Практический пример проекта краулера Python — пакетная загрузка музыкальных чартов NetEase Cloud и сохранение их локально.
Проект сканера Python, практическая пакетная загрузка музыки с диаграмм NetEase Cloud
запросить установку модуля скачать
установка выигрышной платформы
Платформа Win: cmd «Запуск от имени администратора», выполнение запросов на установку pip
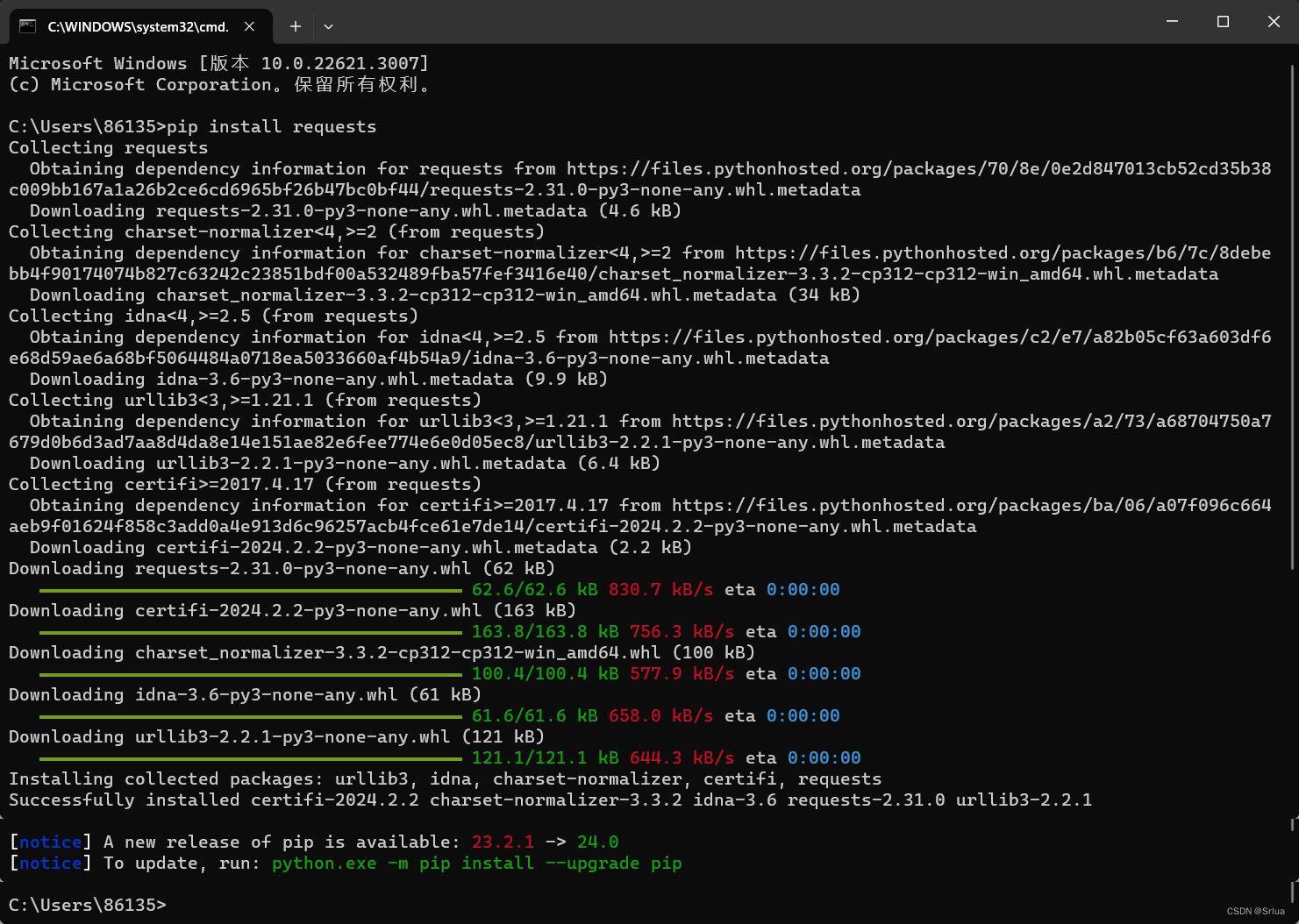
Как проверить, прошла ли установка успешно?
На приведенном выше снимке экрана появится надпись «Успешно установлено...», что означает, что установка прошла успешно.
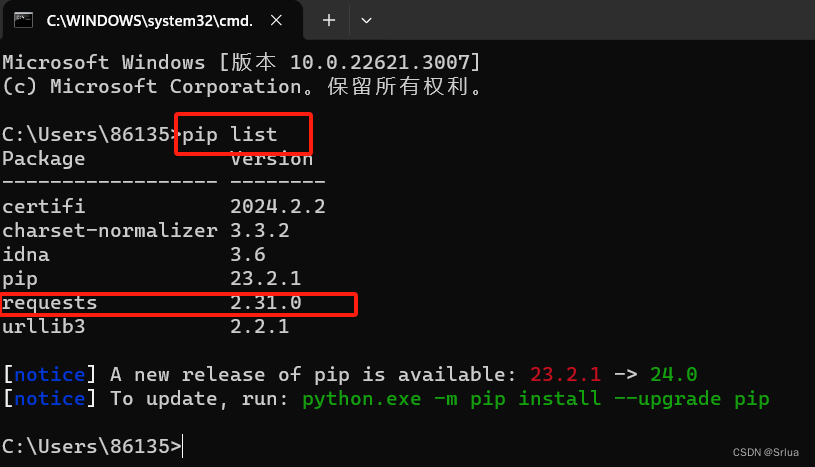
Вы также можете использовать платформу Win: cmd «Запуск от имени администратора», выполните pip list и увидите следующий снимок экрана, показывающий запросы, что означает, что установка прошла успешно.
Установка в pycharm
Если это не сработает, вы также можете установить пакеты запроса на установку с помощью подсказок в pycharm.

Сначала мы заходим на официальный сайт NetEase Cloud Music и выбираем список музыки для сканирования.
Здесь блоггер выбирает список горячих песен
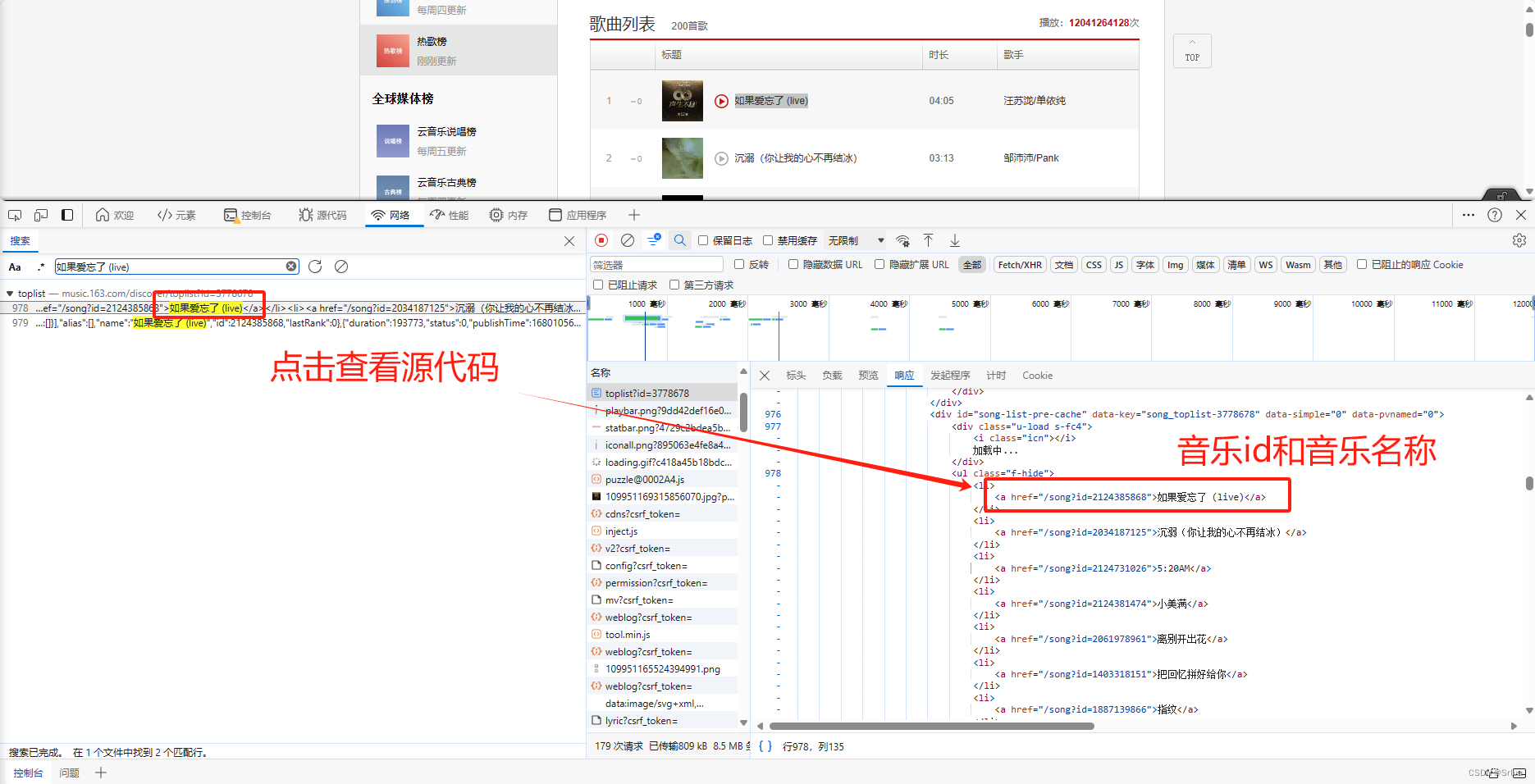
Если мы хотим сканировать эти песни, нам нужно получить название музыки и ее музыкальный идентификатор.
Щелкните правой кнопкой мыши веб-страницу и выберите «Проверить», чтобы войти в режим разработчика, или войдите в него, нажав F12 на клавиатуре.
Затем мы нажимаем +r, чтобы обновить страницу.
Выберите заголовки, чтобы получить содержимое URL-адреса запроса.
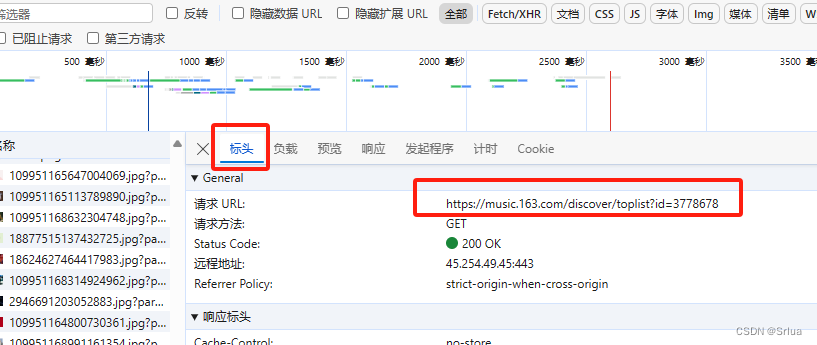

Скопируйте User-Agent: в заголовке запроса в заголовок
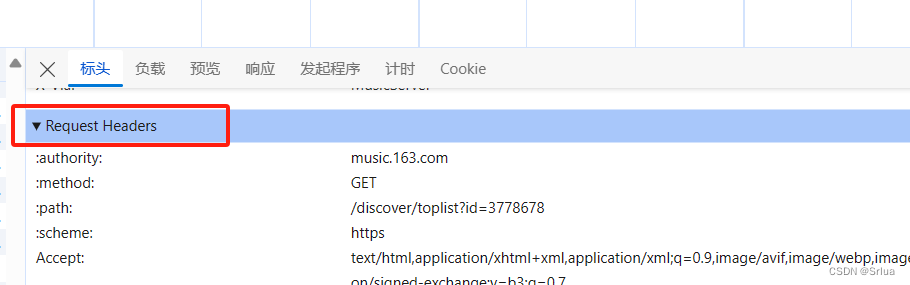
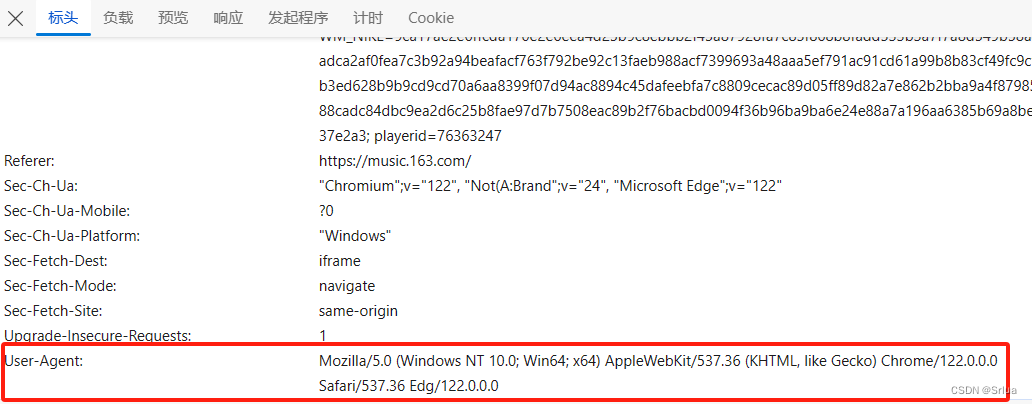
Пользовательский агент: это основная информация нашего браузера.

Успешно просканирован исходный код NetEase Cloud.
использоватьPythonвrequestsбиблиотека отправляетGETпросить,И получите исходный код веб-страницы по указанному URL.
response = requests.get(url=url, headers=headers)
print(response.text) получает исходный код веб-страницы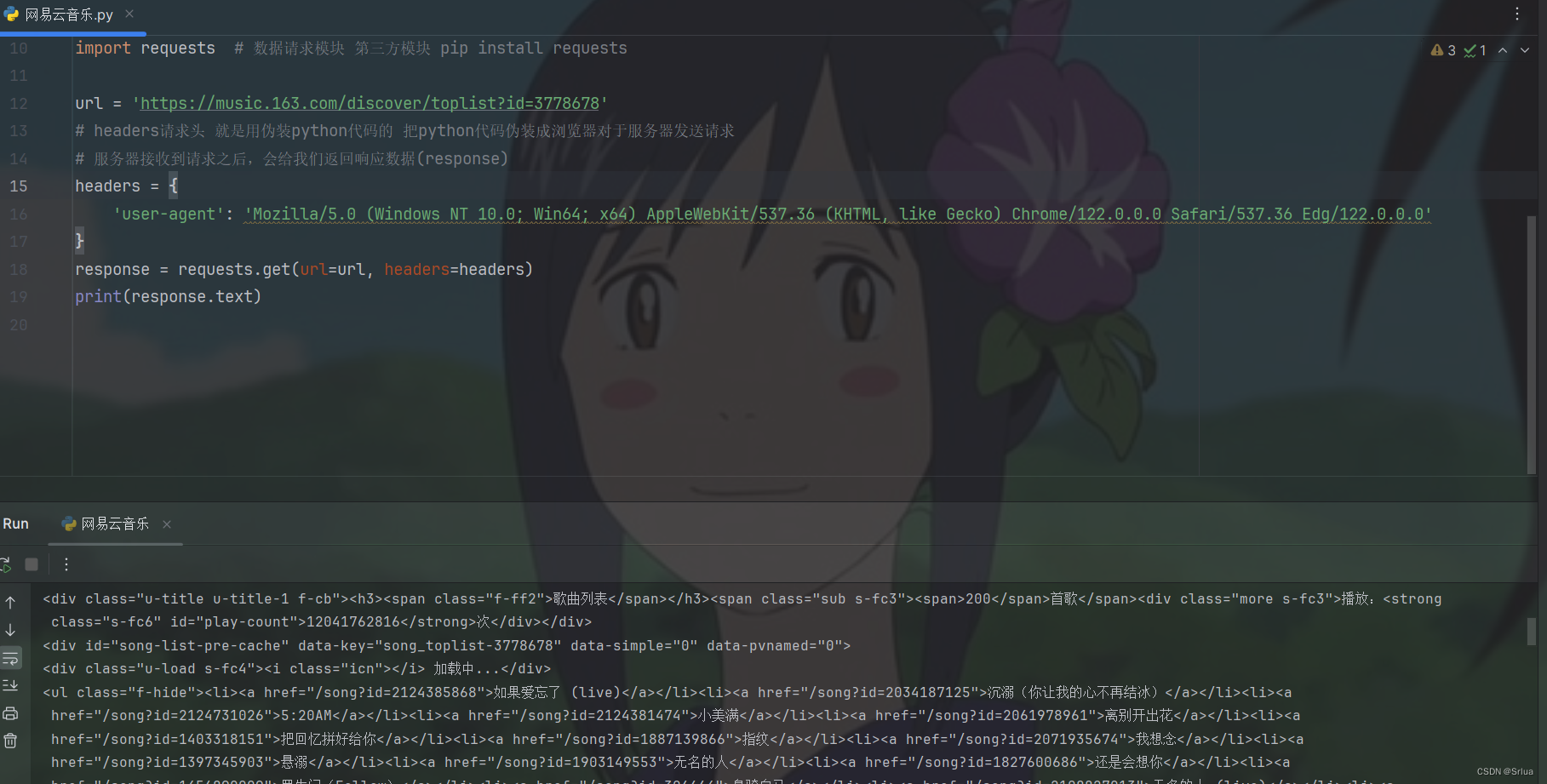
Просмотр содержимого консоли поиска
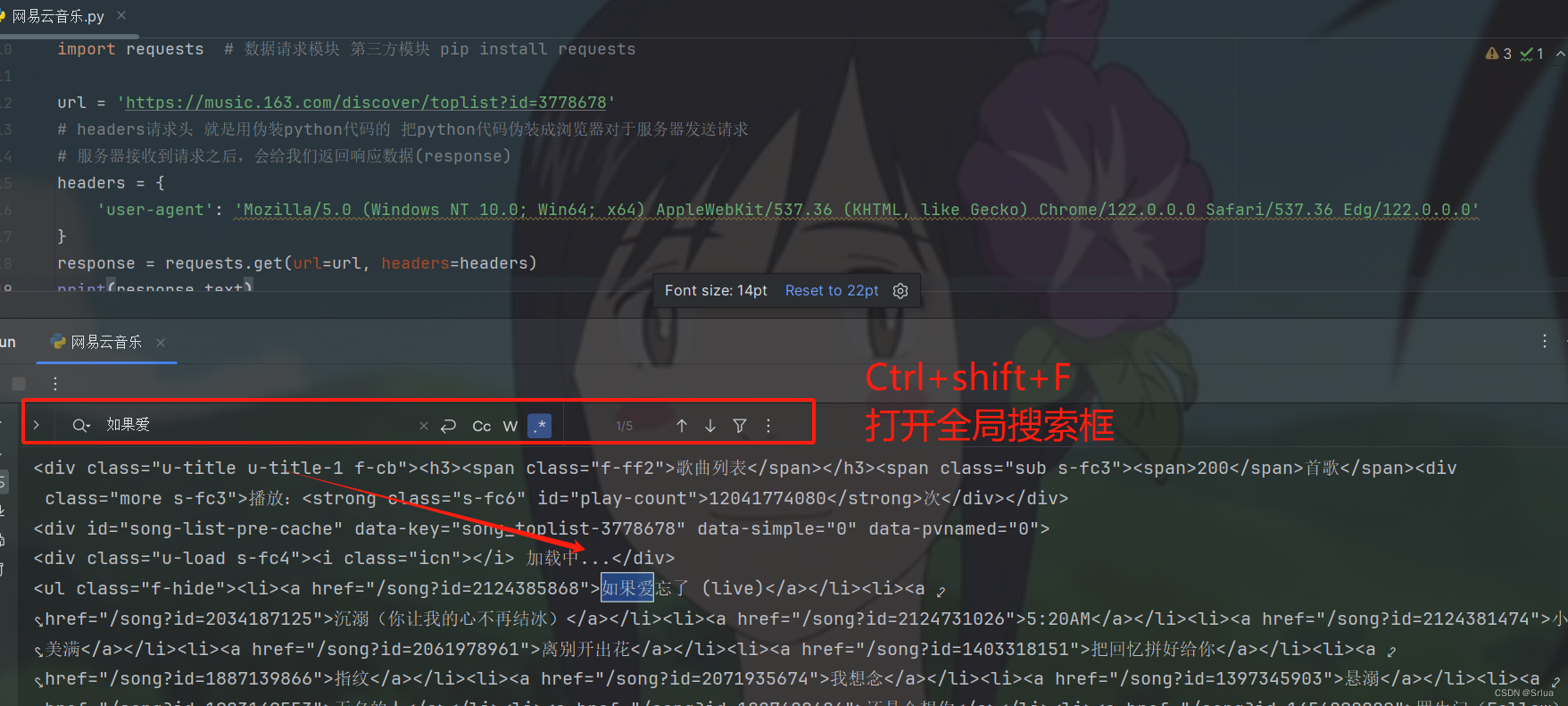
В сочетании с запросом регулярного выражения
'<li><a href="/song\?id=(\d+)">(.*?)</a>'
Это регулярное выражение,Используется для сопоставления определенных шаблонов в HTML. Конкретно,它匹配的да一个<li>внутри тега<a>Этикетка,в<a>Этикетка的hrefАтрибуты начинаются с"/song?id="начало,за которым следует строка цифр(Зависит от\d+выражать),Затемда">"илюбой персонаж(Зависит от(.*?)выражать),наконецда闭合的</a>Этикетка。
Это регулярное выражение можно использовать для извлечения ссылок и названий песен из HTML. Например, если есть строка HTML следующего вида:
<ul>
<li><a href="/song?id=123">Песня 1</a></li>
<li><a href="/song?id=456">Песня 2</a></li>
</ul>Используя это регулярное выражение для сопоставления, вы можете получить два результата:
-
/song?id=123иПесня 1 -
/song?id=456иПесня 2
Извлеките идентификатор музыки и название музыки из списка.
Извлеките идентификатор и название песни из HTML-текста, используя регулярные выражения.
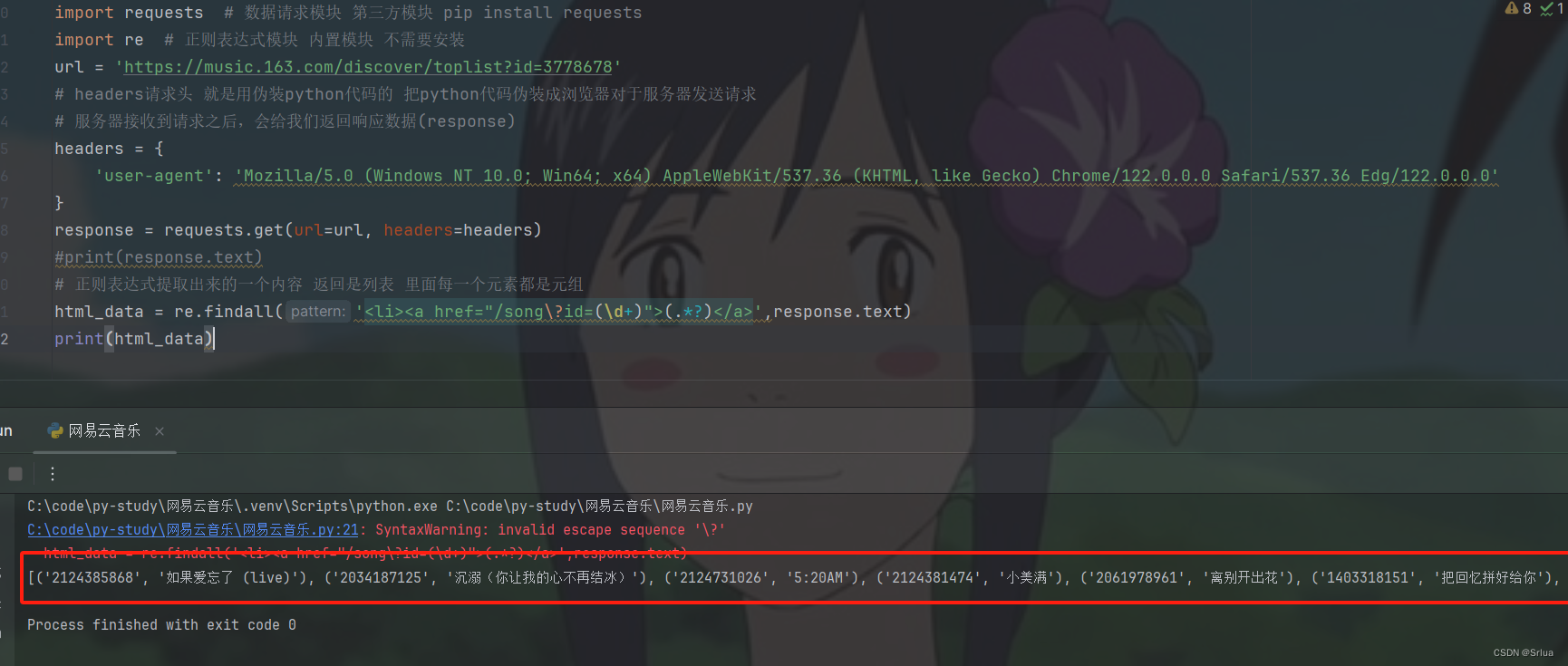
первый,использоватьre.findall()функциячтобы найти все совпадающие строки。
регулярное выражение<li><a href="/song\?id=(\d+)">(.*?)</a>используется для сопоставления с<li><a href="/song?id=начало,за которым следует строка цифр(Зависит от\d+выражать),Затемда">илюбой персонаж(Зависит от(.*?)выражать),наконецда闭合的</a></li>Этикетка。
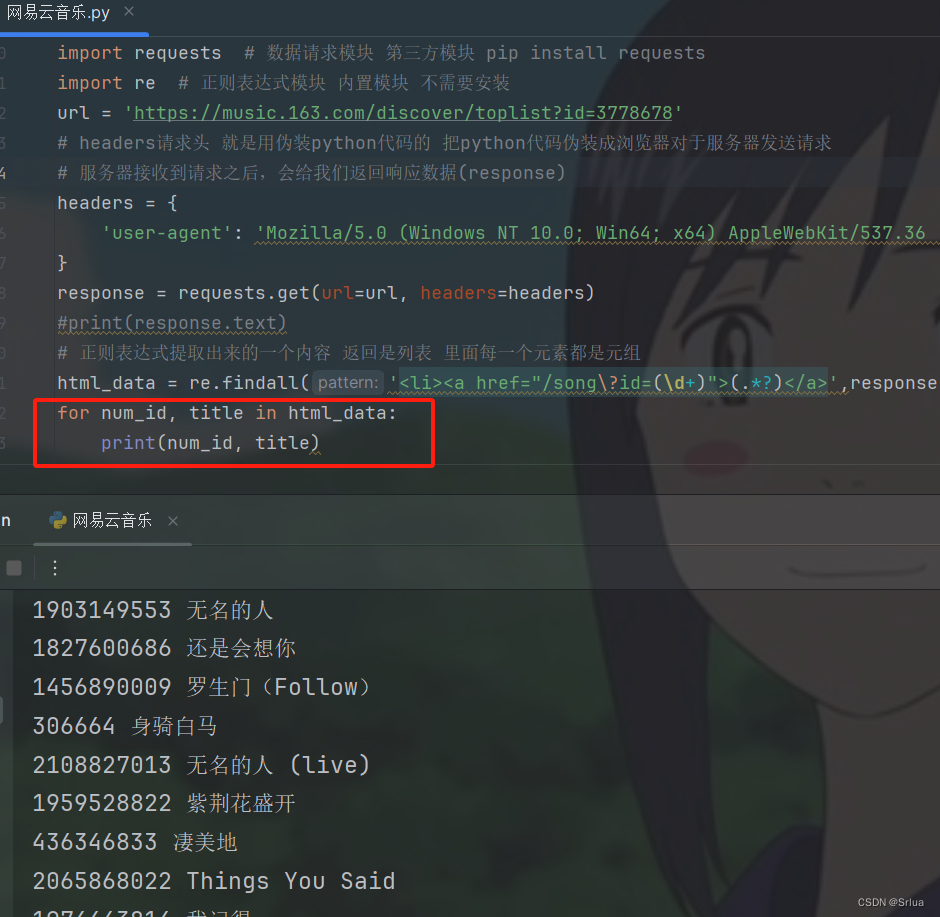
в каждом цикле,num_idПеременные хранят песниID,titleПеременная хранит название песни。Затем,проходитьprint()функцияраспечатайте их。
Реализация пакетной загрузки
После успешного получения идентификатора и имени мы можем подготовиться к загрузке.

Попробуйте вызвать интерфейс для игры
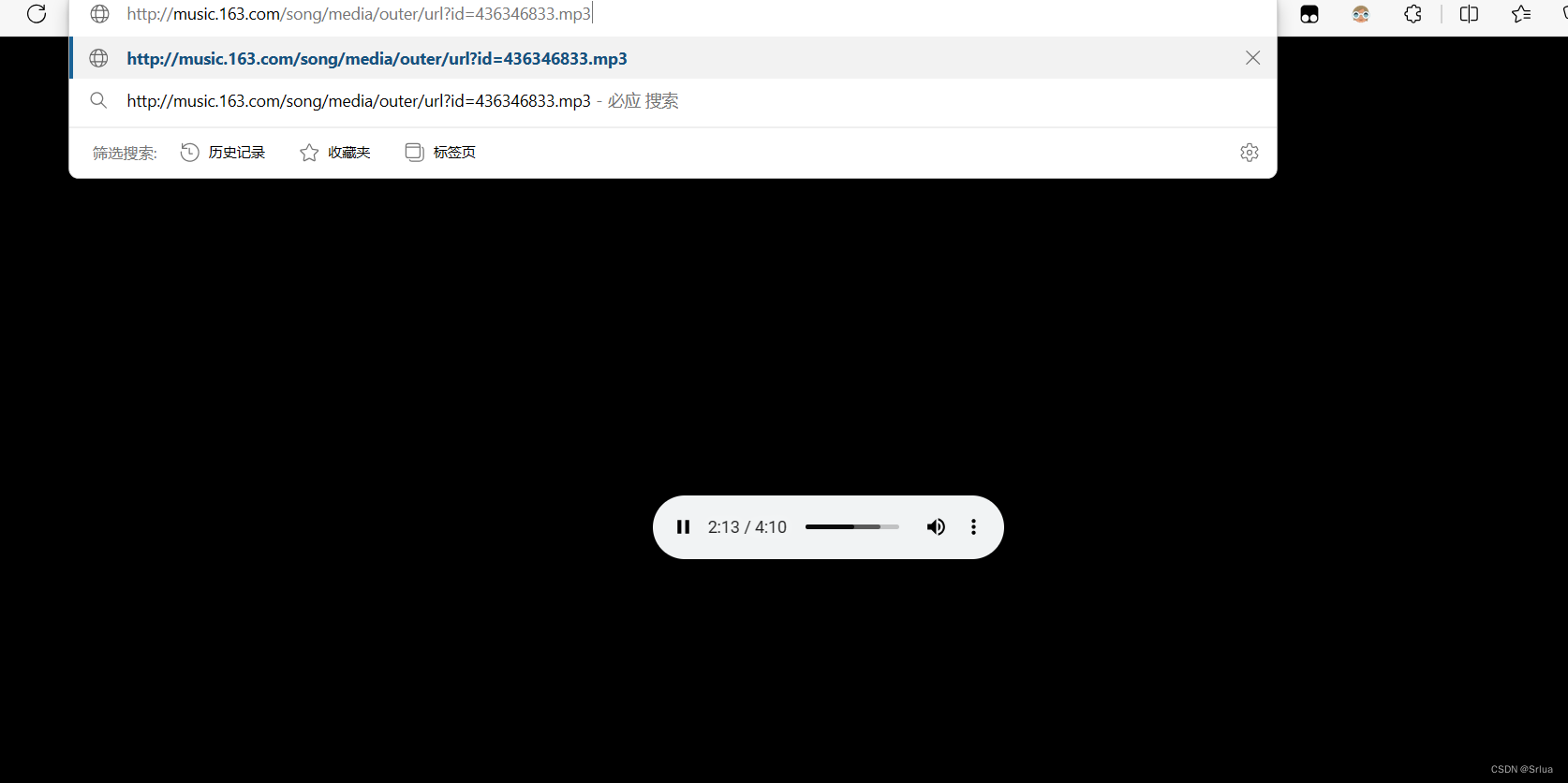
Сыграно успешно
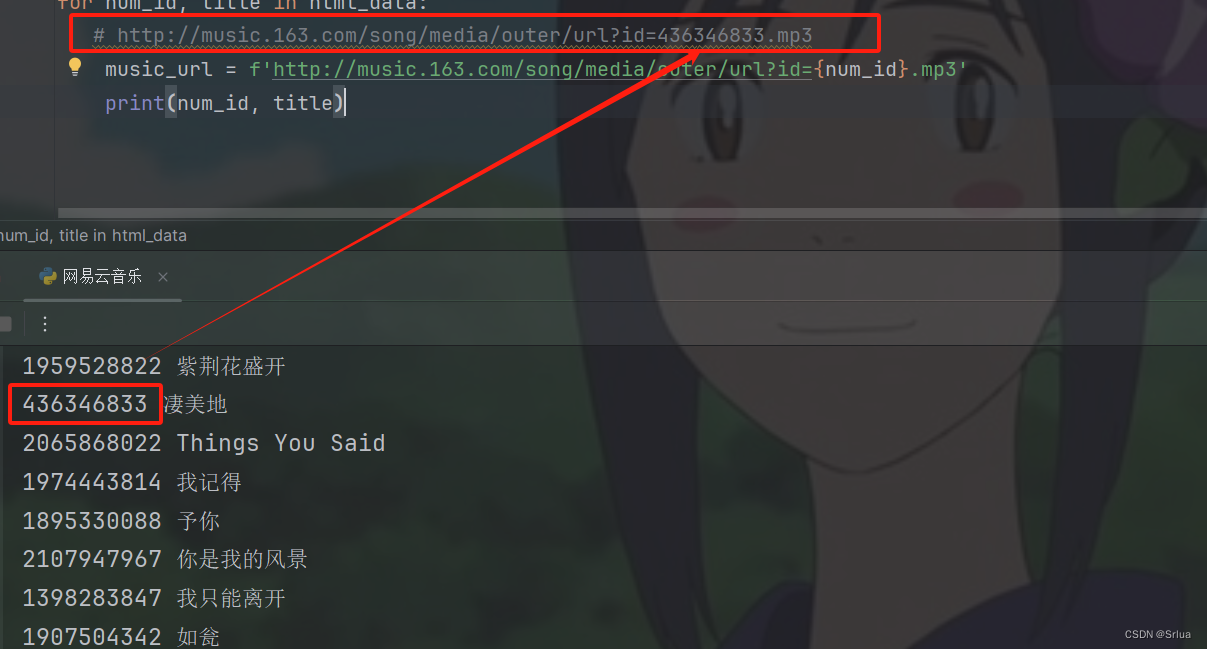
music_url = f'http://music.163.com/song/media/outer/url?id={num_id}.mp3'
# Отправить запрос на адрес воспроизведения музыки Получить содержимое двоичных данных
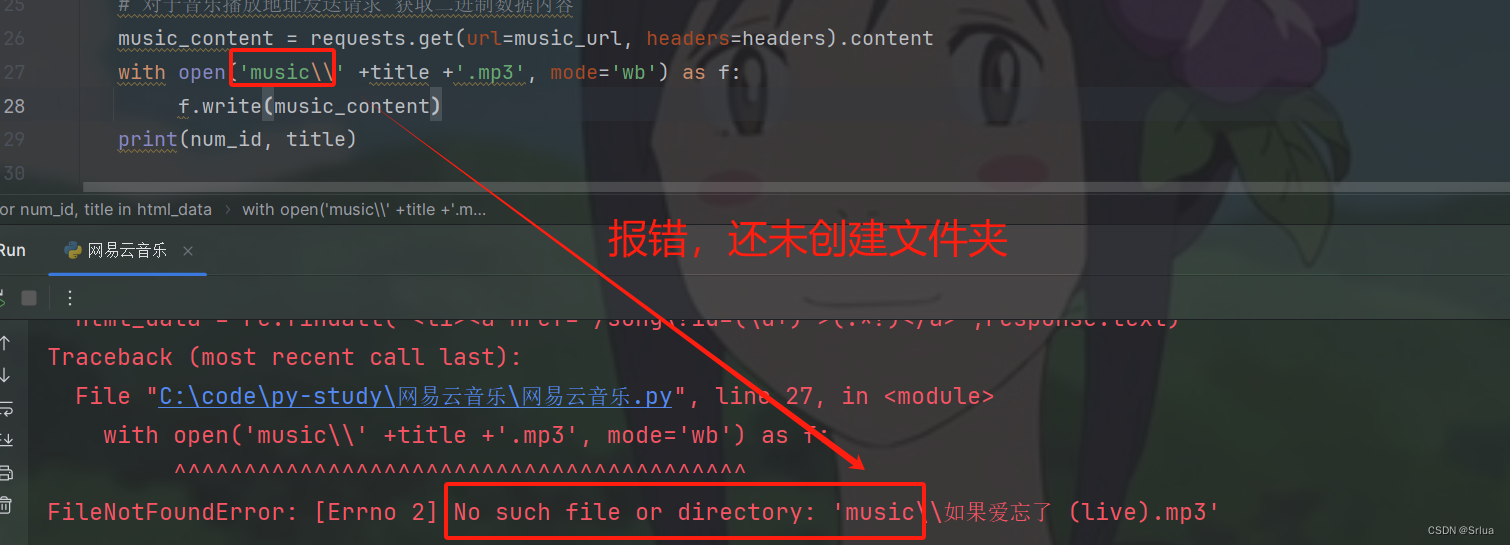
music_content = requests.get(url=music_url, headers=headers).content
with open(filename +title +'.mp3', mode='wb') as f:
f.write(music_content)Этот код используется для загрузки файла MP3 песни.
первый,它использоватьf-stringбудут песниIDВставить в музыкуURLсередина,Создайте полный адрес воспроизведения музыки.
Затем,проходитьrequests.get()функция发送просить Получить содержимое двоичных данных。
наконец,использоватьopen()функция Открыть файл в двоичном режиме для записи,并将音乐内容写入该文件середина。文件名Зависит отfilenameиtitleСоединены вместе,И с.mp3как расширение。
Создание файла
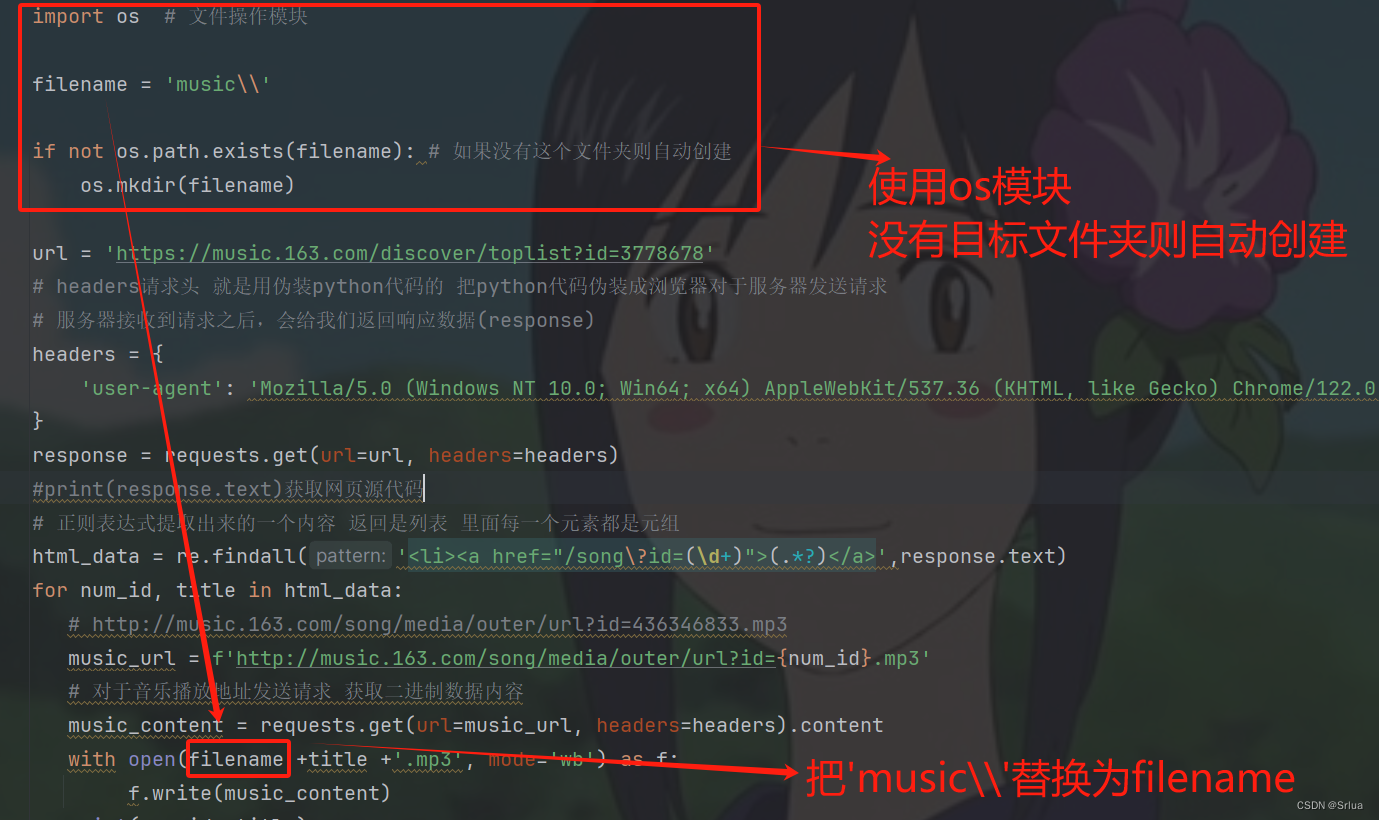
Создание вручную/автоматическое создание модуля ОС
Блогер здесь решает использовать модуль os для создания
Запустить программу
ползать
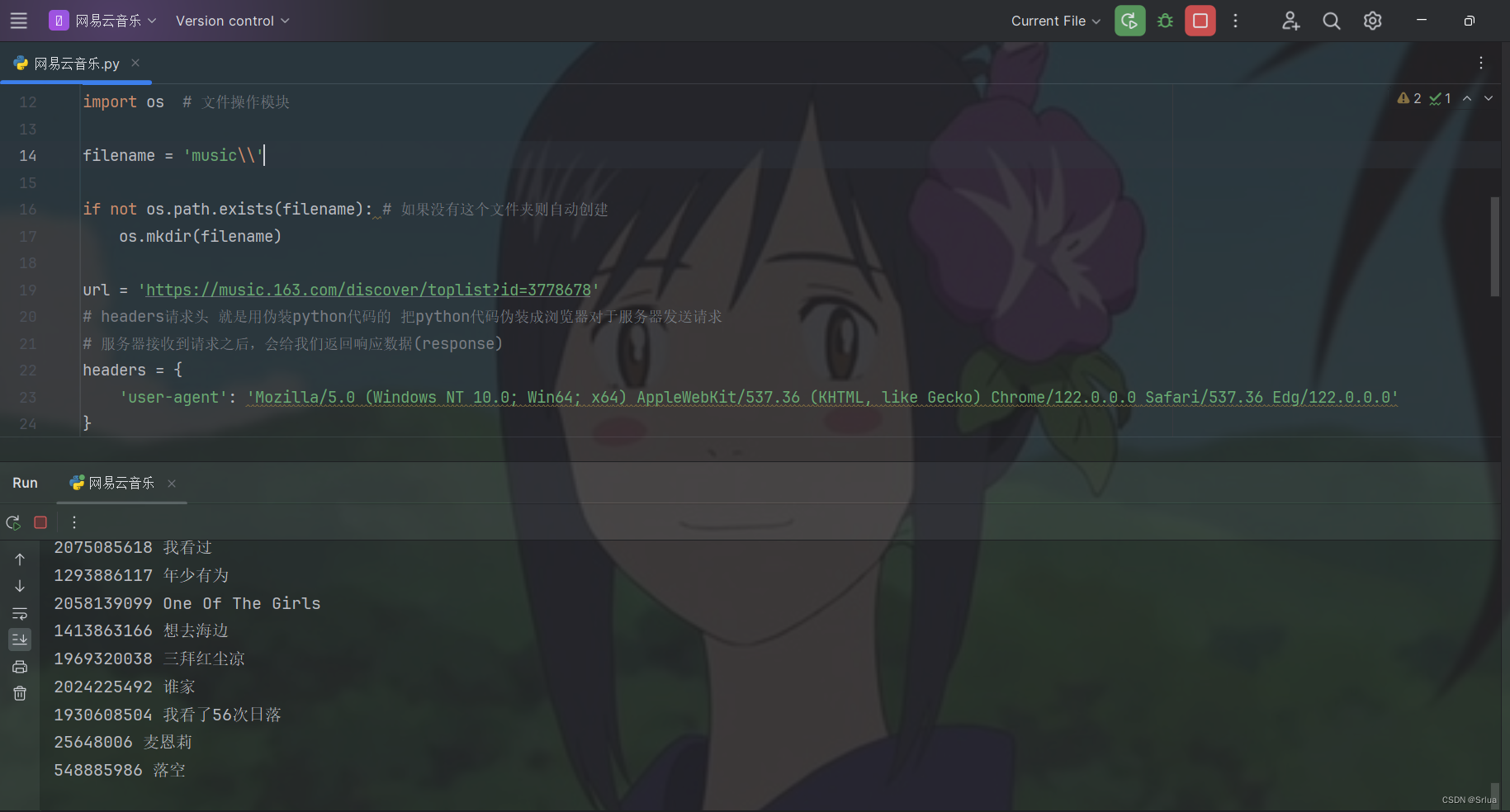
Автоматически загружать в папку пути
Как сканировать другие списки?
Если вы хотите сканировать содержимое песен в других чартах, просто измените идентификатор в URL-адресе запроса.
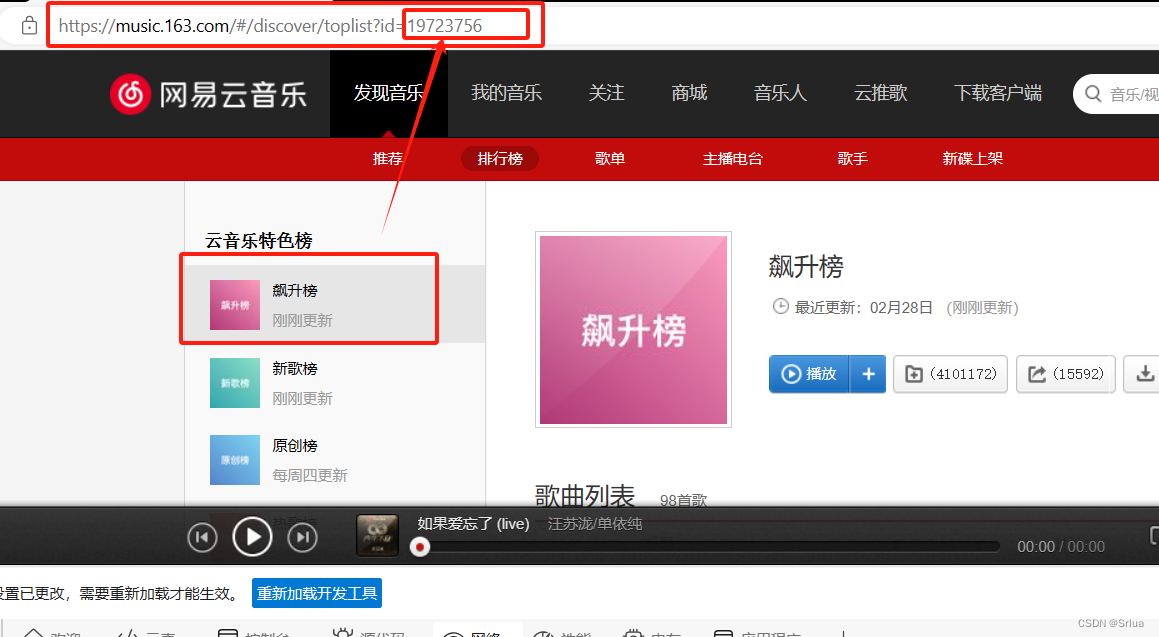
Измените идентификатор списка и успешно сканируйте!
Полный код
import requests # модуль запроса данных сторонние модули pip install requests
import re # регулярное выражение模块 Встроенный модуль Установка не требуется
import os # Модуль работы с файлами
filename = 'music\\'
if not os.path.exists(filename): # Если этой папки не существует, она будет создана автоматически.
os.mkdir(filename)
# Если вы хотите сканировать содержимое песен в других чартах, просто измените идентификатор в URL-адресе запроса.
url = 'https://music.163.com/discover/toplist?id=3778678'
# заголовкизаголовки запросов Просто используйте замаскированный код Python Замаскируйте код Python под браузер и отправляйте запросы на сервер
# После того, как сервер получит запрос, он вернет нам ответные данные(ответ)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'
}
response = requests.get(url=url, headers=headers)
#print(response.text) Получить исходный код веб-страницы
# регулярное Содержимое, извлеченное с помощью выражения Возвращает список Каждый элемент в нем представляет собой кортеж
html_data = re.findall('<li><a href="/song\?id=(\d+)">(.*?)</a>',response.text)
for num_id, title in html_data:
# http://music.163.com/song/media/outer/url?id=436346833.mp3
music_url = f'http://music.163.com/song/media/outer/url?id={num_id}.mp3'
# Отправить запрос на адрес воспроизведения музыки Получить содержимое двоичных данных
music_content = requests.get(url=music_url, headers=headers).content
with open(filename +title +'.mp3', mode='wb') as f:
f.write(music_content)
print(num_id, title)
Надеюсь, это поможет! ну давай же!
Если вы найдете содержание этой статьи полезным, пожалуйста, поставьте ей палец вверх и подпишитесь, чтобы продолжать получать ценную информацию. Искренне благодарю вас за внимание и поддержку!



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
