Преобразователь декодирования: подробное описание и реализация кода механизма самообслуживания и механизма кодека.
В этой статье всесторонне обсуждается Transformer и производные от него модели, проводится углубленный анализ механизма самообслуживания, структур кодера и декодера, перечисляет его реализацию кодирования для более глубокого понимания и, наконец, перечисляются различные модели, основанные на Transformer, такие как BERT, GPT, и т. д. Цель статьи — подробно объяснить, как работает Transformer, и продемонстрировать его широкое влияние в области искусственного интеллекта.
1. Предыстория появления Трансформера
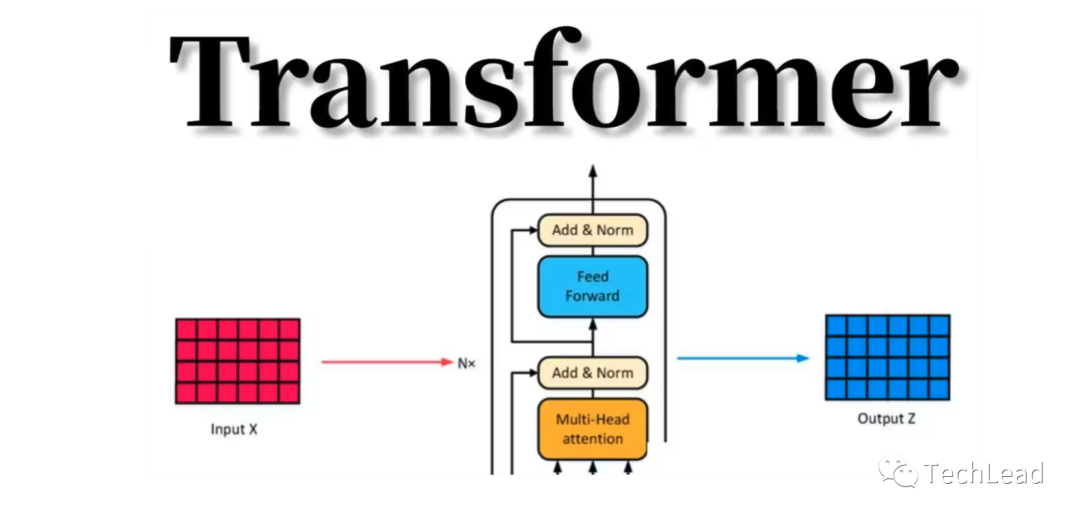
Появление Transformer знаменует собой важную веху в области обработки естественного языка. Ниже будет подробно объяснено его предыстория с трех аспектов: технические проблемы, развитие механизмов самообслуживания и влияние Трансформатора на всю область.
1.1 Технические проблемы и ограничения предыдущих решений
РНН и ЛСТМ
Модель ранней последовательности,Такие как РНН и LSTM,Хотя в некоторых сценариях он работает хорошо.,Однако в реальной эксплуатации возникло множество проблем:
- Вычислительная эффективность:потому чтоRNNРекурсивная структура,Он должен обрабатывать элементы последовательности один за другим.,Это делает вычисления невозможными для распараллеливания.
- проблема зависимости на расстоянии:RNNСложность фиксации зависимостей на больших расстояниях в последовательностях.,Хотя LSTM улучшился,Но все еще не идеально.
Попытки сверточной нейронной сети (CNN) в обработке последовательностей
Сверточные нейронные сети (CNN) могут фиксировать локальные зависимости, используя несколько уровней свертки, и в некотором смысле улучшать фиксацию зависимостей на больших расстояниях. Однако фиксированный размер окна свертки CNN ограничивает диапазон зависимостей, которые он может захватывать, а обработка глобальных зависимостей недостаточно гибка.
1.2 Возникновение механизма самовнимания
Механизм самообслуживания решает вышеперечисленные задачи:
- параллельные вычисления:Наблюдая за всеми элементами последовательности одновременно,механизм самообслуживания позволяет Модели обрабатывать всю последовательность параллельно.
- Захват зависимостей на расстоянии:механизм самообслуживания эффективно фиксирует долгосрочные зависимости в последовательностях, независимо от того, насколько далеко они находятся.
Внедрение этого механизма делает модель Трансформера технологическим прорывом.
1.3 Революционное влияние Трансформатора
Появление Transformer оказало глубокое влияние на всю сферу:
- Установите новые стандарты:в несколькихNLPПо заданию,Трансформаторы установили новые стандарты производительности.
- Продвижение новых исследований и приложений:Структура Трансформатор способствовал появлению многих новых направлений исследований и практических применений, таких как рождение передовых технологий, таких как BERT и GPT.
- Сквозное воздействие:Кромеобработка естественного языке, Transformer также полезен в других областях, таких как биоинформатика, обработка изображения и другие оказали влияние.
2. Механизм внимания к себе

2.1 Концепция и принцип работы
Механизм самообслуживания — это метод, позволяющий фиксировать отношения между элементами внутри последовательности. Он вычисляет сходство каждого элемента последовательности с другими элементами, тем самым фиксируя глобальные зависимости.
- Расчет веса:Путем вычисления сходства между каждым элементом последовательности,Присвойте каждому элементу разный вес.
- Глобальный захват зависимостей:Возможность захвата зависимостей на любом расстоянии в последовательности,Преодолев предыдущие ограничения Модели.
Расчет веса элемента
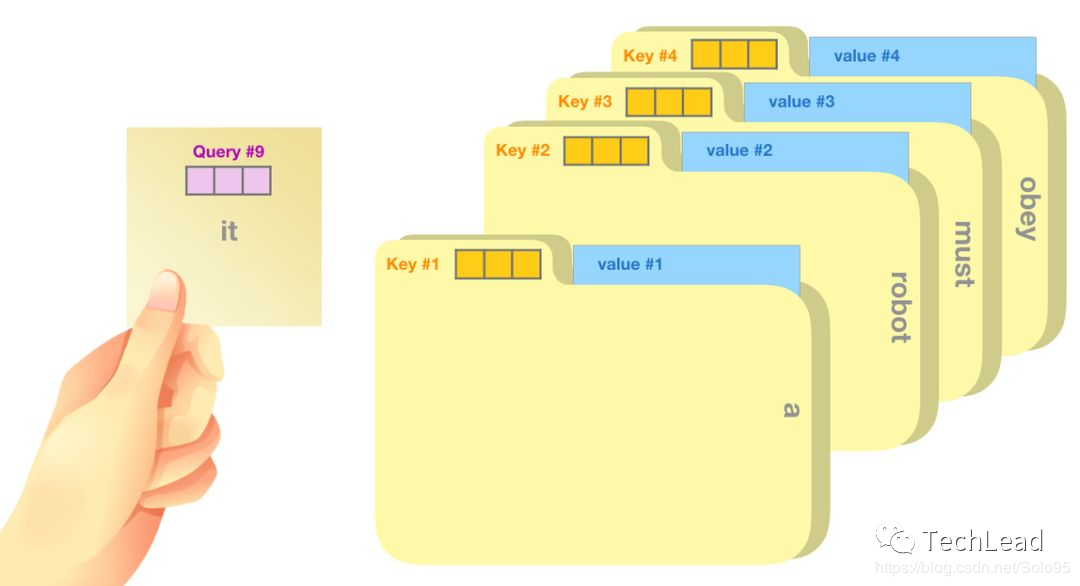
- Запрос, ключ, структура значений:Каждый элемент последовательности представляется какQuery、Key、Стоимость состоит из трех частей.
- мера сходства:использоватьQueryиKeyСкалярное произведение вычисляет сходство между элементами。
- распределение веса:проходитьSoftmaxФункция преобразует сходство в вес。
Например, рассмотрим расчет веса элемента:
import torch
import torch.nn.functional as F
# Query, Key
query = torch.tensor([1, 0.5])
key = torch.tensor([[1, 0], [0, 1]])
# Расчет сходства
similarity = query.matmul(key)
# распределение веса
weights = F.softmax(similarity, dim=-1)
# Выход: тензор([0,7311, 0.2689])взвешенная сумма
механизм самообслуживания Используйте рассчитанный вес для взвешенной долю, тем самым получая новое представление каждого элемента.
value = torch.tensor([[1, 2], [3, 4]])
output = weights.matmul(value)
# Выход: тензор([1.7311, 2.7311])Разница между вниманием к себе и традиционным вниманием
Основное отличие механизма самовнимания от традиционного внимания заключается в следующем:
- самореферентный:механизм самообслуживания – это внимание самой последовательности к себе, а не к внешней последовательности.
- Глобальный захват зависимостей:Не подпадает под местные ограничения на окна.,Может захватывать зависимости на любом расстоянии в последовательности.
Вычислительная эффективность
механизм Самообслуживание способно обрабатывать целые последовательности параллельно, не ограничиваясь длиной последовательности, тем самым достигая значительной Вычислительной способности. эффективность。
- Преимущества распараллеливания:Расчеты самообслуживания могут выполняться одновременно,Улучшена скорость обучения и вывода.
Применение в трансформаторе
В Transformer механизм самообслуживания является ключевым компонентом:
- бычье внимание:проходитьбычье внимание,Модель может изучать разные зависимости одновременно,Увеличена выразительность Модели.
- Визуализация веса:Веса самообслуживания можно использовать для объяснения Модельспособ работы,Повышенная интерпретируемость.
Междоменные приложения
Влияние механизма самовнимания выходит далеко за рамки языковой обработки:
- обработка изображений:在图像分割и识别等По заданиюиз应用。
- распознавание речи:Помогает улавливать временные зависимости в речевых сигналах.。
Будущие тенденции и вызовы
Хотя внимание к себе достигло замечательных успехов, пространство для исследований еще есть:
- Потребности в вычислениях и хранении данных:高复杂度带来了内存и计算挑战。
- Интерпретируемость и теоретическое понимание:Глубокое понимание механизма внимания еще требует дальнейшего изучения.。
2.2 Процесс расчета
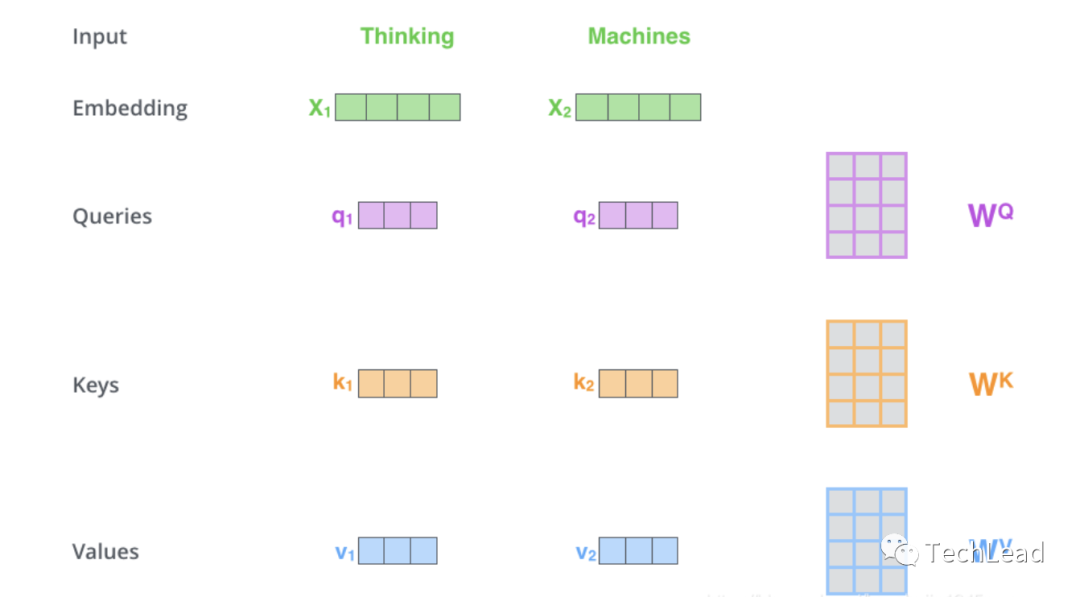
Входное представление
Входными данными для механизма самообслуживания является последовательность, обычно состоящая из набора векторов слов или других элементов. Эти элементы будут преобразованы в три части: запрос, ключ и значение соответственно.
import torch.nn as nn
embedding_dim = 64
query_layer = nn.Linear(embedding_dim, embedding_dim)
key_layer = nn.Linear(embedding_dim, embedding_dim)
value_layer = nn.Linear(embedding_dim, embedding_dim)Расчет сходства
Путем вычисления скалярного произведения запроса и ключа получается матрица сходства между каждым элементом.
import torch
embedding_dim = 64
# Предположим, что последовательность содержит три элемента
sequence = torch.rand(3, embedding_dim)
query = query_layer(sequence)
key = key_layer(sequence)
value = value_layer(sequence)
def similarity(query, key):
return torch.matmul(query, key.transpose(-2, -1)) / (embedding_dim ** 0.5)
распределение веса
Нормализуйте матрицу сходства в веса.
def compute_weights(similarity_matrix):
return torch.nn.functional.softmax(similarity_matrix, dim=-1)взвешенная сумма
Используйте матрицу весов, чтобы выполнить взвешенную длину для значения, чтобы получить выходные данные.
def weighted_sum(weights, value):
return torch.matmul(weights, value)Бычье внимание к себе
В практических приложениях многоголовое внимание обычно используется для последовательного захвата многогранной информации.
class MultiHeadAttention(nn.Module):
def __init__(self, embedding_dim, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.head_dim = embedding_dim // num_heads
self.query_layer = nn.Linear(embedding_dim, embedding_dim)
self.key_layer = nn.Linear(embedding_dim, embedding_dim)
self.value_layer = nn.Linear(embedding_dim, embedding_dim)
self.fc_out = nn.Linear(embedding_dim, embedding_dim)
def forward(self, query, key, value):
N = query.shape[0]
query_len, key_len, value_len = query.shape[1], key.shape[1], value.shape[1]
# Разделить несколько заголовков
queries = self.query_layer(query).view(N, query_len, self.num_heads, self.head_dim)
keys = self.key_layer(key).view(N, key_len, self.num_heads, self.head_dim)
values = self.value_layer(value).view(N, value_len, self.num_heads, self.head_dim)
# Расчет сходства
similarity_matrix = torch.einsum("nqhd,nkhd->nhqk", [queries, keys]) / (self.head_dim ** 0.5)
# распределение веса
weights = torch.nn.functional.softmax(similarity_matrix, dim=-1)
# взвешенная сумма
attention = torch.einsum("nhql,nlhd->nqhd", [weights, values])
# Объединение выходов нескольких головок
attention = attention.permute(0, 2, 1, 3).contiguous().view(N, query_len, embedding_dim)
# Интеграция вывода через линейные слои
output = self.fc_out(attention)
return output
3. Структура трансформатора
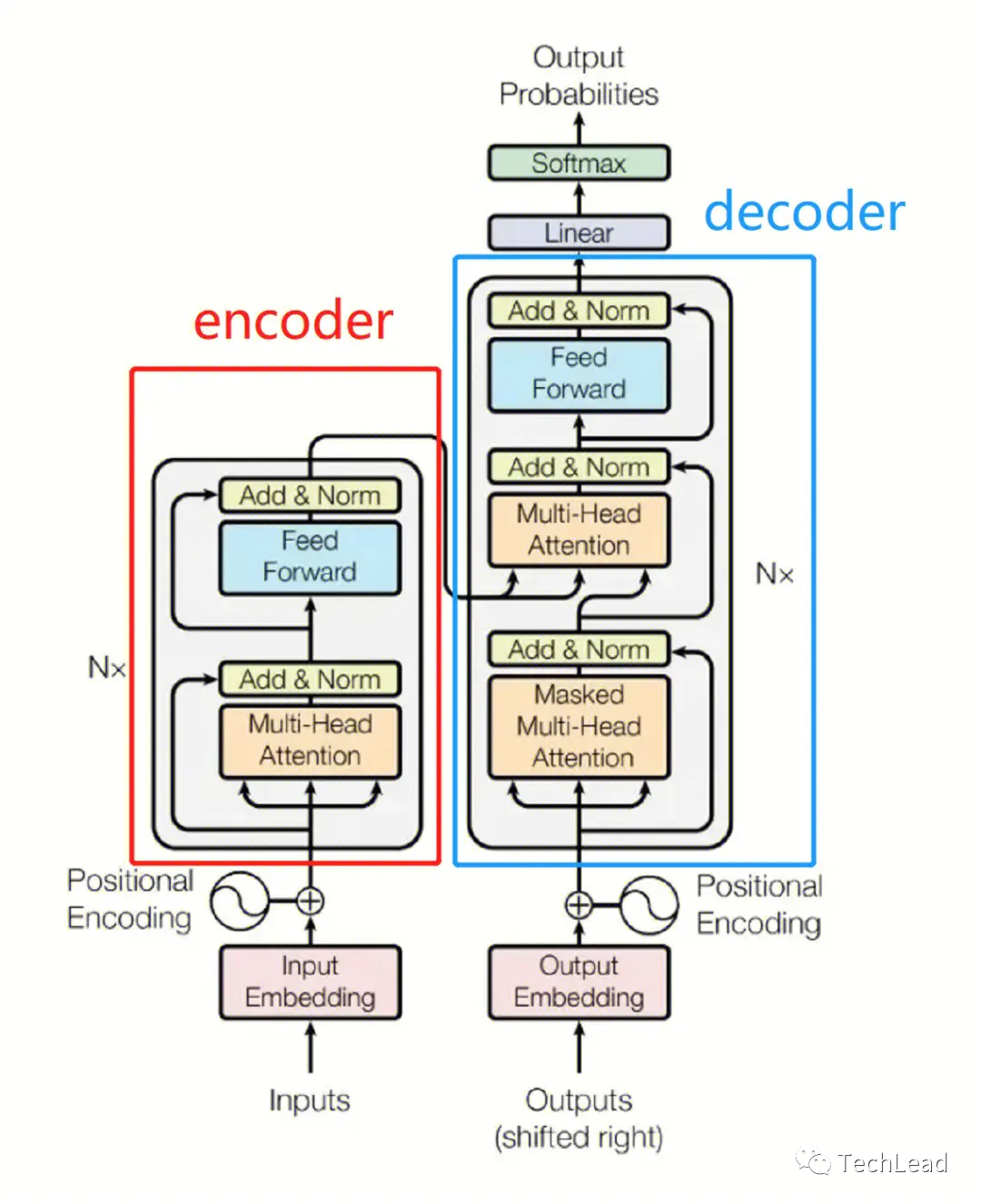
3.1 Кодер
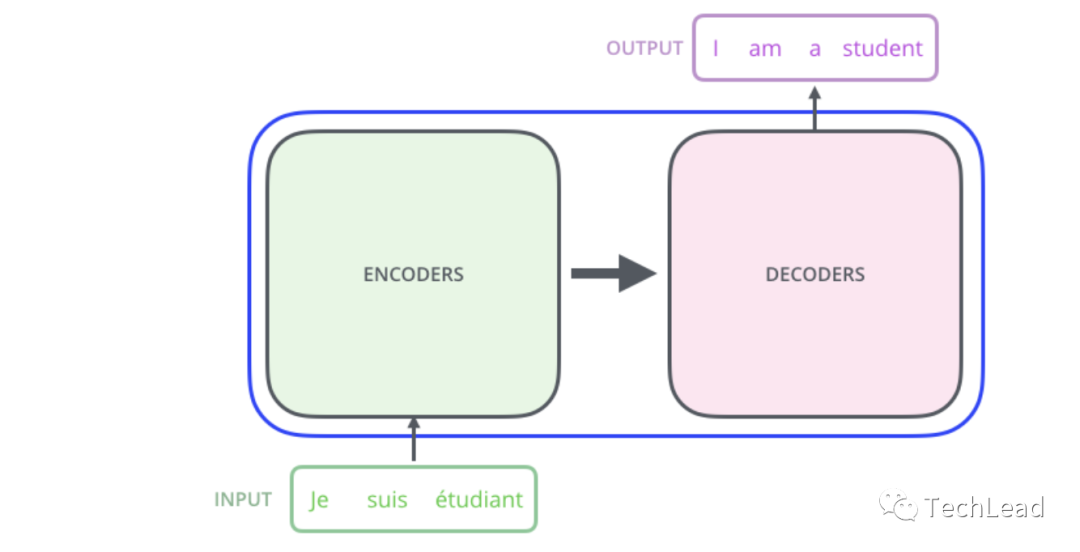
Кодер — один из основных компонентов Transformer. Его основная задача — понимать и обрабатывать входные данные. Кодировщик создает мощный инструмент сопоставления последовательностей, комбинируя механизмы самообслуживания, нейронные сети прямого распространения, уровни нормализации и остаточные связи. Механизм самообслуживания позволяет модели фиксировать сложные взаимосвязи внутри последовательности, а сеть прямой связи обеспечивает возможности нелинейных вычислений. Слои нормализации и остаточные связи помогают стабилизировать процесс обучения. Ниже приведены различные компоненты кодера и их подробные описания.
3.1.1 Уровень самообслуживания
Первая часть кодера — это уровень самообслуживания. Как упоминалось ранее, механизм самообслуживания позволяет модели обращать внимание на все позиции во входной последовательности и кодировать каждую позицию на основе этой информации.
class SelfAttentionLayer(nn.Module):
def __init__(self, embedding_dim, num_heads):
super(SelfAttentionLayer, self).__init__()
self.multi_head_attention = MultiHeadAttention(embedding_dim, num_heads)
def forward(self, x):
return self.multi_head_attention(x, x, x)3.1.2 Нейронная сеть прямого распространения
После уровня внимания кодер включает в себя нейронную сеть прямой связи (FFNN). Эта сеть состоит из двух линейных слоев и функции активации.
class FeedForwardLayer(nn.Module):
def __init__(self, embedding_dim, ff_dim):
super(FeedForwardLayer, self).__init__()
self.fc1 = nn.Linear(embedding_dim, ff_dim)
self.fc2 = nn.Linear(ff_dim, embedding_dim)
self.relu = nn.ReLU()
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))3.1.3 Уровень нормализации
Чтобы стабилизировать обучение и ускорить сходимость, за каждым слоем самообслуживания и слоем прямой связи имеется слой нормализации (Layer Normalization).
layer_norm = nn.LayerNorm(embedding_dim)3.1.4 Остаточное соединение
Трансформатор также использует остаточные соединения, так что выходные данные каждого слоя добавляются к входным. Это помогает предотвратить исчезновение и взрыв градиентов.
output = layer_norm(self_attention(x) + x)
output = layer_norm(feed_forward(output) + output)3.1.5 Полная структура кодера
Конечный кодер состоит из N таких слоев.
class Encoder(nn.Module):
def __init__(self, num_layers, embedding_dim, num_heads, ff_dim):
super(Encoder, self).__init__()
self.layers = nn.ModuleList([
nn.Sequential(
SelfAttentionLayer(embedding_dim, num_heads),
nn.LayerNorm(embedding_dim),
FeedForwardLayer(embedding_dim, ff_dim),
nn.LayerNorm(embedding_dim)
)
for _ in range(num_layers)
])
def forward(self, x):
for layer in self.layers:
x = layer(x)
return x3.2 Декодер
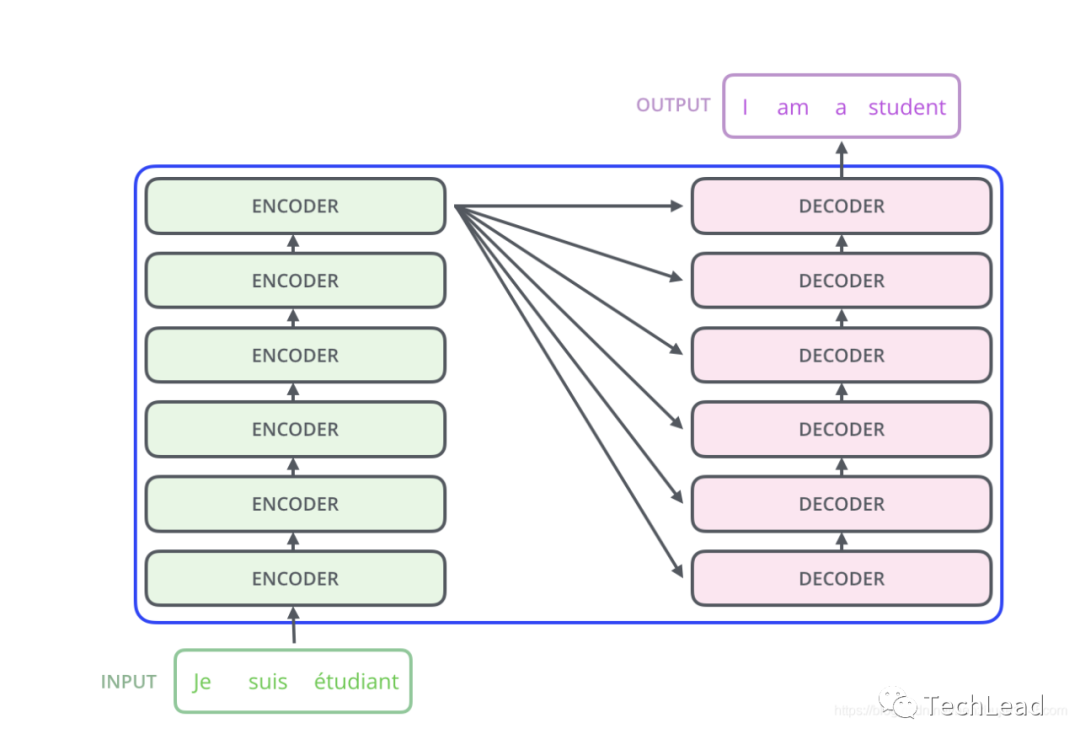
Декодер отвечает за генерацию целевой последовательности на основе выходных данных кодера и ранее сгенерированной частичной выходной последовательности. Декодер имеет структуру, аналогичную кодировщику, но добавляет замаскированный уровень самообслуживания и уровень внимания кодер-декодер для генерации целевых последовательностей. Маска гарантирует, что декодер использует только предыдущие позиции для генерации выходных данных для каждой позиции. Уровень внимания кодер-декодер позволяет декодеру использовать выходные данные кодера. Благодаря такой структуре декодер способен генерировать целевые последовательности, соответствующие контекстной и исходной информации о последовательностях, обеспечивая мощное решение для многих сложных задач генерации последовательностей. Ниже приведены основные компоненты декодера и принципы их работы.
3.2.1 Уровень самообслуживания
Первая часть декодера — это замаскированный уровень самообслуживания. Этот слой аналогичен слою самообслуживания в кодировщике, но добавляет маску, предотвращающую фокусировку местоположений на местоположениях, находящихся за ними.
def mask_future_positions(size):
mask = (torch.triu(torch.ones(size, size)) == 1).transpose(0, 1)
return mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
mask = mask_future_positions(sequence_length)3.2.2 Уровень внимания кодера-декодера
Декодер также включает в себя уровень внимания кодер-декодер, который позволяет декодеру сосредоточиться на выходе кодера.
class EncoderDecoderAttention(nn.Module):
def __init__(self, embedding_dim, num_heads):
super(EncoderDecoderAttention, self).__init__()
self.multi_head_attention = MultiHeadAttention(embedding_dim, num_heads)
def forward(self, queries, keys, values):
return self.multi_head_attention(queries, keys, values)3.2.3 Нейронная сеть прямого распространения
Декодер также имеет нейронную сеть прямого распространения с той же структурой, что и нейронная сеть прямого распространения в кодере.
3.2.4 Уровень нормализации и остаточная связь
Эти компоненты такие же, как и в кодере, и используются после каждого подуровня.
3.2.5 Полная структура декодера
Декодер состоит из уровня самообслуживания, уровня внимания кодер-декодер, нейронной сети прямого распространения, слоя нормализации и остаточной связи и обычно включает N таких слоев.
class Decoder(nn.Module):
def __init__(self, num_layers, embedding_dim, num_heads, ff_dim):
super(Decoder, self).__init__()
self.layers = nn.ModuleList([
nn.Sequential(
SelfAttentionLayer(embedding_dim, num_heads, mask=mask),
nn.LayerNorm(embedding_dim),
EncoderDecoderAttention(embedding_dim, num_heads),
nn.LayerNorm(embedding_dim),
FeedForwardLayer(embedding_dim, ff_dim),
nn.LayerNorm(embedding_dim)
)
for _ in range(num_layers)
])
def forward(self, x, encoder_output):
for layer in self.layers:
x = layer(x, encoder_output)
return x4. Различные модели на базе Трансформера.
Модели на основе трансформаторов продолжают появляться, предоставляя мощные инструменты для различных задач НЛП и других задач обработки последовательностей. От генерации текста до понимания контекста — эти модели имеют различные преимущества и характеристики, и вместе они способствуют быстрому развитию области обработки естественного языка. Общим для этих моделей является то, что все они используют основные концепции оригинального Трансформера и на их основе вносят различные инновации и улучшения. В будущем мы можем ожидать, что все больше моделей на основе трансформаторов будут продолжать появляться, что еще больше расширит сферу их применения и влияние.
4.1 BERT(Bidirectional Encoder Representations from Transformers)
BERT — это модель на основе кодировщика Transformer для создания контекстно-зависимых вложений слов. В отличие от традиционных методов встраивания слов, BERT может понимать конкретное значение слов в предложениях.
Основные особенности
- Двустороннее обучение, сбор контекстной информации
- Обширная предварительная подготовка, подходящая для различных последующих задач.
4.2 GPT(Generative Pre-trained Transformer)
В отличие от BERT, GPT ориентирован на генерацию текста с использованием декодера Transformer. GPT предварительно обучен как языковая модель и может быть настроен для различных задач генерации.
Основные особенности
- Генерировать текст слева направо
- Высокая гибкость при решении различных задач сборки.
4.3 Transformer-XL(Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context)
Transformer-XL решает проблему ограничения длины контекста исходной модели Transformer, вводя механизм многократного использования памяти.
Основные особенности
- Более длительная зависимость от контекста
- Механизм памяти повышает эффективность
4.4 T5(Text-to-Text Transfer Transformer)
Модель T5 рассматривает все задачи НЛП как задачи преобразования текста в текст. Эта унифицированная структура позволяет очень легко переключаться между различными задачами.
Основные особенности
- Универсальность, подходит для различных задач НЛП.
- Упрощает необходимость в архитектурах для конкретных задач.
4.5 XLNet
XLNet — это общая авторегрессионная модель предварительного обучения, сочетающая в себе двунаправленные возможности BERT и авторегрессионные преимущества GPT.
Основные особенности
- Двунаправленная и авторегрессионная комбинация
- Обеспечивает эффективный метод предварительной тренировки.
4.6 DistilBERT
DistilBERT — это облегченная версия модели BERT, которая сохраняет большую часть производительности, но размер модели значительно уменьшен.
Основные особенности
- Меньше параметров и вычислений
- Подходит для сценариев с ограниченными ресурсами.
4.7 ALBERT(A Lite BERT)
ALBERT — это еще одна оптимизация BERT, которая уменьшает количество параметров, одновременно повышая скорость обучения и производительность модели.
Основные особенности
- Совместное использование параметров
- Более высокая скорость обучения
5. Резюме
С момента своего появления Transformer глубоко изменил облик обработки естественного языка и многих других задач обработки последовательностей. Благодаря своему уникальному механизму самообслуживания Transformer преодолевает многие ограничения предыдущих моделей и обеспечивает более высокий уровень распараллеливания и более гибкий захват зависимостей.
В этой статье мы подробно рассмотрели следующие аспекты Transformer:
- появляется фон:ПонятноTransformer是нравиться何从RNNиCNNрожденный из-за ограничений,以及它是нравиться何проходитьмеханизм самообслуживания для обработки последовательностей.
- механизм самообслуживания:подробно объяснилмеханизм самообслуживанияиз Процесс расчет и как разрешить Модели создавать зависимости между различными местоположениями.
- Структура трансформатора:深入ПонятноTransformerиз编码器и解码器из结构,и как различные компоненты работают вместе.
- Различные модели на базе Трансформера:исследовал рядTransformer为基础из Модель,Такие как BERT, GPT, T5 и т. д.,Ознакомьтесь с их характеристиками и применением.
Transformer не только продвигает исследования и приложения в области обработки естественного языка, но и демонстрирует свой потенциал в других областях, таких как биоинформатика, анализ изображений и т. д. Многие современные модели основаны на Transformer, используя его гибкую и эффективную структуру для решения ранее трудно решаемых проблем.
В будущем мы можем ожидать, что Transformer и его производные модели продолжат играть важную роль в более широком спектре областей, постоянно внедряя инновации и способствуя развитию области искусственного интеллекта.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
