Проектирование облачного хранилища данных в эпоху Data + AI

Автор | Чжан Яньфэй
Редактор | Дэн Яньцинь
Мы переживаем золотой век данных + ИИ, и ИИ продемонстрировал большой потенциал в области больших данных. Глобальная конференция по разработке программного обеспечения QCon Guangzhou Station пригласила г-на Чжана Яньфея, соучредителя Datafuse Labs, выступить с речью под названием «Databend: исследование дизайна облачных хранилищ в эпоху больших моделей». Эта статья составлена на основе общедоступного аккаунта Databend. Полная загрузка слайдшоу: https://qcon.infoq.cn/2023/guangzhou/presentation/5257
В этом обмене основное внимание уделяется исследованию дизайна Cloud Warehouse в эпоху больших моделей, анализу того, как использовать открытые и коммерческие LLM для улучшения возможностей Cloud Warehouse и достижения более интеллектуального и автоматизированного анализа данных. Этот обмен в основном делится на две части:
- Как использовать современный цифровой склад
- Как объединить хранилище данных с ИИ
Зачем вам современное облачное хранилище данных
Когда пользователи хотят выполнить анализ больших данных, они ожидают, по сути, следующего:
Я собираюсь провести анализ и хочу, чтобы он был сделан как можно быстрее, и в то же время я хочу платить только за те ресурсы, которые реально использую.
Стоимость = фактическое использование ресурсов * время использования.
Давайте обсудим, как хранилище данных должно удовлетворить эту потребность. Во-первых, давайте посмотрим на проблемы, с которыми сталкивается традиционная архитектура хранилища данных при удовлетворении этого спроса.
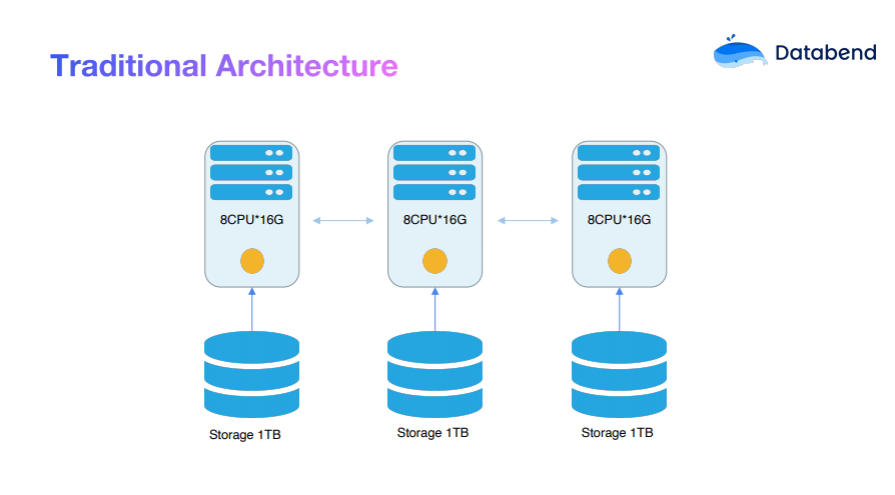
В традиционной архитектуре хранилища данных обычно применяется архитектура без совместного использования, при этом процессор, память и хранилище тесно связаны. Эту схему обычно называют схемой «север-юг», которая основана на секционировании данных для разделения вычислительных задач. . Однако в этой архитектуре часто создается большое количество избыточных копий, что приводит к пустой трате ресурсов. Когда нам потребуется добавить новые узлы, мы столкнемся с проблемами миграции данных и балансировки, в результате чего доставка ресурсов будет не очень своевременной.

Таким образом, в традиционной архитектуре пользовательские данные и вычисления полностью связаны друг с другом, а общие затраты относительно высоки:
Стоимость традиционной архитектуры хранилища данных = ресурсы * время запуска
Так как же новое поколение облачной архитектуры Databend отвечает этой потребности?
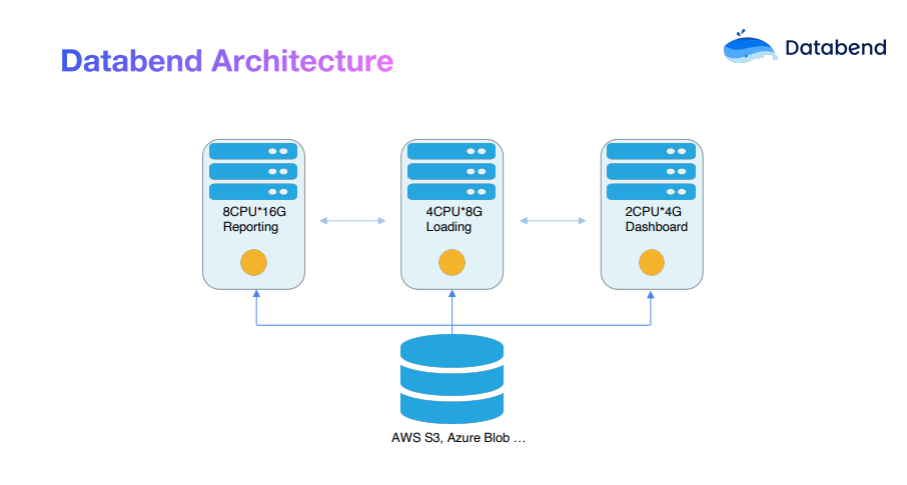
Архитектура Databend внесла множество улучшений в дизайн:
- Проектирование на основе общего хранилища:Databend Поддерживает различные хранилища объектов, в том числе Amazon S3, Azure Blob, OSS, COS ждать. Эта модель дизайна позволяет платить за хранение в зависимости от использования.,Высокая эластичность. Когда вычислительные узлы необходимо расширить,данные Нет необходимости делать какие-либо шаги.
- Архитектура разделения хранилища и вычислений:существоватьэтот Архитектура Вниз,Вычислительные узлы могут запускаться динамически по требованию. Когда бизнес простаивает,Вычислительные узлы автоматически перейдут в спящий режим,Таким образом эффективно экономится ресурс.
- Проектирование объектно-ориентированного планировщика хранилища:Поскольку объектное хранилище хранитсуществовать Различные ограничения и склонность к дрожанию,Он не предназначен для проектирования хранилищ данных. поэтому,Databend Планировщик и оптимизатор сильно оптимизированы для хранения объектов. Например, среда выполнения хранения и существования в планировщике имеет функцию двусторонней чувствительности к давлению и существуетосуществлять. GroupBy shuffle , при передаче указывается адрес файла, а не данные.
- Высокая степень эластичности:С помощью Возможности Kubernetes (k8s), Databend Возможность быстрого эластичного масштабирования для адаптации к различным потребностям бизнеса и изменениям нагрузки.

в дизайне Databend На данный момент мы использовали несколько отличных проектов хранилищ данных, имеющихся в настоящее время на рынке. Например, мы ссылаемся на Clickhouse Векторизованный дизайн для улучшения автономной производительности. В то же время мы также узнали от Snowflake Преимущества кластеризации для расширения возможностей распределенных вычислений. Приняв во внимание эти преимущества, мы выбрали Rust языкруководить Переработка и внедрение。В Databend есть еще одно важное улучшение. Мы превратили каждый функциональный уровень в микросервис.,Итак, из Архитектуры это примерно так:
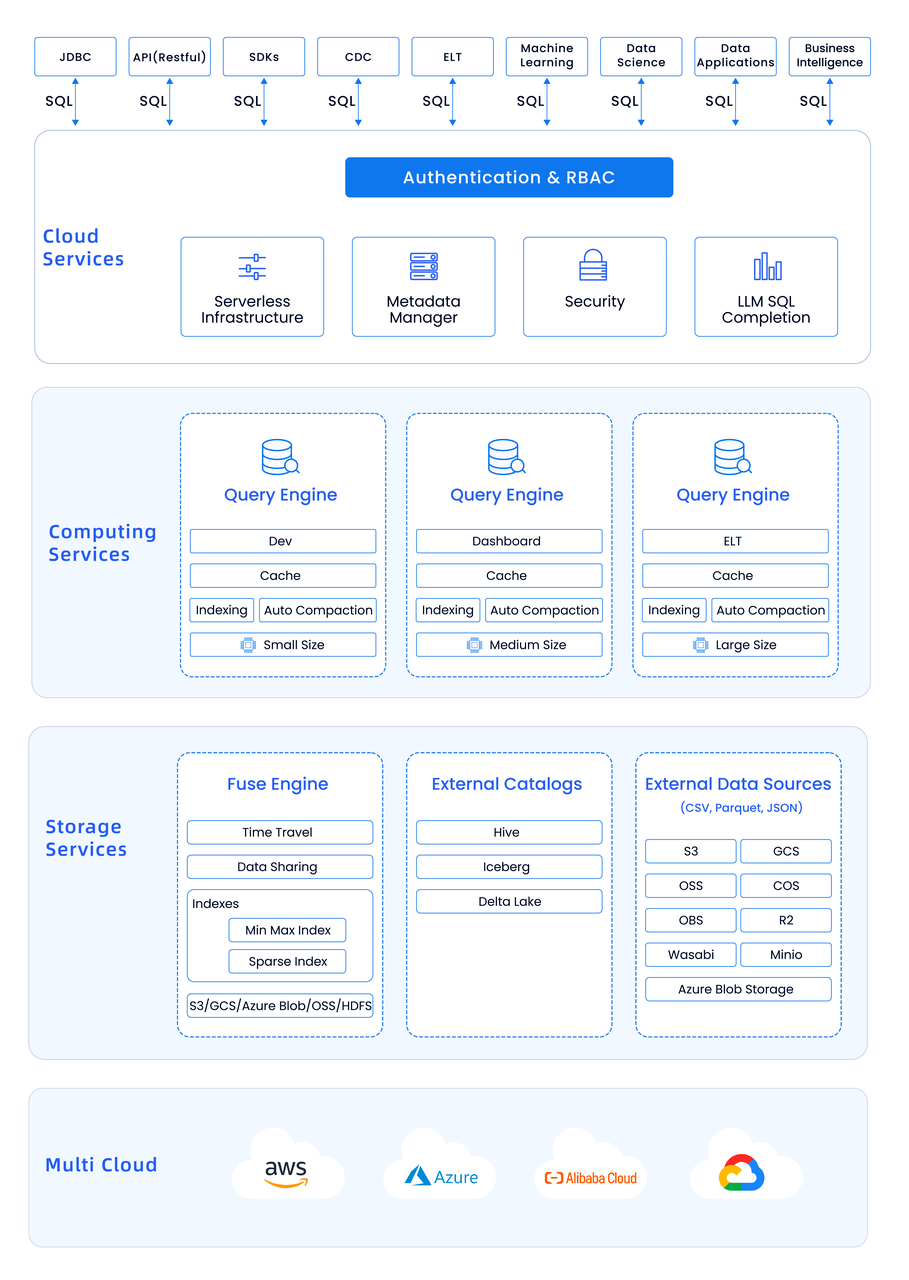
Однако процесс проектирования Databend также полон проблем, поскольку проектирование облачных хранилищ данных существенно отличается от проектирования традиционных хранилищ данных. Основные проблемы в основном отражаются в следующих аспектах:
Затраты на сетевой трафик при записи больших объемов данных
При обработке крупномасштабной записи данных в облаке могут возникнуть значительные расходы на сетевой трафик.
Проблемы проектирования на основе объектного хранилища
Поскольку само объектное хранилище не предназначено специально для хранилищ данных, вы можете столкнуться с различными проблемами при балансировке ограничений задержки и пропускной способности ЦП, сетевого ввода-вывода и локального ввода-вывода.
Повышение интеллекта облачного хранилища данных Databend
Мы надеемся разработать систему, которая сможет автоматически обрабатывать интеллектуальную индексацию для повышения эффективности запросов.
Проблемы интеграции между хранилищем данных и озером данных (Data Lake)
Хотя объединение этих двух технологий может создать новые проблемы проектирования, мы твердо уверены, что за Lake-First будущее. Поэтому Databend использует удобный способ каталога для поддержки чтения данных из Hive, Iceberg и т. д.
В течение последних двух лет мы сосредоточились на исследовании и решении вышеуказанных проблем. В настоящее время Databend выпустила версию v1.2, которая успешно решает основные проблемы, возникшие выше. Конечно, нам еще предстоит изучить много возможностей для оптимизации. В настоящее время Databend используется многими компаниями в производственных средах.
👨🏻💻 Далее, давайте посмотрим Производительность нового поколения Databend Архитектурасуществовать в реальной производственной среде。к Внизданныевсе от пользователейсуществоватьреальная сцена Внизизобратная связь:
- существоватьзаменять Trino/Presto в сцене,75% экономия средств。
- существуют замены в Elasticsearch из сценария,90% экономия средств。
- существующий архив из сценария низкочастотного запроса,95% экономия средств。
- существующий сценарий хранения и анализа журналов,75% экономия средств。
- каждый деньПревосходить 1PB+ изданныепроходить Databend Храните и анализируйте,за пользователя в месяцсэкономлено миллионы доллароврасходы。
Эти данные показывают, что Databend может значительно снизить затраты пользователей, полностью отражая огромную ценность нового поколения облачной архитектуры хранилища данных.

Хранилище данных и искусственный интеллект
Сейчас мы переживаем золотой век больших данных и искусственного интеллекта. В предыдущем разделе мы обсудили соответствующее содержание анализа больших данных. Далее давайте поговорим об ИИ.
Когда мы думаем об ИИ, в первую очередь на ум приходят следующие темы:
- Модель LLM (большая языковая модель)
- нейронная сеть
- генерация контента
- Интеллектуальные вопросы и ответы
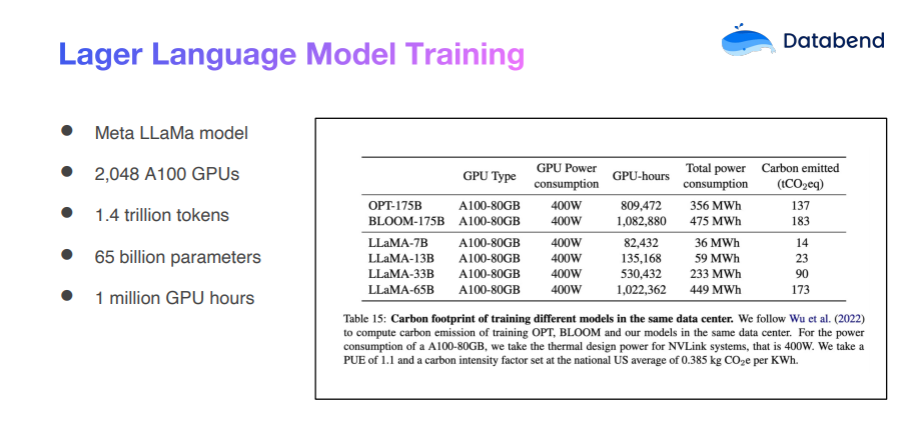
Однако проблемы обучения большой модели с нуля, такой как модель LLaMa от Meta, являются значительными, особенно с точки зрения стоимости. Общедоступные данные показывают, что однократное обучение модели может стоить им миллионы долларов.
По результатам нашего тестирования различных коммерческих моделей и моделей с открытым исходным кодом, представленных на рынке, модель OpenAI GPT хорошо работает в коммерческих условиях (по состоянию на май 2023 г.). Особенно в интеллектуальных системах обслуживания клиентов мы придаем большое значение способности модели рассуждать на основе фрагментов контента и слов-подсказок (подсказка).
Вот рейтинг возможностей модели с lmsys.org (https://lmsys.org/) для справки:

На данный момент направления применения ИИ, которые меня больше волнуют:
- Интеллектуальные вопросы и ответы (вопросы и ответы)
- Полностью автоматизированный анализ больших данных (AutoInsights)
Интеллектуальная система вопросов и ответов (Вопрос и ответ)
Сначала давайте разберемся, как работает интеллектуальная система ответов на вопросы, а затем рассмотрим, как реализовать эту функциональность в хранилище данных.
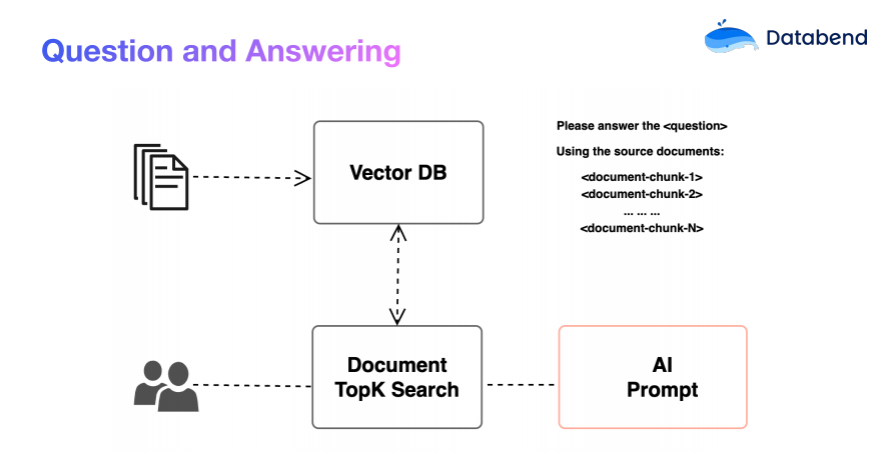
Из-за ограничения входных данных, обрабатываемых большими моделями каждый раз, нам необходимо разбивать большой объем текста на небольшие фрагменты и векторизовать их для хранения в векторной базе данных (Vector Database)середина。Такая конструкция позволяет упростить принцип работы интеллектуальной системы вопросов и ответов до следующих четырех шагов.:
- Входной вопрос векторизуется для получения вектора вопросов QV.
- использоватьвекторная база данныхруководить Поиск по сходству, тем самым выяснив QV Максимально похожая коллекция фрагментов документов (Documents).
- По заданному слову-подсказке (Prompt) найденный фрагмент документа Генеративная обработка ИИ。
- Вернуть обработанный ответ.
Друзья, кто хочет узнать об интеллектуальной системе вопросов и ответов, рекомендую посетить эту ссылку: https://ask.databend.rs/. Это интеллектуальная система вопросов и ответов, основанная на документах Databend. Она полностью построена на базе Databend.
существовать Databend середина,Мы реализовали такие вещи, какВекторизация текста(Embedding)、векторная база данных(Vector Database)、Поиск по сходствуи другие функции,также представил Генеративная обработка ИИ(полировать)и другие технологии。
проходить Databend Диапазон SQL функция(ИИ Функции) пользователи могут легко использовать эти функции для создания собственной интеллектуальной системы вопросов и ответов. Это не только значительно упрощает процесс построения интеллектуальных систем вопросов и ответов, но и предоставляет больше возможностей для использования больших данных. Изгиб данных Позволяет осуществлять существование в одной системе OLAP и обработку векторных данных, а также могут быть подключены к различным крупным моделям для дальнейшего расширения границ больших данных.

Полностью автоматизированный анализ (AutoInsights)

SQL — это огромная проблема. Можем ли мы упростить этот шаг?,позволять AI Создается автоматически на основе структуры таблицы и сводки данных. SQL Шерстяная ткань?Ответ: даиз。в настоящий момент,Databend Cloud Эта функция запущена.
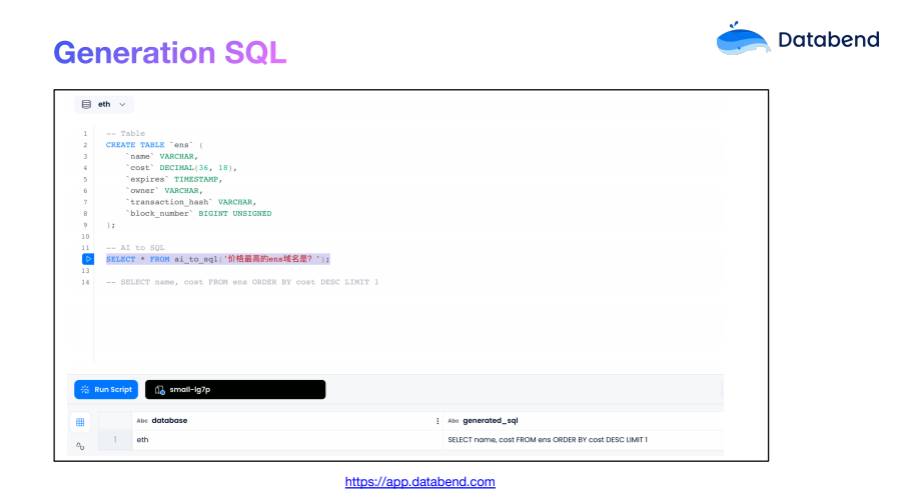
существовать Databend , большинство столбцов были проиндексированы, и в сочетании с хорошей конструкцией оптимизатора сгенерированные SQL Можетсуществовать Не требуется ручное вмешательствоиз Состояние Внизбыстрыйосуществлять。
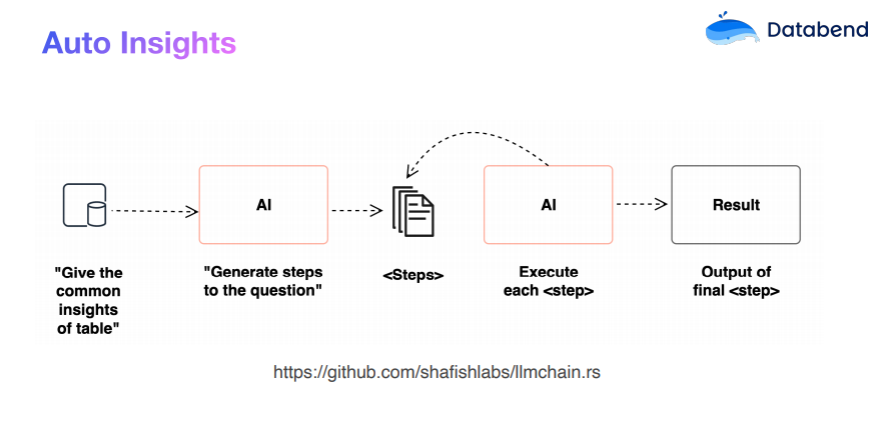
Таким образом, наш автоматизированный анализ можно разбить на следующие этапы:
- Получить структуру таблицы
- позволять AI Согласно структуре таблицы Узел упомянуты некоторые из наиболее популярных из них. вопрос
- Преобразуйте эти вопросы в SQLDatabend для выполнения SQL и получения результатов.
- Автоматически создавать аналитические отчеты на основе результатов
Весь процесс в основном:
Подвести итог
Мы переживаем Data + AI Золотой век ИИ Уже большие поля данных продемонстрировали большой потенциал, например OpenAI Недавно запущенный ChatGPT Code Переводчик, это все знаки AI Это может помочь нам извлечь ценность из данных более инновационными способами.
Databend в Дизайн с самого начала полностью учитывал этот спрос на интеллект, поэтому мы разработали AI Функции. Это делает Databend Не просто хранилище данных; Large Language Model(LLM)из Вход,Можетпроходить SQL выражать AI способности, будущее AI Будет стандартным для каждого хранилища данных.
Мы твердо верим, что Databend продолжит лидировать в инновациях хранилищ данных и приносить больше пользы пользователям. Databend может не только помочь вам сократить расходы и повысить эффективность, но также использовать возможности искусственного интеллекта для извлечения большей ценности данных, что еще больше снижает порог для анализа больших данных.
Представление автора
Чжан Яньфэй,Datafuse Labs Соучредитель , бывший член команды ядра базы данных Alibaba Cloud и бывший руководитель группы базы данных Qingyun. Открытый исходный код Databend Главный ответственный за проект. присутствовал много раз QCon и выступал в качестве приглашенного докладчика & Продюсер.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
