Практическое API Flink Java потребляет данные Kafka в реальном времени и записывает их в HDFS.
1 Анализ требований
В API Java используйте локальный режим flink для использования тем Kafka и сохранения данных непосредственно в hdfs.
флинк версия 1.13
Кафка версия 0.8
Хадуп версии 3.1.4
2 Экспериментальный процесс
2.1 Запуск сервисной программы
Чтобы выполнить требование Flink по получению данных из Kafka и записи их в HDFS в реальном времени, обычно необходимо запустить следующие компоненты:
[root@hadoop10 ~]# jps
3073 SecondaryNameNode
2851 DataNode
2708 NameNode
12854 Jps
1975 StandaloneSessionClusterEntrypoint
2391 QuorumPeerMain
2265 TaskManagerRunner
9882 ConsoleProducer
9035 Kafka
3517 NodeManager
3375 ResourceManagerУбедитесь, что Zookeeper запущен, поскольку Kafka Consumer от Flink зависит от Zookeeper.
Убедитесь, что сервер Kafka работает, поскольку Kafka Consumer Flink должен подключиться к Kafka Broker.
Запустите JobManager и TaskManager Flink, которые являются основными компонентами для выполнения задач Flink.
Убедитесь, что эти компоненты работают, чтобы задание Flink могло правильно использовать данные из Kafka и записывать их в HDFS.
- Конкретная команда запуска здесь не описывается.
2.2 Запуск производства Кафки
- В настоящее время kafka не работает в фоновом режиме демона;
- Создайте тему, запустите создателя темы и выполните его в каталоге bin kafka;
- данные могут быть получены в это время,В этом окне введите любые данные для отправки.
kafka-topics.sh --zookeeper hadoop10:2181 --create --topic topic1 --partitions 1 --replication-factor 1
kafka-console-producer.sh --broker-list hadoop10:9092 --topic topic1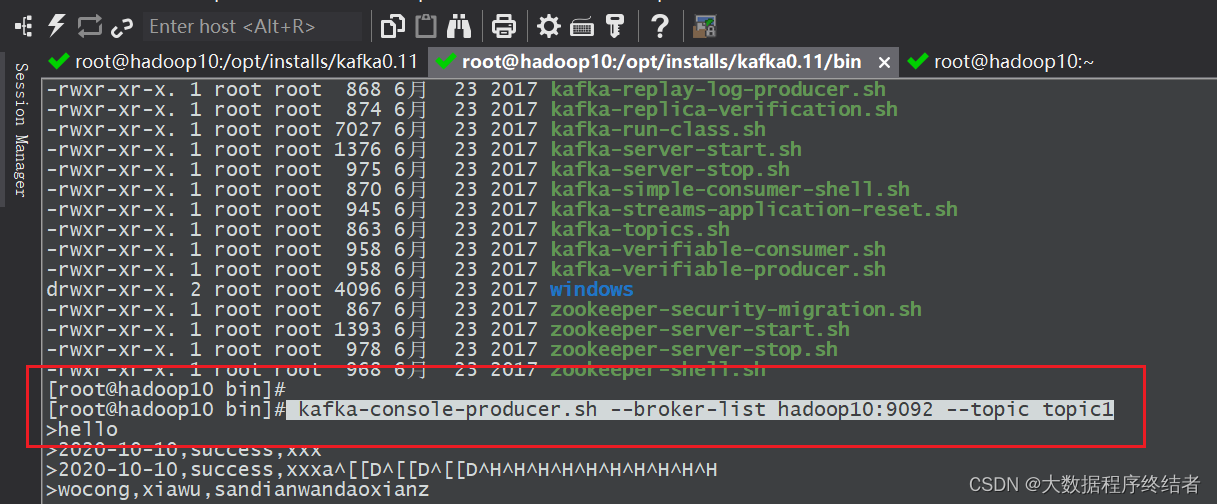
3 Разработка Java API
3.1 Зависимости
Это все зависимости проекта, включая flink, spark, hbase, ck и т. д. Фактические требования не требуют всех зависимостей, и их можно загрузить с зеркальных станций с открытым исходным кодом Alibaba Cloud или Maven.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>flink-test</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<flink.version>1.13.6</flink.version>
<hbase.version>2.4.0</hbase.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!--<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.14.6</version>
</dependency>-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-2-uber</artifactId>
<version>2.7.5-10.0</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
<exclusions>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
<exclusion>
<artifactId>log4j</artifactId>
<groupId>log4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>${hbase.version}</version>
<exclusions>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.4.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.32</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hbase-2.2_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.20</version>
</dependency>
</dependencies>
<build>
<extensions>
<extension>
<groupId>org.apache.maven.wagon</groupId>
<artifactId>wagon-ssh</artifactId>
<version>2.8</version>
</extension>
</extensions>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>wagon-maven-plugin</artifactId>
<version>1.0</version>
<configuration>
<!--загрузитьизместныйjarиз Расположение-->
<fromFile>target/${project.build.finalName}.jar</fromFile>
<!--удаленная копияизадрес-->
<url>scp://root:root@hadoop10:/opt/app</url>
</configuration>
</plugin>
</plugins>
</build>
</project>- Ссылка на зависимости
3.2 Часть кода
- Обратите внимание, что адрес сервера и сопоставление доменных имен необходимо настроить для kafka и hdfs.
- этот кодиз Функция - потребление
topic1тема,Запишите данные непосредственно в hdf.
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class Test9_kafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "hadoop10:9092");
properties.setProperty("group.id", "test");
// Использование FlinkKafkaConsumer в качестве источника данных
DataStream<String> ds1 = env.addSource(new FlinkKafkaConsumer<>("topic1", new SimpleStringSchema(), properties));
String outputPath = "hdfs://hadoop10:8020/out240102";
// Запись данных в HDFS с помощью StreamingFileSink
StreamingFileSink<String> sink = StreamingFileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.build();
// Добавьте приемник для записи данных Kafka непосредственно в HDFS.
ds1.addSink(sink);
ds1.print();
env.execute("Flink Kafka HDFS");
}
}4 Экспериментальная проверка
STEP1
Запустите код идеи, программа начнет выполняться, а консоль пуста, за исключением журнала. На рисунке ниже показан скриншот пользовательской консоли после получения данных от производителя.
STEP2
Запустите продюсер и напишите данные. Данные не имеют ограничений по формату и могут быть заполнены как угодно. Данные, отправленные в это время, можно распечатать на экране консоли на ШАГЕ 1.
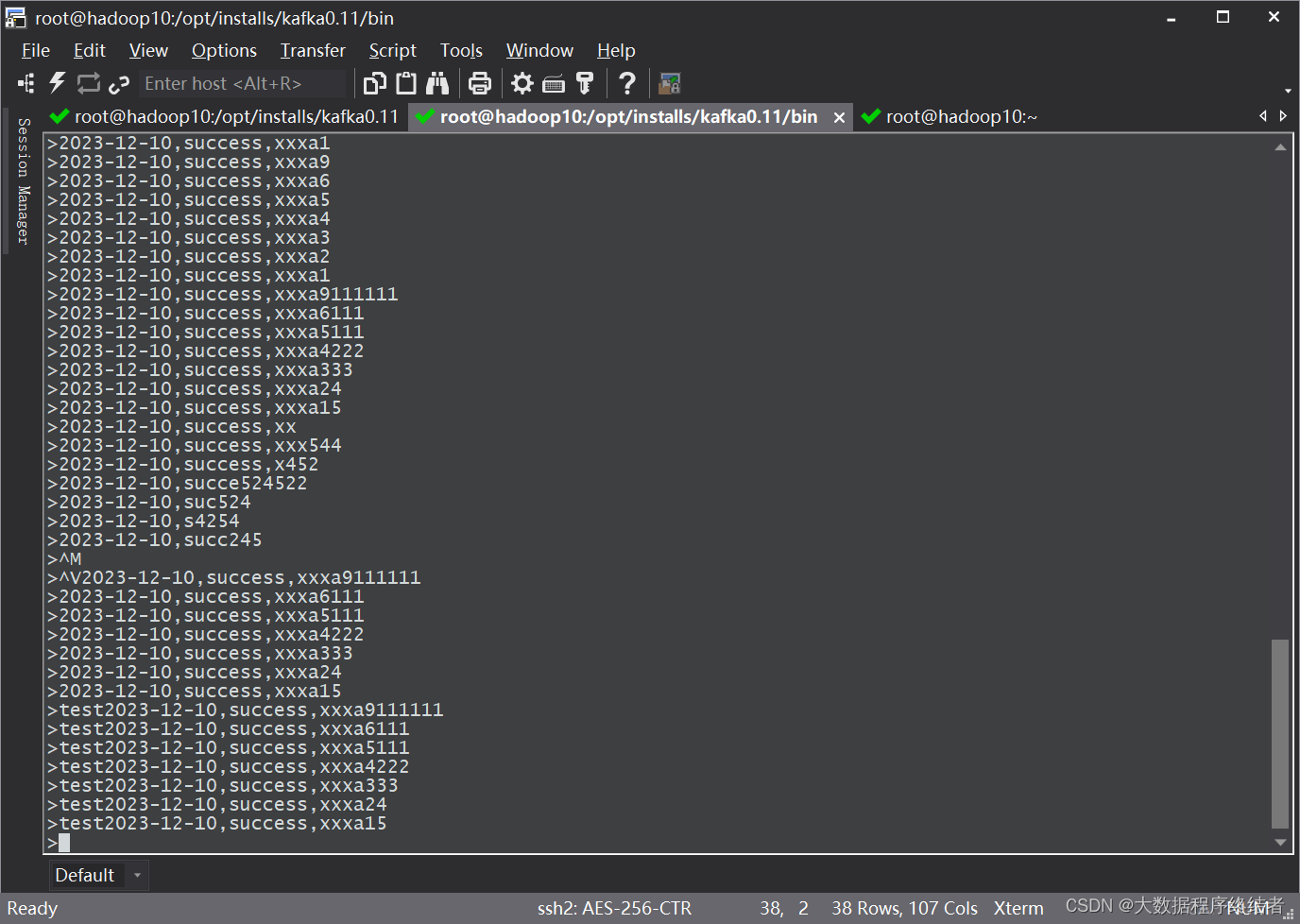
STEP3
Проверьте соответствующий каталог в HDFS, и вы увидите, что данные записаны. Я создал здесь несколько незавершенных файлов, потому что несколько раз тестировал их и несколько раз запускал неработающий код. После того как IDE распечатается на экране, он записывается на HDFS диск. Проходит определенный период времени и нужно подождать. После обновления данных в HDFS можно увидеть процесс изменения размера файла от 0 до . записываемые данные.
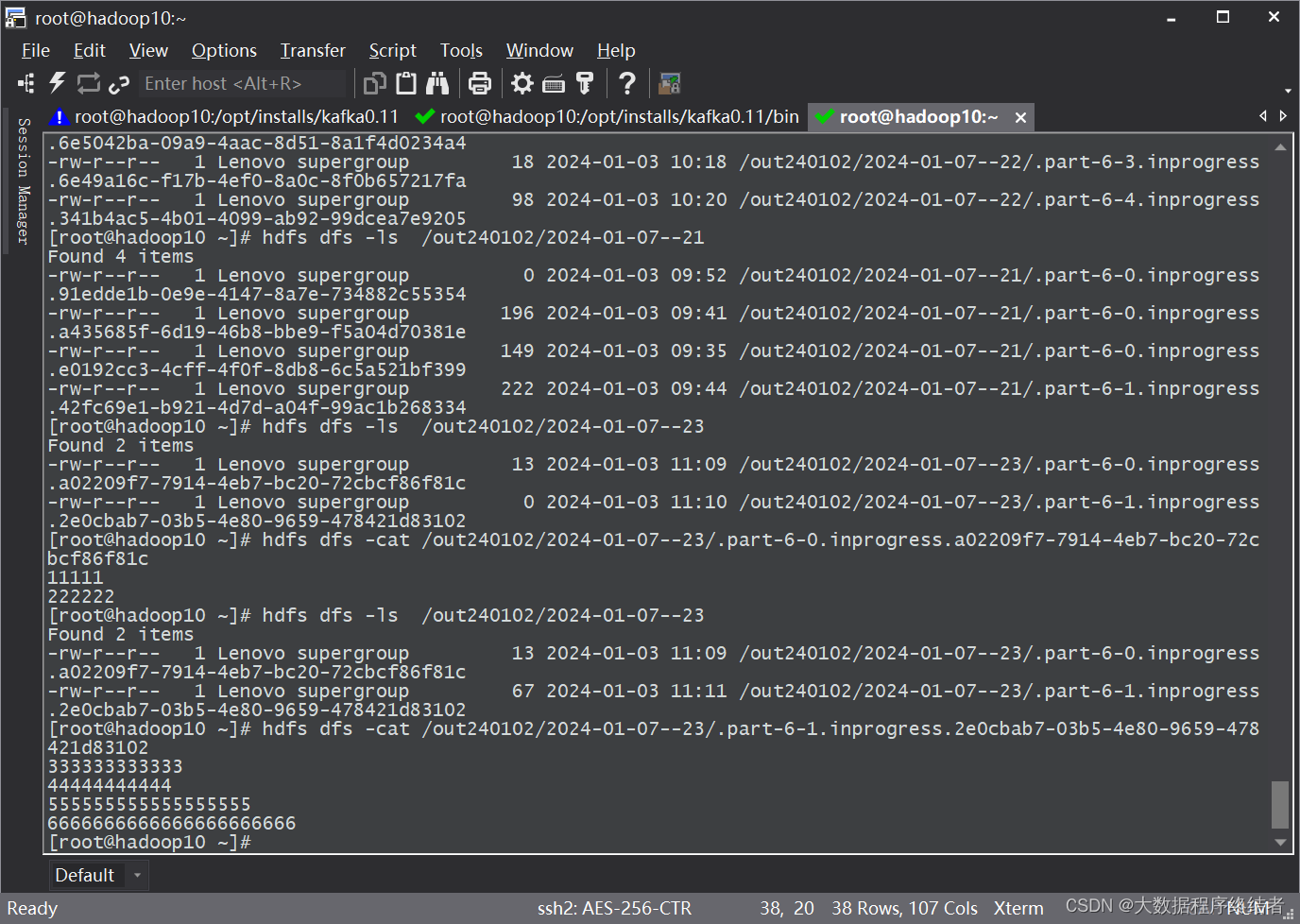
5 временных окон
- Используйте другую идею для достижения, чтобы временное из формы окна записывайте данные в HDFS в режиме реального времени, экспериментальный метод такой же, как указано выше. На снимке экрана показано потребление данных и просмотр данных в HDFS.
package day2;
import day2.CustomProcessFunction;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class Test9_kafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "hadoop10:9092");
properties.setProperty("group.id", "test");
// Использование FlinkKafkaConsumer в качестве источника данных
DataStream<String> ds1 = env.addSource(new FlinkKafkaConsumer<>("topic1", new SimpleStringSchema(), properties));
String outputPath = "hdfs://hadoop10:8020/out240102";
// Запись данных в HDFS с помощью StreamingFileSink
StreamingFileSink<String> sink = StreamingFileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.build();
// во временное окно НайсоданныеписатьHDFS ds1.process(new CustomProcessFunction()) // Использовать пользовательские ProcessFunction
.addSink(sink);
// Выполнить программу
env.execute("Flink Kafka HDFS");
}
}package day2;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
public class CustomProcessFunction extends ProcessFunction<String, String> {
@Override
public void processElement(String value, Context ctx, Collector<String> out) throws Exception {
// Здесь вы можете добавить конкретную логику, например запись данных в HDFS.
System.out.println(value); // Распечатать результаты на экране
out.collect(value);
}
}


Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
