Практика обработки веб-страниц и сканирования веб-страниц Python: использование библиотеки Requests для сканирования данных веб-страниц
Оглавление
Практика обработки веб-страниц и сканирования веб-страниц Python: использование библиотеки Requests для сканирования данных веб-страниц
Обзор проблемы
Python и обработка веб-страниц
Установить библиотеку запросов
веб-сканер
Расширение: Соглашение об исключении роботов
Использование библиотеки запросов
обзор библиотеки запросов
Функция запроса веб-страницы в библиотеке запросов
Функция запроса веб-страницы
Свойства объекта Response
Методы объекта Response
Получить содержимое веб-страницы
Практика обработки веб-страниц и сканирования веб-страниц Python: использование библиотеки Requests для сканирования данных веб-страниц

Обзор проблемы
Введение в проблемы реализации веб-сканеров на языке Python

Python и обработка веб-страниц
- Python В развитии языка произошло знаковое прикладное событие, а именно США Гугл ( GOOGLE) Компания использует Python Язык связан с обработкой и развитием, то есть развитием языка. Важный признак зрелости. Питон Простота языка и возможности сценариев Отлично подходит для связывания и обработки веб-страниц.
- Быстрое развитие Всемирной паутины (WWW) привело к появлению большого количества доступа и Необходимость обмена сетевой информацией породила серию «сетевых рептилий» и других приложение.
- Python Язык предоставляет множество подобных функций Библиотека, включая urllib. 、urllib2、urllib3、wget、scrapy、запросы ожидания. Эти библиотеки имеют разные функции.、Различные способы использования、Пользовательский опыт отличается.
- Для обратного сканирования веб-контента вы можете использовать re (регулярное выражение (формула), beautifulsoup4 и другие функции Библиотеки для обработки, с полем Разработка каждой предметной функции Библиотека, в этой главе будут подробно представлены наиболее важные и важные Две основные функции Библиотека: запросы иbeautifulsoup4, Все они являются сторонними библиотеками.
Приложения веб-сканера обычно делятся на два этапа:
(1) Получение веб-контента через сетевое соединение.
(2) Обработать полученное содержимое веб-страницы.
Эти два шага используют разные функции. Библиотека: запросы и beautifulsoup4.
Установить библиотеку запросов
Принять пип Инструкция Запросы на установка Библиотека, если в системе сосуществуют Python2 и Python3, используйте pip3 инструкция :\>pip install requests # или pip3 install requests
Используйте инструкцию pip или pip3 для установки библиотеки beautifulsoup4.,Уведомление,Не устанавливать beautifulsoupБиблиотека,Последний из-за своего возраста и ветхости. , больше не поддерживается :\>pip install beautifulsoup4 # или pip3 install beautifulsoup4
веб-сканер
использоватьPythonсеть языковой реализациирептилияи Подать информацию очень просто количество строк кода очень мало, и нет необходимости знать о сетевой связи и других аспектах, поэтому он очень подходит для Для неспециалистов-читателей. Однако бессмысленное сканирование сетевых данных не является цивилизованным явлением. , также несправедливо конкурировать за конкурентные ресурсы, автоматически отправляя контент через программы. как те Подобно бессмысленным рекламным звонкам, они игнорируют пожелания получателя и не только раздражают, но и Могут возникнуть юридические споры.
Расширение: Соглашение об исключении роботов
Robots соглашение об исключении(Robots Exclusion Протокол), также известный как протокол сканера, это Метод, позволяющий администраторам веб-сайтов указать, хотят ли они, чтобы сканеры автоматически получали информацию о сети. Менеджеры могут выйти в онлайн Поместите robots.txt в корень сайта. файл и список в файле, ссылки на которые не разрешено сканировать сканерам . Как правило, сканеры поисковых систем сначала захватывают этот файл и сканируют содержимое веб-сайта в соответствии с требованиями к файлу.
Robots соглашение об Исключения Ключевое соглашение заключается в том, что вы не хотите, чтобы контент получался рептилиями. Если такого файла нет, значит, в сети. Содержимое сайта может быть получено сканерами, однако роботы Соглашение не является приказом или средством принуждения, это международный договор. Интернетуниверсальный этический кодекс。Самые зрелые поисковые системырептилия Всевстречаследуйте этому протоколу , рекомендуется, чтобы отдельные лица также могли разумно использовать краулерную технологию в соответствии со стандартами Интернета.
——Джентльменское соглашение——
Использование библиотеки запросов
requests Библиотекаэто краткий и простой процессHTTP请求的第三方Библиотека。
обзор библиотеки запросов
requests Самым большим преимуществом является то, что процесс программирования приближен к обычному. URL процесс доступа.
- Эта библиотека основана на библиотеке urllib3 на языке Python.,Аналогично этому и в других функциях Библиотека Кроме того, функция инкапсулирована, чтобы сделать ее более удобной для пользователя.Pythonна языкеОчень часто。существоватьPythonв экосистеме,любой Все Выражайте мнения посредством технологических инноваций или инноваций на основе опыта Возможность проявить свой талант.
- request Библиотека поддерживает очень богатые функции доступа по ссылкам, включая: международные доменные имена и URL Получить, HTTP Длинное соединение и кэш соединений, HTTP встречаразговариватьиCookie Сохранять Поддержка, стиль использования браузера SSL Аутентификация, базовая дайджест-аутентификация, действительные ключи Пара значений cookie Запись, автоматическая распаковка, автоматическое декодирование контента и загрузка файлов частями.、Функция HTTP(S)-прокси、Обработка тайм-аута соединения、потокданныескачатьждать.
- связанный requests Для получения дополнительной информации о Библиотеке посетите: http://docs.python‐requests.org
Функция запроса веб-страницы в библиотеке запросов
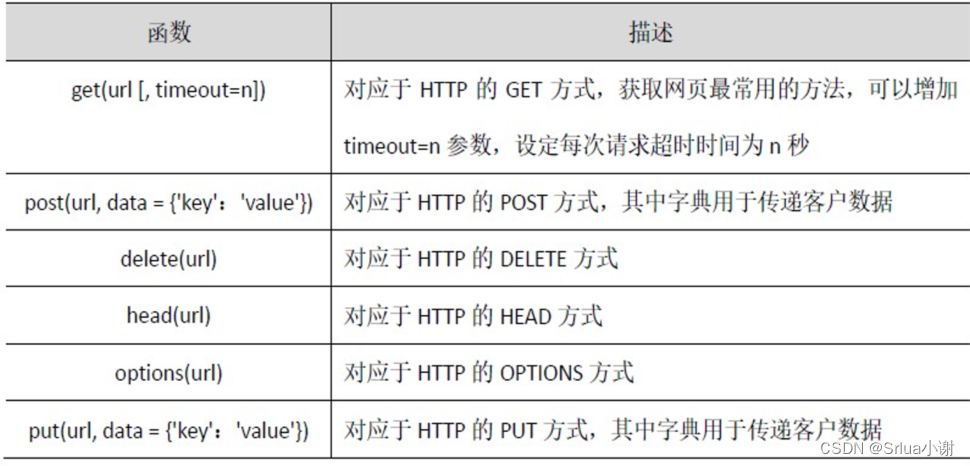
get() — наиболее часто используемый способ получения веб-страниц. После вызова функции request.get() возвращаемое содержимое веб-страницы будет сохранено как объект Response. Среди них должен быть URL-адрес параметра функции get(). доступ через HTTP или HTTPS.
Функция запроса веб-страницы
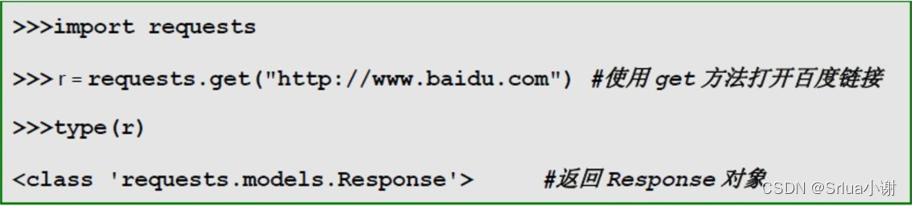
Интерактивный процесс браузера тот же, Requests.get() представляет запрос Процедура, ответ, который она возвращает Объект представляет собой ответ. Возврат контента Поскольку объект более удобен в эксплуатации, Свойства объекта Ответ как Как показано в таблице ниже,Необходимо принять<a>.<b>формаиспользовать。
Свойства объекта Response
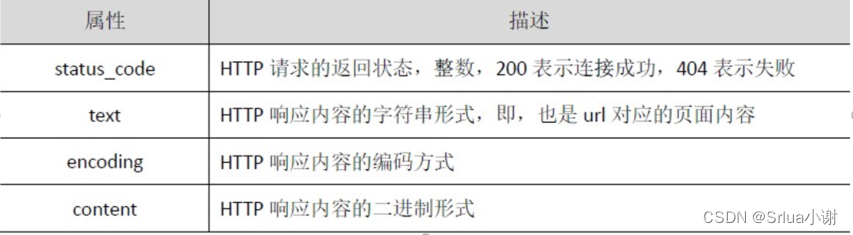
- status_code Запрос на возврат имущества HTTP Окончательный статус должен быть определен до обработки данных. Если на запрос не получен ответ, Обработку контента необходимо прекратить.
- text Атрибут — это запрошенное содержимое страницы, отображаемое в виде строки.
- encoding Атрибут очень важен. Он предоставляет метод кодирования для возврата содержимого страницы. Вы можете изменить кодировку, присвоив значение атрибуту кодировки. способ облегчить обработку китайских иероглифов
- content Свойства — это двоичные формы содержимого страницы.

Методы объекта Response

- json() метод способен анализировать наличие JSON данных, это принесет удобство парсинга HTTP.
- Метод raise_for_status() может генерировать исключение после неудачного ответа, то есть, пока возвращаемый код статуса запроса не равен 200, этот метод будет генерировать исключение для оператора try...кроме. Использование операторов обработки исключений позволяет избежать создания множества сложных операторов if. Вам нужно вызвать этот метод только после получения ответа, и вы сможете избежать различных непредвиденных ситуаций, кроме слова состояния 200.
- запросы порождают несколько распространенных исключений. При возникновении сетевых проблем, таких как: сбой DNS-запроса, отказ в соединении и т. д., запросы выдают исключение ConnectionError; при обнаружении недопустимого ответа HTTP запросы выдают исключение HTTPError, если истекает время ожидания URL-адреса, возникает исключение Timeout; быть выброшено Если запрос превышает установленное максимальное количество перенаправлений, будет выдано исключение TooManyRedirects.
Получить содержимое веб-страницы




Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
