Простой и удобный в использовании инструмент планирования данных: DolphinSchedule.
Привет всем, я брат Юэ.
Сегодня я хотел бы поделиться с вами широко используемым инструментом мобилизации данных: DolphinSchedule.
Скачать адрес
https://dolphinscheduler.apache.org/en-us/download/3.2.2
Предварительные условия
JDK: загрузите JDK (1.8+), установите и настройте переменную среды JAVA_HOME и добавьте каталог bin под ней к переменной среды PATH. Если он уже существует в вашей среде, вы можете пропустить этот шаг.
Разархивируйте и запустите
В сжатом пакете имеется автономный сценарий запуска, который можно быстро запустить после распаковки.
# Разархивируйте и запустите Standalone Server
tar -xvzf apache-dolphinscheduler-*-bin.tar.gz
chmod -R 755 apache-dolphinscheduler-*-bin
cd apache-dolphinscheduler-*-bin
bash ./bin/dolphinscheduler-daemon.sh start standalone-serverВведение функции
DolphinSchedule (далее — Dolphin) — это инструмент межплатформенной и межбазовой синхронизации и планирования данных. Он обычно используется в качестве инструмента планирования больших данных. Конечно, он также поддерживает планирование реляционных баз данных. рабочий интерфейс, требуется только настройка соответствующих параметров. Быстрое выполнение связанных задач планирования, в настоящее время поддерживается только системы Linux.
Здесь мы используем различные реляционные базы данных для синхронизации данных и знакомим вас с конкретными особенностями использования.
Этапы работы
1. Войдите в веб-интерфейс Little Dolphin.
Пароль учетной записи устанавливается администратором во время установки. Адрес по умолчанию:
http://localhost:12345/dolphinscheduler/ui
Вы можете войти в системный интерфейс.
Имя пользователя и пароль по умолчанию:
admin/dolphinscheduler123
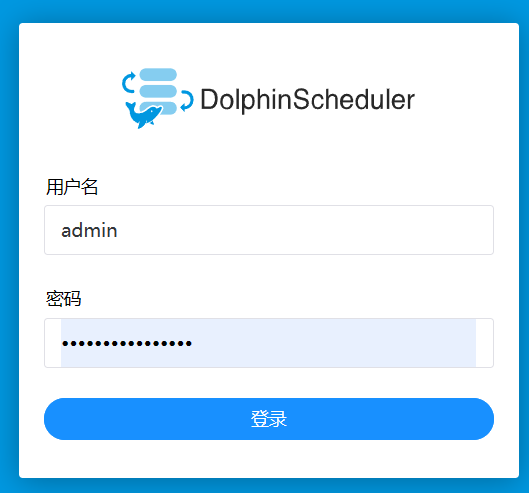
2. Настройте центр источников данных
После входа на домашнюю страницу нам необходимо настроить подключение к базе данных. Нажмите «Центр источников данных» в строке меню, чтобы начать настройку источника данных.
Войдите в центр конфигурации источника данных, нажмите «Создать источник данных» и на всплывающей странице введите информацию о базе данных, к которой вам необходимо подключиться.
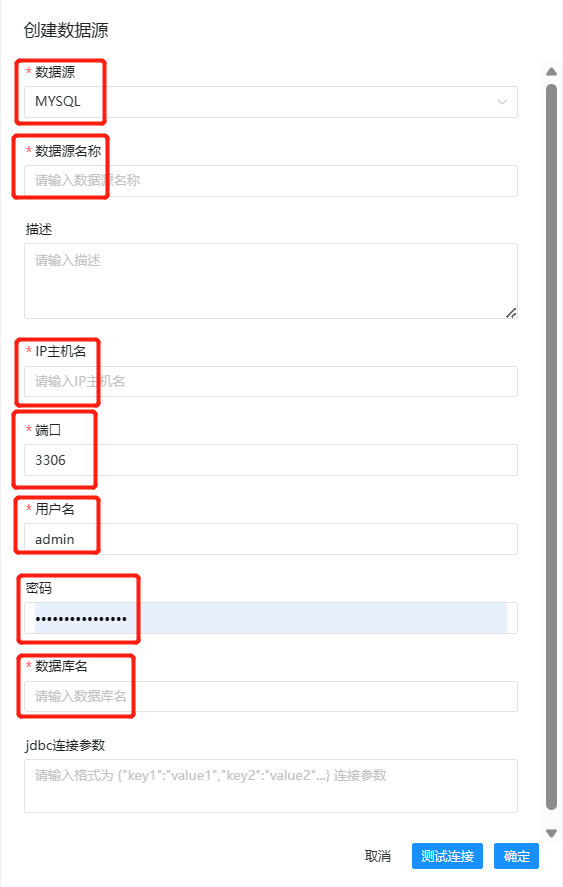
Просто заполните соответствующую информацию в базе данных так, как требуется на странице.
После заполнения нажмите «Проверить соединение» и в случае успешного подключения нажмите «ОК».
3. Создайте проект
1) Нажмите «Управление проектом» в строке меню, нажмите «Создать проект» на открывшейся странице и введите имя проекта на всплывающей странице.
2) После успешного создания нажмите на имя созданного проекта, чтобы войти в интерфейс конфигурации проекта.
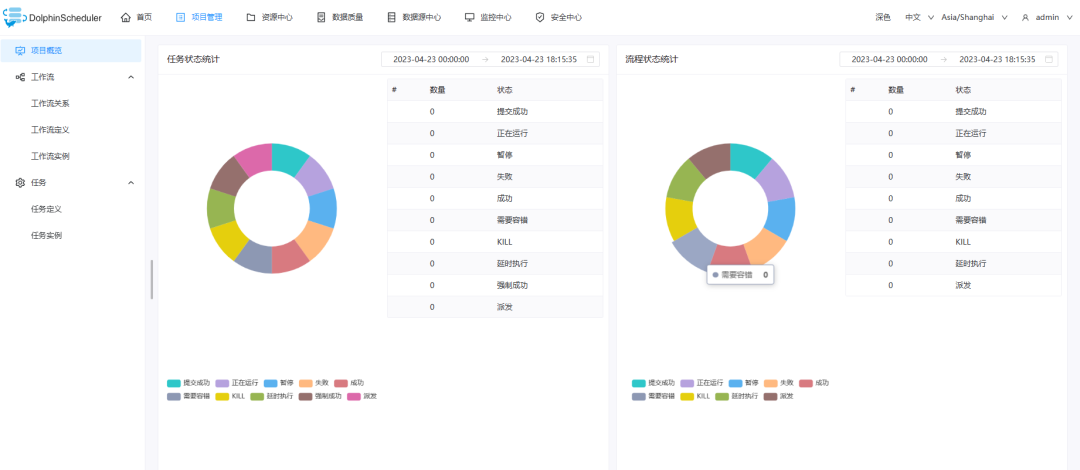
Нажмите «Определение рабочего процесса» в левой строке меню — «Создать рабочий процесс».
Начните настройку рабочего процесса синхронизации данных на открывшейся странице.
Найдите элемент управления «DataX» среди элементов управления слева (использование DataX было описано ранее).,Конкретное использование можно найти в этой статье.:Инструмент синхронизации данных Alibaba с открытым исходным кодом DataX стабилен, эффективен и невероятно прост в использовании!),Перетащите его в рабочую область справа.,Начать настройку Рабочий процесс
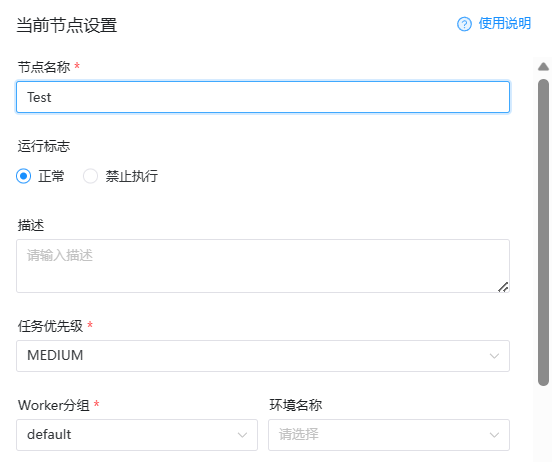
Просто укажите в имени узла задачи, которые необходимо выполнить в текущем рабочем процессе. Другие, отмеченные красным «*», являются обязательными. Просто используйте конфигурацию по умолчанию, чтобы начать настройку задач синхронизации.
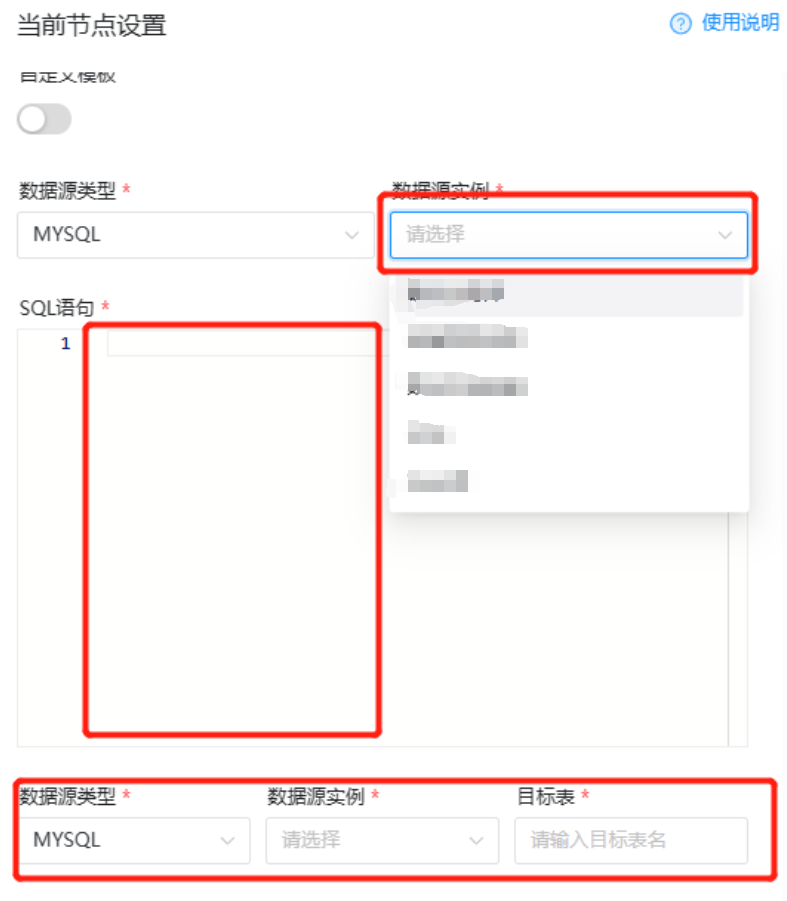
Верхняя и нижняя части «оператора SQL» — это исходная база данных и целевая база данных соответственно. Мы можем выбрать соответствующие исходную и целевую базы данных и таблицы.
Затем заполните нужный нам код синхронизации в области «Оператор SQL».
Примечание. Обычно в области операторов SQL можно записать только операторы запроса SELECT. Поскольку источник и цель по умолчанию синхронизируются с помощью операции INSERT INTO, здесь нельзя записать другие операторы DML (добавление, удаление, изменение).
Во-вторых, количество столбцов в операторе SQL должно соответствовать количеству полей в целевой таблице в целевой базе данных. Неизвлеченные поля можно заменить на NULL, но они не могут отсутствовать, иначе это приведет к ошибке. в котором количество извлеченных столбцов данных непостоянно.
3) После успешного создания вернитесь в интерфейс рабочего процесса, нажмите кнопку «Перейти в Интернет» в правой части настроенного рабочего процесса, а затем нажмите кнопку «Выполнить», чтобы проверить успешность настройки.
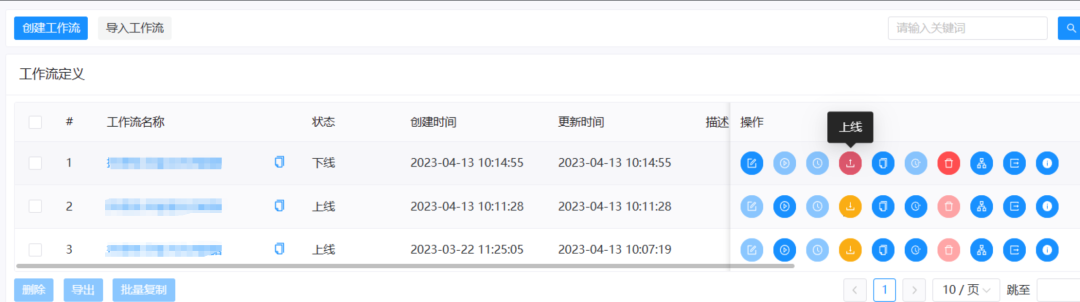
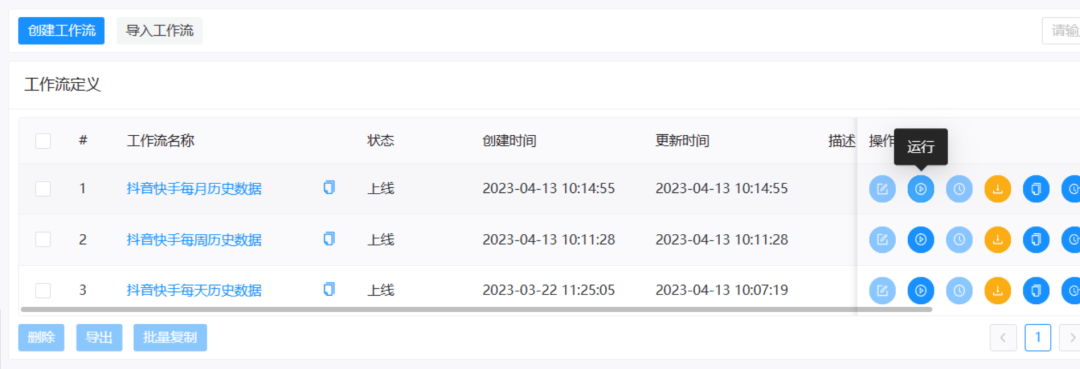
Если возвращенный статус показывает ошибку, вам необходимо перепроверить содержимое конфигурации рабочего процесса.
4. Настройте запланированные задачи
1) После успешного отображения статуса выполнения рабочего процесса, что означает, что его можно выполнять в обычном режиме, нажмите кнопку «Запланировать задачу», чтобы начать настройку запланированной задачи.
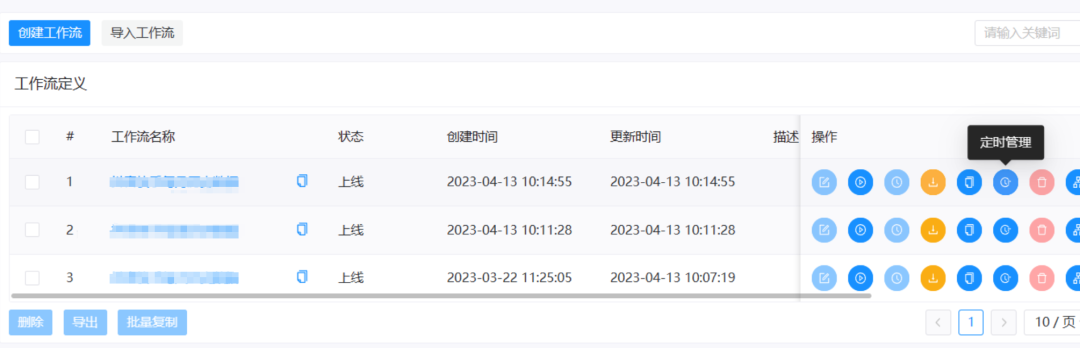
На открывшейся странице выберите кнопку «Редактировать» справа.

Нажмите «Время» на всплывающей странице, чтобы начать настройку конкретного времени выполнения и цикла выполнения.
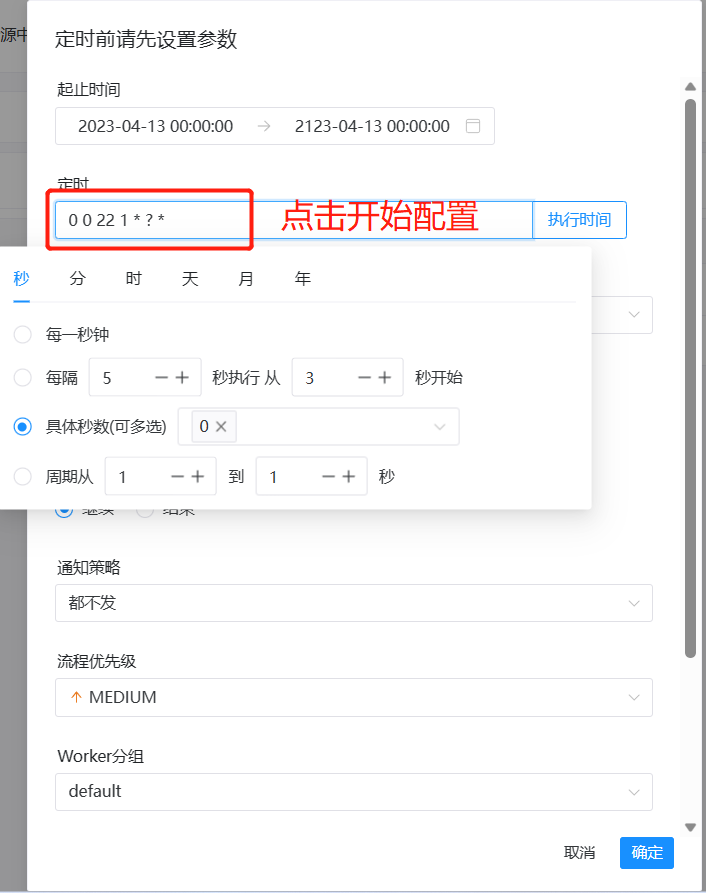
Параметры конфигурации аналогичны запланированным задачам Linux. После завершения настройки не забудьте нажать «Время выполнения», чтобы просмотреть конкретное время выполнения следующих 5 раз запланированного задания и убедиться, соответствует ли оно желаемому времени выполнения. .
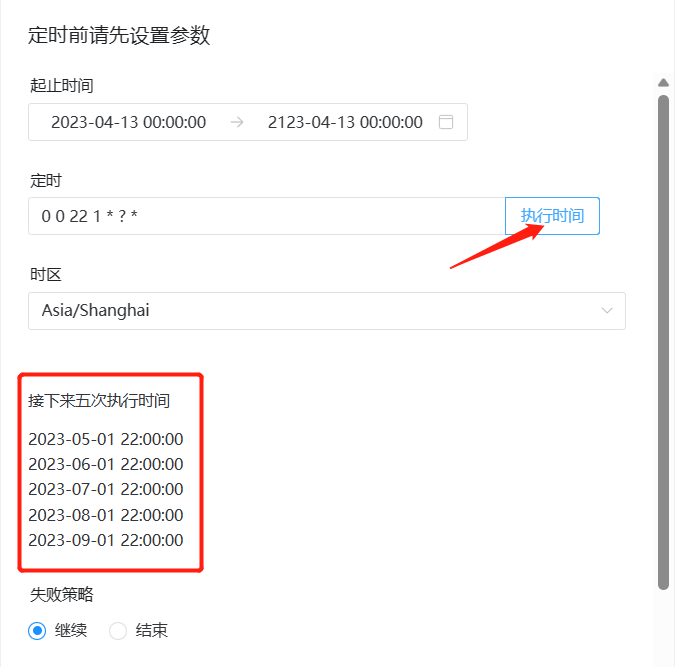
Убедившись в правильности времени и цикла выполнения, нажмите «ОК», чтобы завершить настройку запланированного задания.
2) После настройки запланированного задания обязательно нажмите «Перейти в Интернет», чтобы изменения вступили в силу. Если вы не нажмете, запланированное задание не будет выполнено вовремя.

5. Просмотрите примеры рабочих процессов
1) Нажмите «Экземпляр рабочего процесса» в левой строке меню, чтобы увидеть выполнение нашего рабочего процесса.
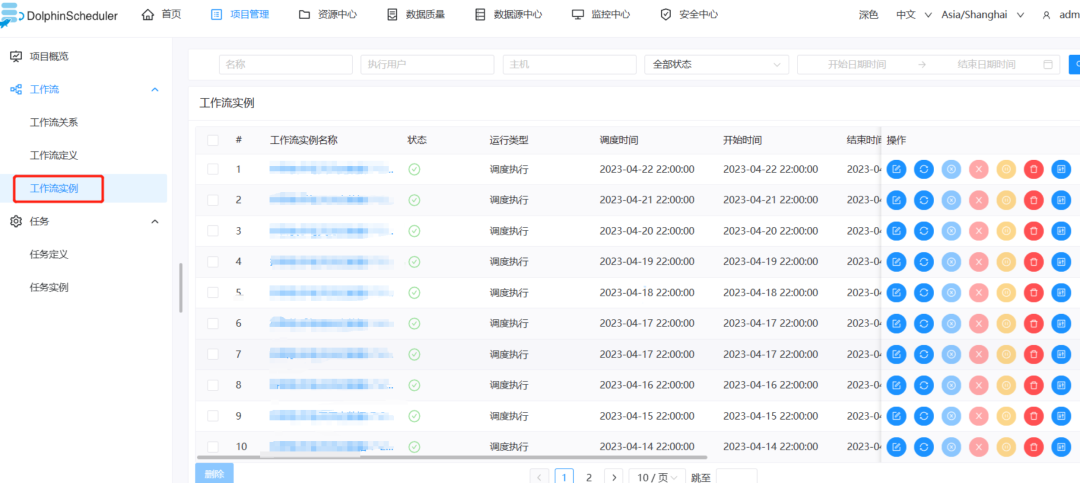
Если вы обнаружите статус, отличный от «Успешно», вам необходимо проверить журнал работы рабочего процесса.
2) Нажмите «Экземпляр рабочего процесса», чтобы войти в интерфейс выполнения рабочего процесса, дважды щелкните конкретный рабочий процесс.
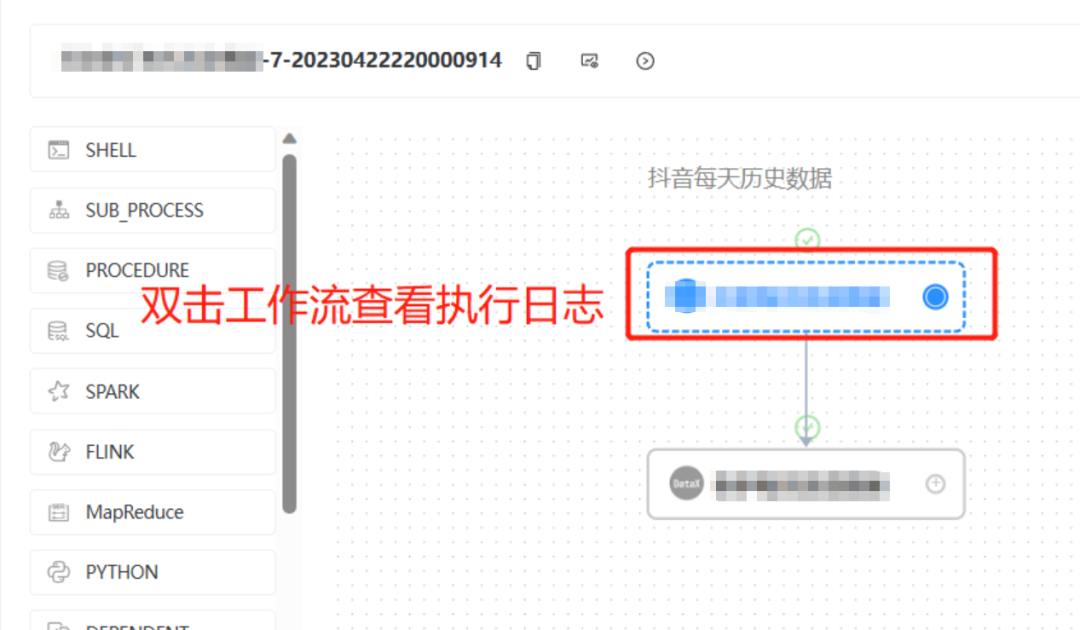
После двойного щелчка мы увидим всплывающую страницу настроек узла рабочего процесса.
Нажмите «Просмотреть журнал», чтобы просмотреть последний статус выполнения текущего рабочего процесса.
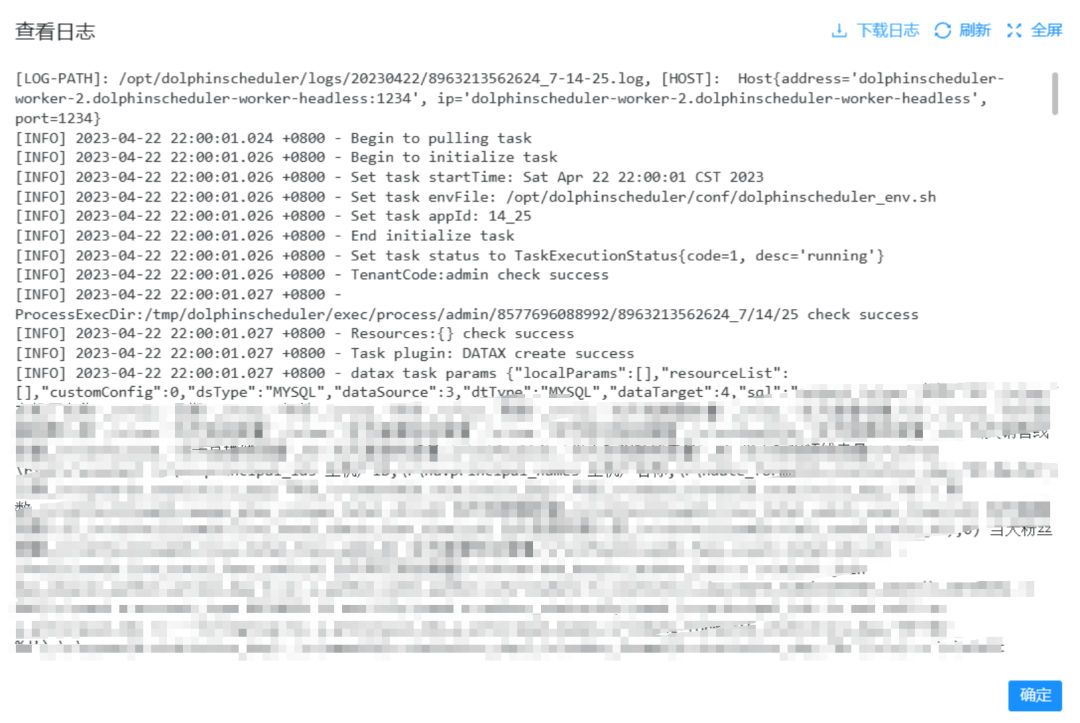
Обычно, если есть ошибка,Сообщение об ошибке будет отображаться в нескольких строках на странице наконец.,Вы можете настроить Рабочий по подсказкам Процесс Квест.
Приложение: Решение проблемы «грязных» данных DataX.
В процессе извлечения при передаче данных DataX возникнут проблемы с некорректными данными. На данный момент вам необходимо настроить шаблон json, чтобы расширить порог некорректных данных.
1. После редактирования SQL запустите его. Обратите внимание, что запуск завершится неудачей. Найдите в журнале ошибок оператор json, содержащий поля «содержимое» и «настройка».

2. Скопируйте весь оператор json. Обратите внимание, что пароль — «*****», и его необходимо заменить вручную. Используйте этот оператор в качестве значения и добавьте ключ «job», например.
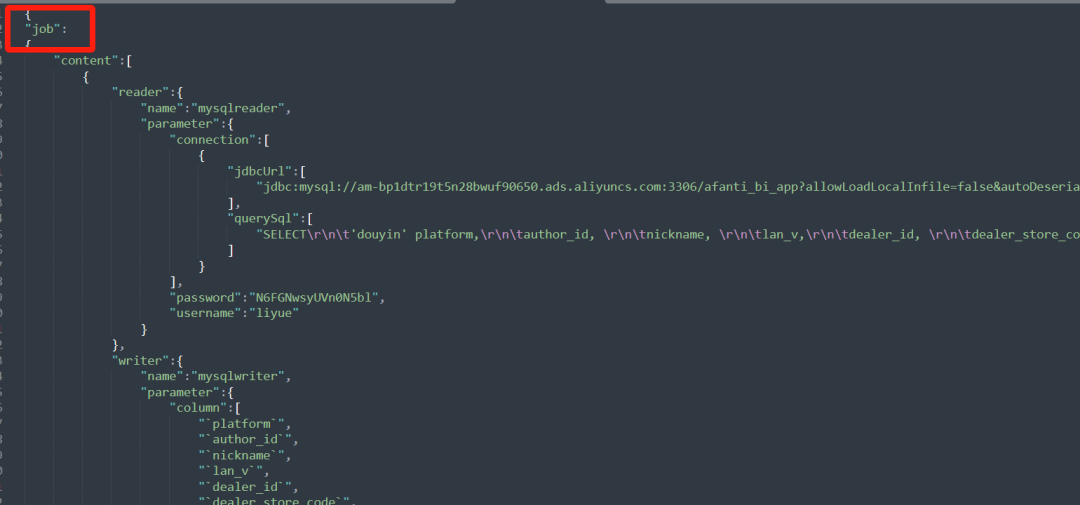
3. Найдите поле «настройки», измените процент и запись, #установите порог максимального количества записей грязных данных (значение записи) или порог доли грязных данных (значение процента, когда количество или процент )

В определении рабочего процесса выберите «Пользовательский шаблон» и скопируйте отредактированный json.

наконец
ЯШурин,Каждый деньПоделитесь вопросом на собеседовании по SQL,И со всемиРасскажите о том, что вы видели и слышали в последнее время。
Добро пожаловать на внимание, увидимся в следующем выпуске~



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
