Полный анализ извлечения сущностей: технология и практика
Погрузитесь в Извлечение Все аспекты сущности технологии, от подходов, основанных на правилах, до нейронных сетьизглубокое метод обучения, представляет собой серию подробных технических вводных и практических случаи。 Следуйте за TechLead и делитесь всесторонними знаниями об искусственном интеллекте. Автор имеет более чем 10-летний опыт работы в области архитектуры интернет-сервисов, опыт исследований и разработок продуктов искусственного интеллекта, а также опыт управления командой. Он имеет степень магистра Университета Тунцзи в Университете Фудань, член Лаборатории интеллекта роботов Фудань, старший архитектор, сертифицированный Alibaba Cloud. , специалист по управлению проектами, а также занимается исследованиями и разработками продуктов искусственного интеллекта с доходом в сотни миллионов человек.
1. Предисловие
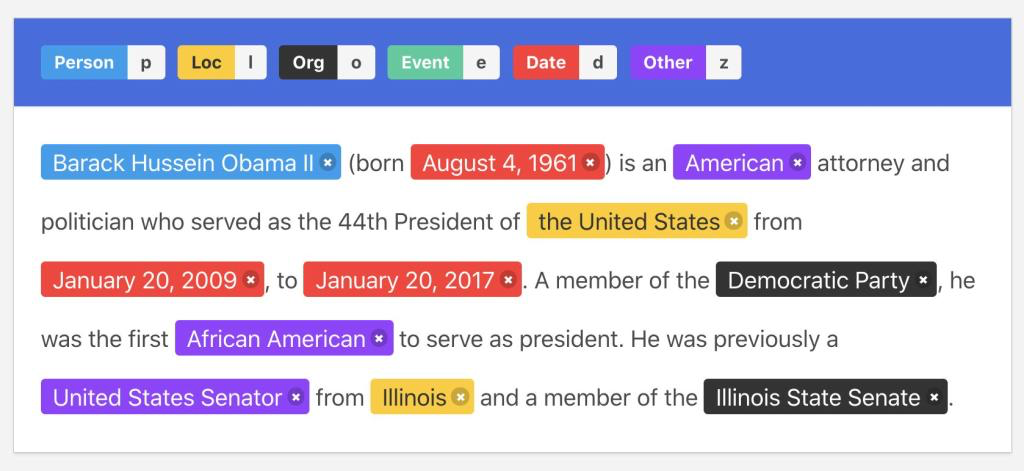
Извлечение сущности(Named Entity Recognition, NER) занимает незаменимую позицию в области обработки естественного языка (НЛП). Его основная задача — идентифицировать в тексте сущности с определенным значением, такие как имена людей, мест, организаций и т. д., что имеет решающее значение для понимания и анализа больших объемов неструктурированного текста. Глубокое понимание Извлечения Суть технологии заключается не только в освоении ее основных принципов и методов применения, но также в изучении ее технических деталей, проблем и инновационных решений для решения этих проблем.
2. Обзор технологии извлечения сущностей
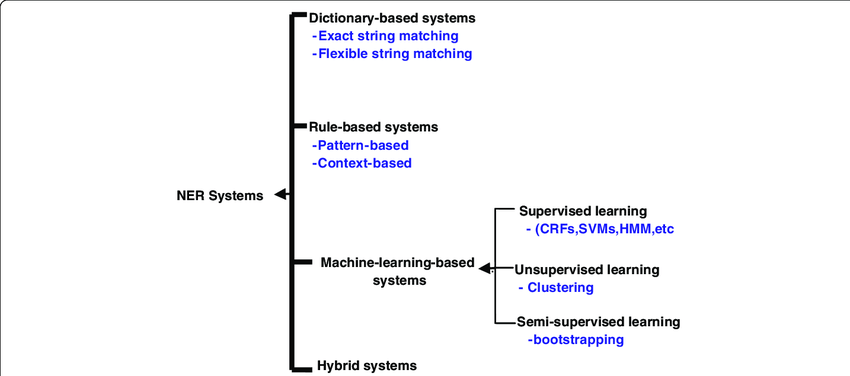
Извлечение сущности, как основная задача обработки естественного языка (НЛП), направлена на выявление фрагментов информации с определенным значением из текста и классификацию их по заранее определенным категориям, таким как имена людей, места, названия организаций и т. д. Этот процесс обычно включает два основных этапа: распознавание объекта и классификация объекта. Распознавание объектов означает определение границ объектов в тексте, а классификация объектов означает отнесение распознанных объектов к соответствующим категориям. Извлечение Технические методы определения причин можно грубо разделить на три категории: методы, основанные на правилах, методы, основанные на статистике, и методы, основанные на глубоких знаниях. метод обучения.
Ранние методы извлечения сущностей
Методы на основе правил и словаря
Ранние системы извлечения причин в основном опирались на рукописные правила и словари. Эти методы идентифицируют и классифицируют объекты в тексте, определяя определенные языковые правила и списки словаря. Хотя эти методы хорошо работают в определенных доменах и ограниченных наборах данных.,Но им не хватает универсальности.,Существуют огромные проблемы с расширением масштабов и адаптируемостью предметной области.
Методы машинного обучения на основе функций
С машинным С развитием технологий обучения для Извлечения стали применяться признаки, основанные на методах. сущности По заданию。这一阶段из方法通常нуждаться要手工设计特征,Например, теги части речи, контекстная информация, грамматические зависимости и т. д.,Эти функции затем используются для обучения модели классификации (например, машины опорных векторов SVM, дерева решений и т. д.) для идентификации объектов в тексте. Этот тип метода является значительным улучшением по сравнению с методами чистого правила и словаря.,Но он по-прежнему требует трудоемкой разработки функций и большого объема знаний в предметной области.
Извлечение сущностей в эпоху глубокого обучения
От традиционных моделей к нейронным сетям
С глубоким обучение Расцвет технологий, Извлечение Фокус исследований миссии сущности стал смещаться в сторону использования модели нейронной сеть. По сравнению с традиционными методами, более глубокие Метод обучения может автоматически изучать сложные представления функций на основе данных, уменьшая зависимость от ручного проектирования функций. Первые дни модели нейронной сети,Такие как свертканейронная сеть(CNN)и циклнейронная сеть(RNN),Уже в Извлечение Он показывает лучшую производительность в задаче по изучению веществ.
Рост моделей маркировки последовательностей
Особенно сочетание сети длинной краткосрочной памяти (LSTM) и условного случайного поля (CRF), для Извлечения. Такие задачи приносят значительное улучшение производительности. Эта комбинация использует преимущества мощных возможностей моделирования последовательностей LSTM и эффективную производительность CRF в задачах аннотации последовательностей и на какое-то время стала популярным выбором. Стандартная практика для задач по определению.
Революция предварительно обученных языковых моделей
в последние годы,Предварительно обученная языковая Появление моделей (таких как BERT, GPT и т. д.) еще больше способствовало Извлечению. Развитие технологии веществ. Эти Модели усвоили богатые языковые возможности и знания посредством предварительного обучения на крупномасштабных корпусах, а затем адаптировались к последующим задачам НЛП посредством тонкой настройки, включая Извлечение. сущности. Применение Предтренировочной Модели не только в Извлечении Это позволило достичь беспрецедентной точности в задаче определения веществ и значительно сократить Модельное сложность и сложность обучения.
3. Подход, основанный на правилах
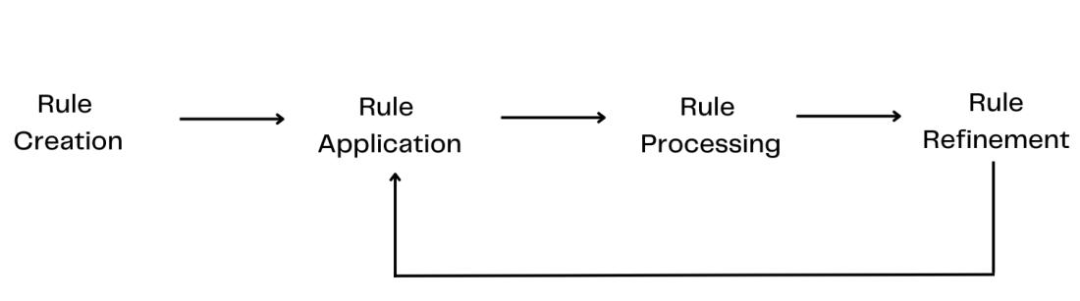
Подход, основанный на правилах, – это Извлечение Одна из самых ранних технологий обнаружения, она опирается на предопределенные языковые правила и словари для идентификации конкретных объектов в тексте. Хотя с машинным обучениеиглубокое Обучение Технологическое развитие, подход, основанный на правилах, может показаться примитивным и ограниченным, но в конкретных сценариях и приложениях этот подход обусловлен своей высокой Его легко понять и реализовать, и он по-прежнему имеет определенную прикладную ценность.
Как работает подход, основанный на правилах
Определение правила
Извлечение на основе правил сущности方法主要依赖于手工编写из规则。Эти правила могут быть регулярными выражениями.、шаблон тега части речи、词汇匹配列表或它们из组合。Например,Сопоставление номеров телефонов и адресов электронной почты с помощью регулярного выражения,или черезшаблон тега части речи来识别名词短语作为潜существоватьиз实体。
Сопоставление словаря
кроме правил,Подходы, основанные на правилах, также часто используют словари (или списки сущностей) для сопоставления сущностей. Эти словари содержат большое количество названий для конкретных типов объектов.,Например, имена людей, мест, организаций и т. д. Автор: Сопоставление словарь, система способна идентифицировать известные объекты, встречающиеся в тексте.
Применение правил
На практике правила и словари часто интегрируются в конвейер обработки для идентификации и извлечения объектов из текста. Этот процесс может включать предварительную обработку текста, маркировку частей речи, синтаксический анализ и другие шаги, способствующие сопоставлению правил и распознаванию объектов.
Преимущества и недостатки подходов, основанных на правилах
преимущество
- Высокая прозрачность:规则да人工定义из,Легко понять и проверить.
- Широкие возможности настройки:可以针对特定领域或Задача定制规则и词典。
- Быстрый ответ:相比于复杂измашинное обучение Модель,Сопоставление правил обычно требует больших вычислительных затрат.,Быстрый.
недостаток
- Плохая масштабируемость:手工编写规则и维护词典耗时耗力,И трудно адаптироваться к языковым изменениям и расширению домена.
- Слабая способность к обобщению:基于规则из方法很难处理未见过из实体或新из表达方式。
- Высокие затраты на техническое обслуживание:随着应用领域из扩大,Стоимость содержания правил и словарей резко возрастает.
Практические случаи
описание сцены
Предположим, нам нужно извлечь названия компаний из статей финансовых новостей. Язык финансовых новостей относительно стандартизирован, а порядок появления названий компаний относительно фиксирован, что обеспечивает применимые сценарии для метода, основанного на правилах.
Правила и словарные определения
- Определение правила:利用正则表达式识别典型из公司后缀,Такие как «Инк.», «Лтд.» и т. д.
- Здание словаря:构建一个包含常见金融机构名称из词典。
Пример реализации
import re
# Правила регулярных выражений, определяющие названия компаний
company_pattern = re.compile(r'\b(?:\w+\s){0,2}\w*?(?:Inc|Ltd|Corporation|Group)\b')
# образец текста
text = "GlobalTech
Inc. announced a merger with Innovate Ltd. today."
# Применить правила
matches = company_pattern.findall(text)
print("Identified Companies:", matches)
выход
Identified Companies: ['GlobalTech Inc.', 'Innovate Ltd.']
С помощью этого простого Практические Иногда мы можем увидеть эффективность подхода, основанного на правилах, в конкретных сценариях. Однако важно отметить, что в более сложных или разнообразных текстовых средах подходы, основанные на правилах, возможно, придется сочетать с другими методами для улучшения Извлечения. точность и охват содержания.
4. Методы машинного обучения на основе функций
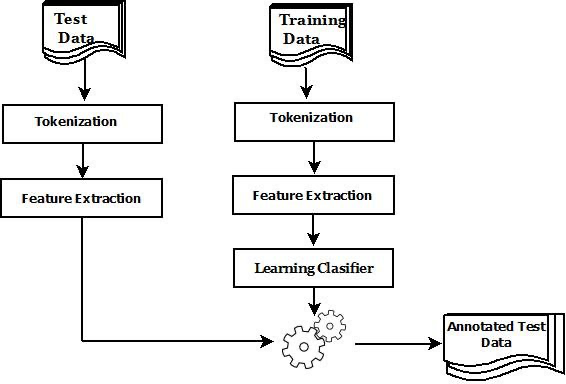
С развитием технологий обработки естественного языка Извлечение Миссия по поиску источников началась с Методов машинного обучения на основе функции. Эти методы работают путем ручного извлечения функций из текстовых данных, а затем использования этих функций для обучения машинных данных. обучение Модель для идентификации и классификации сущностей. Этот переход знаменует собой важный шаг от статических правил к динамическому обучению, обеспечивая основу для Извлечения. Развитие технологии веществ дает новый импульс.
основные понятия
Извлечение признаков
Извлечение признаковда Методы машинного обучения на основе Ключевой шаг в функциях, который включает в себя извлечение информации, которая может представлять характеристики объекта, из исходных текстовых данных. Эти функции обычно включают теги части речи, именованные типы объектов, префиксы и суффиксы слов, корни слов, контекстную информацию. информация, зависимость и т. д.
Модельное обучение
Используя извлеченные функции, можно обучить различные типы моделей машинного обучения распознаванию и классификации объектов, включая деревья решений, случайные леса, машины опорных векторов (SVM), логистическую регрессию и т. д. Эти модели изучают взаимосвязи между функциями и типами объектов для эффективного распознавания объектов в новых текстовых данных.
Технология извлечения признаков
В методах, основанных на функциях, способ выбора и извлечения функций напрямую влияет на производительность модели. Общие признаки технологии извлечения включают в себя:
- Маркировка части речи (POS):标记单词существовать句中из语法角色,Например, существительные, глаголы и т. д.
- анализ синтаксических зависимостей:提取词与词之间из依存关系,Используется для сбора информации о структуре предложения.
- контекстная информация:考虑目标词前后из词汇,Используется для определения контекстуальной значимости.
- Морфологические особенности:нравитьсякорень、префикс、суффикс и т. д.,Используется для выявления морфологических изменений в словарном запасе.
Практические случаи
описание сцены
Рассмотрим сценарий,Нам нужно извлечь упоминания названий продуктов из текстов социальных сетей. Такие тексты обычно очень неформальны.,и полно интернет-сленга и сокращений,Давать Извлечение Существа создают дополнительные проблемы.
Определение функции и выбор модели
- Определение функции:чтобы справиться с неформальными текстами,Мы выбираем тегирование части речи、Информация до и после слова、а также Морфологические Особенности как главная особенность.
- Выбор модели:考虑到Задачаиз复杂性,В качестве классификатора выбираем машину опорных векторов (SVM).,Потому что он хорошо работает при работе с многомерными разреженными данными.
Пример реализации
Предполагая, что мы завершили этапы предварительной обработки и структурирования, вот упрощенный пример обучения с использованием SVM из библиотеки Scikit-learn:
from sklearn.svm import LinearSVC
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.pipeline import Pipeline
from sklearn.datasets import load_files
# Загрузка обучающие
data = load_files('data/product_names', encoding='utf-8')
X, y = data.data, data.target
# Создайте простой конвейер, включающий векторизацию TF-IDF и классификатор SVM.
pipeline = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', Linear
SVC()),
])
# Модель обучения
pipeline.fit(X, y)
# Пример прогноза
predictions = pipeline.predict(["Check out the new smartphone from TechCo!"])
print("Predicted entity:", predictions[0])
выход
Predicted entity: PRODUCT_NAME
По этому Практические иногда мы можем видеть Методы машинного обучения на основе функций Обработка Извлечение В чем заключается гибкость и эффективность при выполнении задач. Однако процессы выбора функций и настройки модели часто требуют большого опыта и экспериментов, что также является серьезной проблемой, с которой сталкивается этот тип метода. С глубоким Возникновение метода обучения, автоматическое Извлечение становится возможным, для Извлечения Развитие технологии веществ открыло новые пути.
5. Метод глубокого обучения на основе нейронной сети.
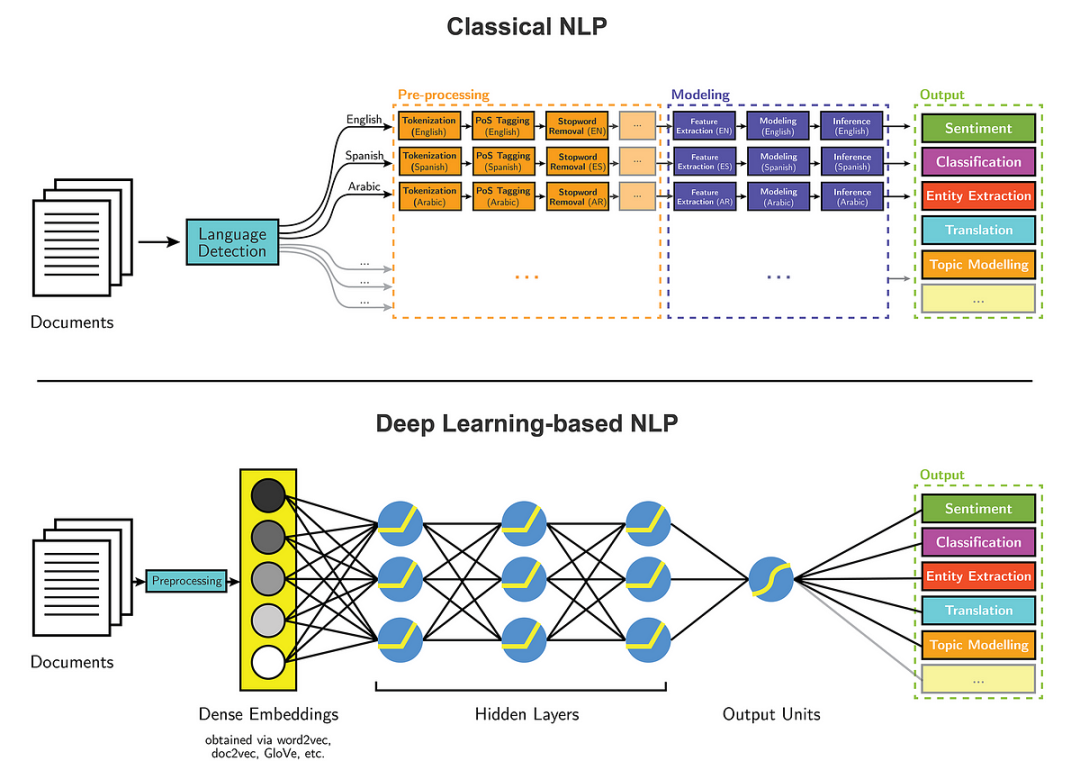
С глубоким Быстрое развитие технологий обучения основано на нейронных Метод сети стал Извлечением Мейнстрим в области сущностей. Эти методы значительно улучшают извлечение за счет автоматического изучения сложных представлений функций из больших объемов данных. Производительность веществ.
Обзор методов на основе нейронных сетей
модель нейронной сети
существовать Извлечение Наиболее часто используемая модель в задачах сущности. нейронной сетивключая сверткунейронная сеть(CNN)、циклнейронная сеть(RNN)、Сеть долгосрочной краткосрочной памяти (LSTM) и вентилируемая рекуррентная единица (GRU). Эти модели способны фиксировать локальные функции (CNN) и зависимости на расстоянии (RNN) в текстовых данных.、LSTM、GRU),Чрезвычайно эффективно справляется со сложностью естественного языка.
Предварительно обученная языковая модель
в последние годы,Предварительно обученная языковая модели, такие как BERT, GPT и RoBERTa и т. д., усвоили богатые языковые функции и знания посредством предварительного обучения на крупномасштабных корпусах, а затем адаптировались к конкретным задачам НЛП посредством тонкой настройки, включая Извлечение. сущности. Появление этой модели еще больше усилило извлечение. Улучшения производительности технологии веществ.
Практические случаи
описание сцены
Учитывая, что комментарии пользователей в социальных сетях содержат большое количество необработанных текстовых данных, содержащих богатые эмоции и мнения пользователей, наша цель — автоматически извлекать из этих комментариев упомянутые названия брендов и продуктов.
использовать Предварительно обученная языковая модельруководить Извлечение сущности
Для достижения этой цели мы решили использовать модель BERT для точной настройки. БЕРТ (Двунаправленный Encoder Representations from Transformers)да一个基于Transformerиз预Модель обучения,Он понимает семантику текста путем двунаправленного обучения модели языка.,очень подходит Извлечение сущности и другие задачи НЛП.
Подготовка данных
Сначала нам нужно подготовить размеченный набор данных, который содержит текст и соответствующие аннотации к объектам. Для упрощения объяснения мы предполагаем, что такой набор данных уже существует.
Тонкая настройка модели
Использование Python и библиотеки PyTorch,Мы можем легко настроить BERTМодель,以适应我们из Извлечение суть миссии. Вот упрощенный пример процесса тонкой настройки:
from transformers import BertTokenizer, BertForTokenClassification, Trainer, TrainingArguments
from torch.utils.data import DataLoader
import torch
# Инициализировать токенизатор BERT
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# Загрузите предварительно обученную модель BERT для классификации токенов (Извлечение сущности)
model = BertForTokenClassification.from_pretrained('bert-base-uncased', num_labels=number_of_entity_types)
# Подготовьте данные и параметры обучения (при условии, что данные уже подготовлены)
train_dataset = ... # Ваш набор данных для обучения
training_args = TrainingArguments(
output_dir='./models',
num_train_epochs=3,
per_device_train_batch_size=16,
warmup_steps=500,
weight_decay=0.01,
logging_dir='./logs',
)
# Инициализировать трейнер
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
)
# Начать обучение
trainer.train()
Этот код показывает, как использовать объятия Библиотека трансформеров Face для загрузки модели BERT, а затем ее точной настройки в соответствии с конкретным извлечением. сущности Задача。
нуждаться Следует отметить, что,这里изnumber_of_entity_types应该根据你из По заданию实体из类型数量来设置。
Извлечение сущности
Модельное После завершения обучения мы можем использовать обученную Модель для выполнения Извлечения новых текстовых данных. сущности:
# образец текста
text = "I love the new iPhone that was released by Apple last week."
# Сегментация слов и преобразование во входной формат модели
input_ids = tokenizer.encode(text, return_tensors="pt")
# Прогнозирование с помощью модели
with torch.no_grad():
output = model(input_ids)[0]
predictions = torch.argmax(output, dim=2)
# Преобразуйте результаты прогнозирования в метки объектов (логика преобразования здесь опущена)
# ...
С помощью этого упрощенного Практические случаях мы можем видеть на основе предварительного обученная языковая модельизглубокое обучение方法существовать Извлечение сущности Задача上из应用。Этот тип метода работает путем извлечения из большого количестваданные Автоматически изучать представления объектов в,Значительно снижает потребность в ручном проектировании функций.,Это также обеспечивает большую точность и гибкость.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
