Познакомьтесь с экосистемой больших данных Hadoop в одной статье
1. Введение в большие данные
1.1 Концепция больших данных
Большие данные: относятся к набору данных, которые невозможно собрать, управлять и обработать в течение определенного периода времени с помощью традиционных программных инструментов. Это огромный объем данных, который требует новых моделей обработки, чтобы иметь более сильные возможности принятия решений и аналитические открытия. и возможности оптимизации процессов, высокие темпы роста и диверсифицированные информационные активы.
В основном он решает проблемы хранения больших объемов данных, а также их анализа и расчета.
Единицы хранения данных указаны в следующем порядке: бит, байт, КБ, МБ, ГБ, ТБ, PB, EB, ZB, YB, BB, NB, DB. 1Байт = 8бит 1К = 1024Байт 1МБ = 1024К 1Г = 1024М 1Т = 1024Г 1П = 1024Т
1.2 Характеристики больших данных
1. Объем: на данный момент объем данных всех печатных материалов, созданных людьми, составляет 200 ПБ, тогда как общий объем данных всех людей в истории составляет около 5 ЭБ. В настоящее время емкость жесткого диска типичного персонального компьютера составляет порядка ТБ, а объем данных некоторых крупных предприятий близок к уровню ЭБ. 2. Характеристики больших данных
2. Скорость (высокая скорость). Это наиболее важная особенность, отличающая большие данные от традиционного интеллектуального анализа данных. Согласно отчету IDC «Цифровая вселенная», ожидается, что к 2020 году глобальное использование данных достигнет 35,2 ЗБ. Перед лицом таких огромных данных эффективность обработки данных — это жизнь предприятия. Tmall Double Eleven: За 3 минуты и 01 секунду в 2017 году объем транзакций Tmall превысил 10 миллиардов
3. Разнообразие. Этот тип разнообразия также позволяет разделить данные на структурированные и неструктурированные. По сравнению со структурированными данными, которые в прошлом представляли собой в основном базу данных/текст и которые было легко хранить, сейчас появляется все больше и больше неструктурированных данных, включая веб-журналы, аудио, видео, изображения, информацию о географическом местоположении и т. д. Обработка этих различных типов данных требует Способность выдвигает более высокие требования.
4. Значение (низкая плотность значений). Плотность значений обратно пропорциональна общему объему данных. Например, в видео наблюдения за один день нас волнует только та минута, когда Учитель Сун работал ночью в постели. Как быстро «очистить» ценные данные, стало сложной проблемой, которую необходимо решить в современном контексте больших данных.
1.3 Что могут сделать большие данные?
1. O2O: Платформа Baidu Big Data+ помогает продавцам совершенствовать операции и увеличивать продажи благодаря передовым технологиям онлайн- и офлайн-интеграции и возможностям анализа потоков клиентов.
2. Розничная торговля: изучайте ценность для пользователей и предоставляйте персонализированные сервисные решения, реализуйте онлайн- и физическую розничную торговлю и работайте вместе, чтобы создать максимальный опыт. Классический чехол, подгузник + пиво.
3. Туризм: Глубоко объединить возможности больших данных с потребностями индустрии туризма, чтобы совместно построить будущее интеллектуального управления, интеллектуальных услуг и умного маркетинга в туристической индустрии.
4. Рекомендация по рекламе продукта: порекомендуйте типы рекламы продукта, которую посещали пользователи.
5. Страхование. Масштабный анализ данных и прогнозирование рисков помогают страховой отрасли осуществлять точный маркетинг и улучшать возможности уточнения ценообразования.
6. Финансы. Отражайте характеристики пользователей в различных измерениях, помогайте финансовым учреждениям рекомендовать высококачественных клиентов и предотвращайте риски мошенничества.
7. Недвижимость. Большие данные всесторонне помогают индустрии недвижимости создавать точные инвестиционные стратегии и маркетинг, выбирать более подходящие земли, строить более подходящие здания и продавать их более подходящим людям.
8. Искусственный интеллект:
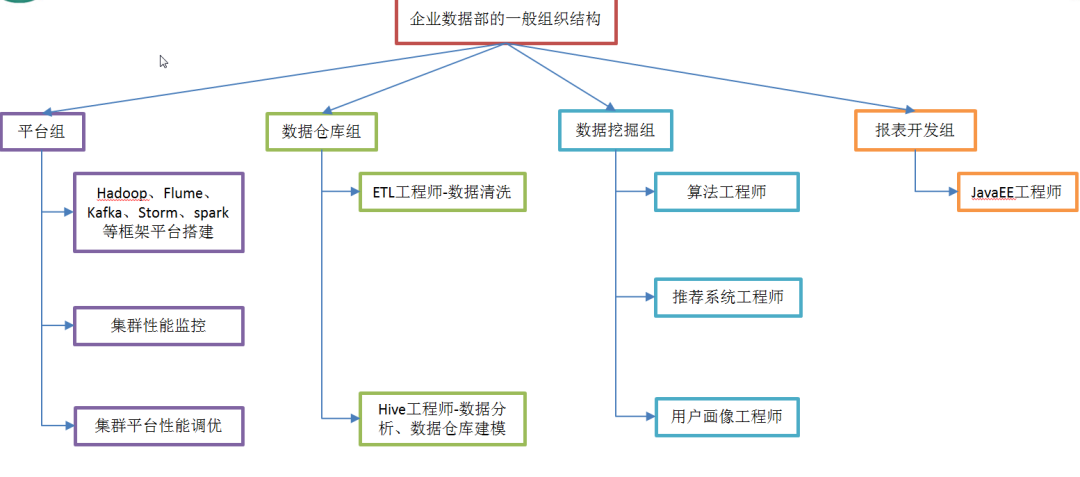
1.4 Общая организационная структура отдела данных предприятия
два. от Hadoop Рамочная программа для обсуждения экологии больших данных
2.1 Что такое Хадуп
1) Hadoop — это распределенная системная инфраструктура, разработанная Apache Foundation.
2)В основном он решает проблемы хранения больших объемов данных, а также их анализа и расчета.
3) Вообще говоря, HADOOP обычно относится к более широкому понятию — экосистеме HADOOP.
2.2 История развития Hadoop
1) Lucene — программное обеспечение с открытым исходным кодом, созданное Дугом Каттингом. Оно использует Java для написания кода для реализации функций полнотекстового поиска, аналогичных Google. Оно обеспечивает архитектуру полнотекстовой поисковой системы, включая полноценную систему запросов и систему индексирования.
2) Стал подпроектом Apache Foundation в конце 2001 г.
3) При большом количестве сценариев Lucene сталкивается с теми же трудностями, что и Google.
4) Изучите и подражайте решению этих проблем от Google: микроверсия Nutch.
5) Можно сказать, что Google является источником идей для Hadoop (три статьи Google о больших данных).
GFS --->HDFS
Map-Reduce --->MR
BigTable --->Hbase
6) С 2003 по 2004 год Google раскрыл некоторые подробности идей GFS и Mapreduce. Основываясь на этом, Дуг Каттинг и другие потратили 2 года в свободное время на реализацию механизмов DFS и Mapreduce, что резко увеличило производительность Nutch.
7) В 2005 году Hadoop был официально представлен Apache Foundation как часть Nutch, подпроекта Lucene. В марте 2006 года Map-Reduce и распределенная файловая система Nutch (NDFS) были включены в проект под названием Hadoop.
8) Назван в честь игрушечного слона сына Дуга Каттинга.
9) Hadoop родился и быстро развивался, ознаменовав наступление эры облачных вычислений.
2.3 Три основные версии распространения Hadoop
Существует три основных версии Hadoop: Apache, Cloudera и Hortonworks.
Самая оригинальная (самая базовая) версия Apache, лучше всего подходит для вводного обучения.
Cloudera широко используется в крупных интернет-компаниях.
Документация Hortonworks лучше.
2.4 Преимущества Hadoop
1) Высокая надежность. Поскольку Hadoop предполагает, что вычислительные элементы и хранилище выйдут из строя, поскольку он поддерживает несколько копий рабочих данных, обработка может быть перераспределена на вышедший из строя узел в случае сбоя.
2) Высокая масштабируемость: распределение данных задач между кластерами позволяет легко расширить тысячи узлов.
3) Эффективность. Согласно идее MapReduce, Hadoop работает параллельно, чтобы ускорить обработку задач.
4) Высокая отказоустойчивость: автоматическое сохранение нескольких копий данных и автоматическое перераспределение невыполненных задач.
2.5 Композиция Hadoop
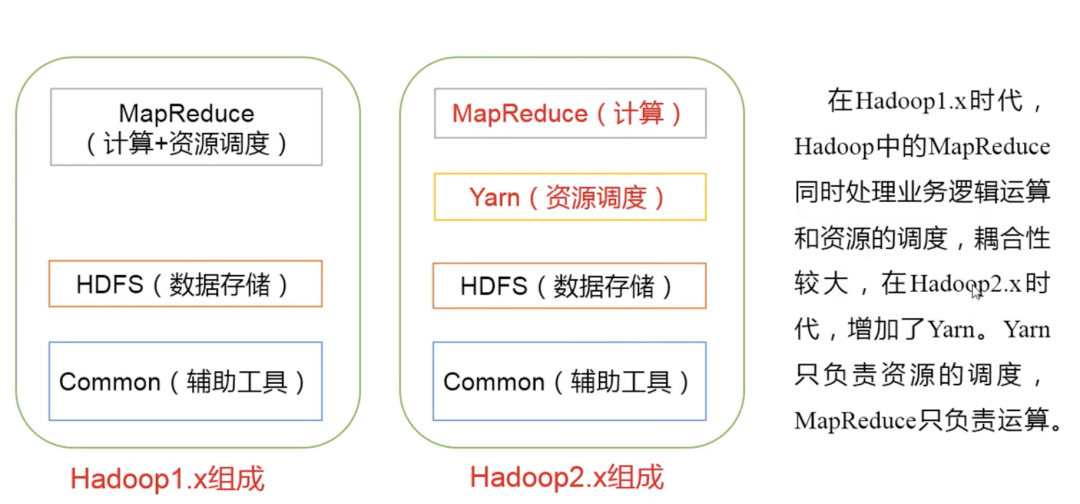
1) Hadoop HDFS: высоконадежная распределенная файловая система с высокой пропускной способностью.
2) Hadoop MapReduce: среда распределенных автономных параллельных вычислений.
3) Hadoop YARN: платформа для планирования заданий и управления ресурсами кластера.
4) Hadoop Common: инструментальные модули, поддерживающие другие модули (конфигурация, RPC, механизм сериализации, операции журнала).
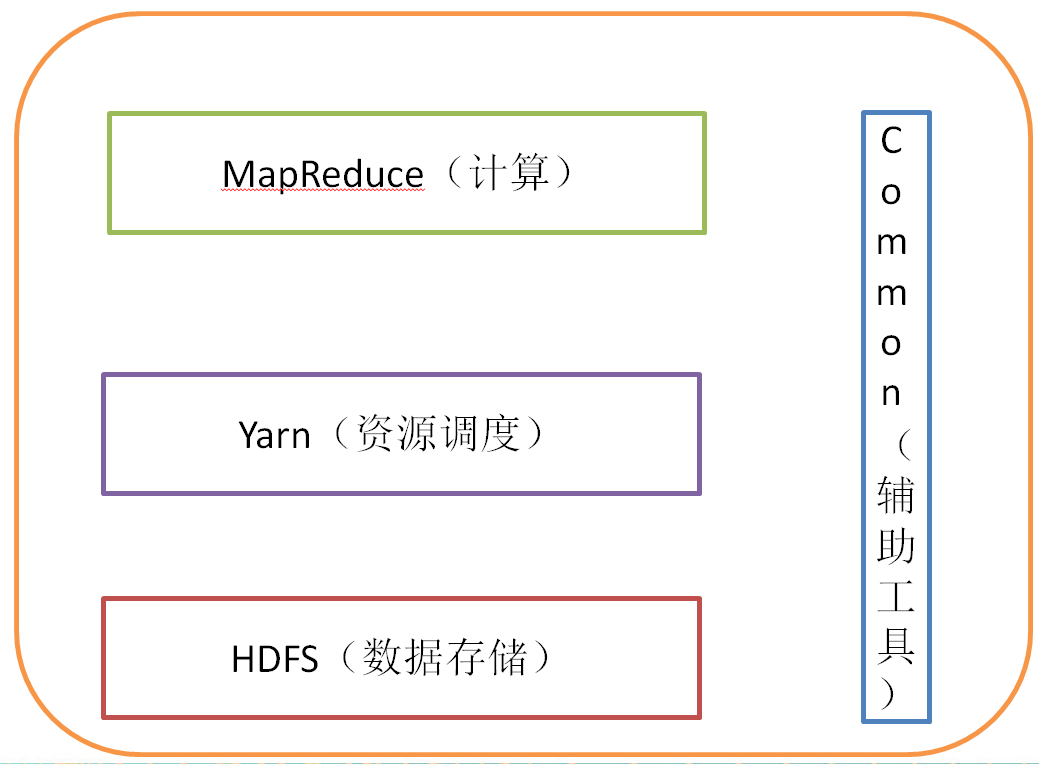
2.5.1 Обзор архитектуры HDFS
1) NameNode (nn): хранит метаданные файла, такие как имя файла, структура каталогов файлов, атрибуты файла (время создания, количество копий, права доступа к файлу), а также список блоков каждого файла и DataNode, где находится блок и т.д.
2) DataNode(dn): хранит данные блока файлов в локальной файловой системе, а также контрольную сумму данных блока.
3) Secondary NameNode(2nn): вспомогательная фоновая программа, используемая для мониторинга состояния HDFS и получения снимков метаданных HDFS через регулярные промежутки времени.
2.5.2 Обзор архитектуры YARN
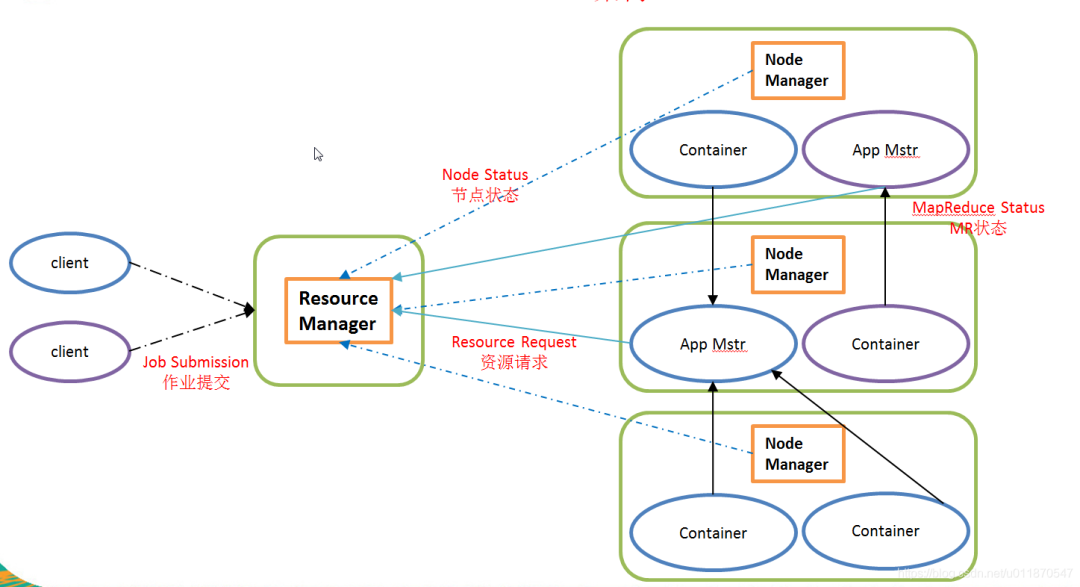
1) ResourceManager(rm): обрабатывает клиентские запросы, запускает/отслеживает ApplicationMaster, контролирует NodeManager, распределение и планирование ресурсов;
2) NodeManager (nm): управление ресурсами на одном узле, обработка команд из ResourceManager и обработка команд из ApplicationMaster;
3) ApplicationMaster: сегментация данных, применение ресурсов приложения и распределение внутренних задач, мониторинг задач и отказоустойчивость.
4) Контейнер: абстракция среды выполнения задачи, инкапсулирующая многомерные ресурсы, такие как ЦП и память, а также информацию, связанную с выполнением задачи, такую как переменные среды и команды запуска.
2.5.3 Обзор архитектуры MapReduce
MapReduce делит процесс вычислений на два этапа: Map и уменьшить.
1) Этап Map параллельно обрабатывает входные данные.
2) Этап сокращения обобщает результаты карты.
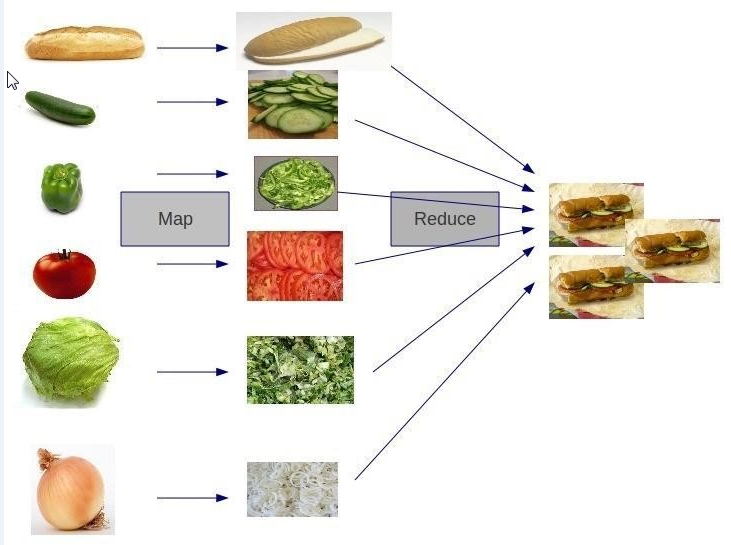
Приведенный выше рисунок просто иллюстрирует два процесса или функции: «Map» и «Reduc». Хотя он и недостаточно строг, его достаточно, чтобы дать примерное представление. Процесс «Map» — это подготовка овощей перед их превращением в пищу. материалы, а затем процесс приготовления еды.
2.6 Экосистема технологий больших данных
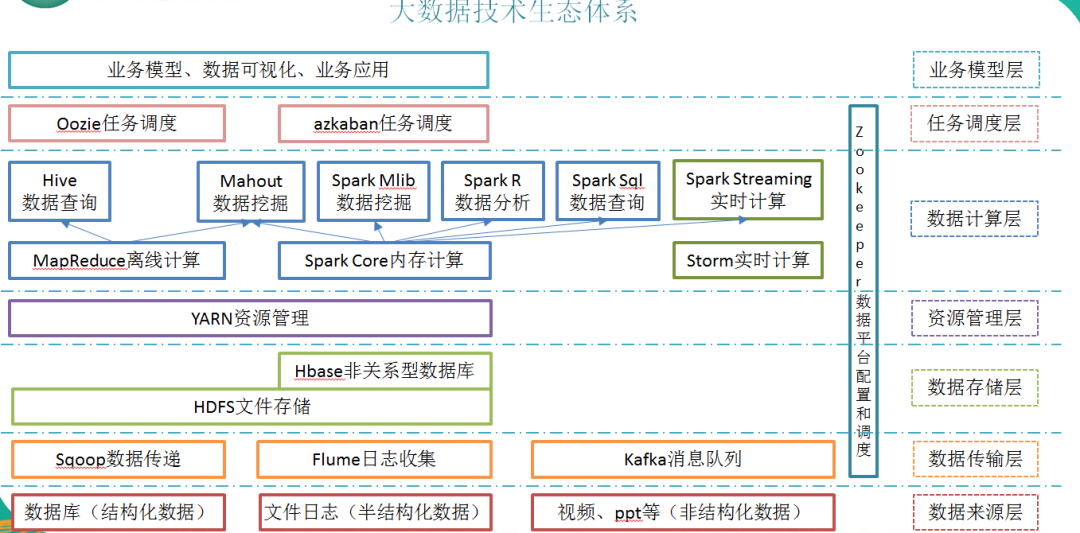
Технические термины, представленные на рисунке, поясняются следующим образом:
1) Sqoop: sqoop — это инструмент с открытым исходным кодом, который в основном используется для передачи данных между Hadoop (Hive) и традиционными базами данных (mysql). Он может передавать данные в реляционную базу данных (например, MySQL, Oracle и т. д.) Импортировать в Hadoop. HDFS и данные HDFS также можно импортировать в реляционную базу данных.
2) Flume: Flume — это высокодоступная, высоконадежная распределенная система массового сбора, агрегирования и передачи журналов, предоставляемая Cloudera. Flume поддерживает настройку различных отправителей данных в системе журналов для одновременного сбора данных. Flume предоставляет возможность; просто обрабатывать данные и записывать их различным получателям данных (настраиваемые).
3) Kafka: Kafka — это распределенная система обмена сообщениями с высокой пропускной способностью, имеющая следующие характеристики:
- проходить Дисковая структура O(1) обеспечивает постоянство сообщений. Эта структура подходит даже для числа. TB новости хранилище также может поддерживать стабильную производительность в течение длительного времени.
- Высокая пропускная способность: даже на очень скромном оборудовании Kafka ХОРОШОподдерживатьмиллионы в секундуновости
- поддерживатьпроходить Kafka Кластеры серверов и потребителей для разделения сообщений.
- поддерживать Hadoop Параллельная загрузка данных.
4) Storm: Storm предоставляет набор общих примитивов для распределенных вычислений в реальном времени, которые можно использовать в «потоковой обработке» для обработки сообщений и обновления базы данных в реальном времени. Это еще один способ управления очередями и рабочими кластерами. Storm также можно использовать для «непрерывных вычислений» для выполнения непрерывных запросов к потоку данных и вывода результатов пользователю в виде потока во время вычислений.
5) Spark. В настоящее время Spark является самой популярной платформой для вычислений в памяти больших данных с открытым исходным кодом. Вычисления могут выполняться на основе больших данных, хранящихся в Hadoop.
6) Oozie: Oozie — это система управления планированием рабочих процессов, которая управляет заданиями Hdoop. Задача координации Oozie — запустить текущий рабочий процесс Oozie с помощью времени (частоты) и достоверных данных.
7) Hbase: HBase — это распределенная, ориентированная на столбцы база данных с открытым исходным кодом. HBase отличается от обычных реляционных баз данных. Это база данных, подходящая для хранения неструктурированных данных.
8) Hive: Hive — это инструмент хранилища данных, основанный на Hadoop. Он может отображать файлы структурированных данных в таблицу базы данных и предоставлять простые функции SQL-запросов. Он может преобразовывать операторы SQL в задачи MapReduce для запуска. Его преимущество заключается в низкой стоимости обучения, простой статистике MapReduce можно быстро реализовать с помощью SQL-подобных операторов, и нет необходимости разрабатывать специальные приложения MapReduce. Он очень подходит для статистического анализа хранилищ данных. 9) Язык R: R — это язык и операционная среда для статистического анализа и графики. R — бесплатное программное обеспечение с открытым исходным кодом, принадлежащее системе GNU. Это отличный инструмент для статистических вычислений и статистической графики.
10)Mahout: Apache Mahout В настоящее время это масштабируемая библиотека машинного обучения и интеллектуального анализа данных. Mahout Поддержите главного 4 личное использование Пример: Анализ рекомендаций: собирайте действия пользователей и используйте их, чтобы рекомендовать то, что может понравиться пользователю. Агрегация: сбор файлов и группировка связанных файлов. Классификация: изучение существующих классифицированных документов, поиск схожих характеристик в документах и исправление немаркированных документов. классификация. Анализ часто встречающихся наборов элементов: группирование набора элементов и определение того, какие отдельные элементы часто появляются вместе.
11) ZooKeeper: Zookeeper — это реализация Google Chubby с открытым исходным кодом. Это надежная система координации для крупномасштабных распределенных систем. Она предоставляет такие функции, как обслуживание конфигурации, служба имен, распределенная синхронизация, групповое обслуживание и т. д. Цель ZooKeeper — инкапсулировать сложные и подверженные ошибкам ключевые сервисы и предоставить пользователям простые и удобные в использовании интерфейсы, а также систему с эффективной производительностью и стабильными функциями.
2.7 Рекомендуемая схема структуры системы
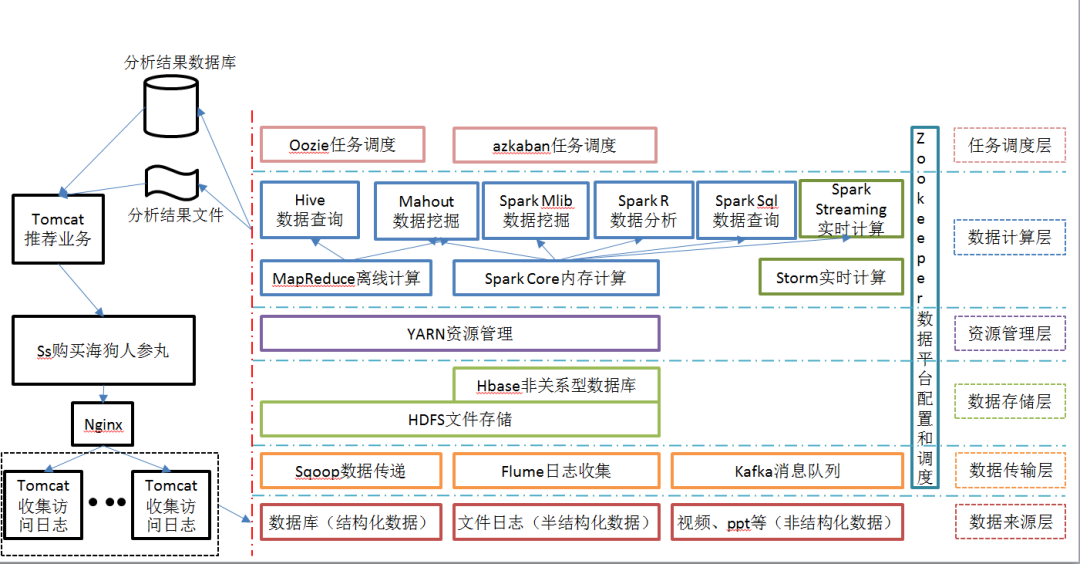



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
