Практика анализа данных Flink+StarRocks в реальном времени
краткое содержание:Эта статья составлена из StarRocks Технический евангелист сообщества Се Инь. Flink Forward Asia 2022 Обмен Hucang в реальном времени. Содержание этой статьи в основном разделено на пять частей:
1. Чрезвычайно быстрый анализ данных
2. Обновление данных в режиме реального времени.
3. StarRocks Connector For Apache Flink
4. Случаи из практики клиентов
5. Планирование на будущее
Tips:Нажмите«Прочитай оригинальный текст»Получите это бесплатно 5000CU*час Flink Облачные ресурсы
01
Чрезвычайно быстрый анализ данных
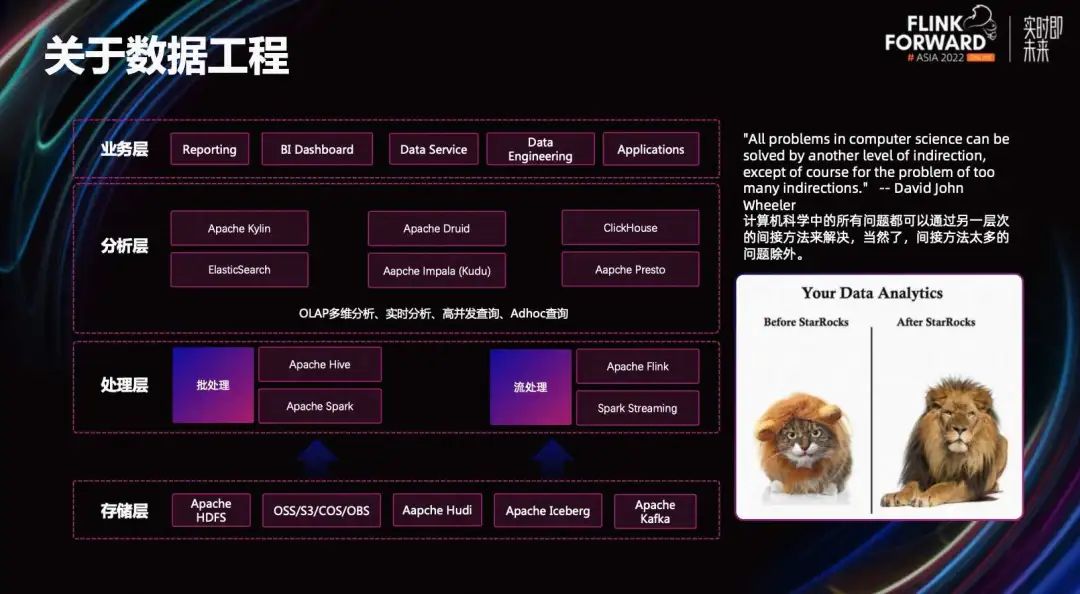
Тенденция унифицированного OLAP-анализа и основные возможности сверхбыстрого анализа запросов StarRocks. Все сложные задачи в информатике можно решить добавлением промежуточных слоев, но нельзя добавлять слишком много вещей. Оглядываясь назад на эволюцию экосистемы Hadoop, впервые появилось распределенное хранилище, которое решило проблему хранения больших объемов данных с помощью дешевого оборудования. А MapReduce помог нам постепенно решить проблему распределенной обработки.
Чтобы позволить аналитикам, умеющим писать только SQL, сосредоточиться на бизнесе, не беспокоясь о программировании на Java, Hive помогает нам решить проблему автоматического анализа SQL в MR. Когда люди почувствовали, что диск Shuffle работает слишком медленно, мы изучили эластичный распределенный набор данных на основе памяти RDD, чтобы обеспечить эффективный расчет данных, распределенных в памяти.
Поскольку микропакетные вычисления в памяти по-прежнему не могут описать всю семантику реального времени, существует Flink, механизм распределенных вычислений, предназначенный для работы в реальном времени.
В первые дни, когда люди не были так уж зависимы от данных, независимо от того, каким образом данные поступали, достаточно было наконец их увидеть. Времена меняются, и не только руководству необходимо смотреть на цифры, но и рядовым партнерам также необходимо использовать цифры. В результате продукты OLAP-анализа растут, как грибы после дождя. Некоторые из них могут напрямую агрегировать показатели, некоторые могут выполнять специальные проверки, некоторые неуязвимы в одной таблице, а некоторые могут поддерживать обновление данных.
Поскольку компонентов слишком много, данные передаются туда и обратно между различными механизмами, что приводит к низкой своевременности, несовместимости калибров и огромной трате аппаратных ресурсов и трудозатрат. Поэтому люди с нетерпением ждут аналитической базы данных с максимальной производительностью, которая сможет объединить уровень анализа OLAP и открыть новую парадигму анализа данных в реальном времени.
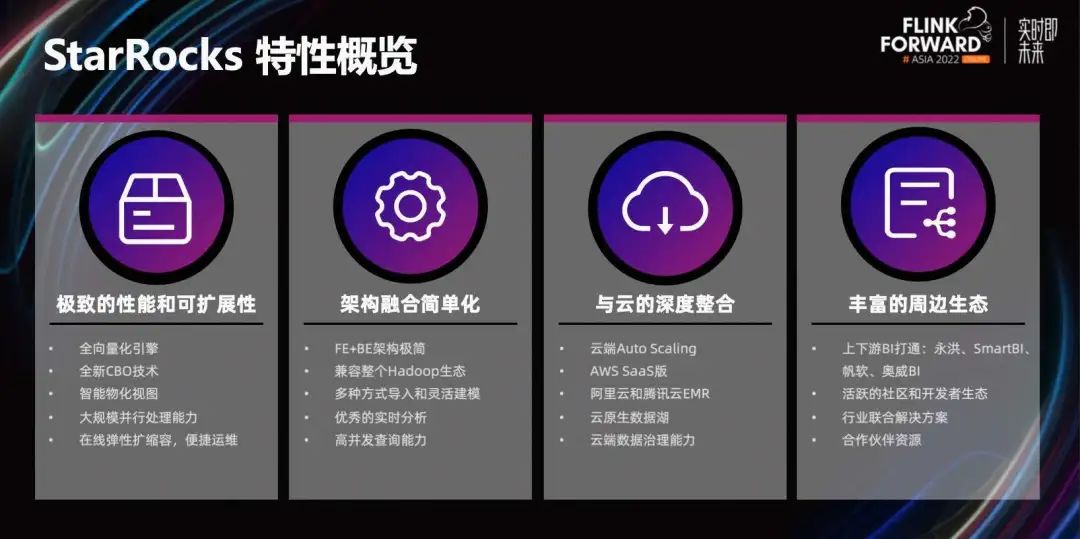
Цель StarRocks — помочь клиентам создать техническую архитектуру, обеспечивающую чрезвычайно быстрый унифицированный анализ OLAP. Прежде всего, после двух лет строительства его высочайшие характеристики глубоко укоренились в сердцах людей. Он полностью поддерживает пакет технологий, таких как механизм векторизации, технология CBO, интеллектуальное материализованное представление и т. д. Это позволяет StarRocks выполнять чрезвычайно быстрый OLAP-анализ за доли секунды, обеспечивая чрезвычайно быстрый ответ на последней миле приложений анализа данных.
В то же время современная архитектура MPP позволяет службам запросов полностью использовать многомашинные и многоядерные ресурсы. Убедитесь, что услуги можно масштабировать и масштабировать с помощью оборудования. Простая архитектура fe+be обеспечивает минимизацию эксплуатации и обслуживания, а также обладает отличными возможностями приема данных в реальном времени, что делает анализ данных в реальном времени легким и простым.
В сценариях перечисления с высоким уровнем параллелизма и разумным планированием ресурсов можно достичь десятков тысяч QPS. Что касается интеграции с облаком, нам удалось быстро развернуть версию StarRocks для сообщества на полууправляемых сервисах крупных облачных провайдеров. Мы также прилагаем все усилия, чтобы интегрировать более богатые экологические решения в окружающую среду. Открытое и активное сообщество постепенно привлекло партнеров, которые помогли нам внести больше ключевых функций.
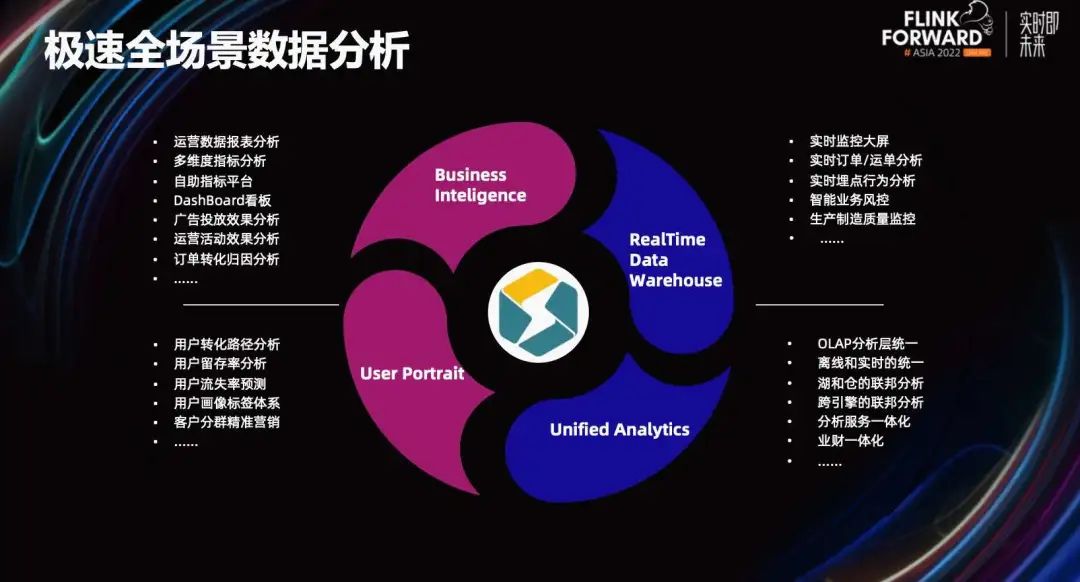
Что может нам сделать StarRocks с такой экстремальной производительностью анализа? Ниже представлены четыре основных сценария.
- Бизнес-отчет BI. Это особенность StarRocks. Если вы хотите ускорить фиксированные отчеты, самообслуживание BI, исследовательский анализ с помощью перетаскивания, вы можете использовать StarRocks для их поддержки.
- Бизнес в реальном времени. Например, большой экран в реальном времени, Flink+StarRocks. План уже очень зрелый. Особенно индикаторы дополнительной агрегации, StarRocks таблица агрегирования. Модель может быть сгенерирована напрямую. DWS слоистый sum,min,max агрегированные показатели.
- Некоторые домохозяйства существуют при создании платформы данных клиентов.,Также будут выполнены такие сценарии, как сегментация домохозяйств, поведенческий анализ и портреты домохозяйств. В автономном режиме ссылки StarRocks в реальном времени также можно импортировать за считанные секунды.,Таким образом, офлайн, в реальном времени и зданные могут быть совместно проанализированы.,Пусть свежесть данных будет выше.
- единыйанализировать。Кроме того, что я только что сказализв реальном времениданныеи Оффлайнданныеизединый,StarRocks Также поддерживает Iceberge/Hudi/Hive Запрос внешнего вида позволяет реализовать объединенный анализ озер и складов. Также доступен для клиентов StarRocks Он действительно решил проблему разделения их анализа и услуг и попытался интегрировать отраслевой и финансовый анализ и т. д.
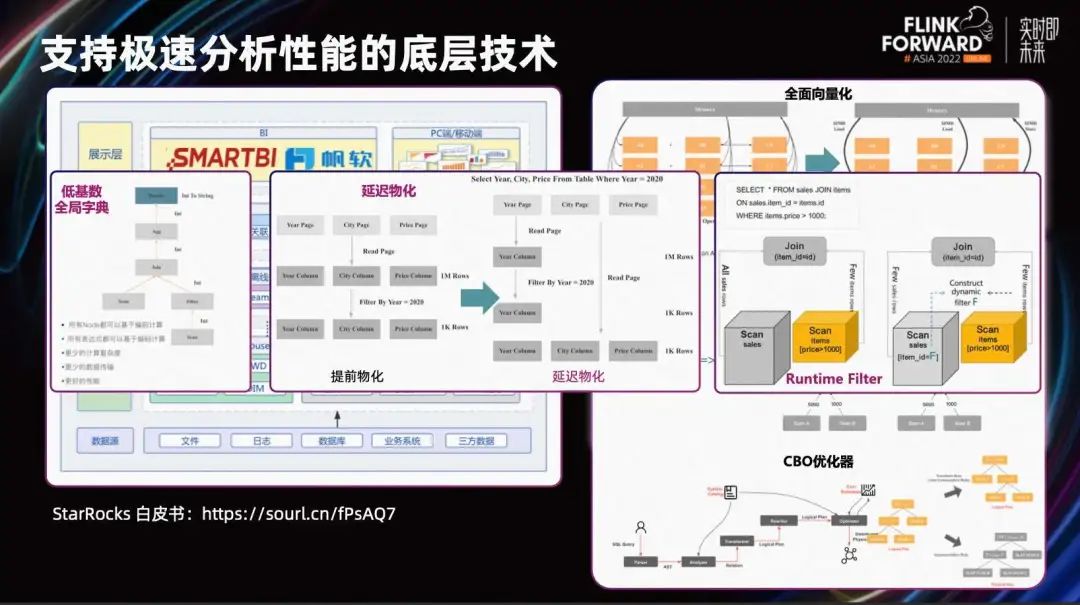
Как показано на рисунке выше, он демонстрирует основные возможности StarRocks. Во-первых, StarRocks полностью поддерживает инструкции SIMD, полностью используя вычислительную мощность одного процессора, что позволяет ему обрабатывать больше данных за одну инструкцию.
StarRocks поддерживает множество стратегий распределенного соединения. Для различных сценариев оптимизатор CBO может автоматически выбирать подходящую стратегию распределенного соединения. Выберите оптимальный план из нескольких вариантов плана запроса, чтобы обеспечить наилучшее качество запросов.
С помощью оптимизатора CBO взаимосвязь между левой и правой таблицами может быть автоматически переписана на основе статистической информации, а оптимальный план запроса может быть разумно выбран. Кроме того, например, использование глобального словаря с низкой мощностью для сопоставления String с int; задержка материализации для уменьшения количества недействительных Scan; runtimeFilter позволяет перенести фильтрацию правой таблицы в левую таблицу для раннего сканирования и т. д. Также существует пакет экстремальных оптимизаций, позволяющий StarRocks справиться с очень сложными аналитическими запросами.
В максимально возможной степени позвольте пользователям сосредоточиться на самой бизнес-логике. Освободите себя от ручной работы по оптимизации, такой как настройка различных параметров, выбор стратегий распределенного соединения и т. д., и позвольте StarRocks выполнять эти задачи автоматически.
StarRock поддерживает очень широкие возможности приема данных. Существуют вспомогательные средства для синхронизации существующих данных с традиционными реляционными данными, или вы можете объединить модель первичного ключа и Flink-CDC для интеграции синхронизации данных Upsert и Delete в реальном времени.
Кроме того, для данных очереди сообщений стандартная загрузка StarRocks может напрямую использовать сообщения Kafka или может быть интегрирована с Connector и Flink. Основной компонент FE отвечает за управление метаданными, анализ SQL, создание плана выполнения и т. д. BE содержит векторизованный механизм выполнения и столбчатое хранилище. На внешнем уровне он поддерживает очень широкие возможности запросов внешнего вида и может интегрировать данные из озер и хранилищ для комплексного анализа. Функция BlockCache, созданная StarRocks, может сделать возможности запроса озера не хуже, чем производительность хранилища.
Кроме того, развертывание StarRocks очень простое. Независимо от того, развертываете ли вы его в облаке или в частном порядке, вы можете добиться минимализма в эксплуатации и обслуживании. Его можно легко подключить извне через MySQL JDBC, чтобы справиться с BI-анализом, отчетами, панелями мониторинга в реальном времени и другими задачами.
02
Обновления данных в режиме реального времени
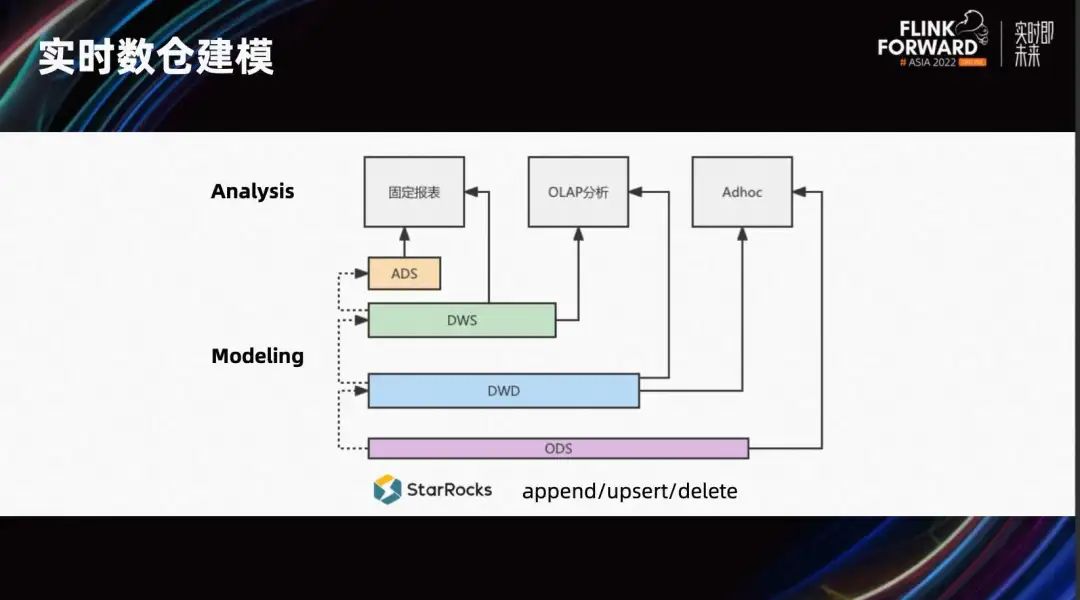
Далее давайте сосредоточимся на том, как StarRocks предоставляет эффективные услуги анализа и запросов в обновленных ссылках в реальном времени. Прежде всего, когда дело доходит до хранилища данных в реальном времени, понимание каждого предприятия и каждого клиента различно, и выбор технического маршрута также будет отличаться.
Некоторая логика обработки сцен очень сложна. Благодаря мощной вычислительной мощности Flink и богатой временной семантике клиенты могут выполнять моделирование в Flink. Затем обработанные результаты сохраняются в шине сообщений. StarRocks может подписаться на соответствующие иерархические данные в Kafka, а затем синхронизировать результаты. В сценариях с фиксированными отчетами основное внимание часто уделяется запросам агрегированных индикаторов на уровне ADS/DWS, что требует чрезвычайно высокой производительности запросов. Это решение расчета в Flink и выполнения чрезвычайно быстрых запросов и анализа в StarRocks является более подходящим. В некоторых сценариях объем данных невелик. Использование идеи запуска пакетов в автономных хранилищах данных и использования системы планирования для выполнения этого слоя за слоем в StarRocks также позволяет реализовать иерархическое построение хранилищ данных. То, что мы обычно называем многомерным анализом OLAP, обычно фокусируется на широких таблицах DWD и уровне легкой агрегации DWS, более гибких специальных запросах, а также может просматривать необработанные данные ODS.
Большинство идей по созданию хранилищ данных реального времени, обсуждавшихся ранее, основаны на потоке добавления. Предположим, что наши данные содержат только операции добавления и не содержат операций Upsert/Delete. В сценариях, где имеются обновления, будь то поэтапное строительство или микропартийное планирование, трудно гарантировать, что индикаторы агрегирования верхнего уровня могут быть детализированы до уровня детализации.
Некоторые клиенты пытались использовать модель первичного ключа для ODS в некоторых сценариях, чтобы обеспечить обновление/удаление данных в реальном времени. Затем указанное выше многоуровневое представление использует логические представления для обеспечения полной синхронизации совокупных показателей и деталей.
Кроме того, когда мы объединяем его с Flink, недостаточно поддерживать только поток добавления. Так сможет ли StarRocks решить эту проблему? Ответ: да.
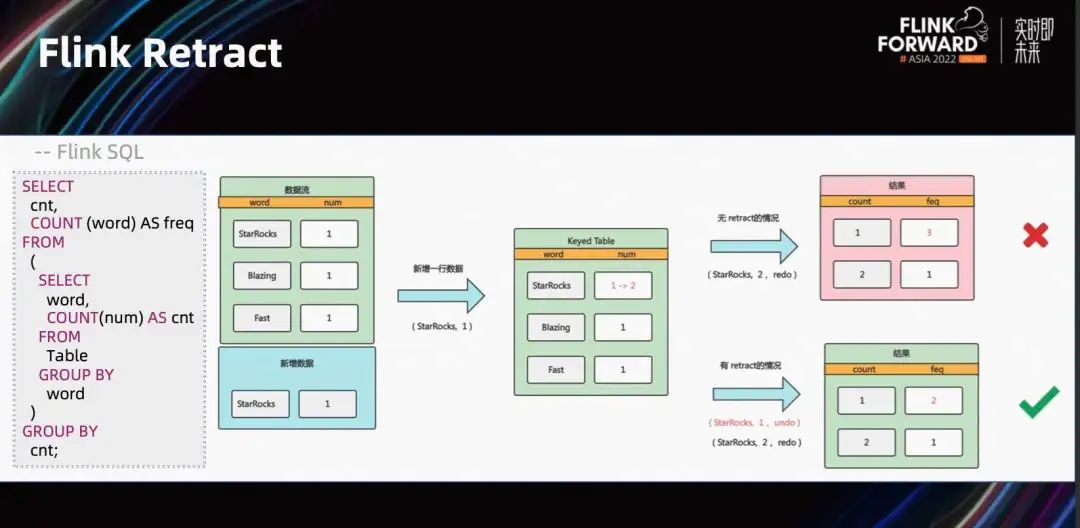
В жизни мы всегда говорим, что после опрокидывания воды трудно прийти в себя, а это значит, что все предрешено и необратимо. Но мощный Flink имеет функцию отслеживания потока. Вот простой SQL для статистики частоты слов.
Видно, что после поступления новых данных «StarRocks, 1» если нет ретрейсинга данных, чтобы пометить данные из предыдущего раунда Sink как недействительные, то наложение новых входящих данных приведет к ошибкам в результатах. Напротив, с помощью Flink Retract вы можете отозвать выводы предыдущей партии и выплюнуть правильные показатели.
В этом случае сторона Flink может решить проблему восстановления, но как насчет стороны OLAP? Без эффективных и стабильных возможностей Upsert/Delete очень легко вызвать дублирование данных и ошибки результатов.

Год назад мы выпустили новую модель таблицы первичных ключей механизма хранения в версии 1.9, которая поддерживает обновления в реальном времени, сохраняя при этом производительность запросов. Он имеет встроенное поле OP, которое отмечает Upsert/Delete данных в форме 0 или 1, что точно соответствует характеристикам данных потока ретрейсмента Flink. В сочетании с предоставляемым нами соединителем Flink поток ретрейсмента Flink может быть напрямую связан с моделью первичного ключа.
Он реализует обновления на основе метода «Удалить+Вставка» или метода слияния при записи. По сравнению с исходной уникальной моделью слияния при чтении производительность запросов повышается в 3–10 раз без ущерба для производительности импорта.
это очень хорошо подходит TP->AP Синхронизируйте данные в режиме реального времени и ускоряйте выполнение сценариев запросов. проходить Flink-CDC инструмент, будет TP бизнес-системы, такие как MySQL Синхронизируйте напрямую с StarRocks значительно упрощает анализ потоков данных в реальном времени и прост в использовании. В настоящее время он принят многими пользователями онлайн-систем и является типичной парадигмой анализа данных в реальном времени.

В 2022 году мы реализовали функцию постоянного индексирования первичного ключа для модели pk, чтобы уменьшить нагрузку на память модели первичного ключа. Исходный индекс первичного ключа основан на хеш-таблице, занимающей всю память, а новый постоянный индекс также использует хеш-дизайн и многоуровневую структуру, аналогичную LSM.
Первый уровень хэша представляет собой хэш-таблицу в памяти, а второй уровень — структуру хеш-таблицы на диске. В целях экономии места для хранения используется структура Shard по длине, аналогичная исходной хеш-таблице с полной памятью. Результаты тестов показывают, что использование памяти обычно составляет лишь 1/10 от исходного. Поскольку запрос индекса по сути представляет собой большое количество случайных операций ввода-вывода, если вам необходимо сохранить индекс, рекомендуется использовать твердотельный накопитель.
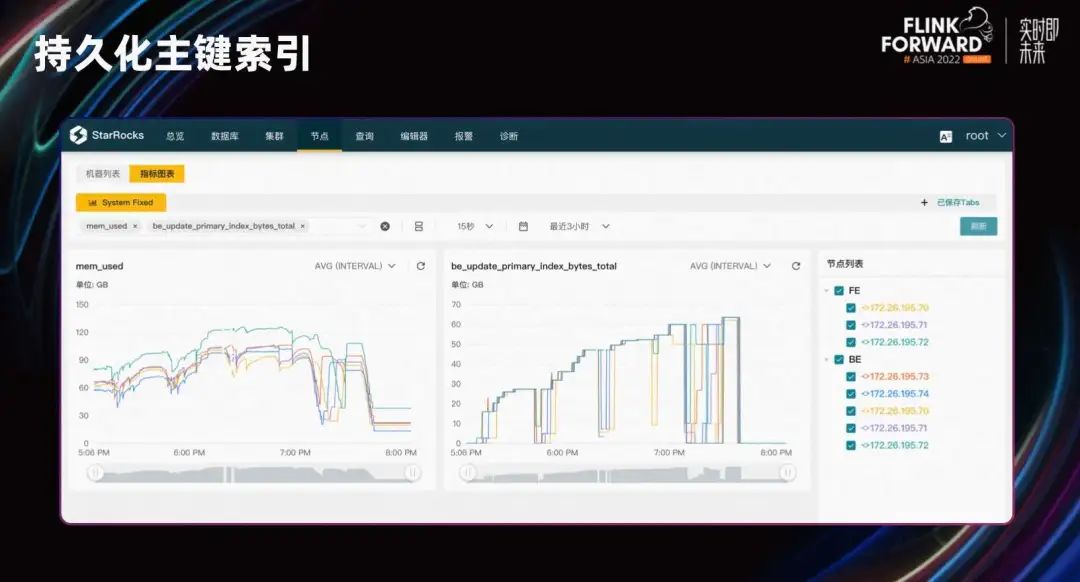
Это сравнение памяти во время нашего теста импорта. Левая часть — это общее использование памяти процессом BE, а правая — использование памяти индексом. В индексном режиме полной памяти, когда данные продолжают импортироваться, общий объем памяти достигает максимума 120 ГБ, а индексная память достигает максимума около 60 ГБ.
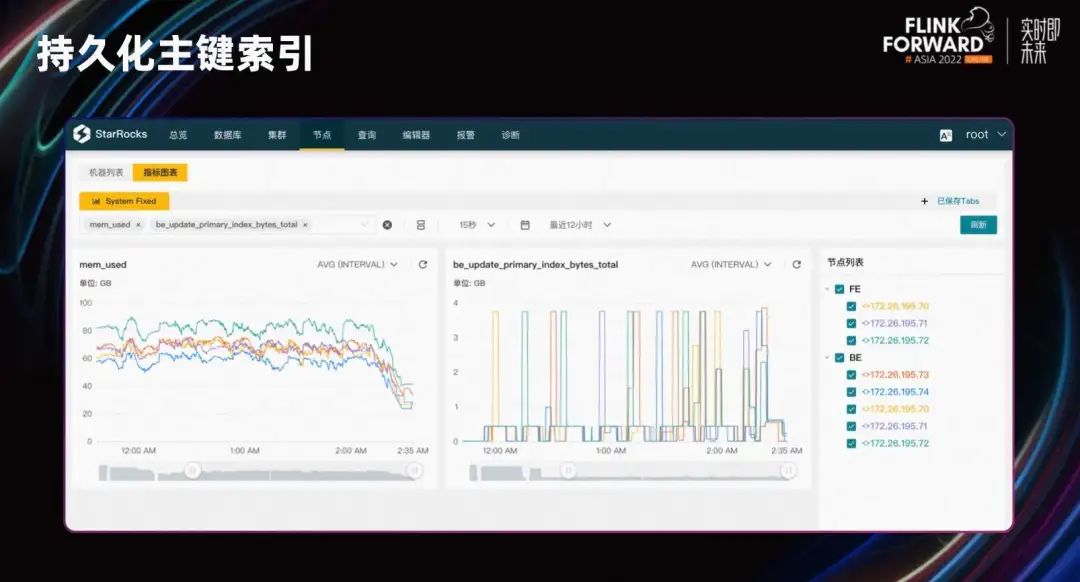
В режиме постоянного индекса, когда данные продолжают импортироваться, общий объем памяти достигает максимума 70-80 ГБ, а индексная память достигает максимума примерно 3-4 ГБ. Использование памяти падает очень значительно.
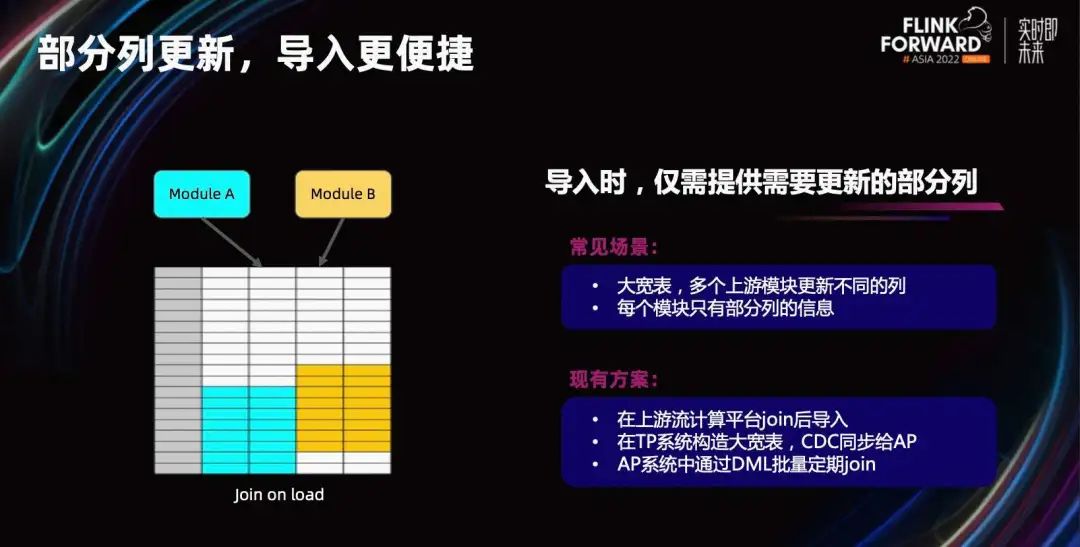
Еще одна функция — поддержка частичного обновления столбцов. На прошлогоднем саммите FFA я поделился методом replace_if_not_null, основанным на модели агрегации для реализации частичного обновления столбцов. Использование этого метода требует определенных затрат на разработку. Разработчикам необходимо собрать все индексы широкой таблицы, а нулевое значение необходимо явно заполнить в позициях, где нет данных.
Функция частичного обновления столбцов модели PK, обсуждаемая сегодня, будет иметь более низкие затраты на разработку. При доступе к данным вам нужно только указать соответствующие имена столбцов потока данных. Хотя SR очень хорошо работает в запросах к нескольким таблицам, в некоторых сценариях пользователи по-прежнему ожидают чрезвычайно высокой производительности, обеспечиваемой большими широкими таблицами.
В настоящее время, если вы хотите добиться такого эффекта, существует несколько распространенных решений.
1. Вставьте модуль или оператор соединения в восходящий поток данных, обычно используя платформу потоковых вычислений, такую как Flink. Используйте многопоточное объединение для формирования всей строки данных.
Если время поступления данных из нескольких восходящих потоков данных несовместимо, трудно спроектировать подходящее окно для расширения данных в механизме вычислений. Включение вычислений состояния, таких как MapState, слишком настраиваемо, и эффективность итерации является еще одной проблемой.
2. Используйте систему TP для создания широкой таблицы. Восходящий модуль записывает в систему TP методом частичного обновления столбца, а затем синхронизирует его с системой AP через систему TP. Для этого необходим дополнительный набор модулей ТП и модулей синхронизации.
3. Сначала импортируйте модули в систему AP. В системе AP соединение выполняется регулярно через DML, а большие и широкие таблицы периодически обновляются позже. Это приведет к некоторому снижению производительности в реальном времени.
Все эти три метода имеют определенную степень сложности. Если SR сможет напрямую поддерживать частичное обновление столбцов, это принесет новые идеи, которые могут хорошо решить эту проблему и упростить ссылку на многопотоковое соединение.
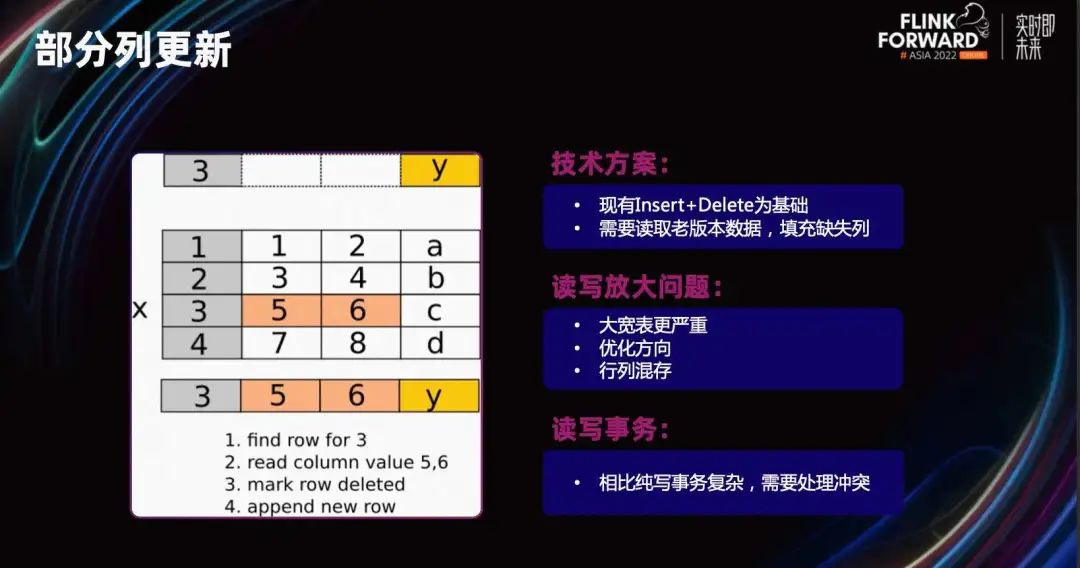
Начиная с версии 2.3 поддерживаются некоторые функции обновления столбцов. Метод реализации по-прежнему основан на существующем режиме «Вставка+Удалить». Процесс можно посмотреть на примере на рисунке. Я собираюсь изменить последний столбец значений c строки, где первый столбец равен 3, на y. Вам нужно сначала найти строку, в которой находится 3, затем вывести столбцы, не относящиеся к данному обновлению, пометить эту строку как Удалить, а затем добавить новую строку после обновления.
Остальные операции аналогичны исходной операции Full Row Upsert. Поскольку метод «Удалить+Вставить» используется для обновления частичных столбцов, проблема усиления чтения-записи фактически накладывает определенные ограничения на это использование, особенно когда в больших и широких таблицах обновляется только небольшое количество столбцов.
Например, если есть таблица с 10 000 столбцов, мы обновляем только один из них. Остальные 9000+ столбцов необходимо прочитать, прежде чем будут записаны все 10000 столбцов. Поэтому в настоящее время мы рекомендуем частичное обновление столбцов, которое следует использовать только в тех случаях, когда столбцов не слишком много (например, менее 500 столбцов), и пытаемся использовать эту функцию на твердотельных накопителях. Чтобы частично решить эту проблему, мы планируем позже ввести хранилище строк, что может решить часть проблемы усиления чтения.

Еще одна особенность — условные обновления. Во время импорта была добавлена условная функция, и обновления будут выполняться только при выполнении условий. Распространенные сценарии включают в себя неупорядоченность импортированных данных или нарушение порядка данных из-за параллелизма.
Чтобы предотвратить перезапись правильных данных неупорядоченными данными, обычно создается поле метки времени. Таким образом, вы можете указать условие при обновлении. Если временная метка больше текущего времени, операция обновления будет выполнена. В противном случае строка будет проигнорирована.

Если во время синхронизации Flink-CDC параллелизм задач очень высок, что приводит к большому количеству транзакций, мы добавили новый интерфейс импорта транзакций на основе Stream Load, который может объединять несколько задач импорта в одну транзакцию. Прежде чем запустится обычный приемник, запустите транзакцию. Затем данные записываются параллельно. Наконец, после того, как все задачи завершают передачу данных, транзакция отправляется целиком.
В приведенном выше примере общее количество транзакций уменьшено с 4 до 1. Узким местом высокочастотного импорта по существу является проблема большого количества транзакций. Уменьшив количество транзакций, можно улучшить возможность импорта в реальном времени.
03
StarRocks Connector For Apache Flink
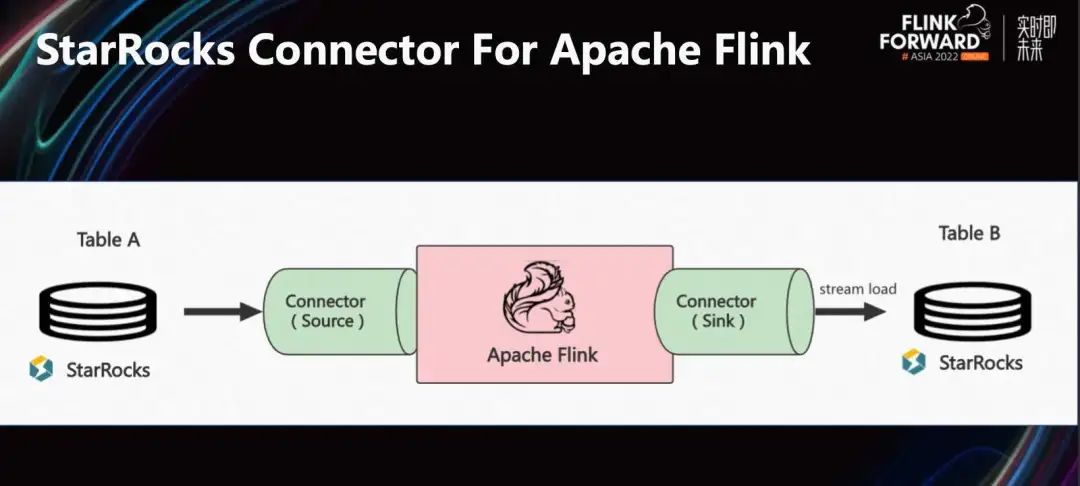
Далее давайте посмотрим, как StarRocks интегрируется с Flink через Connector. На рисунке выше показана общая ситуация с Flink Connector, предоставляемым Source Connector. Пользователи могут использовать таблицы StarRocks в качестве источников данных и использовать Flink для распределенного извлечения данных StarRocks. Его можно использовать для миграции данных между компьютерными залами или для дальнейшей сложной распределенной обработки на базе Flink.
Sink Connector в основном импортирует данные в память Flink через векторизованный интерфейс импорта StarRocks и эффективно импортирует потоковые данные в реальном времени в StarRocks.
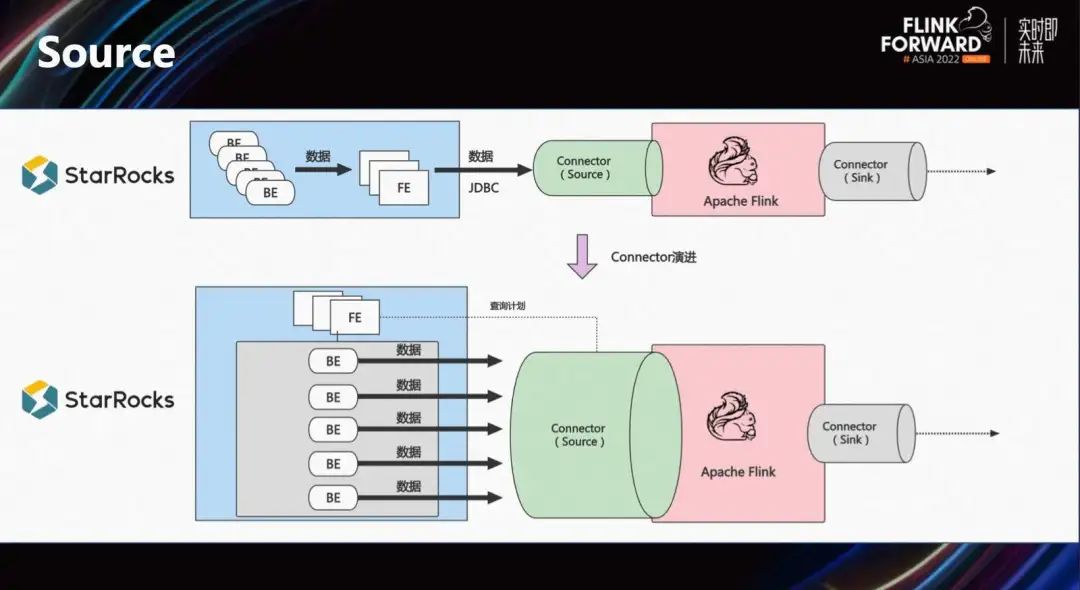
Раньше, чтобы внедрить Flink для чтения таблицы StarRocks, клиентам нужно было настроить свой собственный источник и читать данные в форме MySQL JDBC. Данные BE в конечном итоге нужно было извлечь из одной точки, что было неэффективно.
Source Connector, предоставляемый StarRocks, имеет распределенную структуру. Сначала найдите соответствующую информацию метаданных сегмента в FE, а затем извлеките данные непосредственно из уровня хранения распределенным образом, что значительно повышает общую пропускную способность.
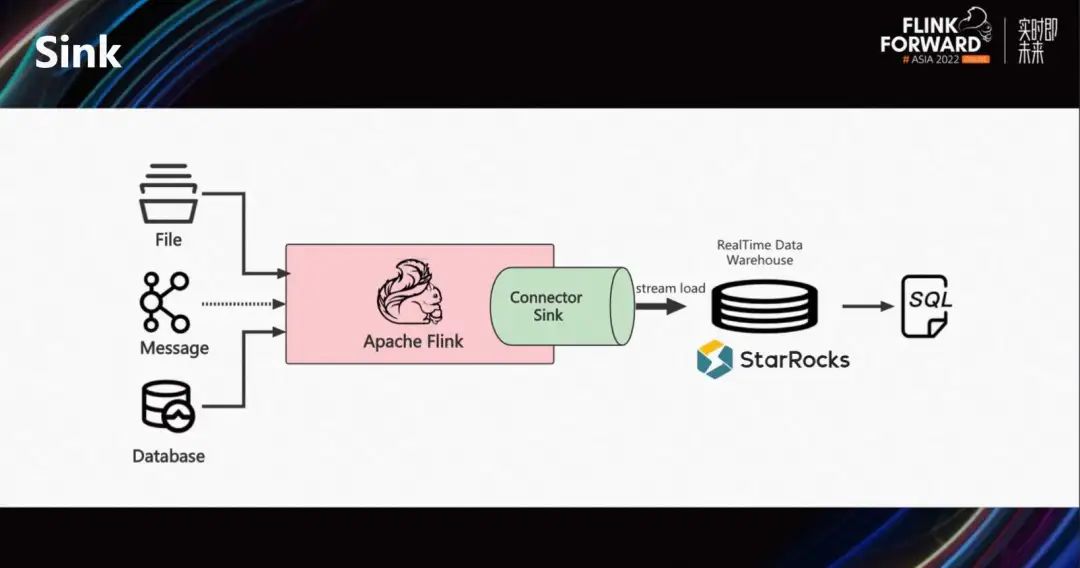
Sink Connector будет использоваться чаще, чем Source. Благодаря мощным интегрированным возможностям потоковой и пакетной обработки Flink он может обрабатывать потоковые сообщения, извлекать данные из баз данных TP и даже данные из хранилищ данных Hive. После обработки Flink он синхронизируется со StarRocks через Sink Connector и интерфейс Stream Load.

Вот пример частичного обновления столбца. Оказывается, есть запись «101, Том, 80». Теперь нам нужно добавить новые данные и обновить их. Цель состоит в том, чтобы превратить Тома из 101 в Лили. Мы видим, что для стороны интерфейса вам нужно только указать столбец идентификатора первичного ключа и столбец имени, который необходимо обновить, и импортировать его в форме обычного импорта данных.

Конфигурация в Flink-Connector также очень проста, и ее использование соответствует интерфейсу Stream Load. Вам нужно только включить частичное_обновление, а затем указать имя столбца данных.
04
Кейсы из практики клиентов
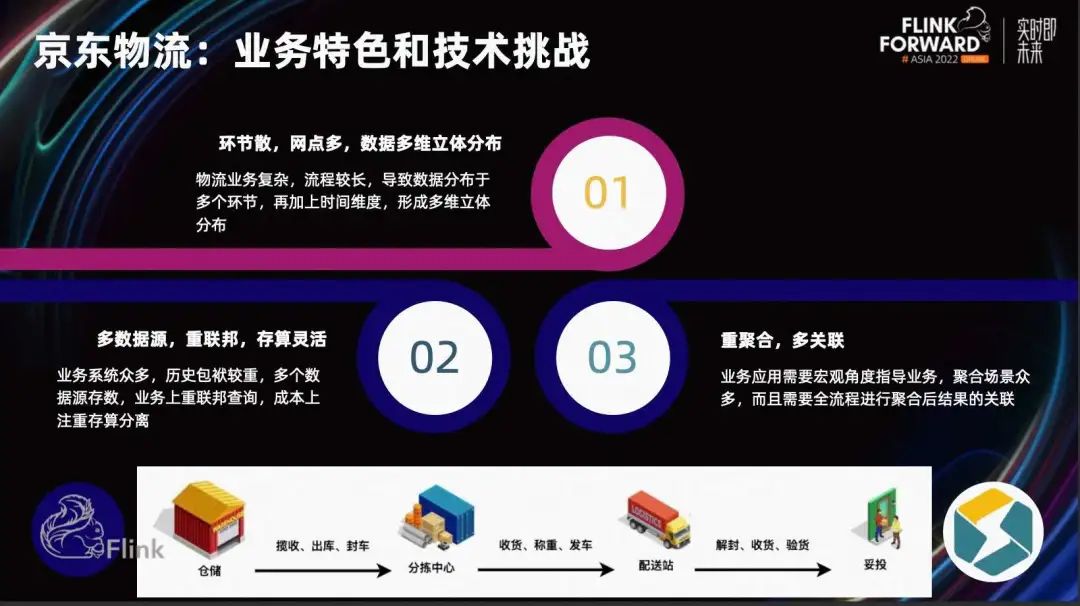
Далее поделитесь практическим примером. В основном о JD Logistics, использующей модель первичного ключа Flink и StarRocks для решения задач анализа и интеграции сервисов.
Во-первых, давайте посмотрим на характеристики данных JD Logistics и основные проблемы, с которыми она сталкивается. Как мы все знаем, после размещения заказа в приложении JD.com заказ переходит из торгового центра в логистический, от складирования к сортировке, от доставки к доставке и, наконец, к потребителю. В целом логистический бизнес сложен, а процесс длительный. Когда физическая упаковка транспортируется к месту логистики, данные проходят через множество связей, а также через некоторые отраслевые концепции логистических партий и некоторые дополнительные временные измерения. Общие связи данных сложны и демонстрируют характеристики многомерного трехмерного распределения.
Кроме того, процессы сложны и существует множество бизнес-систем. По историческим причинам эволюции существующих архитектур по-прежнему существует множество источников данных. Таким образом, архитектура данных JD Logistics больше полагается на возможности федеративных запросов.
На бизнес-уровне существует множество сводных показателей макроданных, которые помогают управлять производством. Агрегированные результаты необходимо сопоставить для создания единых показателей данных. Таким образом, агрегированные запросы и ассоциации с несколькими таблицами также являются функциями.
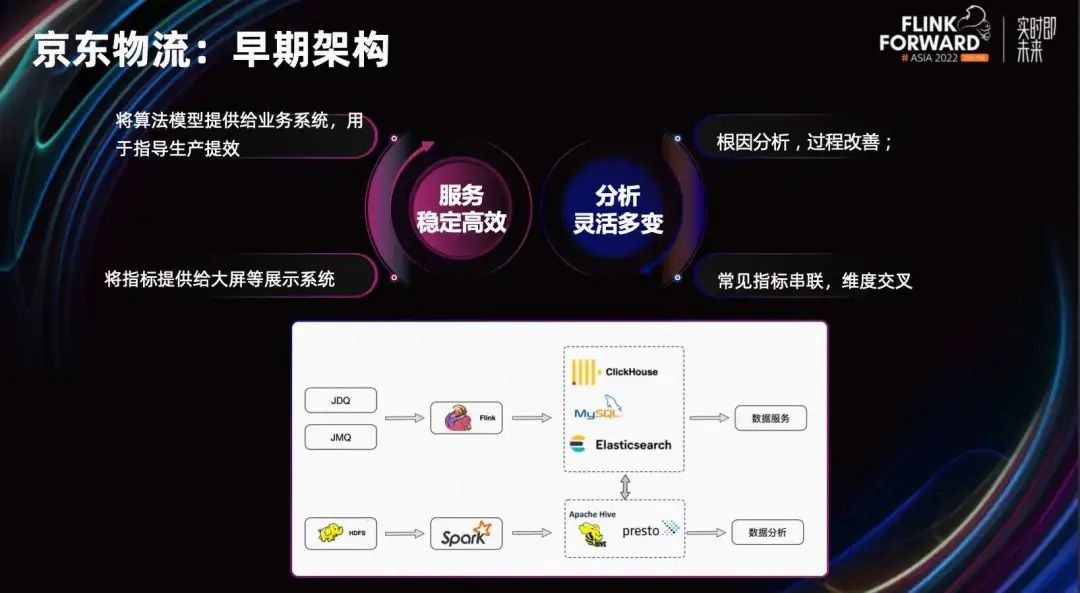
Мы можем взглянуть на раннюю структуру JD Logistics, которая разделена на каналы обслуживания данных и каналы анализа данных. Эти две линии по сути разделены.
Ссылка на службу данных использует Flink для получения данных из очереди сообщений и отправки их в некоторые продукты баз данных. В основном это ClickHouse, ES и MySQL, чтобы обеспечить стабильные и эффективные службы запросов к интерфейсу. В сценариях гибкого анализа не существует фиксированной модели, которая могла бы обрабатывать все запросы. Более сложный SQL может быть выполнен в форме Adhoc на основе Hive или Presto.

Общий анализ показывает, что ранняя архитектура имела некоторые проблемы.
- источники данных разнообразны,Затраты на техническое обслуживание относительно высоки.
- Недостаточная производительность,Большая задержка записи,В сценах крупных продаж будет отставание в данных.,Опыт интерактивных запросов плохой.
- Каждый источник данных фрагментирован.,Невозможно связать запрос,Формирование множества изолированных островов данных. Затем из угла,Каждый двигатель требует соответствующих затрат на обучение и разработку.,Сложность программы относительно высока.
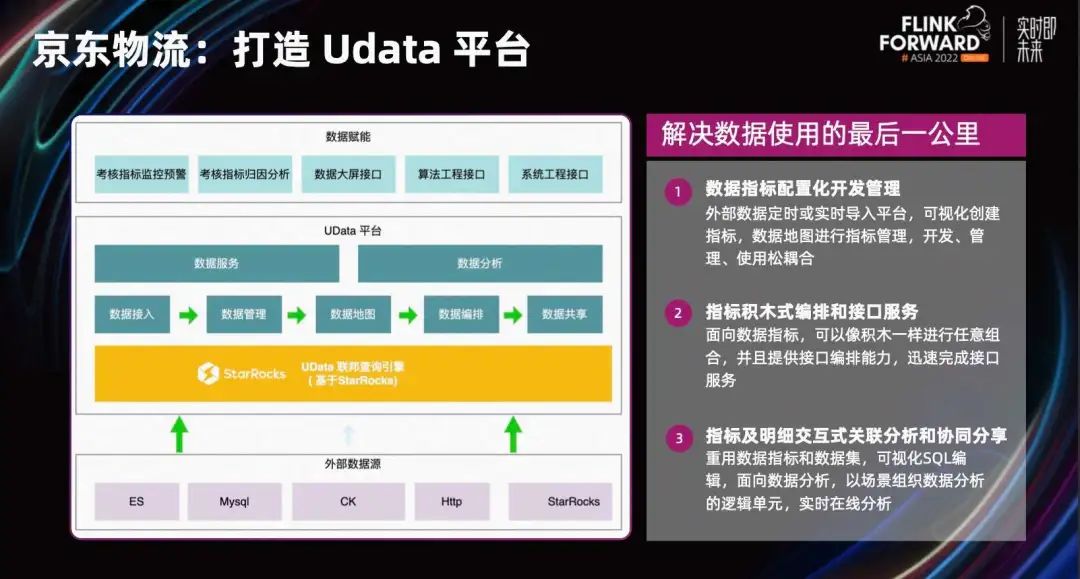
JD Logistics прошла весь процесс индустриализации больших данных с различными приложениями для обработки данных и разными способами использования данных. Поэтому были предприняты усилия по созданию платформы UData, которая служит мостом между активами данных и приложениями данных, образуя единый интерфейс данных в форме доступа к данным или ассоциации внешнего вида. Являясь основной базой платформы UData, StarRocks поддерживает два основных сценария:
1. Обеспечить стабильные и надежные модули обслуживания данных в виде интерфейсов.
2. Обеспечьте бизнес-персонала чрезвычайно быстрыми и гибкими модулями анализа. Позвольте предприятиям находить нужные им показатели данных в Интернете на карте показателей данных.
Он также предоставляет возможности на стороне платформы, такие как разработка конфигурации индикаторов, расположение строительных блоков индикаторов и визуальное редактирование SQL для решения проблемы использования данных на последней миле.
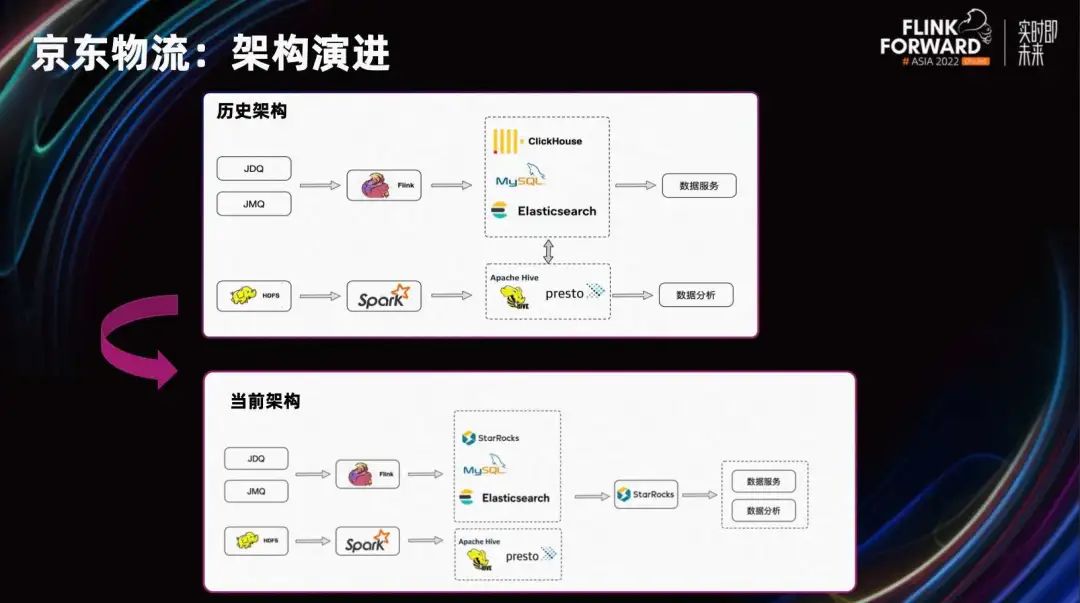
В этом году JD Logistics использовала StarRocks для замены ClickHouse в ссылках в реальном времени, чтобы решить проблему параллелизма запросов и ассоциации нескольких таблиц. Затем, перед ссылкой на сервис в реальном времени и ссылкой на анализ данных, StarRocks используется как единый вход для запроса данных для достижения интеграции анализа и услуг.

При этом JD Logistics также активно участвует в техническом со-строительстве сообщества StarRocks. Функции агрегирования внешнего вида и сортировки реализованы на основе существующей архитектуры. В некоторых ситуациях это может эффективно уменьшить пропускную способность сети и улучшить внешний вид интерфейса RPC и HTTP.
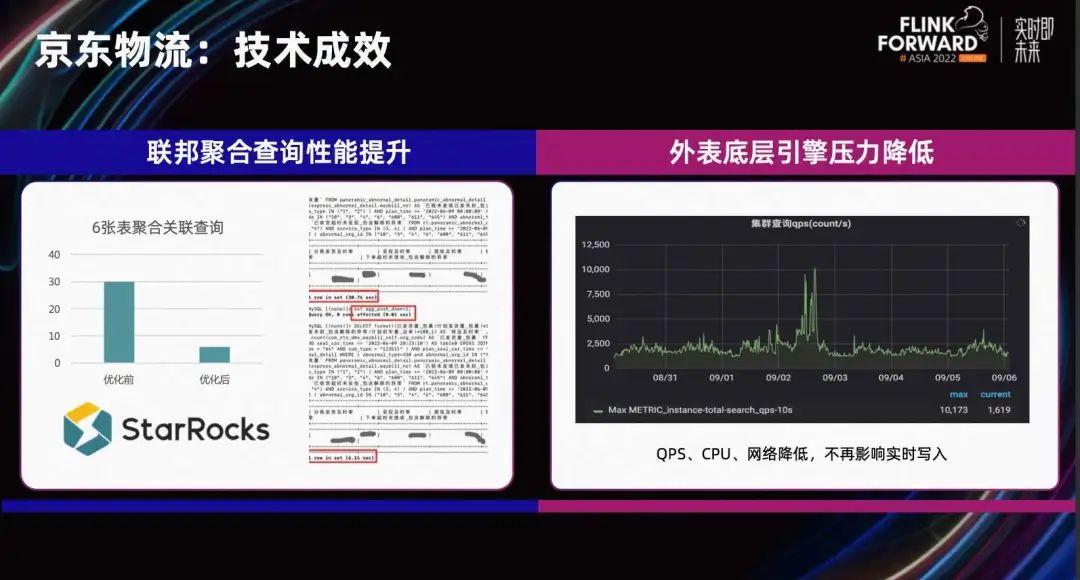
В некоторых сценариях включается функция агрегирования, и производительность агрегирующих запросов значительно повышается. Вот пример сложного SQL, связанного с 6 таблицами, который был оптимизирован с предыдущих 30 секунд до 6 секунд, а производительность улучшена в несколько раз. Из мониторинга справа вы также можете видеть, что функция push-down была включена на некоторое время в среднем тесте, и QPS значительно улучшился.
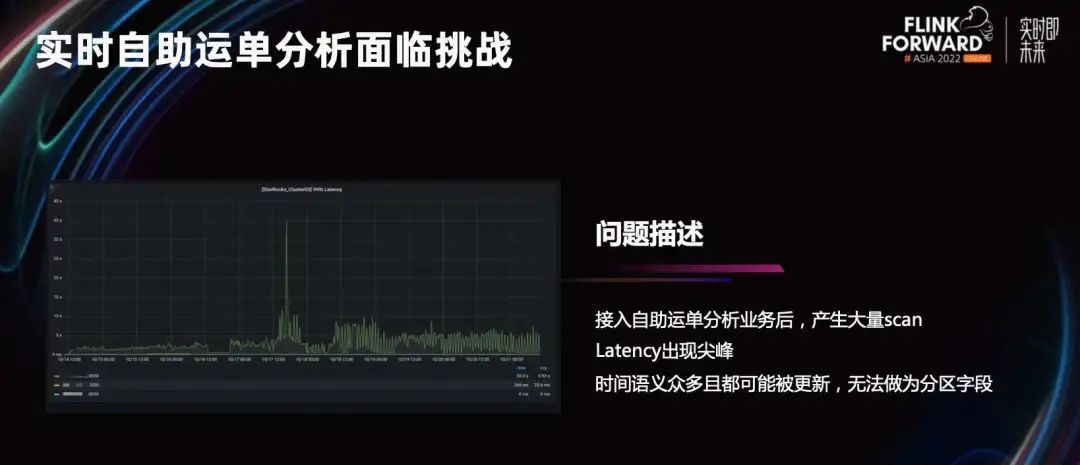
В этом году (2022 г. год) двойной 11,StarRocks Ношение накладной данных в режиме реального времении Запрос для анализа самообслуживания по сценарию. Эта сцена из QPS Он небольшой, но запрос очень гибкий и может выполнять произвольную фильтрацию и связанные с ним запросы на основе таблиц с сотнями столбцов. Еще одна особенность – в накладной есть несколько временных семантических полей. Например, время заказа, время доставки, время доставки и т. д., а также данные времени будут изменены, и не обязательно, какое поле используется для фильтрации при запросе. Это делает невозможным выбор разумного поля секционирования для секционирования, а секционирование невозможно обрезать во время запроса.
Как вы можете видеть на диаграмме мониторинга слева, в середине наблюдается очень большой скачок задержки. Это связано с тем, что этот SQL будет иметь большое количество сканирований, что приводит к высокой задержке запроса.
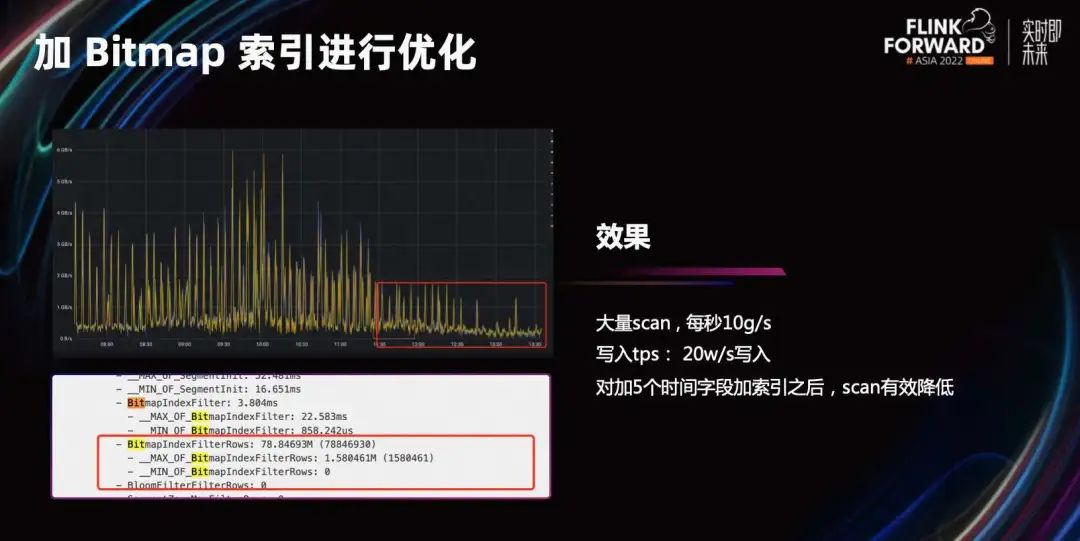
Чтобы решить эту проблему, мы проанализировали и обсудили этот особый сценарий с нашими однокурсниками из JD Logistics. Одним из решений является классификация и организация этих временных семантических полей. Затем разделите его на несколько таблиц для использования в соответствии с разной семантикой времени. Этот метод значительно улучшит эффект адаптации разделов, но стоимость разработки будет относительно высокой и потребует связи между вышестоящими и нижестоящими системами. Для такого крупного рекламного мероприятия, как Double 11, с ограниченным временем и тяжелыми задачами, сложно внести относительно большие структурные изменения.
Итак, мы попробовали решение, добавив индекс Bitmap в поле даты. Как показано на рисунке, после добавления индекса Scan эффективно уменьшается и проблема решается.
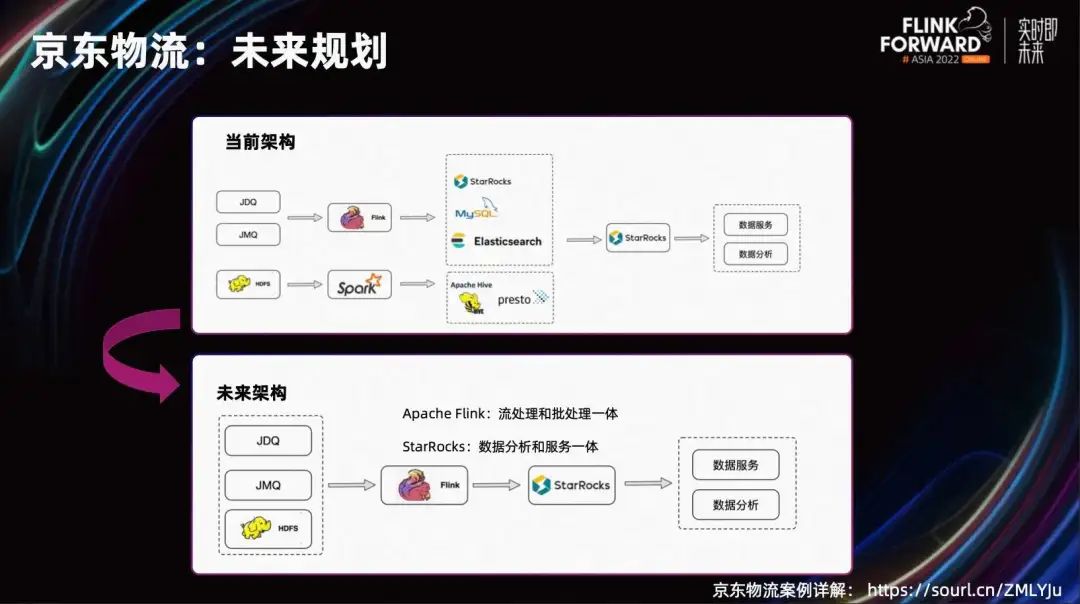
После успешного решения задачи продвижения Double 11 с помощью StarRocks компания JD Logistics разработала дальнейшие планы относительно своей будущей технологической архитектуры. На вычислительном уровне мы планируем оптимизировать вычислительный движок Spark для автономных каналов и использовать Flink для реализации интегрированной обработки потоков и пакетов. На уровне анализа ряд существующих компонентов анализа будет постепенно оптимизирован, а StarRocks будет использоваться в качестве единой базы, позволяющей анализу данных и службам данных объединяться на StarRocks.
05
планы на будущее

Далее давайте расскажем, какую дальнейшую работу StarRocks проделает в плане анализа данных в реальном времени.
С одной стороны, с точки зрения простоты использования он поддерживает разделение первичных ключей и ключей сортировки. В текущей модели первичного ключа ключ сортировки и первичный ключ можно считать унифицированными. Например, в примере справа первичным ключом является id. Если данные отсортированы по идентификатору, запросу фильтра города необходимо сканировать всю таблицу или добавить другие вторичные индексы, чтобы найти способы ускорить фильтрацию.
Если ключ сортировки и первичный ключ можно разделить, ключ сортировки и первичный могут использовать разные поля при создании таблицы. Например, id служит первичным ключом и отвечает за ограничение уникальности обновлений; City служит ключом сортировки и отвечает за порядок хранения данных. Это может ускорить некоторые распространенные запросы.
На самом деле, мы можем подумать об этом дальше. В настоящее время у StarRocks есть несколько моделей столов: дублирующиеся/агрегированные/уникальные. Клиентам необходимо делать выбор в различных ситуациях. Все они могут быть объединены в одно грамматическое выражение. После объединения пользователям будет легче понять только одну таблицу, что может еще больше повысить удобство использования.
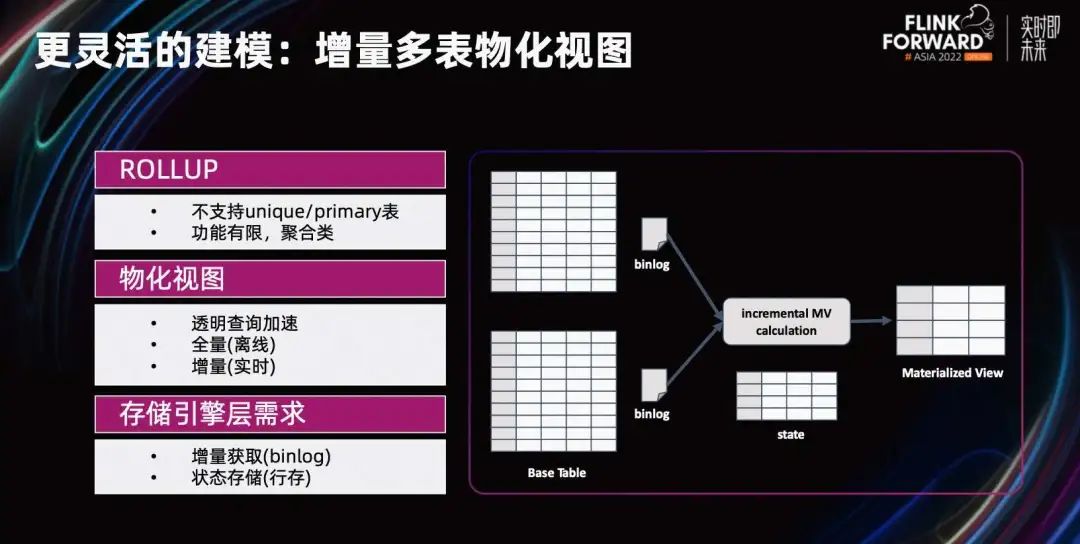
Еще одно важное направление. Материализованное представление с несколькими таблицами. В настоящее время модель первичного ключа не поддерживает ROLLUP и материализованные представления, а функция ROLLUP также относительно ограничена. Новое поколение архитектуры многотабличного материализованного представления StarRocks будет поддерживать более продвинутые функции, включая прозрачное ускорение запросов, автономное полное построение и инкрементное построение в реальном времени; оно может писать более сложные выражения, ассоциации с несколькими таблицами, вложенность подзапросов и т. д. и т. д.; .; автоматически завершает материализацию асинхронно или синхронно с семантикой, аналогичной вставке в перезапись.
Построение дополнительных материализованных представлений требует возможности предоставлять данные постепенного изменения таблицы. Мы реализуем внутренний механизм, подобный бинарному журналу, чтобы помочь в задаче поэтапной материализации нескольких таблиц в реальном времени.
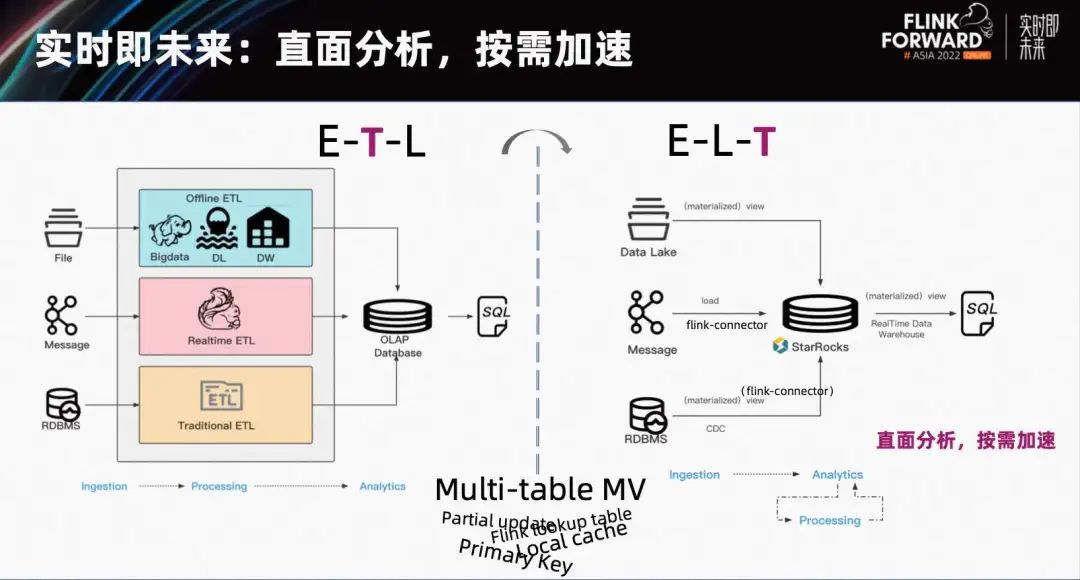
Благодаря инкрементному материализованному представлению с несколькими таблицами модель первичного ключа проще в использовании и имеет более высокую производительность, а также обеспечивает частичное обновление столбцов, ускорение LocalCache и другие преимущества функций. Анализ данных в реальном времени может открыть новую парадигму в будущем. Людям больше не нужно проектировать очень сложную архитектуру ETL, поддерживать так много периферийных программ, выполнять много неэффективной работы по передаче данных, потреблять много человеческих и материальных ресурсов, а ритм доставки никогда не поспевает за скоростью новых требований. .
В будущем вы сможете использовать Flink для непрерывной и стабильной загрузки данных в реальном времени из очереди сообщений или CDC TP в StarRocks за считанные секунды. В StarRocks перейдите непосредственно к анализу и разработайте наши индикаторы и модели. Будь то внешняя форма, логическое представление или CTE, их можно разработать быстро и итеративно, самым гибким способом. После разработки логики SQL в сочетании со сценарием, какие индикаторы требуют сервисов с высоким уровнем параллелизма и низкой задержкой? Какие уровни должны часто многократно вызываться другими нижестоящими уровнями? Будь то широкая таблица или сложный SQL, связанный с несколькими таблицами, мы можем свернуть или построить материализацию по мере необходимости. Непосредственный анализ данных и ускорение по требованию, что делает каналы анализа данных более экономичными и эффективными.
Реальное время — это будущее, и StarRocks постепенно реализует такие возможности. Объединение StarRocks и Flink для создания совместного решения для систем анализа данных в реальном времени в определенной степени устранит некоторые существующие ограничения и сформирует новую парадигму. анализ данных в реальном времени.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
