[Практика сканирования] Используйте Python для сбора любых комментариев, написанных Xiaohongshu, и просканируйте более 10 000 комментариев, включая комментарии второго уровня!
1. Ползущая цель
Привет!ЯМарко Питон сказал,Программист с 10-летним опытом.
Мы продолжаем рассказывать о случае с сканером Python. Сегодня мы сканируем данные комментариев под указанными заметками (заметками, связанными с «Палестиной») на Xiaohongshu.
Старое правило — сначала показывать результаты:
Скриншот 1:
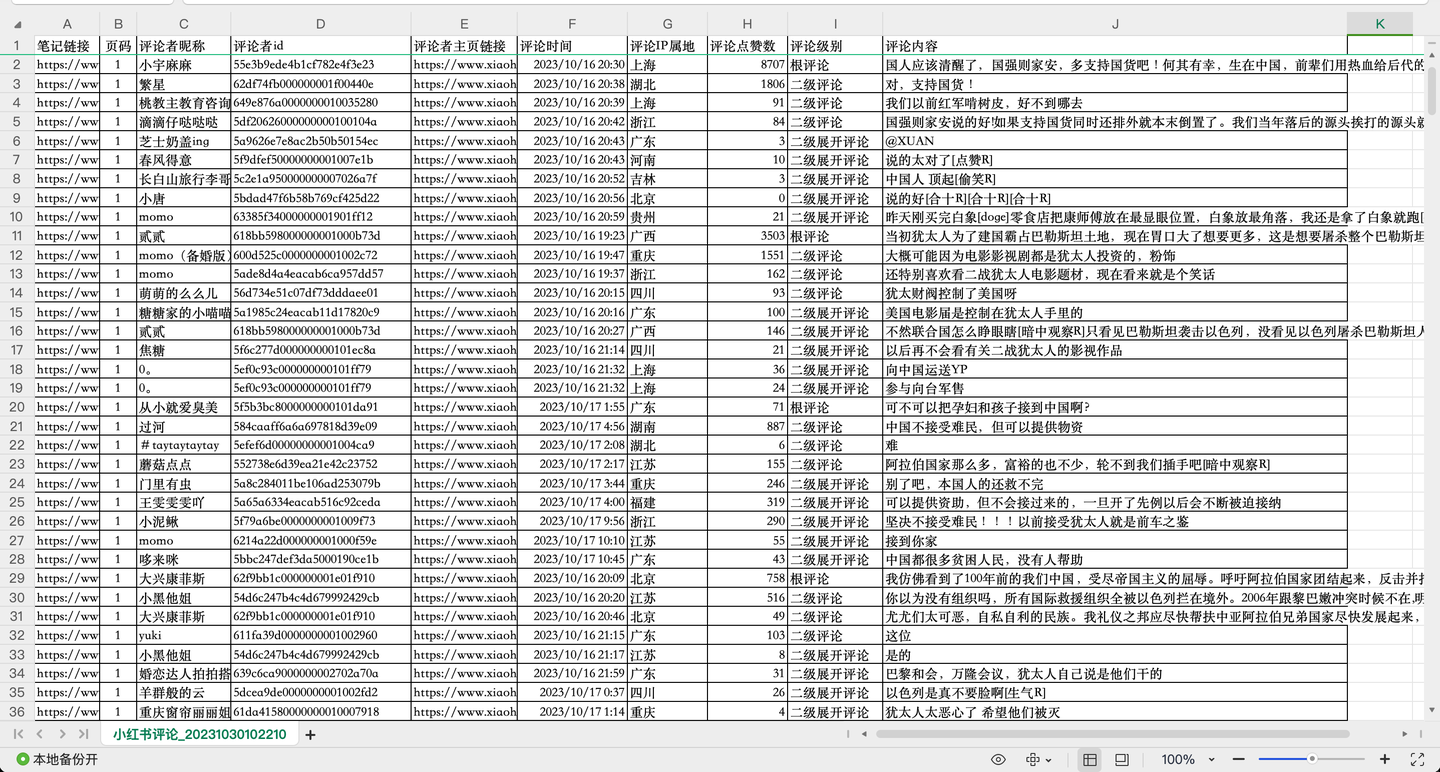
Скриншот 2:
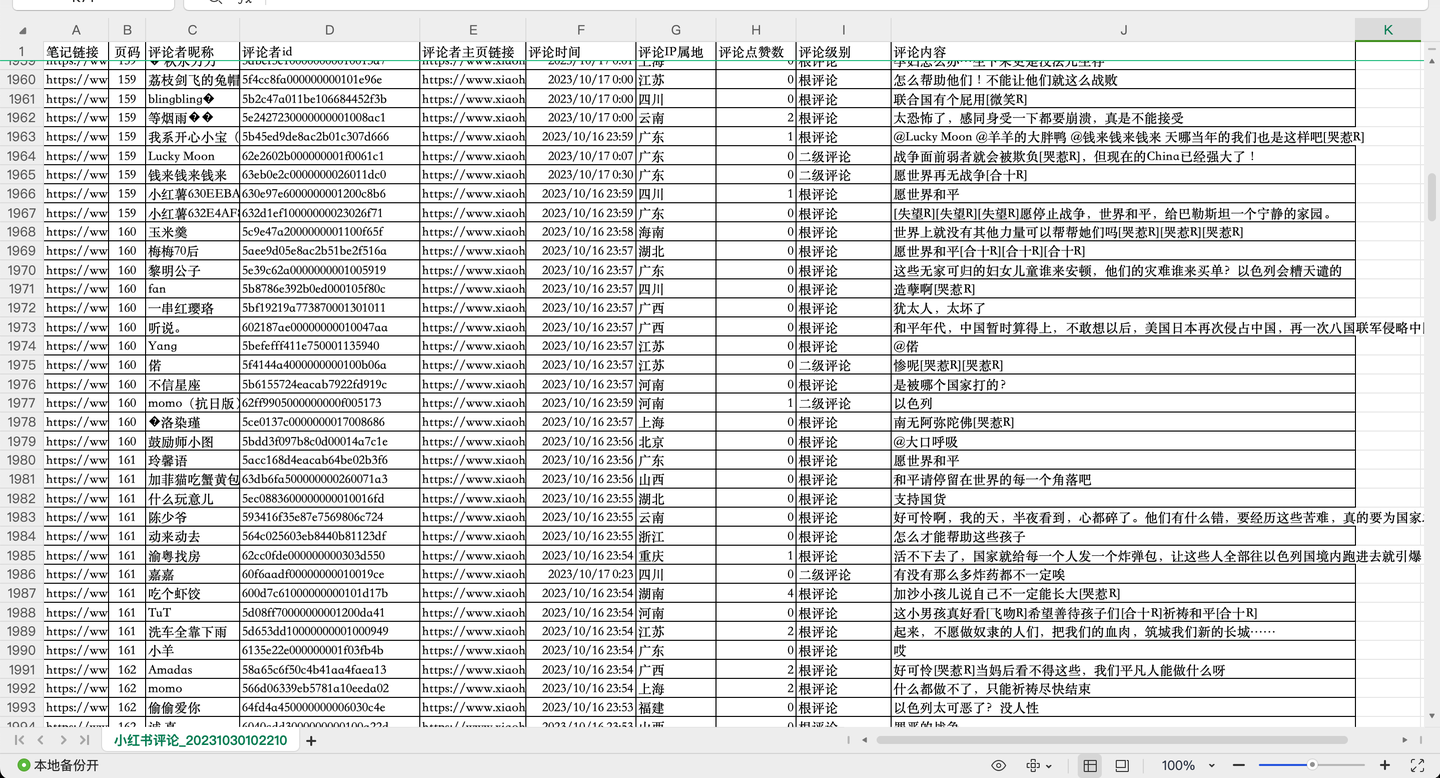
Скриншот 3:

Всего было просканировано более 10 000 комментариев по теме «Палестина». Каждый комментарий содержит 10 ключевых полей, в том числе:
Ссылка на заметку, номер страницы, псевдоним комментатора, идентификатор комментатора, ссылка на домашнюю страницу комментатора, время комментария, IP-адрес комментария, лайки комментария, уровень комментария, содержание комментария.
Среди них уровни комментариев включают в себя: корневой комментарий, комментарий второго уровня и расширенный комментарий второго уровня.
2. Пояснение кода сканера
2.1 Процесс анализа
Откройте любой комментарий в заметках Xiaohongshu, откройте режим разработчика браузера, сеть, XHR и найдите данные предварительного просмотра целевой ссылки следующим образом:
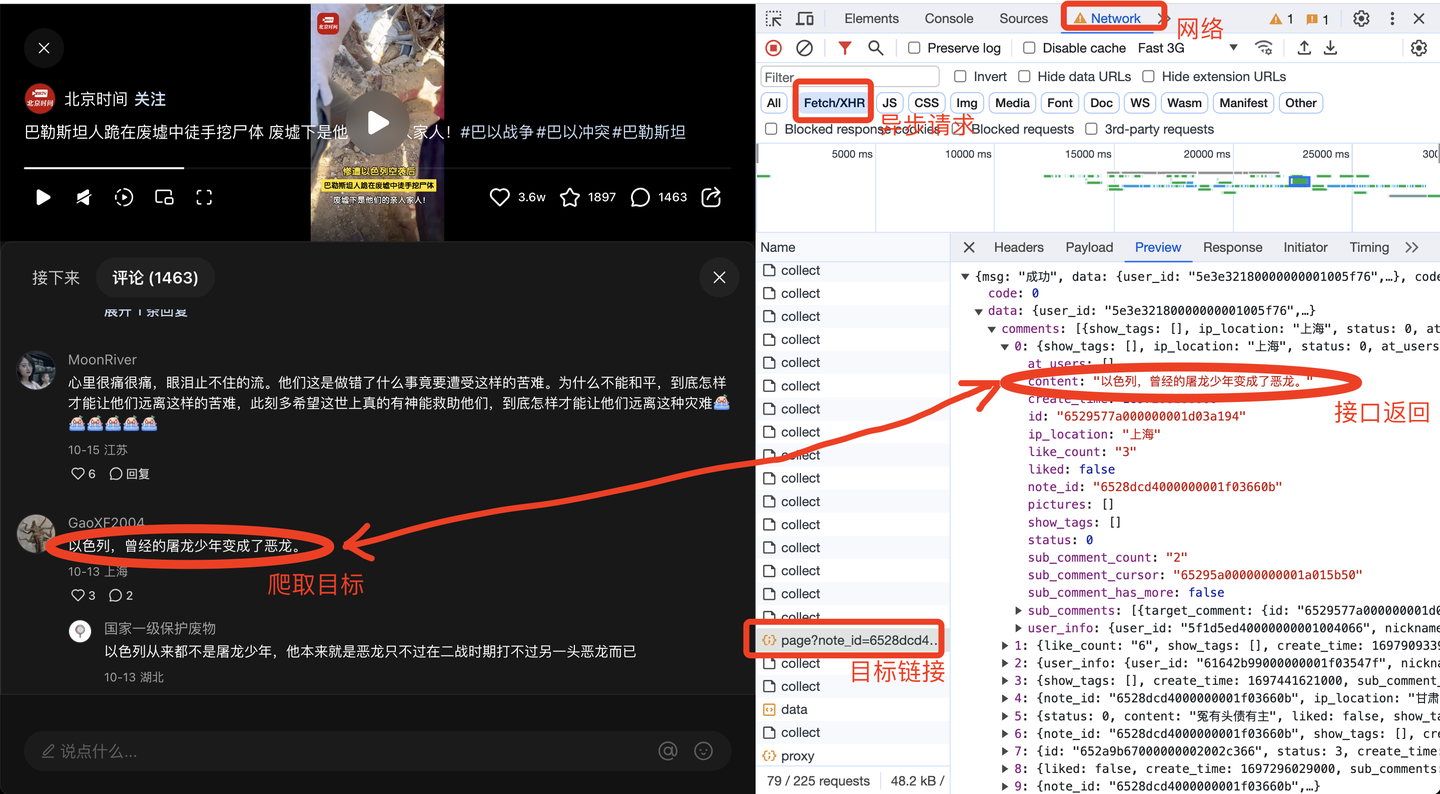
В результате получается ссылка на внешний запрос и начинается разработка кода сканера.
2.2 Код краулера
Сначала импортируйте необходимые вам библиотеки:
import requests
from time import sleep
import pandas as pd
import os
import time
import datetime
import randomОпределите заголовок запроса:
# Заголовок запроса
h1 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
# Файлы cookie необходимо регулярно менять
'Cookie': «Замените собственным значением файла cookie»,
}После моего фактического теста заголовок запроса содержит как User-Agent, так и Cookie, и сканирование может быть достигнуто.
Среди них файлы cookie имеют решающее значение и требуют регулярной замены. Так где же взять печенье? Вот как:
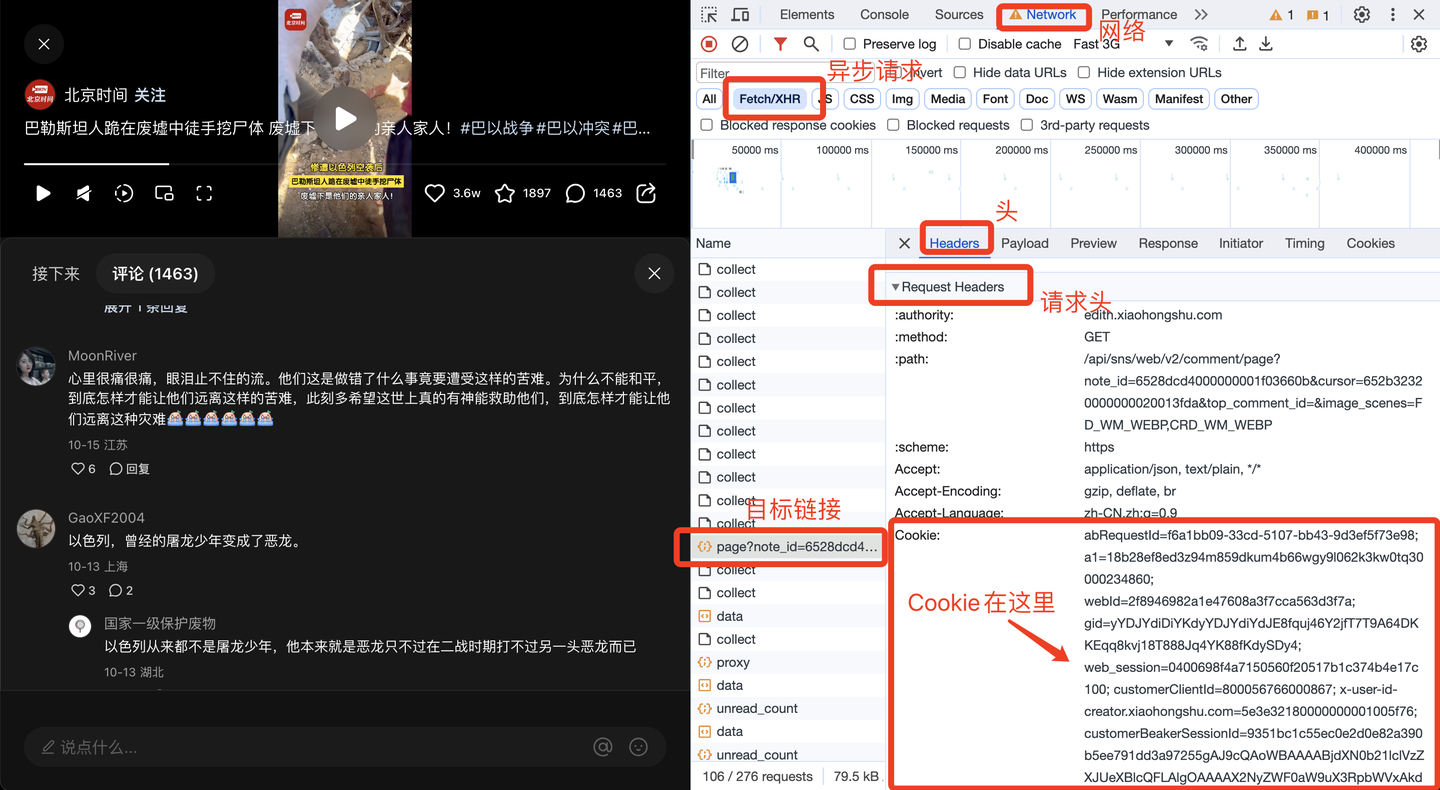
Далее разработайте логику перелистывания страниц.
Поскольку я не знаю, сколько всего страниц и сколько раз нужно прокрутить вниз, я использую цикл while до тех пор, пока не сработает условие завершения.
Итак, как определить условие завершения? Я заметил, что в возвращаемых данных есть параметр под названием «has_more», смело догадываюсь, что он означает, есть ли еще данные, и его значение истинно в обычных обстоятельствах. Если его значение ложно, это означает, что данных больше нет, то есть достигнута последняя страница и пора завершить цикл.
Следовательно, структура основного кода должна быть такой (ниже приведен псевдокод, в основном для выражения логики, не копируйте напрямую):
while True:
# Отправить запрос
r = requests.get(url, headers=h1)
# Анализ данных
json_data = r.json()
# Анализ один за другим
for c in json_data['data']['comments']:
# Содержание комментария
content = c['content']
content_list.append(content)
# Сохраняем данные в csv
。。。
# Определить условия расторжения
next_cursor = json_data['data']['cursor']
if not json_data['data']['has_more']:
print('Следующей страницы нет, завершите цикл!')
break
page += 1Кроме того, есть ключевой вопрос, как перелистывать страницы.
Просмотрите параметры запроса следующим образом:
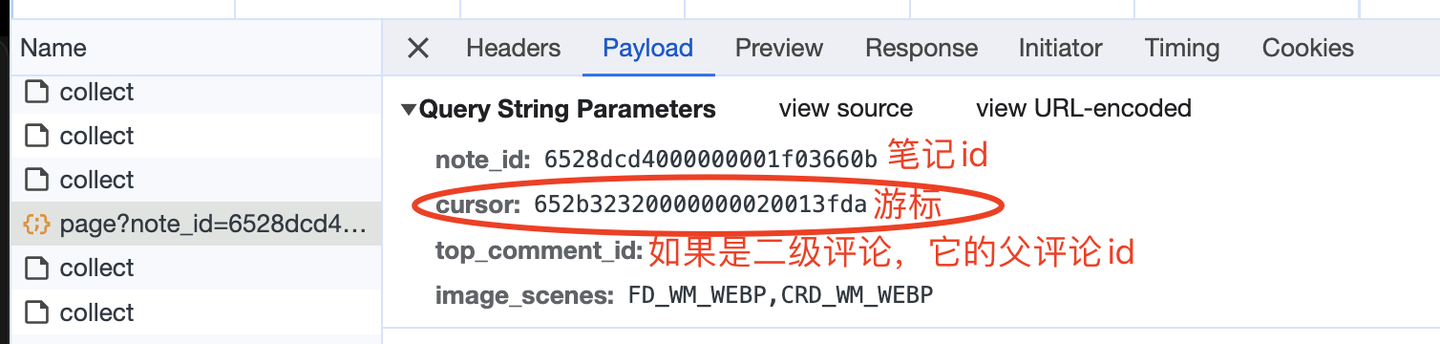
Курсор здесь является основанием для перемещения страницы вниз, поскольку в возвращаемых данных каждого запроса также присутствует курсор:
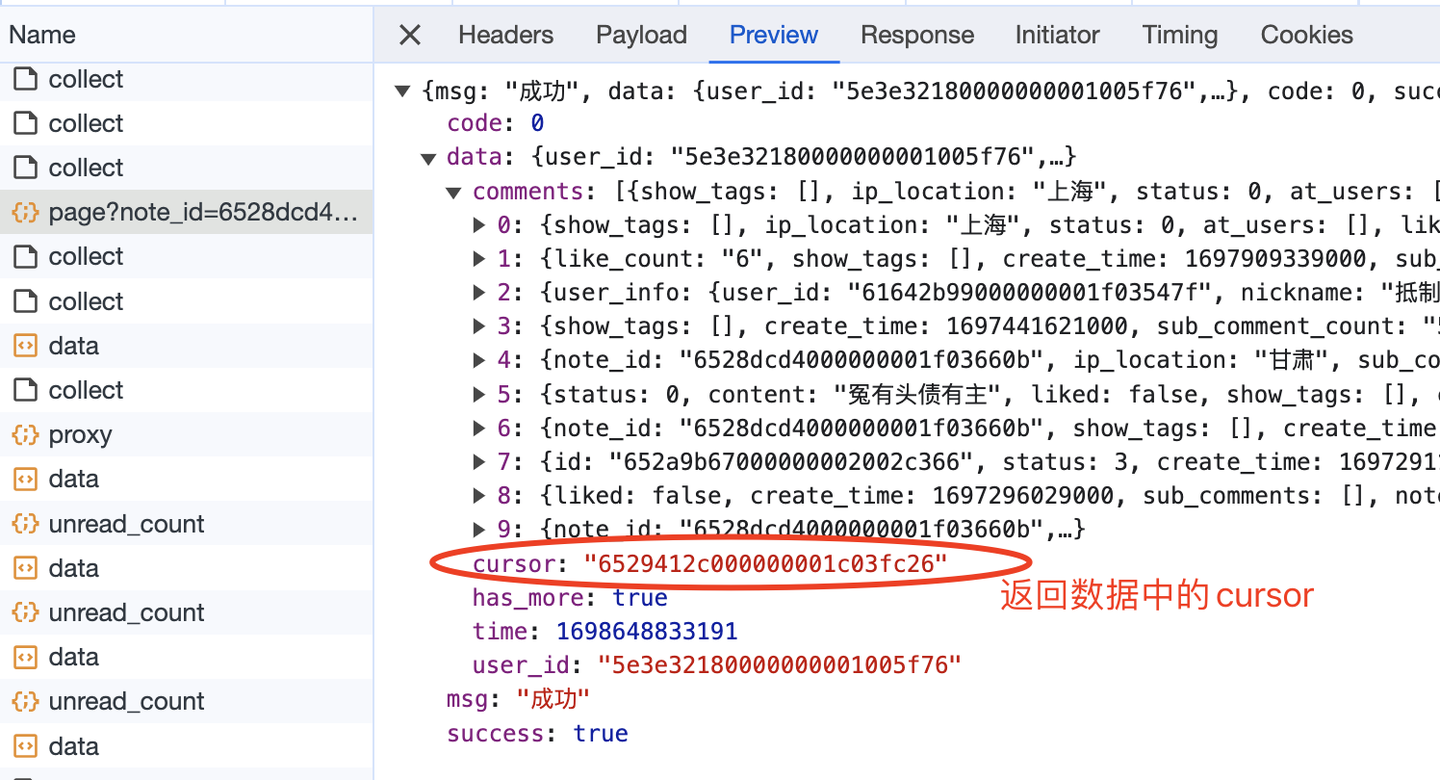
Смелое предположение состоит в том, что курсор в возвращаемых данных — это курсор, используемый для запроса следующей страницы. Следовательно, логическая реализация этой части должна быть следующей (ниже приведен псевдокод, в основном для выражения логики, не копируйте). напрямую):
while True:
if page == 1:
url = 'https://edith.xiaohongshu.com/api/sns/web/v2/comment/page?note_id={}&top_comment_id=&image_scenes=FD_WM_WEBP,CRD_WM_WEBP'.format(
note_id)
else:
url = 'https://edith.xiaohongshu.com/api/sns/web/v2/comment/page?note_id={}&top_comment_id=&image_scenes=FD_WM_WEBP,CRD_WM_WEBP&cursor={}'.format(
note_id, next_cursor)
# Отправить запрос
r = requests.get(url, headers=h1)
# Анализ данных
json_data = r.json()
# Получить курсор для следующей страницы
next_cursor = json_data['data']['cursor']Кроме того, я упоминал в первой главе, что я тоже поднялся на второй уровень комментариев и второй уровень расширенных комментариев. Как я это сделал?
После анализа в возвращаемых данных есть узел sub_comment_count, который представляет количество вложенных комментариев. Если оно больше 0, это означает, что комментарий имеет вложенные комментарии, а затем из узла sub_comments можно сканировать вторичные комментарии.
Среди них комментарий второго уровня расширяется, а root_comment_id в параметре запроса представляет идентификатор родительского комментария. Другая логика такая же и не будет повторяться.
Наконец, логично сохранить данные csv:
# Сохранить данные в DF
df = pd.DataFrame(
{
«Ссылка на заметку»: 'https://www.xiaohongshu.com/explore/' + note_id,
'номер страницы': page,
«Псевдоним комментатора»: nickname_list,
«Идентификатор комментатора»: user_id_list,
«Ссылка на домашнюю страницу комментатора»: user_link_list,
«Время комментирования»: create_time_list,
«Комментарий к территории IP»: ip_list,
«Количество лайков на комментарии»: like_count_list,
«Уровень комментариев»: comment_level_list,
'Содержание комментария': content_list,
}
)
# Установить заголовок файла CSV
if os.path.exists(result_file):
header = False
else:
header = True
# сохранить в csv
df.to_csv(result_file, mode='a+', header=header, index=False, encoding='utf_8_sig')На этом этапе разрабатывается код сканера.
Полный код также включает в себя ключевую логику, такую как преобразование временных меток, случайное время ожидания, анализ других полей, сохранение данных Dataframe и циклическое сканирование нескольких заметок одновременно.
3. Демонстрационное видео
Демонстрационный код: нет
Спасибо за прочтение и добро пожаловать к общению!



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
