Простые в использовании инструкции по обучению LangChain
Эта статья представляет собой краткое изложение официальных документов и серии материалов, посвященных изучению LangChain. В ней рассказывается о понимании и использовании шести основных модулей Langchain. Полный текст довольно длинный, в общей сложности более 50 000 слов. Вы можете сохранить его. сначала за помощь в обучении.
1. Что такое Лангчейн?
В настоящее время бесконечно появляются различные модели ИИ, и расцветают сотни цветов. Скорость разработки больших ребят всегда намного опережает скорость обучения учащихся. . Чтобы повысить производительность и не допустить, чтобы разработчики прикладного уровня были ограничены производственным развертыванием каждой языковой модели... LangChain вышел из мира.
Можно сказать, что Langchain — это архитектура искусственного интеллекта, которую стоит изучить на данном этапе.,Так какая же в нем магия, которая делает ее достойной такого высокого статуса? Будет ли стоимость обучения высокой? Не волнуйся! Хотя Langchain мощный,Но на самом деле он предназначен для повышения эффективности создания приложений, связанных с LLM.,Мы также можем понимать это как «инструкцию по эксплуатации».,даиз,Толькодаодин“руководство”!этостандартныйопределениеубил нассуществовать СтроитьодинLLMМожет использоваться при разработке приложений.извещь。Я, например, уже писализAIпредставлено в статьеизprompt,Форматировать его можно через изPromptTemplate в Langchain:
prompt = """Translate the text \
that is delimited by triple backticks \
into a style that is {style}. \
text: ```{text}```
"""
Когда мы вызываем ChatPromptTemplate для нормализации
from langchain.prompts import ChatPromptTemplate
prompt_template=ChatPromptTemplate.from_template(prompt)
print(prompt_template,'ChatPromptTemplate')
Приглашение будет отформатировано как:

Из приведенного выше примера вы можете интуитивно увидеть, что ChatPromptTemplate может точно извлечь стиль и текст входных переменных, объявленные в приглашении, что делает приглашение более понятным. Конечно, Langchain не только оптимизирует подсказки таким образом, но также предоставляет различные другие интерфейсы для дальнейшей оптимизации подсказок. Вот лишь пример более простого и интуитивно понятного метода, который может попробовать каждый.
LangchainНа самом деле простодасуществоватьопределение НесколькоОбщая спецификация сорта,В процессе оптимизации и разработки приложений ИИ могут использоваться различные технологии.,Разделите их на несколько небольших элементов.,Когда мы создаем приложение,Сложите эти элементы напрямую,Нет необходимости неоднократно изучать детали реализации каждого «элемента».
2. Официальный документ Langchain такой длинный, что мне читать?
Несомненно,Если вы хотите изучить Langchain самым простым и понятным способом, просто прочитайте официальную документацию.,Опубликовать первымодин СвязьОфициальная документация Langchain
Из каталога документов мы видим, что Langchain состоит из 6 модулей, а именно: Модель ввода-вывода, Извлечение, Цепочки, Память, Агенты и Обратные вызовы.
Модель ввода-вывода: основная часть приложений искусственного интеллекта, включая ввод, модель и вывод.
Поиск: «Поиск» — эта функция тесно связана с библиотекой векторных данных, которая предназначена для поиска в базе данных векторов содержимого документа, связанного с проблемой.
Память: сохраняет записи исторических диалогов для моделей диалоговых форм и перезагружает эти записи исторических диалогов в любой момент во время длительного диалога, чтобы обеспечить точность диалога.
Цепочки: хотя создание приложения может быть первоначально завершено с помощью трех модулей: модели ввода-вывода, извлечения и памяти, если вы хотите реализовать мощное и сложное приложение, вам все равно необходимо объединить модули. На данный момент вы можете использовать цепочки для. соединить их, тем самым обогатив функционал.
Агенты: он может понять намерение пользователя посредством пользовательского ввода, вернуть определенный тип действия и параметры, а затем автономно вызывать соответствующие инструменты для удовлетворения потребностей пользователя и сделать приложение более интеллектуальным.
Обратные вызовы. Механизм обратного вызова может вызывать отслеживание ссылок и записывать журналы, чтобы помочь разработчикам лучше отлаживать модель LLM.
Конкретная связь между шестью модулями показана на рисунке ниже (изображение взято из Интернета):
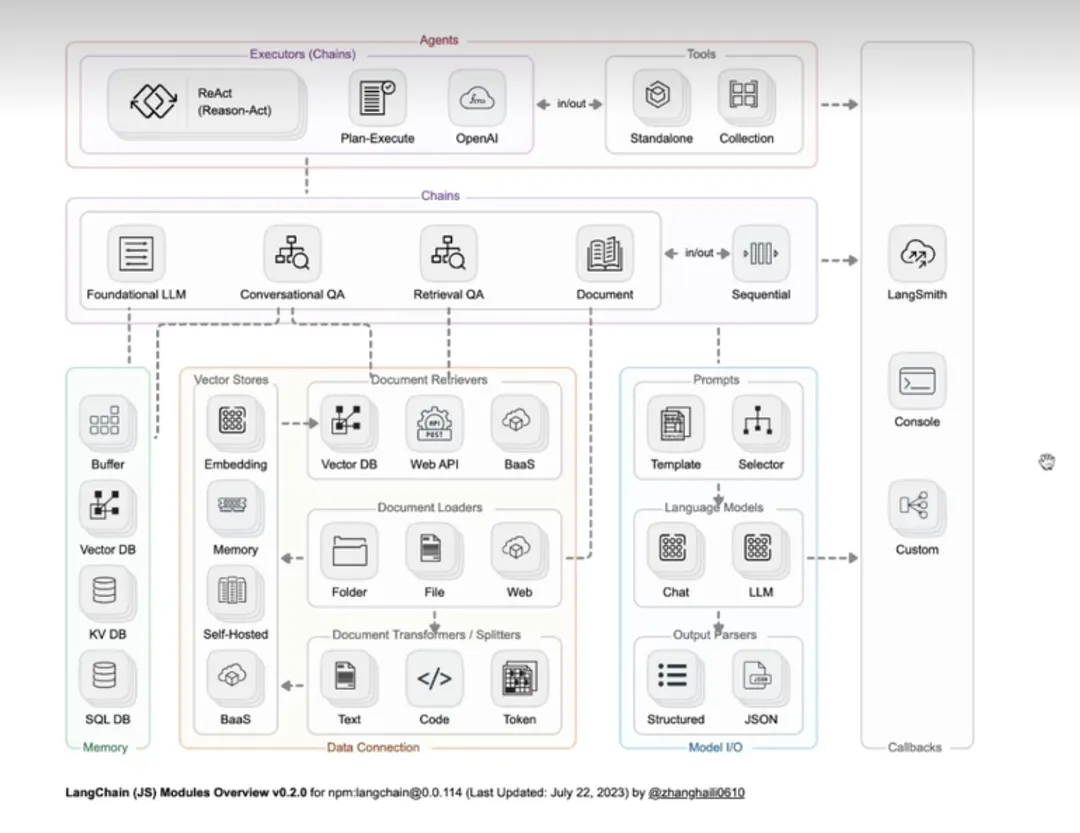
Ладно, сказав это, нам нужно только пройти модули один за другим и, наконец, освоить их, и тогда мы станем квалифицированным учеником Langchain.
3. Модель ИО
Можно сказать, что эта часть является основной частью Langchain. Цитируя диаграмму, использованную ранее при представлении ИИ, она представляет некоторые конкретные принципы реализации в модели IO.
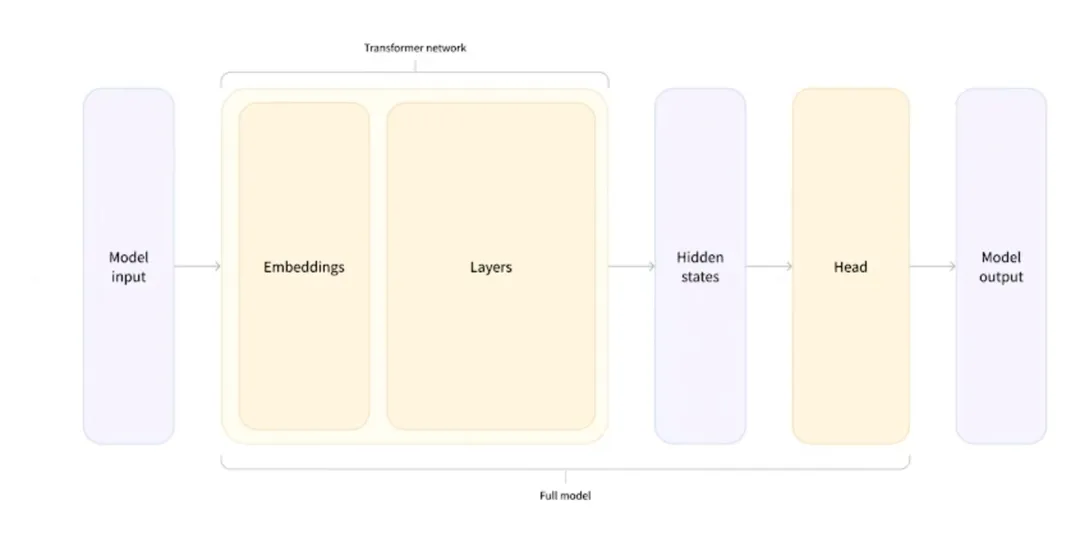
Как видно из рисунка выше: мы используем Модель IOиз Основное времясосредоточиться наиз Сразудаввод, обработка, выводэти три шага。Langchainтакжедав соответствии с Вот как реализовать Модель Модуль ввода-вывода, в этом модуле основными методами реализации Langchain для этого модуля являются: приглашение (ввод), язык. модель (обработка), Выход Pasers (выход), Langchain оптимизирует эти три шага с помощью ряда технических методов, чтобы сделать их более стандартизированными. Нам больше не нужно обращать внимание на конкретную реализацию каждого шага. Мы можем напрямую использовать API, предоставляемый Langchain, чтобы улучшить нас. Составное построение приложения (для более четкого понимания разместите картинку официального документа).
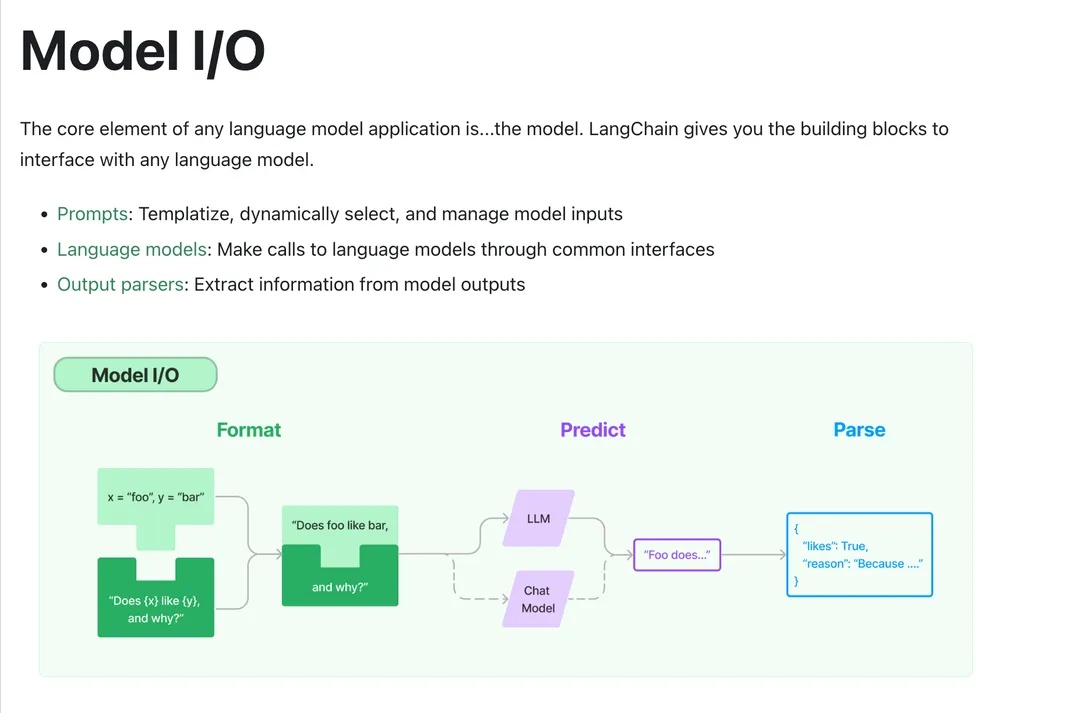
Поскольку нам больше не нужно уделять внимание конкретной реализации каждого шага, при использовании приложения Langchain Model IO основное внимание уделяется построению подсказок. Ниже в основном будут представлены некоторые часто используемые методы быстрого построения в Langchain.
3.1prompt
Langchainдляpromptизоптимизация:основнойдаполон решимости сделать этооптимизациястановитьсяпортативностьвысокийизPrompt,Чтобы лучше поддерживать различные типы LLM,НезачемсуществоватьвыключательModelизменено, когдаPrompt。 Как видно из официальных документов, Prompt в Langchain разделен на две основные категории. Одна из них — Prompt. шаблон, а другой тип — Селекторы.
Шаблон приглашения: на самом деле это легко понять. Он использует интерфейс Langchain для форматирования приглашения в соответствии с шаблоном и выполняет обработку переменных и сочетание слов приглашения.
Селекторы: это означает, что вы можете выбирать разные слова-подсказки в соответствии с разными условиями или выбирать разные примеры с помощью «Селектор» при разных обстоятельствах, чтобы еще больше улучшить возможности поддержки подсказок.
3.1.1 Формат шаблона:
В приглашениях есть два типа форматов шаблонов: один — f-строка, очень распространенный тип приглашения, а другой — jinja2.
f-строка — это функция, представленная в Python 3.6 и более поздних версиях и используемая для вставки значения выражения в строку. Синтаксис краток. Вы можете напрямую заключать переменные или выражения в фигурные скобки {} для выполнения простых операций. Производительность хорошая, но его можно использовать только в py.
#использовать Python f нитьшаблон:
from langchain.prompts import PromptTemplate
fstring_template = """Tell me a {adjective} joke about {content}"""
prompt = PromptTemplate.from_template(fstring_template)
print(prompt.format(adjective="funny", content="chickens"))
# Output: Tell me a funny joke about chickens.
Jinja2 часто используется в веб-разработке и используется в сочетании с такими средами, как Flask и Django. Он поддерживает не только замену переменных, но и другие структуры управления (такие как циклы и условные операторы), а также расширенные функции, такие как настраиваемые фильтры и макросы. Кроме того, он имеет более широкий диапазон использования и может использоваться в различных контекстах. Но в отличие от f-string, использование jinja2 требует установки соответствующей библиотеки.
#использовать jinja2 шаблон:
from langchain.prompts import PromptTemplate
jinja2_template = "Tell me a {{ adjective }} joke about {{ content }}"
prompt = PromptTemplate.from_template(jinja2_template, template_format="jinja2")
print(prompt.format(adjective="funny", content="chickens"))
# Output: Tell me a funny joke about chickens.
Подводя итог: если вам нужна только базовая интерполяция и форматирование строк, предпочтительнее использовать f-строку из-за ее краткого синтаксиса и отсутствия дополнительных зависимостей. Но если вам нужны более сложные функции шаблона (например, циклы, условия, пользовательские фильтры и т. д.), jinja2 подойдет больше.
3.1.1.2Propmpt Template:
Несколько понятий, которые необходимо освоить в этой части шаблона приглашения:
1️⃣Базовый шаблон подсказки:
большинстводанитьили ВОЗда Зависит отОбъект массива, состоящий из разговоров。 При создании приглашения строкового типа необходимо понимать две концепции. Одна из них — input_variables. Атрибут, представляющий переменную, которую необходимо ввести подсказке. Второй — format, который форматирует приглашение через input_variables. Например, используйте PromptTemplate для форматирования.
from langchain.prompts import PromptTemplate #для PromptTemplate Создавайте шаблоны для подсказок.
#По умолчанию, PromptTemplate использовать Python из str.format синтаксис для шаблонов; но можно использовать и другие синтаксисы шаблонов (например,, jinja2 )
prompt_template = PromptTemplate.from_template("Tell me a {adjective} joke about {content}.")
print(prompt_template.format(adjective="funny", content="chickens"))
Вывод выглядит следующим образом (в этом примере для двух входных переменных нужно установить значения смешно и курицы соответственно, а затем использовать формат для присвоения значений соответственно. Если в шаблоне объявлена переменная input_variables, она должна быть назначена при форматировании с использованием формата, в противном случае будет сообщено об ошибке. Если в шаблоне не задан параметр input_variables, он будет проигнорирован автоматически.)
Tell me a funny joke about chickens.
ВерноТип разговораизpromptФорматизкогда,Вы можете использовать ChatPromptTemplate:
#ChatPromptTemplate.from_messages Принимает различные представления сообщений.
template = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
])
messages = template.format_messages(
name="Bob",
user_input="What is your name?"
)
print(messages)
Вывод следующий (как вы можете видеть, ChatPromptTemplate будет выполнять стандартное форматирование каждого предложения в соответствии с ролью. В дополнение к этому методу вы также можете напрямую указать модули идентификации, такие как SystemMessage и HumanMessagePromptTemplate, для форматирования, которые здесь не описываются .)
[('system', 'You are a helpful AI bot. Your name is Bob.'),
('human', 'Hello, how are you doing?'),
('ai', "I'm doing well, thanks!"),
('human', 'What is your name?')]
2️⃣Часть шаблонов слов-подсказок:
Некоторые слова подсказки были инициализированы заранее перед созданием подсказки. При дальнейшем импорте шаблона можно импортировать только инициализированные переменные. Обычно некоторые шаблоны слов приглашения используются в глобальных настройках. В следующем примере значение foo устанавливается в foo перед формальным форматом. Таким образом, вам нужно указать значение bar только при создании окончательного приглашения. Есть два способа указать частичные слова подсказки:
from langchain.prompts import PromptTemplate
prompt = PromptTemplate(template="{foo}{bar}", input_variables=["foo", "bar"])
# Можетиспользовать PromptTemplate.partial() Метод создает частичный шаблон приглашения.
partial_prompt = prompt.partial(foo="foo")
print(partial_prompt.format(bar="baz"))
#также Может Толькоиспользовать Частичная переменнаяинициализациянамекать。
prompt = PromptTemplate(template="{foo}{bar}", input_variables=["bar"], partial_variables={"foo": "foo"})
print(prompt.format(bar="baz"))
Вывод следующий:
foobaz
foobaz
Кроме того, мы также можем вернуть окончательное значение функции как часть приглашения. В следующем примере, если мы хотим отображать текущее время в приглашении в режиме реального времени, мы можем напрямую объявить функцию, возвращающую текущее время. и, наконец, вставьте функцию в приглашение. Перейдите к:
from datetime import datetime
def _get_datetime():
now = datetime.now()
return now.strftime("%m/%d/%Y, %H:%M:%S")
prompt = PromptTemplate(
template="Tell me a {adjective} joke about the day {date}",
input_variables=["adjective", "date"]
)
partial_prompt = prompt.partial(date=_get_datetime)
print(partial_prompt.format(adjective="funny"))
# В дополнение к описанному выше методу объявление частичной функции такое же, как и обычное приглашение, и вы также можете напрямую использовать частичные_переменные для его объявления.
prompt = PromptTemplate(
template="Tell me a {adjective} joke about the day {date}",
input_variables=["adjective"],
partial_variables={"date": _get_datetime})
Вывод следующий:
Tell me a funny joke about the day 12/08/2022, 16:25:30
3️⃣ Сформируйте шаблон слова-подсказки:
Несколько слов подсказки можно объединить вместе с помощью метода PromptTemplate.compose(). В следующем примере создаются Full_prompt и Introduction_prompt для дальнейшей комбинации.
from langchain.prompts.pipeline import PipelinePromptTemplate
from langchain.prompts.prompt import PromptTemplate
full_template = """{introduction}
{example}
"""
full_prompt = PromptTemplate.from_template(full_template)
introduction_template = """You are impersonating Elon Musk."""
introduction_prompt = PromptTemplate.from_template(introduction_template)
example_template = """Here's an example of an interaction """
example_prompt = PromptTemplate.from_template(example_template)
input_prompts = [("introduction", introduction_prompt),
("example", example_prompt),]
pipeline_prompt = PipelinePromptTemplate(final_prompt=full_prompt, pipeline_prompts=input_prompts)
4️⃣Индивидуальный шаблон подсказки:
При создании приглашения мы также можем создать индивидуальный шаблон приглашения в соответствии с нашими потребностями. В официальной документации приведен пример объяснения на английском языке, генерирующего функцию с заданным именем, в которой имя функции принимается в качестве входных данных, а формат приглашения устанавливается для предоставления исходного кода функции:
import inspect
# Функция вернет исходный код, учитывая ее имя изфункциииз. Функция проверки — получить исходный код.
def get_source_code(function_name):
# Get the source code of the function
return inspect.getsource(function_name)
# Тестовая функция
def test():
return 1 + 1
from langchain.prompts import StringPromptTemplate
from pydantic import BaseModel, validator
# инициализироватьподсказку
PROMPT = """\
Укажите имя функции и исходный код и дайте соответствующее объяснение функции.
функцияимя: {function_name}
исходный код:
{source_code}
объяснять:
"""
class FunctionExplainerPromptTemplate(StringPromptTemplate, BaseModel):
"""Настраиваемый шаблон приглашения, который принимает имя функции в качестве входных данных и форматирует шаблон приглашения для предоставления исходного кода функции. """
@validator("input_variables")
def validate_input_variables(cls, v):
"""Проверьте правильность входной переменной да."""
if len(v) != 1 or "function_name" not in v:
raise ValueError("Имя функции должно быть уникальным среди входной переменной.")
return v
def format(self, **kwargs) -> str:
# Получить исходный код
source_code = get_source_code(kwargs["function_name"])
# Исходный код + имя, указанное в подсказке
prompt = PROMPT.format(
function_name=kwargs["function_name"].__name__, source_code=source_code)
return prompt
def _prompt_type(self):
return "function-explainer"
FunctionExplainerPromptTemplate получает две переменные: одна — приглашение, а другая — модель, которую необходимо передать. validate_input_variables в этом классе используются для проверки входных данных, а функция форматирования используется для вывода форматированного приглашения.
#инициализацияpromptПример
fn_explainer = FunctionExplainerPromptTemplate(input_variables=["function_name"])
# определениефункция test_add
def test_add():
return 1 + 1
# Generate a prompt for the function "test_add"
prompt_1 = fn_explainer.format(function_name=test_add)
print(prompt_1)
Вывод следующий:

5️⃣Несколько шаблонов-подсказок:
При создании подсказки вы можете дополнительно отформатировать ее, создав небольшой список примеров. Каждая таблица примеров структурирована как словарь, где ключом является входная переменная, а значением является значение входной переменной. Этот процесс обычно использует PromptTemplate для форматирования примера в строку, а затем создает объект FewShotPromptTemplate для получения примера с несколькими кадрами. Пример из официальной документации:
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
examples = [
{"question": "Who lived longer, Muhammad Ali or Alan Turing?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: How old was Muhammad Ali when he died?
Intermediate answer: Muhammad Ali was 74 years old when he died.
Follow up: How old was Alan Turing when he died?
Intermediate answer: Alan Turing was 41 years old when he died.
So the final answer is: Muhammad Ali
"""},
{"question": "When was the founder of craigslist born?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who was the founder of craigslist?
Intermediate answer: Craigslist was founded by Craig Newmark.
Follow up: When was Craig Newmark born?
Intermediate answer: Craig Newmark was born on December 6, 1952.
So the final answer is: December 6, 1952
"""},
{"question": "Who was the maternal grandfather of George Washington?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who was the mother of George Washington?
Intermediate answer: The mother of George Washington was Mary Ball Washington.
Follow up: Who was the father of Mary Ball Washington?
Intermediate answer: The father of Mary Ball Washington was Joseph Ball.
So the final answer is: Joseph Ball
"""},
{"question": "Are both the directors of Jaws and Casino Royale from the same country?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who is the director of Jaws?
Intermediate Answer: The director of Jaws is Steven Spielberg.
Follow up: Where is Steven Spielberg from?
Intermediate Answer: The United States.
Follow up: Who is the director of Casino Royale?
Intermediate Answer: The director of Casino Royale is Martin Campbell.
Follow up: Where is Martin Campbell from?
Intermediate Answer: New Zealand.
So the final answer is: No
"""}
]
# Настройте форматтер, который будет форматировать подсказку как нить. Этот форматтер должен быть PromptTemplate объект.
example_prompt = PromptTemplate(input_variables=["question", "answer"], template="Question: {question}\n{answer}")
print(example_prompt.format(**examples[0]))
# Создайте селектор для выбора наиболее похожих примеров
example_selector = SemanticSimilarityExampleSelector(
examples=examples,
vector_store=Chroma(),
embeddings_model=OpenAIEmbeddings(),
example_prompt=example_prompt
)
# Наконец, используйте FewShotPromptTemplate. создать шаблон слова-подсказки, который принимает входную переменную в качестве входных данных и форматирует ее так, чтобы она содержала пример слова-подсказки.
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
suffix="Question: {input}",
input_variables=["input"]
)
print(prompt)
В дополнение к вышеупомянутым обычным строковым шаблонам этот метод также можно использовать в шаблонах чата для создания шаблона слова-подсказки чата с примерами:
from langchain.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate
# Это шаблон слова подсказки чата, который принимает входные переменные в качестве входных данных и форматирует их так, чтобы они содержали примеры слов подсказки.
examples = [{"input": "2+2", "output": "4"}, {"input": "2+3", "output": "5"},]
# Подскажите текстовый шаблон для оформления каждого отдельного примера.
example_prompt = ChatPromptTemplate.from_messages(
[("human", "{input}"),
("ai", "{output}"),])
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples)
print(few_shot_prompt.format())

6️⃣Независимая подсказка:
Чтобы облегчить совместное использование, хранение и расширенный контроль версий подсказок, вы можете сохранить формат, поддерживаемый подсказками, которые вы хотите установить, в виде файла формата JSON или YAML. Вы также можете напрямую сохранить приглашение для форматирования в отдельном файле и указать соответствующий путь в файле форматирования, чтобы пользователям было проще загружать информацию о приглашениях любого типа.
Создайте файл JSON:
{
"_type": "prompt",
"input_variables": ["adjective", "content"],
"template": "Tell me a {adjective} joke about {content}."
}
Основной код файла:
from langchain.prompts import load_prompt
prompt = load_prompt("./simple_prompt.json")
print(prompt.format(adjective="funny", content="chickens"))
Вывод следующий:
Tell me a funny joke about chickens.
Здесь оператор шаблона указывается непосредственно в файле json. Кроме того, шаблон также можно извлечь отдельно, а затем в файле json указывается путь к файлу, в котором находится оператор шаблона, для достижения лучшей регионализации и облегчения управления подсказками. .
Создайте файл JSON:
{
"_type": "prompt",
"input_variables": ["adjective", "content"],
"template_path": "./simple_template.txt"
}
simple_template.txt:
Tell me a {adjective} joke about {content}.
Остальная часть кода такая же, как и в первой части, и окончательный результат вывода тоже такой же.
3.1.1.3Selector:
В модуле с несколькими кадрами, когда мы перечисляем серию значений примера без дальнейшего указания возвращаемого значения, будут возвращены все примеры подсказок. В реальной разработке мы можем использовать собственный селектор для выбора примеров. Например, если вы хотите вернуть приглашение, наиболее похожее на вновь введенное содержимое, вы можете выбрать пример, наиболее похожий на входные данные. Основная логика здесь заключается в использовании примера селектора SemanticSimilarityExampleSelector и вычисления сходства векторов (openAIEmbeddings), а также в использовании цветности для хранения данных. Код выглядит следующим образом:
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
example_selector = SemanticSimilarityExampleSelector.from_examples(
# Необязательный список примеров.
examples,
# Используется для создания внедрений из классов внедрения, которые используются для измерения семантического сходства.
OpenAIEmbeddings(),
# Для встраивания базы данных и проведения поиска по сходствуиз VectorStore добрый.
Chroma,
# Количество примеров, которые необходимо создать.
k=1)
Затем мы вводим подсказку, которую хотим построить, просматриваем весь список примеров и находим наиболее подходящий пример.
# Выберите пример, наиболее похожий на входные данные.
question = "Who was the father of Mary Ball Washington?"
selected_examples = example_selector.select_examples({"question": question})
print(f"Examples most similar to the input: {question}")
for example in selected_examples:
print("\n")
for k, v in example.items():
print(f"{k}: {v}")

На этом этапе можно вернуться к наиболее похожему примеру. Далее мы можем повторить несколько шагов и использовать FewShotPromptTemplate для создания шаблона слова-подсказки.
Мы также можем использовать пример селектора для форматирования приглашения типа чата «Несколько снимков»:
examples = [
{"input": "2+2", "output": "4"},
{"input": "2+3", "output": "5"},
{"input": "2+4", "output": "6"},
{"input": "What did the cow say to the moon?", "output": "nothing at all"},
{
"input": "Write me a poem about the moon",
"output": "One for the moon, and one for me, who are we to talk about the moon?",
},
]
# Зависит отнамиспользоватьвекторхранилище Приходитьв соответствии с Пример выбора семантического сходства,Итак, нам нужно сначала заполнитьхранилище。
to_vectorize = [" ".join(example.values()) for example in examples]
# Здесь это просто понимается как извлечение соответствующего значения value и его форматирование.
# После создания векторной библиотеки вы можете создать example_selector Возвращает количество непохожих векторов, выраженных в
# ПРИМЕЧАНИЕ. Сначала вам необходимо создать библиотеку векторной памяти (например: Vectorstore = ...) и заполните его, а затем передайте SemanticSimilarityExampleSelector。
example_selector = SemanticSimilarityExampleSelector(vectorstore=vectorstore, k=2)
# Шаблон слова подсказки будет создан путем передачи входных данных в `select_examples` Способ загрузки примера
example_selector.select_examples({"input": "horse"})

На этом этапе можно вернуться к двум наиболее похожим примерам. Далее мы можем повторить шаги нескольких шагов и использовать FewShotChatPromptTemplate для создания шаблона слова-подсказки.
Выше описаны часто используемые способы создания подсказок при использовании Langchain для разработки приложений. Независимо от того, каким способом, конечная цель — сделать подсказки более удобными и максимально повысить возможность их повторного использования. Инструменты для работы с подсказками, предоставляемые Langchain, намного шире, чем перечисленные выше. После понимания основных возможностей вы можете дополнительно обратиться к официальной документации, чтобы найти инструмент, который лучше всего соответствует характеристикам проекта, и отформатировать подсказку.
3.1.2LLM
В дополнение к упомянутому выше подсказке, LLM является основным содержанием langchain, на понимание и изучение которого нам нужно потратить время. Но опять же, разработка прикладного уровня на самом деле не требует глубокого понимания основных принципов модели. Мы должны скорее сосредоточиться на вызывающей форме фильма, Langc. В качестве «инструмента» Hain не предоставляет собственный LLM, но предоставляет интерфейс для взаимодействия со многими различными типами LLM, такими как знакомый openai,huggingface или cohere и т. д., которые можно быстро вызвать через langchain.
1. Одиночный вызов: напрямую вызовите объект модели, передайте строку и затем напрямую верните выходное значение. В качестве примера возьмем openAI:
from langchain.llms import OpenAI
llm = OpenAI()
print(llm('Кто ты?'))
2. Пакетный вызов: Generate можно использовать для пакетного применения модели к списку строк, что делает вывод более богатым и полным.
llm_result = llm.generate(["Прочитай мне древнее стихотворение", «Расскажи мне историю из 100 слов»]*10)
В это время llm_result сгенерирует массив с ключом «поколения». Длина этого массива — 20 элементов. Первый элемент — древняя поэзия, второй элемент — история, а третий элемент — древняя поэзия. правило..
3. Асинхронный интерфейс. Библиотека asyncio обеспечивает асинхронную поддержку LLM. В настоящее время поддерживаются следующие LLM: OpenAI, PromptLayerOpenAI, ChatOpenAI, Anthropic и Cohere. OpenAI LLM можно вызывать асинхронно с помощью генератора. При написании кода, если вы используете научный Интернет/Magic, взяв в качестве примера openAI, вам необходимо установить прокси-сервер openai в качестве локального прокси перед выполнением асинхронных вызовов (этот шаг очень важен, если не установить, позже произойдет ошибка)
import os
import openai
import asyncio
from langchain.llms import OpenAI
# Установить прокси
openai.proxy = os.getenv('https_proxy')
# определение Синхронный способ генерации текста изфункции
def generate_serially():
llm = OpenAI(temperature=0.9) # Создайте объект OpenAI и установите параметр температуры равным 0,9.
for _ in range(10): # Повторите 10 раз.
resp = llm.generate(["Hello, how are you?"]) # Вызовите метод генерации для генерации текста
print(resp.generations[0][0].text) # Распечатать сгенерированный текст
# определение асинхронно генерируемой текстовой функции
async def async_generate(llm):
resp = await llm.agenerate(["Hello, how are you?"]) # асинхронный Метод callagegenerate генерирует текст
print(resp.generations[0][0].text) # Распечатать сгенерированный текст
# определение. Параллельный (асинхронный) способ генерации текста.
async def generate_concurrently():
llm = OpenAI(temperature=0.9) # Создайте объект OpenAI и установите параметр температуры равным 0,9.
tasks = [async_generate(llm) for _ in range(10)] # Создайте 10 асинхронных задач.
await asyncio.gather(*tasks) # использовать asyncio.gather ожидает завершения всех асинхронных задач
Вы можете использовать библиотеку времени, чтобы проверить время работы. Синхронный вызов занимает около 12 секунд, а асинхронный вызов — всего 2 секунды. Таким образом, выполнение задачи может быть значительно ускорено.
4. Настраиваемая модель большого языка. Если в процессе разработки вам нужно вызывать разные LLM, вы можете повысить эффективность, настроив LLM. При настройке LLM необходимо реализовать метод _call, который принимает строку, некоторые необязательные индексные слова и, наконец, возвращает строку. В дополнение к этому методу вы также можете дополнительно сгенерировать некоторые методы для возврата атрибутов пользовательского класса LLM в режиме словаря.
from langchain.callbacks.manager import CallbackManagerForLLMRun
from langchain.llms.base import LLM
from typing import Optional, List, Any, Mapping
class CustomLLM(LLM): # этот класс CustomLLM унаследованный LLM class и добавил новую переменную класса n。
n: int # Переменная класса, представляющая целое число
@property
def _llm_type(self) -> str:
return "custom"
def _call(
self,
prompt: str, # Войти из подсказки
stop: Optional[List[str]] = None, # Необязательный список остановки, по умолчанию: None
run_manager: Optional[CallbackManagerForLLMRun] = None, # Дополнительный менеджер обратных вызовов, по умолчанию None
**kwargs: Any,
) -> str:
# если stop Параметр не Нет, тогда кидайте ValueError аномальный
if stop is not None:
raise ValueError("stop kwargs are not permitted.")
return prompt[: self.n] # возвращаться prompt нитьизвперед n персонажи
@property # Декоратор недвижимости для получения _identifying_params изценить def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters.""" # Этот метод из документа объясняет, что этот метод из функции получает идентификационный параметр.
return {"n": self.n} # возвращатьсяодинсловарь,Включать n изценить5. Тестирование больших языковых моделей. Чтобы сэкономить наши затраты, при написании строки кода для тестирования мы обычно не хотим фактически вызывать LLM, потому что это будет потреблять токены (работники не могут себе этого позволить). предоставляет нам «поддельную» большую языковую модель для облегчения тестирования.
# Из langchain.llms.fakeимпорт Класс модуляFakeListLLM, этот класс можно использовать для имитации определенного поведения поддельных
from langchain.llms.fake import FakeListLLM
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
# Вызовите функцию load_tools, чтобы загрузить инструмент «python_repl».
tools = load_tools(["python_repl"])
# Определение: список ответов, которые могут имитировать LLM из ожидаемых ответов.
responses = ["Action: Python REPL\nAction Input: print(2 + 2)", "Final Answer: 4"]
# использоватьвышеопределениеизresponsesинициализацияодинFakeListLLMобъект
llm = FakeListLLM(responses=responses)
# вызовinitialize_agentфункция,использоватьвышеизtoolsиllm,и укажитеизактерское мастерствотипиverboseпараметр Приходитьинициализацияодинактерское мастерство
agent = initialize_agent(
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
# Вызовите метод isrun агента, передав ему Whats 2 + 2" в качестве входных данных, спросите у агента 2 плюс 2из результата
agent.run("whats 2 + 2")
Так же, как и при моделировании llm, langchain также предоставляет псевдокласс для имитации человеческих ответов. Эта функция опирается на Википедию, поэтому перед симуляцией вам необходимо установить эту библиотеку и настроить прокси. Здесь fakellm должен полагаться на три класса агентов. Кроме того, он также использует следующие библиотеки:
# С сайта langchain.llms.humanимпорт Класс модуляHumanInputLLM, этот класс может позволять человеческому вводу или взаимодействию для имитации поведения LLM.
from langchain.llms.human import HumanInputLLM
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
# Вызовите функцию load_tools, загрузите название «википедии»-инструмента.
tools = load_tools(["wikipedia"])
# Инициализируйте объект HumanInputLLM, в котором функция Prompt_funcдаафункция используется для печати информации подсказки.
llm = HumanInputLLM(
prompt_func=lambda prompt: print(f"\n===PROMPT====\n{prompt}\n=====END OF PROMPT======"))
# вызовinitialize_agentфункция,использоватьвышеизtoolsиllm,и укажитеизактерское мастерствотипиverboseпараметр Приходитьинициализацияодинактерское мастерство
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
# Вызовите метод isrun агента, передав нить"What is 'Bocchi the Рок!""В качестве входных данных спросите агента о "Бокки". the Rock!'из Информация
agent.run("What is 'Bocchi the Rock!'?")
6. Кэширование больших языковых моделей. Кэширование больших языковых моделей дает тот же эффект, что и тестирование больших языковых моделей. Уровень кэширования может максимально сократить количество вызовов API, тем самым сокращая затраты. Есть две ситуации для установки кеша в Langchain: одна — установка кеша в памяти, а другая — установка кеша в данных. Хранилище в памяти загружается быстрее, но занимает ресурсы и больше не кэшируется после выключения. Пример настройки кэша в памяти следующий:
from langchain.cache import SQLiteCache
import langchain
from langchain.llms import OpenAI
import time
langchain.llm_cache = SQLiteCache(database_path=".langchain.db")
llm = OpenAI(model_name="text-davinci-002", n=2, best_of=2)
start_time = time.time() # Время начала записи
print(llm.predict("Расскажи анекдот по-китайски"))
end_time = time.time() # Время окончания записи
elapsed_time = end_time - start_time # Рассчитать общее время
print(f"Predict method took {elapsed_time:.4f} seconds to execute.")
Время здесь занимает около 1 с+. Поскольку проблема помещается в память, при следующем вызове время почти не будет потрачено.
Помимо хранения в памяти для кэширования, он также может храниться в базе данных для кэширования. При разработке приложений уровня предприятия обычно выбирается хранение в базе данных. Однако скорость загрузки этого метода ниже, чем при хранении в кэше. в памяти Некоторые, но преимущество в том, что они не занимают ресурсы компьютера и сохраненные записи не исчезнут при выключении компьютера.
from langchain.cache import SQLiteCache
import langchain
from langchain.llms import OpenAI
import time
langchain.llm_cache = SQLiteCache(database_path=".langchain.db")
llm = OpenAI(model_name="text-davinci-002", n=2, best_of=2)
start_time = time.time() # Время начала записи
print(llm.predict("Расскажи анекдот по-китайски"))
end_time = time.time() # Время окончания записи
elapsed_time = end_time - start_time # Рассчитать общее время
print(f"Predict method took {elapsed_time:.4f} seconds to execute.")
7. Отслеживать использование токенов (только если модель openAI):
from langchain.llms import OpenAI
from langchain.callbacks import get_openai_callback
llm = OpenAI(model_name="text-davinci-002", n=2, best_of=2, cache=None)
with get_openai_callback() as cb:
result = llm("рассказать анекдот")
print(cb)
Приведенный выше код напрямую использует get_openai_callback для записи токена для одного вопроса. Кроме того, для цепочки или агента с несколькими шагами langchain также может отслеживать токены, использованные на каждом этапе.
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.llms import OpenAI
from langchain.callbacks import get_openai_callback
llm = OpenAI(temperature=0)
tools = load_tools(["llm-math"], llm=llm)
agent = initialize_agent(
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
with get_openai_callback() as cb:
response = Agent.run("Сколько лет Фэй Вонг сейчас?")
print(f"Total Tokens: {cb.total_tokens}")
print(f"Prompt Tokens: {cb.prompt_tokens}")
print(f"Completion Tokens: {cb.completion_tokens}")
print(f"Total Cost (USD): ${cb.total_cost}")
8. Сериализованная конфигурация больших языковых моделей: Langchain также предоставляет возможность сохранять различные коэффициенты, используемые LLM во время обучения, такие как шаблон, имя_модели и т. д. Такие коэффициенты обычно сохраняются в файлах json или yaml. Взяв в качестве примера файл json, настройте следующие коэффициенты, а затем используйте метод load_llm для импорта:
from langchain.llms.loading import load_llm
llm = load_llm("llm.json")
{
"model_name": "text-davinci-003",
"temperature": 0.7,
"max_tokens": 256,
"top_p": 1.0,
"frequency_penalty": 0.0,
"presence_penalty": 0.0,
"n": 1,
"best_of": 1,
"request_timeout": None,
"_type": "openai"
}
Или после настройки параметров большой модели вы можете напрямую использовать метод сохранения, чтобы сохранить конфигурацию непосредственно в указанный файл.
llm.save("llmsave.json")
9. Потоковая передача ответа модели большого языка. Потоковая передача означает, что обработка начинается сразу после получения первого фрагмента данных, не дожидаясь передачи всего пакета данных. Когда эта концепция применяется в LLM, ответ может быть немедленно отображен пользователю при его генерировании или ответ может быть обработан при генерировании ответа, что является эффектом дословного вывода, который мы видим сейчас при разговоре с ИИ: Как видите, это удобнее реализовать. Вам нужно только напрямую вызвать StreamingStdOutCallbackHandler в качестве обратного вызова.
from langchain.llms import OpenAI
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
llm = OpenAI(streaming=True, callbacks=[StreamingStdOutCallbackHandler()], temperature=0)
resp = llm("Write me a song about sparkling water.")
Видно, что реализация более удобна. Вам нужно только напрямую вызвать StreamingStdOutCallbackHandler в качестве обратного вызова.
3.1.3OutputParsers
Содержимое, возвращаемое моделью, обычно представляет собой строковый шаблон, но в реальном процессе разработки часто надеются, что модель сможет возвращать более интуитивно понятный контент, и синтаксический анализатор вывода, предоставляемый Langchain, пригодится. В процессе реализации синтаксического анализатора вывода необходимо реализовать два метода: 1️⃣ Получить инструкции по форматированию: метод, который возвращает строку, содержащую инструкции о том, как форматировать выходные данные языковой модели. 2️⃣Parse: метод, который получает строку (при условии, что это ответ от языковой модели) и анализирует ее в некоторую структуру.
1. Анализатор списков. Используйте этот анализатор для вывода списка, разделенного запятыми.
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
output_parser = CommaSeparatedListOutputParser()
format_instructions = output_parser.get_format_instructions()
prompt = PromptTemplate(
template="List five {subject}.\n{format_instructions}",
input_variables=["subject"],
partial_variables={"format_instructions": format_instructions}
)
model = OpenAI(temperature=0)
_input = Prompt.format(subject="вкус мороженого")
output = model(_input)
output_parser.parse(output)
2. Анализатор даты. Этот анализатор можно использовать для непосредственного анализа выходных данных LLM в формате даты и времени.
from langchain.prompts import PromptTemplate
from langchain.output_parsers import DatetimeOutputParser
from langchain.chains import LLMChain
from langchain.llms import OpenAI
output_parser = DatetimeOutputParser()
template = """Ответ на вопрос пользователя:
{question}
{format_instructions}"""
prompt = PromptTemplate.from_template(
template,
partial_variables={"format_instructions": output_parser.get_format_instructions()},
)
chain = LLMChain(prompt=prompt, llm=OpenAI())
output = Chain.run("Когда был создан биткойн? Выведите время в английском формате")
3. Анализатор перечисления
from langchain.output_parsers.enum import EnumOutputParser
from enum import Enum
class Colors(Enum):
RED = "red"
GREEN = "green"
BLUE = "blue"
parser = EnumOutputParser(enum=Colors)
4. Анализатор автоматического восстановления. Этот тип анализатора представляет собой вложенную форму. Если в первом выходном анализаторе возникает ошибка, для исправления ошибки будет напрямую вызван другой.
# Импортируйте необходимые библиотеки и модули.
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field, validator
from typing import List
# Определение Структура, представляющая изданных актеров, включая их имена, из списка фильмов, в которых они появлялись, из
class Actor(BaseModel):
name: str = Field(description="name of an actor") # Имя актера
film_names: List[str] = Field(description="list of names of films they starred in") # Список фильмов, в которых они снимались
# определение Запрос для создания списка случайных актеров и титров фильмов.
actor_query = "Generate the filmography for a random actor."
# использовать`Actor`Модельинициализацияпарсер
parser = PydanticOutputParser(pydantic_object=Actor)
# определение ошибки формата изнитданные
misformatted = "{'name': 'Tom Hanks', 'film_names': ['Forrest Gump']}"
# использовать парсер пытается проанализировать вышеуказанные данные
try:
parsed_data = parser.parse(misformatted)
except Exception as e:
print(f"Error: {e}")
parser.parse(misformatted)
Причина ошибки формата заключается в том, что для обозначения файла json нужны двойные кавычки, но здесь используются одинарные кавычки. В этот момент при анализе этим парсером появится ошибка. Однако вы можете использовать RetryWithErrorOutputParser, чтобы исправить ошибку. и нормальный вывод не сообщит об ошибке.
from langchain.output_parsers import RetryWithErrorOutputParser
from langchain.llms import OpenAI
retry_parser = RetryWithErrorOutputParser.from_llm(
parser=parser, llm=OpenAI(temperature=0))
retry_parser.parse_with_prompt(bad_response, prompt_value)
Вот «Parse_with_prompt»: метод, который принимает строку (предполагаемую как ответ от языковой модели) и приглашение (предполагаемое как приглашение, сгенерировавшее такой ответ) и анализирует ее в некоторую структуру. Подсказки в основном предоставляются, когда OutputParser хочет каким-либо образом повторить или исправить выходные данные, и для этого необходима информация из подсказки.
4. Поиск
«Поиск» напрямую переводится на китайский язык как «извлечение». Эта функция часто используется для создания «частной базы знаний». Процесс создания больше связан с сохранением внешних данных в базе знаний. Основные функции этого модуля разделены на четыре части, включая сбор, сортировку, хранение и запрос данных. Как показано ниже:
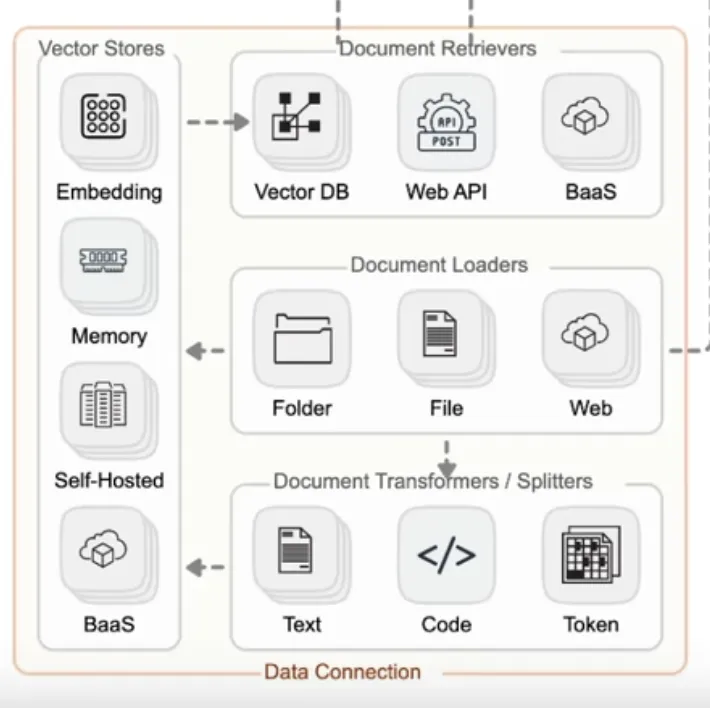
Прежде всего, в этом процессе данные могут быть получены из локальных/веб-сайтов/файловых и других библиотек ресурсов. Когда объем данных небольшой, мы можем хранить его напрямую, но когда объем данных большой, это необходимо. нарезка в определенной степени. При нарезке нарезка может выполняться по типу данных. Например, текстовые данные могут быть нарезаны непосредственно по символам и абзацам, а данные кода необходимо дополнительно подразделить, чтобы обеспечить функциональность. код кроме того, помимо нарезки по типу данных, или можно нарезать непосредственно на основе токена; Затем используйте хранилища векторов для хранения векторов, где внедрение завершает векторизацию данных. Хотя эта возможность часто вложена в большие модели, мы также должны помнить, что не все модели могут напрямую поддерживать возможность векторизации текста. Кроме того, память, самостоятельное размещение и baas относятся к трем формам векторного хранения. Вы можете хранить его непосредственно в памяти или в облаке. Наконец, эти векторизованные данные используются для поиска. Форма поиска может быть предназначена для прямого сопоставления аналогичного контента в соответствии с векторным сходством, или она может быть напрямую подключена к сети, или для достижения поиска и возврата данных могут использоваться другие службы.
4.1 База данных векторов
4.1.1Основные понятия
Из вышесказанного мы видим, что векторная база данных играет большую роль для ретриверов. Она не только реализует хранение векторов, но и реализует поиск векторов по сходству. Но что такое векторная база данных? Чем она отличается от обычной базы данных? Я считаю, что многие студенты, как и я, все еще немного сомневаются, поэтому, прежде чем представить возможности langchain в этом модуле, я сначала представлю векторную базу данных и ее роль в LLM.
Когда мы описываем вещь, мы обычно описываем ее, основываясь на ее различных характеристиках. Представьте себе сценарий, в котором вы фотограф и делаете много фотографий. Для облегчения управления и поиска вы решаете сохранить эти фотографии в базе данных. Традиционные реляционные базы данных (такие как MySQL, PostgreSQL и т. д.) могут помочь вам хранить метаданные фотографий, такие как время съемки, местоположение, модель камеры и т. д. Однако если вы хотите выполнить поиск по содержимому фотографий (например, по цвету, текстуре, объектам и т. д.), традиционные базы данных могут не соответствовать вашим потребностям, поскольку они обычно хранят данные в виде таблиц данных и используют операторы запроса для точного поиска. поиски. Но векторы содержат много информации, и с помощью операторов запроса сложно точно найти уникальные векторы.
Тогда в это время,Библиотека векторных данных пригодится. Мы можем построить многомерное пространство так, чтобы каждый объект фотографии существовал в этом пространстве.,И используйте существующие размеры для представления,Такие как время, местоположение, модель камеры, цвет... Эта фотография из информации будет использоваться как точка,хранить в нем. и так далее,В этом пространстве можно построить бесчисленное количество точек.,Затем соединяем эти точки с началом оси пространственных координат из,Он становится вектором,После того как эти точки станут векторами,Вы можете использовать векторный расчет для получения дополнительной информации. Если вы хотите выполнить поиск фотографий,Это также станет проще и быстрее. Но при поиске в библиотеке векторных данных,Поиск не даетдатолькоизида Запроси Цельвекторсамый похожийизНекоторыйвектор,Имеет двусмысленность.
Тогда мы сможем расширить наше мышление. Пока мы векторизуем изображения, видео, продукты и другие материалы, мы можем реализовать такие функции, как поиск изображений, рекомендации по видео, рекомендации по аналогичным продуктам и т. д. При применении в LLM соответствующие функции могут быть следующими: реализовано напрямую. Подсказка к вопросу: мы можем использовать эту функцию, чтобы найти некоторые из наиболее похожих разговоров в исторических записях разговоров, а затем повторно передать их в большую модель. Это значительно повысит точность выходных результатов большой модели. Чтобы лучше понять базу данных векторов, мы продолжим знакомить с несколькими методами поиска векторов, чтобы глубже понять базу данных векторов.
4.1.2 Способ хранения
Поскольку каждый вектор записывает относительно большой объем информации, он, естественно, занимает большой объем памяти. Например, если одно из измерений нашего вектора имеет размер 256, то размер памяти, занимаемый вектором, составит: 256*32/8=1024. байты, если Всего в базе данных 10 миллионов векторов, а занимаемая память составляет 10240000000 байт, что составляет 9,54 ГБ, что уже является очень большим числом. В реальной разработке этот масштаб часто больше, поэтому занятость памяти вектором. база данных решена. Проблема находится в центре внимания. Мы склонны сжимать каждый вектор, чтобы уменьшить его объем памяти. Часто используется метод количественного определения продукта.
Квантование продукта. Эта идея разлагает многомерный вектор на несколько подвекторов. Например, разложите D-мерный вектор на m субвекторов, и размерность каждого субвектора равна D/m. Затем каждый подвектор квантуется. Для каждого субвекторного пространства используется алгоритм кластеризации для разделения субвекторов на K кластеров, а центры кластеров используются как квантованные значения. Затем исходный подвектор представляется своим индексом в кластере. Таким образом, каждый подвектор может быть представлен целым числом (индексом квантования). Наконец, квантованные индексы объединяются для представления исходных многомерных векторов. Для D-мерного вектора он может быть представлен m целыми числами, где каждое целое число соответствует индексу квантования подвектора. Кроме того, этот тип метода можно использовать не только для оптимизации векторов хранения, но и для оптимизации поиска.
4.1.3 Метод поиска
Благодаря описанию в предыдущем абзаце нетрудно обнаружить, что процесс поиска вектора можно абстрагировать до «задачи ближайшего соседа», а соответствующий алгоритм представляет собой алгоритм поиска ближайшего соседа, который, в частности, включает в себя следующее:
1. Насильственный поиск: сравнивать сходство всех векторов в базе данных векторов с целевым вектором поочередно, а затем находить один или несколько векторов с наибольшим сходством. Качество результатов, полученных таким способом, чрезвычайно высокое, но это. не подходит для баз данных с огромными объемами данных. Это, несомненно, требует очень много времени.
2. Поиск по кластерам. Этот тип алгоритма сначала инициализирует K центров кластеров и группирует объекты данных в несколько категорий или кластеров. Его основная цель — группировать данные на основе их меры сходства или расстояния, а затем обновлять результаты кластеризации посредством итеративных вычислений на основе выбранного алгоритма кластеризации. Например, в алгоритме K-средних центры кластеров необходимо постоянно обновлять, а объекты данных назначать ближайшим центрам кластеров, в алгоритме DBSCAN кластеры необходимо расширять, а соседние кластеры объединять на основе достижимости плотности; Наконец, задается условие сходимости, позволяющее определить, завершен ли процесс кластеризации. Условием сходимости может быть количество итераций, амплитуда изменения центра кластера и т.д. Процесс кластеризации заканчивается, когда выполняются условия сходимости. Такая эффективность поиска значительно повышается, но неизбежно возникают пропуски.
3. Хэширование с учетом позиции. Этот алгоритм сначала выбирает набор хеш-функций, чувствительных к положению, которые должны удовлетворять одной характеристике: для схожих точек данных их хеш-значения имеют более высокую вероятность столкновения для разнородных точек данных, их хеш-значения имеют более высокую вероятность столкновения; хэш-значения имеют меньшую вероятность коллизии. Затем эта функция используется для хеширования каждой точки данных в наборе данных. Сохраняйте точки данных с одинаковым значением хеш-функции в одном и том же хэш-ведре. В процессе поиска для данной точки запроса ее хеш-значение сначала рассчитывается с помощью функции LSH, а затем аналогичные точки данных ищутся в соответствующем хеш-ведре. Наконец, при необходимости сходство может быть дополнительно рассчитано среди найденных точек данных-кандидатов, чтобы найти ближайшего соседа.
4. Алгоритм иерархической навигации в маленьком мире: это метод приближенного поиска ближайшего соседа на основе графов, подходящий для крупномасштабных наборов многомерных данных. Основная идея состоит в том, чтобы организовать точки данных в виде графа иерархической структуры, чтобы точки-кандидаты, находящиеся ближе к точке запроса, можно было быстро найти на высоком уровне, а затем диапазон поиска постепенно уточняется на низком уровне, тем самым ускоряя поиск. Процесс поиска ближайшего соседа.
Алгоритм сначала создает пустую многослойную графовую структуру. Каждый слой представляет собой граф, где узлы представляют точки данных, а ребра представляют связи между узлами. Самый нижний уровень содержит все точки данных, а верхний график содержит только некоторые точки данных. Каждой точке данных присваивается случайный номер слоя, указывающий, на каких уровнях графика появляется точка. Затем вставьте точки данных: для каждой вновь вставленной точки данных сначала определите количество слоев, а затем, начиная с самого высокого слоя, вставьте точку в соответствующий график. В процессе вставки необходимо найти ближайших соседей точки в каждом слое и соединить их. В то же время связи соединений существующих узлов также необходимо обновить, чтобы сохранить производительность навигации по графу. Процесс поиска заключается в том, чтобы сначала найти начальную точку в графе самого высокого уровня, а затем выполнить поиск вниз, слой за слоем, пока не будет достигнут нижний слой. На каждом уровне, начиная с текущей точки, ищите по ребрам, пока не будет найден ближайший локальный сосед. Затем ближайший локальный сосед используется в качестве отправной точки следующего слоя и поиск продолжается. Наконец, результат, найденный на нижнем уровне, является окончательным результатом.
4.2 База данных векторов и искусственный интеллект
В предыдущей статье было примерно представлено, что такое векторная база данных, и некоторые технологии реализации, на которых основаны векторные базы данных. Далее давайте поговорим о взаимосвязи между векторными базами данных и большими моделями. Почему говорят, что если вы хотите эффективно использовать большие модели, вам часто не обойтись без векторной базы данных? Для больших моделей обрабатываемые форматы данных обычно представляют собой неструктурированные данные, такие как аудио, текст и изображения. В качестве примера возьмем большую языковую модель. При подаче фрагмента данных в большую модель данные сначала преобразуются в. Вектор, из приведенного выше содержания мы знаем, что если вектор ближе, это означает, что информация, содержащаяся в двух векторах, более похожа. Когда в большую модель постоянно подается большой объем данных, языковая модель постепенно обнаруживает. семантика и семантика между словами. Когда пользователь задает вопрос и ответ, после ввода вопроса в модель архитектура Transformer будет использоваться для определения веса связи между каждым словом и другими словами, и будет найдена группа словосочетаний с наибольшим весом. группе будет ответ на вопрос и ответ. Наконец, этот набор векторов возвращается, и вопрос и ответ завершаются. Когда мы подключаем базу данных векторов к ИИ, мы можем обновлять данные в базе данных векторов, чтобы большая модель могла постоянно получать и изучать новейшие знания в отрасли, а не ограничивать свои возможности предварительно обученными данными. Этот подход экономит больше средств, чем точная настройка/переобучение больших моделей.
4.3DataLoaders
Чтобы лучше понять функцию поиска, мы сначала представили основную концепцию, на которой он основан, — базу данных векторов. Далее давайте посмотрим, как поиск работает в Лангкайн. Мы уже знаем, что в приложениях общей разработки пользователей (LLM) часто необходимо использовать конкретные данные, которых нет в наборе обучения модели, для дальнейшего расширения возможностей большой языковой модели. Этот метод называется поисковой дополненной генерацией (RAG). . LangChain предоставляет полный набор инструментов для реализации RAG-приложений. Первым шагом является загрузка документа соответствующим образом, а именно DocumentLoader:
LangChain предоставляет множество загрузчиков документов, которые поддерживают загрузку документов из различных источников (например, из частных хранилищ или общедоступных веб-сайтов). Поддерживаемые типы документов также очень разнообразны: например, файлы HTML, PDF, MarkDown и т. д.
1. Загрузите файл md:
from langchain.document_loaders import TextLoader
# Создайте экземпляр TextLoader и укажите путь к файлу Markdown, который нужно загрузить.
loader = TextLoader("./index.md")
# использовать метод загрузки, загрузить содержимое файла и распечатать
print(loader.load())
2. Загрузите файл csv:
# Импортировать класс CSVLoader
from langchain.document_loaders.csv_loader import CSVLoader
# Создайте экземпляр CSVLoader и укажите путь к CSV-файлу, который нужно загрузить.
loader = CSVLoader(file_path='./index.csv')
# использоватьloadметоднагрузкаданныеи сделай этохранилищесуществоватьданныев переменных
data = loader.load()
3. Настройте анализ и загрузку CSV. Просто укажите имя поля CSV-файла.
from langchain.document_loaders.csv_loader import CSVLoader
# Создайте экземпляр CSVLoader и укажите путь к CSV-файлу, который нужно загрузить.иCSVпараметр
loader = CSVLoader(file_path='./index.csv', csv_args={
'delimiter': ',',
'quotechar': '"',
'fieldnames': ['title', 'content']
})
# использоватьloadметоднагрузкаданныеи сделай этохранилищесуществоватьданныев переменных
data = loader.load()
4. Вы можете использовать параметр source_column, чтобы указать столбец, из которого загружается файл.
from langchain.document_loaders.csv_loader import CSVLoader
# Создайте экземпляр CSVLoader и укажите путь к CSV-файлу, который нужно загрузить.иисходный столбецимя
loader = CSVLoader(file_path='./index.csv', source_column="context")
# использоватьloadметоднагрузкаданныеи сделай этохранилищесуществоватьданныев переменных
data = loader.load()
В дополнение к указанной выше загрузке одного файла мы также можем загрузить все файлы в папке в пакетном режиме. Эта загрузка зависит от неструктурированности, поэтому перед запуском вам необходимо выполнить pip. Чтобы загрузить файл md: pip install «unstructured[md]»
# Импортировать класс DirectoryLoader
from langchain.document_loaders import DirectoryLoader
# создаватьDirectoryLoaderПример,Укажите путь к папке для загрузки и тип файла, используйте многопоточность.
loader = DirectoryLoader('/Users/kyoku/Desktop/LLM/documentstore', glob='**/*.md', use_multithreading=True)
# использоватьloadметоднагрузка Все документыи сделай этохранилищесуществоватьdocsв переменных
docs = loader.load()
# Распечатать количество загруженных документов
print(len(docs))
# Импортируйте класс UnstructuredHTMLLoader.
from langchain.document_loaders import UnstructuredHTMLLoader
# Создайте экземпляр UnstructuredHTMLLoader и укажите путь к загружаемому HTML-файлу.
loader = UnstructuredHTMLLoader("./index.html")
# использоватьloadметоднагрузкаHTMLдокументсодержаниеи сделай этохранилищесуществоватьdataв переменных
data = loader.load()
# Импортировать класс BHTMLLoader.
from langchain.document_loaders import BSHTMLLoader
# Создайте экземпляр BHTMLLoader и укажите путь к загружаемому HTML-файлу.
loader = BSHTMLLoader("./index.html")
# использоватьloadметоднагрузкаHTMLдокументсодержаниеи сделай этохранилищесуществоватьdataв переменных
data = loader.load()
4.4 Трансформаторы данных для разделения текста
После успешной загрузки содержимого файла с набором данных обычно выполняется ряд операций, которые лучше подходят для вашего приложения. Например, вы можете захотеть разбить длинный документ на более мелкие части, которые лучше вписываются в вашу модель. LangChain предоставляет ряд готовых конвертеров документов, которые позволяют легко разделять, объединять, фильтровать документы и выполнять другие операции.
Хотя описанные выше шаги кажутся относительно простыми, на самом деле существует множество потенциальных сложностей. В лучшем случае соедините связанные фрагменты текста вместе. Эта «релевантность» может варьироваться в зависимости от типа текста.
Langchain предоставляет инструмент RecursiveCharacterTextSplitter для разделения текста. Его принцип работы: сначала попробуйте разделить, используя первый символ, чтобы создать небольшие блоки. Если некоторые фрагменты слишком велики, он пробует следующий символ и так далее. По умолчанию он пытается разделить символы в порядке ["\n\n", "\n", " ", ""]. Ниже приведен пример кода:
# Откройте текстовый файл и прочитайте содержимое
with open('./test.txt') as f:
state_of_the_union = f.read()
# Импортировать класс RecursiveCharacterTextSplitter.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Создайте экземпляр RecursiveCharacterTextSplitter, установите размер блока, перекрытие блоков, длину. Функция: добавлять ли начальный индекс?
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,
length_function=len,
add_start_index=True,
)
# использоватьcreate_documentsметодсоздавать文档и сделай этохранилищесуществоватьtextsв переменных
texts = text_splitter.create_documents([state_of_the_union])

Из вывода видно, что он разделен на массив.
Помимо вышеописанного разделения текста, при построении llm-приложений также часто используется разделение кода:
# Импортируйте необходимые классы и перечисления.
from langchain.text_splitter import RecursiveCharacterTextSplitter, Language
# определение A, содержащее код Python,
PYTHON_CODE = """
def hello_world():
print("Hello, World!")
# Call the function
hello_world()
"""
# использоватьfrom_languageметодсоздаватьодинпротивPythonязыкизRecursiveCharacterTextSplitterПример
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=50, chunk_overlap=0
)
# использоватьcreate_documentsметодсоздавать文档и сделай этохранилищесуществоватьpython_docsв переменных
python_docs = python_splitter.create_documents([PYTHON_CODE])
Вызов определенного сплиттера может обеспечить логику кода после разделения. Здесь нам нужно только указать разные языки, чтобы разделить разные языки.
4.5 Простое применение векторного поиска
В реальной разработке мы можем разделить векторизацию данных на два этапа: первый — это векторизация данных (инструменты векторизации: встраивание openai, n3d отhuggingface...), а другой — сохранение векторизованных данных в векторах. Среди баз данных распространены и Простые в использовании бесплатные векторные базы данных включают Faiss Meta, chromad Chrome и lance.
1. Высокая производительность. Благодаря использованию возможностей параллельных вычислений центрального и графического процессоров достигается эффективное векторное индексирование и операции запроса. 2. Масштабируемость: поддерживает крупномасштабные наборы данных и может решать задачи поиска по сходству и кластеризации миллиардов многомерных векторов. 3. Гибкость: предоставляет различные алгоритмы индексации и поиска, и вы можете выбрать подходящий алгоритм в соответствии с конкретными потребностями. 4. Открытый исходный код: это проект с открытым исходным кодом, его исходный код и подробную документацию можно найти на GitHub.
Установите связанные библиотеки: pip install faiss-cpu (Студенты с хорошими видеокартами также могут установить версию с графическим процессором)
Подготовьте набор данных, содержащий консультационную беседу о взимании ежегодных комиссий по кредитной карте и увеличении лимитов кредитной карты. Клиент спросил в службе поддержки о годовой плате и лимите кредитной карты, и служба поддержки подробно ответила на вопрос клиента:
text = """Клиент: Здравствуйте.,Я хотел бы спросить о проблеме с кредитной картой. \nСлужба поддержки: Здравствуйте.,Добро пожаловать на консультацию по кредитной карте CCB,Я специалист по обслуживанию клиентов Сяо Ли.,Есть ли у вас вопросы, с которыми я могу вам помочь? \nКлиент: Я хотел бы знать, как взимать годовую плату за кредитную карту? \nОбслуживание клиентов: о взимании ежегодных комиссий с кредитной карты,Мы будем взимать годовую комиссию с вашей кредитной карты в фиксированную дату каждый год. конечно,еслитысуществоватьв течение одного годаиз Расход достигает определенной суммы,Ежегодная плата будет автоматически отменена. Конкретные критерии освобождения от ежегодной пошлины,Пожалуйста, ознакомьтесь с условиями договора по кредитной карте и войдите на наш сайт, чтобы проверить. \nКлиент: ОК,Спасибо. Тогда я все еще хочу спросить,Как увеличить лимит кредитной карты? \nОбслуживание клиентов: об увеличении лимита кредитной карты,ты Можетпроходитьнижеспособдействовать:1. Войдите на официальный сайт кредитной карты CCB и в мобильное приложение и подайте онлайн-заявку на увеличение лимита 2. Позвоните на горячую линию службы поддержки клиентов и следуйте голосовым подсказкам, чтобы подать заявку на увеличение квоты 3. тывозвращаться Можетвперед Иди рядомиз Торговые точки CCB,Подать заявку на повышение. После того, как вы отправите заявку,мы будемв соответствии стыиз Проверка кредитного статуса,После прохождения обзора,Лимит вашей кредитной карты будет соответственно увеличен. \nКлиент: Понятно.,Большое спасибо за ваш ответ. \nОбслуживание клиентов: Вы слишком вежливы.,оченьвысокий Син может помочьты。еслитывозвращаться有其他问题,Пожалуйста, не стесняйтесь обращаться к нам。желаниетысчастливая жизнь!"""
list_text = text.split('\n')
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
db = FAISS.from_texts(list_text, OpenAIEmbeddings())
query = «Можно ли увеличить лимит кредитной карты?»
docs = db.similarity_search(query)
print(docs[0].page_content)
embedding_vector = OpenAIEmbeddings().embed_query(query)
print(f'embedding_vector:{embedding_vector}')
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
Помимо упомянутого выше прямого вывода лучших результатов, вы можете также выводить на основе показателя сходства, но здесь действует правило: чем ниже показатель, тем выше сходство.
# использовать поиск по сходству с дробями из
docs_and_scores = db.similarity_search_with_score(query)
# Печать документов и их оценок сходства
for doc, score in docs_and_scores:
print(f"Document: {doc.page_content}\nScore: {score}\n")
Было бы слишком расточительно каждый раз вызывать внедрение, поэтому в конце концов мы также можем сохранить базу данных напрямую, чтобы избежать повторных вызовов.
# держать
db.save_local("faiss_index")
# нагрузка
new_db = FAISS.load_local("faiss_index", OpenAIEmbeddings())
На официальном сайте также представлены два других метода использования векторных баз данных, которые здесь не будут описаны.
5. Память
Память – хранит историческую информацию о разговорах. Эта функция в основном выполняет два шага: 1. При вводе запрашивает соответствующую историческую информацию из компонента памяти, объединяет историческую информацию и ввод пользователя в слово подсказки и передает ее в LLM. 2. Автоматически сохранять содержимое, возвращаемое LLM, в компонент памяти для следующего запроса.
5.1Основной принцип реализации памяти:
Память – хранит историческую информацию о разговорах. Эта функция в основном выполняет два шага:
1. При вводе запросите соответствующую историческую информацию из компонента памяти, объедините историческую информацию и ввод пользователя в слово подсказки и передайте ее в LLM.
2. Автоматически сохранять содержимое, возвращаемое LLM, в компонент памяти для следующего запроса.
но,В настоящее время в GPT есть эта функция.,Он уже может проводить несколько раундов диалога,Зачем нам нужно выносить эту функцию и объяснять ее подробно? Как было сказано в предыдущей статье, введение подсказки: при проведении нескольких раундов диалога,Мы будем постоянно помещать исторический контент разговора в массив подсказок.,Вообще говоря, все записи чата используются в качестве подсказок.,В большом языке Модельиз функция «память» реализована в виде хранилищеиз.,И сама модель большого языка не имеет гражданства.,Этот вид Способ Это, несомненно, будет более расточительно.token,Так что развивайтесь ВОЗнадо сосредоточиться наКак максимально сократить использование токенов, сохранив при этом функциональность большой языковой модели?Memoryэтот компоненттакже Сразуродился。poодин кусочекMemoryОфициальный сайтизкартина:
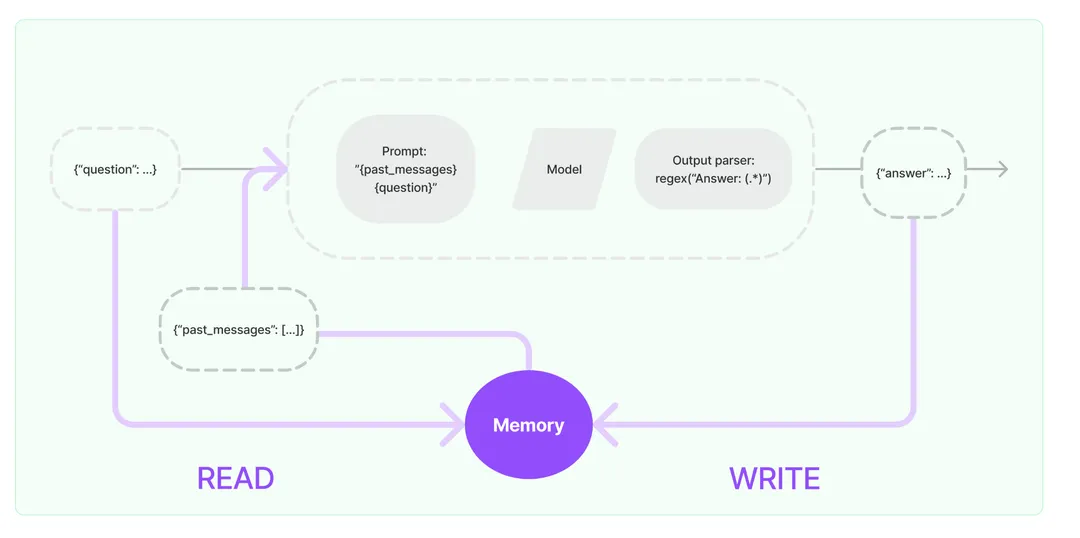
Как видно из рисунка выше, идея реализации памяти довольно проста: нам не нужно долго продумывать процесс хранения. Это не что иное, как сохранение в памяти/базе данных. Процесс чтения по-прежнему достоин нашего обсуждения. Почему мы так говорим? Как мы видели выше, цель памяти — максимально сократить потребление токенов, обеспечивая при этом возможности большой языковой модели. Поэтому мы не можем сбрасывать все данные в большую языковую модель вместе. Это потеряет смысл. память. Не так ли? В настоящее время память часто использует следующие стратегии запросов:
1. Передайте сеанс непосредственно на фон большой модели в виде приглашения, которое можно назвать буфером.
2. Перекиньте в модель все исторические сообщения для создания сводки, а затем используйте сводку в качестве фона подсказки, которую можно назвать сводкой.
3. Используйте упомянутую ранее базу данных векторов для запроса аналогичной исторической информации. В качестве основы ее можно назвать векторной.
5.2Как использовать память:
Использование функции памяти относительно просто. В этом разделе будут представлены некоторые функции памяти, которые часто используются в соответствии с тремя основными категориями памяти.
5.2.1Buffer
1️⃣ConversationBufferMemory
Возьмем пример простейшего метода использования — непосредственное сохранение содержимого в буфере. Независимо от того, сохраняется ли он один или несколько раз, содержимое разговора будет сохранено в памяти:
memory = ConversationBufferMemory() memory.save_context({"input": "Привет, я дахуман"}, {"output": "Привет, я помощник даAI"})memory.save_context({"input": "Рад встрече"}, {"output": "Я тоже да"})
Сохраненный контент можно вывести сразу после сохранения:
print(memory.load_memory_variables({}))
# {'history': 'Human: Привет, я человек\nИИ: Привет, я да ИИ-помощник\nЧеловек: Приятно познакомиться\nAI: Я тоже да'}
2️⃣ConversationBufferWindowMemory
ConversationBufferMemory, несомненно, очень прост и удобен.,Но я могу попытаться представить,Когда мы много разговариваем на большом языке Модель,Использовать буферные хранилища напрямую,Объем занимаемой памяти очень велик.,И потреблять много изтокендаиз,Прошло в это времяConversationBufferWindowMemoryВыполнить кэширование окониз Способ Сразу Может Решите вышеперечисленные проблемы。его основная идея:Сразудабронироватьодинразмер окнаиздиалог,其содержание ТолькоданедавноизNразговоры。существоватьэтотинструментфункциясередина,Вы можете использовать параметр k, чтобы объявить, что память разговора сохраняется.,Например, когда к=1,Результат вывода вышеуказанного диалогового содержимого изменится соответствующим образом:
memory = ConversationBufferWindowMemory(k=1)
memory.save_context({"input": "Привет, я дахуман"}, {"output": "Привет, я помощник даAI"})
memory.save_context({"input": "Рад встрече"}, {"output": "Я тоже да"})
Сохраняются только последние k записей:
print(memory.load_memory_variables({}))
# {'history': 'Human: Приятно познакомиться\nAI: Я тоже да'}
Меомори можно «запомнить» через буферное окно (BufferWindow), встроенное в Langchain.
3️⃣ConversationTokenBufferMemory
Помимо контроля памяти путем установки количества разговоров, вы также можете ограничить ее, установив токены. Если количество символов превышает указанное число, предыдущая часть разговора будет обрезана, чтобы сохранить количество символов, соответствующее самому последнему обмену.
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationTokenBufferMemory
llm = ChatOpenAI(temperature=0.0)
memory = ConversationTokenBufferMemory(llm=llm,)
memory.save_context({"input": «Весна спит, не заметив рассвета»}, {"output": "Я слышу пение птиц повсюду" })
memory.save_context({"input": «Шум ветра и дождя ночью»}, {"output": "Сколько цветов ты узнаешь, когда они падают" })
print(memory.load_memory_variables({}))
#{'history': 'AI: Сколько цветов упало? '}
5.2.2Summary
Что касается буферного метода, то нетрудно обнаружить, что сохранять все — слишком расточительно. При усечении, независимо от того, основано ли оно на количестве разговоров или токенов, невозможно сэкономить память или токены и обеспечить качество разговора. , поэтому мы можем подвести итог:
ConversationSummaryBufferMemory
Самая основная функция инструмента при подведении итогов — ConversationSummaryBufferMemory. При использовании этой функции вы можете установить токен для создания записи разговора при очистке исторических разговоров:
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=40, return_messages=True)
memory.save_context({"input": "Привет"}, {"output": "Ты в порядке"})
memory.save_context({"input": "Ничего особенного, а ты"}, {"output": "Я тоже да"})
messages = memory.chat_memory.messages
previous_summary = ""
print(memory.predict_new_summary(messages, previous_summary))
# И люди, и ИИ заявили, что не сделали ничего особенного.
Этот API успешно подводит итоги разговора с помощью Predict_new_summary.
5.2.3vector
Наконец, давайте представим использование вектора в памяти. Память может храниться в базе данных Vector с помощью VectorStoreRetrieverMemory. При каждом вызове будут найдены k документов с наибольшей ассоциацией с памятью, и последовательность взаимодействия не будет отслеживаться. . Однако следует отметить, что перед использованием VectorStoreRetrieverMemory нам необходимо инициализировать векторные базы данных VectorStore. В их число входят Faiss Meta, chromad и lance. Возьмем, к примеру, faiss:
import faiss
from langchain.docstore import InMemoryDocstore
from langchain.vectorstores import FAISS
embedding_size = 1536 # Dimensions of the OpenAIEmbeddings
index = faiss.IndexFlatL2(embedding_size)
embedding_fn = OpenAIEmbeddings().embed_query
vectorstore = FAISS(embedding_fn, index, InMemoryDocstore({}), {})
После инициализации базы данных мы можем создать экземпляр памяти на основе базы данных:
# существоватьдействительныйиспользоватьсередина,`k` можно установить на более высокое значение,здесьиспользовать k=1 показать
# вектор Найти ещевозвращаться Семантически связанныеизинформация
retriever = vectorstore.as_retriever(search_kwargs=dict(k=1))
memory = VectorStoreRetrieverMemory(retriever=retriever)
# при добавлении водинактерское мастерствочас,Памятьобъект Можетдержать Приходитьсдиалогилииспользоватьизинструментиз Сопутствующая информация
memory.save_context({"input": «Моя любимая еда — пицца»}, {"output": "Ладно, я понял" })
memory.save_context({"input": «Мой любимый вид спорта — футбол»}, {"output": "..."})
memory.save_context({"input": «Мне не нравятся «Селтикс»»},{"output": "хорошийиз"})
print(memory.load_memory_variables({"prompt": «Какие виды спорта мне следует смотреть?»})["history"])В это время результаты памяти будут выведены после извлечения из базы данных векторов.
{
'history': [
{
'input': «Мой любимый вид спорта — футбол»,
'output': '...'
}
]
}
Это значит, что в истории разговоров с пользователем наиболее семантически релевантным вопросу «Какой вид спорта посмотреть?» является разговор «Мой любимый вид спорта — футбол». Чтобы усложнить задачу, вы можете провести несколько раундов разговоров через цепочку разговоров:
llm = OpenAI(temperature=0) # Может ли быть действителен любой из LLM
_DEFAULT_TEMPLATE = """нижедаодинлюди иAIмеждуиздругхорошийдиалог。AIОчень разговорчивый,ииз контекстасередина Предоставьте много конкретных деталей。еслиAIНе знаю проблемыиз Отвечать,это Честно скажу, что не знаю。
Соответствующие части предыдущего разговора:
{history}
(если Не актуально,ты Незачемхотетьиспользоватьэта информация)
Текущий разговор:
Человек: {вход}
AI:"""
PROMPT = PromptTemplate(
input_variables=["history", "input"], template=_DEFAULT_TEMPLATE
)
conversation_with_summary = ConversationChain(
llm=llm,
prompt=PROMPT,
# Мы установили очень низкое значение max_token_limit для тестовой цели.
memory=memory,
verbose=True
)
разговор_with_summary.predict(input="Привет, меня зовут Перри, как дела?")
# выход:"> Entering new ConversationChain chain...
# Prompt after formatting:
# ...
# > Finished chain.
# " Привет, Перри, я в порядке. А ты? "
# Здесь упоминается контент, связанный с баскетболом.
разговор_with_summary.predict(input="Что мне больше всего нравится в спорте?")
# выход:"> Entering new ConversationChain chain...
# ...
# > Finished chain.
# ' Раньше ты говорил мне, что твой любимый вид спорта – футбол. '"
# Хотя язык Модельда не имеет состояния, он может «рассуждать» о времени благодаря приобретению соответствующих воспоминаний.
# Часто полезно ставить временные метки в воспоминаниях, чтобы позволить агентам определять временные корреляции.
разговор_with_summary.predict(input="Какая моя любимая еда?")
# выход:"> Entering new ConversationChain chain...
# ...
# > Finished chain.
# ' Ты сказал, что твоя любимая еда — пицца. '"
# Во время разговора память автоматически удаляется.
# Поскольку этот запрос лучше всего соответствует приведенному выше вводному чату,
# Агент может «запомнить» имя пользователя.
разговор_with_summary.predict(input="Как меня зовут да?")
# выход:"> Entering new ConversationChain chain...
# ...
# > Finished chain.
# ' Тебя зовут Перри. '"
В примере разговора_с_суммари используется объект памяти (память) для хранения истории разговоров с пользователем. Это позволяет ИИ ссылаться на предыдущий контекст в последующих разговорах, предоставляя более точные и релевантные ответы.
Память — относительно простой модуль в Langchain. Сводный тип часто используется при мелкомасштабной разработке. Для более крупных разработок наиболее распространенным является использование векторной базы данных для хранения данных и переход в базу данных, когда модель ИИ дает. Получите контент с наибольшим сходством.
6. Цепи
Если процесс создания приложений ИИ с помощью Langchain сравнить с созданием и объединением «моделей строительных блоков», то можно сказать, что Chain является скелетной частью процесса построения модели. С его помощью каждый модуль можно быстро собрать воедино. для быстрого создания приложения. Использование Chain также осуществляется посредством прямого вызова интерфейса. В этой статье Chain делится на три типа, которые представлены в порядке от простого к сложному. Сначала используется простой пример, чтобы интуитивно почувствовать роль Chain:
6.1 LLMChains:
Этот тип Цепочки очень прост в применении и, можно сказать, является основой Цепочки, которая будет представлена позже, но ее функция достаточно мощная. С помощью LLMChain вы можете напрямую объединить данные, подсказки и модель, которую хотите применить. Давайте рассмотрим LLMChain на простом примере.
from langchain import PromptTemplate, OpenAI, LLMChain
prompt_template = "What is a good name for a company that makes {product}?"
llm = OpenAI(temperature=0)
chain = LLMChain(
llm=llm,
prompt=PromptTemplate.from_template(prompt_template)
)
print(chain("colorful socks"))
# Результат вывода: «Socktastic!»
В этом примере,Мы сначалаинициализация Понятноодинpromptизнитьтрафарет,иинициализациябольшойязык Модель,Затем используйте Chain для запуска Model. В процессе "Цепочка запустится" Модель: Цепочка отформатирует слова подсказки.,Затем передайте его LLM. отзывать,существовать ИзвпередизВведение в ИИсередина,длякаждыйmodelизиспользовать,нам нуженхотетьпротивэтотmodelпровести сериюинициализация、Пример Химические и т. д.действовать。ииспользовать Понятноchainпосле,Нам больше не нужнососредоточиться сама модель.
6.2 Sequential Chains:
В отличие от базовой LLMChain, последовательная цепочка состоит из ряда цепочек. Существует два типа цепочек последовательностей: одна — с одним входом и выходом, другая — с несколькими входами и выходами. Давайте сначала посмотрим на первый пример кода ввода и вывода:
1. Один вход и выход
В этом примере создаются две цепочки, первая цепочка получает название вымышленного сценария, выводит краткое описание сценария в качестве входных данных для второй цепочки, а затем генерирует вымышленный обзор. Это требование может быть легко достигнуто посредством последовательных цепочек.
Первая цепочка:
# This is an LLMChain to write a synopsis given a title of a play.
from langchain import PromptTemplate, OpenAI, LLMChain
llm = OpenAI(temperature=.7)
template = """You are a playwright. Given the title of play, it is your job to write a synopsis for that title.
Title: {title}
Playwright: This is a synopsis for the above play:"""
prompt_template = PromptTemplate(input_variables=["title"], template=template)
synopsis_chain = LLMChain(llm=llm, prompt=prompt_template)
Вторая цепочка:
# This is an LLMChain to write a review of a play given a synopsis.
from langchain import PromptTemplate, OpenAI, LLMChain
llm = OpenAI(temperature=.7)
template = """You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.
Play Synopsis:
{synopsis}
Review from a New York Times play critic of the above play:"""
prompt_template = PromptTemplate(input_variables=["synopsis"], template=template)
review_chain = LLMChain(llm=llm, prompt=prompt_template)
Наконец, SimpleSequentialChain можно использовать для прямого последовательного соединения двух цепочек:
from langchain.chains import SimpleSequentialChain
overall_chain = SimpleSequentialChain(chains=[synopsis_chain, review_chain], verbose=True)
print(review = overall_chain.run("Tragedy at sunset on the beach"))
Вы можете видеть, что для одной последовательной цепочки ввода и вывода просто передайте две цепочки в качестве параметров в simplesequentialchain без необходимости сложных объявлений.
2. Несколько входов и выходов
В дополнение к режиму одного ввода и вывода, цепочка последовательностей также поддерживает более сложные множественные входы и выходы. Для режима с несколькими входами и выходами самое важное, на что следует обратить внимание, — это ключевое слово ввода и ключевое слово вывода. будьте очень точны, чтобы иметь возможность обеспечить идентификацию и применение цепочки, все же возьмите в качестве примера демо-версию:
from langchain import PromptTemplate, OpenAI, LLMChain
llm = OpenAI(temperature=.7)
template = """You are a playwright. Given the title of play and the era it is set in, it is your job to write a synopsis for that title.
Title: {title}
Era: {era}
Playwright: This is a synopsis for the above play:"""
prompt_template = PromptTemplate(input_variables=["title", 'era'], template=template)
synopsis_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="synopsis")
#firstchain
from langchain import PromptTemplate, OpenAI, LLMChain
llm = OpenAI(temperature=.7)
template = """You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.
Play Synopsis:
{synopsis}
Review from a New York Times play critic of the above play:"""
prompt_template = PromptTemplate(input_variables=["synopsis"], template=template)
review_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="review")
#Вторая цепочка
from langchain.chains import SequentialChain
overall_chain = SequentialChain(
chains=[synopsis_chain, review_chain],
input_variables=["era", "title"],
# Here we return multiple variables
output_variables=["synopsis", "review"],
verbose=True)
#третьяцепочка
overall_chain({"title": "Tragedy at sunset on the beach", "era": "Victorian England"})
При определении каждой цепочки необходимо обращать внимание на ее выходные_ключи и входные_переменные и четко указывать их по порядку. Наконец, при запуске цепочки нам нужно указать только те переменные, которые необходимо объявить в первой цепочке.
6.3RouterChains:
Наконец, я представлю часто используемый сценарий. Например, в настоящее время у нас есть три типа цепочек, соответствующих ответам на задачи в трех дисциплинах. Наше входное содержимое также соответствует этим трем дисциплинам, но оно является случайным. Например, когда мы в первый раз вводим вопрос по математике, второй раз может быть вопросом по истории... Ожидаемый эффект в этот момент следующий: в зависимости от того, что будет. входной контент: автоматически применить его к соответствующей подцепи. Цепочка маршрутизатора предоставляет нам такую возможность. Она сначала определяет подцепь, которая будет передана, а затем передает входные данные в эту цепочку. И при настройке нужно обратить внимание на настройку цепочки по умолчанию, чтобы она была совместима с ситуацией, когда входной контент не соответствует ни одному из пунктов.
physics_template = """You are a very smart physics professor. \
You are great at answering questions about physics in a concise and easy to understand manner. \
When you don't know the answer to a question you admit that you don't know.
Here is a question:
{input}"""
math_template = """You are a very good mathematician. You are great at answering math questions. \
You are so good because you are able to break down hard problems into their component parts, \
answer the component parts, and then put them together to answer the broader question.
Here is a question:
{input}"""
Как и выше, есть подсказка по физике и математике:
prompt_infos = [
{
"name": "physics",
"description": "Good for answering questions about physics",
"prompt_template": physics_template
},
{
"name": "math",
"description": "Good for answering math questions",
"prompt_template": math_template
}
]
Затем необходимо объявить основную информацию этих двух подсказок.
from langchain import ConversationChain, LLMChain, PromptTemplate, OpenAI
llm = OpenAI()
destination_chains = {}
for p_info in prompt_infos:
name = p_info["name"]
prompt_template = p_info["prompt_template"]
prompt = PromptTemplate(template=prompt_template, input_variables=["input"])
chain = LLMChain(llm=llm, prompt=prompt)
destination_chains[name] = chain
default_chain = ConversationChain(llm=llm, output_key="text")
Наконец, запустите его в цепочку маршрутизаторов. Когда мы введем данные, цепочка выберет наиболее подходящее приглашение на основе входного содержимого.
from langchain.chains.router.llm_router import LLMRouterChain, RouterOutputParser
from langchain.chains.router.multi_prompt_prompt import MULTI_PROMPT_ROUTER_TEMPLATE
# Create a list of destinations
destinations = [f"{p['name']}: {p['description']}" for p in prompt_infos]
destinations_str = "\n".join(destinations)
# Create a router template
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(destinations=destinations_str)
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser(),
)
router_chain = LLMRouterChain.from_llm(llm, router_prompt)
chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=destination_chains,
default_chain=default_chain,
verbose=True,
)
print(chain.run('Что за излучение черного тела'))
7. Агенты
Модуль «Агенты» также очень важен при использовании langchain. Официальный документ определяет его так: «Основная идея агентов заключается в использовании языковой модели для выбора последовательности действий. В цепочках это последовательность действий. Действия жестко запрограммированы (в коде). В агентах языковая модель используется в качестве механизма рассуждения, позволяющего определить, какие действия и в каких случаях следует выполнять. Другими словами, при использовании агентов их поведение и порядок поведения определяются механизмом рассуждений LLM, а не предопределены базовым кодом для запуска, как традиционные программы.
В качестве примера для сравнения для традиционных процедур можно представить такую сцену: принцу нужно пройти 3 уровня, прежде чем он сможет спасти принцессу. Затем принц должен шаг за шагом пройти определенный маршрут и завершить этот шаг за шагом. Шаг. Для спасения принцессы необходимы три уровня, и он не может пропустить или изменить сам уровень. Но что касается Агентов, мы можем представить его как новорожденного примитивного человека. По мере того, как мозг созревает, а тело продолжает развиваться, у человека постепенно появляются способности принятия решений и способности памяти. В это время представьте, что человеческое существо находится внутри. а Если он голоден, ему нужно поесть. В это время ему довелось прогуляться к речке, и через модуль «памяти» он понял, что «рыбу» в реке можно использовать в качестве еды. Рыбу, а затем используйте огонь, чтобы приготовить рыбу на гриле. На следующий день он снова почувствовал голод. В это время он гулял по джунглям и встретил кабана. Через модуль «памяти» он понял, что «кабана» тоже можно использовать в пищу. был больше, он выбрал для охоты Оснащенное более смертоносным копьем. Из его двух охотничьих опытов мы можем обнаружить, что он не использует фиксированные инструменты для охоты на фиксированную добычу в соответствии с заранее заданным процессом, а выбирает подходящую добычу в соответствии с изменениями в окружающей среде и типом добычи, чтобы решить, какие охотничьи инструменты использовать. . В этом процессе идеально используются собственные системы принятия решений и памяти, а также использование вспомогательных инструментов для выполнения ряда реакций для решения проблем. Если выразить это математической формулой, можно сказать, что Агенты = LLM (принятие решений) + Память (память) + Инструменты (исполнение).
Я полагаю, что из приведенных выше примеров вы ясно поняли, что агенты более гибки, чем традиционные программы. С помощью различных комбинаций часто можно достичь неожиданных результатов. Теперь используйте код, чтобы испытать реальную работу метода приложения, основной функции агентов. пример кода ниже предназначен для того, чтобы дать агенту тему и позволить агенту создать документ.
В этом примере мы определенно хотим создать экземпляры агентов. При создании экземпляра агента нам нужно обратить внимание на три его элемента, описанные выше: LLM, память и инструменты. Код выглядит следующим образом:
# инициализация agent
agent = initialize_agent(
tools,# Конфигурацияинструментнабор llm, # Настройка большого языка Модель Ответственный за принятие решений
agent=AgentType.OPENAI_FUNCTIONS, # настраивать agent тип
agent_kwargs=agent_kwargs, # настраивать agent Роль
verbose=True,
memory=memory, # Режим памяти конфигурации )
7.1 Введение в конфигурацию, связанную с инструментами
Первый — настроить инструменты набора инструментов. Как показано в следующем коде, вы можете видеть, что это двоичный массив, а это означает, что агенты в этом примере полагаются на два инструмента.
from langchain.agents import initialize_agent, Tool
tools = [
Tool(
name="Search",
func=search,
description="useful for when you need to answer questions about current events, data. You should ask targeted questions"
),
ScrapeWebsiteTool(),
]
Давайте сначала рассмотрим первый инструмент: при настройке инструмента вам необходимо объявить функции, от которых он зависит. Поскольку функция, реализованная в этом примере, заключается в сборе соответствующей информации на основе сети и последующем обобщении ее в документе, а. Создана функция поиска. Эта функция используется для вызова поиска Google. Он принимает параметр запроса, а затем отправляет запрос в Serper API. Ответ API будет распечатан и возвращен.
# вызов Google search by Serper
def search(query):
serper_google_url = os.getenv("SERPER_GOOGLE_URL")
payload = json.dumps({
"q": query
})
headers = {
'X-API-KEY': serper_api_key,
'Content-Type': 'application/json'
}
response = requests.request("POST", serper_google_url, headers=headers, data=payload)
print(f'Google Результаты поиска: \n {response.text}')
return response.text
Давайте посмотрим на вторую функцию инструмента, от которой он зависит. Другой способ объявить инструмент — это объявление класса ScrapeWebsiteTool(), который имеет следующие свойства и методы:
class ScrapeWebsiteTool(BaseTool):
name = "scrape_website"
description = "useful when you need to get data from a website url, passing both url and objective to the function; DO NOT make up any url, the url should only be from the search results"
args_schema: Type[BaseModel] = ScrapeWebsiteInput
def _run(self, target: str, url: str):
return scrape_website(target, url)
def _arun(self, url: str):
raise NotImplementedError("error here")
1.name: имя инструмента, здесь «scrape_website». 2.description: описание инструмента. args_schema: режим параметров инструмента. Вот класс ScrapeWebsiteInput, который представляет входные параметры, необходимые этому инструменту. Код объявления следующий. Это класс модели на основе Pydantic, используемый для определения входных параметров функции Scrape_website. . Он имеет два поля: target и url, которые соответственно представляют цели и задачи, поставленные пользователем агенту, и URL-адрес веб-сайта, который необходимо просканировать.
class ScrapeWebsiteInput(BaseModel):
"""Inputs for scrape_website"""
target: str = Field(
description="The objective & task that users give to the agent")
url: str = Field(description="The url of the website to be scraped")
Метод _run: это основная функция выполнения инструмента. Он получает цель и URL-адрес в качестве параметров, а затем вызывает функцию Scrape_website для сканирования веб-сайта и возврата результатов. Функция Scrape_website очищает веб-контент на основе заданной цели и URL-адреса. Сначала он отправляет HTTP-запрос для получения содержимого веб-страницы. Если запрос успешен, он использует библиотеку BeautifulSoup для анализа содержимого HTML и извлечения текста. Если текст длиннее 5000 символов, он вызывает функцию summary для обобщения содержимого. В противном случае он возвращает извлеченный текст напрямую. Код выглядит следующим образом:
# в соответствии с url Сканировать веб-контент и дать окончательный ответ
# target : назначено agent из Начальная миссия
# url : Agent URL-адрес, необходимый для достижения вышеуказанных целей, полностью определяется и выбирается Агентом. Его содержимое требуется для промежуточных шагов и для окончательного решения.
def scrape_website(target: str, url: str):
print(f"Начнём сканирование: {url}...")
headers = {
'Cache-Control': 'no-cache',
'Content-Type': 'application/json',
}
payload = json.dumps({
"url": url
})
post_url = f"https://chrome.browserless.io/content?token={browserless_api_key}"
response = requests.post(post_url, headers=headers, data=payload)
# есливозвращатьсяуспех
if response.status_code == 200:
soup = BeautifulSoup(response.content, "html.parser")
text = soup.get_text()
print("Сканирование конкретного контента:", text)
# Контроль длины контента,еслисодержание太长Сразунуждатьсяхотеть Срезы суммируются и обрабатываются отдельно.
if len(text) > 5000:
# Сводное сканирование извозвращаться контента
output = summary(target, text)
return output
else:
return text
else:
print(f"Ошибка HTTP-запроса, код ошибки: {response.status_code}")
Из приведенного выше кода мы видим, что он также использует функцию суммирования. Эта функция используется для решения проблемы слишком длинного контента. Эта функция использует метод Map-Reduce для суммирования длинных текстов. Сначала он инициализирует большую языковую модель (llm), а затем определяет большой разделитель текста (text_splitter). Затем он создает сводную цепочку (summary_chain) и использует эту цепочку для обобщения входного документа.
# еслинуждатьсяхотетьиметь дело сиз Контент слишком длинный,Сначала нарежьте и обработайте отдельно.,Подробное резюме
# использовать Map-Reduce Способ
def summary(target, content):
# model list : https://platform.openai.com/docs/models
# gpt-4-32k gpt-3.5-turbo-16k-0613
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-16k-0613")
# определение Резак большого текста
# chunk_overlap даодинсуществоватьиспользовать OpenAI из GPT-3 или GPT-4 API Вы можете столкнуться с параметром из, особенно когда да необходимо обработать длинный текст.
# Этот параметр используется для управления степенью перекрытия между текстовыми фрагментами (чанками).
# Обслуживание контекста: перекрытие гарантирует, что Модель будет иметь достаточно контекстной информации при обработке последующих блоков.
# Согласованность: помогает обеспечить более последовательный и последовательный вывод, поскольку программа может «запоминать» части предыдущего блока.
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n"], chunk_size=5000, chunk_overlap=200)
docs = text_splitter.create_documents([content])
map_prompt = """
Write a summary of the following text for {target}:
"{text}"
SUMMARY:
"""
map_prompt_template = PromptTemplate(
template=map_prompt, input_variables=["text", "target"])
summary_chain
Метод _arun: это асинхронная версия метода _run, которая здесь не реализована. При вызове будет выдано исключение NotImplementedError.
7.2 Введение в конфигурацию LLM
# инициализациябольшойязык Модель,Ответственный за принятие решений
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-16k-0613")
Этот код инициализирует большой объект языковой модели с именем llm, который является экземпляром класса ChatOpenAI. Класс ChatOpenAI используется для взаимодействия с большими языковыми моделями (такими как GPT-3) для генерации решений и ответов. При инициализации объекта ChatOpenAI предоставляются следующие параметры:
1.temperature: число с плавающей запятой, представляющее температуру при создании текста. Чем выше значение температуры, тем более случайным и разнообразным будет сгенерированный текст; чем ниже значение температуры, тем более детерминированным и последовательным будет сгенерированный текст; Здесь установлено значение 0, поскольку целью этой демонстрации является создание документа, поэтому мы не хотим, чтобы большая модель имела большую вариативность, но мы хотим генерировать очень точные и последовательные ответы. 2.model: строка, указывающая имя большой языковой модели, которая будет использоваться. Здесь мы установили значение «gpt-3.5-turbo-16k-0613», что означает использование модели GPT-3.5 Turbo.
7.3 Введение в настройку, связанную с типом и ролью агента
первый Приходить ВзглянитеAgentTypeэта переменнаяизинициализация,здесьдаиспользовать Приходитьнастраиватьagentтипизодинпараметр,специфический Можетссылка Официальный сайт:AgentType
Вы можете видеть, что на официальном сайте перечислено 7 типов агентов. Вы можете выбрать в соответствии со своими потребностями. В этом примере выбран первый тип — функции OpenAi. Кроме того, необходимо настроить роль агента и режим памяти:
# созданиеагентовподробное описание
system_message = SystemMessage(
content="""Вы исследователь мирового уровня, который может провести детальное исследование по любой теме и получить основанные на фактах результаты;
Вы не выдумываете ничего из воздуха, вы делаете все возможное, чтобы собрать факты для поддержки исследований.
Для достижения вышеуказанных целей обязательно соблюдайте следующие правила:
1/ Вам следует провести достаточно исследований, чтобы собрать как можно больше информации о вашей цели.
2/ если есть ссылки и статьи по теме и URL-адреса,Вы очистите его, чтобы собрать больше информации
3/ После сканирования и поиска,тыследует подумать“в соответствии с Я принимаюнаборприезжатьизданные,данет Что-то новоеизвещьнуждатьсяхотетья ищуи Получить для извлечениявысокий Качество исследований?”если Отвечатьдаподтверждатьиз,продолжать;но Нетхотетьвыполнить более чем5итерации
4/ Не следует выдумывать факты, следует писать только те факты, которые вы собрали иданные.
5/ В окончательный результат вы должны включить все ссылки на справочные данные для поддержки вашего исследования;
6/ В окончательный результат вы должны включить все ссылки на справочные данные для поддержки вашего исследования;"""
)
# инициализация agent Роль шаблон
agent_kwargs = {
"extra_prompt_messages": [MessagesPlaceholder(variable_name="memory")],
"system_message": system_message,
}
# инициализацияпамятьтип
memory = ConversationSummaryBufferMemory(
memory_key="memory", return_messages=True, llm=llm, max_token_limit=300)
1️⃣При настройке агента_kwargs: «extra_prompt_messages»: значение, соответствующее этому ключу, представляет собой список, содержащий объекты MessagesPlaceholder. Для свойстваvariable_name этого объекта установлено значение «memory», что указывает на то, что мы хотим, чтобы содержимое переменной памяти было вставлено в приглашение при построении приглашения агента. «system_message»: значение, соответствующее этому ключу, представляет собой объект SystemMessage, который содержит описание роли агента и требования к задаче.
7.4 Знакомство с конфигурацией памяти
# инициализацияпамятьтип
memory = ConversationSummaryBufferMemory(
memory_key="memory", return_messages=True, llm=llm, max_token_limit=300)
При установке объекта типа памяти: используется экземпляр класса ConversationSummaryBufferMemory. Этот класс используется для кэширования и управления информацией в разговорах с ИИ-помощниками. При инициализации этого объекта предоставляются следующие параметры: 1. Memory_key: строка, представляющая ключ этого объекта памяти. Здесь установите «память». 2.return_messages: логическое значение, указывающее, включать ли содержимое памяти в возвращаемое сообщение. Установите здесь значение True, чтобы указать, что вы хотите включить содержимое памяти в возвращаемое сообщение. 3.llm: Соответствующий объект большой языковой модели. Здесь находится ранее инициализированный объект llm. Этот параметр используется для указания большой языковой модели, используемой при обработке содержимого памяти. 4. max_token_limit: целое число, указывающее максимальный лимит токенов для кэша памяти. Установите здесь значение 300, что означает, что ожидается, что содержимое кэшированной памяти будет содержать до 300 токенов.
7.5 Заливаем пакеты зависимого окружения и запускаем основную функцию
Импортируйте необходимые библиотеки здесь: этот код импортирует ряд необходимых библиотек, включая os, dotenv, библиотеки, связанные с langchain, запросы, BeautifulSoup, json иstreamlit.
import os
from dotenv import load_dotenv
from langchain import PromptTemplate
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
from langchain.chat_models import ChatOpenAI
from langchain.prompts import MessagesPlaceholder
from langchain.memory import ConversationSummaryBufferMemory
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains.summarize import load_summarize_chain
from langchain.tools import BaseTool
from pydantic import BaseModel, Field
from langchain.schema import SystemMessage
from typing import Type
from bs4 import BeautifulSoup
import requests
import json
import streamlit as st
# нагрузкадолженхотетьизпараметр
load_dotenv()
serper_api_key=os.getenv("SERPER_API_KEY")
browserless_api_key=os.getenv("BROWSERLESS_API_KEY")
openai_api_key=os.getenv("OPENAI_API_KEY")
Основная функция: это основная функция приложенияstreamlit. Сначала он устанавливает заголовок и значок страницы, затем создает несколько заголовков и предоставляет пользователю поле ввода текста для ввода запроса. Когда пользователь вводит запрос, он вызывает агента для обработки запроса и отображает результаты на странице.
def main():
st.set_page_config(page_title="AI Assistant Agent", page_icon=":dolphin:")
st.header("LangChain Пример объяснения 3 -- Agent", divider='rainbow')
st.header("AI Agent :синий[помощник] :dolphin:")
query = st.text_input("Пожалуйста, задавайте вопросы и требования:")
if query:
st.write(f"Начать сбор и обобщение данных 【 {query}】 Пожалуйста, подождите")
result = agent({"input": query})
st.info(result['output'])
На этом этапе описан пример кода для использования Агента. Мы видим, что функция Агентов заключается в самостоятельном выборе и использовании наиболее подходящих инструментов для решения проблем. Чем богаче предоставляемые нами Инструменты, тем мощнее будут их функции. .
8. Обратные вызовы
Обратные вызовы должны быть знакомы программистам. Это функция обратного вызова. Эта функция позволяет нам использовать различные «перехватчики» на различных этапах LLM для выполнения таких функций, как запись журнала, мониторинг и потоковая передача. В Langchain функция обратного вызова реализована путем наследования BaseCallbackHandler. Этот интерфейс объявляет функцию обратного вызова для каждого события подписки. Его подклассы также могут реализовывать обработку событий, наследуя ее. Как показано на официальном сайте:
class BaseCallbackHandler:
"""Base callback handler that can be used to handle callbacks from langchain."""
def on_llm_start(
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
) -> Any:
"""Run when LLM starts running."""
def on_chat_model_start(
self, serialized: Dict[str, Any], messages: List[List[BaseMessage]], **kwargs: Any
) -> Any:
"""Run when Chat Model starts running."""
def on_llm_new_token(self, token: str, **kwargs: Any) -> Any:
"""Run on new LLM token. Only available when streaming is enabled."""
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> Any:
"""Run when LLM ends running."""
def on_llm_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> Any:
"""Run when LLM errors."""
def on_chain_start(
self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs: Any
) -> Any:
"""Run when chain starts running."""
def on_chain_end(self, outputs: Dict[str, Any], **kwargs: Any) -> Any:
"""Run when chain ends running."""
def on_chain_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> Any:
"""Run when chain errors."""
def on_tool_start(
self, serialized: Dict[str, Any], input_str: str, **kwargs: Any
) -> Any:
"""Run when tool starts running."""
def on_tool_end(self, output: str, **kwargs: Any) -> Any:
"""Run when tool ends running."""
def on_tool_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> Any:
"""Run when tool errors."""
def on_text(self, text: str, **kwargs: Any) -> Any:
"""Run on arbitrary text."""
def on_agent_action(self, action: AgentAction, **kwargs: Any) -> Any:
"""Run on agent action."""
def on_agent_finish(self, finish: AgentFinish, **kwargs: Any) -> Any:
"""Run on agent end."""
Этот класс содержит ряд методов, которые langchain изразные этапывызов,так чтосуществоватьиметь дело спроцесссередина执行сопределениедействовать。Справочный исходный кодBaseCallbackHandler:
on_llm_start: вызывается, когда запускается большая языковая модель (LLM). on_chat_model_start: вызывается, когда модель чата начинает работать. on_llm_new_token: вызывается при появлении нового токена LLM. Доступно только при включенной потоковой передаче. on_llm_end: вызывается, когда выполнение LLM заканчивается. on_llm_error: вызывается при возникновении ошибки в LLM. on_chain_start: вызывается, когда цепочка начинает работать. on_chain_end: вызывается, когда цепочка заканчивается. on_chain_error: вызывается, когда в цепочке возникает ошибка. on_tool_start: вызывается, когда инструмент запускается. on_tool_end: вызывается, когда инструмент завершил работу. on_tool_error: вызывается, когда в инструменте возникает ошибка. on_text: вызывается при обработке произвольного текста. on_agent_action: вызывается, когда агент выполняет действие. on_agent_finish: вызывается, когда агент завершает работу.
8.1 Базовое использование StdOutCallbackHandler
StdOutCallbackHandler — это самый простой обработчик, поддерживаемый LangChain, и он наследуется от BaseCallbackHandler. Этот обработчик выводит всю информацию обратного вызова в стандартный вывод, что полезно для отладки. Вот пример использования StdOutCallbackHandler:
from langchain.callbacks import StdOutCallbackHandler
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
handler = StdOutCallbackHandler()
llm = OpenAI()
prompt = PromptTemplate.from_template("Who is {name}?")
chain = LLMChain(llm=llm, prompt=prompt, callbacks=[handler])
chain.run(name="Super Mario")
В этом примере мы сначала импортируем класс StdOutCallbackHandler из модуля langchain.callbacks. Затем создается экземпляр StdOutCallbackHandler и назначается обработчику переменной. Затем были импортированы классы LLMChain, OpenAI и PromptTemplate и созданы соответствующие экземпляры. При создании экземпляра LLMChain установите для параметра callbacks список обработчиков. Таким образом, когда цепочка запущена, вся информация обратного вызова будет выведена на стандартный вывод. Наконец, используйте метод Chain.run() для запуска цепочки, передав параметр name="Super Mario". Во время процесса выполнения цепочки вся информация обратного вызова будет обработана StdOutCallbackHandler и выведена на стандартный вывод.
8.2 Пользовательский процессор обратного вызова
from langchain.callbacks.base import BaseCallbackHandler
import time
class TimerHandler(BaseCallbackHandler):
def __init__(self) -> None:
super().__init__()
self.previous_ms = None
self.durations = []
def current_ms(self):
return int(time.time() * 1000 + time.perf_counter() % 1 * 1000)
def on_chain_start(self, serialized, inputs, **kwargs) -> None:
self.previous_ms = self.current_ms()
def on_chain_end(self, outputs, **kwargs) -> None:
if self.previous_ms:
duration = self.current_ms() - self.previous_ms
self.durations.append(duration)
def on_llm_start(self, serialized, prompts, **kwargs) -> None:
self.previous_ms = self.current_ms()
def on_llm_end(self, response, **kwargs) -> None:
if self.previous_ms:
duration = self.current_ms() - self.previous_ms
self.durations.append(duration)
llm = OpenAI()
timerHandler = TimerHandler()
prompt = PromptTemplate.from_template("What is the HEX code of color {color_name}?")
chain = LLMChain(llm=llm, prompt=prompt, callbacks=[timerHandler])
response = chain.run(color_name="blue")
print(response)
response = chain.run(color_name="purple")
print(response)
В этом примере показано, как реализовать собственный обработчик обратного вызова, наследующий BaseCallbackHandler. В этом примере создается пользовательский процессор с именем TimerHandler, который используется для отслеживания времени начала и окончания взаимодействий цепочки или LLM и расчета времени обработки каждого взаимодействия. Импортируйте класс BaseCallbackHandler из модуля langchain.callbacks.base. Импортируйте модуль времени для обработки операций, связанных со временем.
определение TimerHandler класс, унаследованный от BaseCallbackHandler. TimerHandler сорт init В методе инициализируйте previous_ms и durations свойство。определение current_ms Метод, используемый для возврата значения миллисекунды текущего времени. переписать on_chain_start、on_chain_end、on_llm_start и on_llm_end Методы, в которых фиксируется время начала и окончания и рассчитывается время обработки. Далее мы создали OpenAI пример, один TimerHandler примеры и PromptTemplate Пример. Затем мы создали использование timerHandler как обработчик обратного вызова LLMChain Пример. Наконец, мы дважды запустили цепочку, запросив шестнадцатеричный код синего, фиолетового и з. Во время работы цепочки TimerHandler Время обработки каждого взаимодействия будет записываться и добавляться к durations в списке.
Вывод следующий:

8.3 Краткое описание сценариев использования обратных вызовов
1️⃣Задайте через обратные вызовы параметров конструктора. Таким образом, обработчик обратного вызова может быть установлен при создании объекта. Например, при создании объекта LLMChain или OpenAI вы можете установить обработчик обратного вызова через параметр callbacks.
timerHandler = TimerHandler()
llm = OpenAI(callbacks=[timerHandler])
response = llm.predict("What is the HEX code of color BLACK?") print(response)
Создавая здесь llm, мы напрямую указывали конструктор.
2️⃣Через вызовы функций во время выполнения. Этот метод может динамически устанавливать процессор обратного вызова во время выполнения, например, устанавливая процессор обратного вызова в каждом модуле Langchain, таком как Модель, Агент, Инструмент и функция выполнения запроса Chain. Например, при вызове метода run LLMChain или метода прогнозирования OpenAI вы можете установить процессор обратного вызова через параметр callbacks. Возьмем в качестве примера метод прогнозирования OpenAI:
timerHandler = TimerHandler()
llm = OpenAI()
response = llm.predict("What is the HEX code of color BLACK?", callbacks=[timerHandler])
print(response)
Этот код сначала создает экземпляр TimerHandler и присваивает его переменной timerHandler. Затем создайте экземпляр OpenAI и присвойте его переменной llm. Вызовите метод llm.predict(), передав вопрос «Какой HEX-код цвета ЧЕРНЫЙ?» и установив timerHandler процессора обратного вызова через параметр callbacks.
Два видаметодизосновнойразницасуществовать于何часикакнастраиватьобработчик обратного вызова。
Настройка обратных вызовов параметров конструктора. При создании объекта (например, OpenAI или LLMChain) установите процессор обратного вызова через параметр обратных вызовов конструктора. Преимущество этого подхода заключается в том, что вы можете определить обработчик обратного вызова при создании объекта, и вам не нужно будет устанавливать его снова при дальнейшем использовании объекта. Однако если обработчик обратного вызова необходимо изменить во время последующего использования, возможно, объект придется создать заново.
Через вызовы функций во время выполнения: при вызове метода объекта (например, метода прогнозирования OpenAI или метода запуска LLMChain) установите процессор обратного вызова через параметр обратного вызова метода. Преимущество этого подхода заключается в том, что вы можете динамически устанавливать обработчик обратного вызова каждый раз при вызове метода, что более гибко. Но его необходимо устанавливать каждый раз при вызове метода. Если вы забудете его установить, процессор обратного вызова может не сработать.
При фактическом использовании вы можете выбрать подходящий метод в соответствии с вашими потребностями. Если обработчик обратного вызова не изменится в течение всего жизненного цикла объекта, вы можете установить его в конструкторе; если обработчик обратного вызова должен изменяться динамически, вы можете установить его при вызове функции во время выполнения.
9. Резюме
На этом этапе были представлены методы использования каждого модуля Langchain. Я думаю, вы уже почувствовали возможности Langchain~ Найти этот LangChain несложно. Это очень мощная платформа обработки языка искусственного интеллекта, сочетающая в себе модель Шесть модулей ввода-вывода, извлечения, памяти, цепочек, агентов и обратных вызовов объединены вместе. Модель IOОтветственный за обращениеAIМодельизвходитьивыход,Модуль «Поиск» реализует функцию поиска по библиотеке векторных данных.,MemoryМодуль отвечает засуществоватьдиалогпроцесссерединахранилищеиснованагрузкаисториядиалог Записывать。Chains模块充当Понятноодинразъемиз Роль,Волявперед面提приезжатьиз Модуль подключен Приходитьчтобы стать богачеиз Функция。Agents模块проходить理解использовать户входить Приходитьс主вызов Связанныйинструмент,Сделайте приложения более интеллектуальными. Модуль «Обратные вызовы» предоставляет механизм обратного вызова.,Удобен для развития ВОЗотслеживатьвызовсвязьирегистрация,для лучшей отладки модели LLM. Суммируя,LangChainдаодин Функция Богатый、легкийиспользоватьизAIязыкиметь дело с框架,это Может Помогите разработать ВОЗБыстрая сборкаиоптимизацияAIприложение。Эта статья Толькода Перечисленные модулиизосновнойиспользоватьметоди Некоторый Примерdemo,Чтобы получить от нее пользу, рекомендуется внимательно прочитать официальную документацию вместе с этой статьей~



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
