Применение и настройка Apache DolphinScheduler в среде больших данных
“
Добрый день, меня зовут Ли Цзиньюн, я архитектор платформы данных Zhengcai Cloud. Я в основном отвечаю за базовую архитектуру больших данных и разработку данных в Zhengcai Cloud. Я также являюсь членом PMC Dolphinscheduler. Сегодня я расскажу о некоторых замечательных функциях версии Apache Dolphinscheduler 2.0.9. Причина выбора этой темы заключается в том, что в ходе развития версии 2.0.
”
Текст |Ли Цзинён
Редактирование | Цзэн Хуэй
Представление преподавателя

Ли Цзиньён
Apache DolphinScheduler PMC
В этой статье в основном рассматриваются три основные темы.:первый,Изучите общие Режим настройки рабочего процесс, во-вторых, внедрить ДС Важные функциональные особенности версии 2.0.X и, наконец, общие методы настройки в производственной среде.
01
Режим настройки рабочего процесса
В Apache DolphinScheduler Режим настройки рабочего процесса любим разработчиками за его разнообразие и гибкость.
Хотя эти шаблоны конфигурации, возможно, уже всем знакомы, в этой статье они кратко представлены.
основной Конфигурация Шаблоны включают в себяРежим одного DAG, последовательный режим подпроцесса и планирование зависимостей рабочего процесса в соответствии с уровнем хранилища данных.режим, а такжеПланируйте задачи и запускайте пакеты в соответствии с уровнем хранилища данных.модель。
Эти режимы широко используются на таких платформах, как Zhengcai Cloud, поэтому мы нашли и исправили множество скрытых проблем, а также предоставили отзывы сообществу разработчиков ПО с открытым исходным кодом.
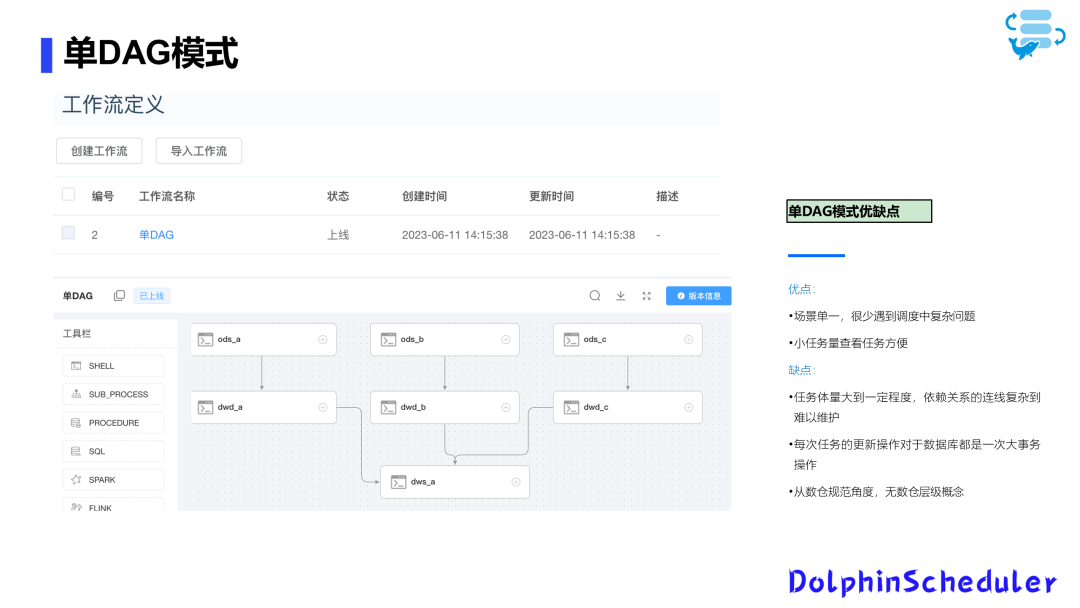
Режим одной группы обеспечения доступности баз данных — это общий режим конфигурации, который позволяет запускать задачи в группе обеспечения доступности баз данных в соответствии с определенной конфигурацией.
Хотя эта модель проще и понятнее.,Но когда количество задач огромно,Становится очевидной сложность обслуживания. В DS версии 2.0 и более поздних версиях,DAGобновление сталоКрупные транзакционные операции,Это оказывает большое давление на базу данных.
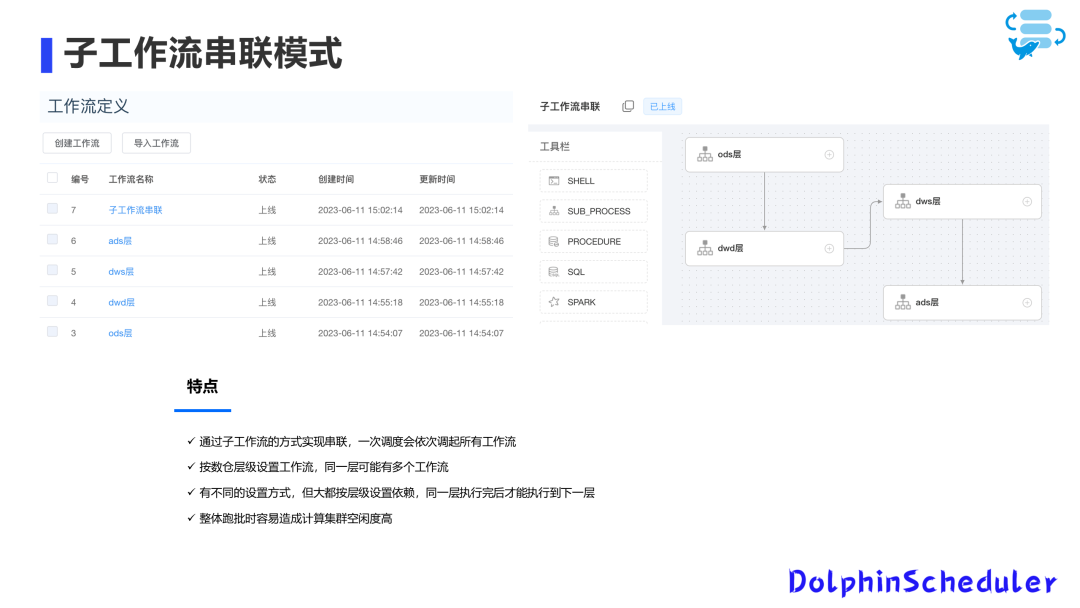
Планирование шаблонов зависимостей рабочих процессов по уровням хранилища данных является относительно сложным.
Это соответствует спецификации хранилища данных, например, в соответствии с общими уровнями хранилища данных, такими как уровень ODS, уровень DW, уровень DWS и уровень ADS, планирование выполняется путем объединения подпроцессов на этих уровнях.
Такая закономерность может привести к более высокому простою вычислительного кластера во время общей пакетной обработки.
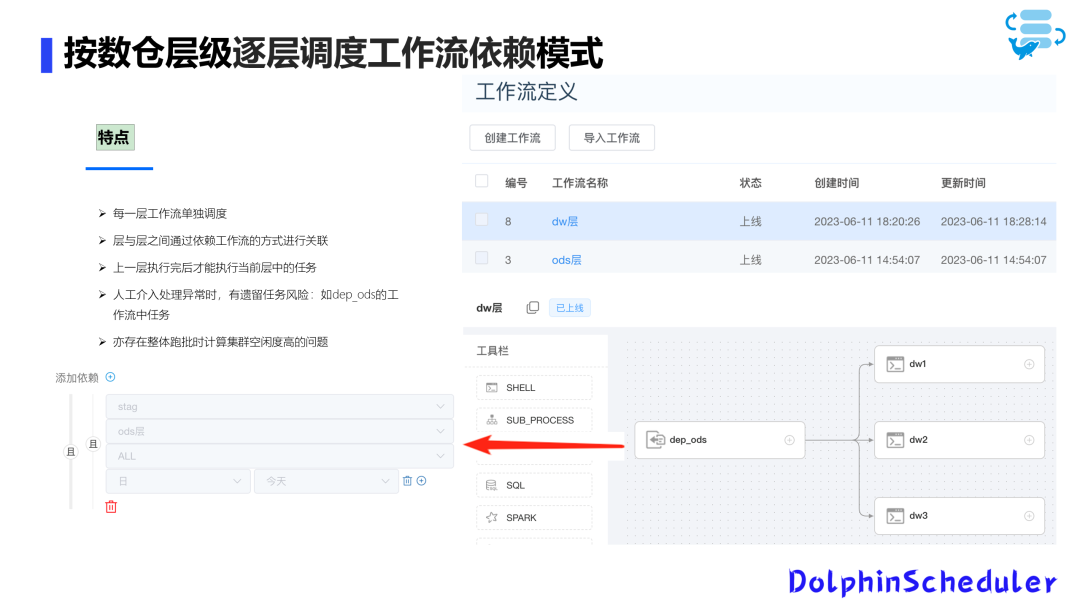
Пакетный режим планирования задач по уровню хранилища данных является более гибким. Он планирует задачи по зависимым узлам, а не по конфигурации подпроцесса.

Этот режим позволяет настроить рабочие процессы в соответствии с уровнями хранилища данных и доменами данных, поэтому блокировка определенной некритической задачи не повлияет на другие задачи.
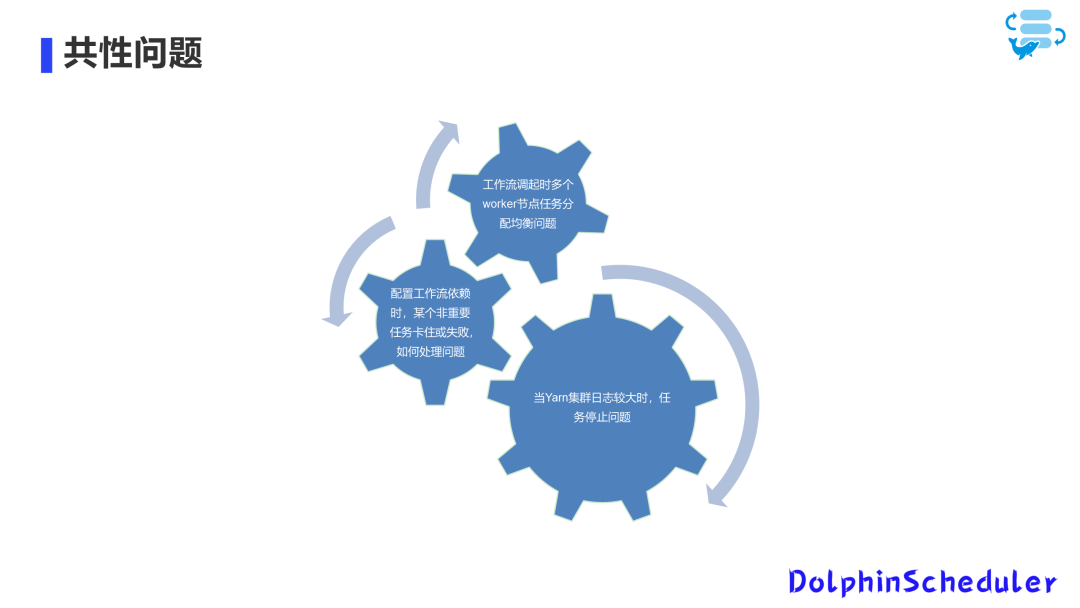
Эти режимы конфигурации имеют свои особенности и применимые сценарии. В разных режимах мы также столкнемся с некоторыми проблемами и проблемами.
Например, во время планирования рабочего процесса неравномерное распределение нескольких рабочих узлов может привести к пустой трате вычислительных ресурсов.
Кроме того, как обрабатывать зависимости, когда некритическая задача зависает или дает сбой, также является проблемой, которую необходимо решить. Остановка задач также может стать проблемой при обработке больших объемов журналов YARN.
В ходе разработки версии 2.0 мы обнаружили эти проблемы и предприняли соответствующие решения.
02
Возможности версии 2.0.X
Далее давайте углубимся в DS. 2.0.XверсияНесколько важных особенностей。Эти функции включают в себяmasterмеханизм отзыва、Зависимость от принудительных успешных изменений в рамках всей задачи、Рабочий Уведомления о событиях остановки процесса и обработка нестандартных ситуаций.

В процессе планирования рабочего процесса,Может возникнуть неравномерное распределение задач,Это приводит к пустой трате вычислительных ресурсов.
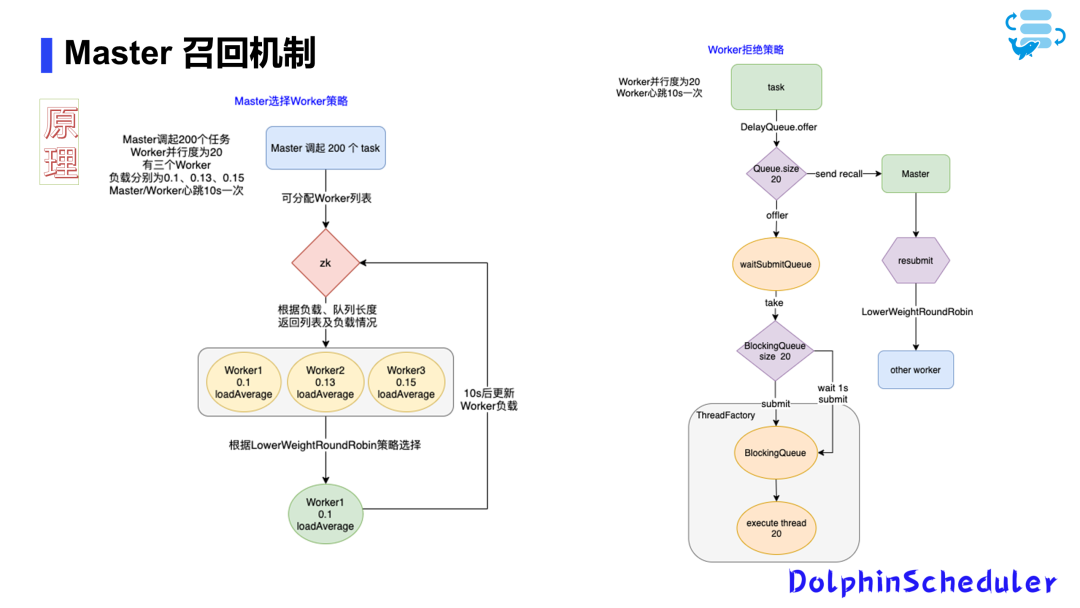
Для решения этой проблемы мы ввели механизм отзыва мастеров, позволяющий решить проблему неравномерного распределения задач путем перераспределения задач.
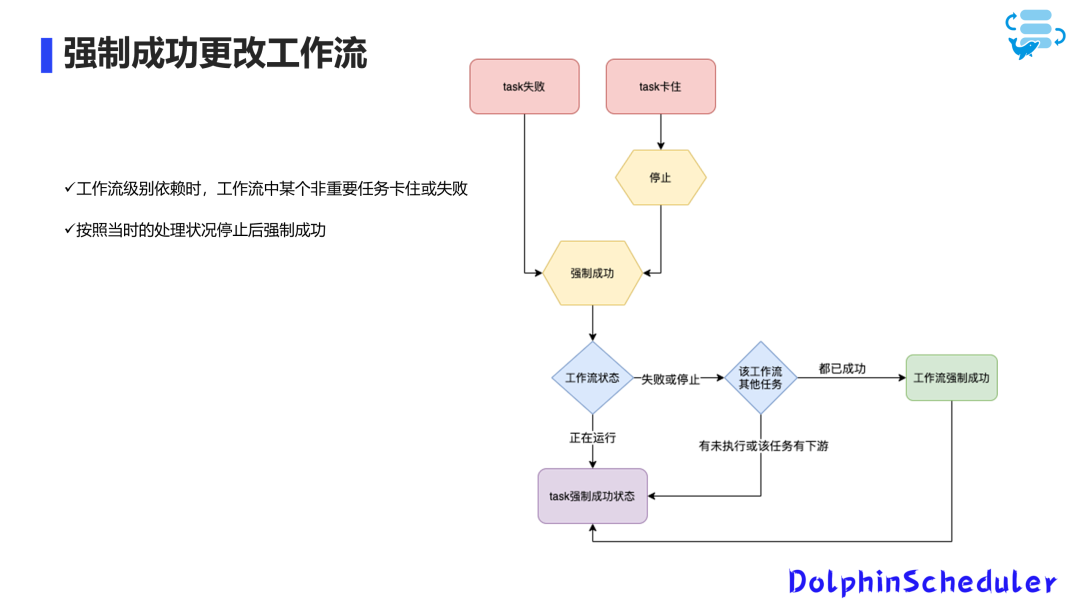
Еще одна важная особенность — возможность принудительного внесения успешных изменений в зависимости от всей задачи.
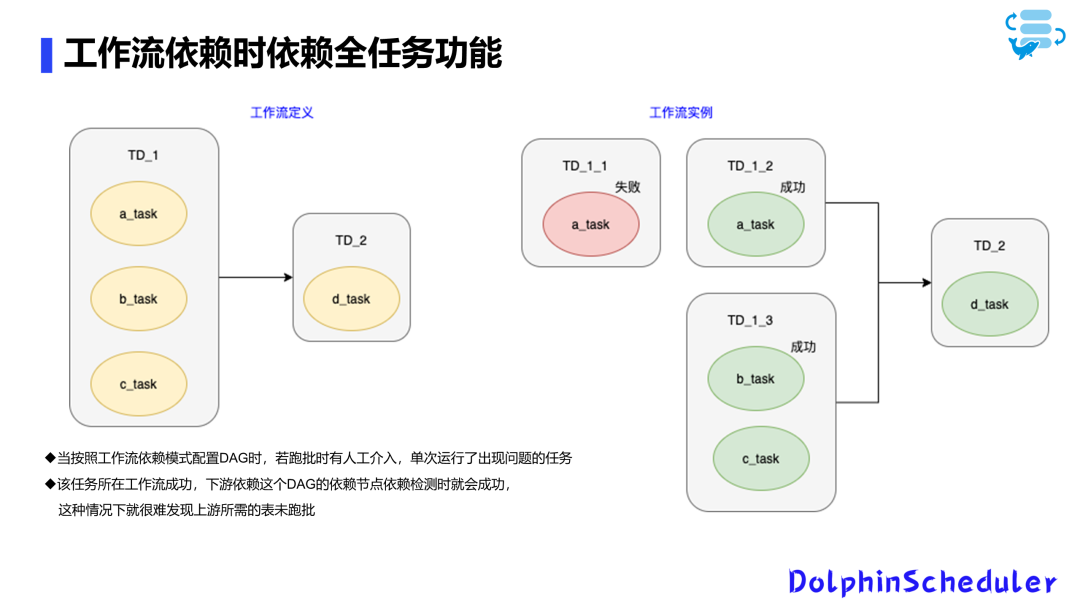
В предыдущих версиях мы сталкивались с ситуациями, когда определенная задача требовала ручного вмешательства, но рабочий процесс, в котором она выполнялась, был успешным, что приводило к выполнению нижестоящих зависимых задач, но вышестоящие необходимые задачи не выполнялись.
Для решения этой проблемы у нас есть процессизУлучшены методы обнаружения зависимостей.,Удалить его из зависимости Рабочий процесс меняется на задачи зависимостей.
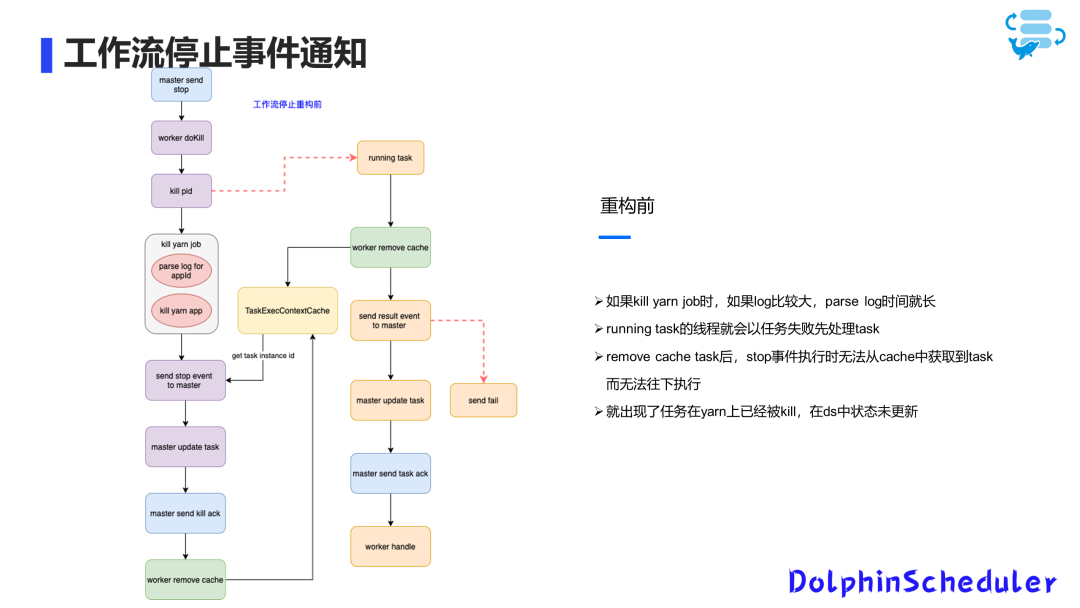
Уведомления о событиях остановки рабочего процесса также получили значительные улучшения. В предыдущем отзыве кто-то упомянул, что статус задачи не менялся при ее остановке.
Мы реструктурировали код, связанный с остановкой задачи, и добавили новый поток обработки, чтобы решить проблему обновления статуса при остановке задачи.
Наконец, мы также исправили DS 2.0.XВ версииНекоторые другие проблемы, которые возникают,например Рабочий подпрограмма завершения процесса Проблемы, возникающие после процесса, проблемы, которые невозможно отправить повторно после того, как задание не было отправлено, и Рабочий Такие проблемы, как недопустимое время повтора при сбое задачи процесса.
В ответ на эти проблемы мы произвели эффективный ремонт и улучшения для повышения стабильности и надежности системы.
03
Настройка в производственной среде
Третья часть будет использовать некоторую производственную среду.изОпыт тюнинга,включая планированиеУправление историей, очистка версий, концепции настройки и конфигурация кластера。также,Также приводится обсуждение некоторых параметров и ситуаций.

В производственной среде из-за сохранения истории версий определений рабочих процессов, связей задач и определений задач сохранение этих данных в течение длительного времени приведет к тому, что таблица журнала будет становиться все больше и больше, что повлияет на производительность пакетной обработки.
поэтому,Рекомендуется регулярно очищать версию.,Например, в Zhengcai Cloud сохраняются 20 последних версий. такой же,каждый деньиз Пакетный запуск приведет к Рабочий Таблицы экземпляров процессов и задач растут, поэтому рекомендуется выполнить очистку.

Конкретные методы очистки включают удаление устаревших процесс Определить версию,Можно использовать"DELETE"интерфейсудалитьбесполезная версия。кроме того,Можно позвонить"DELETE"интерфейсудалить Устаревшийиз Рабочий экземпляр процесса, тем самым очищая историю планирования.
Эта часть кода систематизирована и загружена на GitHub, и вы можете использовать ее по мере необходимости.

При настройке,насизЦель — выполнить необходимые задачи с минимальными ресурсами.Тюнингиз Ключевым моментом является обеспечение того, чтобы кластер иDSкластериз Разумное соотношение,Это сделано для того, чтобы DS не стал узким местом для автономной пакетной обработки.
Например, если кластер может обрабатывать до 80 задач параллельно, а у DS всего два воркера, и каждый воркер параллельно обрабатывает 30 задач, то DS становится узким местом.

Чтобы решить эту проблему, мы можем увеличить количество воркеров в DS, чтобы уменьшить очередь задач.
В то же время очень важна настройка параметров параллелизма, например, разумная настройка параметров параллелизма в соответствии с размером машины и типом задач. Нам необходимо проанализировать нагрузку каждого кластера в часы пик и найти подходящие нам значения параметров. Отслеживая общую нагрузку пакетной обработки кластера и использование ресурсов каждого рабочего узла, можно оптимизировать и корректировать параметры.
Например, для восьми машин с памятью 16 ГБ, если количество параллельных задач составляет около 20-30 и задачи выполняются локально, настройки параметров являются разумными. Если задача выполняется удаленно, параметры параллелизма можно соответствующим образом увеличить. Аналогично, параметры защиты ЦП и резервирования памяти также необходимо настроить в соответствии с конфигурацией машины, чтобы обеспечить стабильность и производительность машины.
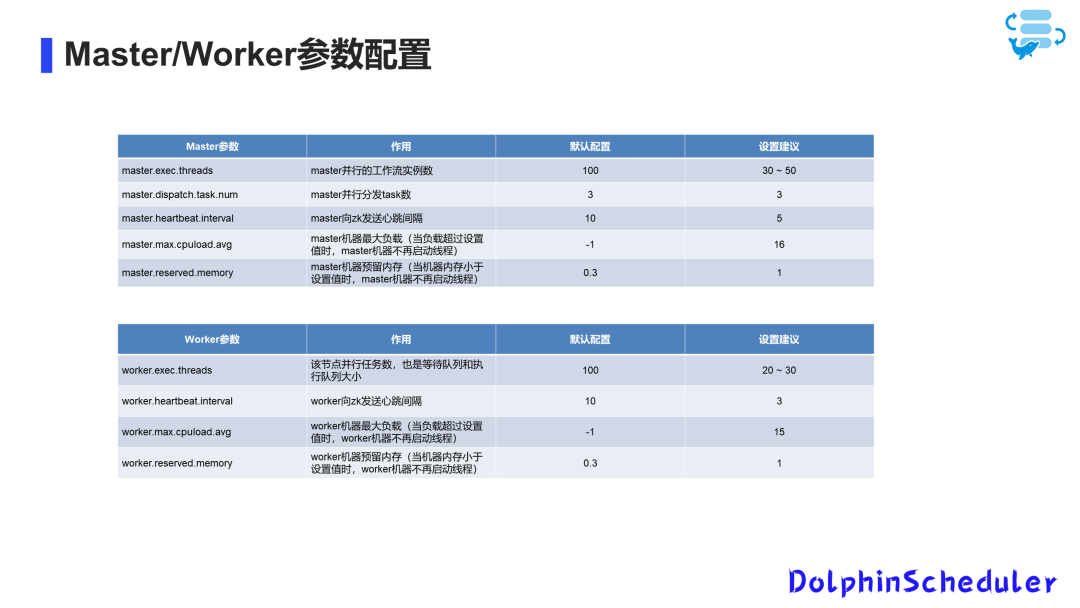
После завершения настройки машины,Улучшена производительность пакетной обработки.,В то же время это также сокращает работу по решению и планированию нештатных ситуаций. После этих корректировок и преобразований,За последние шесть месяцев,У нас больше нет проблем с кластером, вызванных планированием.
Участвуя в сообществе открытого исходного кода, мы можем узнать об основных изменениях версий и найти версию, которая соответствует нашей бизнес-ситуации. Что касается системы планирования, мы не гонимся слепо за последней версией, стабильность является наиболее важной. Присоединяйтесь к сообществу открытого исходного кода. Когда вы сталкиваетесь с проблемами, в сообществе есть много экспертов, которые могут помочь найти и решить их. Это также может улучшить ваше личное техническое видение.
В целом, благодаря эффективному управлению и настройке DolphinScheduler может более эффективно работать в производственной среде и лучше выполнять задачи обработки и анализа больших данных.
Я надеюсь, что эта статья будет полезна всем при практическом применении и оптимизации DolphinScheduler.
Участвуйте и вносите свой вклад
В связи с быстрым ростом открытого исходного кода в Китае сообщество Apache DolphinScheduler переживает бум. Чтобы сделать планирование более полезным и простым в использовании, мы искренне приветствуем партнеров, которые любят открытый исходный код, присоединиться к сообществу открытого исходного кода и внести свой вклад в развитие. открытого исходного кода в Китае. Пусть местный открытый исходный код станет глобальным.

участвовать DolphinScheduler В сообществе много Участвуйте и вносите свой способы вклада, в том числе:

Мы также надеемся, что внести первый PR (документацию, код) будет несложно. Первый PR используется для ознакомления с процессом подачи заявок и сотрудничества с сообществом, а также для того, чтобы почувствовать дружелюбие сообщества.
Сообщество составило следующий список задач, подходящих для новичков: https://github.com/apache/dolphinscheduler/issues/5689
Список проблем для новичков: https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22.
как Участвуйте и вносите свой ссылка на вклад: https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
