Превосходя модель 7Б того же уровня! Китайская команда открыла исходный код ShareGPT4V, крупномасштабного набора высококачественных графических данных, значительно улучшающего мультимодальную производительность.
Новый отчет мудрости
Редактор: ЛРС
【Шин Джиген Введение】исследователь Используйте GPT4-VisionПостроен масштабный и качественныйкартинаискусстводанныенаборShareGPT4V,И на основе этого было обучено 7BМодель,Она превзошла другие модели во многих мультимодальных списках.
В сентябре OpenAI добавила в ChatGPT функцию ввода изображений, позволяющую пользователям загружать одно или несколько изображений для участия в разговоре. За этой новой функцией стоит мультимодальный (язык видения) под названием GPT4-Vision от OpenAI.
Ввиду настойчивости OpenAI в отношении «закрытого исходного кода», появилось множество отличных результатов исследований мультимодальных больших моделей. Например, две репрезентативные работы MiniGPT4 и LLaVA продемонстрировали пользователям мультимодальный диалог и бесконечные возможности для рассуждений.
В области больших мультимодальных моделей эффективное согласование модальностей имеет решающее значение, но эффект согласования модальностей в существующих работах часто ограничивается отсутствием крупномасштабных высококачественных данных «изображение-текст».
Чтобы решить эту проблему, исследователи из Университета науки и технологий Китая и Шанхайской лаборатории искусственного интеллекта недавно запустили ShareGPT4V, новаторский крупномасштабный набор графических и текстовых данных.

Адрес статьи: https://arxiv.org/abs/2311.12793.
Демо: https://huggingface.co/spaces/Lin-Chen/ShareGPT4V-7B
Адрес проекта: https://github.com/InternLM/InternLM-XComposer/tree/main/projects/ShareGPT4V
Набор данных ShareGPT4V содержит 1,2 миллиона фрагментов данных «высокодетального текстового описания изображения», охватывающих многие аспекты, такие как знание мира, атрибуты объектов, пространственные отношения, художественная оценка и т. д., превосходя существующие с точки зрения разнообразия и информационного охвата. данные.

Таблица 1. Сравнение ShareGPT4V и основных наборов данных аннотаций. Среди них «LCS» относится к наборам данных LAION, CC и SBU, «Visible» указывает, видно ли изображение при аннотации, а «Avg» показывает среднее количество английских символов в текстовом описании.
В настоящее время этот набор данных занимает первое место в рейтинге трендов наборов данных Hugging Face.
данные
ShareGPT4V получен из 100 000 данных «изображения карт — высокоподробные текстовые описания», полученных из усовершенствованной модели GPT4-Vision.
Исследователи собрали данные изображений из различных источников данных изображений (таких как COCO, LAION, CC, SAM и т. д.), а затем использовали соответствующие подсказки для конкретных источников данных для управления GPT4-Vision для создания высококачественных исходных данных.
Как показано на рисунке ниже, когда модели GPT4-Vision присвоен кадр «Супермен», она может не только точно идентифицировать персонажа Супермена и его актера Генри Кавилла в кадре «Супермен», но также может полностью анализировать позиции. Взаимосвязь объектов на изображении и цветовые свойства объектов и т.д.
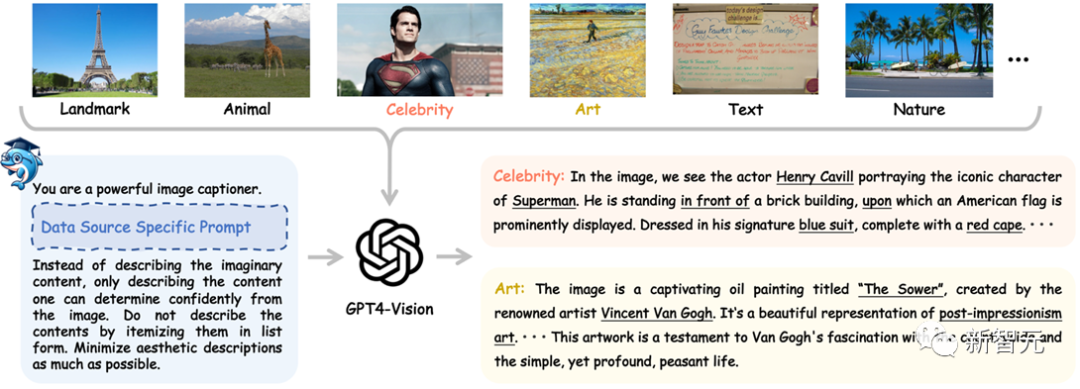
Рисунок 1 Используйте GPT4-Vision 收наборShareGPT4Vоригинальныйданныепроцесскартина
Если модели GPT4-Vision предоставить картину Ван Гога «Сеятель», она сможет не только точно определить имя и автора картины, но и проанализировать художественную школу, к которой принадлежит картина, содержание картины и эмоции, выражаемые самой картиной, информацией и идеями.
Для более полного сравнения с существующим набором данных описания, подобного изображению. Ниже мы перечисляем высококачественные текстовые описания в наборе данных ShareGPT4V вместе с текстовыми описаниями в наборе данных, используемых текущей мультимодальной большой моделью:

картина 2 「картина фото-Текстовое описание」данные сравнение качества картины
Это видно по картинке,Использование наборов COCO, аннотированных человеком, является правильным, но часто очень коротким.,Предоставляемая информация крайне ограничена.
LLaVAданныенабор使用语言МодельGPT4Описания воображаемых сценариев часто слишком сильно полагаются наbounding коробка неизбежно вызывает проблемы с галлюцинациями. Такие как ограничение В ящике есть аннотации для восьми человек, но двое из них находятся в поезде, а не ждут его.
Во-вторых,Набор LLaVAданные может быть ограничен только информацией аннотаций COCO.,Контент, не упомянутый в аннотациях вручную (например, деревья), часто пропускается.
в сравнении,Наша коллекция описаний к картинам не только дает исчерпывающее описание,На изображении нелегко пропустить важную информацию (например, информацию о платформе, текст на доске объявлений и т. д.).
После углубленного обучения этим первоначальным данным,Исследователи разработали мощную картину, похожую на описание ModelShare-Captioner. Воспользуйтесь этой моделью,Кроме того, они сгенерировали 1,2 миллиона высококачественных «картина-текстовых описаний» данныхShareGPT4V-PT для этапа предварительного обучения.

картина3 картина нравится описание Модель расширить данные установить размер процесс картина
Share-Captioner сравним с GPT4-Vision по своей способности описывать изображения изображений. Ниже приведены текстовые описания одного и того же изображения из разных источников.

Картина4 Сравнение описаний изображений из разных источников
Из вышеизложенного видно, что Share-Captioner сузил возможности модели GPT4-Vision в задаче описания изображения. Его можно использовать как «замену» для коллекционирования масштабных качественных картинных пар.
эксперимент
Исследователи впервые полностью продемонстрировали эффективность набора ShareGPT4Vданные на этапе контролируемой точной настройки (SFT), заменив эксперимент равными количествами.
Это видно по картинке,Набор данных ShareGPT4V может значительно повысить производительность мультимодальной модели с несколькими архитектурами и множеством масштабов параметров!
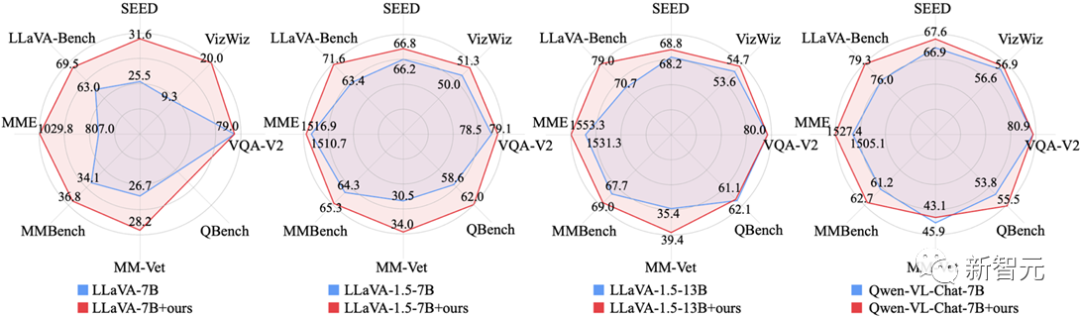
Картина5 Используйте набор ShareGPT4Vданные, чтобы заменить изображение картины в SFT на описание данных и сравнить эффект модели изображения.
Следующий,Исследователи использовали набор ShareGPT4Vданные как на этапе предварительного обучения, так и на этапе контролируемой тонкой настройки.,Получил ПоделитьсяGPT4V-7BМодель.
ShareGPT4V-7B показал отличные результаты в большинстве мультимодальных тестов производительности и оптимальную производительность во всех размерах модели 7B!
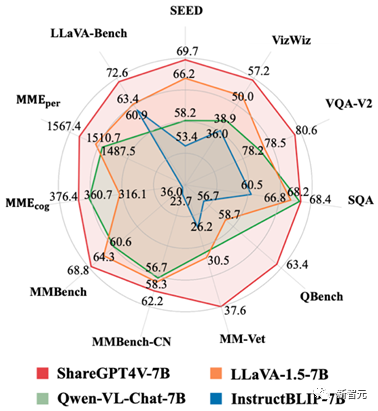
картина6 Производительность ShareGPT4V-7B в различных мультимодальных тестах
В целом, запуск набора ShareGPT4Vданные заложил новый краеугольный камень для будущих мультимодальных исследований и приложений. Мультимодальный Открытый исходный Ожидается, что сообщество программистов разработает более мощную и интеллектуальную мультимодальную модель, ориентированную на высококачественные описания изображений.
Ссылки:
https://github.com/InternLM/InternLM-XComposer/tree/main/projects/ShareGPT4V



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
