Последняя версия — полное руководство по развертыванию автономной версии Hadoop3.3.6.

Привет всем, я Дугу Фэн, автор Big Data Flow.
Эта статья написана на основе последней версии Hadoop 3.3.6 и поможет вам полностью понять использование Apache Hadoop в автономной версии. В этой статье особое внимание уделяется практике. Практика является важной частью изучения больших данных, и вы также можете получить более глубокое понимание технологии на практике. Поэтому некоторые теоретические знания рекомендуют вам прочитать больше соответствующих книг (все в информационном пакете).
Авторские права на этот документ принадлежат Big Data Flow, не используйте его в коммерческих целях. Чтобы получить полный набор учебных материалов по большим данным, управлению данными и искусственному интеллекту, обратите внимание на Big Data Flow.
(Расположение пакета данных, используемого в этой статье: База знаний Big Data Flow VIP 》Технологии больших данных 》Автономный установочный пакет Apache Hadoop 3.3.6)
1. Обзор Hadoop
Apache Hadoop — это платформа с открытым исходным кодом для хранения и обработки крупномасштабных наборов данных. Он написан на Java и поддерживает распределенную обработку. Ключевые особенности Hadoop включают в себя:
- Распределенное хранилище:проходить Hadoop Распределенная файловая система (HDFS),Он может охватывать несколько узлов, в которых хранится большое количество данных.,Обеспечивает высокую надежность иданные резервирования.
- распределенные вычисления:Hadoop использовать MapReduce Модель программирования для параллельной обработки больших размеров данных, что позволяет эффективно обрабатывать и анализировать. HDFS Средний объем массивного набора данных.
- Масштабируемость:Hadoop Возможность легкого масштабирования путем добавления дополнительных узлов для обработки больших объемов.
- отказоустойчивость:Hadoop Проектирование учитывает возможность выхода из строя,Возможность продолжать работу даже в случае сбоя узла,Убедитесь, что данные не потеряны.
5.экосистема:Hadoop Экосистема включает в себя различные инструменты и расширения, такие как Hive、HBase、Spark и т. д.) для обработки, анализа и управления данными.
Hadoop широко используется в анализе больших данных, интеллектуальном анализе данных, обработке журналов и других областях и особенно эффективен в сценариях, где необходимо обрабатывать данные на уровне PB.
Таким образом, мы можем понять, что Hadoop — это экосистема. В основе Hadoop, последующие компоненты, такие как Spark и Flink, появились один за другим, что позволило непрерывно развивать технологии больших данных.
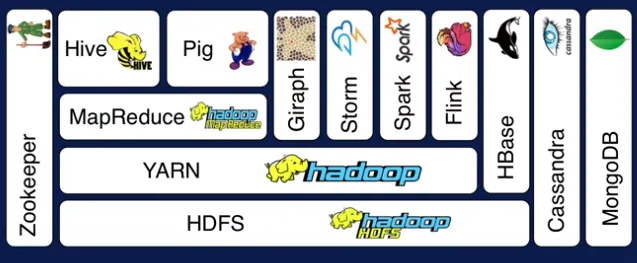
С точки зрения программного обеспечения Hadoop сам по себе является программным обеспечением Apache с открытым исходным кодом.

Apache Hadoop в основном состоит из следующих основных компонентов, каждый из которых имеет свои уникальные функции:
1. Hadoop Common:этотда Hadoop Коллекция базовых библиотек, которая предоставляет Hadoop Общие инструменты и интерфейсы, необходимые модулям. Он включает в себя файловую систему, абстракции уровня операционной системы и необходимые Java файл библиотеки.
- Hadoop MapReduce (MR):этотдамодель программирования,использовать ВСправляйтесь с большими масштабамиданныенаборизраспределенные вычисления。MapReduce Работа Воля разделена на два этапа: Карта (обработка) и Уменьшать. Этот подход обеспечивает параллельную обработку больших Данные стали простыми и эффективными.
- Hadoop YARN (Yet Another Resource Negotiator):YARN да Hadoop из «Управление ресурсами» и «Планировщик заданий». Это воля функции управления вычислительными ресурсами и планирования заданий от MapReduce отделенный от, улучшенный Hadoop изгибкостьи Масштабируемость。
- Hadoop Distributed File System (HDFS):HDFS да Распределенная файловая система с высокой отказоустойчивостью, предназначенная для обработки больших объемов данных. Он может работать на дешевом оборудовании, обеспечивает высокую пропускную способность для данных Алиэкспресс и подходит для приложений с большими объемами данных. Данные эпизодов из приложения.
Вместе эти компоненты делают Hadoop мощным инструментом для хранения, обработки и анализа крупномасштабных наборов данных.

Common — базовая библиотека. Из-за проблем с производительностью распределенные вычисления MapReduce были заменены более эффективными вычислительными механизмами, такими как Spark и Flink.
нодаHDFS,YARNвсе ещеда Ядроиздва компонента,Должен усердно учиться,Я также опубликую отдельные статьи, чтобы изучить эти два компонента.




2. История Hadoop
Конечно, вот обзор истории Apache Hadoop в формате Markdown:
- 2005 - ИстокиЗависит от Doug Cutting и Mike Cafarella создать,получить Google из MapReduce и GFS Эссе вдохновение. (Google Расположение китайской версии трех теорий: большой поток данных VIP база знаний 》большие данныетехнология 》Google Три вагона)
- 2006 – присоединился к Apache.становиться Apache Часть Software Foundation, первоначально да Lucene Проект частично, позже существовал 2008 Год стал топ-проектом.
- 2008 г. и далее – Развитие и популяризацияПолучите это быстрососредоточиться на, экосистема продолжает развиваться, добавляя такие HBase、Hive и другие инструменты.
- 2011 г. — выпущен Hadoop 1.0.отметка Hadoop зрелый, стабильный API и основные компоненты, включая HDFS и MapReduce。
- 2013 Год - Hadoop 2.0 иYARNиз推出引入 YARN,Воля Hadoop Впредь MapReduce Превратите центральную платформу в более универсальную платформу обработки данных.
- Непрерывная эволюция -Hadoop Постоянно обновляемая, расширяющая свои функциональные возможности иэкосистема, в том числе Spark、Kafka、Flink и другие инструменты.
- Облачная интеграция —закрывать Год Приходить,Интеграция с облачными сервисами,Предоставляйте более гибкие и масштабируемые решения для обработки.
Hadoop — это не только Apache Hadoop. Многие компании имеют свои собственные дистрибутивы. Различные дистрибутивы оптимизированы для разных целей и сценариев. Пользователи могут выбрать наиболее подходящую версию в соответствии со своими потребностями. Эти дистрибутивы могут со временем меняться по мере появления новых версий или прекращения поддержки старых версий.
Помимо Apache Hadoop, существуют также Cloudera CDH (Cloudera Distribution Include Apache Hadoop) и Hortonworks Data Platform (HDP), то есть CDH и Ambari. В этой статье мы приведем демонстрацию. Автономная версия Apache Hadoop также является наиболее используемой версией.
3. Автономная установка Hadoop 3.3.6.
Далее мы устанавливаем автономную версию Hadoop3.3.6.
1. Статус версии и подготовка установочного пакета.
Apache Hadoop Официальный адрес сайта: https://hadoop.apache.org/
Здесь мы видим, что последней версией является 3.3.6, которая также является версией, выпущенной в 2023 году. Она была значительно оптимизирована во всех аспектах. Эта статья также основана на этой версии для демонстрации.
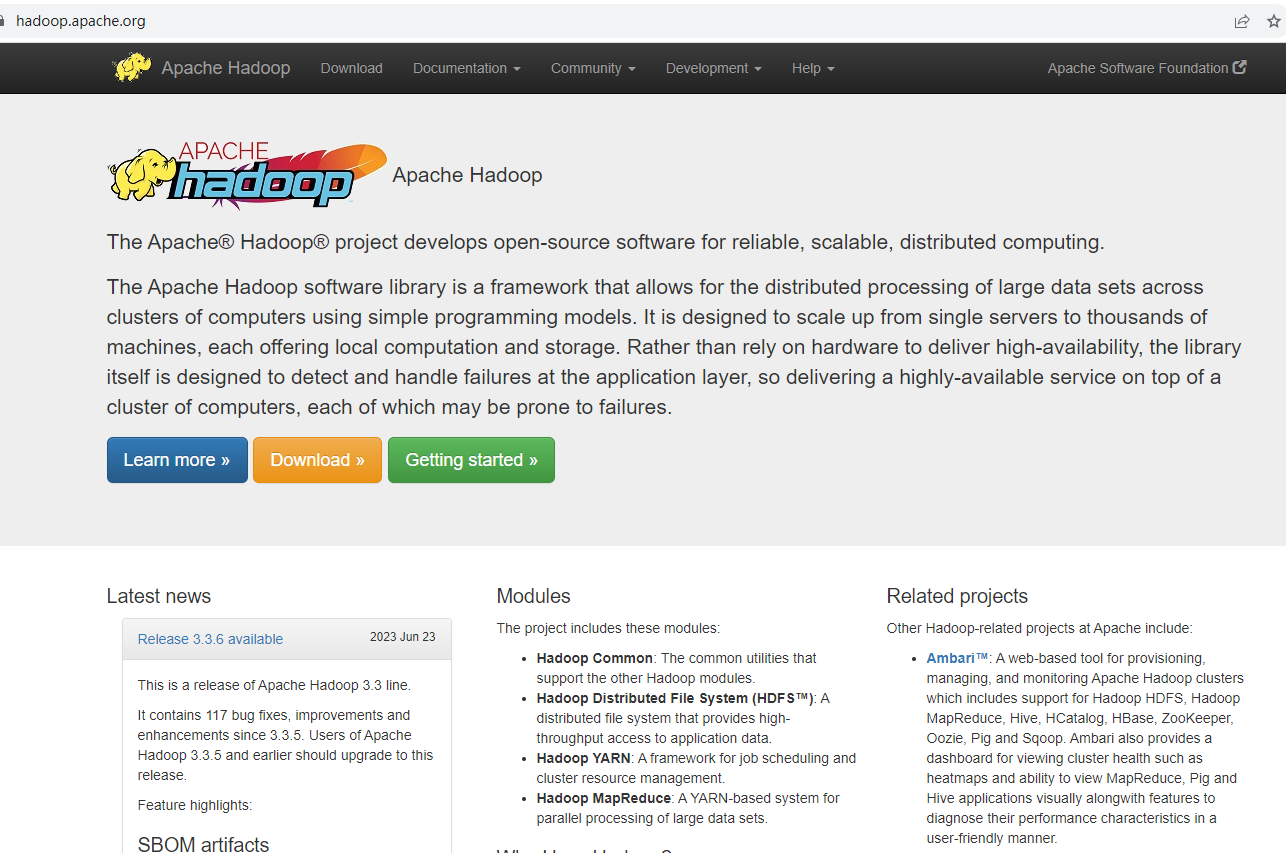
Мы используем версию Hadoop 3.3.6, которую можно скачать с официального сайта:
https://archive.apache.org/dist/hadoop/common/hadoop-3.3.6/
Это 696 МБ.
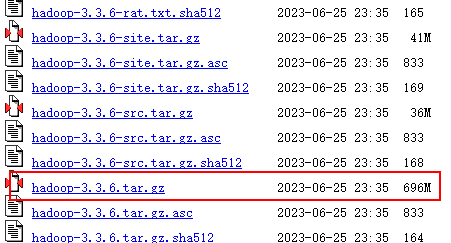
2. Подготовка серверной среды
Независимо от подготовки сервера и среды виртуальной машины, вы можете обратиться к моей предыдущей статье, чтобы настроить виртуальную машину локально, или купить уже готовую, не буду здесь вдаваться в подробности.
Используемая нами версия CentOS — 7.8. Вы можете проверить версию, выполнив следующую команду.
cat /etc/redhat-release

Шаги по установке для CentOS7 в основном такие же, и вы можете обратиться к этому документу.
На сервере необходимо настроить вход без пароля, иначе потом будут проблемы.
ssh-keygen -t rsa -P ""Просто нажмите Enter и скопируйте ключ
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keysМожете ли вы это проверить?
ssh bigdataflowingОбычно вы входите в систему напрямую.
3. Установка JDK
Сначала удалите Java, поставляемую с системой.
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
Загрузите установочный пакет на сервер. Инсталляционный пакет можно найти по адресу. Oracle Официальный сайт скачать:https://www.oracle.com/java/technologies/downloads/
Вы также можете использовать те, которые есть в моем информационном пакете.
jdk-8u221-linux-x64.tar.gz
Создайте папку.
mkdir /opt/jdk/
Зайдите в папку и загрузите файл.
cd /opt/jdk/
Разархивируйте установочный пакет tar -zxvf jdk-8u221-linux-x64.tar.gz
Об ошибках не сообщается, что указывает на то, что распаковка прошла успешно.
Затем мы просто настраиваем JDK в переменных среды.
vi /etc/profile
Добавив эти два предложения внизу, мы на самом деле распаковали jdk.
export JAVA_HOME=/opt/jdk/jdk1.8.0_221
export PATH=PATH:JAVA_HOME/bin
Наконец, пусть переменные среды вступят в силу
source /etc/profile
Проверять проверку версии Java,java -version успех!

Таким образом, на нашей машине доступна среда Java.
4. Установка Hadoop3.3.6
Благодаря среде Java проблема зависимостей Hadoop решена, и ее можно установить напрямую.
подготовиться заранее hadoop Установите пакет и загрузите его на /opt/hadoop3.3.6 в каталоге
Разархивировать,tar -zxvf hadoop-3.3.6.tar.gz Если об ошибке не сообщается, это успех.
Или добавьте переменные среды
vi /etc/profile
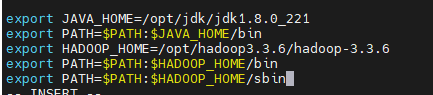
Добавьте эти три предложения внизу, местоположение Hadoop
export HADOOP_HOME=/opt/hadoop3.3.6/hadoop-3.3. 6
export PATH=PATH:HADOOP_HOME/bin
export PATH=PATH:HADOOP_HOME/sbin
Наконец, пусть переменные среды вступят в силу
source /etc/profile
Проверять проверку версии Java,hadoop-version успех!
использовать hadoop version Команда для проверки успешной установки

5. Конфигурация
Хотя установка прошла успешно,Но мы хотим использовать псевдокластер из одной машины.,Еще нужно сделать некоторую конфигурацию.
В каталоге Hadoop есть следующие папки
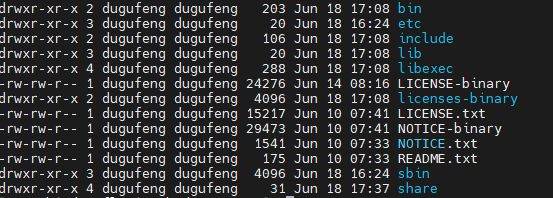
Каталог bin: сценарий основного сервиса Hadoop
Каталог и т. д.: каталог файла конфигурации Hadoop.
Каталог lib: хранит локальную библиотеку Hadoop.
Каталог sbin: хранит сценарии для запуска или остановки служб, связанных с Hadoop.
Введите первый etc Папка конфигурации cd ``etc/hadoop В следующей конфигурации нам нужно изменить только основные.
Сначала измените hadoop-env.sh Воля java и hadoop Корневой путь
export JAVA_HOME=/opt/jdk/jdk1.8.0_221
export HADOOP_HOME=/opt/hadoop3.3.6/hadoop-3.3.6
Также добавьте root-права
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootИзмените core-site.xml
В тег конфигурации добавьте следующее содержимое:
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdataflowing:9090</value>
</property>
<!-- обозначение hadoop данныеизхранилище Оглавление -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop3.3.6/hdfs/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>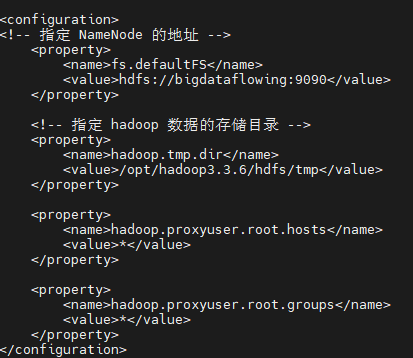
Исправлять hdfs-site.xml,В тег конфигурации добавьте следующее содержимое:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop3.3.6/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop3.3.6/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>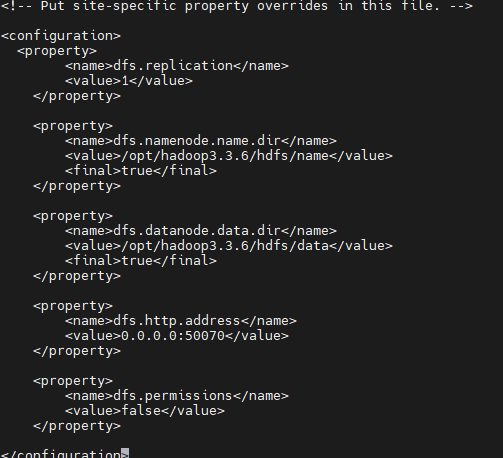
Исправлять mapre-site.xml,В тег конфигурации добавьте следующее содержимое:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>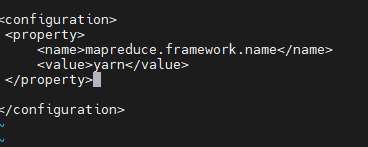
Исправлять yarn-site.xml,В тег конфигурации добавьте следующее содержимое:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>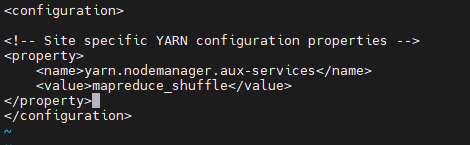
6. Старт
Первый формат HDFS, который предназначен для выполнения самой базовой конфигурации hdfs:
hdfs namenode -format
Форматирование завершено.
Затем мы входим в каталог sbin
cd /opt/hadoop3.3.6/hadoop-3.3.6/sbin/

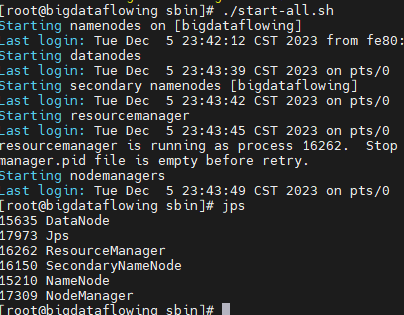
Здесь много скриптов, мы можем запустить их все.
./start-all.sh
Обычно ошибок не возникает, и в то же время используйте jps Команда Проверять, будет Datanode,ResourceManager,SecondaryNameNode,NameNode,NodeManager Пять процессов.
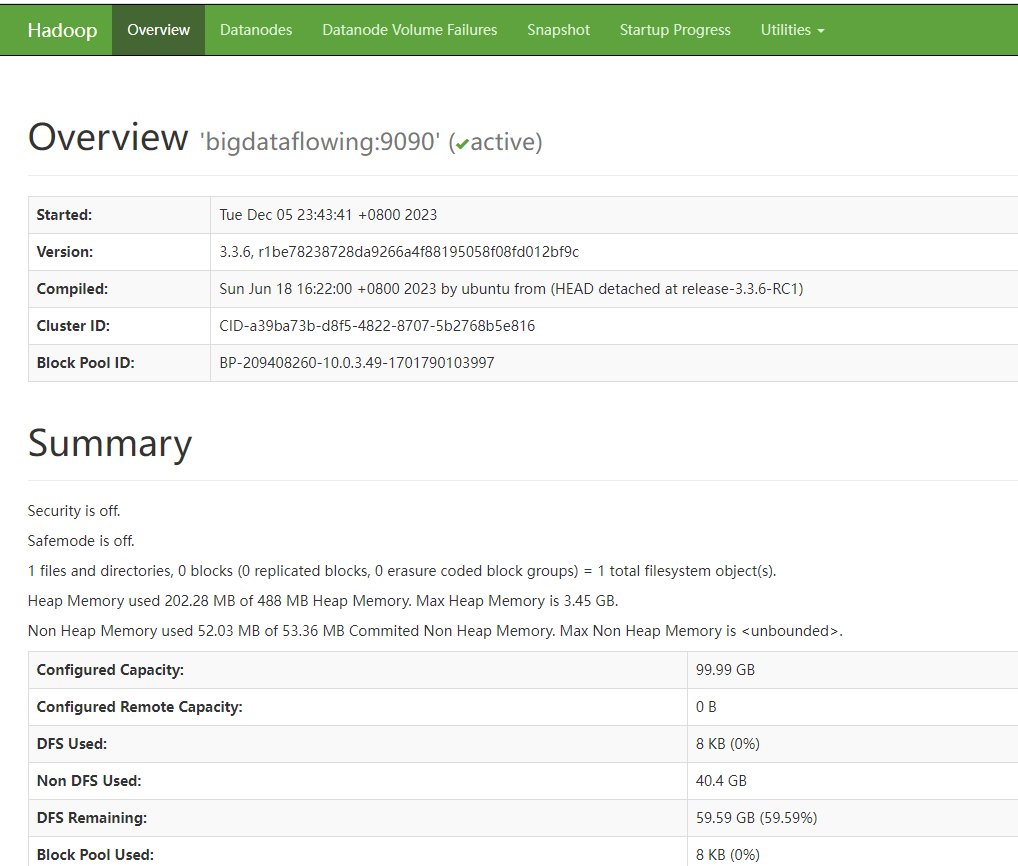
Еще один метод проверки успешности запуска:,дапосещатьпросить Hadoop Страница управления
http://IP:50070/
http://IP:8088/
Эти страницы изиспользовать,Мы будем существовать в соответствии с Hdfs,Yarn Мы объясним это подробно в следующей главе.
7. Сводка отчета об ошибках
Ошибка при запуске, пользователь root не настроен
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [bigdataflowing]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation。Запустить отчет об ошибках для настроек входа без пароля
localhost: Permission denied (publickey,password


Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
