[Повторение статьи] Самоконтролируемое распознавание поведения — разделение пространственных и временных подсказок
введение
Распознавание скелетных действий с самоконтролем — это метод, который использует немаркированные скелетные данные для распознавания действий. Традиционные методы распознавания поведения обычно требуют большого количества размеченных данных для обучения, но получение размеченных данных обходится дорого. Самообучению можно обучать при отсутствии размеченных данных, разрабатывая задачи, которые автоматически генерируют метки.

При самоконтролируемом распознавании поведения скелетов данные о скелетах можно получить с помощью таких устройств, как датчики или камеры глубины. Эти данные содержат информацию о положении и движении суставов человека. Ключом к задаче самостоятельного обучения является разработка метода, который может автоматически генерировать метки из немаркированных скелетных данных.
В процессе обучения обучение с самоконтролем осуществляется с использованием неразмеченных скелетных данных для создания псевдометок. Сгенерированные псевдометки затем используются для обучения контролируемой модели распознавания скелетных действий. Таким образом, обучение с самоконтролем может стать эффективным методом распознавания скелетного поведения в отсутствие размеченных данных.
Итак, с какими проблемами в настоящее время сталкиваются скелеты с самоконтролируемым поведением?
Проблема 1. Путаница пространственно-временной информации
Кодер отвечает за отображение входных данных в скрытом пространстве, которое можно сравнивать. Большинство предыдущих методов направлены на получение единой информации с помощью широко используемых сетей пространственно-временного моделирования. Их конструкция привела к перепутыванию временной и пространственной информации и не позволила дать четкие инструкции для последующих сравнительных измерений.
Проблема 2. Ограничения увеличения данных
Более того, существующие методы часто ограничиваются масштабными преобразованиями (общие стратегии улучшения, такие как обрезка, ротация), что приводит к невозможности полностью использовать потенциал увеличения данных.
Проблема 3. Неспособность учесть возможность переноса метода
Во время оптимизации большинство методов сосредотачиваются на построении сравнений на одном и том же уровне представления; Игнорируйте пробелы между доменами (в рамках одной задачи или внутри набора данных).
1. Обзор статьи
SCD-NET(SCD-Net: Spatio temporal Clues Disentanglement Network for Self-Supervised Skeleton-Based Action Recognition AAAI2024)Представляем новую контрастирующую структуру обучения,То есть сеть развязки пространственных и временных подсказок (SCD-Net). В частности, модуль развязки объединяется с экстрактором признаков для получения явных сигналов из пространственной и временной областей соответственно. Для обучения SCD-Net создается глобальный якорь, который побуждает якорь взаимодействовать с извлеченными сигналами. Кроме того, в этой статье предлагается новая стратегия маскировки со структурными ограничениями для усиления контекстуальной ассоциации, используя моделирование замаскированных изображений в предлагаемой сети SCD-Net. По результатам эксперимента,существоватьNTU-RGB+D(60&120)иPKUMMD (I&II)данные Набор прошел тщательную оценку,Охватывает различные последующие задачи,Такие как распознавание действий, извлечение действий, трансферное обучение и полуконтролируемое обучение. Результаты экспериментов демонстрируют эффективность метода.,Значительно превосходит существующие современные методы (SOTA).
2. Основные моменты инноваций
Чтобы решить три проблемы, с которыми сталкивается самоконтроль, в этой статье предлагаются три метода их решения соответственно. Во-первых, по проблеме путаницы пространственно-временной информации автор предлагает кодер двунаправленного интерфейса с точки зрения улучшения данных, различные стратегии улучшения данных устанавливаются соответственно во времени и пространстве с точки зрения переносимости метода, потери контрастности; установлен, а подробную архитектуру можно увидеть ниже. SCD-NETОбщая архитектура выглядит следующим образом.:скелетданные->данные Усиливать(data После аугментации они отправляются на уровень кодера (encoder) и уровень кодировщика импульса (Momentum Каждый кодер использует двунаправленный кодер с развязкой и после прохождения через экстрактор признаков (функция). экстрактор), соответственно развязывают пространство (пространственные развязка), временная развязка (временная развязка) операция для получения характеристик разных размеров. Выходные данные, полученные кодером импульса, используются в качестве ключевого вектора, а выходные данные, полученные обычным кодером, используются в качестве вектора запроса. Наконец, ключевой вектор и вектор запроса сравниваются и изучаются.
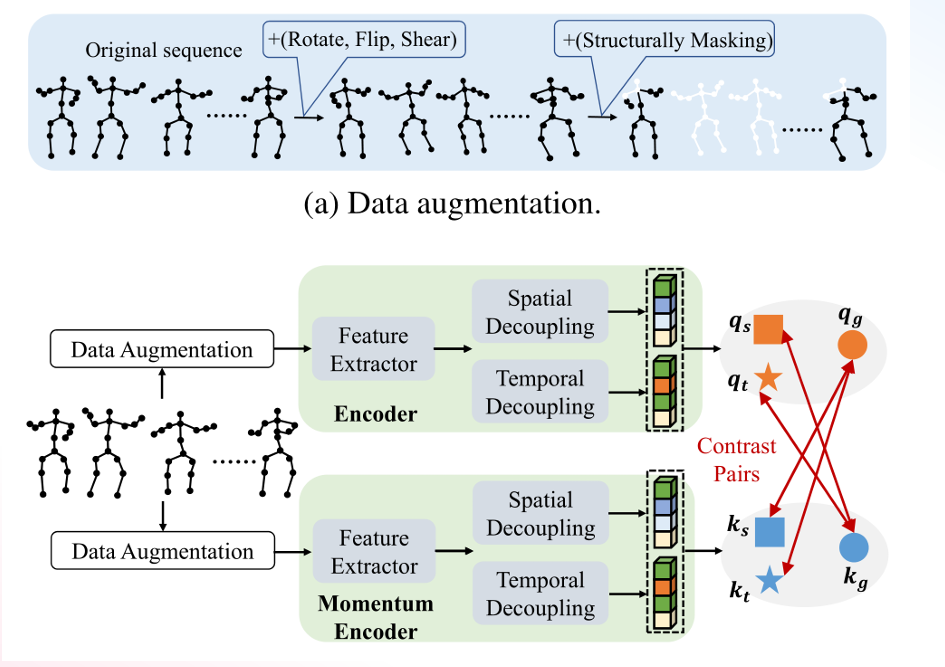
2.1 Двунаправленный энкодер с развязкой
В общем, признаки, извлеченные из скелетных последовательностей, описываются как сложные пространственно-временные корреляции, описывающие действия. Однако в этой статье считается, что эта парадигма не подходит для контрастного обучения. Поскольку информация настолько запутана,трудно дать четкие указания для последующих сравнений. В SCD-Net в этой статье предлагается двусторонний кодер с развязкой для извлечения временной и пространственной информации из информации сложной последовательности для получения лучшего различительного представления. Двунаправленный энкодер с развязкой Структура показана ниже.:Разделено на моделирование(projection)иусовершенствовать(refinement)этап,пара космических частейCTРазмеры для объединения,Сохраните размер V (представляющий костные суставы).,Затем выполните операцию встраивания, чтобы получитьскелеткартина->сериализация–>transformer кодер->пространственное объединение->пространственные особенности;пара частей времениCCРазмеры для объединения,Сохраняйте размер T (представляющий видеокадр),Затем выполните операцию встраивания, чтобы получить совместную последовательность->сериализация–>transformer кодер->объединение времени->временные характеристики;
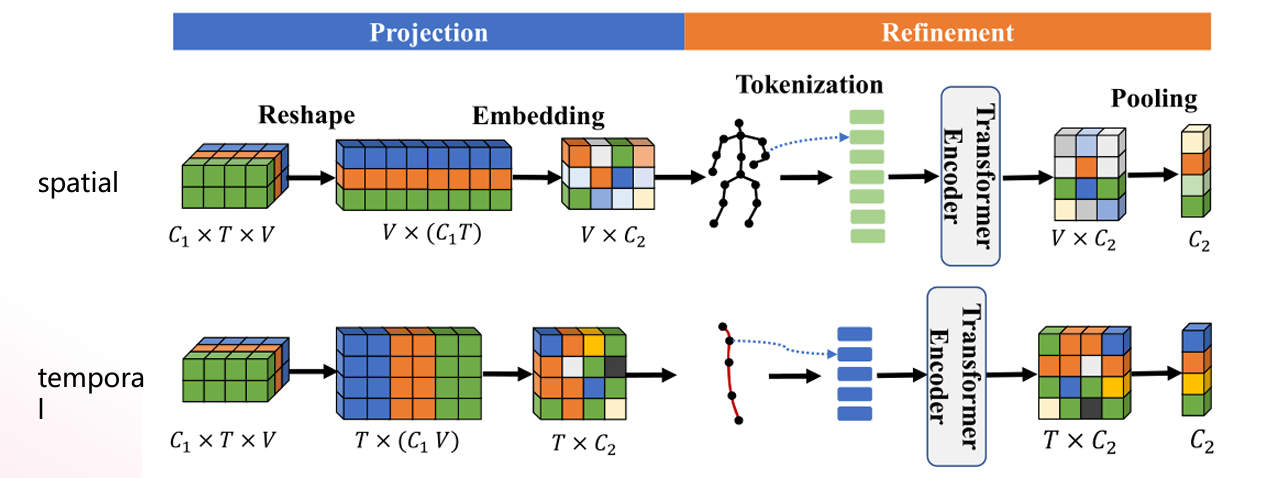
# Двунаправленный энкодер с развязкой
vt = self.gcn_t(x)
vt = rearrange(vt, '(B M) C T V -> B T (M V C)', M=2)
vt = self.channel_t(vt)
vs = self.gcn_s(x)
vs = rearrange(vs, '(B M) C T V -> B (M V) (T C)', M=2)
vs = self.channel_s(vs)
vt = self.t_encoder(vt) # B T C
vs = self.s_encoder(vs)
# implementation using amax for the TMP runs faster than using MaxPool1D
# not support pytorch < 1.7.0
vt = vt.amax(dim=1)
vs = vs.amax(dim=1)
return vt, vs2.2. Построение потерь междоменного сравнения
Используя разделенное пространственно-временное представление, в этой статье сначала получается окончательное представление следующим образом: ZS и Zt соответственно представляют нормализованные характеристики пространственных и временных характеристик, где Fs и Ft — соответствующие функции проекции. Запрос получается после отображения функции. Векторы признаков qs, qt
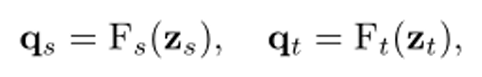
Существует очевидный разрыв между пространственной и временной областями. По этой причине в этой статье вводится глобальная перспектива qg, которая совместима с обеими областями в качестве промежуточного звена для сравнения характеристик времени и пространства, где Fg — функция проекции, соответствующая совместному пространству и время.
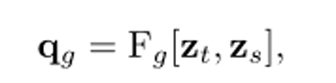
На основе этих потенциальных функций в данной статье определяется новая междоменная потеря. Суть проекта заключается в привязке глобального представления и его связи с другими представлениями, полученными другими кодировщиками. Функция потерь определяется как:
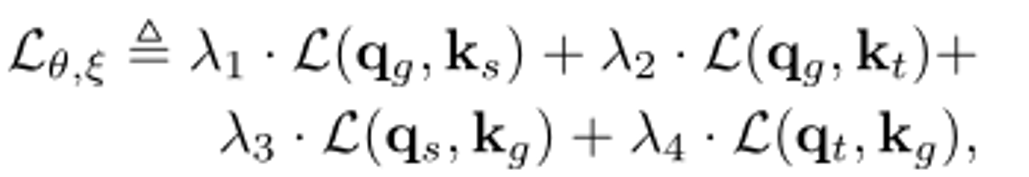
Целью этой конструкции является уменьшение снижения точности распознавания, вызванного междоменным взаимодействием. Поэтому при разработке функции потерь необходимо сравнить каждую комбинацию кодировщика запроса и кодировщика ключа и сравнить потери в пространстве. времени и в глобальном масштабе.
# Положительные и отрицательные образцы и функция потери дизайна
def forward(self, q_input, k_input):
Определение трех векторов запроса
qt, qs, qi = self.encoder_q(q_input) # queries: NxC
qt = nn.functional.normalize(qt, dim=1)
qs = nn.functional.normalize(qs, dim=1)
qi = nn.functional.normalize(qi, dim=1)
# Рассчитать ключевые характеристики
with torch.no_grad(): # no gradient to keys
self._momentum_update_key_encoder() # update the key encoder
kt, ks, ki = self.encoder_k(k_input) # keys: NxC
kt = nn.functional.normalize(kt, dim=1)
ks = nn.functional.normalize(ks, dim=1)
ki = nn.functional.normalize(ki, dim=1)
# Положительные и отрицательные образцы
l_pos_ti = torch.einsum('nc,nc->n', [qt, ki]).unsqueeze(1)
l_pos_si = torch.einsum('nc,nc->n', [qs, ki]).unsqueeze(1)
l_pos_it = torch.einsum('nc,nc->n', [qi, kt]).unsqueeze(1)
l_pos_is = torch.einsum('nc,nc->n', [qi, ks]).unsqueeze(1)
l_neg_ti = torch.einsum('nc,ck->nk', [qt, self.i_queue.clone().detach()])
l_neg_si = torch.einsum('nc,ck->nk', [qs, self.i_queue.clone().detach()])
l_neg_it = torch.einsum('nc,ck->nk', [qi, self.t_queue.clone().detach()])
l_neg_is = torch.einsum('nc,ck->nk', [qi, self.s_queue.clone().detach()])
# Функция потерь
logits_ti = torch.cat([l_pos_ti, l_neg_ti], dim=1)
logits_si = torch.cat([l_pos_si, l_neg_si], dim=1)
logits_it = torch.cat([l_pos_it, l_neg_it], dim=1)
logits_is = torch.cat([l_pos_is, l_neg_is], dim=1)
logits_ti /= self.T
logits_si /= self.T
logits_it /= self.T
logits_is /= self.T2.3 Улучшение структурированных данных
Пространственная и временная части этой позиции предлагают разные стратегии улучшения соответственно. Пространственная часть предлагает Пространственное маскирование на основе структуры, а временная часть предлагает Временную маску на основе. конвейера.
Пространственное маскирование на основе структуры
Учитывая физическую структуру скелета, когда для маскировки выбран определенный сустав, модель может извлечь соответствующую информацию из окружающих точек, и эффект маскировки будет неудовлетворительным. Налагая структурные ограничения, наш метод применяет операцию маскировки в локальной области вокруг текущего случайно выбранного сустава или кадра, а не полагается исключительно на изолированные точки для одновременной маскировки соседних областей. Пусть в этой статье используется матрица p для представления отношений смежности. Если соединения i и j соединены, то Pij = 1, в противном случае Pij = 0. Пусть D = Pn. Чтобы наложить структурные ограничения при выборе узла i, в этой статье анализируется Dij! = 0 выполняет одну и ту же операцию улучшения на всех узлах j.
Временная маска на основе конвейера
Временная маска на основе Основная идея конвейера заключается в извлечении ключевых поведенческих характеристик путем разделения данных временных рядов на несколько конвейеров и генерации соответствующих временных масок для каждого конвейера. В частности, временная маска — это двоичная последовательность, которая указывает важные периоды времени во временном ряду. Сегментируя данные временных рядов и выборочно применяя временные маски к каждому конвейеру на основе конкретных поведенческих задач и требований к функциям. Ниже структурной схемы: Преимущество этого подхода в том, что он позволяет сосредоточить внимание на периодах времени, которые наиболее полезны для распознавания действий, тем самым улучшая способность модели воспринимать ключевые действия. Генерация временных масок может выполняться в соответствии с различными стратегиями, такими как методы на основе порогов, энергии или распознавания образов. Полученную временную маску можно использовать в качестве веса входных данных, чтобы скорректировать важность, которую модель придает различным периодам времени.
3. Развертывание проекта
3.1 Подготовительные работы
Среда Пайторча
Чтобы установить пакеты зависимостей, выполните следующую команду
pip install -r requirements.txt
3.2 Подготовка данных
Генерировать данные Скачать набор данных
Обработка данных
- Обработайте данные с помощью следующего кода: python ntu_gendata.py.
3.3 тренироваться&тест
тренироваться
- тренироваться NTU-RGB+D 60данныенабор существовать Cross-Subject Предварительно тренироваться Модель по критериям оценки, Запустите следующую команду
python ./pretraining.py --lr 0.01 --batch-size 64 --encoder-t 0.2 --encoder-k 8192 \
--checkpoint-path ./checkpoints/pretrain/ \
--schedule 351 --epochs 451 --pre-dataset ntu60 \
--protocol cross_subject --skeleton-representation jointтест
- тестбумагаданный Модельсуществовать По задаче распознавания поведенияNTU-RGB+D 60 данныенабор Cross-Subject Результаты по критериям оценки, Запустите следующую команду
python ./action_classification.py --lr 2 --batch-size 1024 \
--pretrained ./checkpoints/pretrain/checkpoint.pth.tar \
--finetune-dataset ntu60 --protocol cross_subject --finetune_skeleton_representation joint- тестбумагаданный Модельсуществовать Под задачей поведенческого поискаNTU-RGB+D 60 данныенабор Cross-Subject Результаты по критериям оценки, Запустите следующую команду
python ./action_retrieval.py --knn-neighbours 1 \
--pretrained ./checkpoints/pretrain/checkpoint.pth.tar \
--finetune-dataset ntu60 --protocol cross_subject --finetune-skeleton-representation joint4. модификация ошибки
При воспроизведении исходного кода и непосредственном запуске файла ./pretraining появится следующая ошибка:
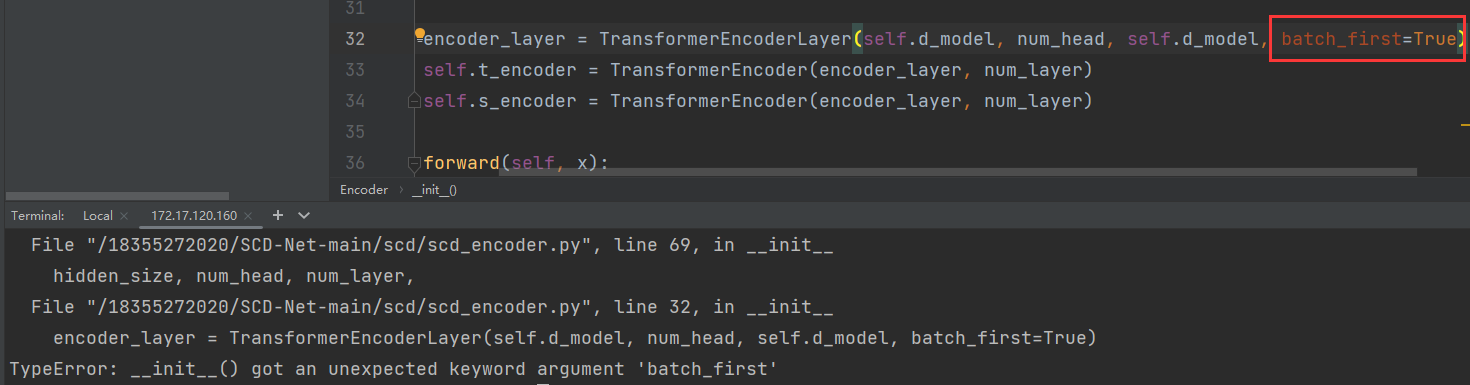
Ошибка заключается в следующем: TypeError: init() got an unexpected keyword argument ‘batch_first’ Анализ причин: У метода init нет параметра «batch_first», поэтому просто удалите пакет_first. При изменении параметра patch_first обязательно вводите данные одновременно для синхронной настройки. В частности, входное измерение, когда пакет_первый=True, равен (batch, seq, функция), в противном случае соответствующее входное измерение необходимо скорректировать до (seq, batch, feature) Решение: Замените часть encoder_layer в коде ошибки следующим кодом, и он будет работать нормально:
encoder_layer = TransformerEncoderLayer(self.d_model, num_head, self.d_model)
self.t_encoder = TransformerEncoder(encoder_layer, num_layer)
self.s_encoder = TransformerEncoder(encoder_layer, num_layer)
def forward(self, x):
vt = self.gcn_t(x)
vt = rearrange(vt, '(B M) C T V -> B T (M V C)', M=2)
vt = self.channel_t(vt)
vs = self.gcn_s(x)
vs = rearrange(vs, '(B M) C T V -> B (M V) (T C)', M=2)
vs = self.channel_s(vs)
# Входное измерение, когда пакетный_первый=True, равен (batch, seq, feature),
# В противном случае соответствующее входное измерение необходимо скорректировать до (seq, batch, feature)
# Отрегулируйте размеры с помощью функции транспонирования
vt = vt.transpose(0, 1) # Отрегулируйте (T, B, M*V*C)
vs = vs.transpose(0, 1) # Отрегулируйте (T, B*M*V, C)
vt = self.t_encoder(vt) #
vs = self.s_encoder(vs) #
vt = vt.amax(dim=1)
vs = vs.amax(dim=1)
return vt, vsБудущее программирования начинается здесь! Раскройте безграничный творческий потенциал, пусть каждая строка кода станет вашей лестницей к успеху и помогите большему количеству людей оценить и учиться!



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
