Проект 3: Flume собирает данные журналов в HDFS.
Введение
- Flume — это распределенная система для сбора, агрегирования и передачи больших объемов данных журналов. Он часто используется в сочетании с HDFS (распределенной файловой системой Hadoop) в экосистеме Hadoop и может хранить данные в HDFS.
- Благодаря следующей конфигурации Flume может эффективно и в режиме реального времени собирать данные журналов из локального каталога и сохранять их в HDFS для облегчения последующего анализа и обработки данных.
- Файл конфигурации Flume обычно содержит следующие части: источники (источники данных), приемники (назначение данных), каналы (каналы данных).
Начало рабочего процесса
- Сначала создайте файл конфигурации для flume для сбора данных в hdfs в каталоге /opt/module/flume/conf/job.
# Перейдите в каталог вакансий
cd /opt/module/flume/conf/job
# Редактировать файл конфигурации
vim hdfs.conf
hdfsAgent.sources = hdfsSource
hdfsAgent.sinks = hdfsSinks
hdfsAgent.channels = hdfsChannel
hdfsAgent.sources.hdfsSource.type = spooldir
hdfsAgent.sources.hdfsSource.channels = hdfsChannel
hdfsAgent.sources.hdfsSource.spoolDir = /opt/module/flume/conf/data/hdfs
hdfsAgent.sources.hdfsSource.fileHeader = true
hdfsAgent.sinks.hdfsSinks.type = hdfs
hdfsAgent.sinks.hdfsSinks.hdfs.path = hdfs://master:8020/flume/events/%y-%m-%d/%H%M/%S
hdfsAgent.sinks.hdfsSinks.hdfs.filePrefix = events
hdfsAgent.sinks.hdfsSinks.hdfs.fileSuffix = log
hdfsAgent.sinks.hdfsSinks.hdfs.round = true
hdfsAgent.sinks.hdfsSinks.hdfs.roundValue = 10
hdfsAgent.sinks.hdfsSinks.hdfs.roundUnit = minute
hdfsAgent.sinks.hdfsSinks.hdfs.minBlockReplicas = 1
hdfsAgent.sinks.hdfsSinks.hdfs.rollInterval = 0
hdfsAgent.sinks.hdfsSinks.hdfs.rollSize = 134217728
hdfsAgent.sinks.hdfsSinks.hdfs.rollCount = 0
hdfsAgent.sinks.hdfsSinks.hdfs.idleTimeout = 60
hdfsAgent.sinks.hdfsSinks.hdfs.fileType = DataStream
hdfsAgent.sinks.hdfsSinks.hdfs.useLocalTimeStamp = true
hdfsAgent.channels.hdfsChannel.type = memory
hdfsAgent.channels.hdfsChannel.capacity = 1000
hdfsAgent.channels.hdfsChannel.transactionCapacity = 100
hdfsAgent.sources.hdfsSource.channels = hdfsChannel
hdfsAgent.sinks.hdfsSinks.channel = hdfsChannelПодробное объяснение параметров файла конфигурации
- Источники
hdfsAgent.sources = hdfsSource
Здесь файл с именем hdfsSource источник данных.
hdfsAgent.sources.hdfsSource.type = spooldir
Тип источника данных: каталог спулинга, значит Flume Будет прослушивать и собирать файлы из указанного каталога.
hdfsAgent.sources.hdfsSource.channels = hdfsChannel
Этот источник данных будет использовать файл с именем hdfsChannel канал для передачи данных.
hdfsAgent.sources.hdfsSource.spoolDir = /opt/module/flume/conf/data/hdfs
Это Flume Путь к каталогу для мониторинга. Он будет проверять наличие новых файлов в этом каталоге.
hdfsAgent.sources.hdfsSource.fileHeader = true
это означает Flume Информация заголовка файла будет включена в собранные файлы, обычно используемые для записи метаданных.- Куда идут данные (приемники)
hdfsAgent.sinks = hdfsSinks
Здесь файл с именем hdfsSinks куда идут данные.
hdfsAgent.sinks.hdfsSinks.type = hdfs
Тип назначения данных: HDFS, что указывает на то, что данные будут записаны в HDFS середина.
hdfsAgent.sinks.hdfsSinks.hdfs.path = hdfs://master:8020/flume/events/%y-%m-%d/%H%M/%S
Эти данные хранятся в HDFS Формат пути в формате , включая дату и время. лоток Каталог будет автоматически создан по этому пути в зависимости от времени сбора.
hdfsAgent.sinks.hdfsSinks.hdfs.filePrefix = events
Префикс выходного файла: “events”。
hdfsAgent.sinks.hdfsSinks.hdfs.fileSuffix = log
Суффикс выходного файла: “.log”。
hdfsAgent.sinks.hdfsSinks.hdfs.round = true
Указывает, что механизм прокрутки включен и файлы разделены по времени.
hdfsAgent.sinks.hdfsSinks.hdfs.roundValue = 10
Прокрутка данных срабатывает каждые 10 минут.
hdfsAgent.sinks.hdfsSinks.hdfs.roundUnit = minute
Указанная здесь единица времени — минуты.
hdfsAgent.sinks.hdfsSinks.hdfs.minBlockReplicas = 1
Минимальное количество копий 1, означает письмо HDFS Будет копия данных.
hdfsAgent.sinks.hdfsSinks.hdfs.rollInterval = 0
Установка значения 0 означает, что прокрутка не будет принудительной в зависимости от времени, в основном через round Механизм прокрутки файлов.
hdfsAgent.sinks.hdfsSinks.hdfs.rollSize = 134217728
Размер файла достигает 128MB будет прокручиваться.
hdfsAgent.sinks.hdfsSinks.hdfs.rollCount = 0
Установка значения 0 означает прокрутку без ограничения количества записей.
hdfsAgent.sinks.hdfsSinks.hdfs.idleTimeout = 60
Если данные не поступают, файл будет закрыт через 60 секунд.
hdfsAgent.sinks.hdfsSinks.hdfs.fileType = DataStream
Этот параметр указывает, что тип файла является потоком, а это означает, что данные будут записываться в виде потока.
hdfsAgent.sinks.hdfsSinks.hdfs.useLocalTimeStamp = true
Включите локальную временную метку в качестве временной метки файла.- Каналы передачи данных
hdfsAgent.channels.hdfsChannel.type = memory
Тип канала — канал памяти, что означает, что данные передаются в памяти.
hdfsAgent.channels.hdfsChannel.capacity = 1000
Канал памяти может хранить до 1000 событий.
hdfsAgent.channels.hdfsChannel.transactionCapacity = 100
В каждой транзакции может быть обработано не более 100 событий.Создание связанных каталогов
# Создайте каталог /flume/events на hdfs.
hadoop fs -mkdir -p /flume/events
# Добавить разрешения
hadoop fs -chmod 777 -R /flume/*
# Создать путь к файлу журнала
mkdir -p /opt/module/flume/conf/data/hdfsСкрипт создания журнала моделирования
- Функция этого сценария — создать смоделированный файл журнала и поместить его в указанный каталог для тестирования или сбора данных.
- Создайте каталог для хранения файлов журналов.
- Создает 5 смоделированных файлов журнала, каждый из которых содержит запись журнала с отметкой времени.
- Каждый файл журнала создается с интервалом в 1 секунду для имитации фактического процесса создания журнала.
# Создайте каталог для хранения скрипта
mkdir -p /opt/module/flume/job-shell
# Переключиться в этот каталог
/opt/module/flume/job-shell
# Редактировать сценарий
vim logData_To_Hdfs
#!/bin/bash
# Установить путь сохранения
SPOOL_DIR="/opt/module/flume/conf/data/hdfs"
# создавать spoolDir путь (если его нет)
mkdir -p "${SPOOL_DIR}"
# генерировать 5 случайные файлы журналов
for i in {1..5}; do
LOG_FILE="${SPOOL_DIR}/logfile_${i}.log"
echo "INFO: This is a simulated log entry $(date '+%Y-%m-%d %H:%M:%S')" > "${LOG_FILE
echo "Generated ${LOG_FILE}"
sleep 1 # Аналоговое сокращение интервалов
done
# Добавить разрешения
chmod 777 ./*скрипт запуска Flume
- Этот сценарий удобно запускает задачи Flume без ручного ввода всех команд. Он также гарантирует, что процесс Flume продолжает работать в фоновом режиме, что делает его пригодным для использования в производственных средах.
cd /opt/module/flume/job-shell
vim hdfs
#!/bin/bash
echo " --------запускать master Соберите данные журнала дляHDFS --------"
nohup /opt/module/flume/bin/flume-ng agent -n hdfsAgent -c /opt/module/flume/conf/ -f /opt/module/flume/conf/job/hdfs.conf >/dev/null 2>&1 &
# Добавить разрешения
chmod 777 ./*Начать процесс
# Сначала запустите все процессы Hadoop
allstart.sh
# Переключиться на путь запуска скрипта
cd /opt/module/flume/job-shell
# Запустите скрипт сбора лотковhdfs
# Запустить скрипт создания файла журнала
logData_To_Hdfs- Запустите скрипт сбора лотков

- Запустить скрипт создания файла журнала
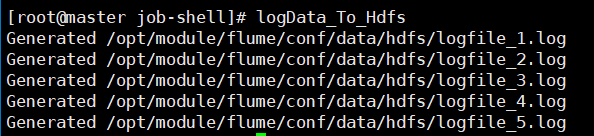
- Просмотр содержимого одного из файлов журнала

Результаты испытаний
- Команда просмотра результатов сбора файлов
hadoop fs -ls -R /flume
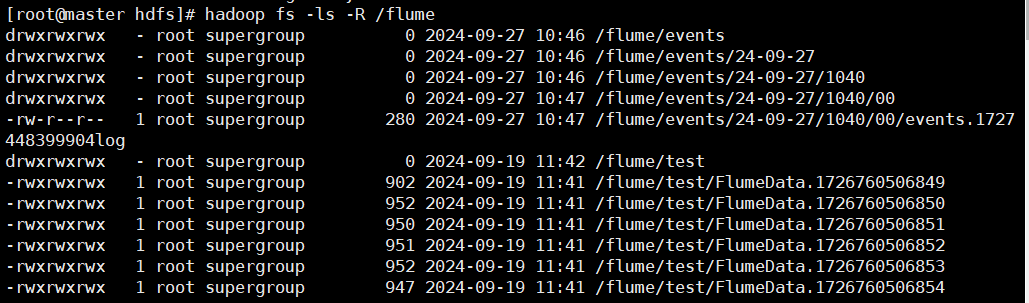
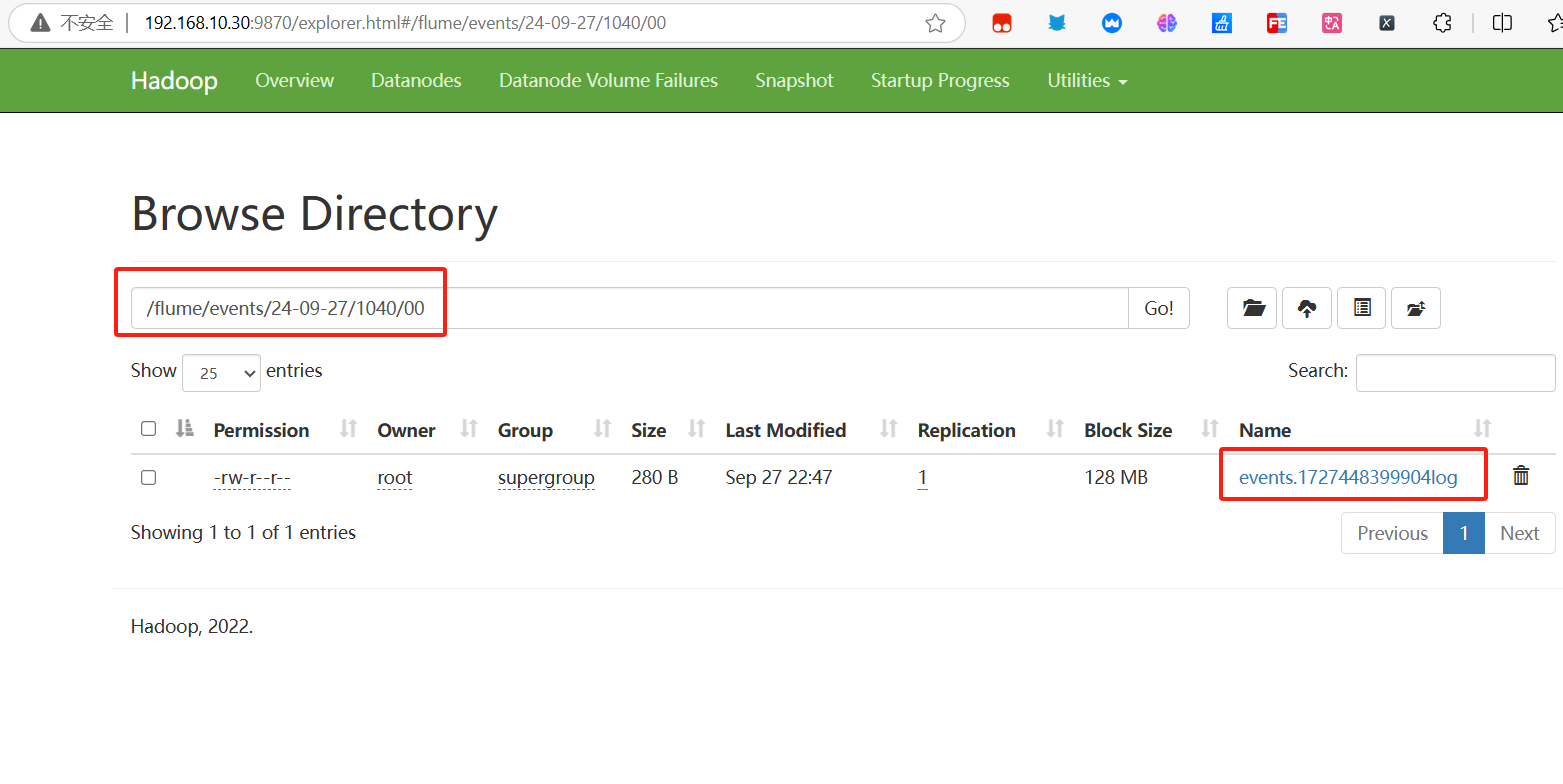
- Результаты просмотра файловой системы



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
