Последний обзор «Большая модель + обучение с подкреплением»! Более 130 статей в Гонконге, Китае и Шэньчжэне: подробное объяснение четырех основных технологических маршрутов.

Новый отчет мудрости
Редактор: ЛРС
【Шин Джиген Введение】Используйте большие Модельпомогатьобучение с подкреплением, которое может улучшить способность Модели выполнять сложные задачи, такие как многозадачное обучение, использование образцов, планирование задач и т. д. В этой статье рассматриваются возможности LLM, расширенные Последние достижения в области RL, Подвести подведение итогов Проанализированы основные технологии, характеристики и четыре основных технических маршрута RL, а также проанализированы возможности и проблемы в этом направлении в будущем;
Обучение с подкреплением (RL) оптимизирует последовательные задачи принятия решений посредством обратной связи методом проб и ошибок, взаимодействующей с окружающей средой.
Хотя RL достигла сверхчеловеческих возможностей принятия решений в сложных средах видеоигр, допускающих множество проб и ошибок (например, Honor of Kings, Dota 2ждать),Но реализовать его в реальных сложных приложениях, содержащих большое количество естественного языка и визуальных образов, сложно.,Причины включают, помимо прочего,:Сложность получения данных、Низкое использование образцов、Плохая способность к многозадачности、Плохое обобщение、скудное вознаграждениеждать。
Модель большого языка (LLM),Благодаря обучению на больших наборах данных,Демонстрирует превосходное обучение многозадачности、Общие знания о мире, способность планировать цели и рассуждать。кChatGPTв лицеLLMОн широко используется в различных практических областях.,Включая, помимо прочего: роботов, медиков, обучать, Закон. и т. д.
В этом контексте LLM может улучшить возможности обучения с подкреплением в таких аспектах, как многозадачное обучение, использование выборки, планирование задач и т. д., а также помочь улучшить эффективность обучения обучения с подкреплением в сложных приложениях, таких как следование инструкциям на естественном языке, переговоры, автономное вождение и т. д. .
с этой целью,из Китайского университета Гонконга(Шэньчжэнь)Команда исследовалаБолее 130 статей о больших языковых моделях и моделях визуального языка (VLM) в обучении с подкреплением (LLM-enhanced RL).Новейшие научные достижения,Сформирована обзорная статья в этой области.,В настоящее время загружен в виде препринта на сайт arXiv.,Мы надеемся предоставить некоторую техническую информацию для исследователей и инженеров.

Ссылка на статью: https://arxiv.org/abs/2404.00282.
Обзор Подвести подведение итогов Проанализированы основные технологии, характеристики и четыре основных технических маршрута RL, а также проанализированы возможности и проблемы в этом направлении в будущем;
Ниже приводится обзор основного содержания статьи. Подробную информацию можно найти в обзорном документе на английском языке.
LLM-enhanced RL рамка
LLM-enhanced RL определение:Относится к использованиюПредварительно обученный、присущий знаниямизAIМодельизМультимодальная обработка информации、генерировать、Рассуждение и другие способностипомогатьRL范式из各种方法。
Основные характеристики (Характеристики):
1. Понимание мультимодальной информации
2. Многозадачное обучение и обобщение
3. Повышенная эффективность выборки
4. Способность долгосрочного планирования траектории (обработка на больших горизонтах)
5. Возможность генерации сигнала вознаграждения
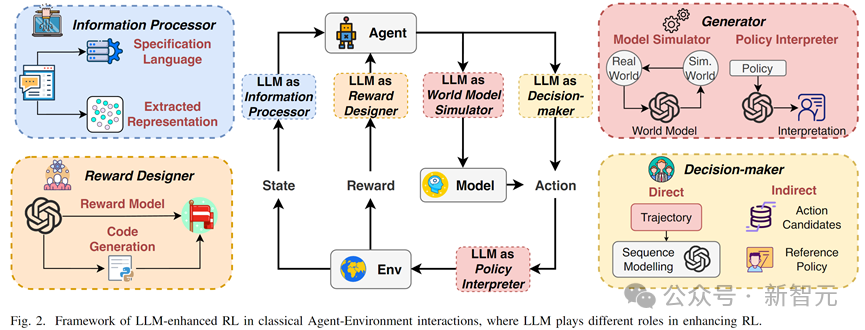
Классификация основных ролей LLM
1. Информационный процессор: включающий 1) извлечение текста и визуального представления 2) сложный перевод на естественный язык;
2. Дизайнер вознаграждений: а именно, модель неявного вознаграждения и модель явного вознаграждения (генерация кода функции вознаграждения).
3. Лицо, принимающее решения: включая прямое принятие решений и косвенное вспомогательное принятие решений.
4. Генератор: а именно 1) генерация траектории в модели мира и 2) генерация объяснения стратегии (поведения) в обучении с подкреплением.
LLM В качестве информационного процессора (LLM as Information Processor)
В средах, богатых текстовой и визуальной информацией, необходимо глубокое обучение с подкреплением (глубокое обучение). RL)обычно требуетсяУчитесь одновременно多模态из信息处理和决策控制策略,Поэтому эффективность обучения существенно падает。иНерегулярный、Изменчивый естественный язык и визуальная информация часто сильно мешают обучению агентов.。
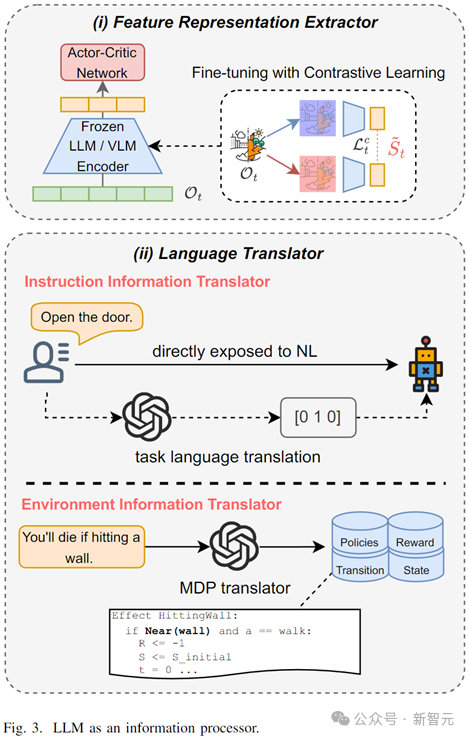
LLM在此情况下可к(1)Эффективное извлечение представлений,Ускорьте дальнейшее обучение нейронных сетей;(2)перевод на естественный язык,Перевести нерегулярные, избыточные и сложные инструкции на естественном языке и информацию об окружающей среде на стандартизированные языки задач.,помощьактерское мастерство фильтрует неверную информацию.
LLM В качестве дизайнера наград (LLM as Reward Designer)
Разработка функции вознаграждения и эффективное генерирование сигналов вознаграждения всегда были двумя основными проблемами обучения с подкреплением в сложных задачах или в условиях скудного вознаграждения.
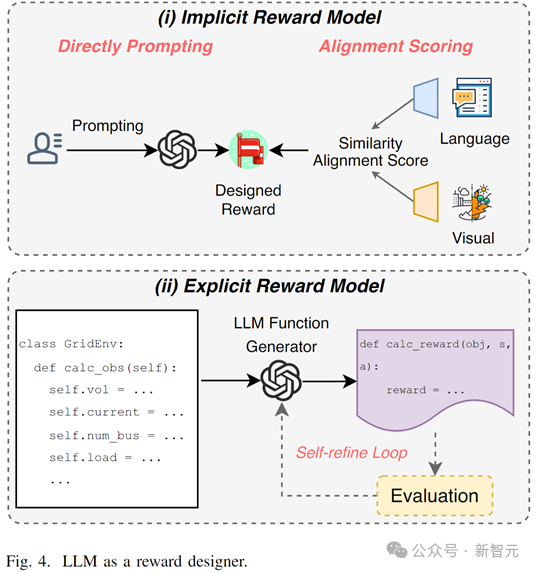
Большие модели могут решить эту проблему двумя способами.
1. Неявная конструкция функции вознаграждения:Используйте контекстуальное понимание、навыки и знания рассуждения,получать вознаграждения через подсказки к задачам или текстовое и визуальное выравнивание
2. Явный дизайн функции вознаграждения:Путем ввода информации об экологических характеристиках,LLMгенерировать Исполняемые наградыфункциякод(Например Python и т. д.), каждая часть функции вознаграждения явно логически рассчитывается и может быть изменена автономно на основе оценки.
LLM Как лицо, принимающее решения (LLM as Decision-Maker)
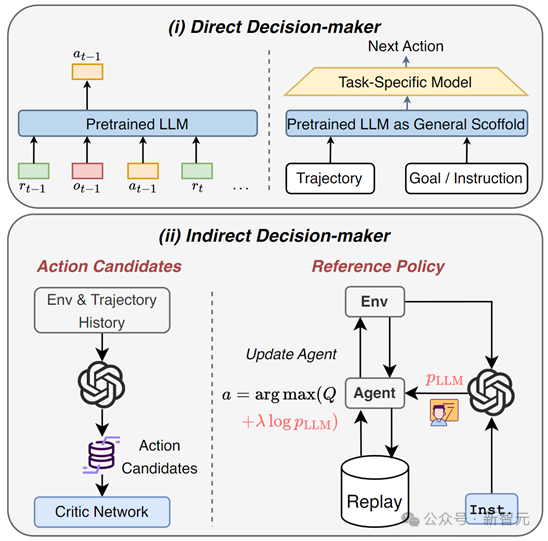
В задачах принятия решений большие модели могут использоваться как:
1. Непосредственное лицо, принимающее решения: Decision Transformer продемонстрировал большой потенциал в автономном обучении с подкреплением. Большую языковую модель можно рассматривать как расширенную версию большой предварительно обученной модели Transformer, использующую для решения свои мощные возможности временного моделирования и возможности понимания естественного языка. автономное подкрепление. Изучение проблем долгосрочного решения.
2. Лицо, принимающее косвенные решения: в качестве руководства используйте экспертные знания, полученные до обучения, и возможности понимания задач, чтобы генерировать варианты действий и сужать объем выбора действий, или сгенерировать справочную политику для руководства обновлением политики RL;
LLM В качестве генератора (LLM as Generator)
В обучении с подкреплением на основе моделей (на основе моделей RL), LLM может использоваться как мультимодальная модель мира (world model),Объедините свои знания и возможности моделирования, чтобыВысококачественные долгосрочные траектории или изучение представлений о переходных состояниях мира。
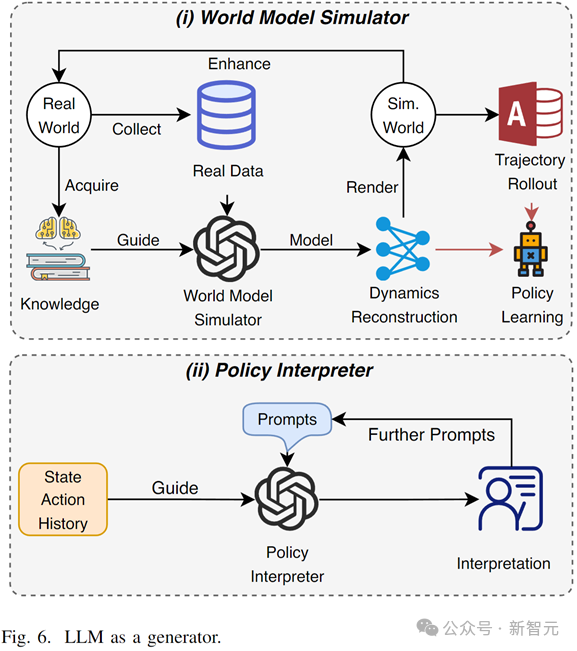
В рамках интерпретируемого обучения с подкреплением большие модели могут автоматически генерировать объяснения поведения агентов на естественном языке на основе подсказок путем понимания траекторий, окружающей среды и задач, что повышает понимание пользователями при вызове и настройке моделей RL.
Обсуждение
LLM-enhanced RLизПотенциальные будущие приложениявключая, но не ограничиваясь:
1. Роботы. Используя возможности мультимодального понимания и рассуждения, RL с расширением LLM может повысить эффективность взаимодействия человека и машины; помочь роботам понять логику человеческих потребностей и улучшить возможности принятия решений и планирования;
2. Автономное вождение. Автономное вождение использует обучение с подкреплением для принятия решений в сложных динамических сценариях, включающих данные от нескольких датчиков, правила дорожного движения, поведение пешеходов и т. д. Большие модели могут помочь в обучении с подкреплением обрабатывать мультимодальную информацию и разрабатывать комплексные функции вознаграждения, такие как безопасность, эффективность, комфорт пассажиров и т. д.
3. Управление энергопотреблением энергосистемы. В энергосистеме операторы или пользователи используют обучение с подкреплением для эффективного управления использованием, преобразованием и хранением множества возможностей, включая возобновляемую энергию с высокой степенью неопределенности. Большие модели могут помочь разработать многоцелевые функции и повысить эффективность использования образцов.
Потенциальные возможности в направлении LLM-enhanced:
1. В обучении с подкреплением: текущая работа сосредоточена на общем обучении с подкреплением, в то время как меньше работы посвящено конкретным ветвям обучения с подкреплением, включая многоагентное обучение с подкреплением, безопасное обучение с подкреплением, трансферное обучение с подкреплением и объяснимое обучение с подкреплением.
2. Что касается больших моделей: в большинстве текущих работ используется только технология быстрой генерации, в то время как технология извлечения расширенной генерации (RAG), API и возможности вызова инструментов могут значительно улучшить производительность LLM в конкретных ситуациях.
Проблемы RL с расширением LLM:
1. Зависимость от способностей большой модели. Способности большой модели определяют стратегию, которую изучает агент обучения с подкреплением. Присущие большой модели предвзятости, иллюзии и другие проблемы также влияют на способности агента.
2. Эффективность взаимодействия. В настоящее время большие модели требуют больших вычислительных затрат и низкой эффективности взаимодействия, что влияет на скорость взаимодействия между агентом и средой при онлайн-обучении с подкреплением.
3. Моральные и этические проблемы. В реальных приложениях «человек-машина» необходимо серьезно учитывать моральные и этические проблемы больших моделей.
Подвести итог
Система обзорных статей Подвести итог получил большую Модель во вспомогательном обучении с Последние достижения исследований в области подкреплений определяют LLM-усиленную RL такой метод, и Подвести итог Большой Модель在其中из四种主要角色及其方法,Наконец, обсуждаются потенциальные будущие приложения, возможности и проблемы.,Я надеюсь, что это может вдохновить будущих исследователей в этом направлении.
1. информационный процессор:большой Модельдляобучение с подкреплениемактерское мастерство извлекает представления наблюдений и язык спецификаций для повышения эффективности использования выборки.
2. Дизайнер наград:在复杂或无法量化из任务中,Большая Модель использует знания и способности к рассуждению для разработки сложных функций вознаграждения и обоснования сигналов вознаграждения.
3. лицо, принимающее решения:большой Модельпрямойгенерироватьдействие или косвенноегенерировать Рекомендации по действию,улучшатьобучение с подкрепление Исследуйте эффективность.
4. генерировать ВОЗ:большой Модельиспользоваться для:(1)作для高保真多模态世界Модель Сократите реальные затраты на обучение и(2)генерироватьактерское Объяснение поведения мастерства на естественном языке.
Ссылки:
https://arxiv.org/abs/2404.00282



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
