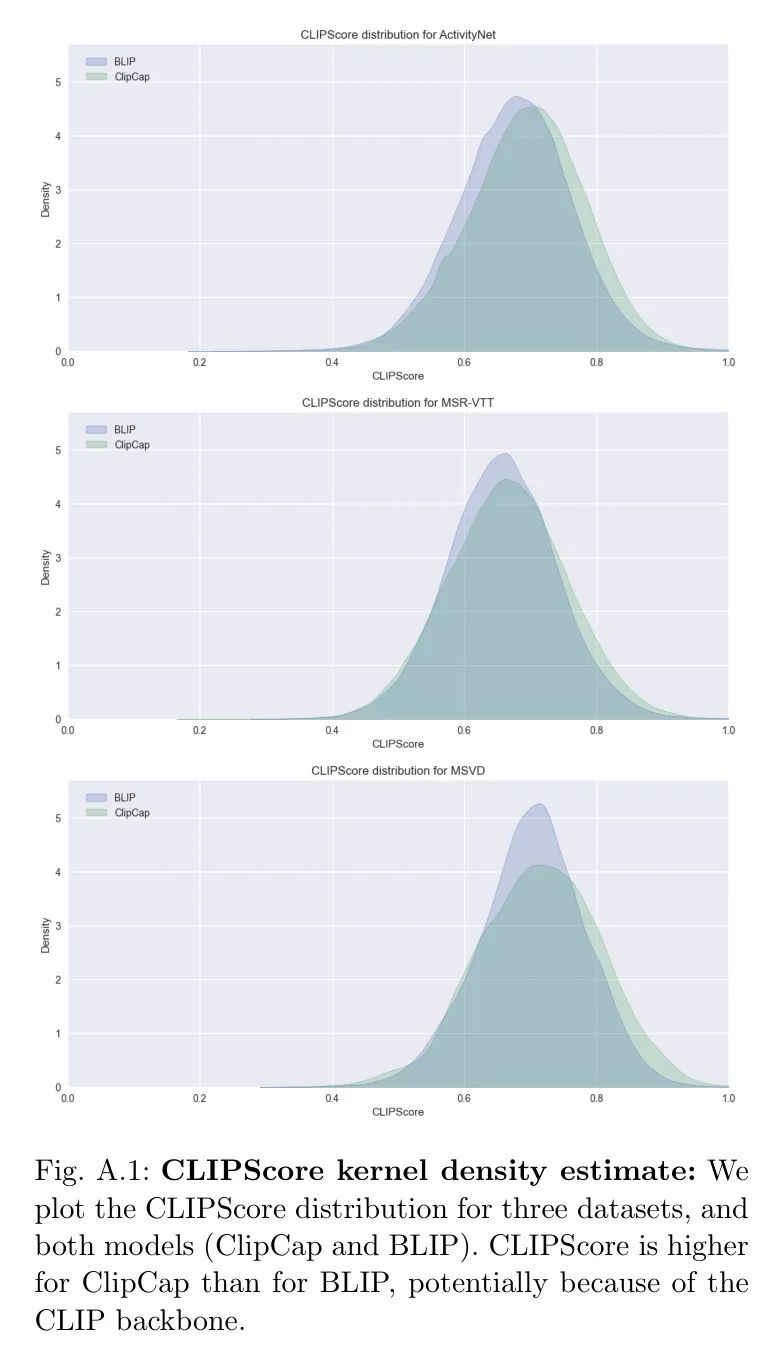
Преодолевая ценовой барьер видеоаннотаций, субтитры к изображениям открывают новую тенденцию в обучении извлечению текста из видео, превосходя базовый уровень CLIP с нулевой выборкой!

Авторы описывают протокол изучения обучения извлечению текста в видео с использованием неразмеченных видео, предполагая, что (i) нет меток для каких-либо видео, т.е. нет доступа к коллекции субтитров GT, но (ii) есть доступ к меткам в текстовой форме изображения. Использование экспертных моделей изображений является реальностью, поскольку аннотирование изображений дешевле и масштабируемее по сравнению с дорогими схемами аннотирования видео. Недавно такие эксперты в области изображений с нулевым кадром, как CLIP, создали новую мощную основу для задач понимания видео. В этой статье авторы используют этот прогресс и создают экспертов по изображениям на основе двух типов моделей: модели преобразования текста в изображение, которая обеспечивает начальную основу, и модели субтитров к изображениям, которая предоставляет управляющие сигналы для немаркированных видео. Авторы показывают, что обучение преобразованию текста в видео может быть достигнуто путем автоматического аннотирования видеокадров с использованием подписей к изображениям. Этот процесс адаптирует функции к целевому домену без затрат на ручное аннотирование, тем самым превосходя мощный базовый план CLIP с нулевым выстрелом. Во время обучения авторы выбирают субтитры, которые лучше всего соответствуют визуальному контенту из нескольких видеокадров, и группируют по времени представление кадров на основе корреляции каждого субтитра. Авторы проводят обширные исследования абляции, чтобы получить представление и продемонстрировать эффективность этой простой структуры, превосходя CLIP Baseline с нулевым выстрелом в задачах извлечения текста в видео на трех стандартных наборах данных: ActivityNet, MSR-VTT и MSVD.
1 Introduction
В последние годы исследования автоматического понимания видео претерпели множество изменений парадигмы. С появлением нейронных сетей первоначальный вопрос заключался в том, как спроектировать архитектуру для ввода пространственно-временных сигналов [49, 68]. Учитывая ограниченность данных видеообучения, затем основное внимание было обращено на заимствование инициализации параметров из предварительного обучения классификации изображений [7]. Чтобы обеспечить предварительное обучение видео, были предприняты дорогостоящие усилия по аннотированным наборам данных классификации видео [27].
С другой стороны, исследовательское сообщество отходит от обучения распознаванию закрытой лексики, поскольку достижения в области языкового моделирования стимулируют достижения в извлечении визуальных данных при вводе текста с открытым словарем, преодолевая ограничения полностью контролируемых методов поиска видео, поскольку эти методы ограничены высокая стоимость видеоаннотации. Даже обучение с использованием пар видео-текст в веб-масштабе [4] не превосходит предварительное обучение CLIP «изображение-текст» [8], несмотря на то, что люди вручную вводят подробные описания, чтобы продавать свои видео на стоковых веб-сайтах. С другой стороны, методы обучения на видео без меток обычно предполагают отсутствие меток даже для изображений и фокусируются конкретно на самоконтролируемом обучении, используя структуру самих данных в качестве обучающего сигнала.
В этой статье авторы ставят вопрос: могут ли внешние, готовые эксперты по имиджу подавать контролирующие сигналы? Авторы исследуют доступность недавно выпущенных надежных генераторов подписей к изображениям, а именно ClipCap [46] и BLIP [32], которые извлекают выгоду из крупномасштабного обучения пар изображение-текст. Например, ClipCap использует предварительное обучение визуальному изображению CLIP и предварительное обучение языковой модели GPT-2 [56]. Применительно к видеокадрам мы заметили, что, хотя выходные тексты были зашумлены, они содержали высококачественные описания, что побудило нас продолжить это исследование.
Хотя идея использования автоматических подписей к изображениям привлекательна, включение таких шумных надписей в обучение создает дополнительные проблемы. Чтобы решить эту проблему, авторы сначала применили метод фильтрации для выбора субтитров, которые лучше описывают кадр, путем расчета метрики CLIPScore [25]. Эта мера кросс-модального сходства аналогична этапу фильтрации в [32]. Кроме того, авторы объединяют несколько генераторов подписей к изображениям, чтобы получить больший пул тегов. Авторы проверили преимущества этих шагов в экспериментах по абляции.
В этой работе авторы проверяют, могут ли готовые модели субтитров служить в качестве стратегии автоматического аннотирования для задач поиска видео. Авторы предлагают простую схему ответа на этот вопрос. Основной базой и весовой инициализацией автора является CLIP [55]. Авторы настраивают эту модель так, что после обучения контрастному поиску встраивание видеокадров и автоматические субтитры сопоставляются с кросс-модальным объединенным пространством. Поскольку одного субтитра может быть недостаточно для представления видео, авторы вводят обучение с несколькими субтитрами, чтобы эффективно использовать несколько текстовых меток для каждого видео, расширяя метод оценки запросов из [5]. Это необходимо для преодоления потенциального шума при автоматической маркировке, а также является методом увеличения данных. Более того, поскольку наш метод не требует ручного аннотирования, мы можем выйти за рамки одного набора данных и объединить несколько источников данных в процессе обучения. Это особенно повышает производительность при работе с небольшими наборами данных. Авторы экспериментально демонстрируют, что использование модели создания подписей к изображениям для создания псевдометок для немаркированных видеокадров является простой и эффективной стратегией, которая повышает производительность по сравнению с базовым уровнем.
Вклад автора тройной:
- Авторы предлагают новый и простой метод обучения поиску видео. Модель,Этот метод использует автоматические заголовки кадров.,Эти названия представляют собой бесплатные ярлыки для надзора (см. Рисунок 1). Насколько известно автору,Прежде чем проводить это исследование,Готовая генерация названий для таких целей пока недоступна.
- По трем тестам поиска текста в видео авторы превосходят современную модель CLIP с нулевыми выборками.
- Авторы предоставляют обширные исследования абляции.,Варианты дизайна: как выбрать качественный заголовок,Включает несколько генераторов подписей к изображениям.,Объединение времени с использованием нескольких названий,А также объединение нескольких наборов данных. Код и Модель будет общедоступен.
2 Связанная работа
Авторы предоставляют краткий обзор исследований, связанных с преобразованием текста в видео, самостоятельным обучением на видео без меток, псевдомаркировкой и созданием титров.
Преобразование текста в видео. Методы преобразования текста в видео только недавно начали обучать сквозные модели нейронных сетей благодаря (i) мощной инициализации из ViT [16] и (ii) крупномасштабным наборам видеоданных: базовый текст ASR из речи. контролировал зашумленные данные HowTol00M [45] или, в последнее время, аннотированные вручную более чистые данные WebVid [4]. Достижения в области преобразования текста в изображение впоследствии привели к развитию преобразования текста в видео. Последние методы используют основу изображения CLIP и исследуют возможность добавления временного моделирования (например, CLIP2TV [20], CLIP4Clip, CLIP2Video [17], CLIP-ViP [79], TS2-Net, ViFi-CLIP [57]). Их результаты показывают, что простое усреднение вложений кадров по-прежнему является мощной основой, которую трудно превзойти. В некоторых исследованиях изучалось детальное контрастивное обучение для видео [84][41; 83], например, одновременное сравнение кадров-слов и кадров-предложений [41]. Бэйн и др. [5] предложили простой, но эффективный метод объединения представлений видеокадров с помощью средневзвешенного значения на основе оценок запроса. В этой работе авторы расширяют этот подход, используя несколько заголовков вместо одной метки для каждого видео. Автор также использует CLIP [55] в качестве базовой линии и инициализации. Как и другие методы поиска [40; 43], авторы поставили перед собой сравнительные цели [51; В отличие от этих методов, которые предполагают ручное аннотирование видеоданных [4; 5; 40] или зашумленные речевые сигналы [43; 77], мы получаем контроль из автоматического аннотирования заголовков. В наших экспериментах мы демонстрируем преимущества нулевой производительности по сравнению с предыдущими моделями, обученными на парах видео-текст из HowTo100M [45] или WebVid [4].
Применение обучения без учителя на видео без меток. Связанным направлением исследований является обучение представлению неразмеченных видео, которое часто называют обучением с самоконтролем. В этой категории есть несколько работ, которые выполняют дифференциацию экземпляров видео аналогично SimCLR [10] или BYOL [23] в настройках изображения. Большинство методов также используют мультимодальную природу видео, например, включение аудиосигналов в обучение. Популярный подход заключается в использовании зашумленных речевых сигналов из нефильтрованных обучающих видеороликов, таких как HowTo100M [45]. Текст, полученный посредством ASR, напрямую обрабатывается как соответствующая метка и затем используется для целей сравнения.
Разработано многоэкземплярное обучение, VideoCLIP предварительно обучен для расширенного поиска, а Support-set [53] определяет цели многозадачных субтитров. Эти работы с самоконтролем могут дополнять наш подход, но в этом исследовании мы фокусируемся на другом: мы стремимся к надзору со стороны внешних моделей изображений, которые предоставляют псевдометки, что можно рассматривать как альтернативный путь самоконтроля.
Псевдо-теги. Работа авторов также связана с методами псевдомаркировки (или самомаркировки). В отличие от настроек полуконтроля [30; 64; 65] или малой выборки [76], рассмотренных в этих работах, псевдоразметка авторов не требует какой-либо аннотации для текущей проблемы. В частности, параллельная работа [76] использует экспертов по изображениям для помощи в обучении языку с видео, но требует небольшого набора маркированных видео. Аналогичным образом VideoCC [48] использует наборы данных изображения-текста для автоматического назначения субтитров аудиовизуальным видео, но ограничен источником ограниченных наборов данных изображений-субтитров. Разница между работой авторов и [48] заключается в том, что авторы генерируют субтитры для нескольких видеокадров вместо того, чтобы извлекать их из такого ограниченного набора. Хотя эти два метода могут потенциально дополнять друг друга, в приложении автора авторы показывают, что поиск субтитров у ближайшего соседа не работает так же хорошо, как сгенерированные субтитры.
При предварительном обучении текстовым изображениям BLIP [32] и BLIP-2 [31] используют метод управляемых подписей к изображениям, который относится к полуконтролируемой категории, т. е. они начинают обучение с набора помеченных изображений (в то время как авторы начинают от не обученных на маркированных видео). Фактически, автор использует BLIP в качестве одного из субтитров авторских изображений для автоматической разметки видео. В экспериментах автора автор также изучал влияние использования инициализации BLIP по сравнению с CLIP.
Генерация титулов. Растет интерес к задаче генерации текста, описывающего заданный визуальный контент [3; 15; 71; 80; Хотя многие исследования сосредоточены на интеграции информации об объекте в качестве дополнительного руководства (например, Оскар [34], VLP [89]), эти методы плохо работают в областях, аналогичных моделям обнаружения объектов (например, набор данных COCO [35] хорошо). ClipCap [46] демонстрирует высокую производительность при работе с наборами данных в разных областях без использования модуля явного обнаружения объектов. Напротив, [46] использует две мощные предварительно обученные модели (CLIP [55] и GPT-2 [56]) и изучает модель сопоставления между функциями изображения и генерацией языка. Недавно BLIP [32], BLIP-2 [31] и CoCa [85] расширили контрастное обучение CLIP за счет совместного изучения подписей к изображениям. Компания Align and Tell [75] также интегрировала головку создания субтитров к видео в свою модель поиска текста и видео во время обучения. OFA [74] дополнительно поддерживает различные задачи языка изображений в рамках единой структуры, где генерация подписей выполняется путем подсказки модели визуального ответа на вопрос «Что описывает изображение?» Недавно компания CapDec [50] добавила декодер текста поверх кодера замороженного изображения CLIP для обучения автокодировщика с помощью кодировщика текста CLIP, используя данные, содержащие только текст.
В нашей работе мы используем ClipCap [46] и BLIP [32] в качестве экспертов по созданию подписей к изображениям, от которых мы получаем управляющие сигналы для неразмеченных видео. Хотя все они представляют собой модели, основанные только на изображении, авторы обнаружили, что их производительность на видеокадрах была удовлетворительной. Производительность моделей генерации подписей к видео в настоящее время отстает от методов генерации подписей к изображениям из-за ограничений в обучающих данных [52; 71]. Будущая работа может изучить улучшение их производительности. Недавние работы, такие как ClipVideoCap [81], Lavander [33], CLIP4Caption [67], HiREST [87] и TextKG [24], дали многообещающие результаты. Однако настройка авторов в этой работе не учитывает доступ к помеченным видео.
3 Training with automatic captions
В этом разделе мы сначала опишем, как автоматически генерировать субтитры для видеоаннотаций, затем представим наше обучение поиску видео с несколькими субтитрами и, наконец, предоставим подробности реализации нашей экспериментальной установки.
Обзор методов авторов представлен на рисунке 2. Таким образом, авторы сначала создают набор меток для каждого видео, применяя модель субтитров к видеокадрам. Учитывая эти шумные субтитры на уровне кадра (от нескольких генераторов субтитров изображений), авторы сортируют их в соответствии с их CLIPScore [25], чтобы выбрать субтитры высокого качества. Авторы используют метод обучения контрастному поиску видеотекста с оценкой по запросу с несколькими субтитрами, в котором они включают все выбранные субтитры в цель. Далее авторы подробно объясняют эти шаги.
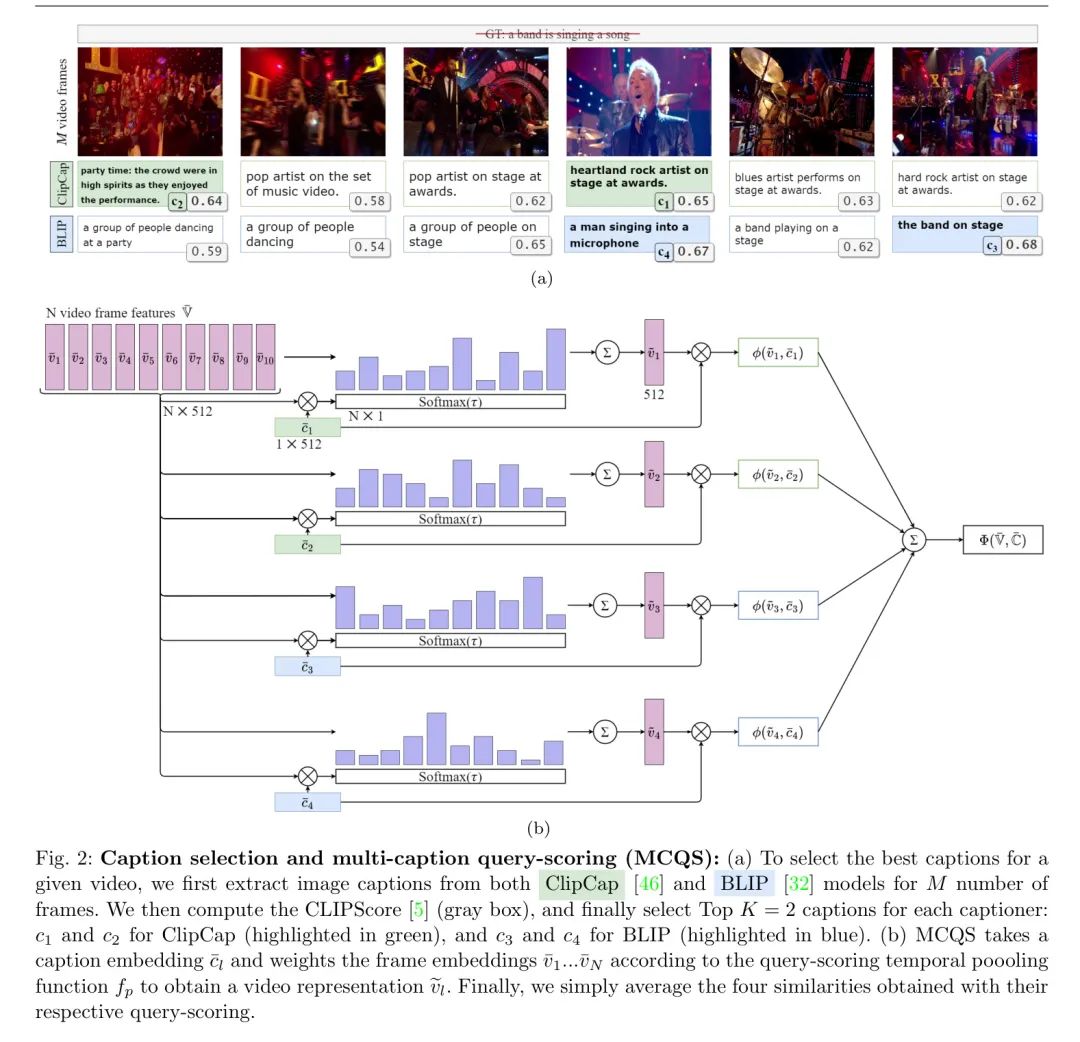
Выбирайте субтитры высокого качества. Дан кадр, состоящий из Без маркировки Для обучающих видеороликов автор выбирает кадры ( ) из видео и использует генератор субтитров изображений для извлечения субтитров и формирования исходного набора меток, где. Затем автор получает текстовое описание для каждого кадра и общее количество меток для каждого видео. Хотя авторы в экспериментах исследовали несколько вариантов формирования меток из субтитров, окончательная стратегия авторов такова. Авторы выбирают подмножество исходных меток главным образом для устранения шумных субтитров, которые плохо представляют соответствующие видеокадры. Для этого авторы использовали CLIPScore. [25] как мера межмодального сходства между субтитрами и соответствующими им кадрами. Для каждого генератора субтитров,Автор зарезервированCLIPScoresсамый высокий перед-субтитры(K<ml=k\times iтеги。Авторы называют эту подгруппу\mathbb{c}^{\prime}。пожалуйста, обрати внимание,Из-за визуального сходства внутри видео,Некоторые субтитры могут повторяться между кадрами, поэтому предполагает автор;,Выбор подмножества не приводит к существенной потере информации.,Авторы используют визуальный кодер для вычисления визуальных вложений () на отдельных кадрах. такой же,Автор вычисляет встраивание текста из соответствующего набора тегов с помощью кодировщика текста.,чтобы получить положительное представление текста,где (имеет те же размеры встраивания, что и ). Чтобы получить одно видео, вставьте,Автор праввидео Представление кадра временно объединено。получать[5]серединапредставлятьиз Query Вдохновленный рейтингами, объединение авторов основано на текстовом представлении, просто реализуемом через средневзвешенное значение, где веса кадров пропорциональны сходству текста. Затем объединенные вложения видео сравниваются с текстом для получения единого сходства. [5] В отличие от авторов, авторы имеют несколько текстов. Поэтому автор неоднократно применял Query баллов и получили множественные сходства, авторы объединили их с помощью простой операции усреднения (эксперименты с использованием взвешенного усреднения не привели к улучшениям; см. раздел 4.2). Более формально,
функция
Представляет коллекцию вложений видеокадров.
Коллекция со встроенными субтитрами
сходство между
это косинусное подобие,
Временное объединение функции «Оценка запроса [5]», также введите текст:
В авторских экспериментах автор задает гиперпараметр температуры softmax
。
из партии
В выборке пар визуально-текст:
, авторы используют для обучения симметричную контрастирующую потерю InfoNCE [51], т. е. рассматривают все остальные образцы в партии как отрицательные:
Окончательный проигрыш давидео с субтитрами (
) и субтитры к видео (
) извлекает сумму условий потерь. Далее авторы подробно объясняют процесс оптимизации.
Детали реализации. Авторы создают экземпляры двух генераторов подписей к изображениям на основе моделей ClipCap [46] и BLIP [32] (
). Модель ClipCap предварительно обучена на изображениях 3M из набора текстовых данных изображений концептуальных изображений Google [63] с использованием сопоставления MLP между магистральной сетью изображений CLIP [55] и моделью генерации текста GPT-2 [56]. BLIP обучает поиску и созданию подписей совместно, используя начальную загрузку и используя 129 миллионов изображений (включая подмножество LAION [60]). Авторы используют общедоступную модель, которая дополнительно дорабатывается на основе набора данных COCO [35]. Учитывая генератор субтитров, мы извлекаем субтитры каждого видео из равноотстоящих друг от друга кадров.
субтитры. Автор опытным путем устанавливает количество качественных субтитров для каждого генератора субтитров равным
(Прямо сейчас
). На одном графическом процессоре GTX1080 затраты на создание субтитров для ClipCap и BLIP составляют 0,65 кадра в секунду и 0,93 кадра в секунду соответственно.
Автор использует Адама [28] оптимизатор и косинусное затухание [38] график скорости обучения для минимизации функции потерь в уравнении 5, как описано в [40]. Для ActivityNet автор работал на 16 Tesla V100 Обучение на GPU за 10 эпох, начальная скорость обучения
, размер мини-партии
. Для MSR-VTT и MSVD авторы обучались на 4 NVIDIA GeForce GTX 1080 в течение 10 эпох с начальной скоростью обучения
, размер мини-партии
。
Если явно не указано иное, веса моделей двойного кодера авторов были получены из CLIP во всех экспериментах. [55] Предварительная инициализация,несмотря ни на чтодакодер изображений(
) также кодировщик датекста (
). Архитектура кодера изображения соответствует ViT-B/16 во всех экспериментах. [16]. Архитектура кодировщика текста соответствует GPT-2. [56]。Оба энкодерадана основеTransformerиз[69],Размерность внедрения операции равна
。
Автор настраивает размер кадра до разрешения 224×224 и вводит его в модель. В ходе обучения автор выполняет на основе пп.
Случайная выборка кадров (как в [72; 4], обратите внимание, что они не обязательно связаны с
названия совпадают). Результирующий пространственно-временной исходный размер видеовхода составляет 224×224×10. Каждый видеокадр проходит через кодировщик изображений независимо, используя выходные данные, соответствующие тегу [cls], для получения 512-мерного внедрения. Как уже говорилось выше, через Query Оценка получается путем временной агрегации, то есть средневзвешенного значения кадров, а вес да получается через сходство текста кадров. Поэтому снимайте видео Level Размерность представления равна 512. Во время обучения авторы используют несколько заголовков в уравнении 1. Query Метод оценки. Во время тестирования авторы вычисляют визуальные встраивания на центральных пространственных кадрах из 10 равноудаленных кадров. Во время оценки, поскольку автор только один Query текст, несколько заголовков Query Оценка да невозможна. Поэтому автор использует общепринятое Query Балльный метод оценки.
4 Experiments
Авторы впервые описывают метод, используемый для сообщения об экспериментальных результатах, в разделе 4.1. данныенабори Показатели оценки。затем в4.2Фестивальсерединаподарокавторизабляционное исследование,Количественно оценивалось влияние следующих факторов: (i) Модель субтитров.,(ii) Выбор субтитров,(iii) В сочетании с генератором субтитров,(iv) Каждое видео обучается с использованием нескольких субтитров.,и (v) в сочетании с набором данных. Следующий,Авторы представляют сравнение с современным состоянием техники в разделе 4.3.,Затем в разделе 4.4 представлен эксперимент по использованию инициализации BLIP без даCLIP. наконец,Авторы предоставляют качественный анализ в разделе 4.5.,ограничения обсуждаются в разделе 4.6.
Datasets and evaluation metrics
Авторы проводят эксперименты по трем установленным критериям поиска текста в видео.,соответственно даActivityNet [29],MSR-VTT [78] и МСВД [9] Набор данных.
ActivityNet Captions [29] содержит 20 тысяч видеороликов YouTube. видео разбито на 42 тыс. сегментов,Средняя продолжительность — 45 секунд. Автор использовал 10 009 видео из обучающей выборки.,и оценивается по разделению «val1» (4917 видео). Уведомление,Автор извлекает заголовки с равным интервалом для каждого сегмента.,И не давай каждое видео.
MSR-VTT [78] состоит из 10 тысяч видеороликов на YouTube. Продолжительность видео варьировалась от 10 до 32 секунд, в среднем 15 секунд. Авторы тренируются с использованием разделов Training-9k, как в [4; 40; 83], и сообщают результаты для отдельных пар видео-текст на разделах 1k, как в [40; 86].
MSVD [9] включает 1970 видеороликов, разделенных на 1200 обучающих, 100 проверочных и 670 тестовых видеороликов. Этот набор данных содержит короткие видеоролики (около 1 секунды) и длинные видеоролики (около 60 секунд). Учитывая небольшой размер набора данных, авторы использовали три разных начальных числа для обучения и усредняли результаты по тестовому разделению.
Как объяснялось ранее, хотя эти наборы данных содержат заголовки GT, авторы не используют их во время обучения (эксперименты в полностью контролируемых условиях см. в разделе A). Авторы сообщают о стандартном протоколе оценки: преобразование текста в видео (T2V) на рангах 1 и 5 для всех экспериментов. Рейтинг
Скорость отзыва (R@
) определяет, что правильное видео находится впереди
количество раз в результатах. Чем выше отзыв, тем лучше производительность.
Ablation study
В этом исследовании проводится исследовательская проверка того, может ли да быть Без маркировки видео Подавайте обучающие сигналыиззаголовок。Отвечатьдаподтверждатьиз;Однако,Автор сделал несколько дизайнерских решений. здесь,Авторы предоставляют исследования абляции для измерения чувствительности к этим решениям. Более конкретно,Авторы исследовали влияние создания заголовков «Модель для Модели» и качество предоставляемых заголовков. Для дальнейшего улучшения результатов,Во время обучения авторы использовали несколько названий для каждого видео.,И объедините наборы данных для обучения одной модели.
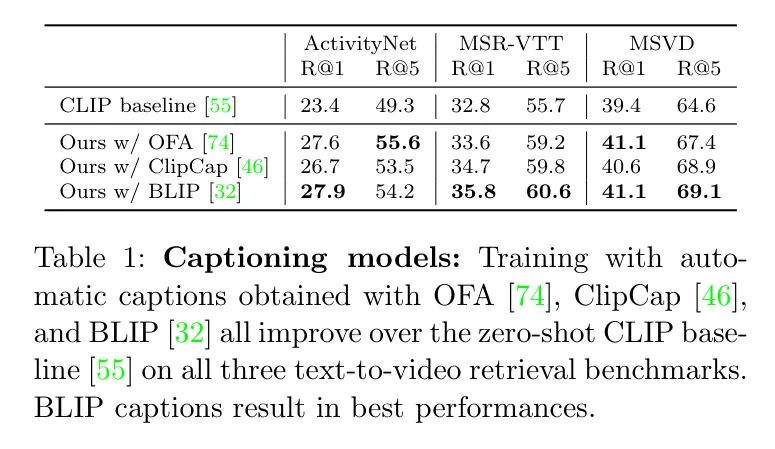
(1) Генерация названия Модель. Первый дизайн выбирает, какую подпись к изображению использовать для создания модели. В таблице 1,Автор провел сравнительное исследование,Экспериментировал с тремя играми последнего поколения. Модель: OFA [74].,ClipCap [46] и BLIP [32]. В частности, авторы использовали лучшие доступные предварительно обученные веса модели: OFA-huge, обученную на 20 миллионах общедоступных пар изображение-текст с использованием Conceptual ClipCap обучался работе с подписями, а BLIP-Large обучался на 129 миллионах изображений и настраивался для COCO. Модель BLIP достигла наилучших результатов благодаря большему объему предварительной тренировки по сравнению с двумя другими моделями. Результаты также показывают, что использование заголовков может превзойти мощный CLIP. Baseline [55] авторы используют встраивание замороженных средних видеокадров CLIP. Обратите внимание, что это отличается от CLIP4Clip. Тот же метод объединения средних значений, который использовался в [40]. В этом эксперименте авторы во время обучения случайным образом выбирают одно из двух лучших названий. Далее авторы оценивают влияние этого выбора.
(2) Выбор названия. Автоматически сгенерированные заголовки различаются по качеству. Авторы выбирают заголовки с высокой совместимостью с текстом изображения, чтобы исключить потенциальный шум при обучении. Приведенная выше модель генерации подписей к изображениям не выводит оценку достоверности, поэтому авторы используют CLIP-Score [25] в качестве меры качества между сгенерированными подписями и соответствующими входными видеокадрами;
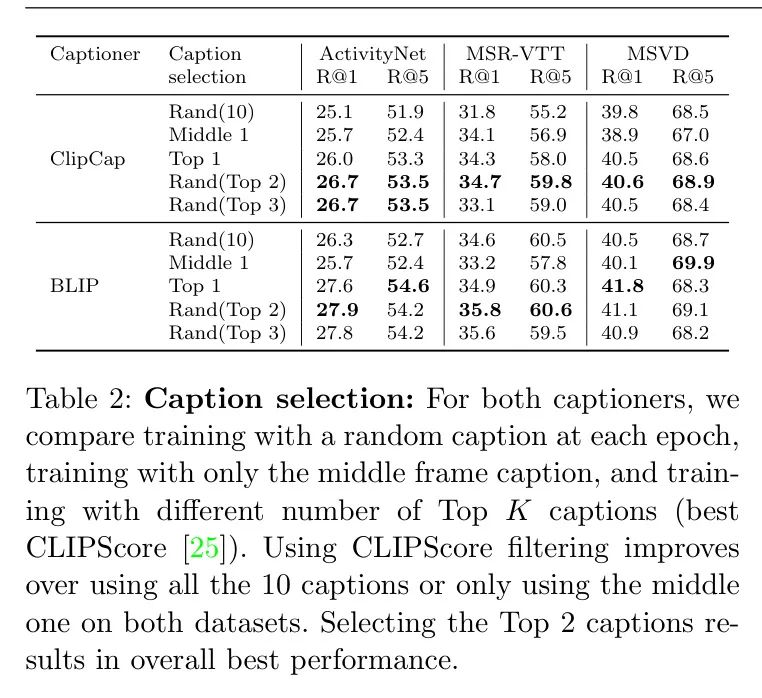
В таблице 2,Авторы оценили, была ли эта фильтрация полезной. В этой экспериментальной установке,Автор использует одно название каквидео Теги для обучения。автор针对每个заголовок生成器进ХОРОШО了五种不同变体изэксперимент:(a) Случайным образом выберите один из 10 извлеченных заголовков в каждую эпоху (б); Используйте только титры, соответствующие промежуточным кадрам (Прямо использовать один и тот же ярлык во все эпохи; (c) Используйте только лучшие заголовки (топ-1 по показателю CLIPscore (d)); Случайным образом выберите одно из двух лучших названий каждой эпохи (e); В каждую эпоху случайным образом выбирается одно из трех лучших названий. Результаты показывают, что CLIPScoreда — это эффективный метод фильтрации, сохраняющий заголовки высочайшего качества. Во всех трех эпизодах с данными и в обоих генераторах титров (ClipCap и BLIP) использование лучших титров было немного лучше, чем использование всех титров или титров между кадрами. В частности, в наборе данных ActivityNet видео относительно длинное, а заголовки промежуточных кадров могут быть не репрезентативными. Однако существует компромисс между количеством и качеством названий. В каждом видео больше нескольких названий может избежать переобучения,Это может действовать как улучшение данных. с другой стороны,Разница в качестве титров начинает увеличиваться. Эмпирические выводы автора,Выбор двух лучших игр представляет собой хороший компромисс.,В целом производительность оказалась многообещающей. Однако,Разница между первыми 1, 2 или 3 (последние три строки) незначительна.
(3) Комбинированный генератор титров. Способ увеличить количество титров в видео без снижения качества титров да Выбирайте лучшее из каждого генератора титров
заголовки для формирования набора тегов. В таблице 3,Автор использует два генератора титров ClipCap иBLIP.,проверить эту гипотезу,Затем интегрируйте их теги. Результаты показывают,по большинству показателей,比单个заголовок生成器изпроизводительность Немного лучше。Можно далее расширить до болеенесколько названий Генератор
。
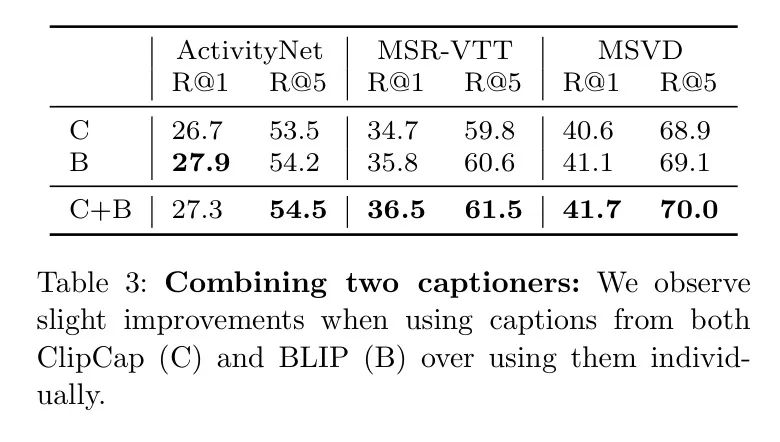
Обратите внимание, что авторы также могут выбирать из всех названий, объединенных обоими генераторами названий.
индивидуальный. Это эквивалентно выбору двух лучших заголовков из 20 (по 10 на каждый генератор заголовков). Однако,Такой подход приводит к худшим результатам,возможныйдаиз-за разныхизCLIPScoreраспределенный(возможныйдапотому чтоCLIP Backbone сети (с небольшим предпочтением ClipCap) и тенденцией данного генератора титров выводить повторяющиеся субтитры в последовательных кадрах. Авторы представляют дальнейший анализ в разделе D.
(iv) несколько названий Query Рейтинг (MCQS). Пока что авторы используют в качестве метки видео только один заголовок (Прямо сейчас делает это случайно выбранным из набора из 4 названий). Здесь автор исследует, как эффективно комбинировать несколько заголовков для получения более богатых видеотегов, которые могут захватывать глобальный контент за пределами одного кадра заголовков. В таблице 4 автор перечисляет несколько названий Query Рейтинг (MCQS) с одним названием, использовавшимся ранее Query Для этих игр сравнивались рейтинги (QS) от ClipCap и BLIP.
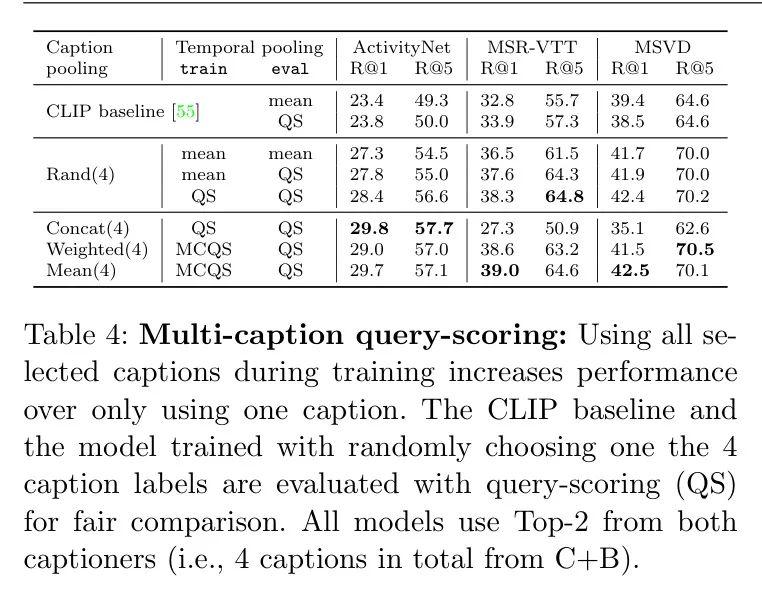
Авторы сначала оценивают QS по сравнению с равномерным средним значением. Baseline Влияние сейчас Только для CLIP при тестировании Baseline и для случайно выбранного заголовка Baseline во время тренировки). Из первого наблюдения да в Таблице 4 QS несколько улучшается при оценке Baseline (CLIP’s 33,9 vs 32,8 рэнда в MSR-VTT Р@1 из 37,6 vs 36.5). Использование QS для обучения и оценки еще больше повысило производительность (38,3 vs 37.6)。
В следующих трех строках Таблицы 4 авторы исследуют три варианта авторского подхода с использованием нескольких заголовков: а) Объедините заголовок в один текст и просто используйте простой QS, б) Взвешенный, в) Использование среднего пула сходства в MCQS. Простая конкатенация значительно снижается на MSR-VTTиMSVD, вероятно, из-за сдвига распределения из-за более длинных предложений во время обучения (4 предложения во время обучения). vs 1 предложение во время оценки). С другой стороны, результаты ActivityNet остаются аналогичными или даже немного улучшаются, поскольку при тестировании также применяется стандартный протокол оценки. GT Описание[40]. Средний пул сходства в MCQS по всем наборам данных по сравнению с одним заголовком CLIP Baseline Все получили общие улучшения. Авторы наблюдали снижение производительности при динамическом взвешивании сходства на основе ClipScore (с использованием температуры softmax 0,1). Поэтому авторы сохраняют метод простым и используют среднее сходство при совместном обучении MCQS с несколькими заголовками.
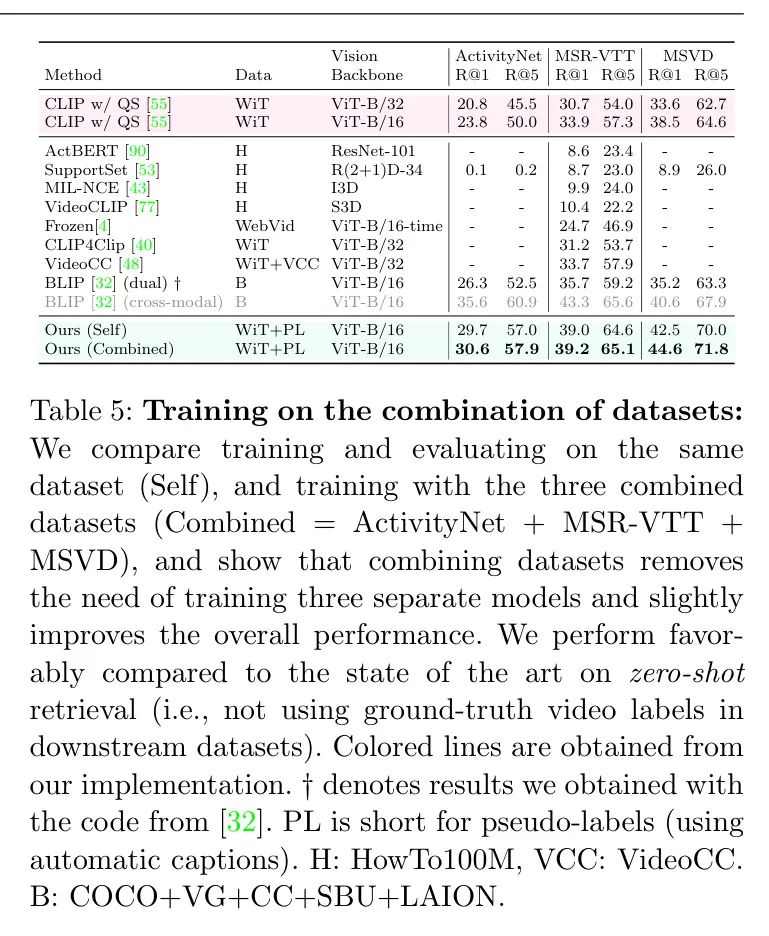
(v) Используйте несколько наборов данных для обучения. Учитывая, что наша платформа не требует аннотированных вручную видео, мы не ограничены фиксированным размером обучающего раздела набора данных и можем использовать больше данных для обучения. В Таблице 5 авторы сравнивают разницу в производительности при следующих условиях: (i) Обучение и оценка (самостоятельная) на том же наборе данных, что и (ii) Объединив несколькоданныенабор Тренируйтесь, чтобы использовать большеизданные(комбинация)。получатьизкомбинациятренироватьсянаборсуществоватьвидеоколичество сегментов от каждогоданныенаборизраспределенныйследующее:о79%отActivityNet,Около 19% приходится на MSR-VTT.,Около 2% приходится на МСВД. Эти проценты представляют относительный вклад каждого набора данных в объединенный обучающий набор.,Это значение основано на общем количестве видео, доступных в каждом наборе данных.,Используйте единый метод выборки,Из-за большого размера ActivityNet,Поэтому он более репрезентативен. Это совместное обучение повышает производительность двух относительно больших наборов данных (ActivityNetиMSR-VTT).,Улучшение более значимо для меньших MSVDданных наборов. В Приложении, раздел C.1.,Авторы также сообщают об оценках наборов данных (например,,Прошел обучение с помощью ActivityNet и прошел оценку по MSR-VTT). Этот эксперимент дает дополнительную информацию о способности метода авторов к обобщению в различных областях набора данных. Дополнительное преимущество: Получите одну модель.,Вместо нескольких моделей, специфичных для набора данных. Если предоставлены достаточные вычислительные ресурсы,В будущем Работа может попытаться включить более крупные наборы данных.
Comparison with the state of the art
В Таблице 5 авторы суммируют эффективность других методов нулевого выстрела, в основном для MSR-VTT, и наш метод работает хорошо по сравнению с современными методами. Цветные строки в таблице соответствуют реализации авторов при сопоставимых настройках (например, с использованием QS); неокрашенные строки соответствуют другим исследованиям; Красные линии обозначают авторство Baseline , зеленая строка показывает окончательную модель автора. На что следует обратить внимание, CLIP4Clip Версия с нулевой выборкой [40] и авторский CLIP Baseline [55] схожи тем, что они оба используют замороженный CLIP для выполнения пула средних значений при встраивании кадров. Единственное отличие состоит в том, что автор использует Query счет,Это было изучено в Таблице 4. Еще одно различие может быть связано с разными гиперпараметрами.,Например Рамки(авториздля
,и 12 в [40]). На что следует обратить внимание,по сравнению с другими исследованиями,Авторам доступны обучающие видео (обозначены PL в Таблице 5).,хотя соответствующего нетиз GT Этикетка. С другой стороны, некоторые конкурентные методы требуют внешних больших источников видео, таких как WebVid. [4]иVideoCC [48]. Другие методы основаны на данных HowTo100M [44; 53; 77; 90], но они по-прежнему работают плохо.
В предыдущей работе BLIP [32] достиг более высокой производительности, чем автор на MSR-VTTиActivityNet. Однако,BLIPМодель существенно отличается от метода двойного энкодера.,Поскольку BLIP также содержит кросс-модальный кодер,используется для дополнительного сопоставления текстов изображений (их ITM в статье) в качестве задачи классификации. Оценки соответствия, полученные с помощью этой головки классификации, затем интегрируются с косинусными сходствами, полученными двойным кодером. Однако известно, что кросс-модальные кодеры работают лучше, чем двойные кодеры;,Они менее эффективны [42]. поэтому,В Таблице 5 автор выделил эту строку серым цветом, чтобы подчеркнуть эту разницу. с другой стороны,Авторы вычисляют двойной кодер BLIP, рассматривая только косинусное сходство между одномодальными вложениями (аналогично духу CLIP). Результат намного ниже,Например,Для МСР-ВТТ,R@1 имеет оценку 35,7.,то есть ниже, чем (i) их ансамблевый результат 43,3 и (ii) лучшая Модель 39,2 авторов с использованием только двойных энкодеров. Следующий,Автор расширяет авторские исследования,Оценить применимость авторского метода в качестве инициализации (без даCLIP) на этом более позднем кросс-модальном кодере BLIP.
BLIP initialization
Для того, чтобы оценить применимость авторского метода при различных инициализациях модели, автор попытался использовать не основную модель CLIP. Backbone сеть。особенныйда,Автор представил модель BLIP[32],Модель доступна в двух версиях без триммера COCO. Детали реализации BLIP кратко изложены в разделе E Приложения.
В таблице 6,Автор сравнил(а) CLIP и BLIP,(б) Две версии предварительной тренировки BLIP,(c)Эффективныйиз Версия с двойным кодировщиком и Дорогостоящая перестановка с помощью кросс-модальной версии BLIP, как это сделано в [32], (d) да Нет принимает автоматические субтитры для точной настройки автора. Автор обнаружил, что во всех эпизодах данных и конфигурациях моделей, за исключением двух последних строк, автоматическая точная настройка субтитров автора неизменно превосходила результаты Baseline . Для КЛИП Backbone сети, улучшение более существенное, чем у BLIP, который Baseline Производительность уже близка к эффективности полностью контролируемого метода (см. Таблицу А.1 в Приложении). Другими словами, с лежащим в основе Backbone сеть Baseline Чем лучше результаты, тем незначительный прирост производительности.
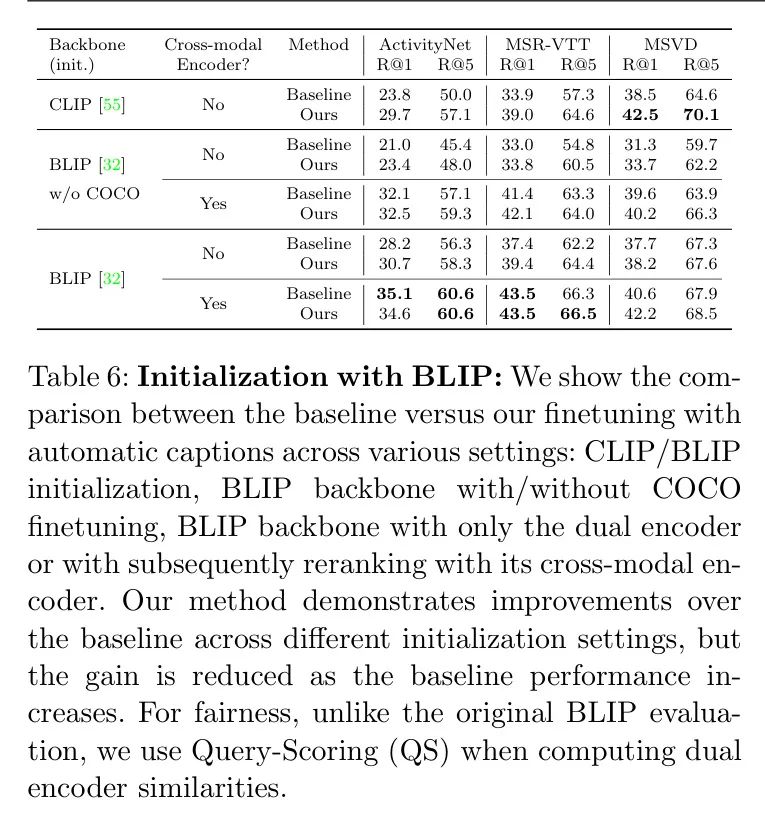
Далее автор отмечает,Хотя операции по перестановке кросс-модального энкодера обычно приводят к повышению производительности,Но его эффективность существенно ниже, чем при использовании только двойных энкодеров. Конкретно,В [32],Получите первоначальный поиск с использованием двойных кодировщиков.,Полученные видео с топ-k (k=128) затем переупорядочиваются с использованием дорогого кросс-модального кодировщика. Когда нет кросс-модального кодировщика,использоватьавторметодизCLIPБаза Модельпоказать превосходствоизпроизводительность(ссылкаповерхность6середина“кросс-модальный кодер”Индекс"No"из ХОРОШО)。Автор также уточнилBLIP Baseline производительность для конфигурации двойного энкодера и кросс-модального энкодера немного отличается от таблицы 5, это связано с тем, что QS включен в оценку для справедливого сравнения, например, для двойного энкодера MSR-VTT; R@1ОтображаетсяQSиниктоQSиз分别для37.4и35.7;длякросс-модальный кодер,Они составляют 43,5 и 43,3 соответственно. Для настроек кросс-модального кодировщика,QS используется только на этапе извлечения двойного кодера.,Не используется на этапе перепланирования,Поскольку кодер вводит все кадры,Нет необходимости выполнять временное объединение, как в [32].
Авторы отмечают, что наборы данных для извлечения текста в изображение можно точно настроить без каких-либо затрат на ручное аннотирование, используя подписи к изображениям для псевдометок наборов данных для извлечения текста в видео. Backbone сети, тем самым значительно улучшая производительность, например, при заморозке CLIP (например, 23,8 на ActivityNet vs 30,6, 33,9 на МСР-ВТТ vs 39,2, 38,5 по МСВД vs 44.6, см. таблицу 5).
Текстовый запрос: Мужчина в зеленой рубашке играет на бубне. Мужчины переглянулись и заговорили. Камера приближается к бубну, а затем снова отдаляется, пока мужчина в зеленой рубашке продолжает играть.
Qualitative analysis
На рисунке 3 авторы показывают результаты преобразования текста в видео для всех трех наборов данных для нескольких примеров. Для каждого тестового примера авторы показывают: (a) Текстовый запрос
(б) Реальное видео, соответствующее текстовому запросу (первый столбец с синей рамкой)
(c) Средние кадры 5 лучших видео (отсортированы по сходству от большего к меньшему)
(d) Если видео соответствует правильному видео, оно выделяется зеленой рамкой, в противном случае оно выделяется красной рамкой.
Обратите внимание, что авторы визуализировали только средние кадры, которые могут не отражать все видео. Авторы заметили, что большинство полученных видео содержат информацию, связанную с текстом запроса. Например, для текста Запрос: «Женщина в мультфильме едет на лошади и спокойно разговаривает», все найденные видеоролики показывают мультфильм. Кроме того, иногда может быть несколько допустимых вариантов, даже если правильное видео не занимает первое место. Авторы приводят дополнительные примеры в разделе F.
Limitations
здесь,Автор обсуждает несколько ограничений этой Работы. первый,Авторы отмечают, что создание субтитров к изображениям не обязательно отражает динамический контент видео. Специальный да,Некоторые изображения можно распознать только после просмотра нескольких кадров. такой же,Метод последовательного объединения, используемый автором, относительно прост.,Порядок кадров игнорируется. Однако,Усилия по временному моделированию не привели к улучшению показателей поиска [5]. Чтобы попытаться объединить информацию о времени,Первоначально автор проанализировал использование технологии резюмирования текста для обработки последовательностей субтитров.,Однако последовательного улучшения не произошло (см. Приложение Б). Еще одним ограничением экспериментов авторов является то, что видео обучалось на обучающем наборе целевого набора данных. Даже если автор не использует свои теги,Эта установка также обеспечивает минимальные зазоры в полях. Future Work может воспользоваться большим количеством Без маркировки Видеоколлекция, учитывающая эту необходимость.
5 Conclusion
Авторы представляют простую, но эффективную структуру, которая использует модели субтитров к изображениям в качестве источника контроля наборов данных для преобразования текста в видео. Посредством серии комплексных экспериментов автор демонстрирует мощный CLIP с нулевой выборкой. Baseline Авторы добились значительных улучшений по сравнению с В будущем есть несколько перспективных направлений развития. Можно было бы изучить возможность интеграции большего количества экспертов по изображениям, помимо субтитров, например, обнаружение объектов открытого словаря. Метод псевдометок можно распространить на большее количество видов видеоданных, упомянутых в разделе 4.6. Можно изучить взаимодополняемость методов обучения представлению с самоконтролем, чтобы повысить Без маркировки видеосерединаконтрольный сигнал。другое будущееизнаправлениеда Узнайте, как объединить серию подписей к изображениям в однувидеосубтитрыизметод。
Appendix
В этом приложении представлен эксперимент в условиях полного наблюдения (Приложение, часть A).,Результаты альтернативных методов (Приложение, часть B),Дополнительная оценка (Приложение Часть C),Анализ выбора субтитров и комбинированных генераторов субтитров (Приложение, часть D),Подробности реализации эксперимента по инициализации BLIP (Приложение, часть E),Дополнительные качественные результаты (Раздел F Приложения),и Заявление о доступности данных (Раздел G Приложения).
Appendix A Fully-supervised setting
Хотя автор акцентирует внимание на настройке нулевой выборки,В этой настройке невозможно получить заметные видеоданные.,Но стоит отметить, что,Для небольших наборов данных,Затраты на маркировку не могут быть непомерно высокими,Это позволяет полностью контролировать настройку. в следующем,Автор прошел обучение с использованием реальных заголовков из набора данных, который использовал автор.,Модель точной настройки, предложенная автором (раздел А.1),и через несколько названные для демонстрации преимуществ MCQS (раздел A.2) для отчетности об экспериментах.
Finetuning with ground-truth captions
авторпоказалавторпредлагатьизметод可以как预тренироваться步骤。здесь,Автор пытается инициализировать Модель с автоматически сгенерированными субтитрами и обучить ее.,Затем он настраивается с использованием реальных субтитров для дальнейшего повышения производительности. В таблице А.1 суммированы эти результаты. Серая строка внизу сравнивает точную настройку Модели с реальными субтитрами (i), инициализированными из CLIP (строка с WiT+GTданные),Или (ii) провести тонкую настройку Модели после предварительного обучения по авторскому методу (последняя строка с WiT+GT+PLданные). Это сравнение подчеркивает преимущества использования метода, предложенного авторами, в качестве этапа предварительного обучения.,Потому что это еще больше улучшается за счет производительности целевого набора данных. Автор отметил,При обучении с реальными данными,Либо да(i) точная настройка из инициализации CLIP, либо да(ii) точная настройка после предварительного обучения с использованием псевдометок,Авторы сохраняют все гиперпараметры одинаковыми.
Multi-caption training on MSR-VTT
Видео MSR-VTT имеют 20 реальных субтитров с аннотациями для каждого видео. Таким образом, в условиях полного контроля мы можем использовать наш метод MCQS для обучения. В таблице A.2 авторы показывают, что использование всех достоверных аннотированных субтитров одновременно с MCQS работает лучше, чем случайная выборка одного субтитра на каждой итерации обучения.
Авторы выбрали два CLIPScore. [25] являются самыми высокими и (iii) усредняют их векторы вложения. Затем автор преобразует текст Query (Также с внедрением S-BERT) Сравните с этим видеопредставлением, используя косинусное сходство. В таблице 4 авторы суммируют результаты. Из двух протестированных кодировщиков текста S-BERT превзошел кодировщик CLIPtext, поскольку S-BERT был специально обучен обнаруживать похожие предложения. Однако даже да лучше всего справляется с узким местом субтитров (Прямо сейчас BLIP с использованием S-BERT) также лучше, чем CLIP с нулевой выборкой. Baseline Результаты хуже. Плохая производительность этого метода поиска на основе субтитров предполагает, что субтитров недостаточно для прямого использования при поиске, но они могут служить контрольным сигналом для обучения.
Текстовое резюме. Как упоминалось в разделе 4.6 основной статьи, авторы использовали модель сводки текста для объединения нескольких субтитров в одном видео. Попытки авторов привели к противоречивым результатам, как показано в таблице 5. Автор попытался суммировать 10 субтитров двух аннотаторов (даSumm(10C) для ClipCap, даSumm(10B) для BLIP) и итог 4 субтитров отфильтрованной комбинации (Summ(2C+2B)). Для обобщения субтитров автор использовал Модель языка Ada от OpenAI. В ходе экспериментов авторы обнаружили, что случайная выборка исходных субтитров перед обобщением помогает создавать более длинные субтитры, содержащие локальную и глобальную информацию (Прямо сейчас,Когда столбец добавления не пуст,Результаты в Таблице 5 улучшились,Например,37,5 против 35,9).
Appendix C Additional evaluations
В этом разделе авторы сообщают об оценке перекрестных наборов данных (раздел C.1), оценке нескольких субтитров в ActivityNet (раздел C.2) и показателях производительности для преобразования видео в текст (раздел C.3).
Cross-dataset evaluation
Как упоминалось в разделе 4.2 основного документа.,Авторы сообщают о результатах оценки по наборам данных. В таблице 6,Автор использовал Модель, обученную с помощью нескольких названных оценок запросов.,где диагональ соответствует предпоследней строке раздела 5 (обучение и оценка на одном наборе). Интересно да,Оценка MSR-VTT, обученная на ActivityNet, почти так же хороша, как оценка производительности, обученная на ActivityNet. также,Модель, обученная только на MSVD, плохо работает со всеми наборами данных (включая себя),Это да из-за его меньшего размера.
в. Автор не объединяет несколько заголовков в один текст. Query , а в качестве текста можно использовать все доступные описания видео Query , и использовать несколько авторских названий Query Балльный метод оценки. В таблице A.7 авторы отмечают, что использование этого подхода еще больше повышает производительность.
Video-to-text retrieval metrics
В основной статье авторы сообщают только показатели преобразования текста в видео. Здесь, в таблице A.8, авторы сообщают о показателях преобразования видео в текст. Мы видим, что наш подход также превосходит базовый вариант по этим показателям.
По сравнению с топ-2 BLIP. Это можно увидеть,Лишь около 7% времени,Первые два субтитра обоих генераторов субтитров берутся из одних и тех же двух кадров. Более 44% времени,Оба генератора субтитров имеют общий кадр. наконец,Самая распространенная ситуация,Из 10 возможных кадров было выбрано 4 разных кадра: по 2 на каждый генератор субтитров.
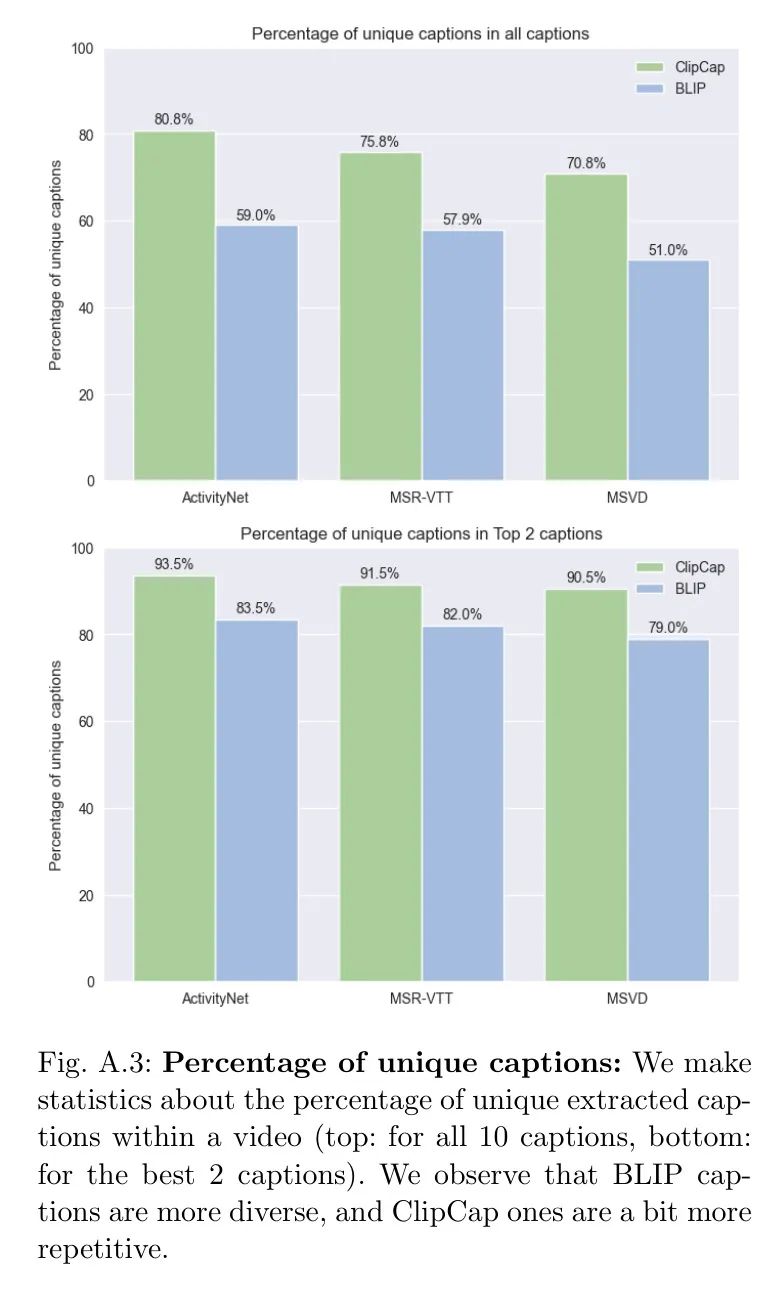
Повторяющиеся субтитры Еще одно преимущество фильтрации субтитров.,Автору был предоставлен менее повторяющийся набор субтитров. См. рисунок А.3.,Процент уникальных субтитров при использовании 10 субтитров и первых 2 субтитров. Автор также подтвердил, что в любых трёх эпизодах данных,Перекрытие субтитров между двумя генераторами субтитров составляет менее 1%. Это еще одна причина, которая мотивирует авторов использовать разные генераторы субтитров, чтобы получить более разнообразные и насыщенные субтитры.
Помимо двух генераторов субтитров. В Таблице 11 автор исследует комбинацию трех разных субтитров: ClipCap (C), BLIP (B) и OFA (O). Результаты не привели к последовательному улучшению обоих показателей (R@1 был лучше).,R@5 хуже),Наверное да, потому что по сравнению с BLIP,OFA сам по себе работает плохо.
E Implementation details for the BLIP initialization experiment
авторздесь Пояснение №.6ФестивальсерединастволсетьэкспериментизBLIPДетали реализации。авториспользовать类似于BLIPизметод进ХОРОШОтренироваться,где потери контраста изображения-текста (ИТК) выражаются по формуле автора (5)
. Из-за потери соответствия изображения-текста (ITM),Авторы расширяют скрытое состояние кодера на количество кадров. Автор использует для обучения 4 кадра,Используйте 8 кадров для оценки. В качестве кодировщика изображений автор использует ту же магистраль ViT-B/16, что и BLIP.,а такжеBERTАрхитектура[14]кактексткодер。автор Используйте одинNVIDIA RTX A600 обучает модель с помощью 4 кадров, а оценка выполняется с использованием 8 кадров, как в исходной статье.
Appendix F Additional qualitative results
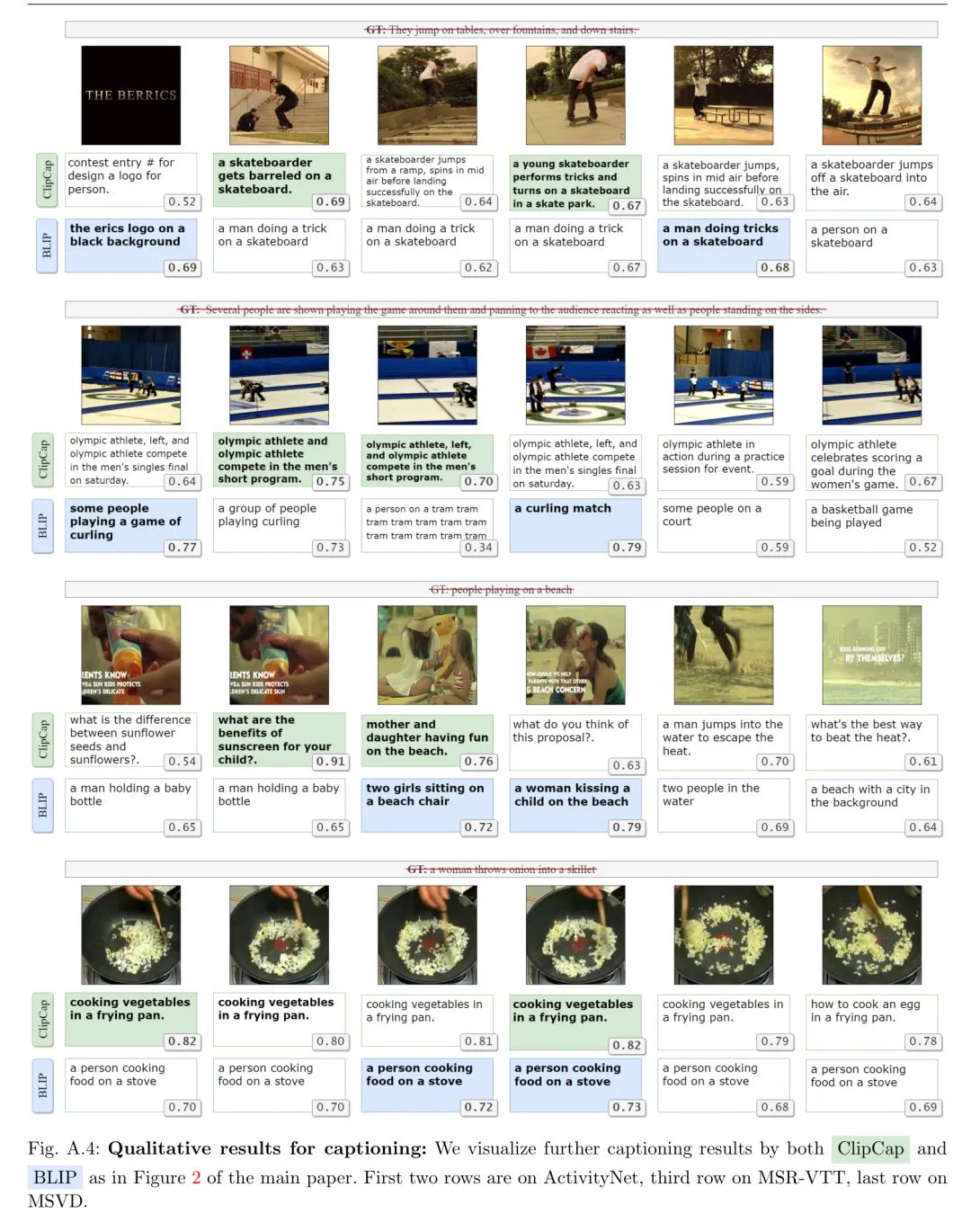
Перевод названия сохранен. Аналогично рисунку 2 в основной статье.,На рисунке 4,Автор приводит дополнительные примеры результатов генерации титров из ClipCapиBLIP.,и соответствующие баллы CLIPScore по сравнению с встраиваниями изображений. На третьей картинке второго видео или на первой картинке третьего видео,Автор видит, что когда заголовок не соответствует рамке,CLIPScore ниже. в последнем видео,Автор увидел короткий видеопример, где все кадры выглядели одинаково.,Извлеченные заголовки одинаковы или почти одинаковы.
Забрать. Дополнить рисунок 3 в основной статье.,Авторы предоставляют дополнительные качественные результаты на рисунке 5 для трех наборов данных: ActivityNet (первые две строки),МСР-ВТТ (два средних ряда) и МСВД (два последних ряда).

Appendix G Data availability statement
Авторы провели эксперименты с тремя популярными текстами для поиска общедоступных наборов данных по видео.,соответственно даActivityNet [29],MSR-VTT [78] и МСВД [9]. Ниже приведен URL-адрес загрузки эпизода с данными:
- ActivityNet
- MSR-VTT
- MSVD
Автор дополняет эти данные эпизодов автоматически сгенерированными тегами субтитров.,И будет выпущен вместе с авторским кодом и предтренировочной Моделью. Рисунок А.4: Качественные результаты генерации субтитров: автор на основе рисунка 2 основной статьи.,Результаты генерации субтитров дополнительно визуализируются через ClipCapиBLIP. Первые две строки результатов на даActivityNet,Результаты третьей строки по даMSR-VTT,Последняя строка — это результат на MSVD.
Рисунок 5. Качественные результаты преобразования текста в видео: Выше показаны лучшие результаты поиска автора по запросу Модель (Комбинированная). Эти примеры относятся к тестовым наборам ActivityNet (первые две строки), MSR-VTT (третья и четвертая строки) и MSVD (последние две строки). Каждый пример демонстрирует текст Query 、 GT Видео (первый столбец, синяя рамка) и первые 5 видео, полученные из галереи. Каждое видео отображается только с использованием промежуточных кадров по сравнению с GT Если видео совпадает, используйте зеленую рамку, в противном случае используйте красную рамку. В целом все полученные видео были связаны с текстом. Query имеет аналогичное семантическое значение даже в том случае, если правильное видео не находится в первом рейтинге.
ссылка
[1].Learning text-to-video retrieval from image captioning.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
