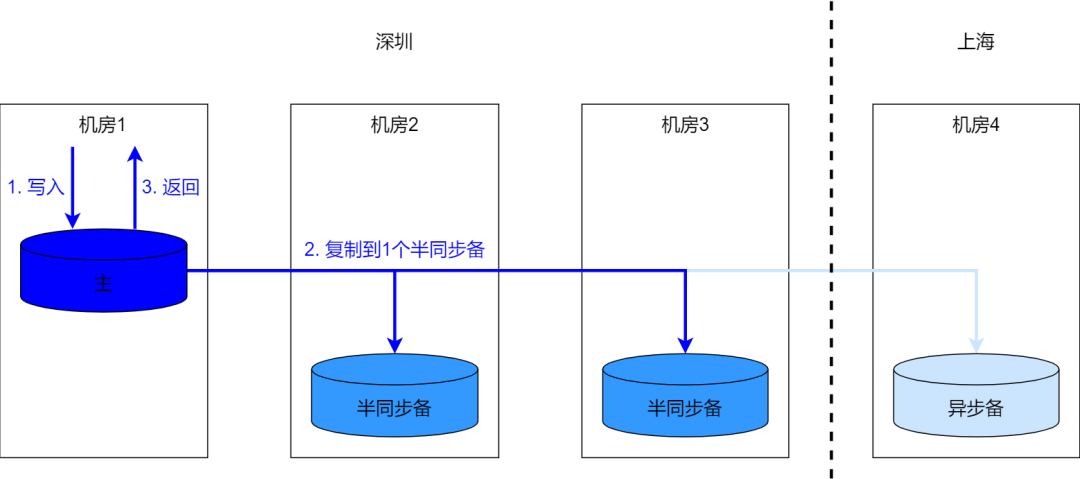
При наличии нескольких наборов из трех равных центров в одном и том же городе в нескольких городах можно обеспечить аварийное восстановление с потерями в пределах города, как показано на следующем рисунке:
- Когда в городе происходит сбой, запрос на запись передается удаленному узлу. центра в одном процесс города, итак, каждая Три на картинке ниже центра в одном во всех городахиз экземпляров есть сверстники Три центра в одном городе Примеризданные;
- Эта модель аварийного восстановления,В случае аварии в городе,Могут возникнуть проблемы с дублированием данных.,Например, пользователь в синем цветеиз set1 Добавлены новые данные, произошел сбой города, данные опоздали на удаленный из асинхронного резервного копирования, аварийное переключение, запрос пользователя был переключен на пир из зеленого цвета set2,в это время,Пользователь не может прочитать новое дополнение изданные,снова будет работать;
- данные при чтении,Возможна интеграция города из данных точки записи и однорангового Три центра в одном городе из данных асинхронной подготовки.
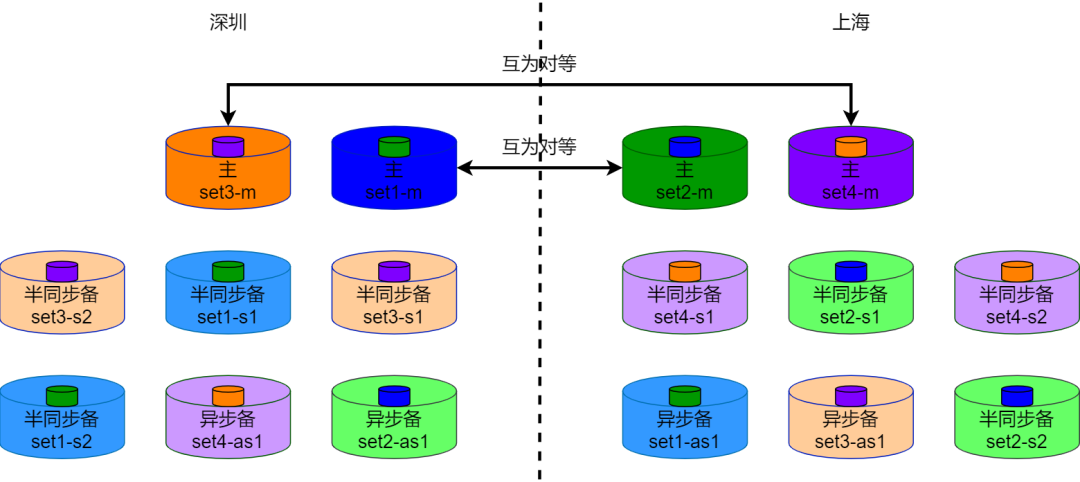
7.4 Двойной мастер и взаимная репликация
Архитектура взаимной репликации с двумя мастерами означает, что каждый экземпляр имеет полные данные. Однако каждый мастер одновременно обрабатывает запись только части данных, чтобы избежать конфликтов записи.
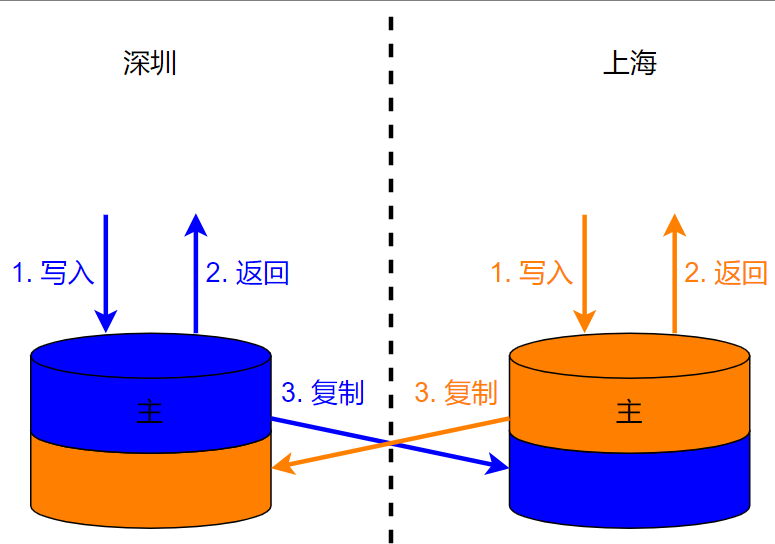
Эта модель при аварийном восстановлении между городами определяет логику записи данных во время аварийного восстановления между городами путем записи временных точек синхронизации, что также происходит с потерями:
- Поддерживать единый генератор временных точек,каждая операция записи,Все моменты времени записываются,Новая запись записывается как Ti (вставка);
- данные При выполнении асинхронной репликации из,Запись скопирована в момент времени,Обозначается как Ts(sync);
- Когда происходит сбой,Отключить запись в экземпляр, где находится неисправность,Время запрета на запись записывается как Tb (запрет);
- с потерямииз Состояние:
- Ts < Ti < Tb,То есть вновь добавленная запись в основном записывающем устройстве не копируется в резервный.,Пользователь не может прочитать перед записью в основной записи изданные,и повторите операцию записи,Произойдёт повторение данных;
- на все новые времена Ti < Tb && Ts < Tb изданные, то есть изданные существовали до того, как запись неисправности была отключена, и не могут быть обновлены после переключения на новую точку записи, поскольку после Tb Всегда былоданные Операции записи не копируются на место,Если вы обновляете напрямую,Может возникнуть конфликт записи.

7.5 Несинхронизированный список
Ранее упомянутая репликация трех центров в одном городе и репликация с двумя мастерами могут привести к дублированию данных. Основная причина заключается в том, что неизвестно, какие данные не были синхронизированы. Если вы можете четко знать, какие данные не были скопированы на место, то вы можете специально отклонить операции с этими данными, которые не были скопированы на место.
Бизнес не может принять влияние N раз на 60 мс, вызванное N раз пересечения города, но, как правило, он может принять задержку в 30 мс для одного пересечения города. Рабочий механизм этого режима:
- Перед выполнением конкретной операции записи,Совершив междугородний звонок, запишите владельца операции записи, соответствующей неуказанному списку;
- После того, как синхронная операция записи достигает межгородского экземпляра, владелец изданной операции записи удаляется из списка бесхозных синхронных;
- Прежде чем делать данные напишите,Сначала проверьте, существует ли владелец операции записи изданных в частном списке.,если существует,затем отклонить запрос;
- этот режим,Это все еще вредно,Это просто приносит в жертву очень небольшое количество пользователей, которые не были скопированы на место.,И согласованность данных гарантирована,Сотрудничать Двойной мастер и взаимная репликация позволяет добиться очень хороших результатов.
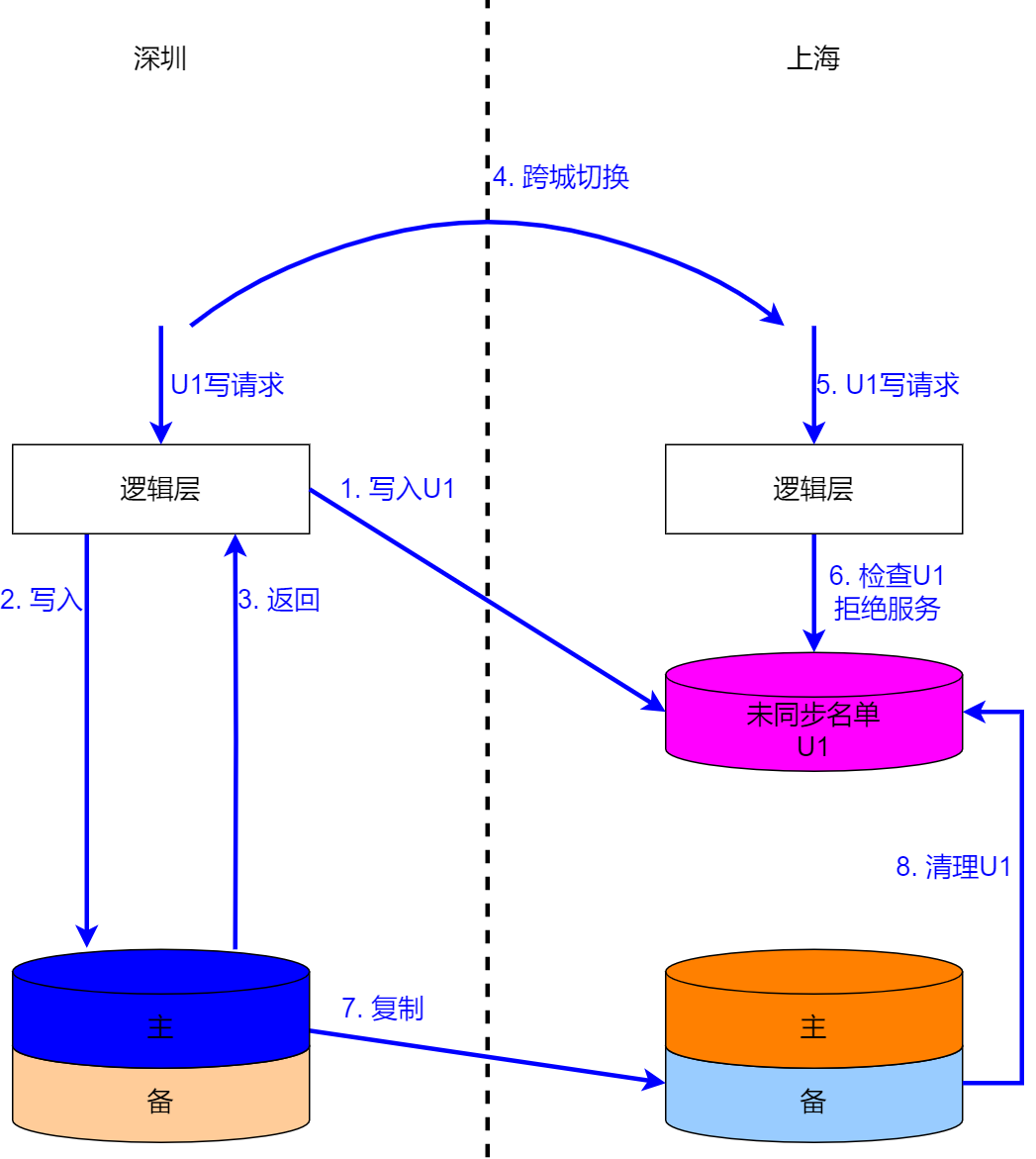
08. Данные влияют на маршрутизацию
Учитывая проанализированные выше факторы, формы данных разных предприятий могут быть разными и их можно разделить на три категории:
- Данные о глобальной ситуации в городе,данные Нет фрагментации,Межгородская репликация между главным и подчиненным устройствами;
- Рядом шардингданные,данные должны быть фрагментированы,Поскольку бизнес не может принять серийное письмо для разных городов, это отнимает много времени.,Копировать можно только один и тот же город несинхронно.,Асинхронная репликация используется в городах;
- Межгородские шардингданные,данные должны быть фрагментированы,Межгородская репликация выполняется между главным и подчиненным узлами каждого шарда.
Давайте посмотрим на влияние этих трех режимов на маршрутизацию.
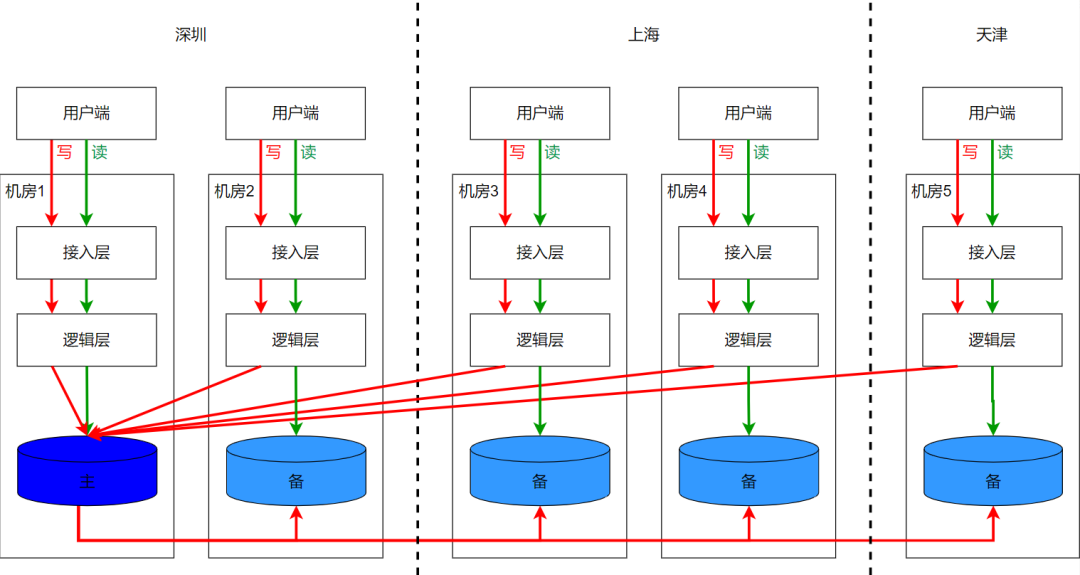
8.1 Ближайшая маршрутизация глобальных данных между городами
Данные не фрагментированы, имеется только одна точка записи, а несколько копий обеспечивают близкое чтение. В этом случае метод маршрутизации подходит для всего звена, а ближайший маршрут выбирается по приоритету компьютерный зал-город-глобальный. Если вы рассматриваете изоляцию логического уровня, вы также можете выполнить разгрузку маршрутизации на уровне доступа. Однако это не имеет большого значения, поскольку для глобальных данных близлежащий доступ уже имеет хорошую изоляцию.
8.2 Разгрузка доступа к данным близлежащих сегментов
Целью сегментирования данных поблизости является решение проблемы межгородской задержки N операций записи, когда через него проходит запрос на запись. Поэтому, прежде чем предприятие выполнит запрос на запись, запрос должен быть заранее перенаправлен в город (компьютер). комнате), где расположены данные, так что они перемещаются N раз. Операции записи выполняются в одном и том же городе (одном и том же компьютерном зале), что исключает трудоемкий процесс между городами. Это требует разгрузки маршрутизации на логическом уровне, который выполняет определенные запросы на запись. Учитывая изоляцию логического уровня, разгрузка маршрутизации обычно выполняется на уровне доступа. Запросы на чтение также могут использовать ту же стратегию маршрутизации, что и запросы на запись, поэтому запросы на чтение и запись для одного и того же сегмента находятся в одном месте. Архитектура репликации трех центров в одном городе в каждом шарде на рисунке ниже не показана.
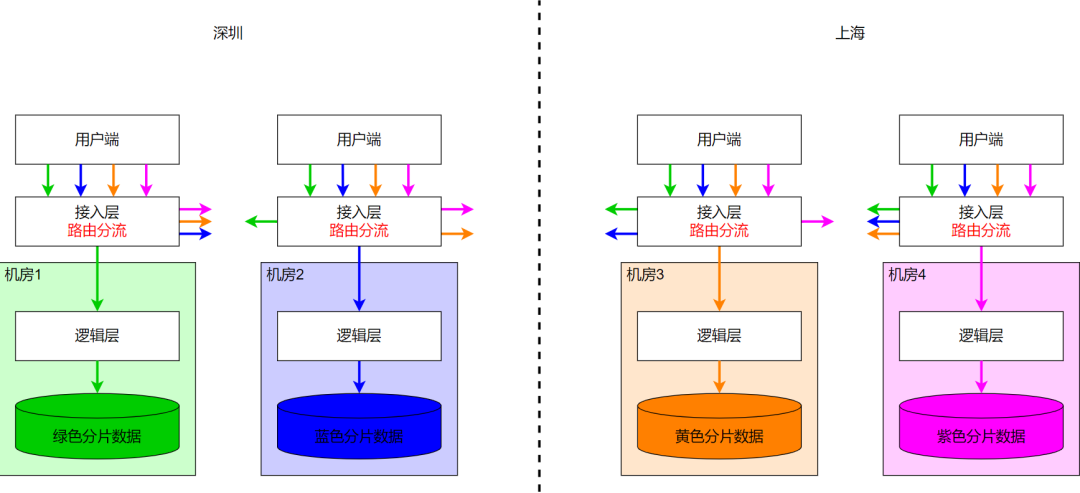
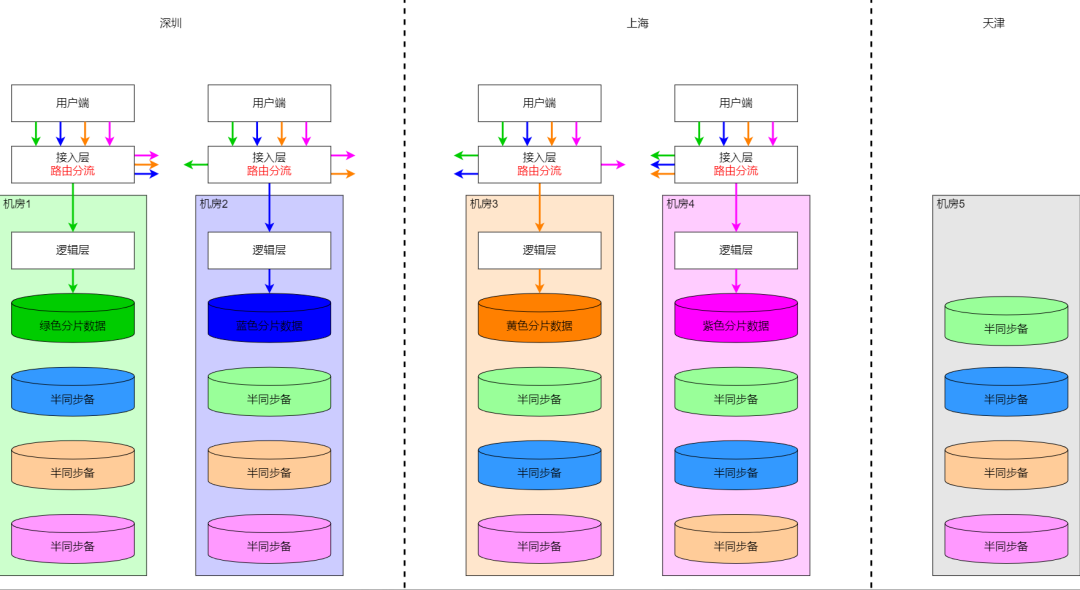
8.3 Доступ к сегментированным данным между городами и их разгрузка
Сегментированные данные между городами могут принимать межгородские задержки, а для операций записи поддерживается межгородская синхронизация. На основе шардирования, ради близости и влияния на изоляцию, в основном это будет выполняться рядом во время разделения. , собираются пользователи и основные точки записи каждого шарда распределяются по разным городам и компьютерным залам. Влияние данных сегментирования между городами на маршрутизацию в основном такое же, как и влияние сегментирования близлежащих городов. Разница в том, что сегментирование между городами требует введения третьего города для полного аварийного восстановления данных. Как показано на рисунке ниже в Тяньцзине, третий город обычно просто формирует большинство для аварийного восстановления данных и не будет обрабатывать трафик. доступ или рассмотрите возможность его использования поблизости.
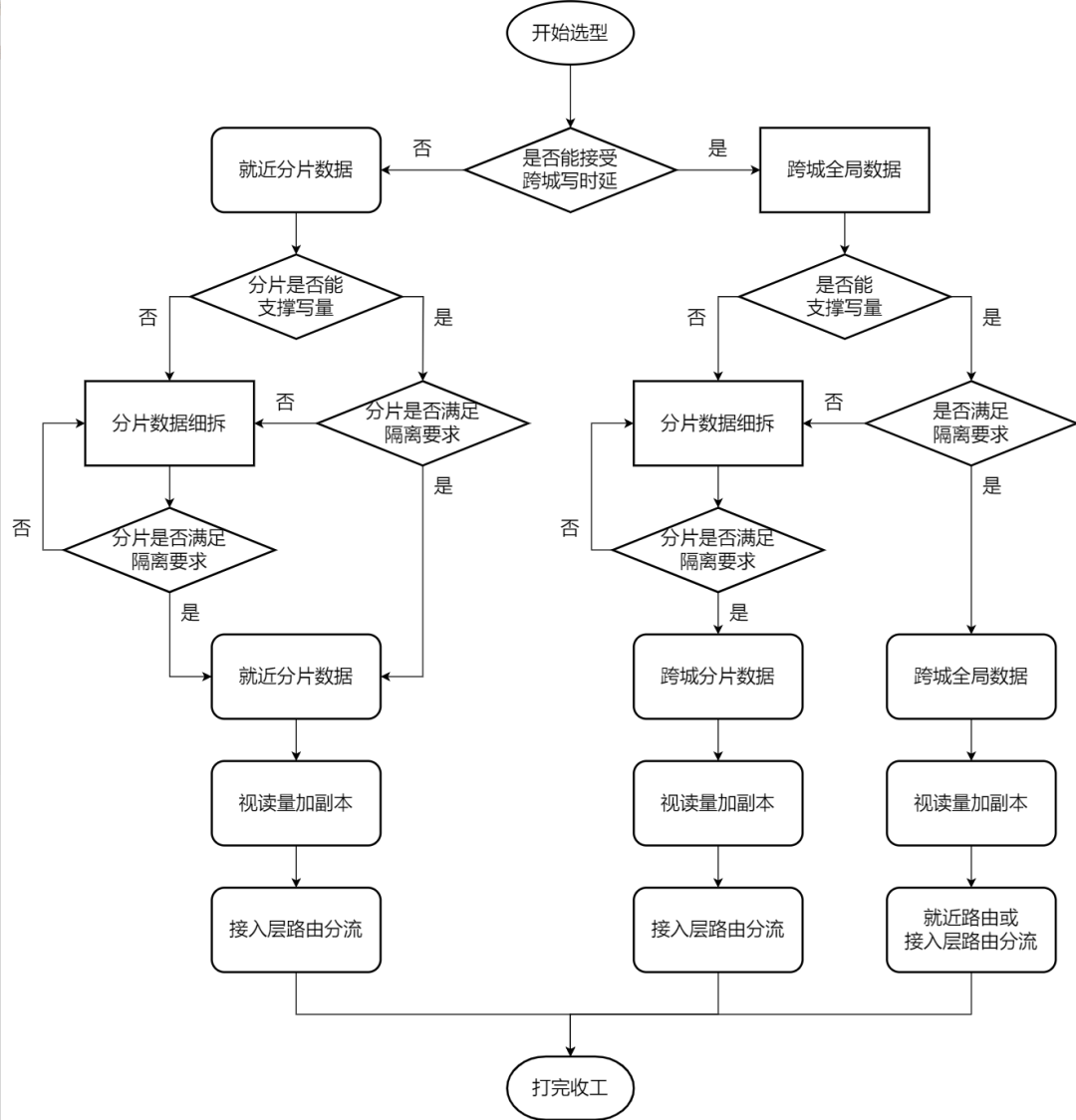
09. Режим выбора архитектуры
При конкретном проектировании архитектуры вы можете обратиться к следующим шагам для рассмотрения и оценки. На рисунке ниже обсуждается только некоторая наиболее распространенная ключевая информация, описанная в этой статье, за исключением многих факторов, которые могут оказаться решающими в некоторых бизнес-сценариях, таких как стоимость в случае нескольких междугородних, трехместных, пятиместных Шардинг центра По сравнению с тремя центрами в одном городе, пропускная способность может снизиться, но машинные ресурсы возрастут, что также может стать решающим фактором при принятии решения о том, какую модель принять. Короче говоря, проектирование архитектуры — это очень сложный процесс, и факторы, которые необходимо учитывать, сложны и разнообразны, и его все равно необходимо анализировать с учетом конкретных условий бизнеса.
-End-
Автор оригинала|Сюн Чжанцзюнь
Спасибо, что прочитали это, почему бы не обратить внимание? 👇



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
