Практика интеллектуального анализа больших данных — основные операции PyODPS
Сегодняшняя рекомендация: разделение дел | Схема двоичного шифрования при передаче больших данных
Ссылка на статью: https://cloud.tencent.com/developer/article/2465951
Причины рекомендации:Шифрование данныхкак эффективное средство защиты,Он широко используется в различных сценариях передачи данных. В эпоху больших данных,Различные платформы хранят большое количество поведенческих данных и информации о пользователях.,Для обеспечения конфиденциальности пользователей,Безопасность данныхкак часть управления данными,Об этом также упоминает все больше и больше людей. Как обеспечить конфиденциальность данных при передаче, стало сложной проблемой, которую необходимо учитывать разработчикам.
Предисловие
Ранее я писал множество проектов Spark и PySpark, а также статей о технических операциях. Основная платформа — это, по сути, Spark. Однако недавно многие друзья по работе с большими данными сообщили, что в дополнение к собственной платформе больших данных компании, развертывающей Spark для вычислений с большими данными. их довольно много. Компания использует метод хостинга больших данных и полагается на управление облачной платформой.
Многие сторонние платформы имеют свои собственные инструменты для работы с большими данными и библиотеки инструментов для кода, поэтому в этой серии основное внимание уделяется PyODPS, которая в настоящее время является основной и широко используемой библиотекой PySpark для больших данных. Она в основном опирается на DataWorks от Alibaba Cloud и может быть непосредственно разработана в больших средах. data. MaxCompute использует PyODPS, что очень удобно для интеллектуального анализа данных. Таким образом, эта серия расширит возможности MaxComputer для выполнения ряда проектов по интеллектуальному анализу данных. Не пропустите, если вам это нужно.
Базовое введение в PyODPS
PyODPS — это Python-версия SDK для MaxCompute.,PySpark похож на Spark. Обеспечивает простое и удобное программирование на Python.,PyODPS предоставляет функциональность, аналогичную инструменту командной строки ODPS.,Например, загрузка и скачивание файлов Создать таблица, запуск ODPS SQL-запросы и т. д., а также предоставляет некоторые расширенные функции, такие как отправка задач MapReduce и использование ODPS. УДФ и т. д.

Будучи в настоящее время основным языком программирования для машинного обучения и разработки моделей искусственного интеллекта, Python предоставляет множество библиотек научных вычислений и визуализации, таких как NumPy, SciPy, Scikit-Learn и Matplotlib, для науки о данных и анализа данных. Он также поддерживает богатые платформы обучения, такие как TensorFlow, PyTorch, XGBoost и LightGBM.
- NumPy: используется для операций с объектами N-мерного массива.
- Pandas: это библиотека анализа данных, содержащая фреймы данных.
- Matplotlib: библиотека 2D-графиков для создания фигур и графиков.
- Scikit-Learn: Алгоритмы для анализа данных и задач интеллектуального анализа данных.
PyODPS был официально выпущен в 2015 году. Как Python SDK MaxCompute, он поддерживает связанные операции с данными MaxCompute через интерфейс Python. После итеративной разработки в нескольких версиях PyODPS в настоящее время поддерживает платформу DataFrame, обеспечивая при этом синтаксис, аналогичный Pandas, и встроенные операторы операций с данными, такие как агрегация, сортировка и дедупликация.
Операционная среда
В качестве SDK PyODPS сам по себе работает на различных клиентах, включая ПК, DataWorks (узел PyODPS для разработки данных) или PAI. Notebooksиз Операционная среда。
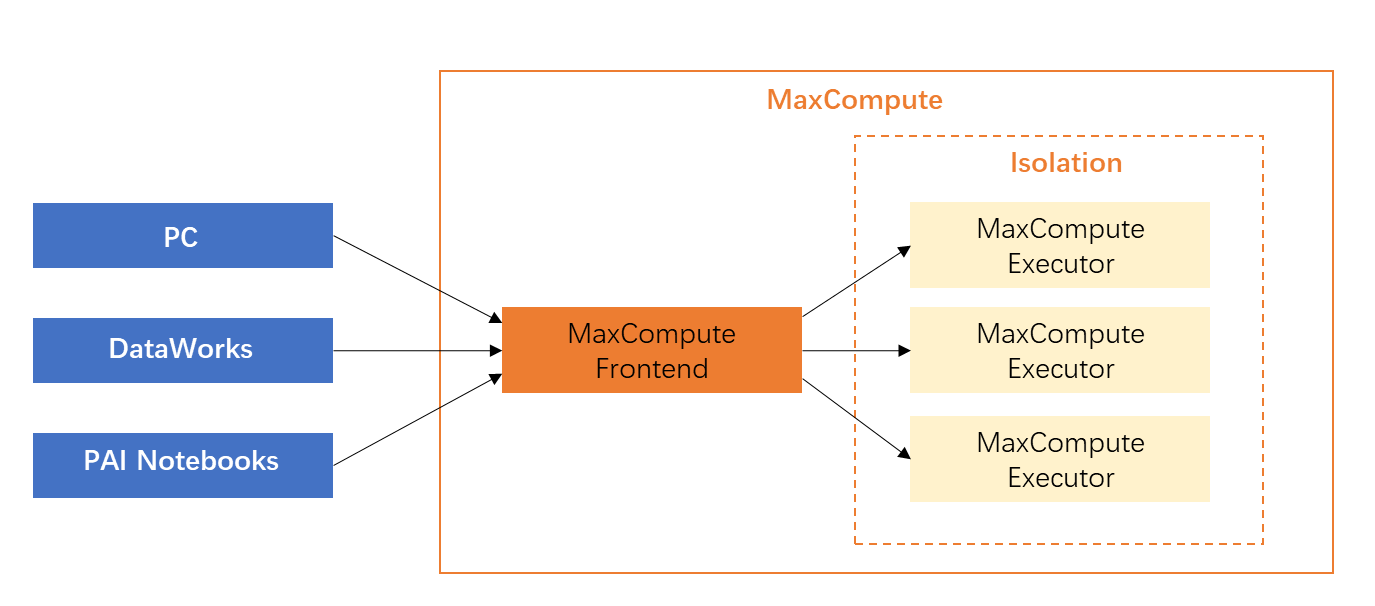
Как и PySpark, если он выполняется, например, локально в одной точке, пользователи, которые изначально используют PyODPS, попытаются получить данные локально, а затем загрузить их в MaxCompute после завершения обработки. Во многих случаях этот метод очень эффективен. неэффективное извлечение данных. Преимущества крупномасштабных параллельных возможностей MaxCompute полностью теряются локально, то есть возможности параллельных вычислений кластеров больших данных не используются. Согласно официальному определению:
Методы обработки данных | описывать | Пример сценария |
|---|---|---|
Переключиться на локальную обработку (не рекомендуется, склонен к OOM) | Например, узел PyODPS в DataWorks имеет встроенный пакет PyODPS и необходимую среду Python. Это клиентский контейнер с очень ограниченными ресурсами. Он не использует вычислительные ресурсы MaxCompute и имеет строгие ограничения по памяти. | PyODPSпредоставил |
Отправить в распределенное выполнение MaxCompute (рекомендуется) | Рекомендуется разумно использовать распределенную функцию DataFrame, предоставляемую PyODPS, и отправлять основные вычисления в MaxCompute для распределенного выполнения вместо загрузки и обработки на клиентском узле PyODPS. Это ключ к правильному использованию PyODPS. | Рекомендуется использовать PyODPS. Интерфейс DataFrame для завершения обработки данных. Общие требования, такие как необходимость обработки каждой строки данных и последующая запись ее обратно в таблицу или разделение строки данных на несколько строк, можно выполнить с помощью PyODPS. DataFrameсерединаиз |
Пример сценария
Пользователям необходимо извлечь некоторую информацию, анализируя строки журнала, генерируемые каждый день. Существует таблица только с одним столбцом, типом которой является строка. С помощью сегментации слов jieba можно сегментировать китайские предложения, а затем можно найти и сохранить нужные ключевые слова. в информационной таблице.
Демонстрация неэффективного кода обработки:
import jieba
t = o.get_table('word_split')
out = []
with t.open_reader() as reader:
for r in reader:
words = list(jieba.cut(r[0]))
#
# Обработать логику и сгенерировать processed_data
#
out.append(processed_data)
out_t = o.get_table('words')
with out_t.open_writer() as writer:
writer.write(out)Идея обработки данных на одной машине состоит в том, чтобы читать данные построчно, затем обрабатывать данные построчно, а затем записывать данные построчно в целевую таблицу. В течение всего процесса загрузка и выгрузка данных занимает много времени, а для обработки всех данных на машине, где выполняется сценарий, требуется большой объем памяти. Особенно для пользователей, использующих узлы DataWorks, это легко превысить. значение выделенной памяти по умолчанию. Это приводит к ошибке операции OOM.
Эффективно обработать демонстрационный код:
from odps.df import output
out_table = o.get_table('words')
df = o.get_table('word_split').to_df()
# Предполагается, что поля и типы, которые необходимо вернуть, следующие:
out_names = ["word", "count"]
out_types = ["string", "int"]
@output(out_names, out_types)
def handle(row):
import jieba
words = list(jieba.cut(row[0]))
#
# Обработать логику и сгенерировать processed_data
#
yield processed_data
df.apply(handle, axis=1).persist(out_table.name)Используйте apply для достижения распределенного выполнения:
- Сложная логика помещается в функцию дескриптора. Эта функция будет автоматически сериализована на сервер и использоваться как UDF. Она будет вызываться и выполняться на сервере. Поскольку сервер дескрипторов также обрабатывает каждую строку, когда она фактически выполняется, логика. Нет никакой разницы. Разница в том, что когда программа, написанная таким образом, передается на выполнение в сторону MaxCompute, несколько машин могут обрабатывать данные одновременно, что может сэкономить много времени.
- Вызов интерфейса persist запишет сгенерированные данные непосредственно в другую таблицу MaxCompute. Все формирование и потребление данных выполняются в кластере MaxCompute, что также экономит локальную сеть и память.
- В этом примере также используются сторонние пакеты.,MaxCompute是支持自定义函数серединаиспользоватьтрехсторонний Сумкаиз(示例серединаиз
jieba),Поэтому нет необходимости беспокоиться о стоимости модификаций.,Вы можете наслаждаться крупномасштабными вычислительными возможностями MaxCompute практически без изменений в основной логике.
Использование PyODPS с DataWorks
Все статьи этой серии посвящены использованию PyODPS с DataWorks,местное использованиекодэффекты и статьикодпоследовательный。может войтиDataWorksизразработка данныхСоздание страницыPyODPSузел。PyODPSузелразделен наPyODPS 2 и Пи ОДПС 3 двух видов:
- Базовой версией PyODPS 2 на языке Python является Python 2.
- Базовой версией PyODPS 3 на языке Python является Python 3.
Узлы PyODPS могут быть созданы в соответствии с фактической используемой версией языка Python:

- Ограничения поддержки пакетов
- DataWorksизPyODPSузел НедостатокmatplotlibОжидание посылки,Следующие функции могут быть ограничены:
- Функция построения графика DataFrame.
- Пользовательские функции DataFrame необходимо отправить в MaxCompute для выполнения. Из-за ограничений песочницы Python сторонние библиотеки поддерживают только все чистые библиотеки Python и NumPy, поэтому Pandas нельзя использовать напрямую.
- Ненастраиваемые функции, выполняемые в DataWorks, могут использовать NumPy и Pandas, предварительно установленные на платформе. Другие сторонние пакеты с двоичным кодом не поддерживаются.
- DataWorksизPyODPSузел Не поддерживаетсяPythonизatexitСумка,Пожалуйста, используйтеtry-finallyструктуравыполнить Связанные функции。
- Ограничение на количество прочитанных записей данных
В узле PyODPS DataWorks,options.tunnel.use_instance_tunnelНастройка по умолчанию:False,то есть по умолчанию,Можно прочитать максимум 10 000 записей данных. Если вам нужно прочитать больше записей данных,Необходимо включить глобальноinstance tunnel,То есть вам нужно вручную изменитьoptions.tunnel.use_instance_tunnelустановлен наTrue。
В узле PyODPS DataWorks,воля Сумка Содержит глобальную переменнуюodpsилиo,Это вход в ОДПС. Нет необходимости вручную определять записи ODPS,например:
#Проверяем, существует ли таблица pyodps_iris
print(o.exist_table('pyodps_iris'))Табличные операции
Остановимся на том, как выполнить серию Табличных операций ОДПС, то есть понять, как использовать инструменты для достижения конечного эффекта.
Табличные операции в рамках текущего проекта
Перечислите все таблицы в пространстве проекта:
o.list_tables()Метод в порядке Перечислите все таблицы в пространстве проекта:
list_tables(project=None, prefix=None, owner=None, schema=None, type=None, extended=False)параметр:
- project (str) – Пространство проекта. Если пространство проекта не указано, по умолчанию используется пространство по умолчанию.
- prefix (str) – Укажите начальный символ для соответствия
- owner (str) – Укажите таблицу, принадлежащую владельцу запроса.
- schema (str) – Руководство Шма
- type (str) – Укажите тип таблицы
- extended (bool) – Если True, развернуть информацию таблицы
возвращаться:
tables in this project, filtered by the optional prefix and owner.
Тип возврата:
generator
for table in o.list_tables():
print(table)выходизинформация Сумка Содержитимя таблицы<Название библиотеки>.<имя таблицы>、тип<type>и столschema
может пройтиprefixпараметр Перечислить только заданные префиксыизповерхность:
for table in o.list_tables(prefix="table_prefix"):
print(table.name)
Получено этим методом Table Объект не будет автоматически загружать атрибуты, кроме имени таблицы. Если вам нужно прочитать эти атрибуты при перечислении таблицы, PyODPS 0.11.5 и последующие версии,может бытьlist_tablesдобавить вextended=Trueпараметр:
for table in o.list_tables(extended=True):
print(table.name, table.creation_time,table.schema)Если вам нужно перечислить таблицу по типу,Можно указатьtypeпараметр。другойтипизповерхность Список举методследующее:
managed_tables = list(o.list_tables(type="managed_table")) # Получение списка встроенных таблиц
external_tables = list(o.list_tables(type="external_table")) # внешний вид списка
virtual_views = list(o.list_tables(type="virtual_view")) # Просмотр списка
materialized_views = list(o.list_tables(type="materialized_view")) # Получение списка материализованных представленийОпределить, существует ли таблица
o.exist_table()Метод в порядке Определить, существует ли таблица。
print(o.exist_table('pyodps_iris'))
# Возврат True указывает на то, что таблица pyodps_iris существует.
Получить таблицу
Входной объектизo.get_table()Метод в порядке Получить таблицу。
get_table(name, project=None, schema=None)- Получить таблицуизschemaинформация。
t = o.get_table('products')
print(t.schema) # Получить таблицуpyodps_irisизschema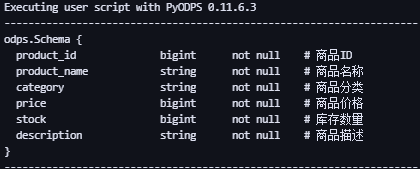
- Получить таблицу Списокинформация
t = o.get_table('products')
print(t.schema.columns) # table
- Определенный столбец информации для Tweet таблицы.
t = o.get_table('products')
print(t.schema['category']) # Получить Информация о столбце sepallength таблицы продуктов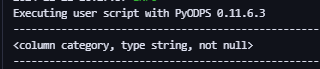
- Примечания к информации столбца таблицы Tweet.
t = o.get_table('products')
print(t.schema['category'].comment) # Получить Примечания к информации столбца категории таблицы продуктов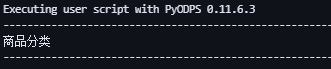
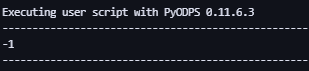
- Получить таблицуизжизненный цикл。
t = o.get_table('products')
print(t.lifecycle) # Получить Жизненный цикл tablepyodps_iris-1 представляет постоянное существование
- Время создания Tweet таблицы.
t = o.get_table('products')
print(t.creation_time) # Получить Время создания таблицыpyodps_iris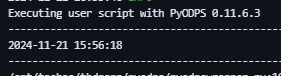
- Получить таблицу, является ли это виртуальным представлением.
t = o.get_table('продукты')
print(t.is_virtual_view) # Является ли Получить таблицупродуктов виртуальным представлением?,Вернуть ложь,Это значит нет.
Кросс-проектиз Табличные операции
t = o.get_table('table_name', project='other_project')вother_projectпересекизпроект,table_name为Кросс-проект获取изимя таблицысказать。
Создать схему таблицы
- Инициализируется столбцами таблицы и дополнительным секционированием.
from odps.models import Schema, Column, Partition
columns = [
Column(name='num', type='bigint', comment='the column'),
Column(name='num2', type='double', comment='the column2'),
]
partitions = [Partition(name='pt', type='string', comment='the partition')]
schema = Schema(columns=columns, partitions=partitions)После инициализации вы можете получить информацию о полях, информацию о разделах и т. д.
- Получить всю информацию о поле
print(schema.columns)
- Получить имя поля без раздела
print(schema.names)
- Получить несекционированный тип поля
print(schema.types)
использоватьSchema.from_lists()метод。Долженметод Полегчевызов,Однако невозможно напрямую задать комментарии для столбцов и разделов.
from odps.models import Schema
schema = Schema.from_lists(['num', 'num2'], ['bigint', 'double'], ['pt'], ['string'])
print(schema.columns)
Создать таблицу
Можетиспользоватьo.create_table()метод Создать таблицы, есть два способа ее использования: с помощью метода схемы таблицы, с помощью метода имени поля и метода типа поля. В то же время Создать Существуют определенные ограничения на типы данных полей таблицы. Подробности заключаются в следующем.
С помощью таблицы Схема Создать таблицу
С помощью таблицы Схема Создать Когда таблицу, вам нужно сначала создать схему таблицы, затем передать SchemaСоздать таблицу。
#Создать таблицуизschema
from odps.models import Schema
schema = Schema.from_lists(['num', 'num2'], ['bigint', 'double'], ['pt'], ['string'])
#byschemaСоздать таблицу
table = o.create_table('my_new_table', schema)
#Только когда таблица не существует, Создать таблицу。
table = o.create_table('my_new_table', schema, if_not_exists=True)
#Установить жизненный цикл.
table = o.create_table('my_new_table', schema, lifecycle=7)После создания таблицы,тыможет пройтиprint(o.exist_table('my_new_table'))Проверьте, успешно ли создана таблица,возвращатьсяTrueУказывает, что таблица успешно создана。

Используйте имена и типы полей. Создать таблицу.
#Создаем таблицу разделов my_new_table,Можно передать (список полей таблицы,Список полей раздела).
table = o.create_table('my_new_table', ('num bigint, num2 double', 'pt string'), if_not_exists=True)
#Создаем несекционированную таблицу my_new_table02.
table = o.create_table('my_new_table02', 'num bigint, num2 double', if_not_exists=True)Это можно определить с помощью существующей_таблицы:
print(o.exist_table('my_new_table'))
Используйте имена и типы полей. Создать таблицу.:новые данныетип
Когда переключатель нового типа данных не включен (выключен по умолчанию),Типы данных Создать таблицу могут быть только типами BIGINT, DOUBLE, DECIMAL, STRING, DATETIME, BOOLEAN, MAP и ARRAY. Если вам нужно создать таблицу с полями новых типов данных, такими как TINYINT и STRUCT,можно открытьoptions.sql.use_odps2_extension = Trueвыключатель,Примеры следующие.
from odps import options
options.sql.use_odps2_extension = True
table = o.create_table('my_new_table', 'cat smallint, content struct<title:varchar(100), body:string>')Синхронное обновление таблиц
Когда таблица обновляется другими программами,Например, изменение схемы,Можно позвонитьreload()метод同步поверхностьизвозобновлять。
#Изменение схемы таблицы
from odps.models import Schema
schema = Schema.from_lists(['num', 'num2'], ['bigint', 'double'], ['pt'],['string'])
#проходитьreload()Синхронное обновление таблиц
table = o.create_table('my_new_table', schema)
table.reload()Запись данных таблицы
- использовать Входной объектиз
write_table()метод Запись данных。

records = [[111, 1.0], # Это может быть список.
[222, 2.0],
[333, 3.0],
[444, 4.0]]
o.write_table('my_new_table', records, partition='pt=test', create_partition=True) #Создаем раздел pt=test и записываем данные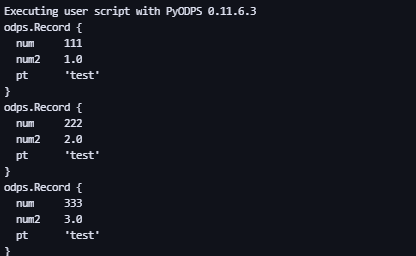
- каждый звонок
write_table()метод,MaxCompute сгенерирует файл на стороне сервера. Эта операция занимает много времени,В то же время слишком большое количество файлов снизит эффективность последующих запросов. Поэтому рекомендуется при использовании этого метода,Запись нескольких наборов данных одновременно,Или передайте объект-генератор. - вызов
write_table()метод向поверхностьсередина Запись данных时会追加приезжать原有数据середина。PyODPSДанные о покрытии не предоставленыиз Параметры,Если данные необходимо перезаписать,Пожалуйста, удалите исходные данные вручную. Для несекционированных таблиц,нуждатьсявызовtable.truncate()метод;Для секционированных таблиц,нуждатьсяудалить раздел, а затем создайте новый раздел.
对поверхность对象вызовopen_writer()метод Запись данных。
t = o.get_table('my_new_table')
with t.open_writer(partition='pt=test02', create_partition=True) as writer: #Создаем раздел pt=test02 и записываем данные
records = [[1, 1.0], # Это может быть список.
[2, 2.0],
[3, 3.0],
[4, 4.0]]
writer.write(records) # Здесь Records может быть итерируемым объектом.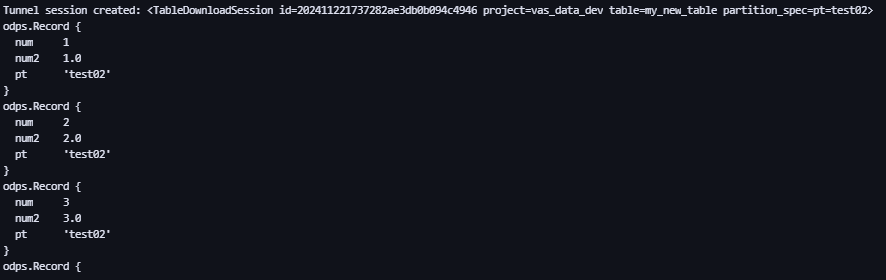
Если это многоуровневая таблица разделов, то пример записи следующий.
t = o.get_table('test_table')
with t.open_writer(partition='pt1=test1,pt2=test2') as writer: # Многоуровневая запись разделов.
records = [t.new_record([111, 'aaa', True]), # Это также может быть объект Record.
t.new_record([222, 'bbb', False]),
t.new_record([333, 'ccc', True]),
t.new_record([444, 'Китайский', False])]
writer.write(records)Используйте несколько процессов для параллельной записи данных
Каждый процесс использует один и тот же Session_ID при записи данных, но имеет разные Block_ID. Каждый блок соответствует файлу на стороне сервера. Основной процесс выполняет Commit для завершения загрузки данных.
import random
from multiprocessing import Pool
from odps.tunnel import TableTunnel
def write_records(tunnel, table, session_id, block_id):
# Создайте сеанс, используя указанный идентификатор.
local_session = tunnel.create_upload_session(table.name, upload_id=session_id)
# Укажите Block_ID при создании Writer.
with local_session.open_record_writer(block_id) as writer:
for i in range(5):
# Сгенерируйте данные и запишите их в соответствующий блок.
record = table.new_record([random.randint(1, 100), random.random()])
writer.write(record)
if __name__ == '__main__':
N_WORKERS = 3
table = o.create_table('my_new_table', 'num bigint, num2 double', if_not_exists=True)
tunnel = TableTunnel(o)
upload_session = tunnel.create_upload_session(table.name)
# Каждый процесс использует один и тот же Session_ID.
session_id = upload_session.id
pool = Pool(processes=N_WORKERS)
futures = []
block_ids = []
for i in range(N_WORKERS):
futures.append(pool.apply_async(write_records, (tunnel, table, session_id, i)))
block_ids.append(i)
[f.get() for f in futures]
# Наконец, выполните Commit и укажите все блоки.
upload_session.commit(block_ids)Вставить строку в таблицу
Запись представляет собой строку записей в таблице.,对поверхность对象вызовnew_record()методсоздать новыйизRecord。
t = o.get_table('test_table')
r = t.new_record(['val0', 'val1']) # Количество значений должно быть равно количеству полей в схеме таблицы.
r2 = t.new_record() # Никакое значение не может быть передано.
r2[0] = 'val0' # Установите значение через смещение.
r2['field1'] = 'val1' # Установите значение по имени поля.
r2.field1 = 'val1' # Установите значения через свойства.
print(record[0]) # Возьмите значение в позиции 0.
print(record['c_double_a']) # Получите значение из поля.
print(record.c_double_a) # Получите значение через атрибут.
print(record[0: 3]) # Операция нарезки.
print(record[0, 2, 3]) # Берите значения из нескольких позиций.
print(record['c_int_a', 'c_double_a']) # Получайте значения из нескольких полей.Получить данные таблицы
Есть много способов сказать: Получить данные таблицы. Распространенными методами являются следующие:
- использовать Входной объектиз
read_table()метод。
# Обработать запись.
for record in o.read_table('my_new_table', partition='pt=test'):
print(record)Если вам нужно просмотреть менее 10 000 фрагментов данных в начале каждой таблицы,Может对поверхность对象вызовhead()метод。
t = o.get_table('my_new_table')
# Обработайте каждый объект Record.
for record in t.head(3):
print(record)вызовopen_reader()метод Чтение данных。
- использовать
withповерхность达式из写法следующее。
from odps.models import Schema
t = o.get_table('my_new_table')
with t.open_reader(partition='pt=test') as reader:
count = reader.count
for record in reader: # Его можно выполнять несколько раз, пока не будет прочитано количество записей. Это можно преобразовать в параллельную операцию.
print(record) # Обработка записи, например печать самой записи.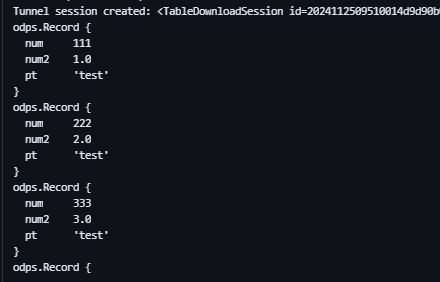
Нетиспользоватьwithповерхность达式из写法следующее
reader = t.open_reader(partition='pt=test')
count = reader.count
for record in reader: # Его можно выполнять несколько раз, пока не будет прочитано количество записей. Это можно преобразовать в параллельную операцию.
print(record) # Обработка записи, например печать самой записи.Удалить таблицу
использоватьdelete_table()метод Удалить существующиеизповерхность。
o.delete_table('my_table_name', if_exists=True) # Удалить только тогда, когда таблица существует таблицу。
t.drop() # Если объект Table существует, вызовите метод Drop напрямую.раздел таблицы
Определите, является ли это таблицей разделов
#Создать таблицуизschema
из схемы импорта odps.models
таблица = o.get_table('my_new_table')
если таблица.схема.разделы:
print('Таблица %s секционирована. % table.name)
Обход всех разделов таблицы
from odps.models import Schema
table = o.get_table('my_new_table')
for partition in table.partitions: # Обход всех разделов
print(partition.name) # Конкретные шаги обхода, здесь печатается имя раздела.
for partition in table.iterate_partitions(spec='pt=test'): # траверс pt=test Вторичный раздел под разделом
print(partition.name) # Конкретные шаги обхода, здесь печатается имя раздела.
for partition in table.iterate_partitions(spec='dt>20230119'): # траверс dt>20230119 Вторичный раздел под разделом
print(partition.name) # Конкретные шаги обхода, здесь печатается имя раздела.
Определить, существует ли раздел
table = o.get_table('my_new_table')
table.exist_partition('pt=test,sub=2015')Получить раздел
#Создать таблицуизschema
из схемы импорта odps.models
таблица = o.get_table('my_new_table')
раздел = table.get_partition('pt=test01')
печать (partition.creation_time)
печать(partition.size)
удалить раздел
t = o.get_table('my_new_table')
t.delete_partition('pt=test', if_exists=True) # Настройте параметр if_exists только в том случае, если раздел существует. раздел。
partition.drop() # Если объект раздела существует, напрямую вызовите метод Drop для удаления объекта раздела.Канал загрузки и скачивания данных
Туннель — это канал данных MaxCompute. Пользователи могут загружать или скачивать данные в MaxCompute через Tunnel.
Пример загрузки данных
from odps.tunnel import TableTunnel
table = o.get_table('my_table')
tunnel = TableTunnel(odps)
upload_session = tunnel.create_upload_session(table.name, partition_spec='pt=test')
with upload_session.open_record_writer(0) as writer:
record = table.new_record()
record[0] = 'test1'
record[1] = 'id1'
writer.write(record)
record = table.new_record(['test2', 'id2'])
writer.write(record)
# нужно быть внутри with код вне блока commit, иначе данные не записываются коммит приведет к ошибке
upload_session.commit([0])Скачать пример данных
from odps.tunnel import TableTunnel
tunnel = TableTunnel(odps)
download_session = tunnel.create_download_session('my_table', partition_spec='pt=test')
# Обработка каждой записи.
with download_session.open_record_reader(0, download_session.count) as reader:
for record in reader:
print(record) # специфическийизтраверсшаг,Вот объект записи печати


Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
