Практические навыки работы с Python RAPIDS | Ускорение рабочих процессов обработки данных с помощью графических процессоров
Каталог статей
CSDN Е Тингюнь:https://yetingyun.blog.csdn.net/
1. Предисловие
Традиционно,Рабочие процессы обработки данных медленны и громоздки,в целомопирается на ЦП для загрузки, фильтрации и манипулирования данными,И обучите и разверните модель. в силу RAPIDS Библиотека программного обеспечения с открытым исходным кодом, которая может использовать GPU Значительно сократите затраты на инфраструктуру и обеспечьте превосходную производительность для комплексных рабочих процессов обработки данных. графический процессор Ускоренная обработка данных доступна на ноутбуках, в центрах обработки данных, на периферии и в облаке.
Ученые, работающие с данными, нуждаются в вычислительной мощности. Используете ли вы Pandas Для обработки большого набора данных по-прежнему используйте Numpy Выполните некоторые вычисления на большой матрице, и вам понадобится мощная машина, способная выполнить работу за разумное время. За последние несколько лет ученые, работающие с данными, широко использовали Python Библиотека стала очень хорошо использовать CPU способность. Панды Основной код использует C написан на языке, который может обрабатывать скважины размером, превышающим 10GB больших наборов данных. Если вам не хватает RAM для размещения этих наборов данных,тогда ты сможешь сделатьиспользоватьФункция фрагментации,это очень удобно,Одновременно может обрабатываться один блок данных.
Графические процессоры против процессоров: параллельная обработка
Столкнувшись с большим объемом данных, одному процессору сложно его сегментировать.
Набор данных размером более 100 ГБ будет содержать множество точек данных со значениями в диапазоне миллионов или даже миллиардов. При таком большом количестве данных для обработки, независимо от того, насколько быстр ваш процессор, ему не хватит ядер для эффективной параллельной обработки. Если ваш процессор имеет 20 ядер (что будет довольно дорогим процессором), вы можете обрабатывать только 20 точек данных одновременно!
CPUs будет лучше в задачах, где тактовая частота более важна — или поскольку у вас просто нет GPU выполнить. Если процесс, который вы пытаетесь выполнить, имеет GPU реализация, и задача может выиграть от параллельной обработки, тогда GPU будет более эффективным.
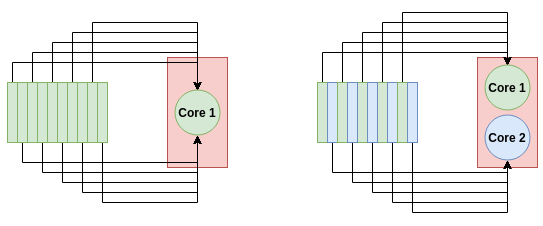
На диаграмме выше показано, как многоядерная система может быстрее обрабатывать данные. Для одноядерной системы (слева) все 10 задач передаются на один узел. В двухъядерной системе (справа) каждый узел берет на себя 5 задач, что удваивает скорость обработки.
Глубокое обучение уже в полной мере использует преимущества GPU Значительные успехи были достигнуты по итогам выступления. Многие операции свертки, выполняемые при глубоком обучении, повторяются, поэтому в GPU можно значительно ускорить и даже достичь 100 раз. Сегодняшняя наука о данных ничем не отличается, поскольку многие повторяющиеся операции выполняются с большими наборами данных с использованием библиотек инструментов: Pandas, Numpy. и Scikit-Learn。этот Эти операции предназначены длясуществовать GPU Реализация не очень сложна.
в настоящий моментиметьхорошийизрешение:RAPIDS
2. Используйте RAPIDS для ускорения графического процессора.
С минимальными изменениями кода и без необходимости изучать новые инструменты. Python Цепочка инструментов для анализа данных.
RAPIDS Официальная документация:https://rapids.ai/index.html
представлять RAPIDS:https://www.youtube.com/watch?v=T2AU0iVbY5A
RAPIDS представляет собой набор библиотек программного обеспечения с открытым исходным кодом, который позволяет вам полностью GPU Выполнение комплексных конвейеров обработки данных и аналитики,цельсуществовать通过利использовать GPU Ускорьте обработку данных。это делаетиспользовать Первый этаж CUDA код для быстрой реализации, графический процессор оптимизированный алгоритм, а также простой в использовании Python слой. Пороги Прелесть в том, что он очень плавно интегрируется с библиотеками обработки данных: например pandas DataFrames можно легко передать Пороги, для достижения GPU ускориться. На рисунке ниже показано Rapids Как сделать верхний слой простым, сохраняя при этом оптимизацию нижних слоев.
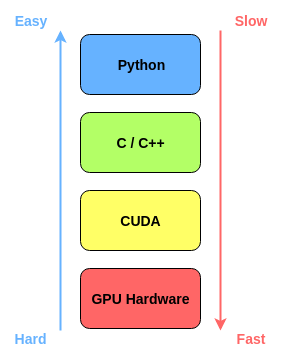
Rapids использует несколько библиотек Python:
- cuDF:Python GPU версияиз DataFrames, существующие в сфере обработки данных и операций, могут в значительной степени Pandas Могу сделать все;
- cuML:Python GPU версияизмашинное учебная библиотека. он содержит много Scikit-Learn Поддержка иметьиз ML Алгоритмы. Все алгоритмы очень похожи в том, как они используются;
- cuGraph:Python GPU Версия обработки изображения. Он содержит множество распространенных алгоритмов анализа графов, в том числе PageRank и Различные меры сходства.
3. Практика RAPIDS
Благодаря предыдущему пониманию мы знаем RAPIDS можно использовать GPU Ускорьте обработку данные. Теперь самое главное — нам нужно настроить среду.,Как насчет того, чтобы почувствовать это?использоватьиз!
Чтобы установить RAPIDS,Пожалуйста, посетите:https://rapids.ai/start.html,В существующем вы увидите как установить ПОроги. ты можешь пройти Conda Установите его прямо на свой компьютер или просто используйте Докер-контейнер。существовать При установке,Вы устанавливаете характеристики своей системы в соответствии с реальной ситуацией.,нравиться CUDA Версия и которую вы хотите установитьиз библиотеки. Например, у меня есть CUDA 11.3,думать Чтобы установить библиотека хаиз, поэтому я из install Команда:
Как только эта строка команды будет выполнена, вы сможете начать использовать графический процессор для ускорения обработки данных!
conda create -n rapids-22.12 -c rapidsai -c conda-forge -c nvidia \
cudf=22.12 cuml=22.12 cugraph=22.12 cusignal=22.12 cucim=22.12 python=3.8 cudatoolkit=11.3
В этом уроке мы возглавим DBSCAN из scikit-learn версия против. RAPIDS GPU Ускоренная версия. я буду использовать один A5000 Чтобы протестировать. DBSCAN Это алгоритм кластеризации на основе плотности, который может автоматически кластеризовать данные без необходимости указания пользователем количества кластер. существовать Scikit-Learn Уметь это извыполнить. Начнем с получения всех настроек импорта. Сначала импортируйте данные, чтобы загрузить данные и визуализировать данные. ML Модель из библиотеки.
import os
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
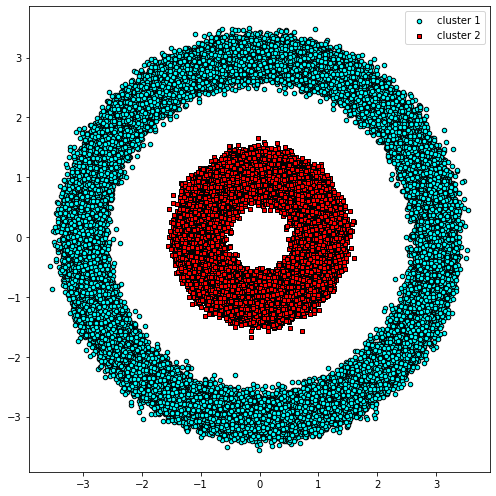
from sklearn.datasets import make_circlesmake_circles Функция автоматически создаст сложное распределение данных, подобное тому, которое мы применили бы к DBSCAN из Два круга. пусть мы начинаем с Создать 100000 Набор данных начинается с точек данных и отображается на графике:
X, y = make_circles(n_samples=int(1e5), factor=.35, noise=.05)
X[:, 0] = 3*X[:, 0]
X[:, 1] = 3*X[:, 1]
plt.scatter(X[:, 0], X[:, 1])
plt.show()
CPU начальствоиз DBSCAN:делатьиспользовать Scikit-Learn существовать CPU беги дальше DBSCAN Очень легко. мы будем импортировать DBSCAN Алгоритм и установка некоторых параметров:
from sklearn.cluster import DBSCAN
db = DBSCAN(eps=0.6, min_samples=2)Наше нынешнее существование можно регулировать, регулируя использование. Scikit-Learn Функция используется с циклическими данными. ДБСКАН. функции существования предшествует %%раз, вы можете сделать Jupyter Notebook Разумно измеряйте время его работы.
%%time
y_db = db.fit_predict(X)этот 10 Время работы для 10 000 баллов составляет примерно 8.31 секунд, как показано на рисунке ниже:
сейчассуществовать,Давайтеиспользовать Rapids Ускорьтесь! Сначала мы преобразуем данные в pandas.DataFrame и использовать его для создания cudf.DataFrame pandas.DataFrame Легко конвертируйте в cudf.DataFrame, никаких изменений в формате данных.
import pandas as pd
import cudf
# Еслииметь форму csv Данные также можно получить непосредственно из csv Чтение данных:
# https://docs.rapids.ai/api/cudf/stable/api_docs/io.html
# X_df = cudf.read_csv("./datas/gene_edges_embeddings.csv")
X_df = pd.DataFrame({fea%d %i: X[:, i] for i in range(X.shape[1])})
X_gpu = cudf.DataFrame.from_pandas(X_df)Тогда мы начнем с cuML Импортируйте и инициализируйте GPU ускорятьсяизверсиякнигаиз DBSCAN。DBSCAN из cuML Версия из формата функции и Scikit-Learn Формат из функции точно такой же: тот же из параметров, Тот же стиль、То же самое из функции.
from cuml import DBSCAN as cumlDBSCAN
db_gpu = cumlDBSCAN(eps=0.6, min_samples=2)
# print(" ".join(["CSDN", "Е Тингюнь", "https://yetingyun.blog.csdn.net/"]))Наконец, мы можем измерить время работы при запуске функции прогнозирования DBSCAN графического процессора.
%%time
y_db_gpu = db_gpu.fit_predict(X_gpu)GPU Версия времени выполнения 4.22 секунды, почти ускоренный 2 раз. Поскольку мы используем тот же алгоритм, результирующий граф также CPU Версия точно такая же.
Получите сверхвысокую скорость с графическими процессорами Rapids
мы начинаем с Rapids получатьизускоряться Сумма зависит от того, что мы делаемсуществоватьиметь дело сиз Объем данных。Хорошее практическое правило заключается в том, что большие наборы данных выиграют от ускорения графического процессора.。существовать CPU и GPU Передача данных между ними требует некоторого накладного времени,И для больших наборов данных,Потраченное время становится более ценным.
Мы можем использовать простой пример, чтобы немного проиллюстрировать это.
Мы создадим случайное число из Numpy массив и примените его ДБСКАН. Мы будем более традиционными CPU DBSCAN и cuML из GPU версиякнигаизскорость,Одновременно увеличивайте и уменьшайте количество точек данных.,чтобы понять, как это влияет на наше время выполнения.
Следующий код иллюстрирует, как выполнить тест:
import numpy as np
n_rows, n_cols = 10000, 100
X = np.random.rand(n_rows, n_cols)
print(X.shape)
X_df = pd.DataFrame({ fea%d %i: X[:, i] for i in range(X.shape[1])})
X_gpu = cudf.DataFrame.from_pandas(X_df)
db = DBSCAN(eps=3, min_samples=2)
db_gpu = cumlDBSCAN(eps=3, min_samples=2)
%%time
y_db = db.fit_predict(X)
%%time
y_db_gpu = db_gpu.fit_predict(X_gpu)использовать Matplotlib Визуализируйте результаты нескольких экспериментов по изменению объема данных:
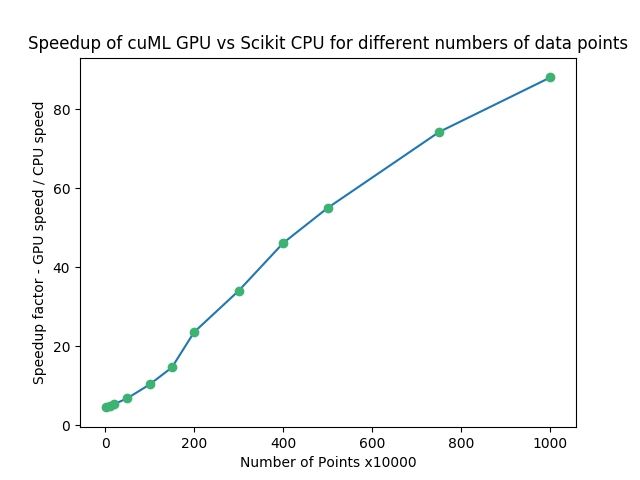
Горизонтальная ось представляет количество точек данных, а вертикальная ось представляет GPU speed и CPU speed изсоотношение。когдаделатьиспользовать GPU вместо CPU , их число резко возрастет. Даже существовать 10000 (крайняя левая точка), наша скорость все еще 4.54x。существоватьвышеизодин конец,1 Десять миллионов точек, переходим на GPU час из скорости 88.04x!
Справочные ссылки:
- Here’s how you can accelerate your Data Science on GPU
- Статьи паблик аккаунта | 【передовой】нравитьсячтосуществовать GPU начальство Ускорьте обработку данных
- YouTube RAPIDSAI | Introduction to RAPIDS
- Сообщество RAPIDSAI | Введение в RAPIDS
- NVIDIA Ускорьте обработку данных
- Официальная документация RAPIDS |
- CSDN блог | Пакет [Python-GPU] для анализа данных графического процессора ——RAPIDS



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
