Практическое занятие | Кластеризация и визуализация временных рядов с помощью TSLearn
#TSer#
Кластеризация временных рядов очень распространена в промышленном производстве и жизни. От анализа неявных корреляций в массивных кривых KPI в промышленной эксплуатации и техническом обслуживании до классификации моделей роста на кривых доходности акций — методы кластеризации временных рядов помогают нам обнаружить некоторые из них. скрытая и глубокая информация в выборках данных.
TSLearn — популярный пакет Python, предоставляющий инструменты машинного обучения для анализа временных рядов. Пакет основан на библиотеках scikit-learn, numpy и scipy, что делает запуск и запуск встроенного алгоритма кластеризации очень простым и понятным.
В этой статье будет показан процесс использования TSLearn для кластеризации и визуализации временных рядов.
Адрес проекта: https://github.com/tslearn-team/tslearn
Сначала импортируем необходимые нам зависимости:
import pandas as pd
import numpy as np
from tslearn.preprocessing import TimeSeriesScalerMeanVarianceЗатем используйте Pandas для извлечения некоторых данных временных рядов. Среди них графики — широко используемая функция рисования. Определив входные данные, мы можем легко нарисовать изображение временного ряда. Теперь приступаем к определению параметров кластеризации:
n_clusters = 50 # number of clusters to fit
smooth_n = 15 # n observations to smooth over
model = 'kmeans' # one of ['kmeans','kshape','kernelkmeans','dtw']Далее полученные данные подвергаются некоторой стандартной обработке:
if n_charts:
charts = np.random.choice(get_chart_list(host), n_charts).tolist()
print(charts)
else:
charts = get_chart_list(host)
# get data
df = get_data(host, charts, after=-n, before=0)
if smooth_n > 0:
if smooth_func == 'mean':
df = df.rolling(smooth_n).mean().dropna(how='all')
elif smooth_func == 'max':
df = df.rolling(smooth_n).max().dropna(how='all')
elif smooth_func == 'min':
df = df.rolling(smooth_n).min().dropna(how='all')
elif smooth_func == 'sum':
df = df.rolling(smooth_n).sum().dropna(how='all')
else:
df = df.rolling(smooth_n).mean().dropna(how='all')
print(df.shape)
df.head()Затем мы можем использовать tslearn для построения нашей модели кластеризации:
if model == 'kshape':
model = KShape(n_clusters=n_clusters, max_iter=10, n_init=2).fit(X)
elif model == 'kmeans':
model = TimeSeriesKMeans(n_clusters=n_clusters, max_iter=10, n_init=2).fit(X)После того, как у нас есть кластерный кластер, мы можем сначала подготовить некоторые вспомогательные объекты для дальнейшего использования в рисовании:
cluster_metrics_dict = df_cluster.groupby(['cluster'])['metric'].apply(lambda x: [x for x in x]).to_dict()
cluster_len_dict = df_cluster['cluster'].value_counts().to_dict()
clusters_final.sort()
df_cluster.head()Наконец, давайте построим график каждой группы кластеров отдельно и посмотрим, каковы результаты:
for cluster_number in clusters_final:
x_corr = df[cluster_metrics_dict[cluster_number]].corr().abs().values
plot_lines(df, cols=cluster_metrics_dict[cluster_number], renderer='colab', theme=None, title=plot_title)Вот несколько замечательных примеров:
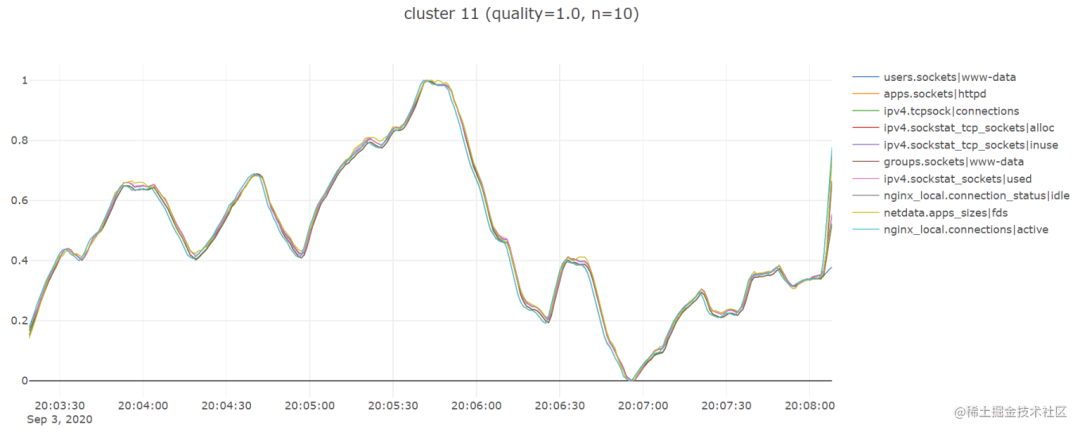
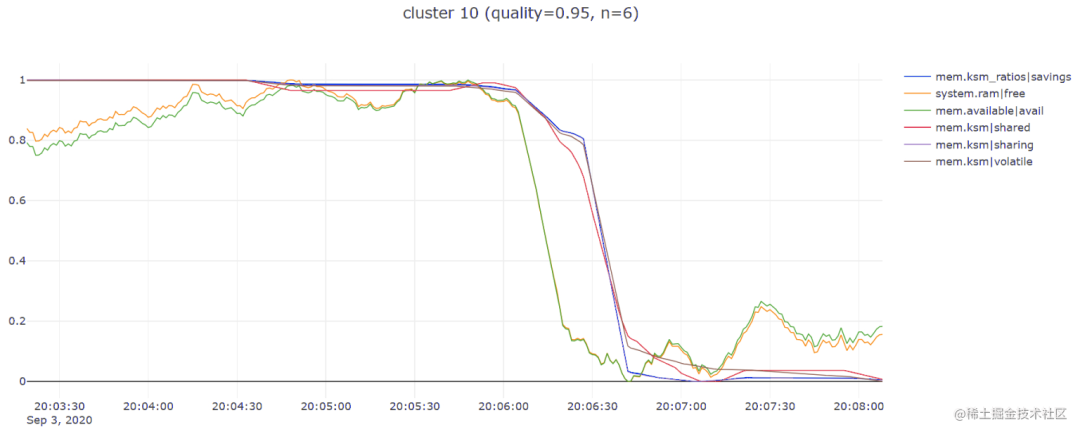
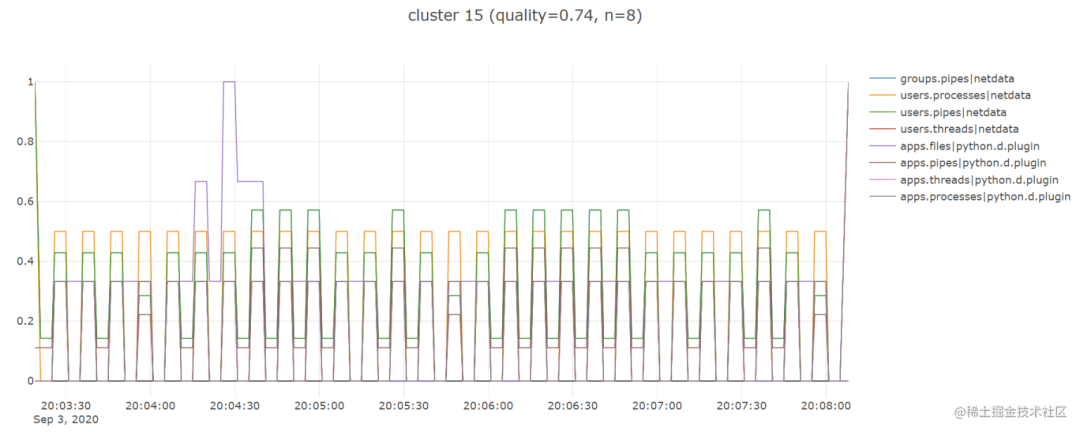
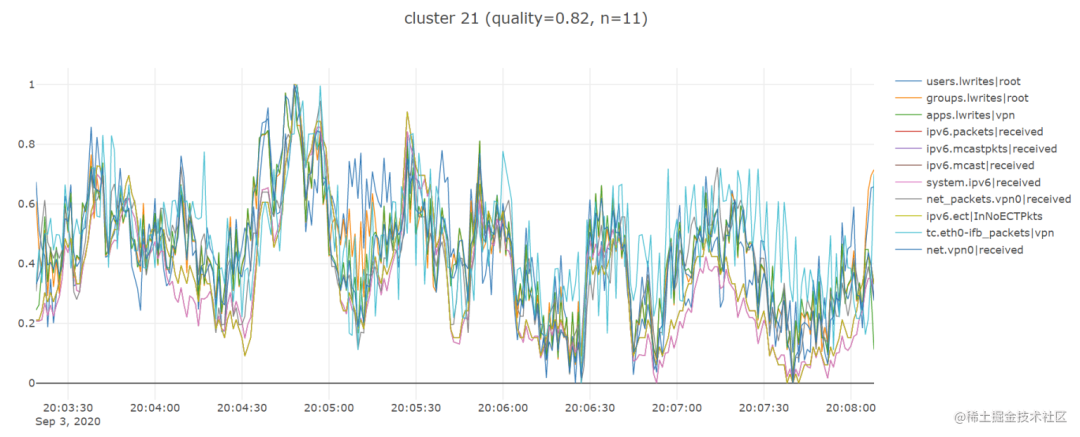
Выполнив описанные выше шаги, я обнаружил, что библиотека tslearn очень полезна, поскольку она сэкономила мне много времени и позволила мне быстро запустить рабочий прототип, поэтому я с нетерпением жду возможности использовать некоторые другие временные ряды. соответствующие функциональные возможности, которые он предоставляет.
Эта статья составлена с https://tecdat.cn/?p=33484.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
