Познакомьтесь с архитектурой ИИ-трансформера в одной статье!
1 Что такое преобразователь AI?
Конвертер — архитектура нейронной сети, которая преобразует или изменяет входную последовательность в выходную последовательность. Они делают это, изучая контекст и отслеживая связи между компонентами последовательности. Например, рассмотрим следующую входную последовательность: «Какого цвета небо?» Модель преобразователя использует внутреннее математическое представление для определения корреляций и отношений между словами «цвет», «небо» и «синий». Используя эти знания, он генерирует вывод: «Небо голубое».
Организации могут использовать модели конвертеров для всех типов преобразования последовательностей, включая распознавание речи, машинный перевод и анализ последовательностей белков.
2 Почему важен преобразователь?
Первые дниглубокое обучениеМодель в основном ориентирована наобработка естественного языка(NLP)Задача,Разработан, чтобы позволить компьютерам понимать естественный человеческий язык и реагировать на него. Они угадывают следующее слово последовательности на основе предыдущего слова.
для лучшего понимания,Обратите внимание на функцию автозаполнения в вашем телефоне. Делает предложения в зависимости от того, как часто вводятся пары слов. Например, частое написание «Я в порядке»,печатаниеоченьпосле,возможность мобильного телефонас Подсказка движенияхороший。
Первые днимашинное обучение(ML)Модель применяет аналогичные методы в более широком масштабе.。Они отображают частоту взаимосвязей между различными парами или группами слов в наборе обучающих данных.,и попытайтесь угадать следующее слово. Однако,Первые дни Техника не может сохранять введенные данные дольше определенной длины.Внизискусство。нравиться Первые днииз ML Модель не может генерировать осмысленные абзацы, поскольку она не может сохранить контекст между первым и последним предложениями абзаца. Чтобы сгенерировать вывод типа «Я из Италии, мне нравится кататься на лошадях, я говорю по-итальянски», модель должна помнить о связи между Италией и итальянским языком, чего ранние нейронные сети просто не могли сделать.
Модели-трансформеры фундаментально меняют методы НЛП, позволяя моделям обрабатывать такие долгосрочные зависимости в тексте.
Дополнительные преимущества конвертеров.
2.1 Использование крупномасштабных моделей
Преобразователь обрабатывает всю длинную последовательность посредством параллельных вычислений, что значительно сокращает время обучения и обработки. Это позволяет обучать очень большие языковые модели (LLM), такие как GPT и BERT, которые могут изучать сложные языковые представления. Благодаря миллиардам параметров они могут охватить широкий спектр человеческого языка и знаний, а также стимулируют исследования в области систем искусственного интеллекта более общего назначения.
2.2 Ускорьте настройку
При использовании преобразовательных моделей доступна технология RAG. Эти технологии позволяют настраивать существующие модели для приложений, специфичных для отраслевых организаций. Модели могут быть предварительно обучены на больших наборах данных, а затем точно настроены на небольших наборах данных для конкретных задач. Такой подход демократизирует использование сложных моделей и устраняет ограничения ресурсов при обучении больших моделей с нуля. Модели могут хорошо справляться с задачами в нескольких областях и различных сценариях использования.
2.3 Продвижение мультимодальных систем искусственного интеллекта
Трансформеры позволяют использовать ИИ для объединения сложных наборов данных. Такие модели, как DALL-E, показывают, что преобразователи могут сочетать НЛП и компьютерное зрение для создания изображений из текстовых описаний. Трансформеры позволяют создавать приложения искусственного интеллекта, которые интегрируют различные типы информации и более точно имитируют человеческое понимание и творчество.
2.4 Исследования искусственного интеллекта и отраслевые инновации
Converter создает новое поколение технологий искусственного интеллекта и исследований в области искусственного интеллекта, которые расширяют границы возможностей машинного обучения. Их успех вдохновляет на создание новых архитектур и приложений, решающих инновационные проблемы. Они позволяют машинам понимать и генерировать человеческий язык для разработки приложений, которые улучшают качество обслуживания клиентов и создают новые возможности для бизнеса.
3 Варианты использования конвертера?
Большие модели преобразователей можно обучать на любых последовательных данных (например, человеческом языке, музыкальных композициях, языках программирования и т. д.).
3.1 Обработка естественного языка
Переводчики позволяют машинам понимать, интерпретировать и генерировать человеческий язык с большей точностью, чем когда-либо прежде. Они могут Подвести итог Большие документы и создание связного и контекстуального текста для различных случаев использования. картина Alexa Такие виртуальные помощники используют технологию переводчика, чтобы понимать голосовые команды и реагировать на них.
3.2 Машинный перевод
Приложения-переводчики используют конвертеры для обеспечения точного перевода между разными языками в режиме реального времени. Конвертер значительно повышает плавность и точность перевода по сравнению с предыдущими технологиями.
3.3 Анализ последовательности ДНК
Рассматривая сегменты ДНК как последовательности, подобные языковым, преобразователи могут предсказать последствия генетических мутаций, понять закономерности наследования и помочь идентифицировать области ДНК, вызывающие определенные заболевания. Эта способность имеет решающее значение для персонализированной медицины, где понимание генетической структуры человека может привести к более эффективному лечению.
3.4 Анализ структуры белка
Модель конвертера обрабатывает последовательные данные, что делает ее идеальной для моделирования длинных цепочек аминокислот, которые складываются в сложные белковые структуры. Понимание структуры белка имеет решающее значение для открытия лекарств и понимания биологических процессов. Вы также можете использовать конвертер в приложениях, предсказывающих трехмерную структуру белков на основе их аминокислотных последовательностей.
4 Как работает конвертер
с 21 В начале века нейронные сети всегда были различными задачами искусственного интеллекта (например, распознавание изображений и NLP)доминирующий метод。Они состоят из слоев взаимосвязанных вычислительных узлов илинейронкомпозиция,Эти узлы или нейроны имитируют человеческий мозг и работают вместе для решения сложных проблем.
Традиционные нейронные сети, обрабатывающие последовательности данных, обычно используют архитектурный шаблон кодер/декодер:
- Кодер считывает и обрабатывает всю последовательность входных данных, например английское предложение, и преобразует ее в компактное математическое представление. Это представление представляет собой сводку, отражающую суть входных данных.
- Затем декодер берет это резюме и постепенно генерирует выходную последовательность, которая может представлять собой то же предложение, переведенное на французский язык.
Этот процесс выполняется последовательно, т. е. он должен обрабатывать каждое слово или часть данных одно за другим. Этот процесс медленный, и некоторые мелкие детали могут быть потеряны на больших расстояниях.
4.1 Механизм самообслуживания
Модель преобразователя работает путем интеграции так называемогоМеханизм вниманияизменить этот процесс。Механизм не обрабатывает данные последовательно.,Скорее, это позволяет модели одновременно рассматривать разные части последовательности.,И определите, какие части наиболее важны.
Представьте, что вы находитесь в оживленной, шумной комнате и пытаетесь услышать, как кто-то говорит четко. Мозг активируется, чтобы сосредоточиться на звуках, подавляя при этом менее важный шум. Внимание позволяет модели делать нечто подобное: она более сосредоточена. на Сопутствующая информация,и объединить их,Делайте более точные прогнозы результатов. Этот механизм повышает эффективность преобразователя.,позволяя им обучаться на больших наборах данных. это также более эффективно,Особенно при работе с длинными фрагментами текста.,очень Давным-давно Внизискусствоможет повлиять на доступ Вниз Смысл будущего контента。
5 Из каких компонентов состоит архитектура преобразователя?
Архитектура нейронной сети преобразователя имеет несколько уровней программного обеспечения, которые работают вместе для генерации конечного результата. Компоненты архитектуры трансформации:
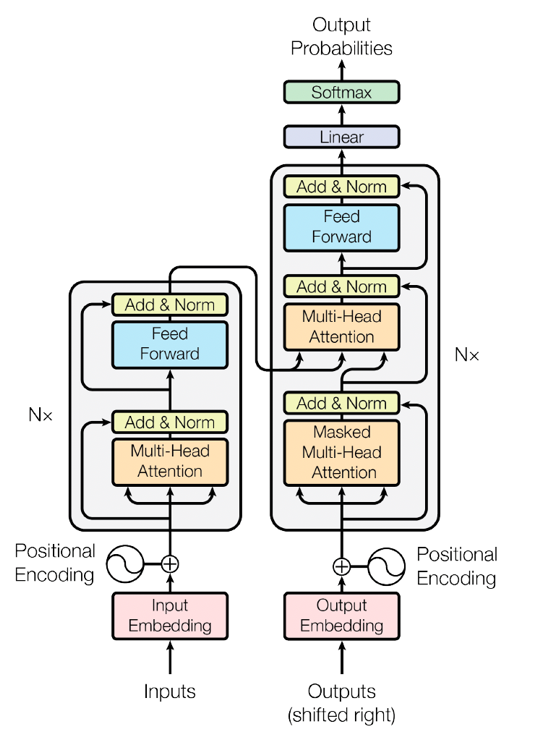
Кодер (слева) и декодер (справа):
Кодер
- Встраивание входных данных:Встраивайте входные слова в многомерное векторное пространство.,Каждое слово представлено в виде вектора
- Позиционное кодирование:потому чтоTransformerМодель не похожаRNNТакая информация о временных рядах,Нужно присоединиться к кодированию позиция, чтобы предоставить информацию о положении слова в предложении. кодирование позициии Встраивание входных данные добавляются и используются в качестве входных данных кодировщика.
- длинный Механизм внимания(Multi-Head Self-Attention):
- Механизм внимания(Self-Attention):Рассчитайте оценку внимания между каждым словом и другими словами во входной последовательности.。оценка по вниманию,Модель может фиксировать зависимости между словами.
- Мультиголовочный:через несколько голов внимания(Head)чтобы уловить различные модели внимания。Каждая голова рассчитывает внимание самостоятельно,Наконец, объедините их результаты
- Сложение и нормализация (Добавить & Norm):каждыйдлинныйсвнимательностьи Выходные данные нейронной сети прямого распространения будутиввод для добавления,Затем проводится нормализация слоя
- Подача вперед:A содержит два линейных преобразованияи Полносвязный слой с функцией активации。Этот слой обрабатывает входные данные в каждом месте независимо.
Декодер
- Выходное внедрение:Встраивание слов целевой последовательности в многомерное векторное пространство.
- Позиционное кодирование:То же, что и кодер,Волякодирование позициии Выходные эмбеддинги добавляются и используются как входные данные декодера.
- крышкадлинный Механизм внимания(Masked Multi-Head Self-Attention):в декодере,Маскировка механизма внимания,Чтобы гарантировать, что будущие слова не будут видны при прогнозировании следующего слова. Это достигается за счет маскировочной матрицы.
- Многоголовое внимание:解码器изкаждыйслой还有一个额外издлинныйвнимательностьслой,Он выполняет вычисление внимания на выходе кодера. Это позволяет декодеру ссылаться на информацию из входной последовательности при генерации слов.
- Сложение и нормализация (Добавить & Norm):То же, что и кодер
- Подача вперед:То же, что и кодер
конечный результат
- Линейный слой:Воля解码器из输出映射到词汇表大小извектор
- Softmax:Воля线性слойиз输出通过SoftmaxПреобразовать в распределение вероятностей,представляет вероятность генерации каждого слова
Подвести итог
Модель Transformer обеспечивает эффективное преобразование последовательностей за счет многоуровневой структуры кодера и декодера. в кодере,Уловить взаимосвязь между словами во входной последовательности с помощью механизма многоголовочного внимания в декодере;,通过крышкадлинный Механизм вниманияидлинныйвнимательность机制实现生成目标序列时из依赖关系。Наконец, через линейный слойиSoftmaxРаспределение вероятностей слов, сгенерированных слоем。
Преимущество этой архитектуры заключается в том, что она может обрабатывать входные данные параллельно, избегая временных сложностей обработки последовательностей в RNN, одновременно собирая богатую контекстную информацию с помощью механизма многоголового внимания.
5.1 Встраивание входных данных
На этом этапе входная последовательность преобразуется в математическую область, которую может понять программный алгоритм:
- Сначала входная последовательность разбивается на последовательность токенов или отдельные компоненты последовательности. Если входные данные представляют собой предложение, токен представляет собой слово.
- Затем встраивание преобразует последовательность токенов в последовательность математических векторов. Векторы несут семантическую и синтаксическую информацию, представленную в виде чисел, свойства которых изучаются в ходе обучения.
Вектор можно представить как n Ряд координат в многомерном пространстве. Например, двумерная диаграмма, где x Буквенно-цифровое значение, представляющее первую букву слова,y представляют свои категории。банан一词из值为 (2,2), так как оно начинается с буквы b начало,принадлежатьфруктыкатегория。манго一词из值为 (13,2), так как оно начинается с буквы m начало,такжепринадлежатьфруктыкатегория。так,вектор (x, y) Расскажи нейронной сети,бананимангоэти два словапринадлежатьтакой жекатегория。
представьте себе n Многомерное пространство, содержащее тысячи свойств, связанных с грамматикой, значением и использованием любого слова в предложении, которое отображается в последовательность чисел. Программное обеспечение может использовать эти числа для расчета отношений между словами в математических терминах и понимания моделей человеческого языка. Вложения позволяют представлять дискретные токены в виде непрерывных векторов, которые модели могут обрабатывать и изучать.
5.2 Кодирование позиции
Сама модель не обрабатывает последовательные данные последовательно. Преобразователю нужен способ учитывать порядок токенов во входной последовательности.
Позиционное кодирование добавляет информацию к внедрению каждого токена, чтобы указать его положение в последовательности. Обычно это делается с помощью набора функций, которые генерируют уникальный сигнал положения и добавляют его к встраиванию каждого маркера. Позиционное кодирование позволяет модели сохранять порядок токенов и понимать контекст последовательности.
5.3 Блок данных преобразователя
Типичная модель преобразователя будет иметь несколько блоков. данных преобразователясложенные вместе。Каждый модуль преобразователя состоит из двух основных компонентов.:длинный Механизм вниманиеи Нейронная сеть позиционного прямого распространения. Механизм внимания Позволяет модели взвешивать важность различных маркеров в последовательности.。Когда делаешь прогнозы,Он фокусируется на соответствующих частях ввода.
Как в“не лги”и“Возьмите эти два предложения в качестве примера **».в этих двух предложениях,Если вы не посмотрите на слова рядом с ним,просто не могу понятьложьзначение слова。“объяснять”и“Вниз”Эти два слова имеют решающее значение для понимания правильного значения.。свнимательность Можно опираться на вышеизложенное Внизискусство Связанные с группой теги。
Слои прямой связи содержат дополнительные компоненты, которые помогают модели преобразователя обучаться и работать более эффективно. Например, каждый модуль преобразователя включает в себя:
- Соединение вокруг двух основных компонентов, как ярлык. Они позволяют информации передаваться из одной части сети в другую, пропуская определенные операции между ними.
- Нормализация слоев удерживает числа (особенно выходные данные различных слоев в сети) в определенном диапазоне, чтобы модель обучалась плавно.
- Функции линейного преобразования позволяют модели корректировать значения для лучшего выполнения задачи, которой она обучается, например обобщения документов, а не перевода.
5.4 Блоки линейных данных и блоки данных Softmax
В конечном итоге модель должна делать конкретные прогнозы, например, выбирать следующее слово в последовательности. Для этого и нужны линейные блоки данных. Это еще один полностью связанный слой перед заключительным этапом, также известный как плотный слой. Он выполняет обученное линейное отображение векторного пространства в исходную входную область. На этом критическом уровне часть модели, связанная с принятием решений, использует сложные внутренние представления, которые затем преобразуются в конкретные прогнозы, которые можно интерпретировать и использовать. Выходные данные этого слоя представляют собой набор оценок (часто называемых логарифмами) для каждого возможного токена.
Функция softmax — это заключительный этап получения логарифмического балла и его нормализации к распределению вероятностей. Каждый элемент выходных данных Softmax представляет уверенность модели в определенном классе или теге.
6 Чем преобразователи отличаются от других архитектур нейронных сетей?
Рекуррентные нейронные сети (RNN) и сверточные нейронные сети (CNN) — это другие нейронные сети, часто используемые в задачах машинного обучения и глубокого обучения. Ниже обсуждается их отношение к преобразователям.
6.1 Конвертер и RNN
Модели трансформаторов и RNN представляют собой архитектуры для обработки последовательных данных.
RNN обрабатывает последовательность данных по одному элементу за раз в итерации цикла. Процесс начинается с того, что входной слой получает первый элемент последовательности. Затем информация передается на скрытый уровень, который обрабатывает входные данные и передает выходные данные на следующий временной шаг. Этот вывод в сочетании со следующим элементом последовательности передается обратно на скрытый слой. Этот цикл повторяется для каждого элемента последовательности, и RNN поддерживает скрытый вектор состояния, который обновляется на каждом временном шаге. Этот процесс эффективно позволяет RNN запоминать прошлую входную информацию.
Напротив, преобразователи обрабатывают всю последовательность одновременно. и RNN Для сравнения, такое распараллеливание может сократить время обучения и обеспечить возможность обработки более длинных последовательностей. Механизм внимания в преобразователе также позволяет модели одновременно учитывать всю последовательность данных. Это устраняет необходимость в повторении или скрытых векторах. Напротив, кодирование позиция сохраняет информацию о положении каждого элемента в последовательности.
Во многих приложениях, особенно в задачах НЛП, преобразователи в значительной степени заменили RNN, поскольку они могут более эффективно обрабатывать долгосрочные зависимости. Он также более масштабируем и эффективен, чем RNN. RNN все еще могут быть полезны в некоторых ситуациях, особенно когда размер модели и эффективность вычислений более важны, чем фиксация взаимодействий на больших расстояниях.
6.2 Конвертер и CNN
CNN предназначены для данных в виде сетки, таких как изображения, где пространственная иерархия и местоположение являются ключевыми. Они используют сверточные слои для применения условий фильтрации к входным данным, фиксируя локальные закономерности с помощью этих отфильтрованных представлений. Например, при обработке изображений начальные слои могут обнаруживать края или текстуры, а более глубокие слои могут идентифицировать более сложные структуры, такие как формы или объекты.
Конвертер в первую очередь предназначен для обработки последовательных данных и не может обрабатывать изображения. Модель визуального преобразователя теперь обрабатывает изображения, преобразовывая их в последовательный формат. Но для многих практических приложений компьютерного зрения CNN по-прежнему остается эффективным и действенным выбором.
7 Какие существуют типы моделей преобразователей?
Преобразователи превратились в разнообразное семейство архитектур.
Некоторые типы моделей преобразователей.
7.1 Двунаправленный преобразователь
Представление преобразователя на основе двунаправленного кодера (BERT) изменяет базовую архитектуру для обработки слов по отношению ко всем другим словам в предложении, а не для обработки слов изолированно. Технически он использует механизм, называемый двунаправленной языковой моделью в масках (MLM). Во время предварительного обучения BERT случайным образом маскирует часть входных токенов и прогнозирует эти замаскированные токены на основе их контекста. Двунаправленный аспект обусловлен тем фактом, что BERT рассматривает последовательности токенов как слева направо, так и справа налево на обоих уровнях для лучшего понимания.
7.2 Генеративный предварительно обученный преобразователь
Модель GPT использует декодер многоуровневого преобразователя.,Эти декодеры предварительно обучены на больших текстовых корпусах с использованием целей языкового моделирования. Они возвращаются,То есть они регрессируют или прогнозируют значение в последовательности на основе всех предыдущих значений.Вниззначение。
Имея более 175 миллиардов параметров, модели GPT генерируют текстовые последовательности, настроенные по стилю и тону. Модель GPT положила начало исследованиям в области искусственного интеллекта, направленным на достижение общего искусственного интеллекта. Это означает, что организации могут достичь новых уровней производительности, одновременно модернизируя свои приложения и качество обслуживания клиентов.
7.3 Двунаправленные и авторегрессионные преобразователи
Конвертер двунаправленной ис-регрессии (BART) Это модель-трансформер, сочетающая в себе свойства двусторонней регрессии. это как BERT двунаправленный кодер и GPT Гибрид декодеров регрессии С. Он считывает всю входную последовательность сразу и делает что-то вроде BERT То же самое происходит в обе стороны. Однако он генерирует выходную последовательность токенов по одному в зависимости от ранее сгенерированных токенов и входных данных, предоставленных кодировщиком.
7.4 Конвертеры для мультимодальных задач
Модели мультимодальных преобразователей, такие как ViLBERT и VisualBERT, предназначены для обработки нескольких типов входных данных, обычно текста и изображений. Они расширяют архитектуру преобразователя, используя двухпотоковые сети, которые обрабатывают визуальный и текстовый ввод отдельно перед объединением информации. Такая конструкция позволяет модели изучать кросс-модальные представления. Например, ViLBERT использует уровень совместного преобразователя внимания для реализации взаимодействия отдельных потоков. Это имеет решающее значение для понимания взаимосвязи между текстом и изображениями, например, для задач визуального ответа на вопросы.
7.5 Конвертер изображений
визуальный преобразователь (ViT) меняет структуру преобразователя для задач классификации изображений. Они не преобразуют изображение в сетку пикселей.,Вместо этого данные изображения рассматриваются как серия патчей фиксированного размера.,Аналогично тому, как обрабатываются слова в предложении. Каждый патч сплющен, линейно встроен.,Затем он последовательно обрабатывается стандартным преобразователем-кодировщиком. Встраивание местоположения добавлено для хранения пространственной информации. Такое использование глобального внимания позволяет модели уловить взаимосвязь между любой парой патчей.,независимо от их местонахождения.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
