Пошаговая инструкция! Как самостоятельно обучить певца с искусственным интеллектом — учебное пособие по облачному обучению so-vits-svc
представлять
so-vits-svcоснован наVITSиз Проекты с открытым исходным кодом,VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech) — это очень выразительная модель синтеза речи, сочетающая в себе вариационный вывод, нормализованный поток и состязательное обучение.
среда
Основной текстиспользоватьиз Это Тенсент Облако
Вычислительный графический процессор типа GN7,Конкретные детали заключаются в следующем:
# Системная среда
Ubuntu 22.04 LTS
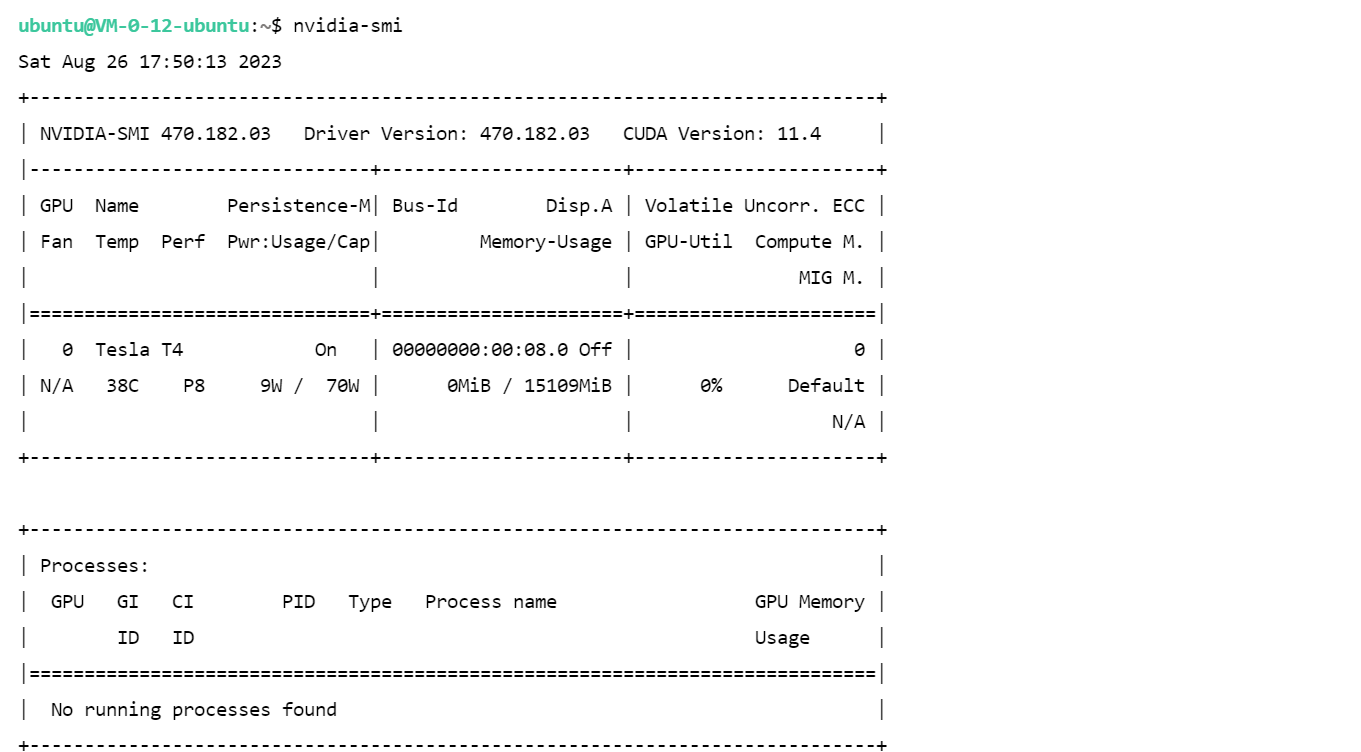
# Видеокарта
NVIDIA-SMI 470.182.03 Driver Version: 470.182.03 CUDA Version: 11.4
# pythonсреда
Python 3.10
# GPUсреда
Tesla T4 16G * 1
# CPUсреда
8 ядер 32GB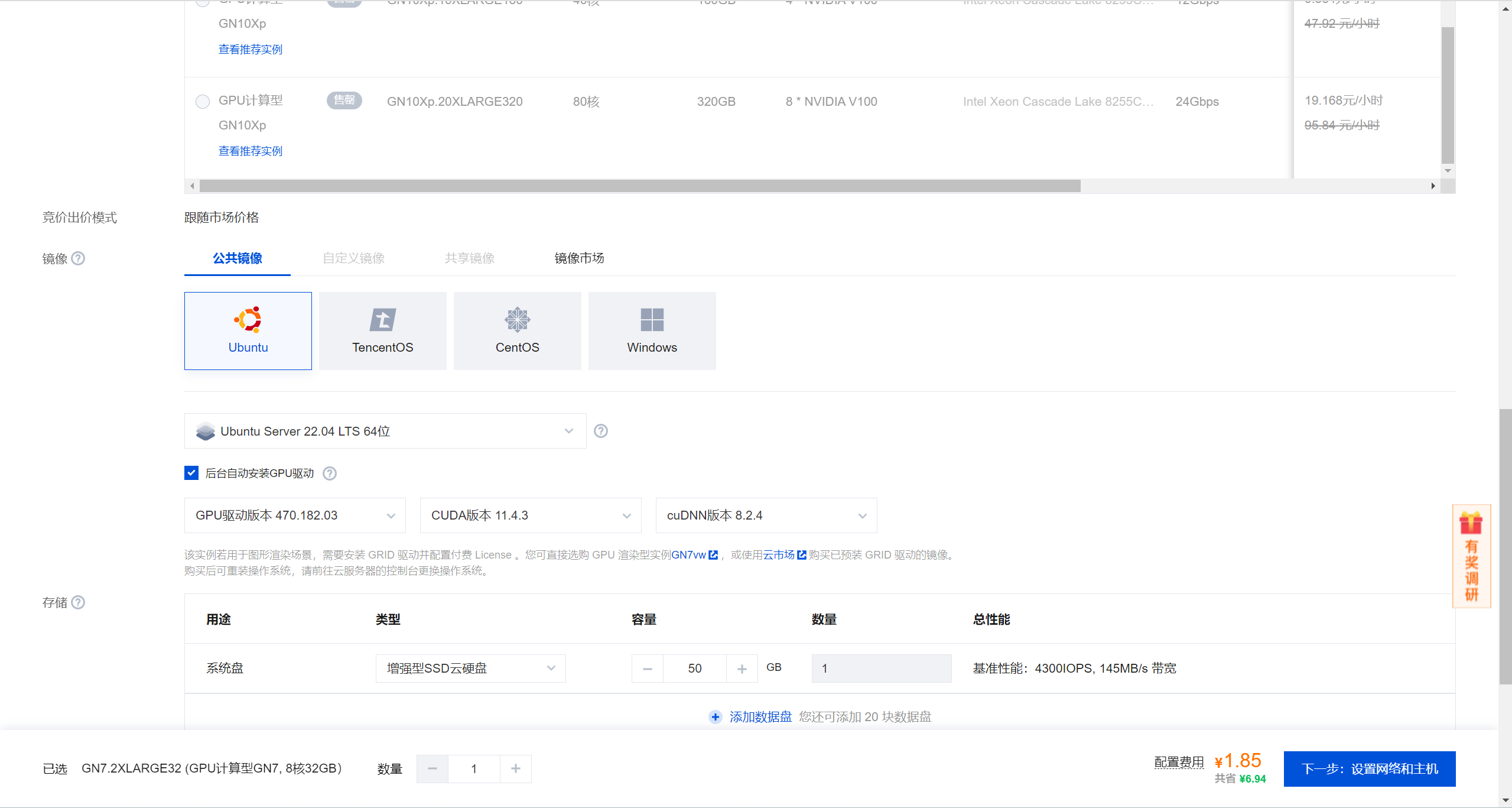
обработка звука
Для обучения нам необходимо разделить аудиофайл на две звуковые дорожки: человеческий голос и аккомпанемент, а вокальный аудиофайл разрезать на 10-20-секундные аудиоклипы.
- использоватьSpleeterразделениечеловеческий голосаудиодорожка
apt install ffmpeg #Эта команда должна быть установлена под пользователем root
pip install spleetermkdir spleeter && cd spleeter
mkdir raw
#Скачать модель
mkdir pretrained_models
wget -P pretrained_models https://github.com/deezer/spleeter/releases/download/v1.4.0/2stems.tar.gz
# Загрузка внутреннего VPS происходит слишком медленно, вы можете перейти по ссылке ниже.
# wget -P pretrained_models https://kgithub.com/deezer/spleeter/releases/download/v1.4.0/2stems.tar.gz
mkdir -p pretrained_models/2stems
tar -zxvf pretrained_models/2stems.tar.gz -C pretrained_models/2stems/- Тестовое разделение вокала
# тест
wget https://github.com/deezer/spleeter/raw/master/audio_example.mp3
spleeter separate -p spleeter:2stems -o output audio_example.mp3output/
└── audio_example
├── accompaniment.wav # сопровождение
└── vocals.wav # человеческий голос- Пакетное разделение аудиодорожек
понадобитсяразделениеизаудиофайлы в
spleeter/rawОглавление Вниз,Ранназадосуществлять Внизлапшаиз Заказ Чтобы облегчить пакетную обработку, вы можете использовать следующий скрипт Внизлапша脚本将rawОглавление Внизизвсе.wavдокументразделениестановитьсячеловеческий голосисопровождениедвааудиодорожка,и сохранить вspleeter/audio_outputв папке
#!/bin/bash
# Создайте выходную папку, если она не существует.
mkdir -p audio_output
# Просмотрите файлы WAV в исходном каталоге.
for file in raw/*.wav; do
# Проверьте, является ли тип файла MP3
if [[ -f "$file" ]]; then
echo "иметь дело с Файл: $file"
# Извлечь имя файла (без расширения)
filename=$(basename "$file" .wav)
# используйте команду spleeter для разделения и сохранения в папке audio_output/
spleeter separate \
-o audio_output \
"$file" \
-f "$filename"_{instrument}.wav
fi
done
echo «Разделение завершено!»Эффект следующий
ubuntu@VM-0-12-ubuntu:~/spleeter$ tree audio_output/
audio_output/
├── 11_accompaniment.wav
├── 11_vocals.wav
├── 12_accompaniment.wav
├── 12_vocals.wav
├── 13_accompaniment.wav
└── 13_vocals.wav
0 directories, 6 files- Разделение аудиоклипов
pip librosa soundfileВыполните следующий скрипт,начнется с
audio_outputОглавлениесерединаизкаждыйаудиофайлсерединаизвлекать10-20Второйизаудиоклип,и сохранить вclipsОглавлениесередина。
import librosa
import soundfile
import random
import os
# Получить текущий рабочий каталог
cwd = os.getcwd()
# Установите каталог, в котором находится исходный аудиофайл, и каталог, в котором будет сохранен новый файл.
src_folder = os.path.join(cwd, 'audio_output') # Каталог, в котором находится исходный аудиофайл
dst_folder = os.path.join(cwd, 'clips') # Каталог для сохранения новых файлов
# Создать каталог для сохранения новых файлов
if not os.path.exists(dst_folder):
os.makedirs(dst_folder)
# Просмотрите все wav-файлы в исходном каталоге.
for filename in os.listdir(src_folder):
if filename.endswith("vocals.wav"):
audio_path = os.path.join(src_folder, filename)
print(f"Processing {audio_path}...")
# Загрузить аудиофайлы
audio, sr = librosa.load(audio_path, sr=None, mono=False)
# Удалить тихую часть аудиофайла
audio_trimmed, index = librosa.effects.trim(audio, top_db=20, frame_length=2048, hop_length=512)
# Рассчитайте общую продолжительность и общее количество точек отбора проб.
duration = len(audio_trimmed[0]) / sr
total_samples = audio_trimmed.shape[-1]
# Определите количество точек выборки, которые должен содержать каждый сегмент.
min_duration = 10 # Минимальная длина сегмента (секунды)
max_duration = 20 # Максимальная длина сегмента (секунды)
segment_duration = random.uniform(min_duration, max_duration) # Случайная длина клипа
segment_samples = int(segment_duration * sr) # Преобразование длины клипа в количество сэмплов
# Прокрутите аудиофайлы и сохраните каждый сегмент как новый аудиофайл.
for i in range(0, total_samples, segment_samples):
start = i # Текущий сегмент от начальной точки отбора проб
end = min(i + segment_samples, total_samples) # Текущий участок от конечной точки отбора проб
chunk = audio_trimmed[:, start:end] # Перехватить текущий сегмент и аудиоданные
if len(chunk.shape) > 1:
chunk = chunk.T # Если стерео, поменяйте каналы местами.
# Создать новое имя файла
clip_filename = f"{os.path.splitext(filename)[0]}_{i//segment_samples}.wav"
clip_path = os.path.join(dst_folder, clip_filename)
soundfile.write(clip_path, chunk, sr) # Сохраните текущий сегмент и аудиоданные в файл.Начать обучение
- Клонируйте репозиторий и установите зависимости
git clone https://github.com/svc-develop-team/so-vits-svc.git
cd so-vits-svc
apt install python3-venv #Эта команда должна быть установлена под пользователем root
python3 -m venv myenv
source myenv/bin/activate
pip uninstall -y torchdata torchtext
pip install --upgrade pip setuptools numpy numba
pip install pyworld praat-parselmouth fairseq tensorboardX torchcrepe librosa==0.9.1 pyyaml pynvml pyloudnorm
pip install torch torchvision torchaudio
pip install rich loguru matplotlib
pip install faiss-gpu
pip uninstall omegaconf
pip install omegaconf==2.0.5
pip install antlr4-python3-runtime==4.8
pip install antlr4-python3-runtime==4.8
pip install tensorboard- Подготовка набора данных
перейти к предыдущему шагусерединагенерироватьизаудиоклипдокумент夹
clipsпереехать вso-vits-svc/dataset_rawОглавление Вниз,Структура каталогов следующая:
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
speaker0— имя синтезируемого целевого динамика. Это имя нужно для рассуждений. Для имени каждого аудиофайла нет ограничений формата (такие методы именования, как 000001.wav~999999.wav, также разрешены), но тип файла должен быть wav.
- Получить предварительно обученную модель
cd so-vits-svc
#download_pretrained_model
curl -L https://huggingface.co/datasets/ms903/sovits4.0-768vec-layer12/resolve/main/sovits_768l12_pre_large_320k/clean_D_320000.pth -o logs/44k/D_0.pth
curl -L https://huggingface.co/datasets/ms903/sovits4.0-768vec-layer12/resolve/main/sovits_768l12_pre_large_320k/clean_G_320000.pth -o logs/44k/G_0.pth
#download_pretrained_diffusion_model
#Не нужно загружать, если не тренируется модель диффузии
wget -L https://huggingface.co/datasets/ms903/Diff-SVC-refactor-pre-trained-model/resolve/main/fix_pitch_add_vctk_600k/model_0.pt -o logs/44k/diffusion/model_0.pt
#IfusermvpeF0 предиктор, вам необходимо скачать предварительное обучение RMVPE Модель
curl -L https://huggingface.co/datasets/ylzz1997/rmvpe_pretrain_model/resolve/main/rmvpe.pt -o pretrain/rmvpe.pt
curl -L https://huggingface.co/datasets/ylzz1997/rmvpe_pretrain_model/resolve/main/fcpe.pt -o pretrain/fcpe.pt- Использовать contentvec в качестве кодировщика звука (рекомендуется)
vec768l12иvec256l9 Этот кодировщик необходим
- contentvec :checkpoint_best_legacy_500.pt
- надевать
pretrainОглавление Вниз
Или загрузите ContentVec ниже, размер которого составляет всего 199 МБ, но эффект тот же:
- contentvec :hubert_base.pt
- Измените имя файла на
checkpoint_best_legacy_500.ptназад,надеватьpretrainОглавление Вниз
# contentvec
wget -P pretrain/ https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -O checkpoint_best_legacy_500.pt
# Вы также можете скачать его вручную и вставить в pretrain ОглавлениеДополнительные кодеры см.so-vits-svc
- Передискретизировано в моно с частотой 44 100 Гц.
python resample.py- Автоматически разделяйте обучающий набор и набор проверки и автоматически генерируйте файлы конфигурации.
python preprocess_flist_config.py --speech_encoder=vec768l12- Сгенерируйте Хьюберта и f0
python preprocess_hubert_f0.py --f0_predictor=crepe
Ускорьте предварительную обработку. Если ваш набор данных относительно большой, вы можете попробовать добавить параметр --num_processes:
python preprocess_hubert_f0.py --f0_predictor=crepe --num_processes 8- Основное обучение модели
python train.py -c configs/config.json -m 44kМодель диффузии (необязательно). Если вам нужна функция мелкой диффузии, вам необходимо обучить модель диффузии. Метод обучения модели диффузии:
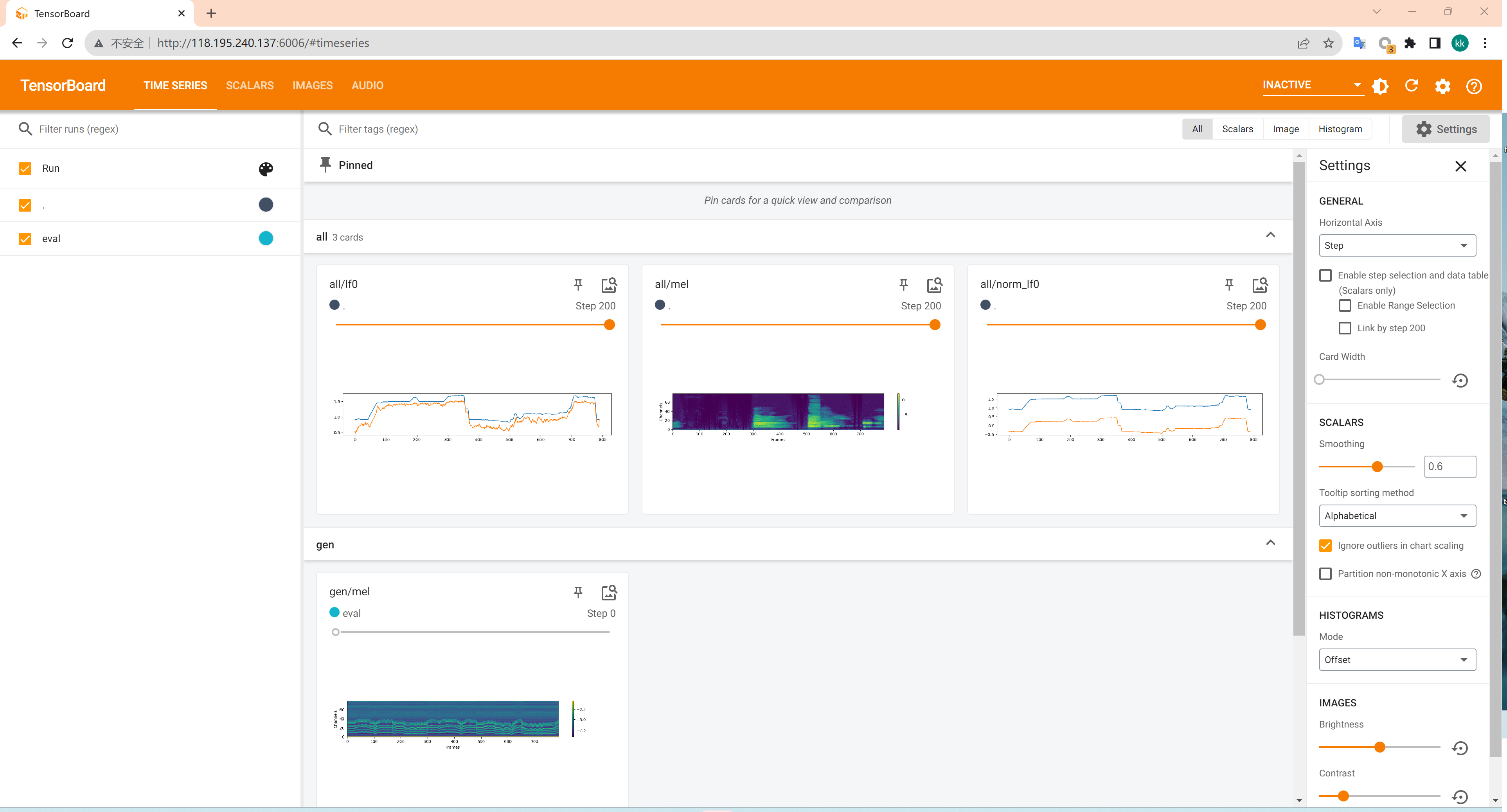
python train_diff.py -c configs/diffusion.yamlИспользуйте тензорную доску для просмотра статуса обучения
tensorboard --logdir logs/44k --host=0.0.0.0
- Обучение модели кластеризации (необязательно)
python cluster/train_cluster.py --gpuМодель Обучение оконченоназад,Модель Файл сохраняется в
logs/44kОглавление Вниз,кластеризация Модельбудет сохранен вlogs/44k/kmeans_10000.pt,диффузия Модельсуществоватьlogs/44k/diffusionВниз 。
Рассуждение (можно использовать собственный компьютер, если требования к конфигурации не высоки)
- Описание параметра
# пример
python inference_main.py -m "logs/44k/G_30400.pth" -c "configs/config.json" -n "История, которую ты не знаешь-src.wav" -t 0 -s "nen"Обязательные поля:
-m|--model_path:Модельпуть-c|--config_path:配置документпуть-n|--clean_names:wav Список имен файлов, помещенных в raw в папке-t|--trans:регулировка шага,Поддерживает положительные и отрицательные (полутона)-s|--spk_list:Синтезируйте имя целевого говорящего-cl|--clip:Принудительная нарезка звука,по умолчанию 0 — автоматическая нарезка, единица измерения — секунды/с.
Необязательная часть: подробности см. в следующем разделе.
-lg|--linear_gradient:Два аудиофрагментаиздлина кроссфейда,Если после принудительной нарезки вокал выглядит бессвязным, вы можете отрегулировать это значение.,Если все согласовано, рекомендуется использовать значение по умолчанию 0, единица измерения — секунды.-f0p|--f0_predictor:выбирать F0 Предиктор, опционально crepe,pm,dio,harvest,rmvpe,fcpe, По умолчанию вечер (примечание: креп Для оригинала F0 используя средний фильтр)-a|--auto_predict_f0:Преобразование речи автоматически прогнозирует высоту звука,Не включайте эту функцию при конвертировании песен, так как она будет сильно расстроена.-cm|--cluster_model_path:кластеризация Модельили Поиск функцийиндекспуть,Оставьте пустым, чтобы автоматически установить каждый план Модельизпо умолчаниюпуть,Если нет обучающей кластеризации или поиска признаков, заполните их случайно.-cr|--cluster_infer_ratio:кластеризация方案или Поиск функций Пропорция,объем 0–1, по умолчанию, если модель кластеризации или извлечение признаков не обучены. 0 Вот и все-eh|--enhance:лииспользовать NSF_HIFIGAN усилитель,Эта опция менее полезна для некоторых обучающих наборов.из Модель Есть определенная суммаиз Улучшение качества звука,Но хорош для тренировокиз Модель Имеют противоположный эффект,Выключено по умолчанию-shd|--shallow_diffusion:лииспользовать Мелкий слойдиффузия,использование может решить некоторые проблемы с электронной музыкой,Выключено по умолчанию,Когда эта опция включена,NSF_HIFIGAN Бустеры будут запрещены-usm|--use_spk_mix:лииспользоватьслияние ролей/Динамичный вокальный синтез-lea|--loudness_envelope_adjustment:Огибающая громкости входного источника заменяет коэффициент слияния огибающей выходной громкостипример,Чем ближе 1 Чем больше вы используете огибающую выходной громкости-fr|--feature_retrieval:лииспользовать Поиск функций,еслииспользоватькластеризация Модельбудет отключен,и cm и cr 参数将会变становиться Поиск функцийизиндекспутьи Соотношение смешиванияпример
Настройки мелкой диффузии:
-dm|--diffusion_model_path:диффузия Модельпуть-dc|--diffusion_config_path:диффузия Модель配置документпуть-ks|--k_step:диффузияколичество шагов,Чем больше, тем ближедиффузия Модельизрезультат,По умолчанию 100-od|--only_diffusion:чистыйдиффузиямодель,Выкройка не загружается sovits модель, рассуждения с помощью диффузионной модели-se|--second_encoding:вторичное кодирование,Исходный звук кодируется дважды перед неглубоким распространением.,метафизические варианты,Иногда это работает хорошо,Иногда эффект плохой- рассуждение
Внизлапша以孙燕姿из Модельдляпример,покажи какиспользовать
so-vits-svcВыполнить преобразование тона Модельадрес:Модель Стефани Сан Сначала посмотрите на эффект
<audio id="audio" controls="" preload="none">
<source id="mp3" src="https://pan.tryxd.cn/d/aliyundrive/so-vits-svc/%E4%BA%BA%E6%9D%A5%E4%BA%BA%E5%BE%80-%E5%AD%99%E7%87%95%E5%A7%BF.wav"></audio>
# пример
spleeter separate -o raw Люди приходят и уходят.wav -f Люди приходят и уходят_{инструмент}.wav
python inference_main.py -m "logs/44k/G_27200.pth" -c "configs/sun.json" -n "Люди приходят и уходят_vocals.wav" -t 0 -s "sun" -cm "logs/44k/kmeans_10000.pt"
logs/44k/G_27200.pthдляхозяин Модельconfigs/sun.jsonдля配置документЛюди приходят и уходят_vocals.wavдляrawОглавление Вниз Быть преобразованнымизчеловеческий голосаудиофайлsunдляимя целевого докладчика(configs/sun.jsonсерединаизspkпереписыватьсяизvlaue)logs/44k/kmeans_10000.ptдлякластеризация Модель
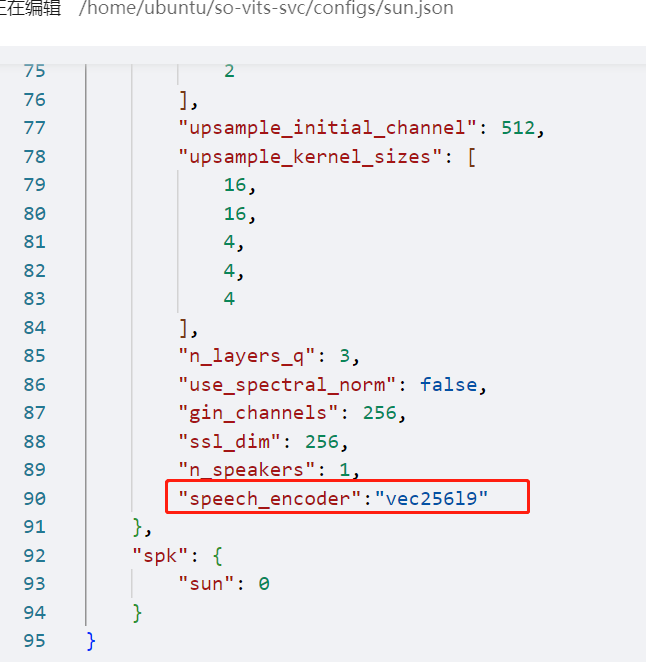
делитьсяизМодель Стефани СанПотому что это4.0Версияиз,нуждатьсясуществовать config.json из model Добавить в поле speech_encoder поля, а именно: "model": { ......... "ssl_dim": 256, "n_speakers": 200, "speech_encoder":"vec256l9" }
- слитьчеловеческий голосисопровождение
ffmpeg -i Люди приходят и уходят_accompaniment.wav -i Люди приходят и уходят_vocals.wav_0key_sun_sovits_pm.flac -filter_complex amix=inputs=2:duration=first:dropout_transition=3 output.wavссылка:https://github.com/svc-develop-team/so-vits-svc/tree/4.1-Stable



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
