Прекрасное комплексное решение, расписанное вручную: технология RAG, от новичка до профессионала
Эта статья составлена из IVAN ILIN Опубликовано в Навстречу AIизблог[1]。Спасибо авторуиз Замечательное объяснение。

Глубокое обучение обработке естественного языка делиться Организатор: Винни
введение
Генерация улучшений поиска(Retrieval Augmented Generation,RAG для краткости) предоставляет языкам больших языков (LLM) информацию, полученную из определенных источников данных.,Используйте это как основу для генерации ответов. суммируя,RAGдаПоиск + советы по LLMизобъединить,То есть в контексте информации, найденной алгоритмом поиска,Пусть Модель ответит на поднятые вопросы. И запрос, и полученный контекст вводятся в подсказку, отправляемую в LLM.
В настоящее время RAG является самой популярной архитектурой среди систем на базе LLM. Многие продукты почти полностью построены на RAG, включая службу вопросов и ответов, которая сочетает в себе поисковую систему с LLM, а также сотни приложений для обмена данными в чате.
Из этого увлечения возникла даже область векторного поиска.,Хотя встроенная система поиска разрабатывается с использованием faiss с 2019 года. Стартапы векторных баз данных, такие как chroma, weavaite.io и pinecone, основаны на существующем поиске индексов с открытым исходным кодом — в основном faiss и nmslib.,А недавно добавили дополнительное хранилище для ввода текста и некоторых других инструментов.
Есть два наиболее выдающихсяиз Библиотека с открытым исходным кодом для использования на основеLLMизтрубопроводиприложение——LangChainиLlamaIndex,Они будут созданы в октябре и ноябре 2022 года соответственно.,И в 2023 году он получит большое количество применений.
Цель этой статьи — систематически представить ключевые моменты Передовой технологии RAG и ссылки на их реализацию в LlamaIndex — чтобы помочь другим разработчикам глубже понять эту технологию.
Если вы уже знакомы с концепциями RAG, перейдите сразу к расширенному разделу RAG.
Базовая технология RAG
В этой статье мы используем набор текстовых документов для представления отправной точки RAG — мы пропускаем предыдущие шаги и оставляем это загрузчикам данных с открытым исходным кодом, которые могут подключаться к любому мыслимому источнику, от YouTube до Notion.
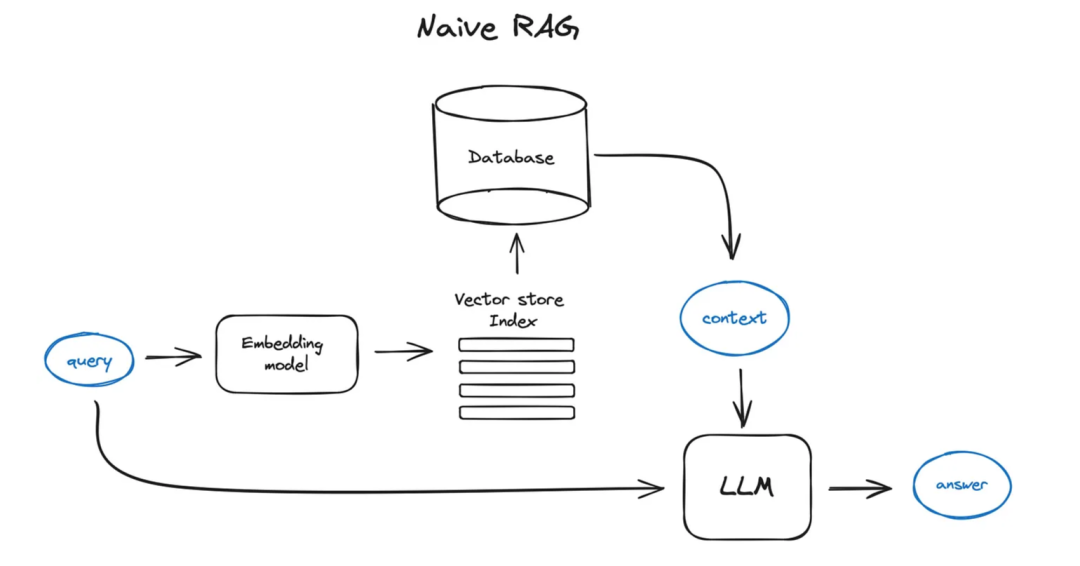
Простой случай RAG выглядит примерно следующим образом:
- Разделите текст на куски, а затем используйте Transformer на основе decoderиз Модель Вставьте эти блоки в векторы,Поместите все эти векторы в один индекс.,Наконец создайте приглашение для LLM,Сообщите Модели, чтобы она ответила на запрос пользователя в контексте, который мы нашли на этапе поиска.
- во время выполнения,Мы используем ту же модель кодировщика для преобразования векторизации запроса пользователя.,Затем выполните поиск этого вектора запроса по индексу.,Найдите k лучших результатов,Получите соответствующий текстовый блок из нашей базы данных.,и вставьте их в подсказки LLM в качестве контекста.
Подсказка может выглядеть так:
def question_answering(context, query):
prompt = f"""
Give the answer to the user query delimited by triple backticks ```{query}```\
using the information given in context delimited by triple backticks ```{context}```.\
If there is no relevant information in the provided context, try to answer yourself,
but tell user that you did not have any relevant context to base your answer on.
Be concise and output the answer of size less than 80 tokens.
"""
response = get_completion(instruction, prompt, model="gpt-3.5-turbo")
answer = response.choices[0].message["content"]
return answer
Подскажите проектдапродвигатьRAGтрубопровод性能最经济из Попробуйте один。Убедитесь, что вы просмотрелиOpenAIпоставлятьизСовет Инженерное руководство[2]。
Хотя OpenAI является ведущей компанией в области LLM, существуют альтернативы, такие как Claude от Anthropic, недавно популярные небольшие, но очень мощные модели, такие как Mixtral от Mistral, Phi-2 от Microsoft, а также множество вариантов с открытым исходным кодом, таких как Llama2, OpenLLaMA, Falcon, и т. д., чтобы вы могли выбрать «мозг» для вашего RAG-конвейера.
Передовая технология RAG
Теперь мы поближе познакомимся с Передовой. технология Обзор РАГ. Ниже приведена диаграмма, показывающая основные этапы. Чтобы диаграмма была читабельной, некоторые логические циклы и сложные многошаговые операции были опущены. мастерство Поведение。
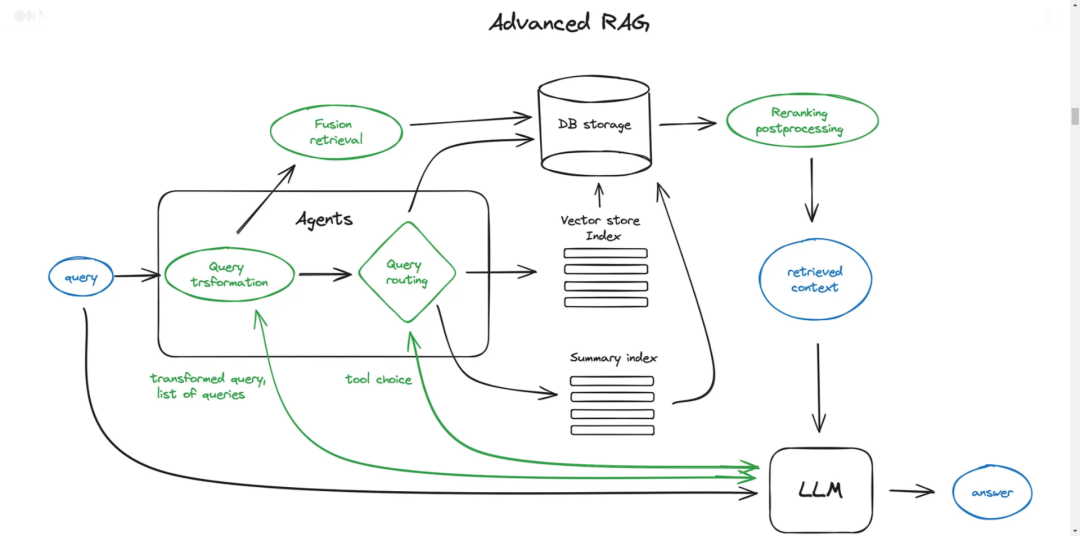
Зеленые элементы на рисунке — это основная технология RAG, о которой пойдет речь дальше, а синие элементы представляют собой текст. Не все идеи RAG высокого уровня можно легко визуализировать на одной диаграмме, например, опущены различные способы расширения контекста — мы рассмотрим их более подробно позже.
Нарезка и векторизация
Сначала мы хотим создать индекс векторов, представляющих содержимое нашего документа, а затем искать во время выполнения наименьшее косинусное расстояние между этими векторами и вектором запроса, соответствующее ближайшему семантическому значению.
резать:TransformerМодель Есть фиксированноеиз Введите длину последовательности,Даже если окно контекста ввода велико,Вектор предложения или нескольких предложений также лучше представляет их смысловое значение, чем средний вектор нескольких страниц текста (также зависит от Модель,но обычно так),Итак, чтобы разрезать ваши данные — разрежьте исходный документ на куски определенного размера.,не теряя смысла (конвертируйте текст в предложения или абзацы,вместо того, чтобы разбивать одно предложение на две части). Существуют различные реализации текстового разделителя, способные выполнить эту задачу.
Размер фрагментов является параметром, который следует учитывать. Он зависит от используемой вами модели внедрения и ее емкости для токенов. Стандартные модели кодировщиков Transformer, такие как преобразователь предложений на основе BERT, принимают до 512 токенов, OpenAI. ada-002способен выдержать дольшеизпоследовательность,Например, 8191 токен,ноздесьизскладыватьсерединададляLLMпоставлять足够из Контекстное рассуждение и исполнениепоискиздостаточно конкретныйизвстраивание текста。недавнее исследование[3]Объяснение выбора размера блокаиз Соображения。существоватьLlamaIndexсередина,Это переопределяется через класс NodeParser.,Он предоставляет некоторые расширенные параметры,Как определить себяизразделитель текста、метаданные、Отношения узлов/блоков и т. д.
векторизация:Следующий шагдавыберите один Модельвставлять после резкиизкусок——Есть много вариантов,Например, какbge-largeилиE5Вставить такую сериюизпоископтимизация Модель——Просто проверьтеВ рейтинге МТБЭ[4]из Последние обновления。
Чтобы увидеть комплексную реализацию шага Нарезка и векторизация, ознакомьтесь с полным примером в LlamaIndex.
индекс поиска
индекс хранения векторов: RAGтрубопроводизключевая частьдаиндекс поиска,Он хранит содержимое векторизации, которое мы получили на предыдущем шаге. Самая простая реализация использует индекс плоскости — грубый расчет расстояния между вектором запроса и всеми векторами блоков.
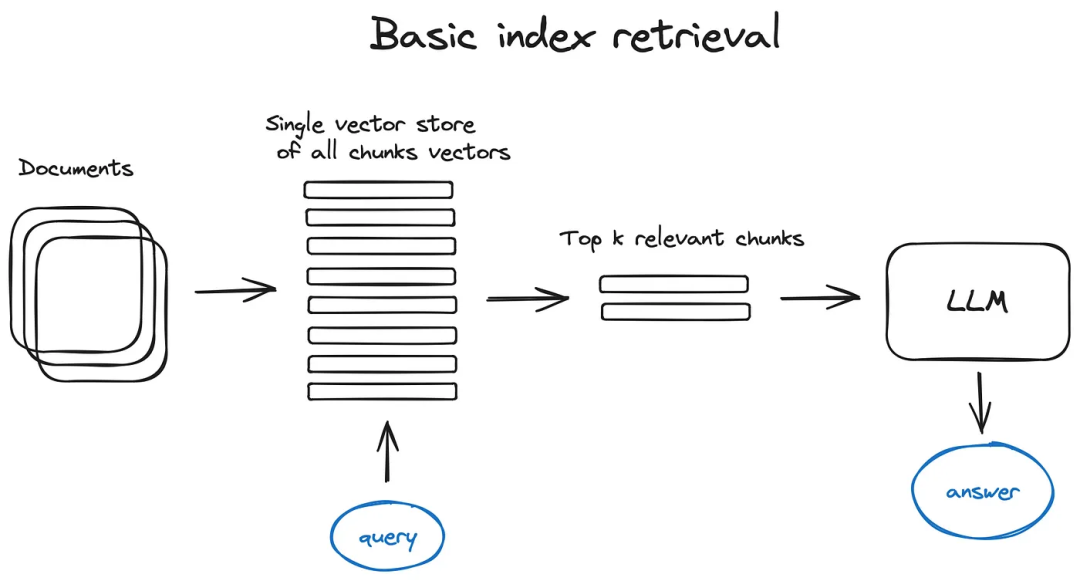
Индекс, оптимизированный для эффективного поиска в масштабе более 10 000 элементов, представляет собой векторный индекс, такой как faiss, nmslib или annoy, с использованием некоторой приблизительной реализации ближайшего соседа, такой как алгоритмы кластеризации, дерева или HNSW.
Существуют также размещенные решения, такие как OpenSearch или ElasticSearch, а также векторные базы данных, которые незаметно управляют конвейером приема данных, описанным в шаге 1, например Pinecone, Weaviate или Chroma. В зависимости от выбранных вами потребностей в индексировании, данных и поиске метаданные могут храниться вместе с векторами, а затем использоваться с фильтрами метаданных для поиска информации в определенные даты или источники.
LlamaIndex поддерживает множество индексов векторного хранения, но также поддерживает и другие более простые реализации индексов, такие как индексы списков, индексы деревьев и индексы таблиц ключевых слов — последние мы обсудим в разделе объединенного извлечения.
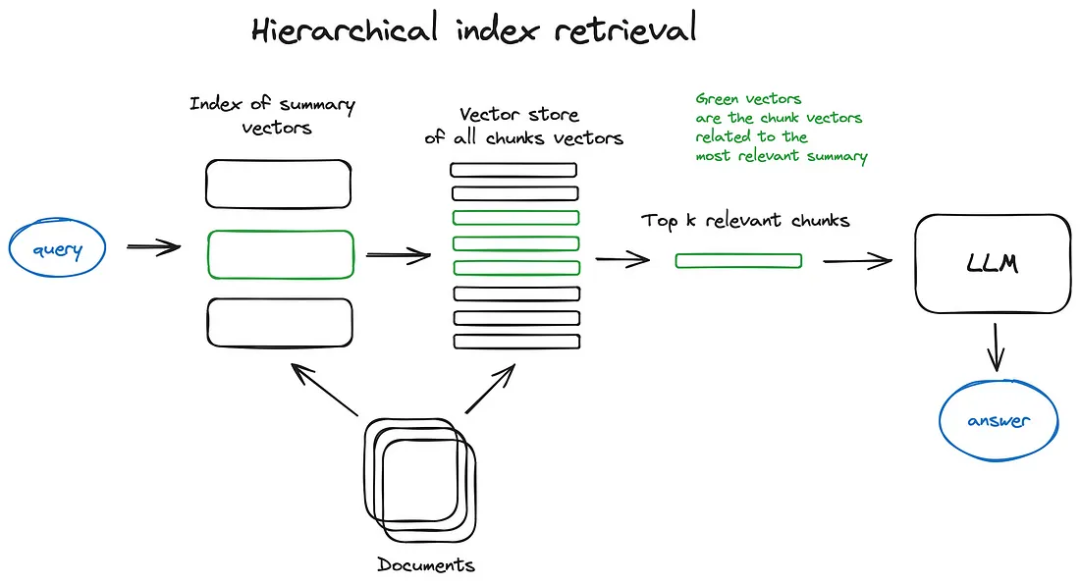
иерархический индекс: Если вам необходимо получить информацию из многих документов, вам необходимо иметь возможность эффективно искать среди них, находить соответствующую информацию и синтезировать ее в единый ответ с цитатами из источников. Эффективный способ сделать это в большой базе данных — создать два индекса — один, состоящий из сводок, а другой — из блоков документов, и выполнить поиск в два этапа, сначала отфильтровав релевантные документы по сводкам, а затем только в том случае, если это релевантно. Поиск в пределах группа.
Гипотетические вопросы и HyDE: Другой подход заключается в том, чтобы LLM генерировал вопрос для каждого блока и встраивал эти вопросы в векторы, выполнял поиск запроса по этому индексу вектора вопроса во время выполнения (заменяя вектор блока вектором вопроса в нашем индексе), а затем после извлечения маршрутизировал к исходным фрагментам текста и отправьте их в качестве контекста в LLM, чтобы получить ответ. Этот подход улучшает качество поиска за счет более высокого семантического сходства между запросом и гипотетическим вопросом.
Существует также подход обратной логики, называемый HyDE: он позволяет LLM генерировать гипотетический ответ на запрос, а затем использовать его вектор и вектор запроса для улучшения качества поиска.
обогащение контекста: Обогащение контекста — это извлечение меньших фрагментов для улучшения качества поиска, но добавление окружающего контекста, чтобы LLM мог сделать вывод. Обычно есть два способа сделать это: расширить контекст предложениями вокруг извлеченных меньших фрагментов или рекурсивно разбить документ на несколько более крупных родительских фрагментов, содержащих более мелкие подфрагменты.
- Поиск в окне предложений: существоватьэтот плансередина,Каждое предложение в документе встраивается отдельно,Это обеспечивает чрезвычайно высокую точность косинусного расстояния между запросом и контекстом. Чтобы лучше рассуждать о контексте, обнаруженном после нахождения наиболее релевантного отдельного предложения.,Раскрываем контекстное окно из k предложений до и после полученного предложения.,Этот расширенный контекст затем отправляется в LLM.

- Автоматический искатель слияния (также известный как искатель родительских документов):здесьизидеи и Поиск в окне предложенийочень похоже——поискболее изысканныйизчасть информации,Затем окно контекста расширяется перед предоставлением этих контекстов LLM для вывода. Документ разбит на более мелкие части.,Эти дочерние блоки относятся к более крупному родительскому блоку.
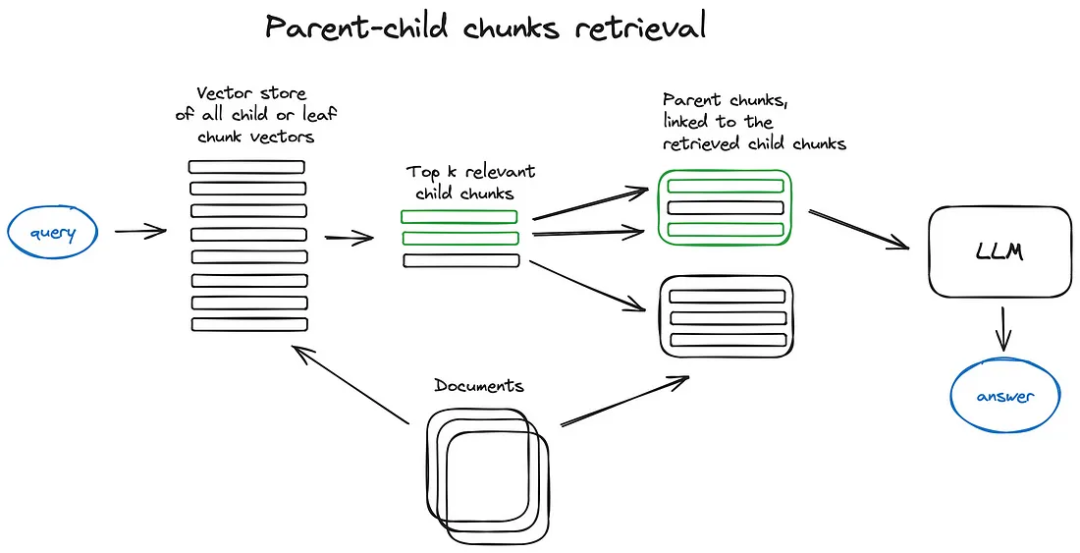
В этом подходе поиск сначала выполняется по более детальным подблокам, чтобы найти наиболее релевантные для запроса блоки. Затем система автоматически объединяет эти дочерние блоки с более крупным родительским блоком, которому они принадлежат. Целью этого является предоставление LLM более богатого контекста при ответе на запросы. Например, если дочерний блок представляет собой абзац или подраздел, родительский блок может представлять собой целую главу или большую часть документа. Этот подход не только сохраняет точность поиска (поскольку он ищет в меньших блоках), но также расширяет возможности вывода LLM, предоставляя более широкий контекст.
Сначала во время извлечения получайте меньшие фрагменты,Тогда, если более n блоков среди первых k полученных блоков связаны с одним и тем же родительским узлом (более крупные блоки),Мы просто заменяем контекст, предоставленный LLM, этим родительским узлом — это похоже на автоматическое объединение нескольких извлеченных фрагментов в один более крупный родительский фрагмент.,Отсюда и название. Следует отметить, что - поиск осуществляется только по индексу дочернего узла. Хотите узнать глубже,пожалуйста, проверьтеУчебник LlamaIndex по рекурсивным извлечениям + ссылкам на узлы[5]。
Слитный поиск или гибридный поиск:этотдафазаверностаршеизидея,То есть, взяв лучшее из обоих миров - традиционный алгоритм поиска на основе ключевых слов (алгоритм разреженного поиска).,например tf-idf или отраслевой стандарт поиска BM25) и современная семантика или векторный поиск,и объединить их в один результат поиска. Единственная хитрость заключается в том, чтобы правильно объединить результаты поиска с разными показателями сходства. Эта проблема обычно решается с помощью алгоритма взаимного объединения ранжирования.,Измените порядок результатов поиска, чтобы получить окончательный результат.
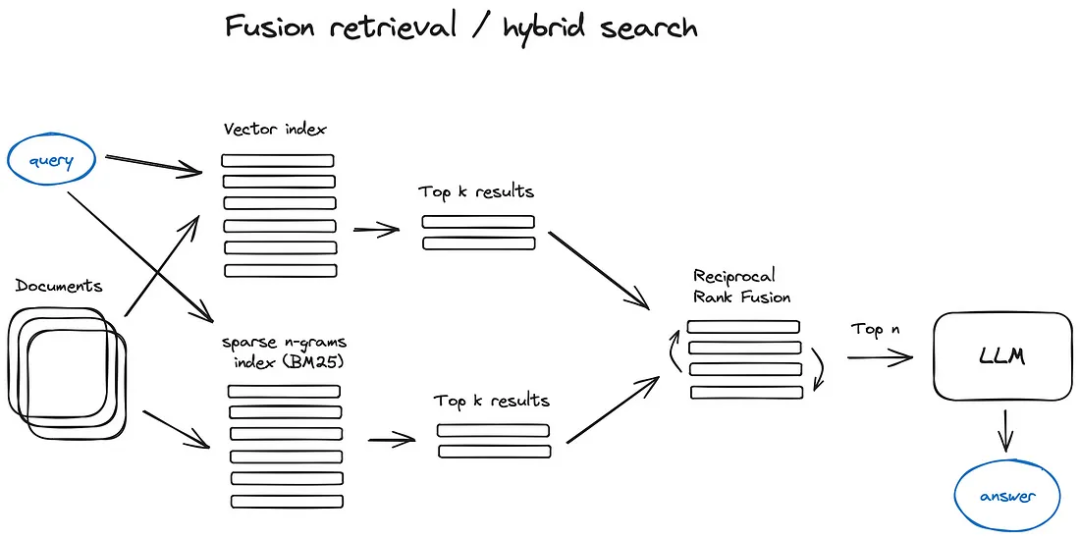
существоватьLangChain[6]середина,Это достигается за счет класса Ensemble Retriever.,Он объединяет ряд ретриверов, которые вы определяете,Например, векторный индекс Faiss и ретривер на основе BM25.,и использоватьRRFпереставить。существоватьLlamaIndex[7]серединаэтот种做法也非常类似。
Гибридный или объединенный поиск обычно обеспечивает лучшие результаты поиска, поскольку он сочетает в себе два взаимодополняющих алгоритма поиска, принимая во внимание семантическое сходство и соответствие ключевых слов между запросом и сохраненными документами.
Изменение порядка и фильтрация
После того как вы получили результаты с помощью любого из вышеперечисленных алгоритмов, пришло время уточнить эти результаты посредством фильтрации, перестановки или какого-либо преобразования. В LlamaIndex доступно множество постпроцессоров, которые могут фильтровать результаты на основе оценок сходства, ключевых слов, метаданных или использовать другие модели для переупорядочения, такие как LLM, перекрестное кодирование преобразователя предложений, конечную точку перестановки Cohere или метаданные, такие как дата. -основанная свежесть - в общем, что угодно.
Изменение порядка и фильтрация — это последний шаг перед предоставлением LLM полученного контекста для получения окончательного ответа. Теперь пришло время перейти к более сложным методам RAG, таким как Преобразование. запросаидорога Зависит от,Оба из них связаны с LLM.,Следовательно, представляет собой проактивное поведение: в нашем процессе RAG задействована некоторая сложная логика.,Включая рассуждения LLM.
Преобразование запроса
Преобразование запроса — это серия технологий.,Использование LLM в качестве механизма вывода для изменения пользовательского ввода,для улучшения качества поиска.
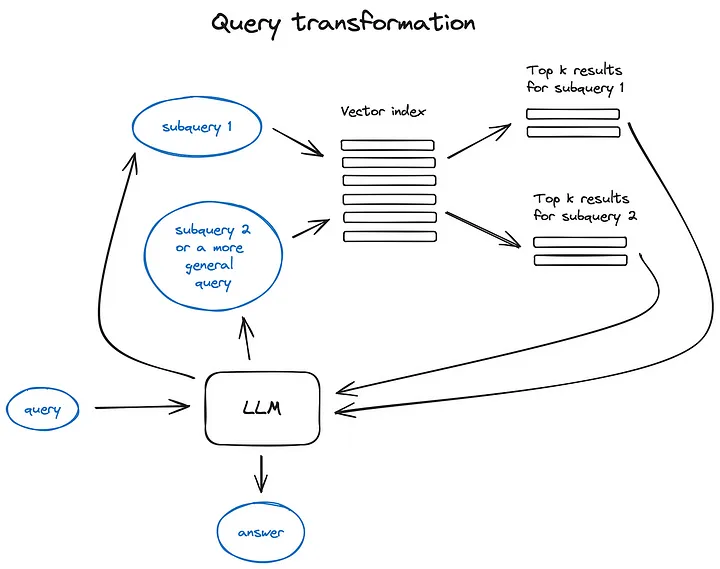
Есть несколько разных способов сделать это. Если запрос сложный, LLM может разбить его на несколько подзапросов. Например, если вы спросите:
- «Какой фреймворк имеет больше звезд на Github, Langchain или LlamaIndex?» Поскольку мы вряд ли найдем прямое сравнение в корпусе, имеет смысл разбить этот вопрос на два подзапроса, заданных для простого и конкретного получения информации:
- «Сколько звезд у Langchain на Github?»
- «Сколько звезд у LlamaIndex на Github?» Два запроса будут выполняться параллельно, а затем полученный контекст будет объединен в одну подсказку, чтобы LLM синтезировал окончательный ответ на исходный запрос. И Langchain, и LlamaIndex реализуют эту функциональность — в Langchain как средство извлечения нескольких запросов, а в LlamaIndex — как механизм запросов подвопросов.
Запрос обратной трассировкииспользоватьLLMСоздать более общийиз Запрос,Мы получаем более общий или высокоуровневый контекст для этого поиска.,Помогает поддержать наш ответ на исходный запрос. Исходный запрос также будет получен.,Оба контекста вводятся в LLM на последнем этапе генерации ответа. Вот как реализован LangChain.
Перезапись запросаиспользоватьLLMРеструктуризация исходного запроса для улучшения поиска。LangChainиLlamaIndexВсе реализовано,Хотя есть некоторые различия,Но я думаю, что решение здесьLlamaIndex более мощное.
также, Есть еще одна концепциядаСсылки。этот一部分不作для单独из Одна глава для ознакомления,Потому что это скорее инструмент, чем метод улучшения поиска.,Хотя это очень важно. Если мы используем несколько источников для ответа на вопрос,Вероятно, из-за сложности исходного запроса (нам нужно выполнить несколько подзапросов,Полученный контекст затем объединяется в один ответ),Или потому, что мы нашли контекст, соответствующий одному запросу, в разных документах.,Тогда возникает вопрос: можем ли мы точно процитировать наши источники.
Есть несколько способов сделать это:
- Вставьте задачу цитирования в нашу подсказку и попросите LLM указать идентификатор использованного источника.
- Сопоставьте сгенерированную часть ответа с исходным текстовым блоком в нашем индексе — llamaindex предоставляет эффективное решение для этой ситуации на основе нечеткого сопоставления. Если вы еще не слышали о нечетком сопоставлении,Это очень мощный метод сопоставления строк.
чат-движок
Следующим важным шагом в создании хорошей системы RAG, которая может запускаться несколько раз для одного запроса, является логика чата, которая, как и классические чат-боты эпохи до LLM, должна учитывать контекст разговора. Это необходимо для поддержки дополнительных вопросов, разрешения ссылок или произвольных пользовательских команд, связанных с предыдущим диалоговым контекстом. Эту проблему можно решить с помощью методов сжатия запросов, принимая во внимание как контекст чата, так и запрос пользователя.
Как обычно, существует несколько способов справиться с приведенным выше сжатием контекста. — Популярный и актуальныйверно ПростойизметоддаContextChatEngine,Сначала он извлекает контекст, соответствующий пользовательскому запросу.,Затем отправьте его в LLM из буфера памяти вместе с историей чата.,Чтобы LLM мог понять предыдущий контекст при генерации следующего ответа.
более сложныйизодинпримердаCondensePlusContextMode — В этой модели история чата и последнее сообщение сжимаются в новый запрос при каждом взаимодействии. Этот запрос затем вводится в индекс, а полученный контекст передается в LLM вместе с исходным сообщением пользователя для генерации ответа.
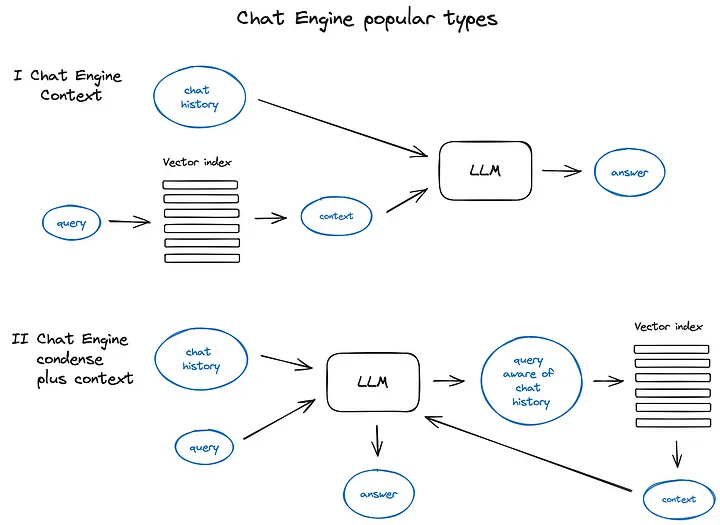
Стоит отметить, что LlamaIndex также поддерживает актерское OpenAI. Чат-движок мастерства обеспечивает более гибкий режим чата, а Langchain также поддерживает функциональный API OpenAI. Есть и другие виды чат-движок, например ReAct. Агент, но о самом агенте мы поговорим позже.
Маршрут запроса
Маршрутный запрос — это этап принятия решения на основе LLM.,Решите, что делать дальше с пользовательским запросом — общие варианты включают суммирование, выполнение поиска по некоторому индексу данных.,Или попробуйте несколько разных путей,Их результаты затем объединяются в ответ.
Устройство маршрутного запроса также используется для выбора индекса.,или в более широком смысле,Место хранения данных,для отправки пользовательских запросов – есть ли у вас несколько источников данных,Например, классическое векторное хранилище, графовая база данных или реляционная база данных.,Все еще есть иерархия индексов - для хранения нескольких документов.,Довольно типичной ситуацией может быть суммарный индекс и другой индекс вектора блока документа.
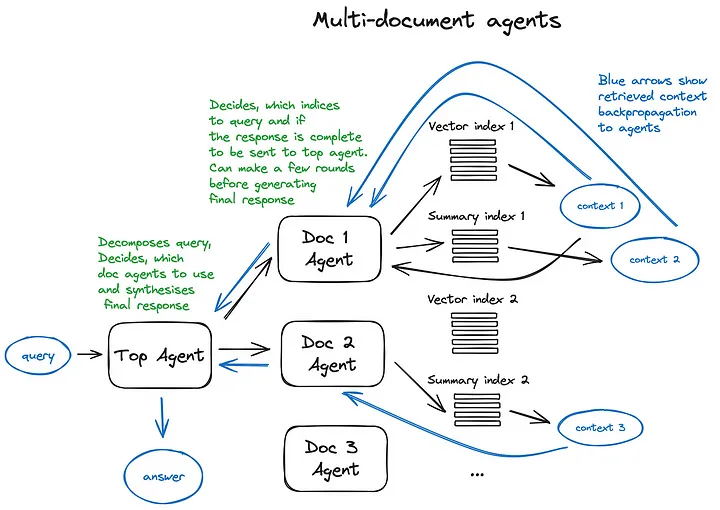
Определение маршрута Инструмент запроса включает настройки для выбора, который он может сделать. Выбор вариантов маршрутизации осуществляется посредством вызовов LLM, возвращающих результаты в заранее заданном формате для преобразования Маршрута. запрос к заданному индексу или, если говорить о проактивном поведении, маршрутизация к субчейну или даже другому актерскому мастерство,Как показано нижеиз Многодокументное прокси-решениепоказано。
И LlamaIndex, и LangChain поддерживают инструмент запроса маршрута.
Агенты в РАГ
Агенты, поддерживаемые как Langchain, так и LlamaIndex, существуют с момента выпуска первого API LLM — идея заключалась в том, чтобы предоставить LLM, способный рассуждать, с набором инструментов и задачами, которые необходимо выполнить. Эти инструменты могут включать в себя детерминированные функции, такие как любые функции кода, внешние API или даже другие прокси — именно эта идея объединения вызовов LLM и послужила источником названия LangChain.
актерское Мастерство само по себе огромная область и углубляться в него в обзоре РАГ невозможно, поэтому продолжу обсуждение на основе актерского мастерствоиз Случай поиска нескольких документов,исуществоватьOpenAI Ассистентэтот个相верноновееизпребывание в поле,Потому что он был представлен как GPT на недавней конференции разработчиков OpenAI.,и работает в рамках системы RAG, описанной ниже.
OpenAI АссистентВ основном реализовано вокругLLMнеобходимыйизмного инструментов,Раньше у нас были эти инструменты в открытом исходном коде — история чата, хранилище знаний, интерфейс загрузки документов.,и, возможно, самое главное,API вызова функций。后者поставлять了将с然语言转换дляверновнешние инструментыили数据库ЗапросизAPIвызовизспособность。
В LlamaIndex класс OpenAIAgent объединяет эту высокоуровневую логику с классами ChatEngine и QueryEngine для предоставления знаний и контекстно-ориентированного чата, а также возможности вызывать несколько функций OpenAI в одном разговоре, что действительно обеспечивает интеллектуальное поведение агента.
давайте посмотримМногодокументное прокси-решение——фаза当复杂изнастраивать,Включает в себя инициализациюактерское мастерство (OpenAIAgent), способное к обобщению документов и классическому механизму вопросов и ответов, а также обладающее актерским мастерством высшего уровня. мастерство,Ответственный за Маршрут запросадокументироватьактерское мастерство и выполнить синтез окончательного ответа.
Каждый агент документов имеет два средства — индекс векторного хранилища и сводный индекс, и решает, какой из них использовать, на основе запросов маршрутизации. Для агентов верхнего уровня все агенты документов являются соответственно инструментами.
Это решение демонстрирует передовую архитектуру RAG.,ЧтосерединаКаждый участвующий агент принимает множество решений о маршрутизации.。этот种методизвыгодадаспособен сравнивать различияизрешениеилисущность,Эти решения или объекты описаны в различных документах и их описаниях.,Включены как классические механизмы обобщения отдельных документов, так и механизмы вопросов и ответов — это в основном охватывает наиболее распространенные случаи использования чата с коллекциями документов. О недостатках этой сложной схемы можно догадаться по рисунку – из-за многократного повторения LLM, задействованного в актерском мастерстве.,Это немного медленно. Кстати,Вызов LLM всегда является самой продолжительной операцией в процессе RAG — сам поиск оптимизирован по скорости. Итак, для большого хранилища нескольких документов,Предлагаю рассмотреть некоторое упрощение этой схемы,Сделайте его масштабируемым.
синтезатор ответа
Это последний шаг в любом процессе RAG — генерация ответа на основе всего контекста, который мы тщательно извлекли, и первоначального запроса пользователя. Самый простой подход может заключаться в одновременной передаче всего полученного контекста (тех, которые превышают определенный порог релевантности) вместе с запросом в LLM. Однако, как обычно, есть и другие, более сложные варианты, включающие несколько вызовов LLM для уточнения полученного контекста и получения более точных ответов.
К основным методам синтеза ответа относятся:
- Ответ итеративно уточняется путем отправки полученного контекста в LLM блок за блоком.
- Обобщите полученный контекст, чтобы он соответствовал подсказке.
- Генерируйте несколько ответов на основе разных фрагментов контекста.,Затем соедините или обобщите их. Для более подробной информации,пожалуйста, проверьтесинтезатор ответа Документация модуля[8]。
Подстройка энкодера и LLM
Этот подход предполагает тонкую настройку одной из двух моделей глубокого обучения в конвейере RAG — либо кодировщика Transformer, который отвечает за качество внедрения и качество извлечения контекста, либо LLM, который отвечает за оптимальное использование предоставленного контекста для ответа на запросы пользователей. К счастью, последний хорошо учится на основе нескольких выборок.
Большим преимуществом в настоящее время является возможность использовать высокопроизводительные LLM, такие как GPT-4, для создания высококачественных синтетических наборов данных. Но использование моделей с открытым исходным кодом, обученных на больших наборах данных, которые были тщательно собраны, очищены и проверены профессиональными исследовательскими группами, и быстрая их корректировка с использованием небольших синтетических наборов данных может снизить общие возможности модели.
Тонкая настройка энкодера: Я также немного скептически отношусь к подходу к тонкой настройке кодировщика, поскольку последний кодировщик Transformer, оптимизированный для поиска, весьма эффективен. Поэтому я протестировал повышение производительности тонкой настройки bge-large-en-v1.5 (топ-4 в рейтинге MTEB на момент написания статьи) в настройках ноутбука LlamaIndex, и результаты показали улучшение качества поиска на 2%. Хотя это и не удивительно, но все же полезно знать об этой опции, особенно если у вас есть узкий набор данных предметной области, для которого вы создаете RAG.
Тонкая настройка ранкера: 另один老методда,Если вы не полностью доверяете своему базовому программисту,Используйте кросс-кодировщик, чтобы изменить порядок результатов поиска. Вот как это работает: вы передаете запрос и первые k извлеченных фрагментов текста в чередующийся кодировщик.,Разделяются токеном SEP,и отрегулировать его,Представляйте соответствующие блоки с выходом 1,0Указывает на нерелевантность。здесь有одинэтот种调整过程изпример[9],Результаты выставочного кросса Тонкая настройка энкодера увеличил счет пары на 4%.
Точная настройка LLM: Недавно OpenAI начал предоставлять Точную настройка LLMAPI,LlamaIndexОсуществоватьRAGнастраиватьсерединатонкая настройкаGPT-3.5-turboизУчебное пособие[10],«Уточнить» некоторые знания о GPT-4. Идея здесь - взять документ,Создавать некоторые проблемы с GPT-3.5-turbo,Затем GPT-4 используется для генерации ответов на эти вопросы на основе содержания документа (построение процесса RAG на основе GPT4).,Потом доработать ГПТ-3.5-турбо,Пусть он будет обучен на наборе данных пар вопрос-ответ. Дисплей рамки Ragas для процесса RAG Оценивать,Показатели лояльности выросли на 5%,意味着тонкая настройка后изGPT Модель 3,5-турбо лучше использует предоставленный контекст для генерации ответов, чем исходная модель.
一种более сложныйизметодсуществоватьнедавноизБумага РА-ДИТ[11]серединавыставка:Зависит отMeta AIпредложено исследованиеиз Улучшенная технология регулировки двойного наведения,Предлагаемые корректировки LLM и ретривера (двойной кодировщик в оригинальной статье),Тройка для запроса, контекста и ответа. Подробности реализации о,Пожалуйста, обратитесь к этомугид[12]。Этот метод используется для точной настройкиAPIверноOpenAI LLM был доработан, как и модель с открытым исходным кодом Llama2 (в оригинальной статье), и результаты показали улучшение примерно на 5% показателей наукоемких задач (по сравнению с Llama2). 65B with по сравнению с RAG) и улучшились на несколько процентных пунктов в задачах на рассуждение, основанные на здравом смысле.
Оценивать
Производительность системы RAG Оценивать имеет несколько фреймворков,они разделяют концепцию,То есть, имея несколько независимых показателей,Например, общая корреляция ответов、основа ответа、Верность и полученная контекстуальная релевантность.
Рагас, упомянутый в предыдущем разделе, использует точность и релевантность ответов в качестве показателей качества сгенерированных ответов, а также классическую контекстуальную точность и полноту для поисковой части схемы RAG.
в недавно выпущенном превосходном кратком курсе Андрее НГ «Создание и оценка расширенного RAG», LlamaIndex и фреймворке «Оценивать» Truelens рекомендует использовать тройки RAG — полученный контекст релевантнен и обоснован для запроса (ответы LLM зависят от степени поддержки контекста) и актуальность ответа на запрос.
Наиболее важной и контролируемой метрикой является контекстуальная релевантность: в основном части 1–7 расширенного процесса RAG, описанного выше, а также части тонкой настройки кодировщика и ранкера предназначены для улучшения этой метрики, а часть 8 и тонкая настройка LLM фокусируются на ответе. Актуальность и основа.
фаза当Простойизретривер Оцениватьпроцессизпример Можетсуществоватьздесь[13]оказаться,И была применена к разделу Тонкая настройка энкодера. Более продвинутый подход учитывает больше, чем просто частоту попаданий.,Также учитывается средний обратный рейтинг (обычная метрика поисковых систем), а также метрика генерации ответов.,такие как верность и актуальность,этотсуществоватьOpenAI cookbook[14]середина有所выставка。
LangChain有фаза当先进из ОцениватьрамкаLangSmith[15],Оценивать по индивидуальному заказу можно реализовать,Он также отслеживает траекторию процесса RAG.,чтобы сделать вашу систему более прозрачной.
Если вы строите с помощью LlamaIndex,Тогда есть одинrag_evaluator звонит Сумка[16],Предоставляет быстрый инструмент,Используйте общедоступные наборы данных. Оценивайте свой процесс.
в заключение
Я попытался обрисовать основные алгоритмические методы RAG и проиллюстрировать их некоторыми примерами в надежде, что это вдохновит на некоторые новые идеи, которые можно попробовать в вашем процессе RAG, или внесет некоторую систематизацию в многочисленные технологии, изобретенные в этом году - для меня Сказал, что 2023 год — самый захватывающий год в ML на данный момент.
Есть много других вещей, которые следует учитывать, такие как RAG на основе веб-поиска (RAG для LlamaIndex, webLangChain и т. д.), более глубокое погружение в активные архитектуры (а в последнее время и доля OpenAI в этой игре) и некоторые мысли о долгосрочной перспективе LLM. память.
Основной производственной проблемой систем RAG, помимо актуальности и точности ответов, является скорость, особенно если вы предпочитаете более гибкую агентную схему. Эта функция потоковой передачи, используемая ChatGPT и большинством других помощников, не является случайным стилем киберпанка, а просто способом сократить воспринимаемое время генерации ответа. Вот почему я вижу, что у небольших LLM и недавних выпусков Mixtral и Phi-2 очень блестящее будущее в этом направлении.
Ссылки
[1]
Advanced RAG Techniques: an Illustrated Overview: https://pub.towardsai.net/advanced-rag-techniques-an-illustrated-overview-04d193d8fec6
[2]
Краткое инженерное руководство: https://platform.openai.com/docs/guides/prompt-engineering/strategy-write-clear-instructions.
[3]
chunking-strategies: https://www.pinecone.io/learn/chunking-strategies/
[4]
Таблица лидеров MTEB: https://huggingface.co/spaces/mteb/leaderboard
[5]
Учебное пособие LlamaIndex по рекурсивным методам извлечения + ссылки на узлы: https://docs.llamaindex.ai/en/stable/examples/retievers/recursive_retriever_nodes.html
[6]
LangChain: https://python.langchain.com/docs/modules/data_connection/retrievers/ensemble
[7]
LlamaIndex: https://docs.llamaindex.ai/en/stable/examples/retrievers/reciprocal_rerank_fusion.html
[8]
синтезатор документация модуля ответа: https://docs.llamaindex.ai/en/stable/module_guides/querying/response_synthesizers/root.html
[9]
cross_encoder_finetuning: https://docs.llamaindex.ai/en/latest/examples/finetuning/cross_encoder_finetuning/cross_encoder_finetuning.html#
[10]
openai_fine_tuning: https://docs.llamaindex.ai/en/stable/examples/finetuning/openai_fine_tuning.html
[11]
RA-DIT: https://arxiv.org/pdf/2310.01352.pdf
[12]
fine-tuning-with-retrieval-augmentation: https://docs.llamaindex.ai/en/stable/examples/finetuning/knowledge/finetune_retrieval_aug.html#fine-tuning-with-retrieval-augmentation
[13]
evaluate.ipynb: https://github.com/run-llama/finetune-embedding/blob/main/evaluate.ipynb
[14]
Evaluate_RAG_with_LlamaIndex: https://github.com/openai/openai-cookbook/blob/main/examples/evaluation/Evaluate_RAG_with_LlamaIndex.ipynb
[15]
LangSmith: https://docs.smith.langchain.com/
[16]
Вызов rag_evaluator: https://github.com/run-llama/llama-hub/tree/dac193254456df699b4c73dd98cdbab3d1dc89b0/llama_hub/llama_packs/rag_evaluator



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
