Пошаговая интерпретация работы компилятора нейросетей TVM (1) – простой пример
Предисловие
Это серия руководств по TVM. В ней планируется дать вам общий анализ основных принципов работы TVM, от инструкций по использованию TVM до внутреннего исходного кода TVM. Поскольку на TVM относительно мало китайских материалов, я надеюсь внести свой вклад. Если в описании есть какие-либо ошибки, пожалуйста, укажите на них вовремя.
Так что же такое ТВМ?
Проще говоря,TVM можно назвать набором множества наборов инструментов.,Эти инструменты можно использовать в сочетании,реализовать некоторые из нашихнейронная сетьускорение иразвертывать Функция。Вот почему это называетсяTVM StackПонятно。TVMЕсть много способов использования,Он может поддерживать почти все нейронные сети, представленные на рынке (ONNX, TF, Caffe2 и т. д.).,В нее также можно играть практически на любой платформе.,Например, Windows, Linux, Mac, ARM и т. д.
Опишем это следующей картинкой:,Эта картинка взята из(https://tvm.ai/about):
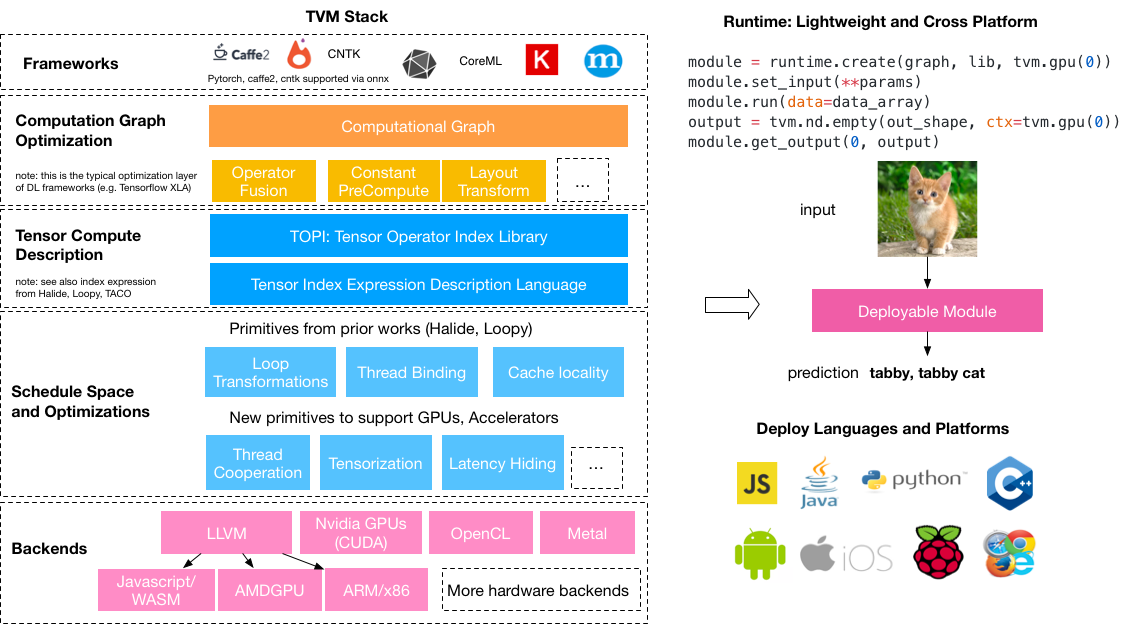
На первый взгляд, многие вещи кажутся очень сложными.,Но нам просто нужно знатьTVMосновной Функция Вот и все:TVM может оптимизировать обученную модель и упаковать вашу модель, а затем вы сможете запустить эту оптимизированную модель на любой платформе.,Можно сказать, что это тесно связано с посадкой.
TVM содержит множество вещей и концепций знаний. Он не только включает в себя ряд шагов, таких как оптимизация нейронной сети, количественный анализ и объединение опций, но также поддерживает другие более подробные технологии (Halide, LLVM), что делает TVM очень мощными функциями... Хорошо, не говорите глупостей, я больше не смогу это сдерживать. Если вы хотите узнать больше о TVM, вы можете напрямую выполнить поиск по ключевому слову TVM на Zhihu. У этих больших парней есть много вводных статей о TVM. иди и прочитай это.
Фактически, существует множество библиотек, которые выполняют этот этап оптимизации модели.,Независимо от того, что этоNvidiaсобственныйTensorRTвсе ещеPytorchсобственныйtorch.jitмодуль,Все они работают над оптимизацией модели.,Здесь нечего сказать,Если вам интересно, вы можете прочитать следующие статьи:
Используйте TensorRT для ускорения нейронных сетей (прочитайте модель ONNX и запустите ее)
Ускорьте глубокое обучение с помощью TensorRT
Начать
Вот и все,Я чувствую необходимость сказать это:Почему нам следует использовать TVM?
Если вы хотите перенести свою модель обучения на сторону Windows, ARM (Raspberry Pi, ряд других плат, использующих это ядро) или на некоторые другие платформы, используйте ЦП или графический процессор для ее запуска и надейтесь, что ее можно будет оптимизировать. Чтобы модель работала быстрее на платформе (это не имеет ничего общего с разработкой алгоритма самой модели) и для исследования целевых приложений, тогда TVM — ваш лучший выбор. Кроме того, исходный код TVM создается совместно C++ и Python. Чтение соответствующего исходного кода также поможет нам улучшить наше программирование.
Установить
Установить на самом деле нечего сказать,чиновникПримерыОчень подробно。Все двигайтесь туда и следуйтечиновник Просто следуйте инструкциям шаг за шагом。
Однако следует отметить два момента:
- предположение УстановитьLLVM,Хотя LLVM не является обязательным для TVM,Но если мы хотим развернуть на сторону процессора,Тогда llvm практически необходим
- Потому что TVM — это проект Python и C++.,Можно сказать, что Python — это передняя часть C++.,Установите официальное руководство после компиляции C++ конца.,здесьпредположение Выберите официальныйвMethod 1выполнятьpythonНастройки терминала,Таким образом, мы можем изменить исходный код по своему желанию.,Перекомпилируйте еще раз,Сторону Python можно использовать напрямую без каких-либо изменений.
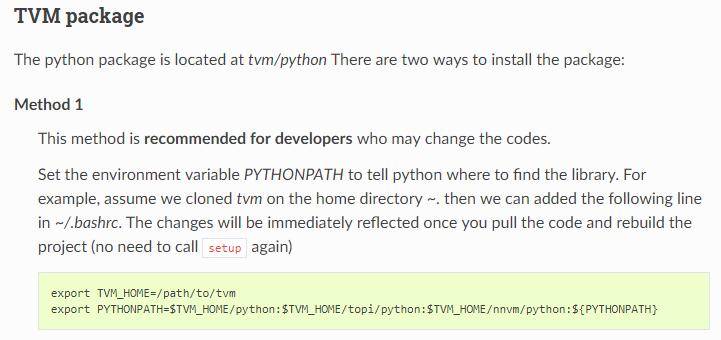
(Официально рекомендуется использовать метод 1)
Экспортировать модель Onnx с помощью Pytorch
Сказав так много, только продемонстрировав пример, вы сможете лучше понять, что делает TVM, поэтому здесь мы используем простой пример, чтобы продемонстрировать, как используется TVM.
Первое, что нам нужно сделать, это,Получите уже обученную Модель,Вот я выбираю этоgithubна складеmobilenet-v2,Предоставляются код модели и веса, обученные в ImageNet. хороший,Переносим код Модели с github на локальный,Затем вызовите и загрузите обученные веса:
import torch
import time
from models.MobileNetv2 import mobilenetv2
model = mobilenetv2(pretrained=True)
example = torch.rand(1, 3, 224, 224) # воображаемый ввод
with torch.no_grad():
model.eval()
since = time.time()
for i in range(10000):
model(example)
time_elapsed = time.time() - since
print('Time elapsed is {:.0f}m {:.0f}s'.
format(time_elapsed // 60, time_elapsed % 60)) # Распечатайте времяЗдесь мы загружаем веса обученной модели, устанавливаем входные данные и непрерывно запускаем их 10 000 раз на стороне Python. Время, которое мы здесь тратим, составляет: 6 м2.
Затем мы экспортируем модель Pytorch как модель ONNX:
import torch
from models.MobileNetv2 import mobilenetv2
model = mobilenetv2(pretrained=True)
example = torch.rand(1, 3, 224, 224) # воображаемый ввод
torch_out = torch.onnx.export(model,
example,
"mobilenetv2.onnx",
verbose=True,
export_params=True # С выводом параметров
)Таким образом мы получаем Понятноmobilenetv2.onnxэтотonnxОтформатированный Модельмасса。Обратите внимание, что здесь нам придется С выводом параметров,Потому что мы будем напрямую читать ONNXModel для прогнозирования позже.
После экспорта,предположениеиспользоватьNetronПриходите и проверьте нас Модельструктура,Вы можете видеть, что эта модель экспортируется Pytorch-1.0.1.,Всего 152 операции.,А также идентификатор ввода и формат ввода и другая информация.,Мы можем перетащить мышь, чтобы просмотреть более подробную информацию:
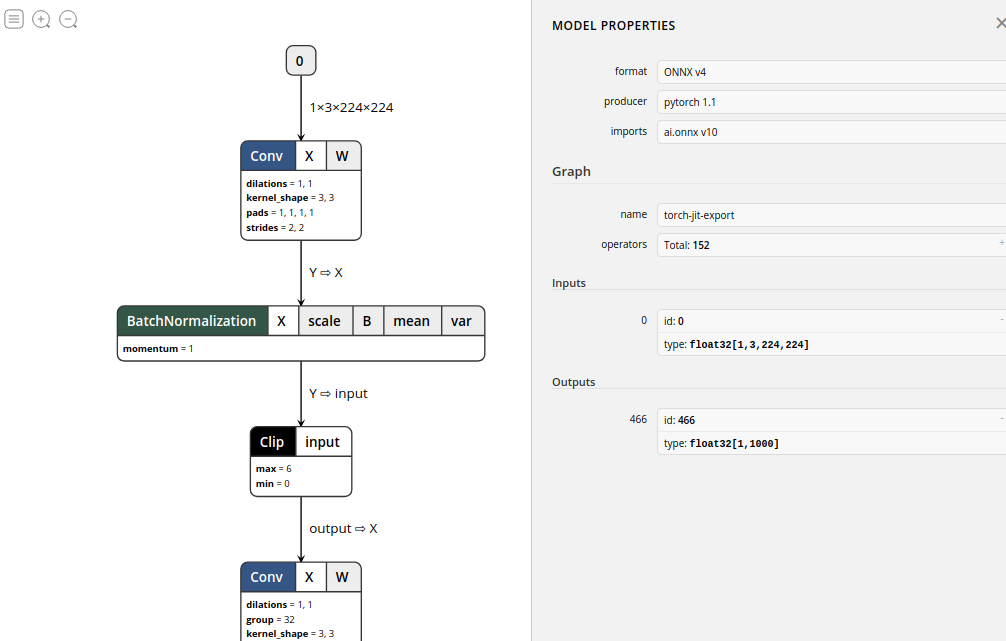
хорошо,Пока что нашmobilenet-v2Модель Экспортирован успешно Понятно。
Используйте TVM для чтения и прогнозирования моделей ONNX
После того, как мы успешно скомпилируем и сможем нормально ссылаться на TVM на стороне Python, мы сначала импортируем нашу модель в формате onnx. Здесь мы подготовили изображение самолета:

этотизображение вImageNetКатегория принадлежит404: 'airliner',То есть авиалайнеры.
Ниже мы будем использовать TVM для развертывания модели onnx и прогнозирования этого изображения.
импортировать onnx
время импорта
импорт твм
импортировать numpy как np
импортировать tvm.relay как реле
из изображения импорта PIL
onnx_model = onnx.load('mobilenetv2.onnx') # импортировать Модель
среднее = [123., 117., 104.] # Среднее и стандартное значение набора обучающих данных в ImageNet
std = [58.395, 57.12, 57.375]
def transform_image(image): # Определите функцию преобразования для преобразования изображений формата PIL в массивы форматов numpy с размерностями формата.
image = image - np.array(mean)
image /= np.array(std)
image = np.array(image).transpose((2, 0, 1))
image = image[np.newaxis, :].astype('float32')
return image
img = Image.open('../datasets/images/plane.jpg').resize((224, 224)) # Здесь мы изменяем размер изображения до определенного размера
x = transform_image(img)Таким образом мы получаемxдля[1,3,224,224]Размерныйndarray。этотсоответствоватьNCHWСтандарты формата,Это также наш общий тензорный формат.
Далее мы устанавливаем целевой портllvm,То есть развернуть на сторону CPU,И здесь мы используемTVMвRelay IR,Проще говоря, этот IR может прочитать нашу Модель и построить исполняемый график вычислений в порядке Модели.,конечно,Мы можем выполнить серию оптимизаций на этом вычислительном графе. (TVM теперь в основном рекомендует Relay вместо NNVM.,Реле можно назвать NNVM второго поколения).
target = 'llvm'
input_name = '0' # Обратите внимание, что это входной идентификатор Модели в ранее экспортированной модели onnxModel, здесь он равен 0.
shape_dict = {input_name: x.shape}
# Используйте интерфейс onnx в Relay, чтобы прочитать экспортированную модель onnx.
sym, params = relay.frontend.from_onnx(onnx_model, shape_dict)экспортировано в приведенном выше кодеsymиparamsЭто основная вещь, которую мы будем использовать дальше.,Среди них параметры — это информация о весе при экспорте модели.,Представлено dic в Python:
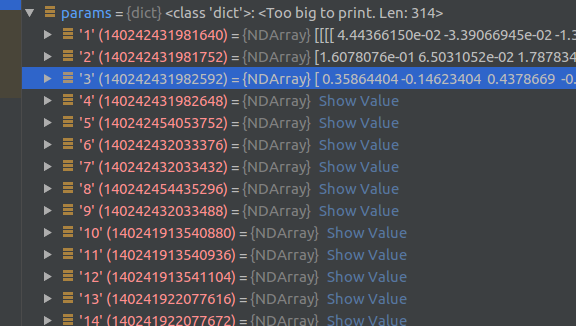
иsymОн представляет собой структуру расчетного графа.Функцияфункция,Эта функция содержит последовательность операций графа расчета.,и различная информация о параметрах, необходимая в некоторых расчетах.,Relay IRЗатем выполните сетьоптимизация Это в основном оэтотsymруководитьоптимизацияпроцесс:
fn (%v0: Tensor[(1, 3, 224, 224), float32],
%v1: Tensor[(32, 3, 3, 3), float32],
%v2: Tensor[(32,), float32],
%v3: Tensor[(32,), float32],
%v4: Tensor[(32,), float32],
%v5: Tensor[(32,), float32],
...
%v307: Tensor[(1280, 320, 1, 1), float32],
%v308: Tensor[(1280,), float32],
%v309: Tensor[(1280,), float32],
%v310: Tensor[(1280,), float32],
%v311: Tensor[(1280,), float32],
%v313: Tensor[(1000, 1280), float32],
%v314: Tensor[(1000,), float32]) {
%0 = nn.conv2d(%v0, %v1, strides=[2, 2], padding=[1, 1], kernel_size=[3, 3])
%1 = nn.batch_norm(%0, %v2, %v3, %v4, %v5, epsilon=1e-05)
%2 = %1.0
%3 = clip(%2, a_min=0, a_max=6)
%4 = nn.conv2d(%3, %v7, padding=[1, 1], groups=32, kernel_size=[3, 3])
...
%200 = clip(%199, a_min=0, a_max=6)
%201 = mean(%200, axis=[3])
%202 = mean(%201, axis=[2])
%203 = nn.batch_flatten(%202)
%204 = multiply(1f, %203)
%205 = nn.dense(%204, %v313, units=1000)
%206 = multiply(1f, %v314)
%207 = nn.bias_add(%205, %206)
%207
}Хорошо, дальше нам нужно оптимизировать эту модель вычислительного графа. Здесь мы выбираем уровень оптимизации 3:
with relay.build_config(opt_level=3):
intrp = relay.build_module.create_executor('graph', sym, tvm.cpu(0), target)
dtype = 'float32'
func = intrp.evaluate(sym)наконец Мы получаем что-то, что можно запустить напрямуюfunc。
Уровни оптимизации разделены на следующие категории:
OPT_PASS_LEVEL = {
"SimplifyInference": 0,
"OpFusion": 1,
"FoldConstant": 2,
"CombineParallelConv2D": 3,
"FoldScaleAxis": 3,
"AlterOpLayout": 3,
"CanonicalizeOps": 3,
}наконец,Мы конвертируем изображение, которое было отформатировано ранееxмножествои Модель Параметры вводятся вэтотfuncсередина,и возвращает максимальное значение в этом выходном массиве
output = func(tvm.nd.array(x.astype(dtype)), **params).asnumpy()
print(output.argmax())здесь我们得到的输出для404,Соответствует предыдущему описанию классификационной маркировки изображений в ImageNet.,Покажите, что наш TVM правильно читает onnxModel и применяет его на этапе прогнозирования.
Мы также отдельно протестировали скорость бега после оптимизации модели и сравнили скорость бега напрямую с помощью pytorch. Мы обнаружили, что окончательное время бега составляет 3 минуты 20 секунд, что почти в два раза быстрее, чем предыдущие 6 м2.
since = time.time()
for i in range(10000):
output = func(tvm.nd.array(x.astype(dtype)), **params).asnumpy()
time_elapsed = time.time() - since
print('Time elapsed is {:.0f}m {:.0f}s'.
format(time_elapsed // 60, time_elapsed % 60)) # Распечатайте времяКонечно, это сравнение не очень стандартизировано, но мы можем примерно проанализировать некоторые преимущества TVM.
постскриптум
Эта статья поможет вам понять, что такое TVM и как его использовать, на простом примере. Следующая статья будет включать анализ части структуры проекта TVM и исходного кода. Возможные точки знаний включают в себя:
- Простой принцип компилятора
- Специальный синтаксис C++ и метапрограммирование шаблонов
- нейронная сеть Модельоптимизация过程
- 代码развертывать
Подождите, изменения могут быть внесены в любое время.
Искусственный интеллект начал вступать в эпоху встроенных технологий. Скоро будут выпущены различные чипы искусственного интеллекта. Запуск сложных сетевых моделей на дешевых и маломощных платах больше не является далекой мечтой. Я не знаю, каким будет будущее. Вот так, но структура TVM начала делать небольшой шаг.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
