Понимание встраивания моделей в семантический поиск с нуля
Проблемы реализации семантического поиска
Как рекламируется большинством поставщиков векторных поисковых систем,Система семантического поискаиз Есть две основные конструкцииПростой(это ирония) шаг:
- Вычисление документа, запрос и встраивание. где-то. Как-то. Ты разбираешься в этом сам.
- Загрузите их в векторные поисковые системы и наслаждайтесь более качественным семантическим поиском.
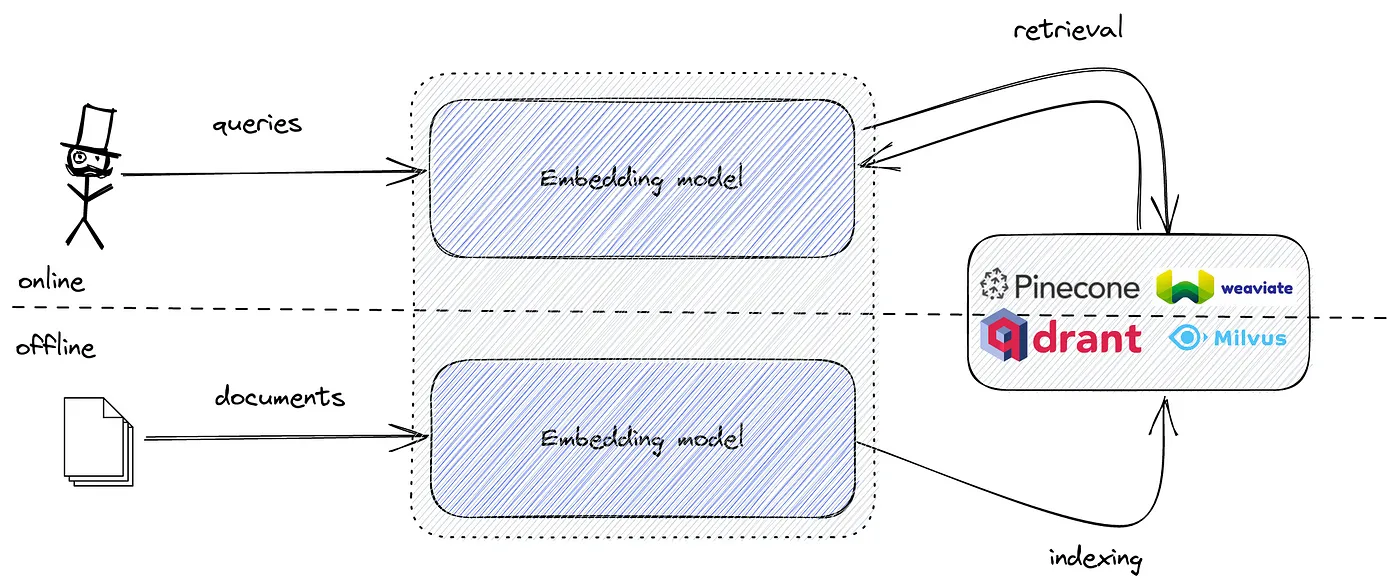
Конечная производительность семантического поиска зависит от вашей модели внедрения.но Модель выбора часто считается недосягаемой для большинства первых пользователей.из Объем возможностей。Так что каждый выбирает, как только появится. sentence-transformers/all-MiniLM-L6-v2,И надеяться на лучший результат.
Однако этот подход создает больше проблем, чем дает ответов:
- Есть ли разница между встраиванием моделей? Опен АИ и Cohere Платная модель лучше?
- Как они справляются с несколькими языками? Являются ли модели с более чем 1 миллиардом параметров более выгодными?
- Использовать встраиваниеиз Плотный поиск - один из многих методов семантического поиска.。это лучше, чемSPLADEv2и ELSER Являются ли такие разреженные методы нового века лучше?
Трансформатор: прародитель всех LLM
Исходную архитектуру Transformer можно рассматривать как черный ящик, который преобразует входной текст в выходной текст. Но сами нейронные сети не понимают текст, они понимают только числа — все внутренние преобразования происходят в форме чисел.
Трансформатор состоит из двух основных модулей:
- кодер:Принять цифровую формуиз Ввод текста,и генерирует встраиваемое представление входного семантического значения из.
- декодер:обратить процесс вспять,Принять встроенное представление,и предсказать следующий текстовый токен
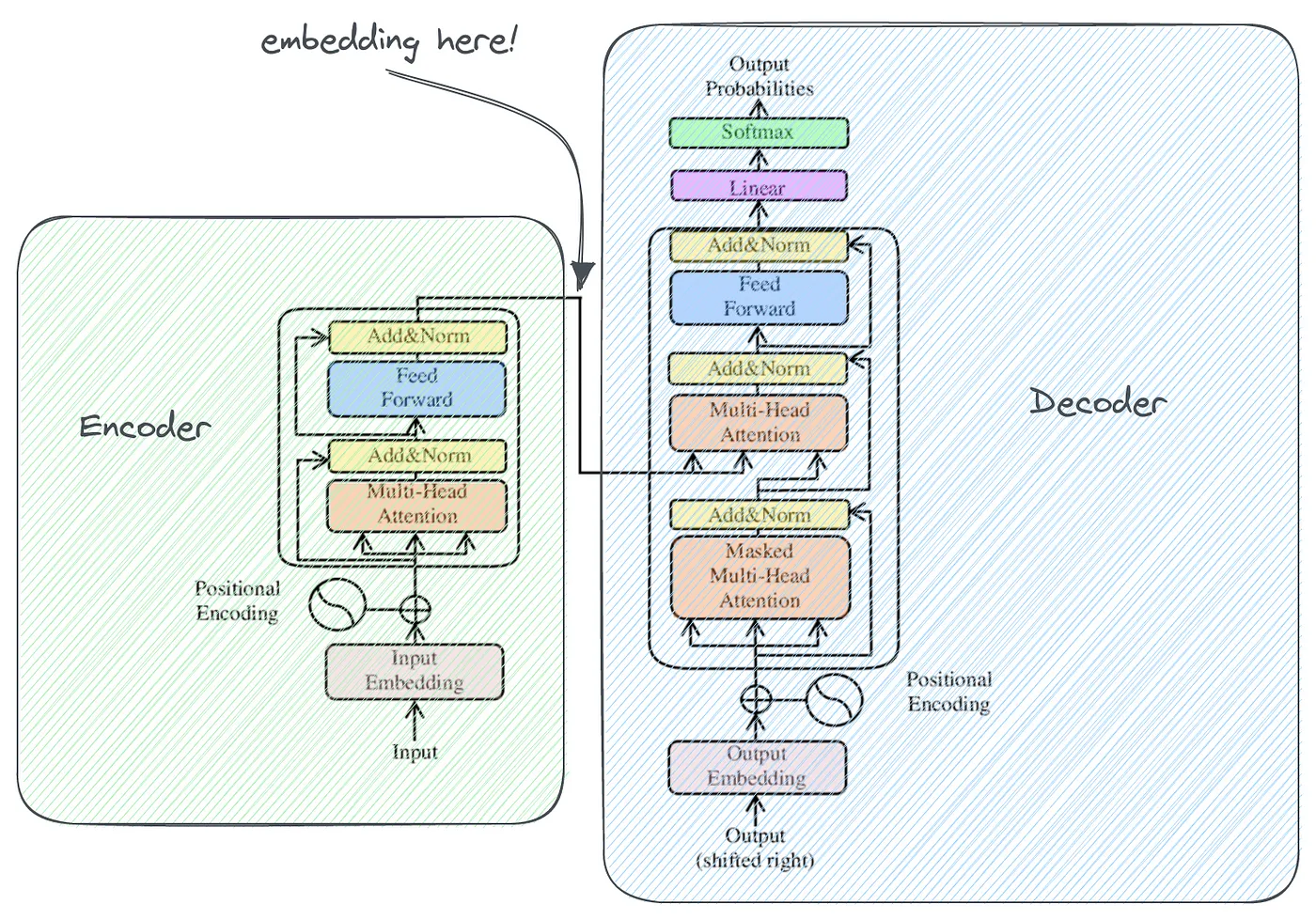
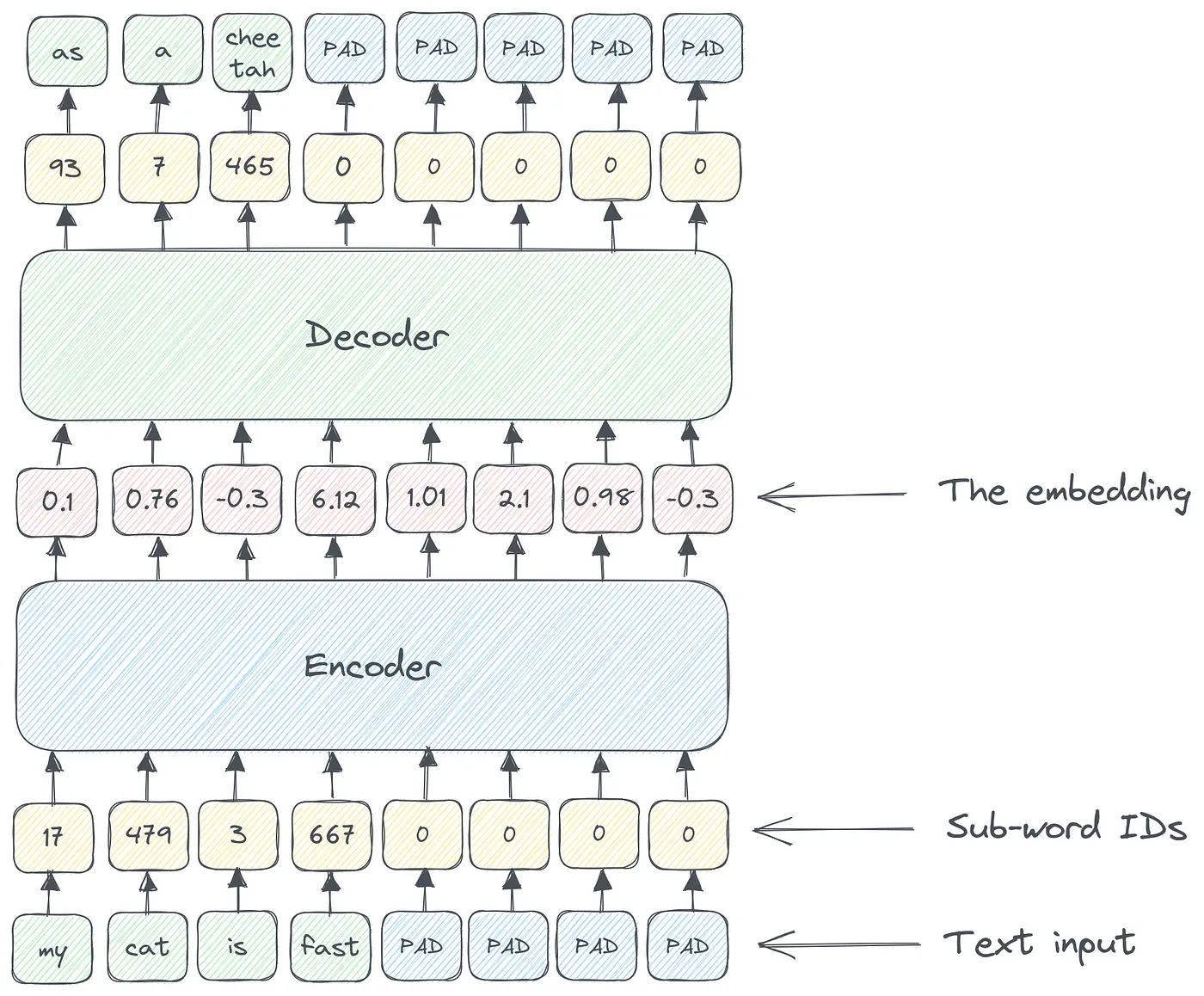
Следовательно, между кодером и декодером существует встроенное представление входа. И входные данные, и внедрение представляют собой числовые векторы, но между ними все же есть существенные различия:
- Входной вектор представляет собой просто последовательность идентификаторов терминов из предопределенного словаря (размер словаря 32 КБ для BERT), дополненную до фиксированной длины.
- Вектор внедрения — это входные данныеизвнутреннее представительство。Вот как тебя видит сетьизвходить。Вы можете ожидать, что аналогичные документы будут иметь схожие внутренние представления.
Несколько лет спустя появилось активное семейство различных моделей обработки текста на основе преобразователей с двумя основными независимыми ветвями:
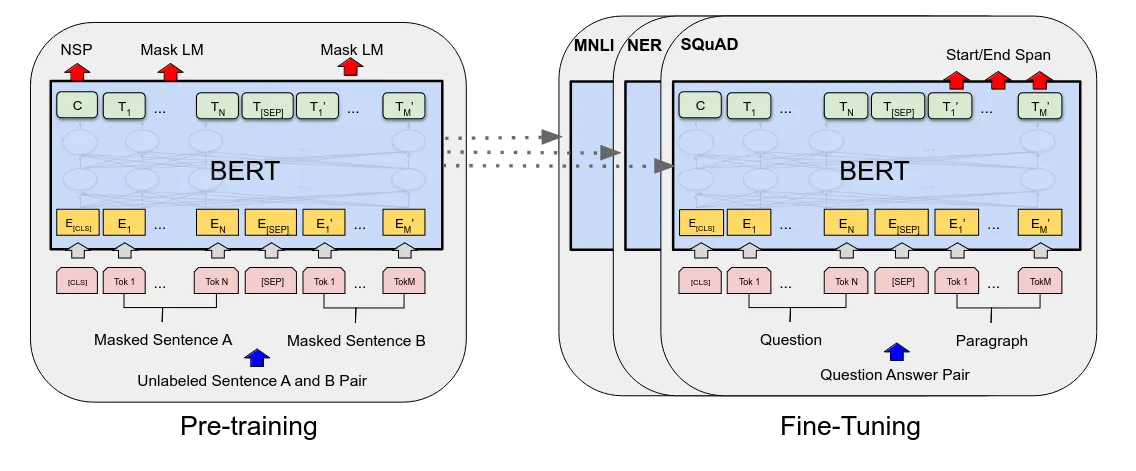
- Соблюдайте BERT, используйте только трансформаторную часть изкодера. Хорошо умеет классифицировать, обобщать и распознавать объекты.
- GPT Серия, только декодер. Хорошо справляется с переводами, контролем качества и другими производственными задачами.
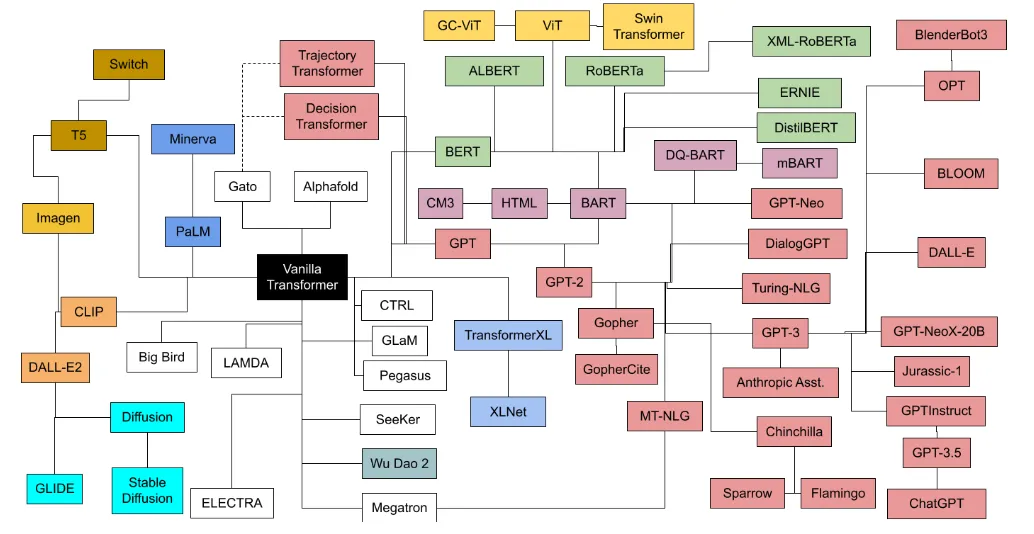
На картинке выше вы можете видеть BERT и GPT между подсемействами моделейизразделять。Традиционно потомки BERT чаще всего использовались в области семантического поиска.。
БЕРТ-модель
Модель BERT кажется очень подходящей для нашей задачи семантического поиска, поскольку ее можно упростить до задачи двоичной классификации конкретных запросов, релевантных и нерелевантных документов.
но BERT Вложения изначально не были предназначены для семантического сходства.:Модель обучена прогнозировать большие текстовые массивы.из Блокировать слова。фактически,Похожие тексты имеют схожие вложения,Это хороший естественный побочный эффект.
но «изначально не предполагалось семантическое сходство» — это всего лишь мнение. Есть ли способ объективно оценить, насколько хорош набор справочных данных?
Тест BEIR
научные статьи “ BEIR: гетерогенный тест для нулевой оценки моделей поиска информации” предложенный IR Метод изэталони Набор данных из набора ссылок. И это делает битву за качество моделей менее интересной: теперь существование имеет Рейтинговый список может сравнить вашу встроенную модель с конкурентами.

Тест BEIR предложенный SET 19 другой IR Набор данных и используется для оценки качества поиска всеми механизмами.
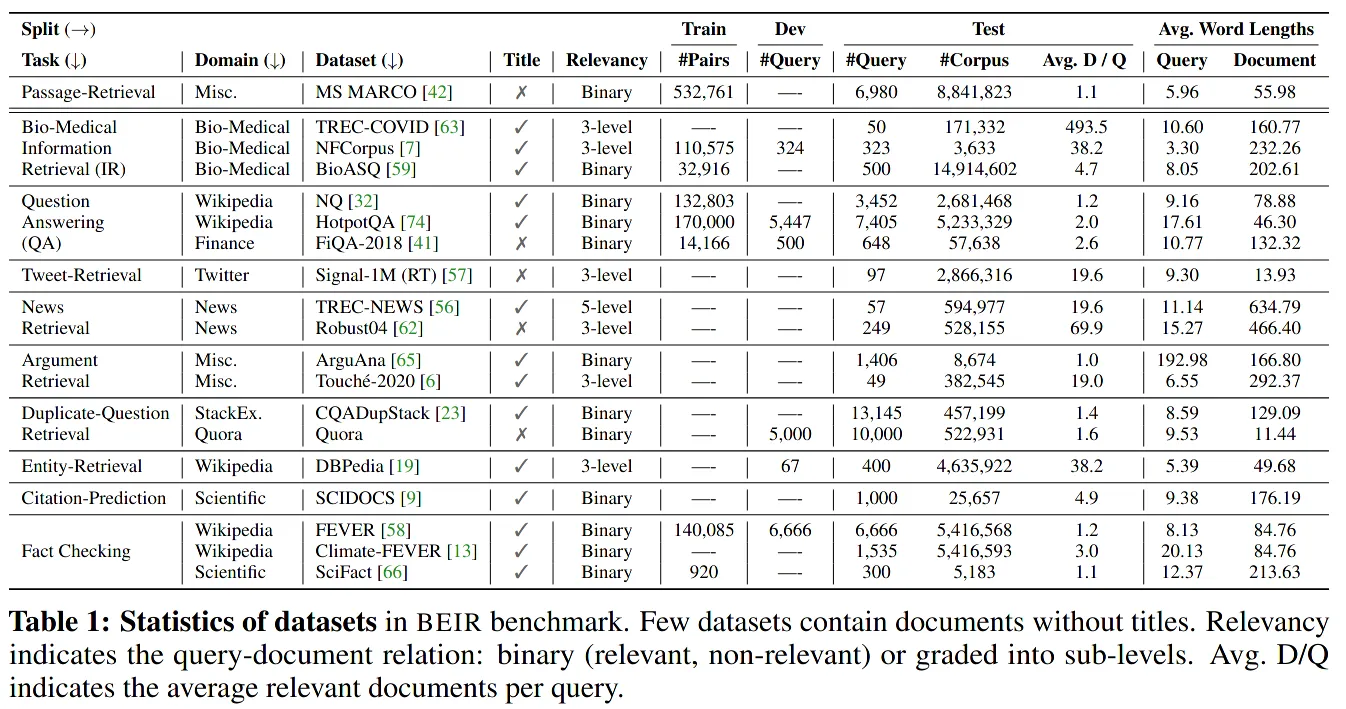
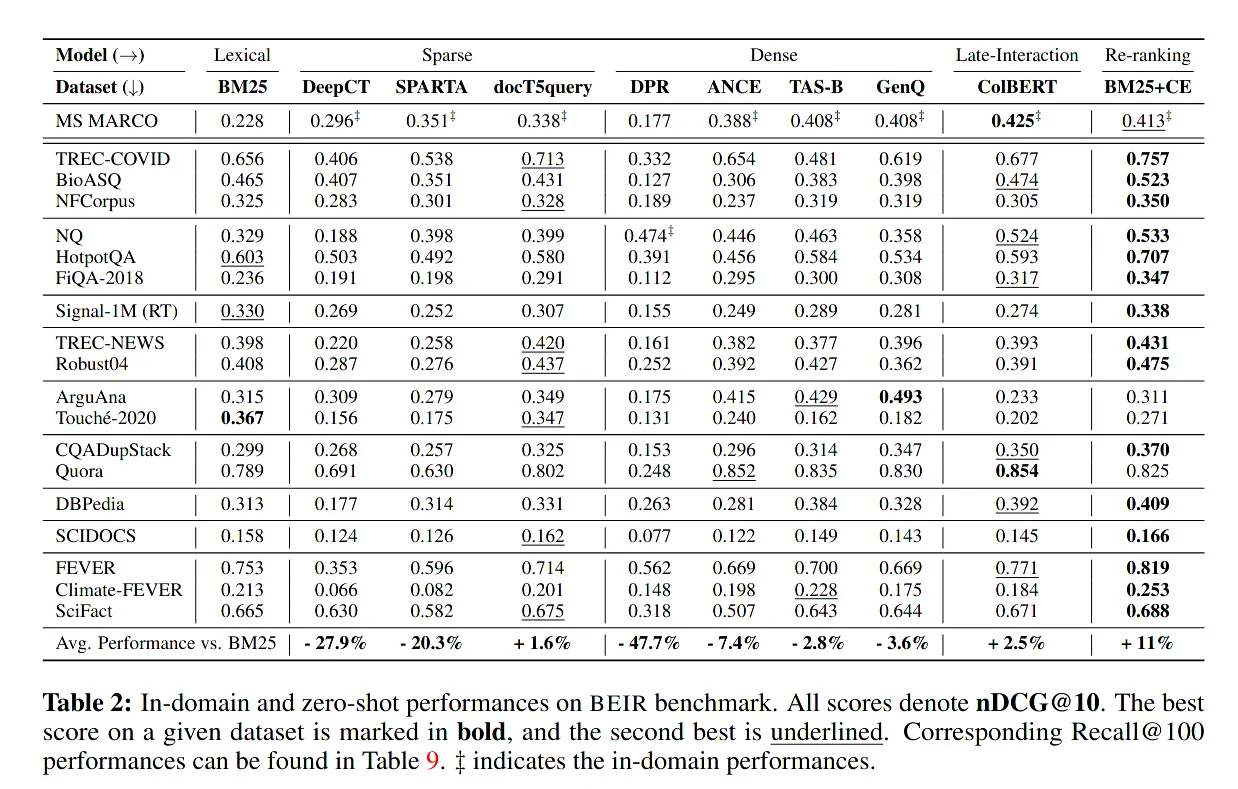
оригинальный Диссертация такжесуществовать Ко всему набору данных было применено несколько базовых методов.эталонтест。2021Год Приходите виз Главный вывод заключается в том,BM25 – вневременная технологияимощныйизбазовый уровень。
позже BEIR быть объединены в более широкуюизэталонв комплекте:MTEB, крупномасштабный тест для встраивания текста。Запустить его очень просто(если у тебя есть 128GB оперативная память, современная GPU и 8 часов свободного времени):
from mteb import MTEB
from sentence_transformers import SentenceTransformer
# load the model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
# run a subset of all benchmarks
evaluation = MTEB(tasks=["MSMARCO"])
results = evaluation.run(model, output_folder="results")
Как мы уже говорили ранее, давайте вернемся к центральной идее статьи: «исходное встраивание BERT нельзя использовать для семантического поиска». если мы будем bert-base-uncased(языковая модель)ина высшем уровнеиз Модель преобразования предложений all-MiniLM-L6-v2 а также all-mpnet-base-v2 Собрав все это вместе и протестировав на бенчмарке BEIR/MTEB, мы получаем следующие цифры:
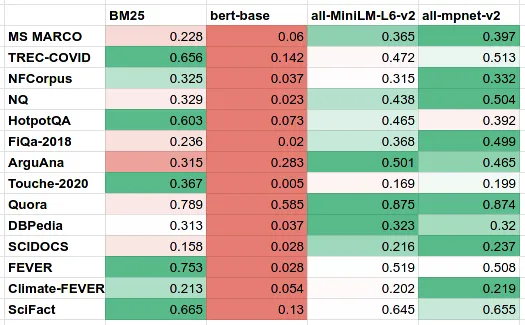
Из этой таблицы можно сделать два очевидных вывода:
- исходныйоригинальныйВложения BERT предназначены для предсказания следующего слова, а не для семантического поиска.и Сходство документов。сейчассуществовать Вы можете понять, почему。
- BM25 остается сильным базовым показателем——Даже с поправкой на смысловое сходство.из大规模 MPNET Модели тоже не всегда могут победить
но почему производительность аналогичных моделей встраивания настолько различна в задачах семантического поиска?
Рейтинговый список
Текущий (2023 г.) Год 6 月)МТЕБ/БЭИР эталон Рейтинговый Список выглядит полным неизвестных имён:

Мы можем Подвести итоги на данный момент самый продвинутый из семантического поиска:
- SBERT Спецификация(s-MiniLM-L6-v2;s-MiniLM-L12-v2 и all-mpnet-base-v2) имеет хороший баланс между простотой и качеством ранжирования.
- SGPT (5.8B, 2.7B, 1.3B) — это Ло Ра.тонкая настройкаиз Открытый исходный код GPT-NeoX Последняя версия модели ранжирования
- GTR-T5да Google Модель внедрения с открытым исходным кодом для семантического поиска с использованием T5 LLM в качестве основы.
- E5(v1 и в2) Да Microsoft Последняя модель встраивания.
Мы можем рассматривать эти четыре семейства моделей через призму двух философий построения моделей семантического поиска:
- производительность。Модель越小,Чем ниже задержка поиска,Скорость индексирования выше。огромныйиз SGPT и GTR Модель может существовать только дорого из GPU беги дальше.
- размер。Модель中из Чем больше количество параметров,Чем лучше качество поиска。all-MiniLM-L6-v2 Отличная модель, но она слишком мала для использования. 10M Параметры фиксируют все семантические различия при поиске.
Поиск баланса между размером и размером имеет решающее значение для создания отличных моделей внедрения.
Встраивание и разреженный поиск
Встраивание — один из многих способов проведения поиска. старый BM25 По-прежнему сильная база, и есть несколько новых «редких» методов поиска, например. SPLADEv2 и ColBERT - 结合了分词术语搜索инейронная сетьиз Преимущества。
В таблице ниже мы попытались объединить все общедоступные оценки BEIR из нескольких источников:
- Хранилище результатов MTEB Содержит Рейтинговый списокиспользуется визвсеоригинальный Фракция。оно также включает в себяOpenAI商用嵌入Модельиз Фракция,В том числе последняя модель Изада-2.
- ArXivиз Бумажные обложки для препринтовColBERT、SPLADEv2 и BEIR Содержание статьи.
- поставщикиз Сообщение в блоге представляетVespa о внедрении ColBERTизсодержание,а ТакжеElasticО программе ELSER содержание.
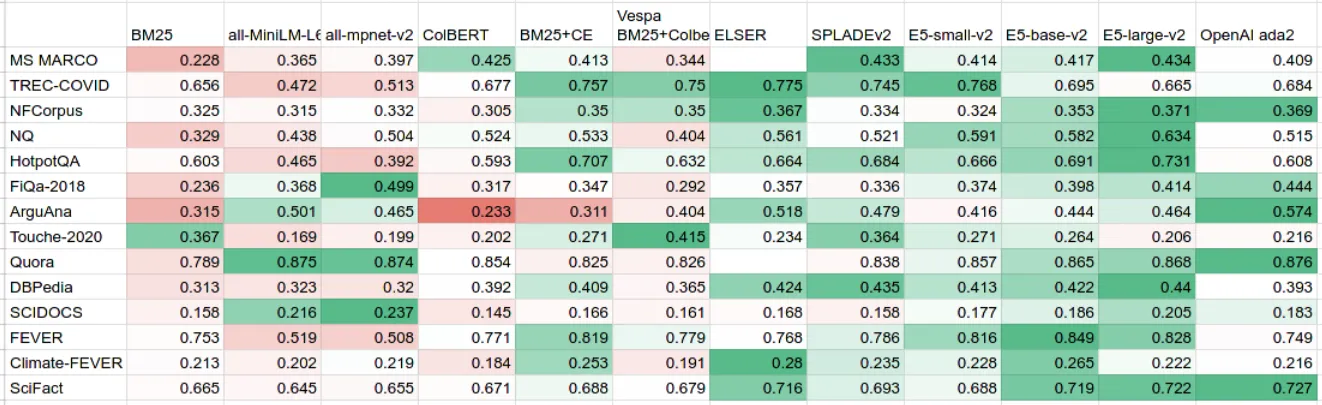
Если эта таблица опубликована два года назад BEIR таблица для сравнения, вы можете заметить BM25 Считается сильной базой - ноBM25 существует 2023 Год больше не является явным победителем。
另一个观察结果даразреженный (например, ELSER и SPLADev2) и интенсивный (E5) методы поиска качественно существуют очень близко。поэтому,В этой области нет явного победителя,но здорово видеть такую большую конкуренцию.
Личный взгляд автора на спор между разреженными и плотными методами поиска:
- Интенсивный поиск более перспективен в будущем。от SBERT обновить до E5 Только 10 ХОРОШОкод,Качество поиска значительно улучшилось. И ваша векторная поисковая система остается неизменной,Никакого дополнительного проектирования не требуется.
- Разреженный поиск вызывает меньше галлюцинаций.,И может обрабатывать точное соответствие и соответствие ключевых слов. NDCG@10 — единственные критерии измерения качества поиска.
но дебаты продолжаются, и мы будем держать вас в курсе последних событий.
Скрытые расходы на большие модели
Принято считать, что чем больше модель, тем лучше качество ее поиска. от MTEB Рейтинговый Это хорошо видно по списку,но它忽略了服务这些Модельизпростотаидешевый Секс – это важно и практично.изособенность。
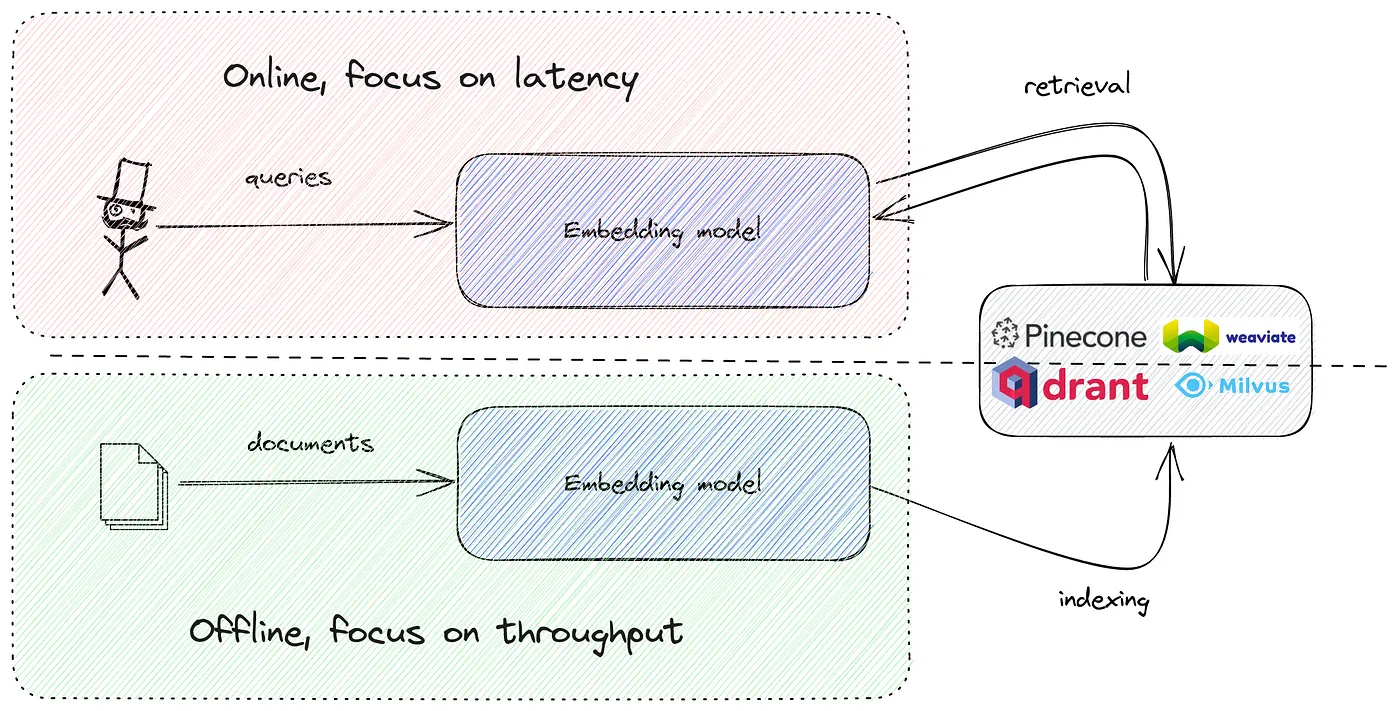
По сути, вам нужно запустить модель внедрения дважды:
- Фаза индексирования отключена。这да一个批处理作业,Нужна высокая пропускная способность,но Нечувствителен к задержкам.
- Встроить поисковый запрос в строку существования в каждом поисковом запросе。
картина SBERT и E5 Таким образом, маленькая модель может разумно существовать без задержек и легко существовать в рамках бюджета. CPU Запустить но, если параметры превышают 500M(SGPT ситуации), вы не можете избежать использования графический процессор. сейчас GPU Дорогой.
Чтобы увидеть реальные цифры задержки, мы существуем https://github.com/shuttie/embed-benchmark, обеспечивающий JMH маленьких ONNX Основа рассуждений:
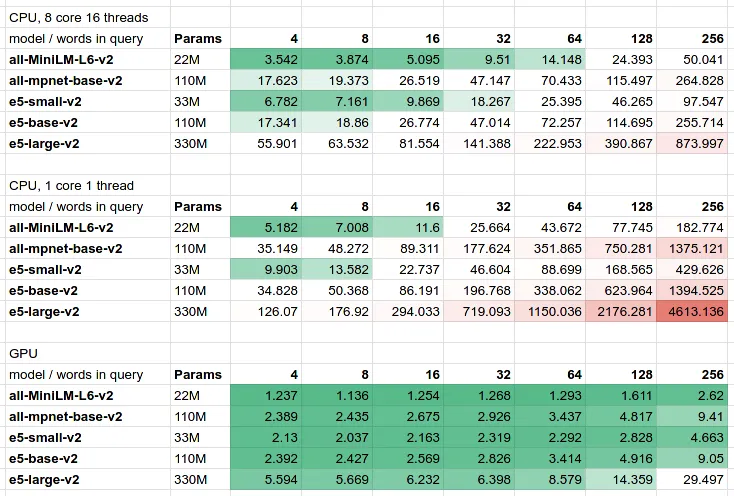
Как видно из таблицы:
- Существует линейная зависимость между количеством параметров и задержкой на CPU и GPU.。для краткостииз 4 Словесный запрос, картина SGPT-1.3B такиз大型Модель预计延迟为200 миллисекунд,Зачастую этого оказывается слишком много для рабочих нагрузок, связанных с клиентами.
- Компромисс задержки/стоимости/качества。тыиз Семантический поиск быстрый、дешевый、точный —— У вас не может быть всех троих, вы можете выбрать только два из них.
Многоязычная модель
Не только мир говорит на английском языке, но и большинство моделей и оценочных систем работают только на английском языке:
- Оригинальный словарный запас BERT в основном обучается на английских данных.,существование обучения на других языках достаточно слабое.
- Почти все модели внедрения обучаются на существующем корпусе английских текстов.,Поэтому они оба слегка предвзято относятся к корпусам английских текстов.
Это происходит, если вы передаете в токенизатор BERT текст не на английском языке:
from transformers import BertTokenizer, AutoTokenizer
bert = BertTokenizer.from_pretrained("bert-base-uncased")
e5 = AutoTokenizer.from_pretrained('intfloat/multilingual-e5-base')
en = bert.encode("There is not only English language")
print(bert.convert_ids_to_tokens(en))
# ['[CLS]', 'there', 'is', 'not', 'only', 'english', 'language', '[SEP]']
de = bert.encode("Es gibt nicht nur die englische Sprache")
print(bert.convert_ids_to_tokens(de))
# ['[CLS]', 'es', 'gi', '##bt', 'nic', '##ht', 'nur', 'die', 'eng', '##lis', '##che', 'sp', '##rac', '##he', '[SEP]']
de2 = e5.encode("Es gibt nicht nur die englische Sprache")
print(e5.convert_ids_to_tokens(de2))
# ['<s>', '▁Es', '▁gibt', '▁nicht', '▁nur', '▁die', '▁englische', '▁Sprache', '</s>']Токенизатор BERT не может правильно обрабатывать немецкие слова как отдельные токены и должен быть разделен на подслова. Для сравнения, многоязычный токенизатор XLM обрабатывает то же предложение гораздо лучше.
К счастью, большинство моделей, упомянутых в этой статье, доступны на нескольких языках:
- E5:multilingual-e5-base,является многоязычной согласованной версией XLM-Roberta-base.
- SGPT:sgpt-bloom,На основе модели BLOOM.
- SBERT:на основеMUSE'sМногоязычный MiniLM-L12-v2
Подвести итог
Подводя итог, основные выводы этой статьи заключаются в следующем:
- BM25существовать нелегко превзойти с точки зрения качества поиска.。Учитывая, что это не требует никаких корректировок.,并且ты可以существовать 3 Создайте его за несколько минут Elasticsearch кластер - существовать 2023 Год полагается на то, что это еще осуществимо из.
- недавносуществоватьредкийиплотный мириз Поле поискаПроисходит большой прогресс.SGPTиE5из История еще не1Год,SPLADEи ELSER из История легче.
- Среди разреженных/плотных методов нет единого победителя, но IR Отрасль объединяется в один инструмент бенчмаркинга, MTEB/BEIR Комплект приходитИзмерьте качество поиска.
Источник этой статьи: https://blog.metarank.ai/from-zero-to-semantic-search-embedding-model-592e16d94b61.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
