Предварительное обучение больших языковых моделей [2]: теоретические знания, связанные с GPT, GPT2, GPT3, GPT3.5, GPT4 и реализация модели, применение модели и подробное объяснение различий между каждой версией.
Предварительное обучение большим языковым моделям 2: теоретические знания, связанные с GPT, GPT2, GPT3, GPT3.5, GPT4 и реализация модели, применение модели и подробное объяснение различий между каждой версией.
1. Модель GPT
1.1 Введение в модель GPT
В задачах обработки естественного языка из Интернета можно загрузить большой объем неразмеченных данных, но для конкретных задач очень мало размеченных данных. GPT — это полуконтролируемый метод обучения, который предназначен для использования большого количества неразмеченных данных. чтобы позволить модели учиться. «здравый смысл», чтобы облегчить проблему недостаточности информации в аннотациях. Конкретный метод заключается в предварительном обучении модели. Предварительное обучение с использованием неразмеченных данных перед обучением. Точная настройка помеченных данных и обеспечение того, чтобы два обучения имели одинаковую сетевую структуру. Нижний уровень GPT также основан на модели Transformer. Отличие от модели Transformer для задач перевода заключается в том, что он использует только несколько слоев Deocder.
На рисунке ниже показана структура модели GPT и показано, как использовать ее для адаптации к таким проблемам, как множественная классификация, текстовая импликация, сходство и множественный выбор, без изменения основной структуры модели.

Слева показана 12-слойная модель трансформера-декодера, соответствующая базовой модели трансформера. Справа видно, что в Fine-Tune различные задачи сначала объединяются через данные и подставляются в модель Трансформера, а затем к выводам данных базовой модели добавляется полносвязный слой (Линейный) для адаптации к формату модели. аннотированные данные.
Например, простейшая задача классификации, такая как задача определения эмоциональной окраски предложения, включает только одно предложение, и результатом является бинарная классификация. Следовательно, вам нужно только заменить предложения и добавить в конце полностью связный слой, поскольку между двумя предложениями нет связи, поэтому вам нужно добавить разделители, чтобы соединить два предложения в разном порядке соответственно; Введите модель, сгенерируйте различные данные скрытого слоя, а затем подставьте их в окончательный полностью связный слой.
1.2 Реализация модели
В части предварительного обучения u используется для представления каждого токена (слова). Когда длина окна установлена равной k и предсказано i-е слово в предложении, используются k слов перед i-м словом, а также на основе гиперпараметров Θ, чтобы предсказать, каким скорее всего будет i-е слово. Короче говоря, предыдущие слова используются для предсказания следующих слов.

Конкретный метод заключается в замене модели Трансформера. Модель в следующей формуле состоит из L групп скрытых слоев. Исходные данные, вводимые в скрытый слой, представляют собой кодировку слова U, умноженную на параметр встраивания слова We плюс параметр положения Wp; позже он проходит через L слоев (как показано в левой части рисунка выше) группы Трансформаторов).
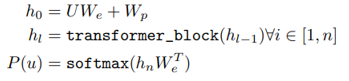
В части тонкой настройки контролируемого обучения, например, для определения эмоциональной окраски предложения (задача двух категорий), предложение содержит m слов x1... Введите параметр Wy связи между информацией x и целью y и, наконец, предсказать цель y.
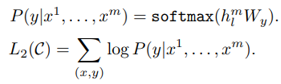
Принимая во внимание L1 и L2 в приведенной выше формуле, добавьте весовой параметр λ, чтобы контролировать их соотношение, чтобы вычислить L3 в качестве основы для оптимизации.
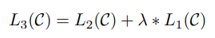
Также GPT имеет следующие модификации по сравнению с базовым Трансформером:
- Принимая GLUE (линейную единицу ошибки Гаусса) в качестве функции ошибки, GLUE можно рассматривать как улучшенный метод ReLU, преобразующий данные меньше 1 в 0, оставляя часть больше 1 неизменной, в то время как GELU слегка корректирует ее, как показано на рисунке. рисунок ниже:

- Кодирование положения: базовый преобразователь использует функции синуса и косинуса для построения информации о местоположении, а информация о положении не требует обучения соответствующих параметров, в то время как GPT использует информацию об абсолютном положении в качестве кодирования.
1.3 Эффект модели
GPT модифицирован на основе Transformer и обучен на корпусе из 800 миллионов слов. Он имеет 12 слоев декодера, 12 голов внимания, а размерность скрытого слоя составляет 768.
GPT превзошел предыдущие модели в различных оценках рассуждений на естественном языке, классификации, ответах на вопросы и сравнительном сходстве. И он хорошо работает как с небольшими наборами данных, такими как STS-B (около 5,7 тысяч экземпляров обучающих данных), так и с большими наборами данных (550 тысяч обучающих данных). Даже при предварительной тренировке можно выполнить некоторые задачи Zero-Shot. Однако, поскольку соответствие между немаркированными данными и конкретными задачами низкое, обучение происходит медленнее и требует больше вычислительной мощности.
1.4 Применение модели
Модели GPT можно использовать для создания текста на естественном языке. В практических приложениях модель GPT может применяться к нескольким сценариям. Ниже приведены некоторые распространенные сценарии применения.
- Генерация языка. Модель GPT можно использовать для создания текстов на естественном языке, таких как статьи, беседы, новости, романы и т. д. Этот сценарий применения можно применить к автоматическому написанию, машинному переводу, интеллектуальному обслуживанию клиентов и другим областям.
- Понимание языка. Модель GPT можно использовать для понимания естественного языка, например, для классификации текста, анализа настроений, распознавания объектов и т. д. Этот сценарий применения можно применить к поисковым системам, рекламным рекомендациям, мониторингу общественного мнения и другим областям.
- Диалоговая система: GPT Модель можно использовать для создания надежных чат-систем, таких как интеллектуальная служба поддержки клиентов и чат-роботы. Это приложение-сцену можно использовать в сфере обслуживания клиентов, развлекательного ожидания.
- Языковая модель: модель GPT можно использовать для построения языковых моделей, таких как распознавание речи, машинный перевод и т. д. Этот сценарий применения можно применить к умным домам, интеллектуальному транспорту и другим областям.
Короче говоря, модель GPT может применяться к нескольким областям, включая генерацию естественного языка, понимание естественного языка, диалоговые системы, языковые модели и т. д. Благодаря постоянному развитию и применению технологий искусственного интеллекта сценарии применения модели GPT будут продолжать расширяться и углубляться.
2. Модель GPT2
GPT2 — это предварительно обученная языковая модель, выпущенная Open AI. Она демонстрирует потрясающую производительность при генерации текста. Генерируемый ею текст превосходит ожидания людей с точки зрения контекстуальной связности и эмоционального выражения. С точки зрения архитектуры модели, GPT-2 не имеет особенно новой архитектуры. GPT-2 продолжает использовать модель одностороннего трансформатора, первоначально использовавшуюся в GPT, и цель GPT-2 состоит в том, чтобы воспользоваться преимуществами односторонней архитектуры. Way Transformer, насколько это возможно. Создайте функцию, которая не может быть достигнута с помощью двустороннего преобразователя, используемого BERT, то есть сгенерируйте следующий текст из приведенного выше.
2.1 Архитектура модели GPT2
Структура GPT-2 аналогична модели GPT. Она по-прежнему использует модель одностороннего преобразователя и внесла лишь некоторые локальные изменения: например, переместила слой нормализации во входную позицию блока, добавив слой после последнего; блок самообслуживания Нормализация; увеличение словарного запаса и т. д. Схема структуры модели GPT2:

Структура декодера Transformer выглядит следующим образом:

Модель GPT-2 состоит из декодерной части многоуровневого одностороннего преобразователя. По сути, это авторегрессионная модель, то есть каждый раз, когда генерируется новое слово, новое слово добавляется в конец исходного ввода. предложение как новое входное предложение.
GPT-2 увеличивает количество слоев стека Transformer до 48, размерность скрытого слоя — 1600, а количество параметров достигает 1,5 миллиарда (Bert big — 340 миллионов). «Маленький» имеет 12 этажей, «Средний» — 24 этажа, «Большой» — 36 этажей, «Очень большой» — 48 этажей. GPT-2 обучил 4 набора моделей с разным количеством слоев и длиной вектора слов, как показано на рисунке:

GPT-2 исключает тонкую настройку обучения: есть только неконтролируемый этап предварительного обучения. Он больше не настраивает моделирование для различных задач. Вместо этого он не определяет, какие задачи должна выполнять модель. задачи нужно сделать. Для формирования набора данных собирается более широкий и крупный корпус. Набор данных содержит 8 миллионов веб-страниц и имеет размер 40 ГБ. Для GPT2 требуются данные с информацией о задачах. Предлагается новая парадигма НЛП, в которой особое внимание уделяется обучению высокопроизводительных языковых моделей с помощью более высококачественных обучающих данных для выполнения последующих многозадачных задач без присмотра. Попробуйте использовать метод общей языковой модели для решения большинства существующих задач НЛП.
2.2 Применение модели
Модель GPT-2 в основном используется для задач обработки естественного языка, таких как:
- Генерация текста: GPT-2 может учиться на больших объемах текстовых данных и генерировать статьи, рассказы или стихи, напоминающие человеческое письмо.
- Машинный перевод: GPT-2 может переводить текст на одном языке в текст на другом языке, например, китайско-английский перевод.
- Анализ настроений. Используя GPT-2 для анализа настроений, вы можете определить, является ли настроение, выраженное фрагментом текста, положительным, отрицательным или нейтральным.
- Классификация текста: GPT-2 может классифицировать текст по различным категориям, таким как классификация новостей, классификация обзоров фильмов и т. д.
- Система вопросов и ответов: GPT-2 может отвечать на вопросы пользователей и предоставлять соответствующую информацию и решения.
- Диалоговая система: GPT-2 Может имитировать человеческие разговоры, взаимодействовать с пользователями и отвечать на вопросы, заданные пользователями.
2.3 Оценка модели
- преимущество:
- Мощные возможности генерации: GPT-2 обладает отличными возможностями генерации текста и может генерировать связные и плавные статьи, истории и даже фрагменты кода.
- Контекстное понимание: изучая большой объем текстовых данных, эта модель может понимать контекст и генерировать логически связанные ответы.
- Многопрофильные приложения: GPT-2 хорошо применим для задач в нескольких областях, включая машинный перевод, создание сводок, диалоговые системы и т. д.
- Доступность предварительно обученных моделей. Предварительно обученные модели GPT-2 опубликованы в открытом доступе и могут быть легко настроены в соответствии с требованиями конкретных задач.
- Разнообразие языковых выражений: GPT-2 Он может генерировать разнообразные языковые выражения: от формальных до разговорных, от юмористических до серьезных, делая создаваемый текст более ярким и интересным.
- недостаток:
- Отсутствие здравого смысла и практических знаний. Хотя GPT-2 может генерировать связный текст, он не обладает собственным здравым смыслом и практическими знаниями и подвержен ложной или вводящей в заблуждение информации.
- Уязвимость к состязательным примерам. GPT-2 уязвим к состязательным примерам, которые представляют собой намеренно созданные входные данные, которые обманывают модель, что приводит к неточным или вводящим в заблуждение результатам.
- Отсутствие творчества и инициативы: GPT-2 представляет собой статистическую модель, основанную на большом объеме данных. Она не обладает настоящим творчеством и инициативой и может генерировать текст только в рамках существующих знаний.
- Существуют проблемы долгосрочных зависимостей: GPT-2 может столкнуться с проблемами долгосрочных зависимостей при обработке длинных текстов, в результате чего сгенерированный текст становится логически непоследовательным или бессвязным.
- Плохая интерпретируемость: GPT-2 Это модель «черного ящика», процесс принятия решений которой трудно объяснить и который не может обеспечить подробное обоснование или фактическое обоснование.
3. Модель GPT3
GPT3 (Генераторный предварительно обученный преобразователь 3) — это модель обработки естественного языка, разработанная OpenAI и в настоящее время признанная создательница больших языковых моделей. В серии GPT первое поколение GPT было выпущено в 2018 году и содержало 117 миллионов параметров. GPT2, выпущенный в 2019 году, содержит 1,5 миллиарда параметров. GPT3 же имеет 175 миллиардов параметров, что более чем в 100 раз больше, чем у его предшественницы и более чем в 10 раз больше, чем у аналогичных программ. GPT3 использует структуру нейронной сети Transformer в глубоком обучении и использует технологию предварительного обучения без учителя для автоматического решения различных задач на естественном языке, таких как генерация текста, вопросы и ответы, перевод и т. д.
GPT3 продолжает использовать собственный метод одностороннего обучения языковой модели, не только значительно увеличивая параметры модели, но и сосредотачиваясь на более общих моделях НЛП. Модель GPT3 хорошо работает в серии тестов производительности и задачах обработки естественного языка в конкретных областях (от). языковой перевод для генерации новостей) для достижения последних результатов SOTA. Для всех задач GPT3 не был доработан и взаимодействовал с моделью только посредством текста. То же, что и архитектура модели GPT2, как показано на рисунке ниже:

Однако по сравнению с GPT-2 функция генерации изображений GPT-3 более зрелая и может создавать полное изображение на основе неполных образцов изображений без точной настройки. GPT-3 означает, что скачок от одного поколения к трем поколениям достиг двух оборотов:
- поворот от языка к образу;
- Используйте меньше данных домена и не используйте шаги по тонкой настройке для решения проблемы.
3.1 Стратегия обучения GPT3
GPT3 обучается с использованием контекстного обучения для выполнения последующих задач. Контекстное обучение: учитывая несколько примеров задач или описание задачи, модель должна иметь возможность выполнять другие экземпляры задачи посредством простых прогнозов. Вот три метода ситуационного обучения:
- обучение с несколькими выстрелами (без распространения градиента, некоторые примеры также используются в качестве входных и выходных моделей при прогнозировании) неопределенное определение: разрешить ввод нескольких примеров и описания задачи неопределенное. Примером является следующий рисунок:
- однократное обучение (без распространения градиента, пример также используется в качестве входной и выходной модели при прогнозировании) неопределенное определение: разрешено вводить только один пример и одно описание задачи неопределенное Следующий рисунок является примером:
- обучение с нулевым выстрелом (без распространения градиента) неопределенное определение: вводить примеры нельзя, можно вводить только одно описание задачи. Неопределено Следующий рисунок является примером:
3.2 Производительность модели
GPT-3 работает лучше, чем наборы данных языкового моделирования, такие как LAMBADA и Penn Tree Bank, в настройках с несколькими или нулевыми выстрелами. Что касается других наборов данных, он не может превзойти современные модели, но улучшает современную производительность при нулевом выстреле.
GPT-3 также довольно хорошо справляется с задачами НЛП, такими как ответы на вопросы закрытой книги, анализ шаблонов, перевод и т. д., часто превосходя самые современные методы или наравне с точно настроенными моделями. Для большинства задач модель работает лучше при настройке «несколько выстрелов», чем при настройках «один выстрел» и «нулевой выстрел».
Помимо оценки традиционных задач НЛП, GPT-3 также оценивается по комплексным задачам, таким как арифметическое сложение, интерпретация слов, генерация новостей, а также изучение и использование новых слов. Для этих задач производительность также увеличивается с увеличением количества параметров, и модель работает лучше при нескольких настройках, чем при однократных и нулевых настройках.
На рисунке ниже показано, как GPT-3 можно понимать как метаобучение. Модель изучает множество различных задач, и ее можно сравнить с процессом метаобучения, поэтому она имеет лучшее обобщение.

3.3 Ограничения
Хотя GPT-3 способен создавать высококачественный текст, он иногда начинает терять связность при формировании длинных предложений и многократном повторении текстовых последовательностей.
Ограничения GPT-3 включают сложный и дорогостоящий вывод модели из-за его тяжелой архитектуры, низкую интерпретируемость результатов, полученных с помощью языка и модели, а также неуверенность в том, что помогает модели достичь небольшого количества обучающих действий.
3.4 Применение модели
GPT-3 — очень мощная языковая модель, которую можно использовать во многих различных приложениях и областях:
- Генерация естественного языка: GPT-3 можно использовать для автоматического создания различных типов текста, таких как статьи, электронные письма, описания продуктов и т. д.
- Интеллектуальное обслуживание клиентов: GPT-3 можно использовать для создания чат-ботов для решения проблем клиентов и оказания помощи.
- Помощник по написанию: GPT-3 предлагает темы, абзацы и предложения, автоматически генерируя соответствующий текст на основе введенных пользователем данных.
- Языковой перевод: GPT-3 можно использовать для перевода текста между разными языками, тем самым способствуя межкультурному общению.
- Автоматическое обобщение: GPT-3 можно использовать для автоматического извлечения основной информации и основных моментов статьи или документа, помогая пользователям быстрее понять их содержание.
- Виртуальные помощники: GPT-3 можно использовать для создания виртуальных помощников, таких как Siri или Alexa. Он может понимать инструкции пользователя и выполнять соответствующие операции.
- Персональные рекомендации: GPT-3 может анализировать историческое поведение и предпочтения пользователей, чтобы предоставлять им персональные рекомендации по продуктам.
- Интеллектуальный поиск: GPT-3 можно использовать для улучшения результатов поисковых систем, предоставляя более точные ответы и предложения.
- Автоматизированное программирование: GPT-3 можно использовать для автоматического создания кода и сценариев, что экономит время разработчиков и уменьшает количество ошибок.
- Художественное творчество: возможности генерации текста GPT-3 можно использовать для создания стихов, романов, сценариев и других форм искусства, тем самым обеспечивая новый литературный опыт.
Это лишь некоторые области применения GPT-3. С развитием технологий GPT-3 будет применяться во все большем количестве областей.
4. Большая языковая модель GPT3.5
GPT3.5 — это модель чат-бота, разработанная OpenAI. Она может имитировать поведение человеческого языка и естественным образом взаимодействовать с пользователями. Его название происходит от используемой технологии — архитектуры GPT-3, третьего поколения генеративных языковых моделей. В то же время модель интеллектуального чат-бота ChatGPT была разработана на основе GPT3.5. GPT3.5 имитирует поведение человеческого языка, используя большой объем обучающих данных, и генерирует текст, понятный людям, посредством синтаксического и семантического анализа. Он может давать точные и соответствующие ответы в зависимости от контекста и контекста, а также имитировать различные эмоции и тона. Таким образом, пользователи могут получить более реальный и естественный опыт общения при взаимодействии с машиной.
Модель GPT3.5 не сильно изменилась по сравнению с предыдущей GPT-3. Основное изменение заключается в том, что изменилась стратегия обучения и было использовано обучение с подкреплением. На следующем рисунке показана структурная схема модели GPT3.5:
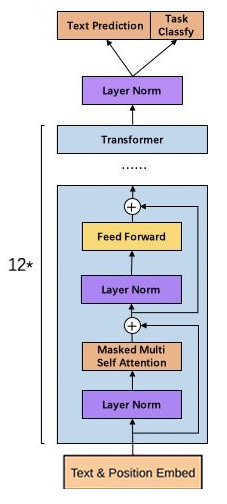
4.1 Стратегия обучения GPT3.5
Стратегия обучения GPT3.5 использует для обучения модель вознаграждения. Цель модели вознаграждения (RM) — определить, хорошо ли результаты модели работают в глазах человека. То есть подсказка ввода (приглашение) текста, генерируемого моделью, выводит скалярное число, характеризующее качество текста.

Модель вознаграждения можно рассматривать как дискриминативную языковую модель, поэтому ее можно начать с предварительно обученной языковой модели, а затем точно настроить на аннотированном корпусе, состоящем из [x = подсказка, модельный ответ, y = человеческое удовлетворение], или его можно напрямую рандомизировать. Инициализировать и обучать непосредственно в корпусе.
4.2 Оптимизация языковой модели на основе обучения с подкреплением (RL)
GPT3.5 моделирует задачу тонкой настройки исходной языковой модели как задачу обучения с подкреплением (RL), поэтому необходимо определить основные элементы, такие как политика, пространство действий и функция вознаграждения.
Стратегия основана на языковой модели, получает подсказку в качестве входных данных, а затем выводит серию текста (или вероятностное распределение текста, а пространство действий представляет собой расположение и комбинацию всех токенов в словаре на всех выходных позициях (a); одна позиция обычно имеет около 50 тыс. кандидатов на токены); пространство наблюдения представляет собой возможную входную последовательность токенов (т. е. подсказку), которая представляет собой перестановку и комбинацию всех токенов в словаре во всех входных позициях, а функция вознаграждения основана на RM; модель, обученная на основе модели вознаграждения, с некоторыми ограничениями расчета вознаграждения на уровне политики.
Рассчитать вознаграждение:
- На основе предыдущих предварительно обогащенных данных выберите из него образец подсказки и одновременно введите его в исходную языковую модель и языковую модель, обучаемую в данный момент (политику), чтобы получить выходные тексты y1 и y2 двух моделей. Используйте модель вознаграждения RM, чтобы получить баллы y1 и y2, чтобы определить, кто лучше. Разницу в баллах можно использовать в качестве сигнала для параметров модели стратегии обучения. Этот сигнал обычно используется для расчета размера «награды/наказания» через расхождение KL. Если оценка текста y2 выше, чем оценка текста y1, награда будет больше, в противном случае штраф будет больше. Этот сигнал вознаграждения отражает общее качество генерации текста.
- Благодаря этому вознаграждению параметры модели могут быть обновлены в соответствии с алгоритмом оптимизации проксимальной политики (PPO). undefined Процесс этого этапа показан на рисунке ниже:

4.3 Преимущества и недостатки модели
GPT3.5, одна из важных технологий в области обработки естественного языка, имеет очень широкие перспективы применения и потенциал развития. С помощью технологии генерации диалогов можно реализовать различные сценарии применения, такие как интеллектуальное обслуживание клиентов, системы вопросов и ответов, а также генерация естественного языка, что значительно повышает эффективность и удобство взаимодействия человека с компьютером. Благодаря постоянному развитию компьютерных технологий и постоянному совершенствованию алгоритмов глубокого обучения области применения GPT3.5 будут продолжать расширяться и углубляться, предоставляя людям более совершенные, эффективные и интеллектуальные услуги по обработке естественного языка. На изображении ниже показаны выходные данные GPT3.5 для двух запросов.

- Преимущества GPT3.5:
1. Универсальность: GPT3.5 Может ответить на различные вопросы,Дарите творческое вдохновение,Поддерживает несколько функций ожидания распознавания голоса,Может применяться во многих областях,Такие как техническая поддержка, Интеллектуальное обслуживание клиентов、Генерация текста ждать.2. обработка естественного языкаспособность:GPT3.5 Иметь сильную изообработку естественного языкаспособность,Может имитировать человеческую речь,выражать мысли и чувства,Давайте более естественные и плавные ответы.3. Многоязычная поддержка: GPT3.5. Поддерживает несколько языков и может удовлетворить языковые потребности разных стран и регионов.4. Интеллектуальное обучение: GPT3.5 может пройтиверно Обучение на больших объемах данных,Постоянно совершенствуйте свои способности к выражению эмоций и точность ответов.,Иметь определенные интеллектуальные способности к обучению.5. Удобство: GPT3.5 Его можно использовать через стороннее приложение или веб-сайт OpenAI. Предоставить из API или ВОЗсуществовать OpenAI Он доступен на официальном сайте и очень удобен в использовании.- Недостатки GPT3.5:
1. Возможная предвзятость: из-за GPT3.5 да получается путем обучения на большом объеме данных, и могут возникнуть проблемы с предвзятостью данных. Это может привести к GPT3.5 верно Определенные группы или Определенные мнения из Ответы носят предвзятый характер.2. Безличный: Хотя GPT3.5 Может имитировать человеческую речь,Но ему все еще не хватает настоящих эмоций и человечности.,Неспособен к сложному мышлению и выражению эмоций, как настоящие люди.3. Необходимо много данных: чтобы GPT3.5 Иметь более высокийиз Точность ответаи表达способность,Требуется большой объем обучающих данных.,Это требует много времени и ресурсов.4. Могут возникнуть риски безопасности: при использовании модели GPT3.5.,Необходимо ввести определенное количество текстовых и голосовых данных.,Это может привести к утечке личной информации и риску.5.Большая языковая модель GPT4
GPT-4 (Генераторный предварительно обученный трансформатор 4) — это большая мультимодальная модель, которая принимает входные изображения и текст и выводит текст. GPT4 по-прежнему использует структуру модели Transformer, которая может обрабатывать изображения. Структура модели больше не предназначена только для декодера, но имеет кодировщик для завершения кодирования изображений. Как показано на изображении ниже, GPT4 отметил, что изображение большого и устаревшего порта VGA, подключенного к маленькому и современному порту для зарядки смартфона, нелепо.

Количество параметров модели GPT4 в несколько раз больше, чем у модели GPT3, а количество параметров модели может приближаться к уровню триллиона. Для обучения GPT4 OpenAI использует службу облачных вычислений Microsoft Azure, которая включает в себя тысячи. графических процессоров Nvidia A100 или графического процессора. GPT4 предлагает RBRMS (модель вознаграждения на основе правил) в стратегии обучения для решения проблем безопасности.
5.1 Безопасность модели GPT4
GPT-4 проделала большую работу для обеспечения безопасности модели. Во-первых, она наняла более 50 экспертов предметной области из разных направлений для проведения состязательного тестирования и тестирования красной команды. Во-вторых, она обучила модель вознаграждения, основанную на правилах (Rule). -Модели вознаграждения на основе), RBRM)+RLHF для помощи в обучении моделей.
RBRMS (модели вознаграждения на основе правил): цель состоит в том, чтобы направить обучение модели с помощью правильных вознаграждений, чтобы отклонять вредные запросы, а не отклонять безобидные запросы.
RLHF (обучение с подкреплением на основе обратной связи человека): использует методы обучения с подкреплением для непосредственной оптимизации языковых моделей с использованием сигналов обратной связи человека. Процесс обучения показан на рисунке ниже и может быть разбит на три основных этапа:
- Несколько стратегий для создания образцов и сбора отзывов людей
- Модель вознаграждения за обучение
- Обучайте стратегиям обучения с подкреплением и настраивайте LM

5.2 Сравнение моделей
- Размер модели: GPT-4 больше, чем GPT-3, включает больше параметров и более глубокую структуру сети. По мере увеличения масштаба GPT-4 способен улавливать более сложные языковые шаблоны и семантические отношения, тем самым улучшая способность понимать и генерировать естественный язык.
- Улучшения производительности: за счет увеличения масштаба GPT-4 по сравнению с GPT-3 существоватьбольшинствообработка естественного Продемонстрировал более высокие результаты в языковых задачах. Сюда входит понимание прочитанного, машинный перевод, составление сводки, вопросы и ответы ожидания Задача. GPT-4 Способность лучше понимать вводимые пользователем данные и генерировать более точные и естественные ответы.
- Данные обучения и очистка данных: GPT-4 использовался обновленный и более богатый набор обучающих данных. по сравнению с GPT-3,GPT-4 Приняты более строгие стандарты проверки и очистки данных, чтобы уменьшить дезинформацию, устаревший контент и предвзятость в обучающих данных.
- Возможности точной настройки: GPT-4 работает лучше, чем GPT-3 при точной настройке. Это означает, что, используя меньше размеченных данных, GPT-4 может адаптироваться к конкретным задачам и областям. Это делает применение GPT-4 при индивидуальной настройке и конкретных сценариях более гибким и эффективным.
- Надежность и интерпретируемость: GPT-4 добился определенного прогресса в надежности и интерпретируемости модели. Внедряя новые техники и методы, GPT-4 лучше справляется с необычными входными данными и противостоит состязательным атакам, обеспечивая при этом объяснимость своих прогнозов.
- Оптимизированное потребление ресурсов. Хотя GPT-4 больше по размеру, OpenAI предприняла ряд мер по оптимизации, чтобы снизить потребление ресурсов модели на этапах обучения и вывода. Это позволяет GPT-4 снизить вычислительные затраты и воздействие на окружающую среду, сохраняя при этом высокую производительность.
- Улучшения в стратегиях генерации: GPT-4 был оптимизирован с точки зрения стратегий генерации, улучшая качество, разнообразие и управляемость выходного текста. Это означает, что GPT-4 лучше удовлетворяет потребности и предпочтения пользователей при создании ответов, одновременно снижая риск создания нерелевантного, дублированного или неподходящего контента.
- Более широкие области применения: благодаря повышению производительности и мерам по оптимизации GPT-4 существуют различные области приложений с более широкой областью применения. В дополнение к традиции изобработка естественного языка Вне миссии, GPT-4 Он также может обрабатывать более сложные сценарии, такие как мультимодальные задачи, создание графа знаний и т. д.
- Поддержка сообщества и инструменты разработки: с запуском GPT-4 OpenAI также предоставляет разработчикам более широкие ресурсы и инструменты поддержки, включая API, SDK, предварительно обученные модели и т. д. Это упрощает разработчикам интеграцию и использование GPT-4 в своих собственных проектах.
GPT-4 демонстрирует больше здравого смысла, чем предыдущие модели, как показано в примере ниже:

5.3 Применение
Мультимодальный и междисциплинарный состав: GPT-4 не только демонстрирует высокие знания в различных областях, таких как литература, медицина, право, математика, физика и программирование, но также свободно сочетает навыки и концепции из разных областей, демонстрируя впечатляющую способность понимать. сложные идеи. На рисунке ниже показан пример сравнения GPT-4 и ChatGPT при выполнении междисциплинарных задач:

Генерация кода: GPT-4 способен кодировать на очень высоком уровне, будь то написание кода на основе инструкций или понимание существующего кода, и может решать широкий спектр задач кодирования, от проблем кодирования до реальных приложений, от низкоуровневой сборки. до фреймворков высокого уровня, от простых структур данных до сложных программ, также могут рассуждать о выполнении кода, моделировать эффекты инструкций и интерпретировать результаты на естественном языке и даже выполнять псевдокод, который требует интерпретации не- вербальный код, недопустимый ни на одном языке программирования. Формальные и расплывчатые выражения. На следующем рисунке показан пример выполнения кода Python GPT-4:

Сценарии применения GPT4 в различных областях принесли человечеству инновационную мощь. Помимо вышеуказанных областей применения существуют также следующие области применения:
- Создание и редактирование контента: отличная производительность undefinedGPT-4 при генерации текста обеспечивает мощную поддержку создателям. От написания программных статей и сообщений в блогах до создания книг — GPT-4 может генерировать высококачественный контент в соответствии с потребностями пользователей. В то же время GPT-4 также имеет интеллектуальные функции исправления ошибок и редактирования, которые могут помочь пользователям быстро оптимизировать текст и повысить эффективность работы.
- Язык перевода: не определен с помощью GPT-4 из Технология глубокого обучения обеспечивает точный перевод Служить в области языкового перевода в режиме реального времени. ГПТ-4 Поддерживает перевод между несколькими языками, обеспечивая удобный языковой мост для международного обмена и сотрудничества.
- Обслуживание и поддержка клиентов: undefinedВсе больше и больше компаний начинают GPT-4 приложение в существующей онлайн-системе обслуживания клиентов для достижения интеллектуального и эффективного изпользования Служить. ГПТ-4 Он может быстро генерировать точные и профессиональные ответы на вопросы пользователей, что значительно повышает удовлетворенность клиентов и эффективность обслуживания клиентов.
- Умное образование: undefinedGPT-4 Перспективы применения в сфере образования также весьма широки. ИИ Система репетиторства может предоставлять учащимся персонализированные предложения по обучению и ответы на вопросы. Кроме того, ГПТ-4 Его также можно использовать для сбора образовательных ресурсов, таких как учебные материалы и планы уроков, чтобы разделить рабочую нагрузку учителей.
- Разработка игр: undefinedGPT-4 также играет важную роль в игровой сфере. Разработчики могут использовать GPT-4 для создания различных игровых сцен, диалогов персонажей и дизайна сюжетов, чтобы создать для игроков богатый и уникальный игровой опыт.
- Голосовой помощник: undefinedГолосовой помощник стал незаменимой частью повседневной жизни людей. ГПТ-4 проходитьобработка естественного языкатехнология,Позволяет голосовым помощникам лучше понимать потребности пользователей и предоставлять более точные ответы.,Удовлетворять потребности людей в жизни и работе.
- Анализ и визуализация данных: undefinedGPT-4 может применяться в области анализа данных, чтобы помочь компаниям и частным лицам обнаружить потенциальную ценность посредством глубокого анализа больших объемов данных. В то же время GPT-4 также может создавать четкие и простые для понимания визуальные диаграммы, что делает результаты анализа данных более интуитивными и простыми для понимания.
- Юридическая консультация: не определено Благодаря запасу знаний и возможностям интеллектуального рассуждения GPT-4 пользователи могут получать профессиональные ответы и советы по юридическим вопросам. Это позволит значительно сократить затраты и время людей на юридические консультации.
- Медицинская сфера: не определеноGPT-4 Медицинская сфера применения также становится все более популярной. на。AI Модель может помочь врачам в анализе случаев и выдаче диагностических рекомендаций, а также повысить точность и эффективность медицинской помощи. Кроме того, ГПТ-4 Он также может предоставить пациентам медицинские консультации и научно-популярные знания для повышения осведомленности общественности о здравоохранении.
- IIЭтика и регулирование: undefinedWith GPT-4 ждать AI С популяризацией технологий этические и нормативные вопросы становятся все более заметными. ГПТ-4 Может помочь соответствующим учреждениям исследовать и сформулировать соответствующую политику и правила для обеспечения AI Технологии развиваются в соответствующей и безопасной среде.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
