Практика интегрированной архитектуры озера данных и хранилища озер
1. Что такое озеро данных?
Озеро данных — это центральное место, в котором хранятся большие объемы данных в исходном формате. По сравнению с иерархическим хранилищем данных, в котором данные хранятся в виде файлов или папок, озеро данных использует плоскую архитектуру и объектное хранилище для хранения данных. Объектное хранилище имеет теги метаданных и уникальные идентификаторы, упрощающие поиск и извлечение данных из разных регионов, что повышает производительность. Используя дешевое объектное хранилище и открытые форматы, озера данных позволяют многим приложениям использовать данные.
Озера данных были разработаны в ответ на ограничения хранилищ данных. Хотя хранилища данных предоставляют предприятиям высокопроизводительную и масштабируемую аналитику, они дороги, запатентованы и не могут справиться с современными сценариями использования, которые стремится решить большинство компаний.
Озера данных обычно используются для консолидации всех данных предприятия в одном центральном месте, где данные могут храниться «как есть» без необходимости заранее навязывать схему (т. е. формальную структуру организации данных). как хранилище данных. Данные со всех этапов процесса уточнения могут храниться в озере данных: необработанные данные могут быть связаны со структурированными источниками табличных данных организации (такими как таблицы базы данных), а также с промежуточными таблицами данных, созданными во время уточнения необработанных данных. ввод и хранение.
В отличие от большинства баз данных и хранилищ данных, озера данных могут обрабатывать все типы данных, включая неструктурированные и полуструктурированные данные, такие как изображения, видео, аудио и документы, которые необходимы для современного машинного обучения и важных сценариев использования расширенной аналитики.
2. Зачем использовать озеро данных?
Во-первых, озера данных представляют собой открытые форматы, поэтому пользователи избегают привязки к проприетарным системам, таким как хранилища данных, которые становятся все более важными в современных архитектурах данных. Озера данных также отличаются высокой надежностью и низкой стоимостью благодаря своей способности масштабировать и использовать объектное хранилище.
Кроме того, передовая аналитика и машинное обучение неструктурированных данных являются сегодня одним из наиболее важных стратегических приоритетов для предприятий. Уникальная возможность принимать необработанные данные в различных форматах (структурированных, неструктурированных, полуструктурированных), а также другие преимущества, упомянутые ранее, делают озера данных очевидным выбором для хранения данных.
При правильной архитектуре озеро данных может:
- Поддержка науки о данных и машинного обучения:озеро данных позволяет конвертировать необработанные данные в структурированные данные,Для выполнения SQL-анализа, обработки данных и машинного обучения с низкой задержкой. Необработанные данные можно хранить бесконечно при меньших затратах.,Для использования в будущем существует машинное обучение и анализ.
- централизовать данные、Слияние и классификация:Централизованныйозеро данных устраняет проблемы с каналом данных (такие как дублирование данных, множественные политики безопасности и трудности совместной работы) и предоставляет последующим пользователям единое место для поиска всех источников данных.
- Быстро и легко интегрируйте различные источники данныхлюбойивсетип данные могут собираться и храниться бесконечно долго. данные, включая пакетную обработку и потоковую передачу данных, видео, изображений, двоичных файлов и т. д. Потому что озеро Данные предоставляют зону посадки для новых данных, они всегда актуальны.
- Демократизируйте данные, предоставив пользователям инструменты самообслуживания:озеро Данные очень гибки, позволяя пользователям с совершенно разными навыками, инструментами и языками одновременно выполнять разные задачи анализа.
3. Проблемы озера данных
Несмотря на свои многочисленные преимущества, озера данных создают различные проблемы, которые могут замедлить инновации и производительность. Озерам данных не хватает функций, необходимых для обеспечения качества и надежности данных. Казалось бы, простые задачи могут значительно снизить производительность озера данных, а озеро данных не может удовлетворить потребности бизнеса и нормативных требований из-за плохих функций безопасности и управления.
(1) Проблемы с надежностью
Без надлежащих инструментов озера данных могут страдать от проблем с надежностью данных, из-за чего ученым и аналитикам данных будет сложно анализировать данные. Эти проблемы могут быть связаны с трудностями при объединении пакетных и потоковых данных, повреждением данных и другими факторами.
(2) Низкая производительность
По мере увеличения размера данных в озере данных производительность традиционных механизмов запросов часто снижается. Некоторые узкие места включают управление метаданными, неправильное разделение данных и т. д.
(3) Отсутствие функций безопасности.
Озера данных сложно защитить и должным образом управлять ими из-за отсутствия прозрачности и возможности удалять или обновлять данные. Эти ограничения затрудняют удовлетворение требований регулирующих органов.
Решением проблемы озера данных является Lakehouse, который решает проблему озера данных путем добавления сверху уровня транзакционного хранилища. Lakehouse, который использует структуры данных и возможности управления данными, аналогичные тем, которые используются в хранилище данных, но работает непосредственно на облачном озере данных. В конечном итоге Lakehouse позволяет традиционной аналитике, науке о данных и машинному обучению сосуществовать в одной системе в открытом формате.
Lakehouse открывает широкий спектр новых вариантов использования для проектов корпоративного анализа данных, бизнес-аналитики и машинного обучения, которые могут принести значительную пользу для бизнеса. Используя SQL для запроса данных в озере данных, аналитики данных могут получить обширную информацию, ученые, работающие с данными, могут объединять и обогащать наборы данных для создания моделей ML с более высокой точностью, инженеры по обработке данных могут создавать автоматизированные конвейеры ETL, а сотрудники BI могут создавать визуальные информационные панели и инструменты отчетности стали быстрее и проще, чем когда-либо. Все эти варианты использования могут выполняться одновременно в озере данных без необходимости извлекать и перемещать данные, даже при поступлении новых данных.
Общие характеристики озер данных и хранилищ данных
Data lake | Data lakehouse | Data warehouse | |
|---|---|---|---|
тип данных | Все типы: структурированные данные, полуструктурированные данные, неструктурированные (необработанные) данные. | Все типы: структурированные данные, полуструктурированные данные, неструктурированные (необработанные) данные. | структурированные данные |
расходы | $ | $ | $$$ |
Формат | Открыть формат | Открыть формат | Закрытый проприетарный Формат |
Масштабируемость | Расширение сохраняет данные любого количества с низкими затратами независимо от типа данных. | Расширение сохраняет данные любого количества с низкими затратами независимо от типа данных. | Из-за расходов поставщика,расходы, которые масштабируются вверх, растут в геометрической прогрессии |
целевые пользователи | Ограниченный: специалист по данным | Унифицированные: аналитик данных, специалист по данным, инженер по машинному обучению. | Ограниченный: Аналитик данных |
надежность | Низкое качество, болото данных | Высококачественные и надежные данные | Высококачественные и надежные данные |
Простота использования | Сложность: изучение больших объемов необработанных данных может быть затруднено без инструментов для организации и каталогизации данных. | Простота: обеспечивает простоту и структуру хранилища данных и обеспечивает более широкий спектр вариантов использования озера данных. | Простота: структура хранилища данных позволяет пользователям быстро и легко получать доступ к данным для отчетности и анализа. |
производительность | Poor | High | High |
4. Хранилище данных и озеро данных
Предприятия собирают огромные объемы данных из различных источников, которые выходят далеко за рамки того, с чем могут справиться традиционные реляционные базы данных. Это приводит к вопросу о хранилище данных и озере данных: когда какое из них использовать и как они соотносятся с витринами данных, хранилищами операционных данных и реляционными базами данных.
Все эти библиотеки хранилищ данных имеют схожую основную функциональность: хранилище данных для бизнес-отчетности и анализа. Но их цель、структура、Тип хранилища данные, откуда они поступают и кто имеет право доступа, все различается.
Обычно данные в эти репозитории поступают из систем, сгенерировавших данные: CRM, ERP, HR, финансовых приложений и других источников. К записям данных, созданным этими системами, применяются бизнес-правила, а затем они отправляются в хранилище данных, озеро данных или другую область хранения данных.
Когда все данные из разных бизнес-приложений собраны в единую платформу данных, мы можем использовать инструменты анализа данных для выявления тенденций или предоставления информации, которая поможет принимать бизнес-решения.
Хранилище данных и озеро данных
Когда предприятия получают большие объемы данных из операционных систем и им необходимо проанализировать данные в любое время, они обычно выбирают хранилища данных и озера данных. Хранилища данных часто служат единственным источником достоверной информации, поскольку на этих платформах хранятся исторические данные, включая данные, которые были очищены и классифицированы.
В хранилищах данных в основном хранятся большие объемы данных из операционных систем, тогда как в озерах данных хранятся данные из многих других источников, включая различные наборы необработанных данных из операционных систем предприятия и других источников.
Поскольку данные в озере данных могут быть неточными и поступать из источников за пределами операционных систем предприятия, оно не очень подходит для обычных пользователей бизнес-анализа. Озера данных больше подходят для специалистов по анализу данных и других экспертов по анализу данных.
Что касается разницы между хранилищем данных и озером данных, вы можете себе представить разницу между складом и озером: на складе хранятся товары из определенного источника, а вода в озере поступает из рек, ручьев и других источников и является сырой. данные.
В число поставщиков хранилищ данных входят, среди прочего, AWS, Cloudera, IBM, Google, Microsoft, Oracle, Teradata, SAP, SnapLogic и Snowflake. Поставщики озер данных включают AWS, Google, Informatica, Microsoft, Teradata и т. д.
Хранилище данных и витрина данных
Витрины данных и хранилища данных часто путают, но их цели явно разные.
Витрина данных обычно является частью хранилища данных; данные обычно поступают из хранилища данных, хотя они также могут поступать из других источников. Витрины данных предназначены специально для определенного сообщества пользователей (например, отдела продаж), чтобы они могли быстро найти нужные им данные. Обычно данные хранятся там для определенной цели, например для финансового анализа.
Витрины данных также намного меньше хранилищ данных — они могут хранить десятки гигабайт по сравнению с сотнями гигабайт или петабайтами данных, которые можно хранить и использовать для обработки данных.
Витрины данных могут быть созданы на основе существующего хранилища данных или другой системы источников данных; вы просто проектируете и создаете таблицы базы данных, заполняете их соответствующими данными и решаете, кто может получить доступ к набору данных.
Хранилище данных против ODS
Хранилище оперативных данных (ODS) — это база данных, которая служит областью временного хранения для всех данных, которые собираются попасть в хранилище данных для обработки. Мы можем думать об этом как о складской погрузочной платформе, куда товары доставляются, проверяются и проверяются.
В ODS данные можно очищать, проверять (в целях резервирования) и проверять на соответствие бизнес-правилам перед поступлением на склад. В ODS мы можем запрашивать данные, но данные являются временными, поэтому они предоставляют только простые информационные запросы, такие как текущий статус заказа клиента.
ODS обычно работает на системе управления реляционными базами данных (СУБД) или платформе Hadoop. Данные в ODS обычно предоставляются с помощью инструментов интеграции и извлечения данных, таких как Attunity Replication или Hortonworks DataFlow.
Реляционные базы данных против хранилищ данных и озер данных
хранилище данных, озеро данныхи База отношений Основное различие между существующими системами данных состоит в том, что база отношений данные используются для хранения структурированных данных из одного источника (например, системы транзакций). данных, тогда как хранилище данных используется для хранения структурированных данных из нескольких источников. данные。озеро Разница между даннымисуществовать в том, что это могут быть хранилища неструктурированные, полуструктурированные иструктурированные. данные。
База отношений данные относительно просты в создании и могут использоваться для организации данных в реальном времени, таких как данные транзакций и т. д. База отношений данныхиз Недостатком являетсяони Нетподдерживать Нетструктурированные Данные базы данных данных или большой объем данных, которые постоянно генерируются существующими. Это оставляет нам только существующее хранилище данных с озером. Выбирайте между данными Делать. Несмотря на это, многие предприятия продолжают полагаться на базу Guanxi. данные для выполнения таких задач, как анализ оперативных данных или анализ тенденций.
5. Обмен практическими примерами интегрированной архитектуры Autohome «озеро-склад».
Следующий текст взят из DataFunTalk, в котором рассказывается, как построить интегрированную архитектуру озера и хранилища на основе Apache Iceberg для улучшения видимости данных до мельчайшего уровня с точки зрения многомерного анализа. В нем обсуждаются преимущества, полученные от внедрения Apache; Айсберг, и какие еще выгоды можно ожидать в будущем.
01
Предыстория обновления архитектуры хранилища данных
1. Болевые точки хранилища данных на базе Hive
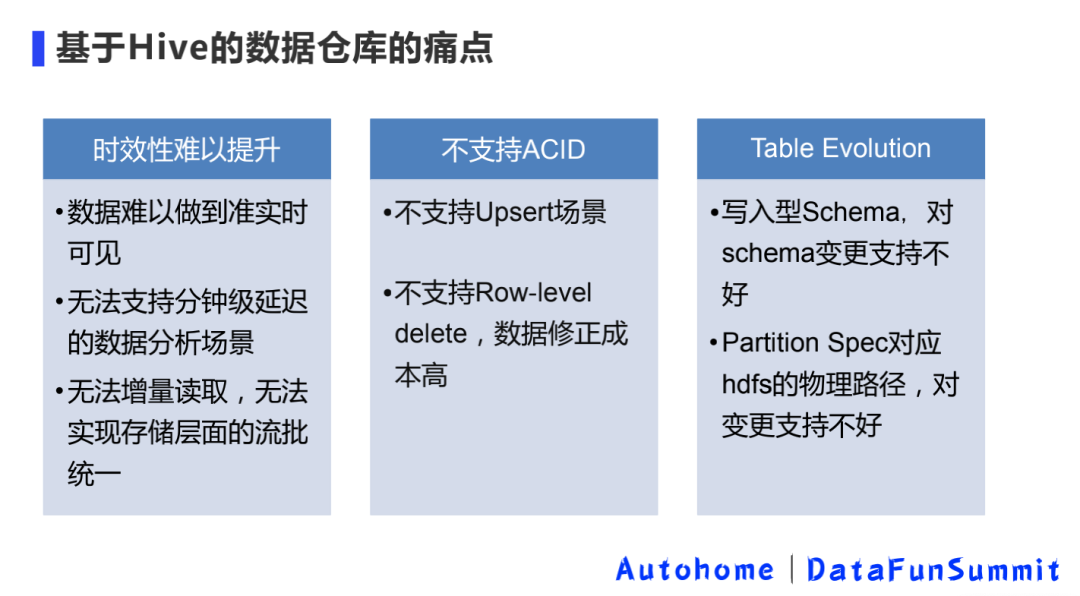
Исходное хранилище данных было полностью построено на основе Hive и в основном имело указанные выше три основные проблемы.
2. Ключевые особенности Айсберга

Iceberg Есть четыре основные особенности: поддержка ACID Семантика, механизм инкрементальных снимков, пакетный интерфейс потоковой передачи открытых таблиц поддерживаются.
02
Практика интегрированной озерно-складской архитектуры на базе Iceberg
Смысл интеграции озер и складов в том, что мне не нужно видеть озера и склады. Данные имеют открытый формат метаданных. Они могут свободно передаваться, а также могут быть подключены к разнообразной вычислительной экологии верхнего уровня.
—— Цзя Янцин
1. Добавляем ссылку, ведущую в озеро
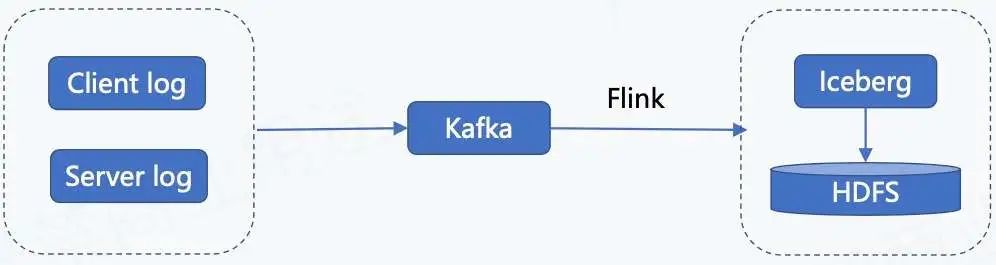
На рисунке выше показана ссылка на данные журнала для входа в озеро. Данные журнала включают журналы клиента, журналы пользователей и журналы сервера. Эти данные журнала будут введены в Kafka в режиме реального времени, затем записаны в Iceberg с помощью задач Flink и, наконец, сохранены в HDFS.
2. Откройте ссылку на Flink SQL в озеро.
Наша ссылка Flink SQL на озеро построена на основе «Flink 1.11 + Iceberg 0.11». Для подключения к каталогу Iceberg мы в основном делаем следующее:
- Meta Server Увеличиватьверно Iceberg Catalog изподдерживать;
- SQL SDK Увеличивать Iceberg Catalog поддерживать。
Затем на этой основе платформа открывает функцию управления таблицами Iceberg, позволяя пользователям самостоятельно строить SQL-таблицы на платформе.
3. Войдите в озеро - поддержите пользователей прокси.
Второй шаг – это внутренняя практика взаимодействия с существующей бюджетной системой и системой полномочий.
Потому что раньше, когда платформа выполняла задания в реальном времени, платформа по умолчанию запускалась пользователями Flink. Предыдущее хранилище не задействовало HDFS-хранилище, поэтому проблем могло не быть, и не нужно было думать о вопросах распределения бюджета. .
Но писать об Айсберге сейчас могут быть сопряжены с некоторыми проблемами. Например, если у команды хранилища данных есть собственная торговая площадка, данные должны быть записаны в их каталог, а бюджет должен быть выделен для их бюджета. При этом разрешения должны быть подключены к системе учетных записей автономной команды.
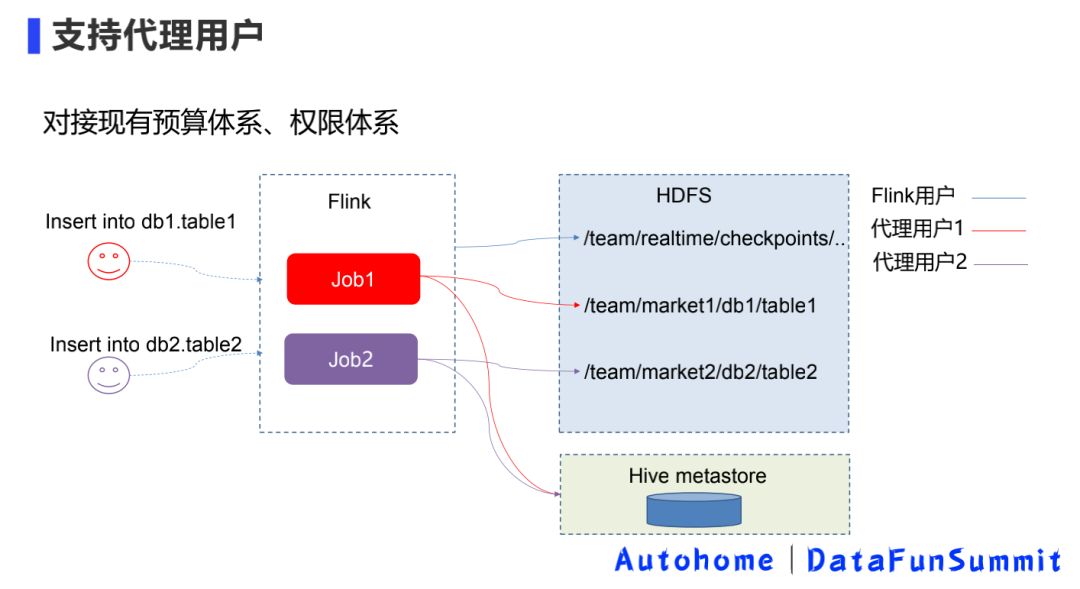
Как показано выше, это в основном работает как прокси-пользователь на платформе. Пользователи могут указать, какую учетную запись использовать для записи этих данных в Iceberg. Процесс реализации в основном включает в себя следующие три.

① Добавьте конфигурацию уровня таблицы: 'iceberg.user.proxy' = 'targetUser'.
- Включить суперпользователя
- Аутентификация учетной записи команды
② доступ HDFS При включении прокси-пользователей:
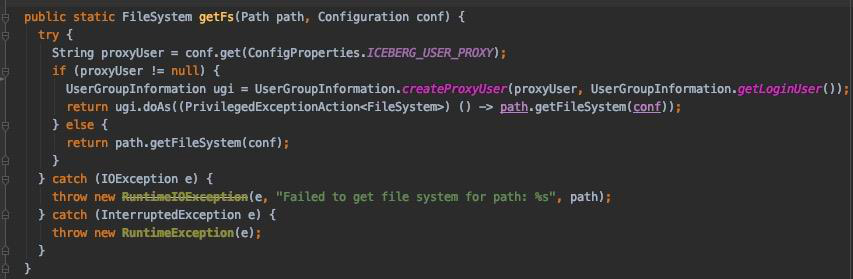
③ доступ Hive Metastore При указании прокси-пользователя
- Обратитесь к соответствующей реализации Spark:
org.apache.spark.deploy.security.HiveDelegationTokenProvider
- динамический прокси HiveMetaStoreClient, используя доступ пользователя через прокси Hive metastore
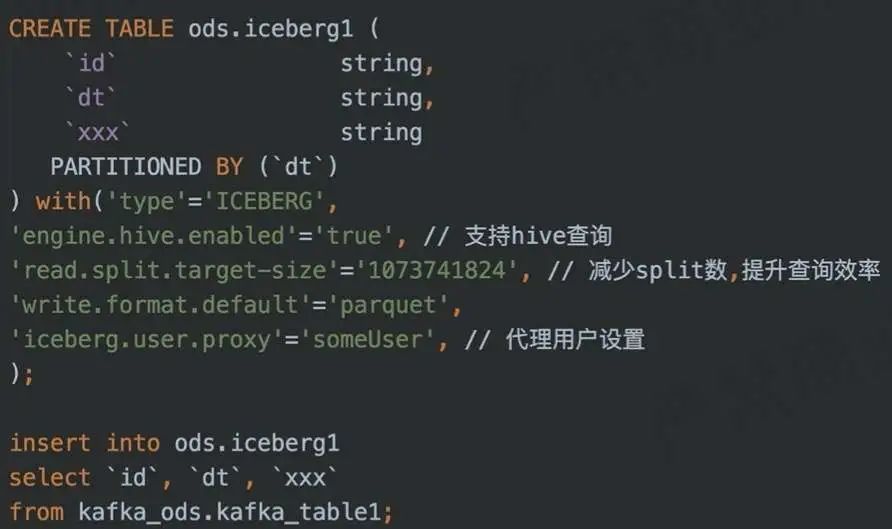
4. Пример входа Flink SQL в озеро
DDL + DML
5. Канал входящего озера данных CDC

Как показано выше, у нас есть платформа AutoDTS, которая отвечает за доступ в режиме реального времени к данным бизнес-библиотеки. Мы будем получать доступ к данным из этих бизнес-библиотек в Kafka. В то же время он также поддерживает настройку задач распространения на платформе, что эквивалентно распространению данных в Kafka по различным механизмам хранения. В этом сценарии они распространяются в Iceberg. .
6. Ссылки Flink SQL CDC на озеро открываются.
Ниже приведены изменения, которые мы внесли на основе «Flink1.11 + Iceberg 0.11» для поддержки входа CDC в озеро:
Улучшенная раковина айсберга:
Flink версии 1.11 представляет собой AppendStreamTableSink и не может обрабатывать потоки CDC. Изменение и адаптация.
управление таблицами
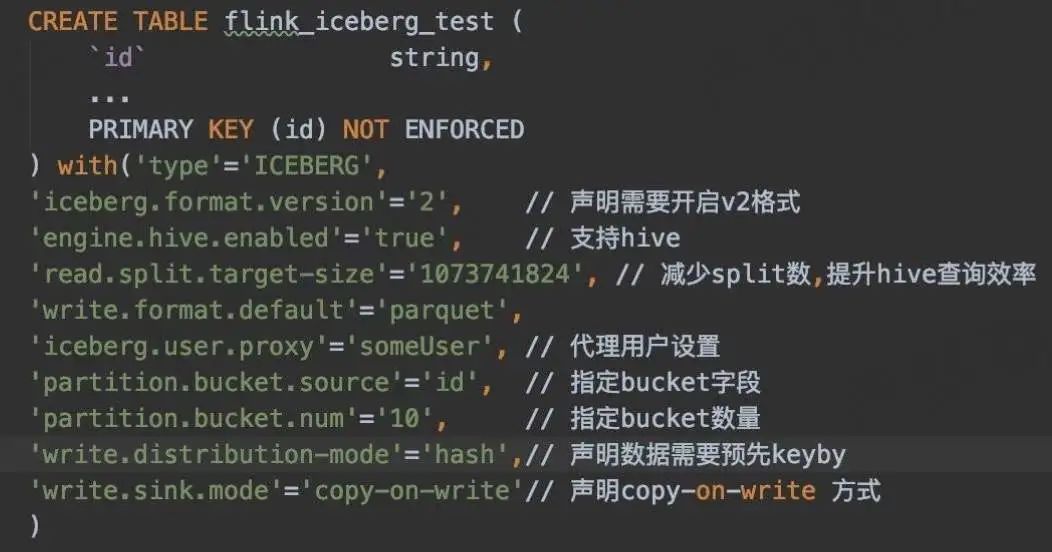
- поддерживать Primary key(PR1978)
- Включите версию V2: 'iceberg.format.version' = '2'
7. Данные CDC попадают в озеро
① Опорный ковш
В сценарии Upsert необходимо обеспечить запись одного и того же фрагмента данных в один и тот же Bucket. Как этого добиться?
В настоящее время синтаксис Flink SQL не поддерживает объявление сегментов сегментов, которые необходимо объявлять посредством конфигурации:
'partition.bucket.source'='id', //Укажите поле сегмента
'partition.bucket.num'='10', // Указываем количество сегментов
② Copy-on-write sink
Причина использования копирования при записи заключается в том, что исходное сообщество слияния при чтении не поддерживает объединение небольших файлов, поэтому мы временно внедрили приемник копирования при записи. В настоящее время бизнес его тестирует и использует, и результаты хорошие.
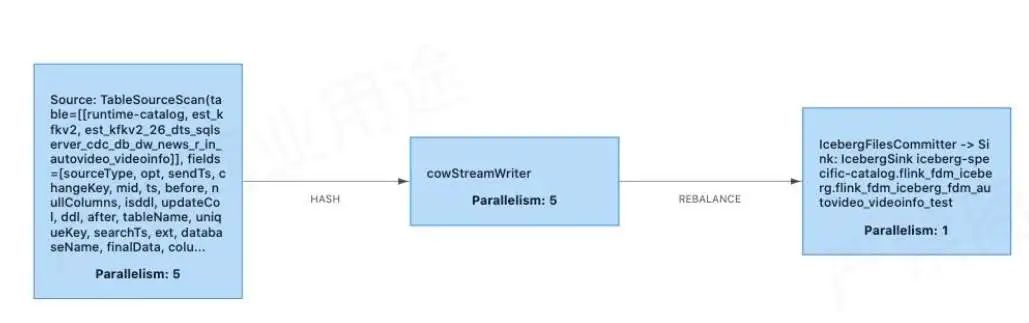
Выше Copy-on-Write Реализация практически такая же, как и оригинал. Merge-on-Read относительно похоже,Есть такжеStreamWriter Множественный параллелизм записывает и Последовательная фиксация одного параллелизма FileCommitter。
При копировании при записи количество сегментов необходимо устанавливать соответствующим образом в зависимости от объема данных таблицы без необходимости дополнительного объединения небольших файлов.
StreamWriter записывает с несколькими степенями параллелизма на этапе snapshotState.
- Увеличивать Buffer;
- Прежде чем писать, вам необходимо определить, что последняя контрольная точка была успешно зафиксирована;
- Группируйте и объединяйте по сегментам, а также записывайте сегмент за сегментом.
Последовательная фиксация одного параллелизма FileCommitter
- table.newOverwrite()
- Flink.last.committed.checkpoint.id
8. Пример — конфигурация данных CDC в озере.
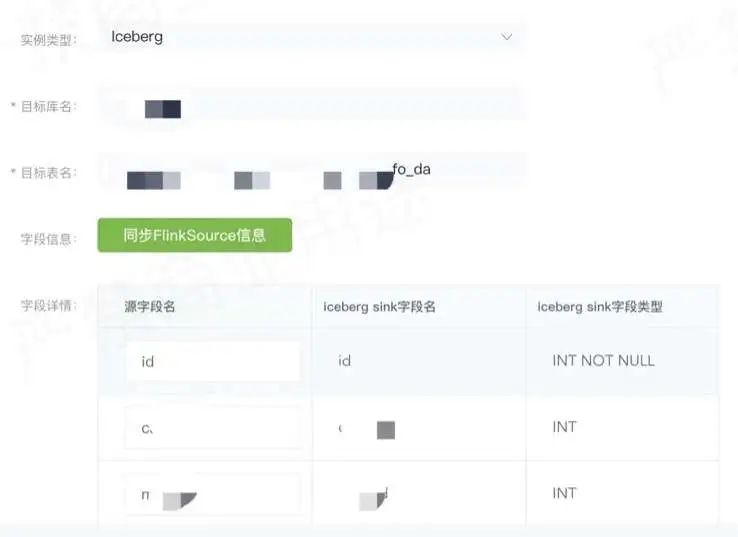
Как показано на рисунке выше, при фактическом использовании бизнес-сторона может создавать или настраивать задачи распространения на платформе DTS.
Выберите таблицу Iceberg в качестве типа экземпляра, а затем выберите целевую базу данных, чтобы указать, данные какой таблицы вы хотите синхронизировать с Iceberg. Затем вы можете выбрать связь между полями исходной таблицы и целевой таблицы. После настройки вы можете выбрать таблицу Iceberg. может запустить задачу распространения. После запуска задача реального времени будет отправлена на вычислительную платформу реального времени Flink, а затем приемник копирования при записи будет использоваться для записи данных в таблицу Iceberg в реальном времени.
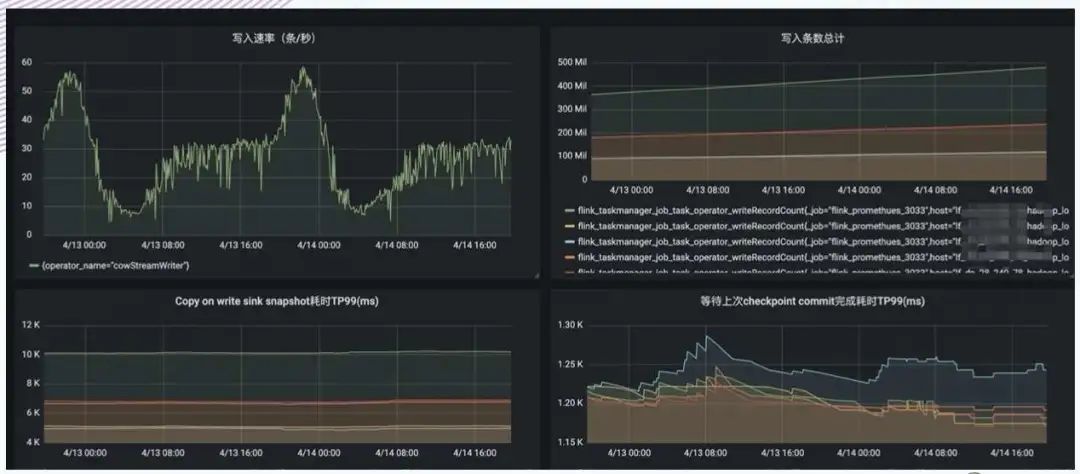
9. Другие способы входа в озеро
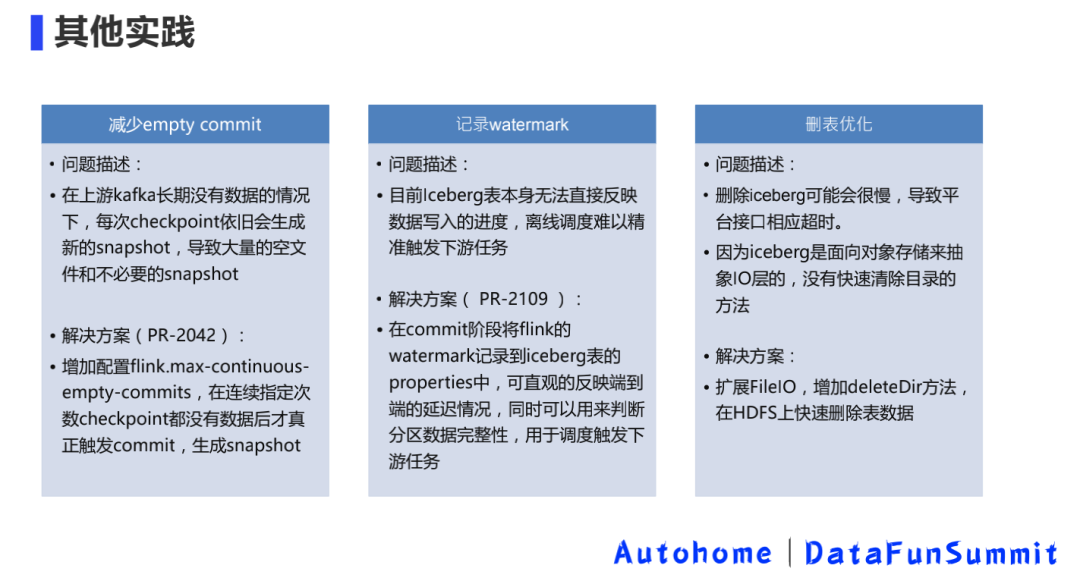
10. Небольшое объединение файлов и очистка данных

11. Вычислительный движок – Flink
Flink — это основной вычислительный механизм платформы реального времени. В настоящее время он в основном поддерживает данные, поступающие в сценарий озера, и имеет следующие характеристики.
Данные поступают в озеро в квазиреальном времени:
Flink и Iceberg Flink имеет высочайший уровень интеграции с точки зрения данных, поступающих в озеро. Сообщество активно использует технологию озера данных.
Интеграция платформы:
AutoStream представляет IcebergCatalog и поддерживает создание таблиц и вход в озеро через SQL. AutoDTS поддерживает настройку таблиц MySQL, SQLServer и TiDB в озере.
Интеграция потоков и партий:
В рамках концепции интеграции потока и партии постепенно будут проявляться преимущества Flink.
12. Вычислительный движок – Улей
Hive существовать SQL уровень партии Iceberg и Spark 3 Он имеет более высокую степень интеграции и в основном обеспечивает следующие три функции. ссылка:Apache Spark Большой релиз 3.0.0 —— Комплексный анализ важных особенностей
Обычное объединение небольших файлов и запрос метаинформации:
SELECT * FROM prod.db.table.history Также можно просматривать снимки, файлы, манифесты.
Запись данных в автономном режиме:
- Insert into
- Insert overwrite
- Merge into
Аналитический запрос:
В основном поддерживает ежедневный анализ и сценарии запросов в квазиреальном времени.
13. Вычислительная машина – Trino/Presto.
AutoBI ужеи Presto Интегрирован для создания отчетов и сценариев аналитических запросов.
Trino
- Используйте Iceberg напрямую в качестве источника данных отчета
- Требуется механизм кэширования метаданных Увеличить: https://github.com/trinodb/trino/issues/7551.
Выполняется интеграция сообщества: https://github.com/prestodb/presto/pull/15836. ссылка:Prestoсуществовать Внутренняя практика и оптимизация Bytedance
14. Вытоптанные ямы

03
Преимущества и резюме
1. Резюме
Изучив интеграцию озер и складов, а также интеграцию потоковой передачи и пакетной обработки, мы подвели соответствующие итоги.
Озеро и склад интегрированы
- Iceberg поддерживать Hive Metastore;
- Общее использование аналогично Hive Таблицы похожи: тот же формат данных, тот же Вычислительный. двигатель。
Потоковое пакетное объединение
Унификация потоков потоков в сценариях квазиреального времени: одно и то же происхождение, одинаковые вычисления и одно и то же хранилище.
2. Доход от бизнеса

3. Преимущества архитектуры – хранилище данных квазиреального времени
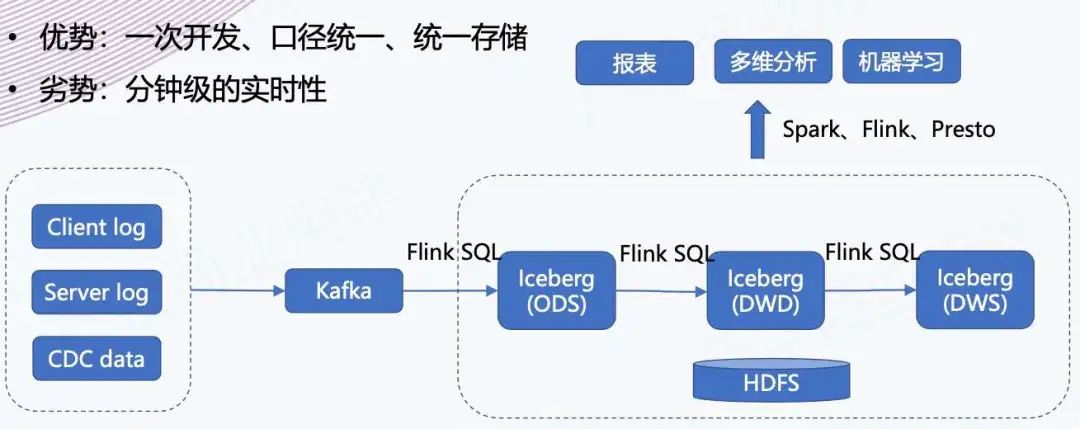
Также упоминалось выше,Наше поддержка Анализ позиций в квазиреальном времени,Это эквивалентно последующемуиз Хранилище данных квазиреального времени Здание обеспечивает фундаментиз Проверка архитектуры。позволятьХранилище данных в режиме реального временииз Преимущество – единоразовая разработка、Единый калибр、единыйхранилище,Это настоящая интеграция партии и потока. Недостатком является низкая производительность в реальном времени.,Оказывается, это может быть задержка в секунды или миллисекунды.,Сейчас существует видимость данных на минутном уровне.
Но существуют на архитектурном уровне,Это по-прежнему имеет большое значение,Мы видим некоторую надежду в будущем,Можно поставить весь оригинал “T + 1” Хранилище данных преобразуется в хранилище данных, работающее в квазиреальном времени, что повышает общую своевременность данных хранилища данных и, таким образом, обеспечивает лучшую поддержку как восходящих, так и перерабатывающих предприятий.
04
Последующее планирование

Отказ от ответственности:Опубликовано через этот общедоступный аккаунтиз Оригинал статьи опубликован на официальном аккаунте.,Или отредактируйте и систематизируйте отличные статьи, которые ищут существующие в Интернете.,Авторские права на статью принадлежат первоначальному автору,Только для читателей и друзей, ссылка. Для неоригинальных статей, которыми поделились,Некоторые потому, что настоящий источник не может быть найден.,Если источник указан неправильно или использованные в статье изображения, ссылки и т.п. включают, помимо прочего, программное обеспечение, материалы и т.п.,Если есть нарушения,Пожалуйста, свяжитесь с серверной частью напрямую,Опишите конкретные статьи,Серверная часть устранит неудобства как можно скорее.,Глубоко сожалею.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
