Postman импортирует запросы в jmeter для простого нагрузочного тестирования, которому студенты-разработчики могут научиться в кратчайшие сроки.
фон
Это то, что я сделал недавно, потому что я заменил онлайн-nginx на openresty, а затем служба уровня доступа также внесла серьезные изменения. Хотя параллелизм нашего приложения (типа внутреннего офиса) не высок, нам все равно нужно провести стресс-тест. , я чувствую себя немного более стабильно, когда выхожу в Интернет.
Поэтому я использовал jmeter, чтобы провести простой стресс-тест и записать его здесь.
На этот раз я нашел несколько интерфейсов для подавления: интерфейс входа в систему, интерфейс для получения информации о пользователе после входа в систему и интерфейс для записи данных после входа в систему.
Поскольку эти интерфейсы доступны в postman, мне лень вводить их в jmeter вручную (такая форма, лень делать это по одному). Единственное, что нужно решить, — смогу ли я экспортировать запросы в него. почтальон, а затем импортируйте их в jmeter.
Почтальон просит импортировать jmeter
экспорт почтальона
Напоминаем: если запрос отсутствует в Postman, вы также можете использовать захват пакетов (charles, fiddler), чтобы экспортировать запрос в формат Curl в charles, а затем импортировать его в Postman.
Способ импорта jmeter почтальоном также относительно прост. Кто-то в Интернете написал для этого библиотеку с открытым исходным кодом.
Сначала экспортируйте:
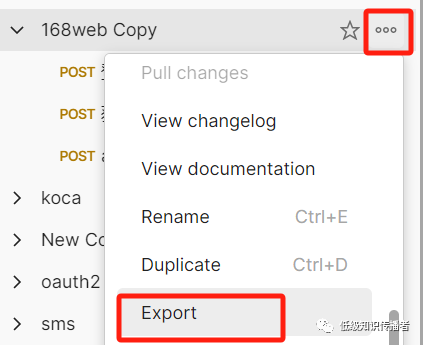
image-20231015100947681

image-20231015101004277
В итоге вы получите файл JSON.
Преобразование файла json в jmx jmeter
Используется библиотека с открытым исходным кодом, также написанная на Java:
https://github.com/Loadium/postman2jmx
Когда я его использовал, у меня в почтальоне возникла проблема с запросом, из-за которой сообщался нулевой указатель. Потом я сам отладил и решил, так что вы можете вытащить его из моего склада:
https://github.com/cctvckl/postman2jmx
Я также отправил запрос на первоначальный склад.
Как использовать:
$ git clone https://github.com/Loadium/postman2jmx.git
$ cd postman2jmx
$ mvn package
$ cd target/Postman2Jmx
$ java -jar Postman2Jmx.jar my_postman_collection.json my_jmx_file.jmx
Обычно в конечном итоге вы получаете файл my_jmx_file.jmx, который можно импортировать в jmeter.
конфигурация jmeter
Импортировать эффекты
Открыв этот jmx, я внес несколько изменений, добавил номер результата просмотра и изменил конфигурацию группы потоков, которая выглядит примерно следующим образом:
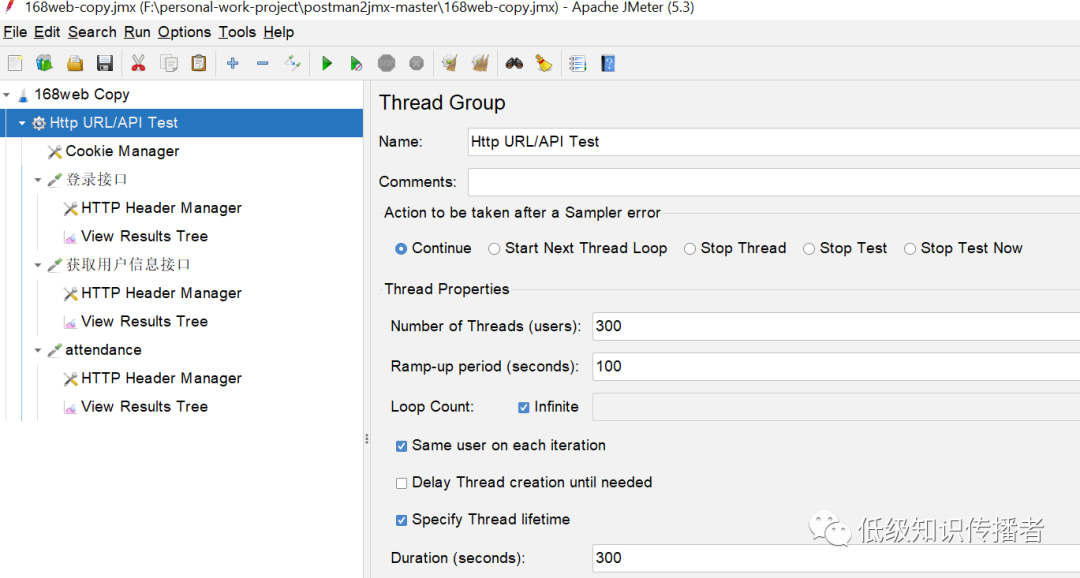
image-20231015103852884
Мой проект по-прежнему опирается на механизм cookie, поэтому я использую менеджер cookie. Он автоматически сохранит возвращенный set-cookie в области cookie потока, и последующие запросы будут автоматически переносить его:
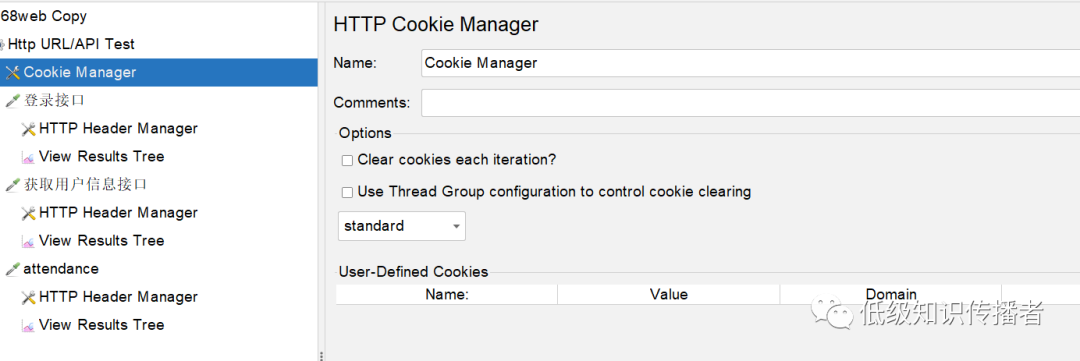
image-20231015104333902
Если вы не понимаете, вы можете нажать «Справка» на этой странице, чтобы просмотреть справочную документацию.
image-20231015104444341
Эффект импорта довольно хороший:
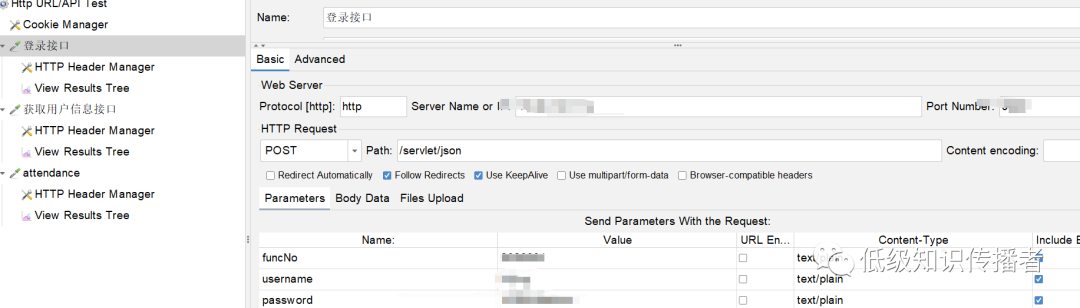
image-20231015104759417
Установка количества одновременных потоков в группе потоков
Вообще говоря, во время стресс-тестирования мы фокусируемся на qps или tps определенного интерфейса. В это время нам обычно нужно добавить прослушиватель, например совокупный отчет, для просмотра конечной пропускной способности интерфейса (tps):
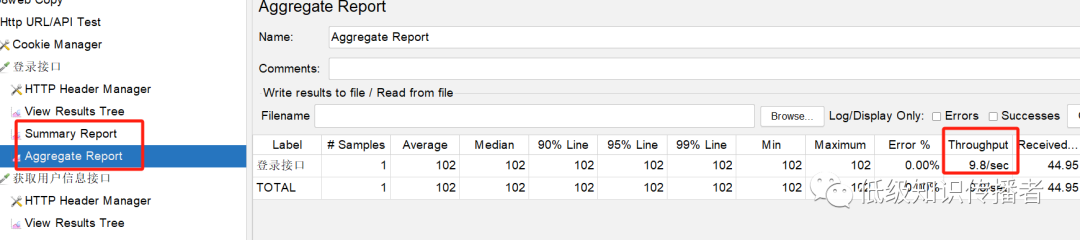
image-20231015110645808
Обычно мы используем jmeter для стресс-тестирования. Нам нужно провести стресс-тестирование, чтобы выяснить, каков предел интерфейса в текущей архитектуре и среде и сколько перьев/сек он может достичь. В настоящее время нам необходимо постоянно увеличивать его. давление (например, увеличение давления) (количество одновременных пользователей). По мере увеличения давления на систему значение пропускной способности системы может вначале полностью увеличиваться, но постепенно оно достигнет точки перегиба. В этот момент, какое бы сильное давление вы ни применяли, оно не будет продолжать увеличиваться, и в это время я достиг предела tps.
Конечно, мы также можем повысить давление до определенного уровня и обнаружить, что tps интерфейса достигает стандарта. Мы проигнорируем это и не будем продолжать повышать давление, чтобы найти точку перегиба tps при возрастающем давлении.
Однако раньше у меня всегда была проблема, то есть я не знаю, как задать количество одновременных потоков в jmeter. После проверки я обнаружил, что в области тестирования производительности индустрия обычно называет это значение VU ( виртуальный пользователь).
Когда тестеры производительности составляют планы тестирования, они сначала оценивают это значение, исходя из размера пользователей системы и продолжительности часов пиковой нагрузки системы. Вообще говоря, это все еще немного сложно. Я также прочитал здесь книгу «Руководство по обучению полнофункциональному тестированию производительности», в которой в главе 7 объясняется, как конкретно ее рассчитать.
Я также кратко проверил онлайн, например:
https://www.cnblogs.com/gltou/p/15168252.html
общая формула
Для большинства сценариев мы используем:
одновременно объем = (общее количество пользователей/статистическое время) * импакт-фактор (обычно 3) для оценки.
#Общее количество пользователей и статистическое время рассчитываются по принципу 2/8, то есть 80% пользователей концентрируются на 20% времени
#Фактор влияния, обычно 3, в зависимости от реальной ситуации
#Общая формула использует принцип 80-20, и рассчитанная одновременно сумма является пиковой одновременной суммой.
пример
Ехать на метро - это пример,Количество пассажиров в день – 50 000.,Утренний пик — с 7 до 9 часов каждый день.,Вечерний пик – с 6 до 7 часов.,По правилу 2/8,80% пассажиров будут ездить в метро в часы пик,Тогда количество людей, прибывающих к кассе метро в секунду, составит 50000*80%/(3 часа*60*60с)=3,7.,Около 4 человек/с,Рассмотрим проверку безопасности,Закрытие входа и другие факторы,Фактическое количество людей, скопившихся у билетных касс, должно быть больше этого значения.,Предположим, каждому человеку требуется 3 секунды, чтобы войти на станцию.,Тогда фактическое количество одновременно должно составлять 4 человека/с*3с=12.,Конечно, импакт-фактор может быть увеличен в зависимости от реальной ситуации!В этом примере с метро расчетное количество одновременных пользователей должно быть установлено равным 12.
Затем пример из другой статьи, этот рассчитан на основе PV:
Рассчитано на основе PV
одновременно объем = (дневное PV/статистическое время) * импакт-фактор (обычно 3)
#Daily PV и статистическое время рассчитываются по принципу 2/8, то есть 80% пользователей концентрируются на 20% времени
#Фактор влияния, обычно 3, в зависимости от реальной ситуации
В формуле #PV используется принцип 80-20, а рассчитанная сумма одновременно является пиковой суммой одновременно.
пример
Например, на сайте около 10 миллионов PV в день. По принципу 2/8 можно считать, что 80% из этих 10 миллионов PV выполняется за 9 часов в день (энергия человека ограничена), тогда TPS составляет: 1000w*80%/(9*60*60)=246,92 шт./с, принимая коэффициент опыта 3, тогда количество должно быть: 246,92*3=740
Поэтому после окончательного расчета количество одновременных пользователей на самом деле не очень велико. Для общих систем кажется, что количество одновременных потоков в jmeter должно контролироваться в пределах 500. Если нет, достаточно 1000. Если оно превышает 1000, посмотрите, стоит ли вам рассмотреть возможность использования нескольких экземпляров jmeter для распределенного стресс-тестирования, потому что, как правило, для относительно крупных предприятий, таких как крупные компании, стресс-тестирование является распределенным стресс-тестированием, и на Тайване есть десятки кластеров машин для стресс-тестирования.
Конечно, если вам нужно отчаянно увеличить количество потоков в одном экземпляре jmeter (то есть Java-процессе), вы можете прочитать следующую статью:
https://www.blazemeter.com/blog/jmeter-maximum-concurrent-users
Давайте посмотрим, как увеличить количество потоков до 10 000 за счет увеличения размера кучи, но я все равно не рекомендую это делать, ведь машины обычно имеют всего несколько ядер или десятки ядер. Открытие такого большого количества потоков приведет. к частому переключению потоков.
Настройки других свойств в группе потоков
Следующий рисунок является примером:
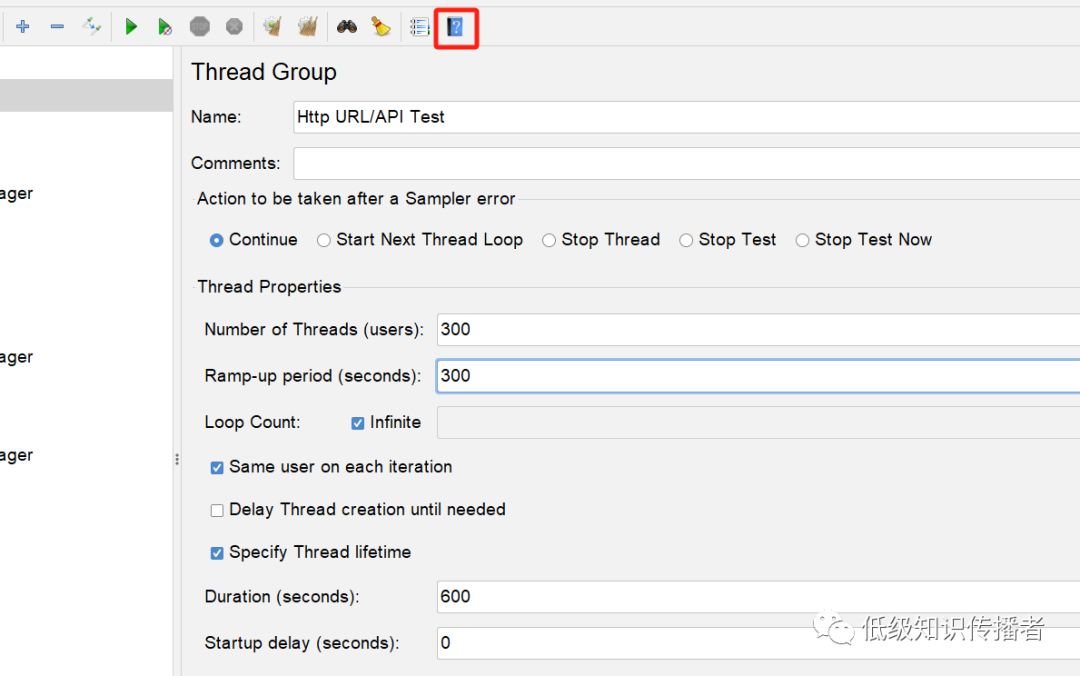
image-20231015130928277
300 потоков, но период нарастания составляет 300 с, что означает, что мои 300 потоков будут запущены в течение 300 с, что означает, что один будет добавляться каждые 1 с, если вы установите значение 1, 300 потоков будут запускаться в течение 1 с; что воздействие на компьютер относительно велико, поэтому лучше действовать мягче.
Число циклов здесь установлено на бесконечное значение. Итак, весь сценарий продолжает работать? Конечно, нет. Как вы можете видеть на рисунке выше, я установил продолжительность на 600 секунд, что означает, что сценарий выполняется в общей сложности 10 минут. .
Что можно предсказать:
В первые 300 секунд оно будет постепенно увеличиваться с 1 потока до 300 потоков; в следующие 300 секунд 300 потоков будут одновременно запускать сценарии.
запуск jmeter
При проведении строгого стресс-тестирования мы обычно не запускаем его в графическом интерфейсе, а используем метод cli.
Например, используйте метод cli для выполнения стресс-тестирования в Windows:
F:\apache-jmeter-5.2.1\bin>jmeter -n -t Test.jmx -l result.jtl -j test.log
Или выполните стресс-тест под Linux:
./jmeter -n -t Test.jmx -l result.jtl
Долгосрочный стресс-тест
nohup ./jmeter -n -t Test.jmx -l result.jtl 2>&1 &
Во время стресс-теста будет выдан следующий результат:
summary = 3801 in 00:00:40 = 94.5/s Avg: 417 Min: 13 Max: 3817 Err: 0 (0.00%)
Указывает, что это 40-я секунда после начала стресс-теста, 3801 — общее количество отправленных запросов, 94,5/с — количество tps за этот период, за которым следует среднее, минимальное, максимальное и количество ошибок.
Через некоторое время появится что-то вроде этого:
summary + 2590 in 00:00:35 = 74.3/s Avg: 1076 Min: 97 Max: 9799 Err: 0 (0.00%) Active: 151 Started: 151 Finished: 0
summary = 6391 in 00:01:15 = 85.1/s Avg: 684 Min: 13 Max: 9799 Err: 0 (0.00%)
Строка с + представляет собой приращение. С момента окончания предыдущей строки прошло 35 секунд. За эти 35 секунд было сгенерировано 2590 запросов. Значение tps за этот период составило 74,3.
Строка с = — это общий показатель с начала скрипта на данный момент, например количество запросов 6391, то есть количество запросов за 40 секунд 3801 + добавочное 2590.
Кстати, покажу, что перед выходом в интернет в этот раз, чтобы проверить стабильность, я нажимал ее 18 часов:
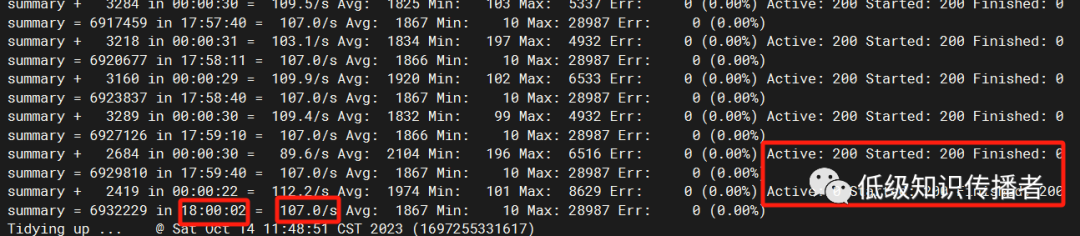
image-20231015132432013
Кроме того, надпись «Активный» сзади означает количество активных потоков. Я использовал 200 и нажимал ее в течение 18 часов. Когда я пришел туда на следующий день, я обнаружил, что система все еще достаточно стабильна.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
