Полное руководство по локальному развертыванию больших моделей с открытым исходным кодом: LangChain + Streamlit + Llama.
За последние несколько месяцев большие языковые модели (LLM) привлекли к себе значительное внимание, и эти модели открывают захватывающие перспективы, особенно для разработчиков, работающих над чат-ботами, личными помощниками и созданием контента.

Большие языковые модели (llm) относятся к моделям машинного обучения, которые способны генерировать текст, очень похожий на человеческий язык, и естественным образом понимать сигналы. Эти модели обучаются с использованием широкого спектра наборов данных, включая книги, статьи, веб-сайты и другие источники. Анализируя статистические закономерности в данных, LLM прогнозирует слова или фразы, которые с наибольшей вероятностью могут встретиться при заданных входных данных.
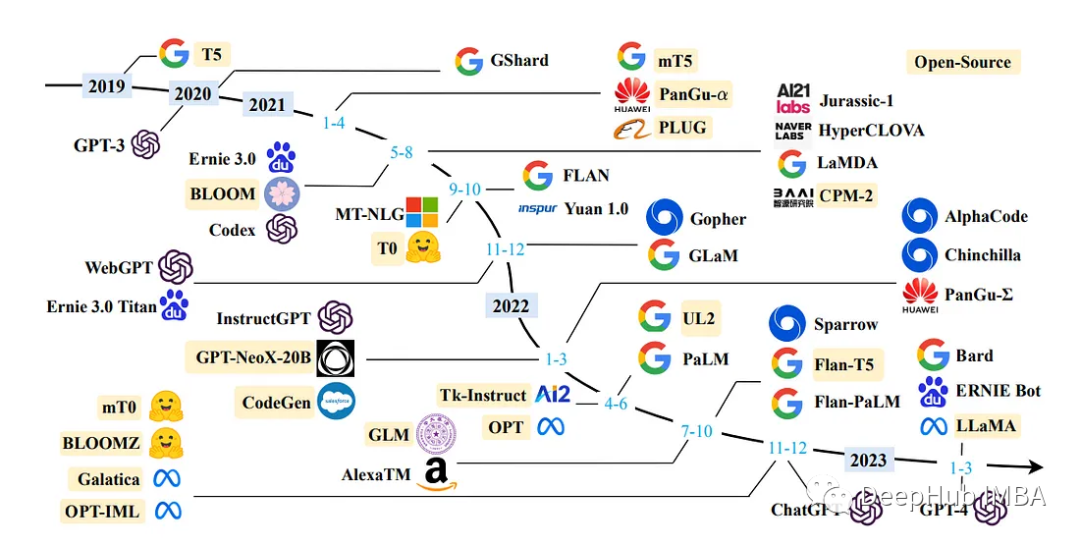
Выше представлен панорамный вид нынешнего LLM.
В этой статье я покажу, как создать собственный Document Assistant с нуля, используя LLaMA 7b и Langchain.
Базовые знания
1、LangChain 🔗
LangChain — это впечатляющая и бесплатная платформа, которая революционизирует процесс разработки широкого спектра приложений, включая чат-боты, генеративные ответы на вопросы (GQA) и обобщение. Путем плавного связывания компонентов из нескольких модулей LangChain может создавать приложения, используя большую часть llm.
2、LLaMA 🦙
LLaMA — это новая крупномасштабная языковая модель, разработанная Meta AI, материнской компанией Facebook. Благодаря коллекции моделей, насчитывающей от 7 до 65 миллиардов параметров, LLaMA является одной из наиболее полных языковых моделей, доступных в настоящее время. 24 февраля 2023 года Meta представила публике модель LLaMA, продемонстрировав свою приверженность открытой науке (хотя в настоящее время мы используем утекшую версию).
3. Что такое ГГМЛ
GGML — это тензорная библиотека для машинного обучения, это просто библиотека C++, которая позволяет запускать llm на ЦП или ЦП+ГП. Он определяет двоичный формат для распространения больших языковых моделей (llm). GGML использует технику, называемую квантованием, которая позволяет запускать большие языковые модели на потребительском оборудовании.
4. Количественная оценка
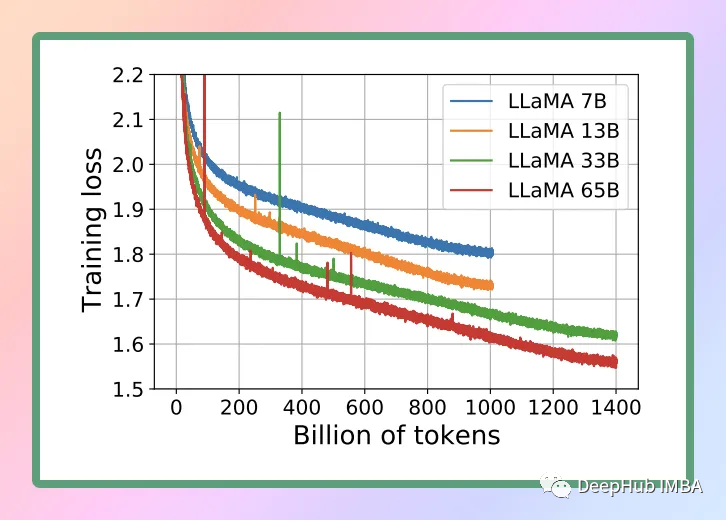
Мы все знаем, что веса модели представляют собой числа с плавающей запятой. Точно так же, как для представления большого целого числа (например, 1000) требуется больше места, чем для маленького целого числа (например, 1), так и для представления числа с плавающей запятой высокой точности (например, 0,0001) требуется больше места, чем для представления числа с плавающей запятой низкой точности. число (например, 0,1). Процесс количественной оценки больших языковых моделей включает снижение точности представления весов для уменьшения ресурсов, необходимых для использования модели. GGML поддерживает ряд различных стратегий квантования (например, 4-битное, 5-битное и 8-битное квантование), каждая из которых предлагает различные компромиссы между эффективностью и производительностью.
Ниже приводится сравнение размеров модели после квантования:

5、Streamlit🔥
Streamlit — это библиотека Python с открытым исходным кодом для создания приложений для обработки данных и машинного обучения. Он предназначен для того, чтобы позволить разработчикам создавать интерактивные приложения простым и быстрым способом без необходимости утомительной внешней разработки. Streamlit предоставляет простой набор API-интерфейсов для создания приложений с возможностями исследования данных, визуализации и взаимодействия. Вы можете создать веб-приложение с помощью простого скрипта Python. Вы можете использовать богатую библиотеку компонентов Streamlit для создания пользовательских интерфейсов, таких как текстовые поля, ползунки, раскрывающиеся меню и кнопки, а также визуальных компонентов, таких как диаграммы и карты.
1. Создайте виртуальную среду и структуру проекта.
Настройка виртуальной среды обеспечивает контролируемую и изолированную среду для запуска приложений, гарантируя, что их зависимости отделены от других общесистемных пакетов. Такой подход упрощает управление зависимостями и помогает поддерживать согласованность в различных средах.
Затем создаем наш проект. Хорошая структура ускорит нашу разработку, как показано на рисунке ниже.
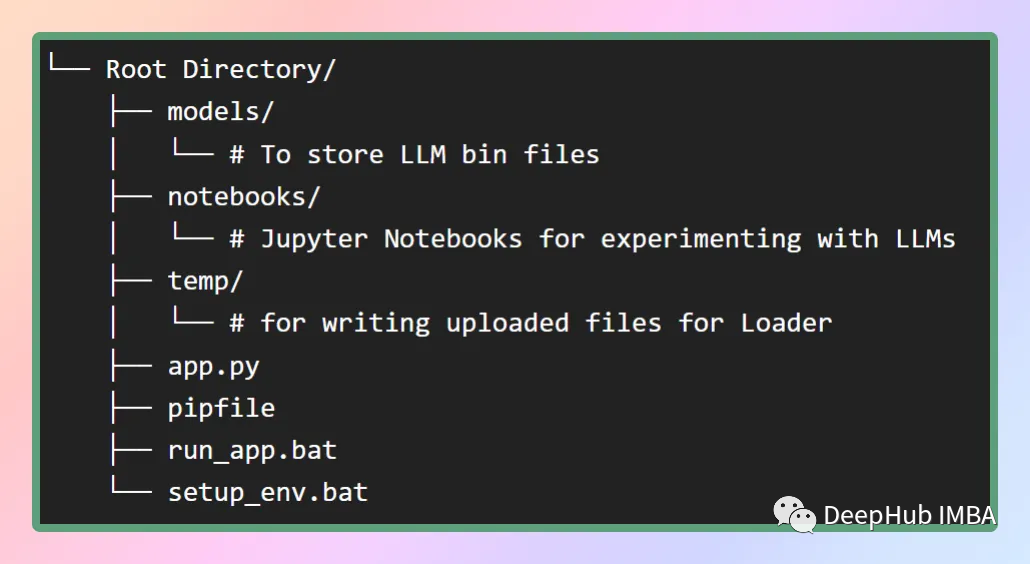
В папке моделей, где мы хотим хранить скачанный llm, setup_env.bat установит все зависимости из pip-файла. А run_app.bat запускает наше приложение напрямую. (Два вышеуказанных файла представляют собой сценарии в среде Windows)
2. Установите LLaMA на свой локальный компьютер.
Чтобы эффективно использовать модель, необходимо учитывать память и диск. Поскольку модели должны быть полностью загружены в память, на диске должно быть достаточно места не только для их хранения, но и достаточно оперативной памяти для их загрузки во время выполнения. Например, модель 65B даже после квантования требует 40 ГБ ОЗУ.
Поэтому, чтобы запустить его локально, мы будем использовать самую маленькую версию LLaMA — LLaMA 7B. Хотя это самая маленькая версия, LLaMA 7B также обеспечивает хорошие возможности языковой обработки, и нам удалось эффективно достичь ожидаемых результатов.
Для выполнения LLM на локальном процессоре мы используем локальные модели в формате GGML. Здесь загрузите файл bin непосредственно из репозитория Hugging Face Models, а затем переместите файл в каталог моделей в корневом каталоге.
Мы уже говорили об этом выше,GGML — это библиотека C++.,Таким образом, вам все равно нужно использовать Python для вызова интерфейса C++.,К счастью, этот шаг очень прост,мы будем использоватьllama-cpp-python,Это ЛЛАМА Привязки Python для .cpp, который работает на чистом C/ Вывод как модель LLaMA в C++. Основная цель cpp — запуск моделей LLaMA с использованием 4-битного целочисленного квантования. Это позволяет эффективно использовать модель LLaMA и в полной мере использовать возможности C/. Преимущество C++ в скорости и преимущество количественной оценки 4-битных целых чисел🚀.
llama.cpp также поддерживает множество других моделей. На следующем рисунке представлен список:

Когда у вас будет готова модель GGML и все зависимости, вы можете начать интеграцию LangChain. Но прежде чем мы начнем, нам нужно провести некоторое тестирование, чтобы убедиться, что наш LLaMA доступен локально:
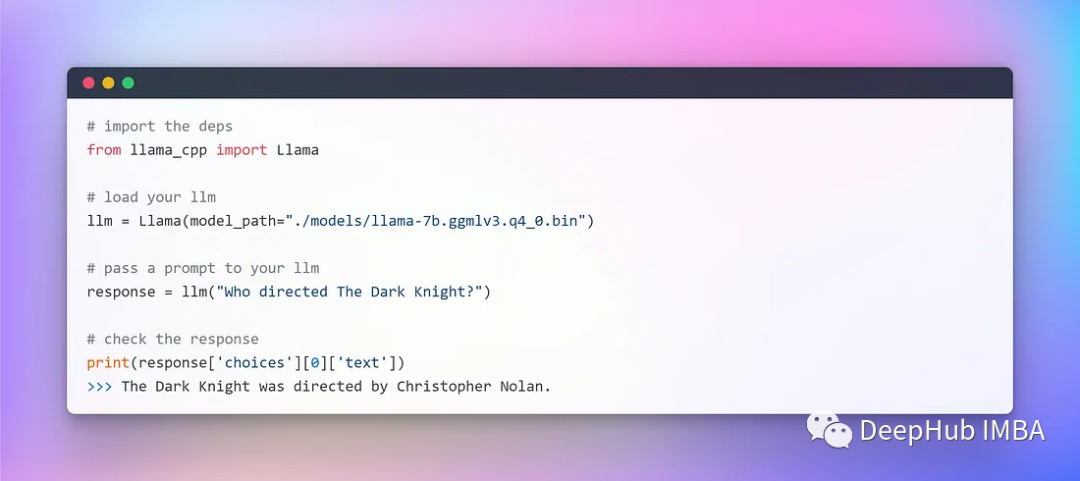
Никаких проблем не возникает, программа полностью автономна и запускается совершенно случайным образом (можно использовать гиперпараметры температуры).
3. LangChain интегрирует LLM
Теперь мы можем использовать платформу LangChain для разработки приложений с использованием llm.
Чтобы обеспечить беспрепятственное взаимодействие с llm, LangChain предоставляет несколько классов и функций, которые упрощают создание и использование подсказок с помощью шаблонов подсказок. Он содержит шаблон текстовой строки, который принимает набор параметров от конечного пользователя и генерирует приглашение. Давайте сначала рассмотрим несколько примеров.
Шаблон без входных параметров
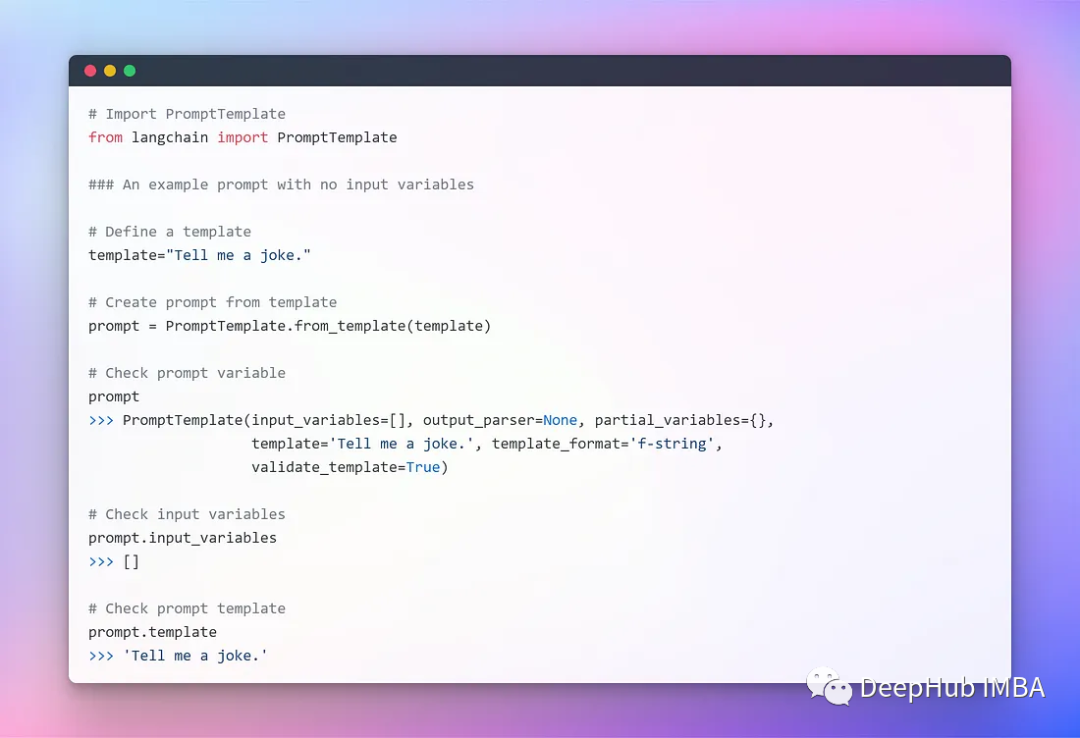
Шаблоны с несколькими параметрами
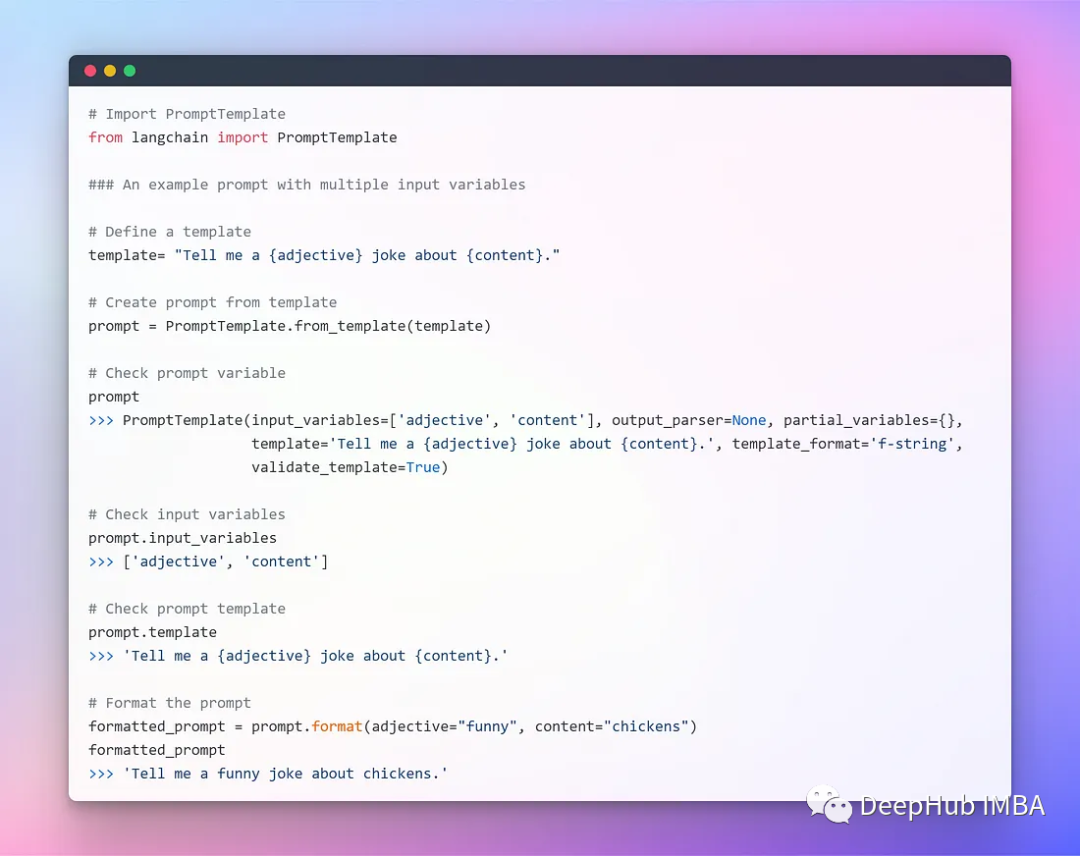
Далее мы можем использовать LangChain для интеграции.
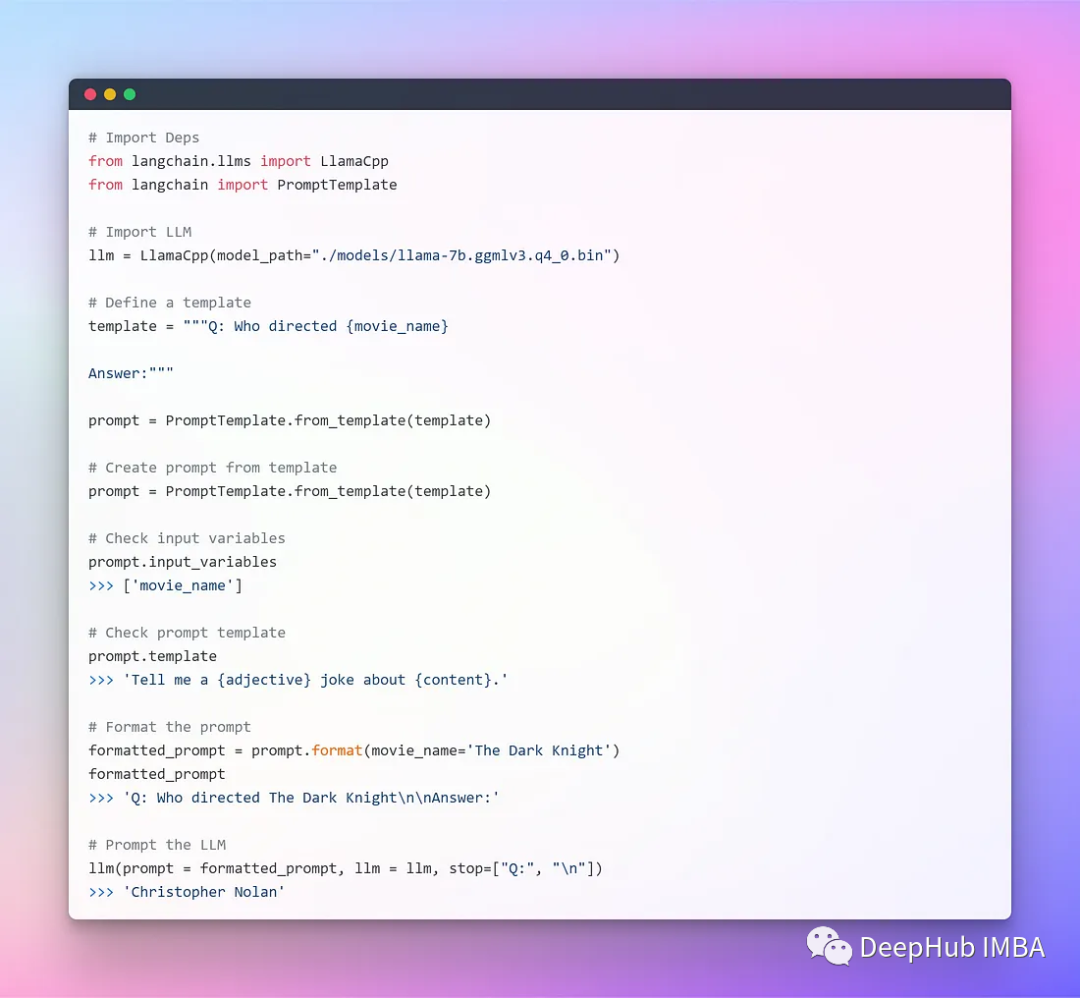
В настоящее время мы используем отдельный компонент, форматируем его с помощью шаблона приглашения, а затем используем llm, передавая эти параметры в llm для генерации ответа. Для простых приложений можно использовать только LLM, но для более сложных приложений требуется связь LLM — либо друг с другом, либо с другими компонентами.
LangChain предоставляет интерфейс Chain для такого рода приложений связи. Мы можем определить цепочку как последовательность вызовов компонента, которая может содержать другие цепочки. Цепочка позволяет нам объединять несколько компонентов вместе для создания единого согласованного приложения. Например, вы можете создать цепочку, которая принимает вводимые пользователем данные, форматирует их с помощью шаблона подсказки, а затем передает форматированный ответ в LLM. Мы можем создавать более сложные цепочки, объединяя несколько цепочек вместе или комбинируя их с другими компонентами. На самом деле это похоже на конвейер в нашей общей обработке данных.
Создайте очень простую цепочку🔗, которая будет принимать вводимые пользователем данные, форматировать с их помощью приглашение, а затем отправлять его в LLM, используя различные компоненты, которые мы создали выше.
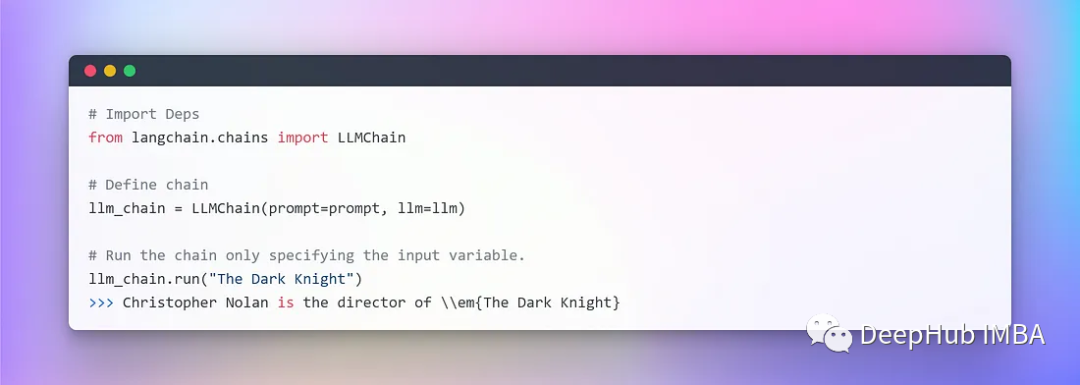
4. Создание вложений и векторных библиотек
Во многих приложениях LLM требуются специфичные для пользователя данные, которые не включены в обучающий набор модели. LangChain предоставляет базовые компоненты для загрузки, преобразования, хранения и запроса данных, которые мы можем использовать прямо здесь.
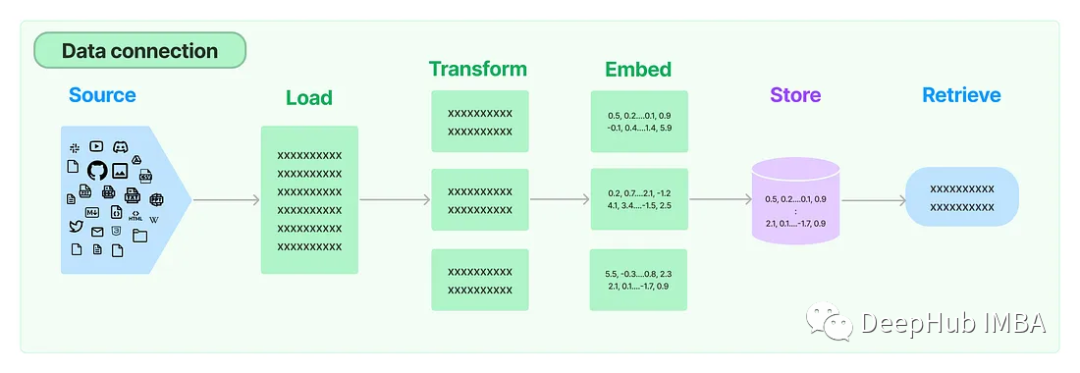
На картинке выше 5 компонентов:
- Загрузчик документов: используется для загрузки данных в виде документов.
- Конвертер документов: разбивает документ на более мелкие фрагменты.
- Встраивание: преобразует блоки в векторные представления, т. е. вложения.
- Встроенное хранилище векторов: используется для хранения вышеуказанных блочных векторов в базе данных векторов.
- Поиск: используется для извлечения набора векторов, наиболее похожих на запрос, в виде векторов, встроенных в одно и то же скрытое пространство.
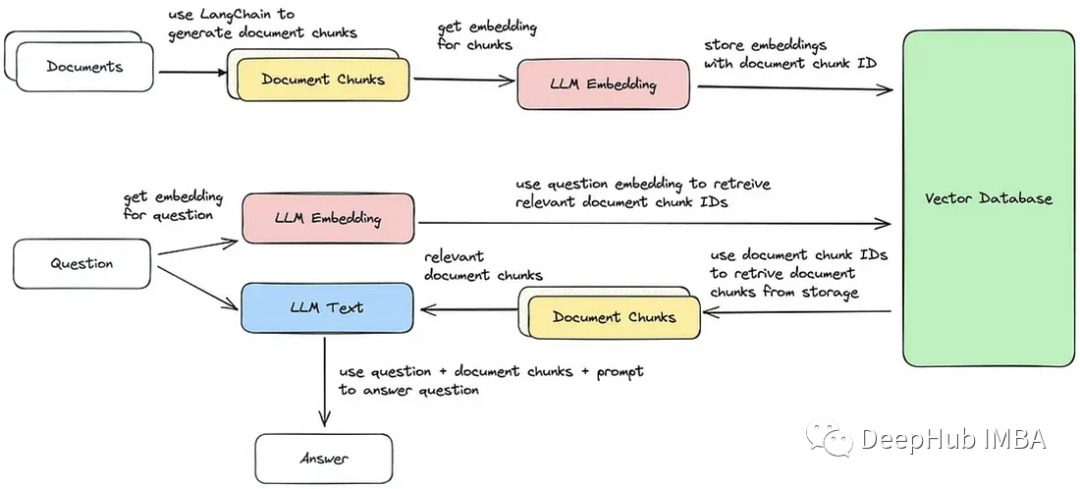
Мы реализуем эти пять шагов, а блок-схема показана на изображении ниже.
Здесь мы используем текст, скопированный из Википедии, о некоторых супергероях DC для тестирования при разработке. Исходный текст следующий:
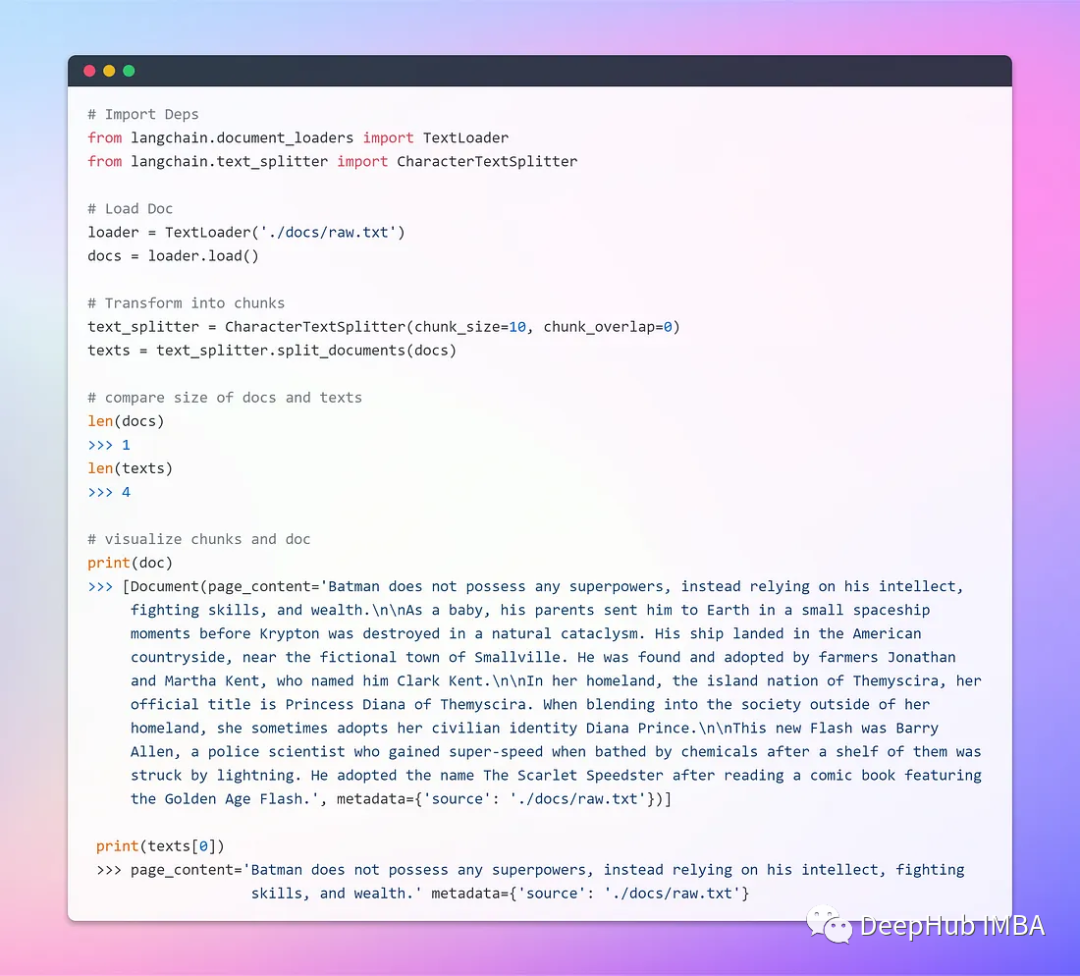
а. Загрузите и конвертируйте документы.
Создайте объект документа с помощью текстового загрузчика (цепочка Lang обеспечивает поддержку нескольких документов, и в зависимости от документа можно использовать разные загрузчики), получите данные с помощью метода загрузки и загрузите их как документ из предварительно настроенного источника.
После загрузки документа продолжите процесс преобразования, разбив его на более мелкие фрагменты. Используйте TextSplitter (по умолчанию разделитель разделяет документы разделителями '\n\n'). Если вы установите для разделителя значение null и определите определенный размер блока, каждый блок будет иметь указанную длину. В результате получается список фрагментов, длина которого будет равна длине документа, разделенной на размер фрагмента.
b.Embeddings
Встраивание слова — это просто векторное представление слова, и вектор содержит действительные числа. Вложения слов решают проблему простых векторов двоичных слов из-за высокой размерности, обеспечивая плотное представление слов в низкомерном векторном пространстве.
Базовый класс Embeddings в LangChain предоставляет два метода: один для внедрения документов, а другой — для внедрения запросов. Первый принимает на вход несколько текстов, а второй — один текст.
Поскольку последующий поиск также извлекает наиболее похожие векторы, встроенные в одно и то же скрытое пространство, векторы слов должны быть сгенерированы с использованием одного и того же метода (модели).
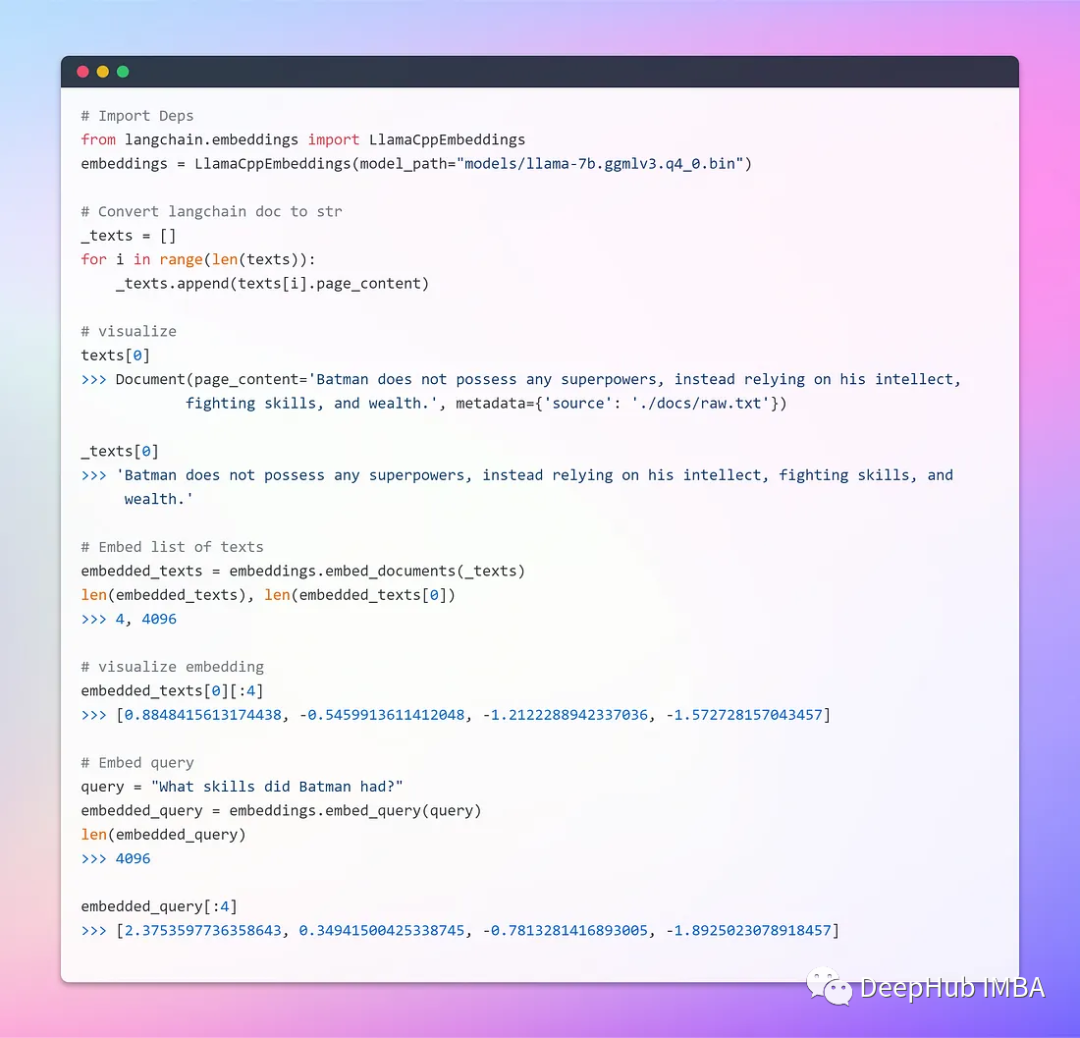
c. Создание документов хранения и поиска.
Векторное хранилище эффективно управляет хранением встроенных данных и ускоряет операции векторного поиска. Мы будем использовать Chroma, векторную базу данных, специально разработанную для упрощения разработки приложений, содержащих встроенный искусственный интеллект. Он предоставляет полный набор встроенных инструментов и функций, и нам просто нужно установить его локально с помощью команды pip install chromadb.

Теперь, когда мы можем хранить и извлекать векторы, давайте интегрируем их с LLM.
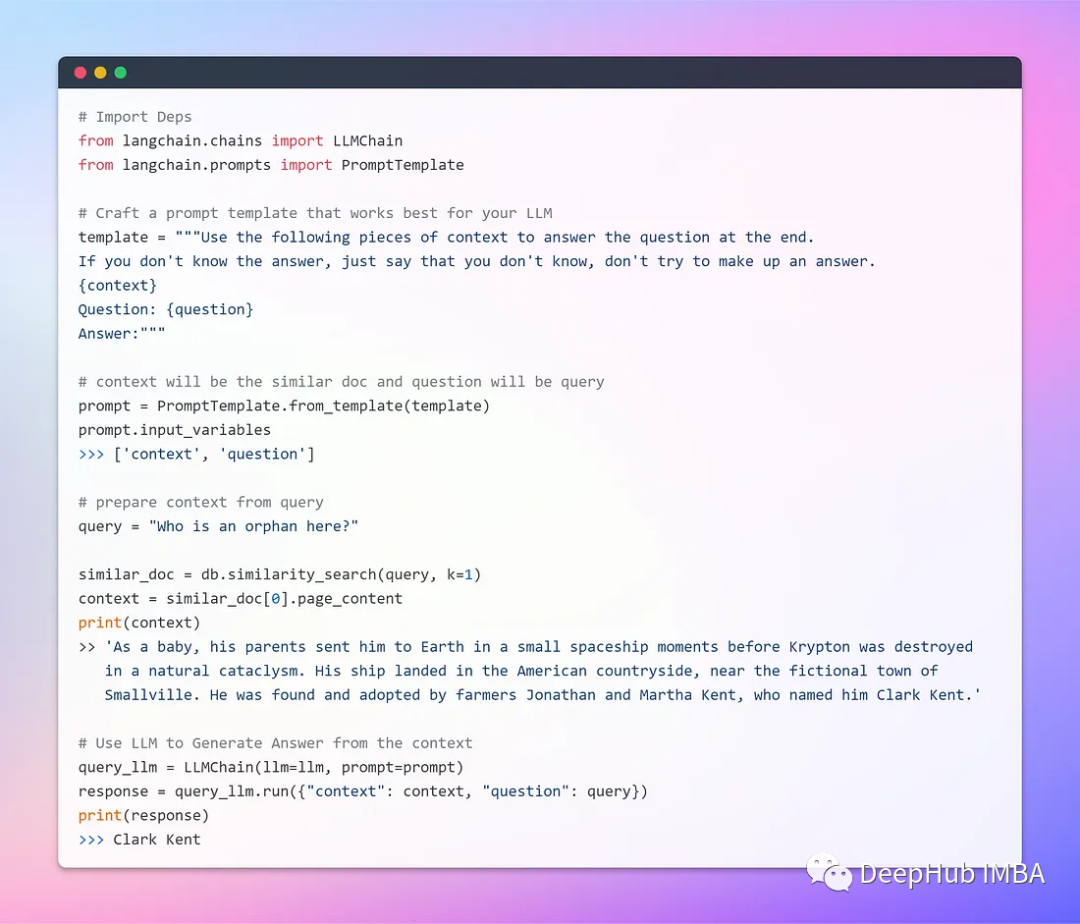
На этом этапе мы уже можем использовать локально работающий LLM для создания робота вопросов и ответов. Результат неплох, но у нас все еще есть лучшее требование — графический интерфейс.
5、Streamlit
Если вы предпочитаете запускать только из командной строки, этот раздел совершенно необязателен. Потому что здесь мы создадим WEB-программу, которая позволит пользователям загружать любой текстовый документ. Документы можно анализировать, задавая вопросы посредством ввода текста.
Поскольку требуется загрузка файла, чтобы предотвратить возможные ошибки нехватки памяти, мы просто прочитаем документ, запишем его во временную папку и переименуем в raw.txt. Таким образом, независимо от исходного имени документа, Textloader будет легко обрабатывать его в будущем (здесь мы предполагаем: один пользователь обрабатывает только один файл за раз).
Мы также обрабатываем только txt-файлы, код следующий:
import streamlit as st
from langchain.llms import LlamaCpp
from langchain.embeddings import LlamaCppEmbeddings
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# Customize the layout
st.set_page_config(page_title="DOCAI", page_icon="🤖", layout="wide", )
st.markdown(f"""
<style>
.stApp {{background-image: url("https://images.unsplash.com/photo-1509537257950-20f875b03669?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=1469&q=80");
background-attachment: fixed;
background-size: cover}}
</style>
""", unsafe_allow_html=True)
# function for writing uploaded file in temp
def write_text_file(content, file_path):
try:
with open(file_path, 'w') as file:
file.write(content)
return True
except Exception as e:
print(f"Error occurred while writing the file: {e}")
return False
# set prompt template
prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Answer:"""
prompt = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
# initialize hte LLM & Embeddings
llm = LlamaCpp(model_path="./models/llama-7b.ggmlv3.q4_0.bin")
embeddings = LlamaCppEmbeddings(model_path="models/llama-7b.ggmlv3.q4_0.bin")
llm_chain = LLMChain(llm=llm, prompt=prompt)
st.title("📄 Document Conversation 🤖")
uploaded_file = st.file_uploader("Upload an article", type="txt")
if uploaded_file is not None:
content = uploaded_file.read().decode('utf-8')
# st.write(content)
file_path = "temp/file.txt"
write_text_file(content, file_path)
loader = TextLoader(file_path)
docs = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
texts = text_splitter.split_documents(docs)
db = Chroma.from_documents(texts, embeddings)
st.success("File Loaded Successfully!!")
# Query through LLM
question = st.text_input("Ask something from the file", placeholder="Find something similar to: ....this.... in the text?", disabled=not uploaded_file,)
if question:
similar_doc = db.similarity_search(question, k=1)
context = similar_doc[0].page_content
query_llm = LLMChain(llm=llm, prompt=prompt)
response = query_llm.run({"context": context, "question": question})
st.write(response)Взгляните на наш интерфейс:
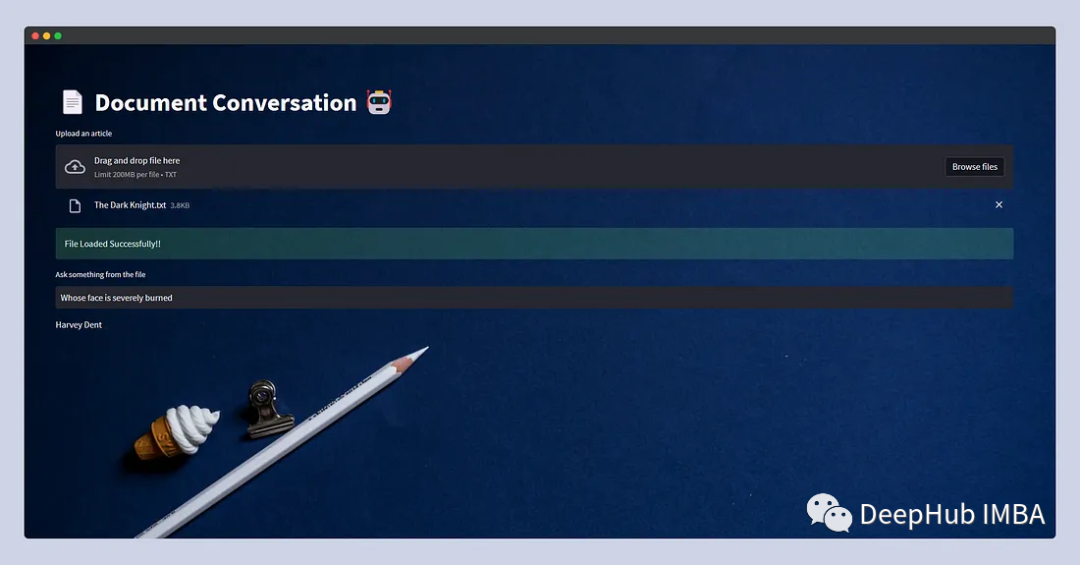
На этом простая и удобная программа завершена.
Подвести итог
С помощью LangChain и Streamlit мы можем легко интегрировать любую модель LLM, а с помощью GGML мы можем запускать большие модели на оборудовании потребительского уровня, что очень полезно для наших личных исследований.
Если вас заинтересовала эта статья, вот полный исходный код этой статьи, который можно скачать и использовать напрямую:
https://github.com/afaqueumer/DocQA
Автор: Афак Умер



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
